为什么以前的多麦克风阵列降噪技术会被AI降噪的单麦克风降噪技术取代?(传统的单/多麦克风降噪原理与AI降噪单麦克风原理对比)
本文基于传统单双麦克风降噪原理和AI降噪原理,详细总结传统单麦克风降噪、传统双麦克风降噪(含主副双麦、双麦阵列波束成型)与AI神经网络单麦克风降噪的核心区别,并深入解析为何AI降噪仅需单个麦克风,就能实现优于传统多麦克风降噪的效果,全面呈现三种降噪技术的特点、局限与优势。
一、三种降噪技术核心概述与详细对比
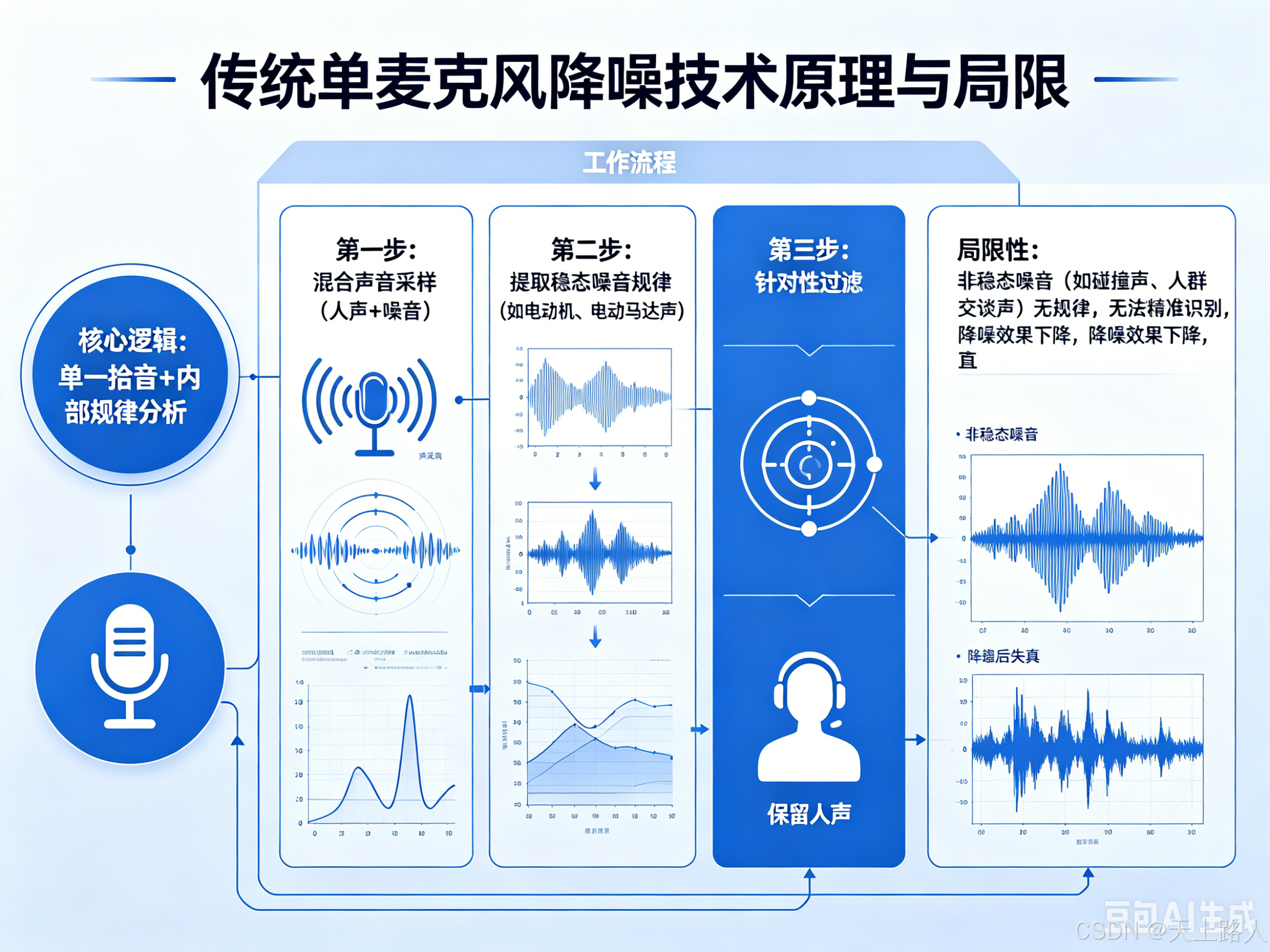
(一)传统单麦克风降噪技术
传统单麦克风降噪是早期主流的降噪方案,核心逻辑是“单一拾音+内部规律分析”,无需额外麦克风辅助,仅通过对单个麦克风收录的混合声音(人声+噪音)进行内部处理,实现降噪效果。
核心工作流程:先对麦克风采集的声音进行采样,提取噪音标本并分析其规律,再针对该规律对混合声音进行过滤,最终保留人声、去除噪音。
核心特点:
-
硬件要求简单:仅需1个麦克风,无需额外硬件,成本低、易集成;
-
降噪范围有限:仅能有效处理稳态噪音(即具有固定规律的噪音,如电动机、电动马达的运行声,波形稳定、可预测);
-
局限性显著:面对无规律的非稳态噪音(如突发的碰撞声、人群交谈声)时,无法精准识别和处理,降噪效果大幅下降;且仅能通过固定规律过滤噪音,易出现误伤人声的情况。
(二)传统双麦克风降噪技术
传统双麦克风降噪是为解决单麦克风降噪无法处理非稳态噪音的痛点而发展的技术,主要分为两种类型,核心逻辑均为“多拾音+对比/定位分析”,需两个麦克风配合工作。
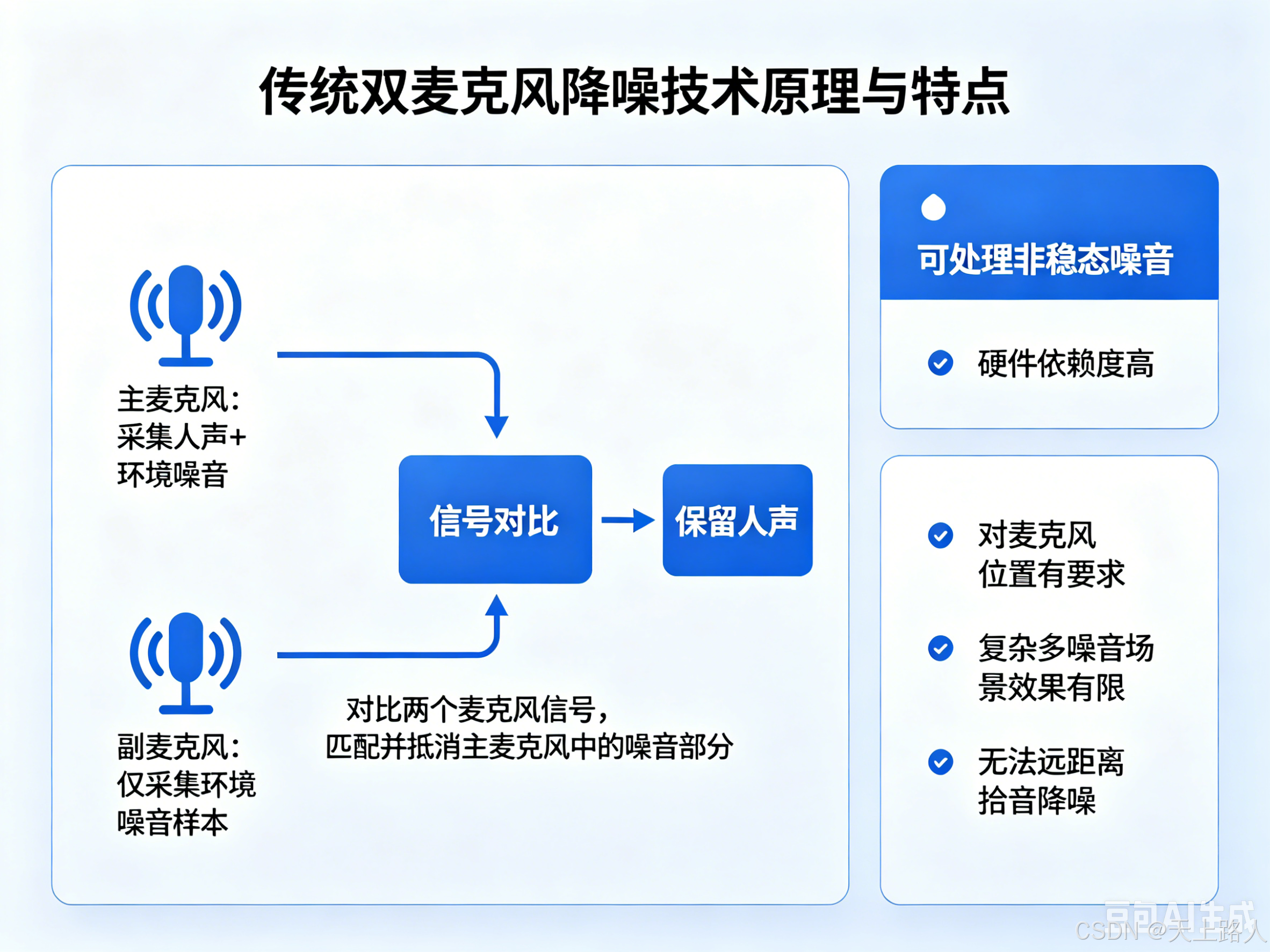
1. 主副双麦克风降噪
核心设计:设置1个主麦克风(负责采集人声+环境噪音)和1个副麦克风(仅负责采集环境噪音样本),通过对比主、副麦克风采集的信号,将主麦克风中的噪音部分与副麦克风的噪音样本进行匹配、抵消,从而保留人声。
核心特点:
-
可处理非稳态噪音:相比单麦克风降噪,新增副麦克风专门采集噪音样本,能针对性处理无规律的非稳态噪音;
-
硬件依赖度高:需两个麦克风配合,且对主副麦克风的位置摆放有一定要求,集成难度高于单麦克风方案;
-
局限明显:仅能通过“噪音样本比对”降噪,无法精准定位人声,面对复杂多噪音场景(如多种非稳态噪音同时存在)时,降噪效果有限;且无法实现远距离拾音降噪。
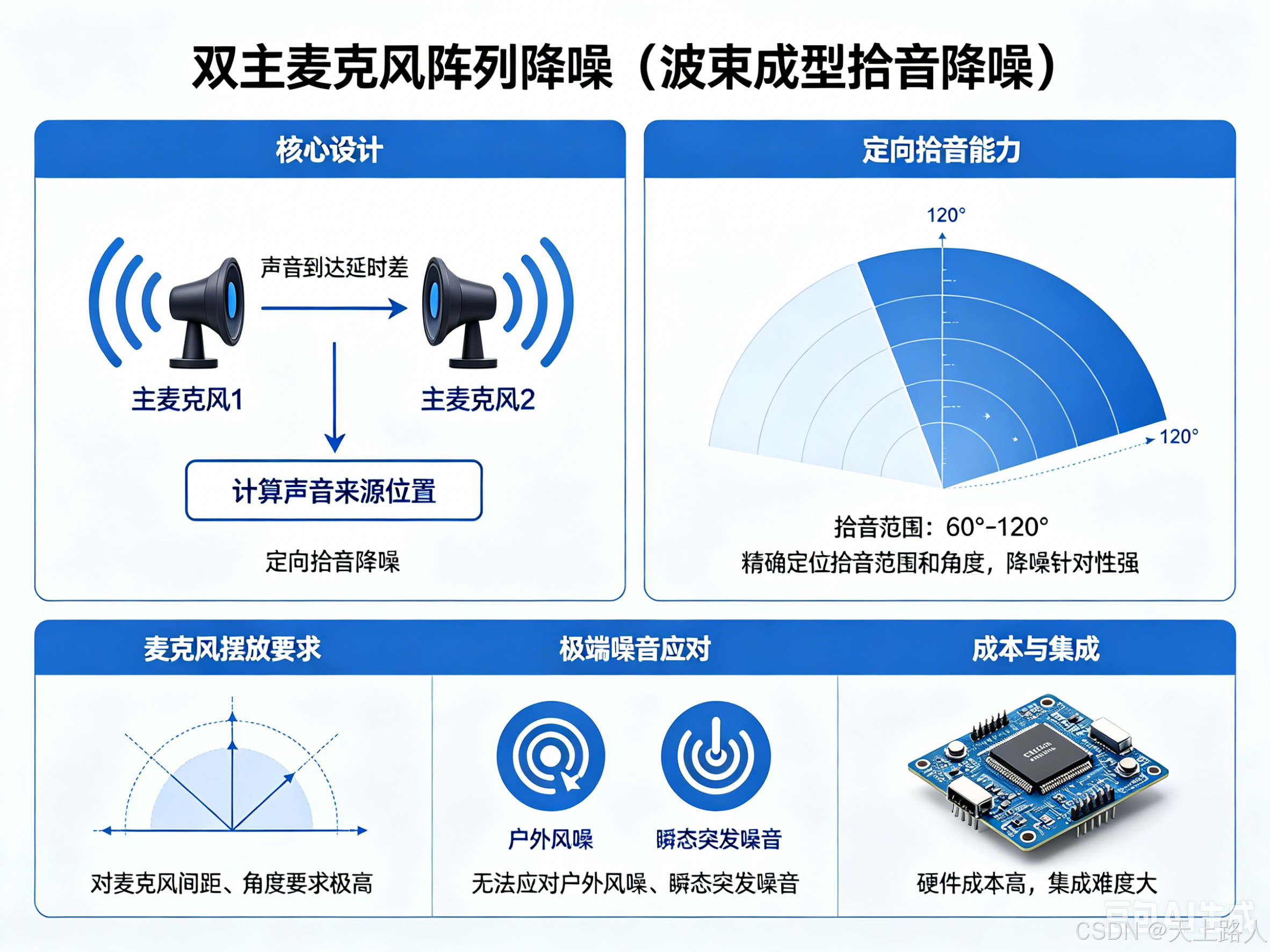
2. 双主麦克风阵列降噪(波束成型拾音降噪)
核心设计:采用两个主麦克风组成阵列,利用声音到达两个麦克风的延时差,计算声音的来源位置,进而对目标方向的声音进行频段分析并保留,对非目标方向的声音(噪音)进行压制、消除,实现定向拾音降噪。
核心特点:
-
具备定向拾音能力:可精确定位拾音范围和角度,能辅助语音识别产品精准提取目标语音;
-
降噪针对性强:通过空间定位区分人声与噪音,对目标方向的噪音抑制效果优于主副双麦方案;
-
局限性突出:对麦克风的摆放间距、角度要求极高,摆放不当会导致定位偏差、降噪失效;仍无法应对极端复杂噪音(如户外风噪、瞬态突发噪音);且硬件成本和集成难度进一步提升。
-
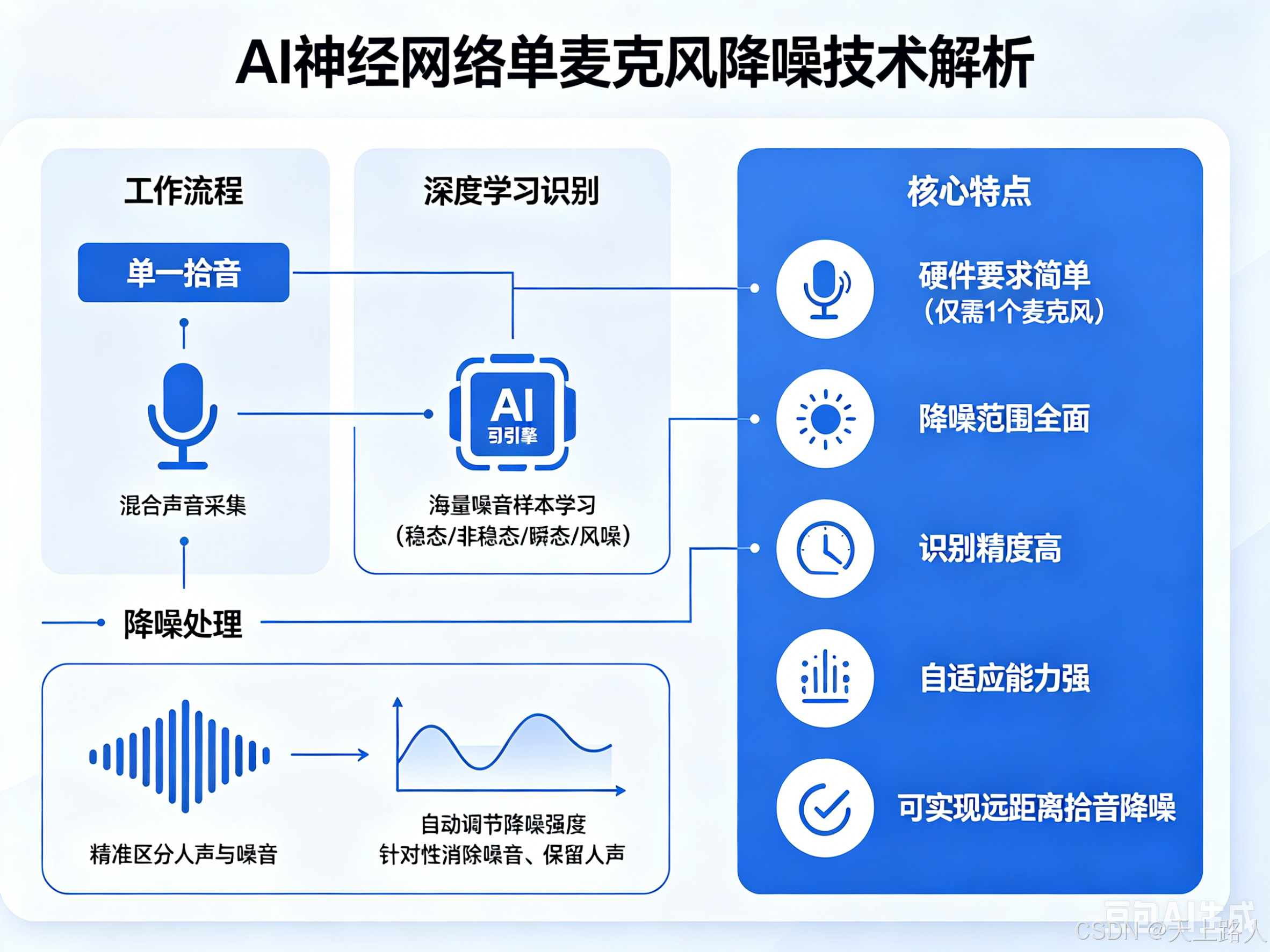
(三)AI神经网络单麦克风降噪技术
AI神经网络单麦克风降噪是依托AI技术发展的新型降噪方案,核心逻辑是“单一拾音+深度学习识别”,仅需1个麦克风,通过内置的AI神经网络引擎,对海量噪音样本进行提前训练学习,实现自适应、高精度降噪。
核心工作流程:AI降噪引擎提前学习海量不同类型的噪音样本(涵盖稳态、非稳态、瞬态、风噪等),当单个麦克风采集到混合声音后,AI引擎通过深度学习的特征识别能力,精准区分人声与噪音,自动调节降噪强度,针对性消除噪音、保留人声。
核心特点:
-
硬件要求简单:仅需1个麦克风,无需额外副麦克风或阵列配置,成本低、集成难度低;
-
降噪范围全面:可同时处理稳态噪音、非稳态噪音,还能应对传统降噪无法处理的极端噪音(如风噪、瞬态突发噪音);
-
识别精度高:通过神经网络深度学习,能精准识别人声结构与各种噪音特征,避免误伤人声;
-
自适应能力强:可实时学习当前环境的噪音变化,动态调节降噪策略,无需人工干预;
-
突破距离限制:无需依赖多麦克风定位,可实现远距离拾音降噪,解决了传统双麦降噪无法实现的远距离降噪需求。
(四)三种技术核心参数对比表
|
对比维度 |
传统单麦克风降噪 |
传统双麦克风降噪(主副/阵列) |
AI神经网络单麦克风降噪 |
|---|---|---|---|
|
麦克风数量 |
1个 |
2个 |
1个 |
|
核心原理 |
单一拾音+固定规律分析 |
双拾音+样本比对/空间定位 |
单一拾音+AI深度学习识别 |
|
可处理噪音类型 |
仅稳态噪音 |
稳态+非稳态噪音(部分) |
稳态、非稳态、瞬态、风噪等所有常见噪音 |
|
硬件成本 |
低 |
中-高 |
低 |
|
集成难度 |
低 |
中-高(依赖麦克风摆放) |
低 |
|
降噪精度 |
低(易误伤人声) |
中(依赖场景与摆放) |
高(精准识别人声与噪音) |
|
自适应能力 |
弱(固定规则,无法适应环境变化) |
弱(需人工调整摆放/参数) |
强(实时学习,动态适配环境) |
|
远距离降噪 |
不可实现 |
难以实现 |
可实现 |
二、为什么AI降噪仅需单麦克风,就能优于传统多麦克风降噪?
核心原因在于AI神经网络降噪的“深度学习能力”,打破了传统降噪“依赖硬件数量(多麦克风)实现降噪”的逻辑,通过软件算法的革新,用单一麦克风实现了传统多麦克风无法达到的降噪效果,具体可从以下4个核心维度解析:
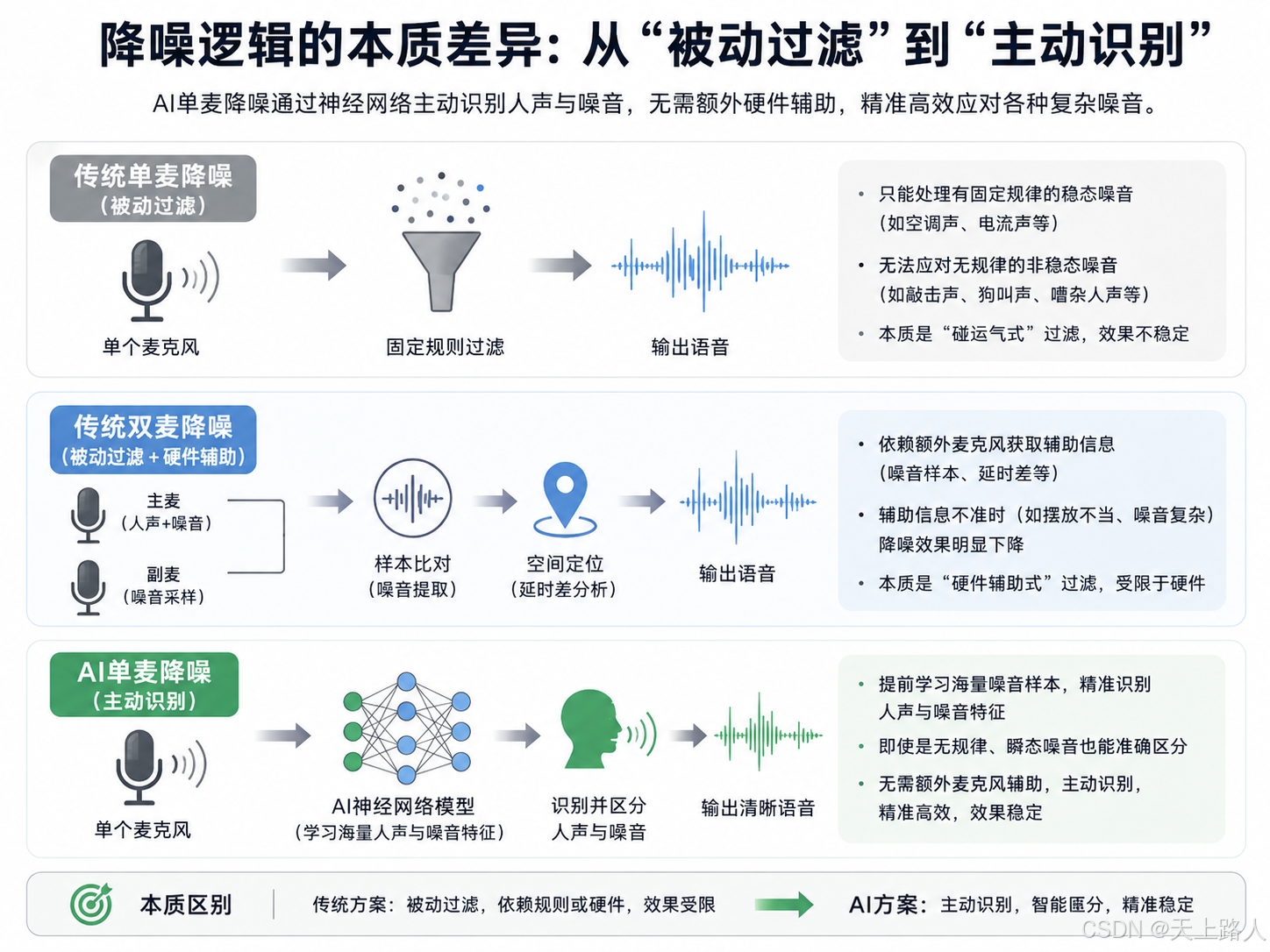
(一)降噪逻辑的本质差异:从“被动过滤”到“主动识别”
传统单/双麦克风降噪均属于“被动过滤”逻辑,依赖“固定规则”或“硬件辅助”实现降噪:
-
传统单麦降噪:仅能识别“有固定规律”的稳态噪音,通过预设的过滤规则去除噪音,无法应对无规律的非稳态噪音,本质是“碰运气式”过滤;
-
传统双麦降噪:无论是主副双麦的“样本比对”,还是双麦阵列的“空间定位”,都需要通过额外麦克风获取辅助信息(噪音样本、延时差),才能实现针对性降噪,本质是“硬件辅助式”过滤,一旦辅助信息获取不准(如麦克风摆放不当、噪音样本复杂),降噪效果就会下降。
而AI单麦降噪采用“主动识别”逻辑:AI神经网络提前训练了海量噪音样本(涵盖所有传统降噪能处理和不能处理的噪音类型),能够精准识别“人声”与“噪音”的核心特征——即使是无规律的非稳态噪音、瞬态噪音,AI也能通过深度学习的经验,快速判断并区分,无需依赖额外麦克风的辅助信息,从根源上提升了降噪的精准度。
(二)噪音处理能力的全面性:覆盖传统多麦无法应对的场景
传统双麦克风降噪虽然比单麦降噪的处理范围广,但仍有明显局限:无法处理风噪、瞬态突发噪音(如椅子移动、茶杯破碎、装修砸墙声),且难以实现远距离降噪——这些局限并非“增加麦克风数量”就能解决,而是传统降噪算法的本质缺陷。
AI单麦降噪则通过深度学习,突破了这些局限:
-
应对风噪:AI能识别风噪的独特特征(如风吹麦克风振膜的震动信号),针对性进行动态抑制,而传统双麦降噪无法区分风噪与人声的震动差异,难以处理;
-
应对瞬态噪音:AI无需像传统降噪那样“先采样、再分析、后处理”,凭借自适应算法,可瞬间识别并排除瞬态噪音,避免噪音输出;
-
远距离降噪:传统双麦降噪依赖麦克风间距计算延时差,远距离拾音时延时差不明显,定位失效,降噪效果骤降;而AI单麦降噪无需定位,仅通过声音特征识别,就能精准提取远距离的人声,抑制环境噪音。
-

(三)硬件依赖度降低:用算法替代硬件,避免硬件局限
传统双麦克风降噪的效果,高度依赖麦克风的摆放位置、间距、角度:主副双麦需合理区分“拾音”与“采噪”位置,双麦阵列需严格控制间距以保证延时差计算精准,一旦摆放不当,降噪效果会大幅下降,甚至失效。而这种硬件摆放的限制,在很多小型设备(如耳机、小型对讲机)中难以实现,导致传统双麦降噪的应用场景受限。
AI单麦降噪则完全摆脱了对硬件摆放的依赖:仅需1个麦克风,无需考虑间距、角度等问题,通过AI算法的深度学习能力,就能实现高精度降噪。相当于用“软件算法的优势”,替代了“硬件数量的优势”,既降低了硬件成本和集成难度,又避免了硬件摆放带来的局限。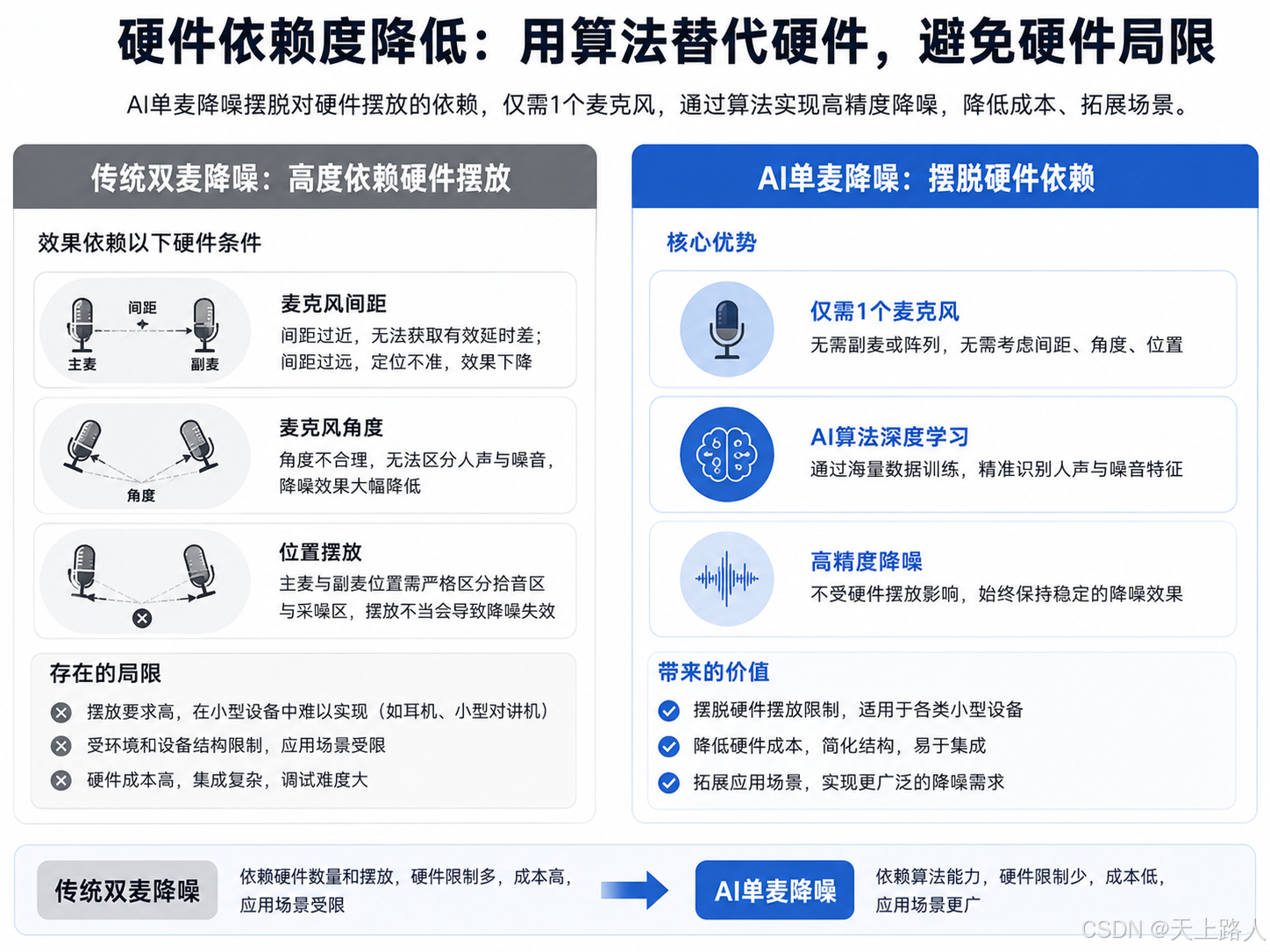
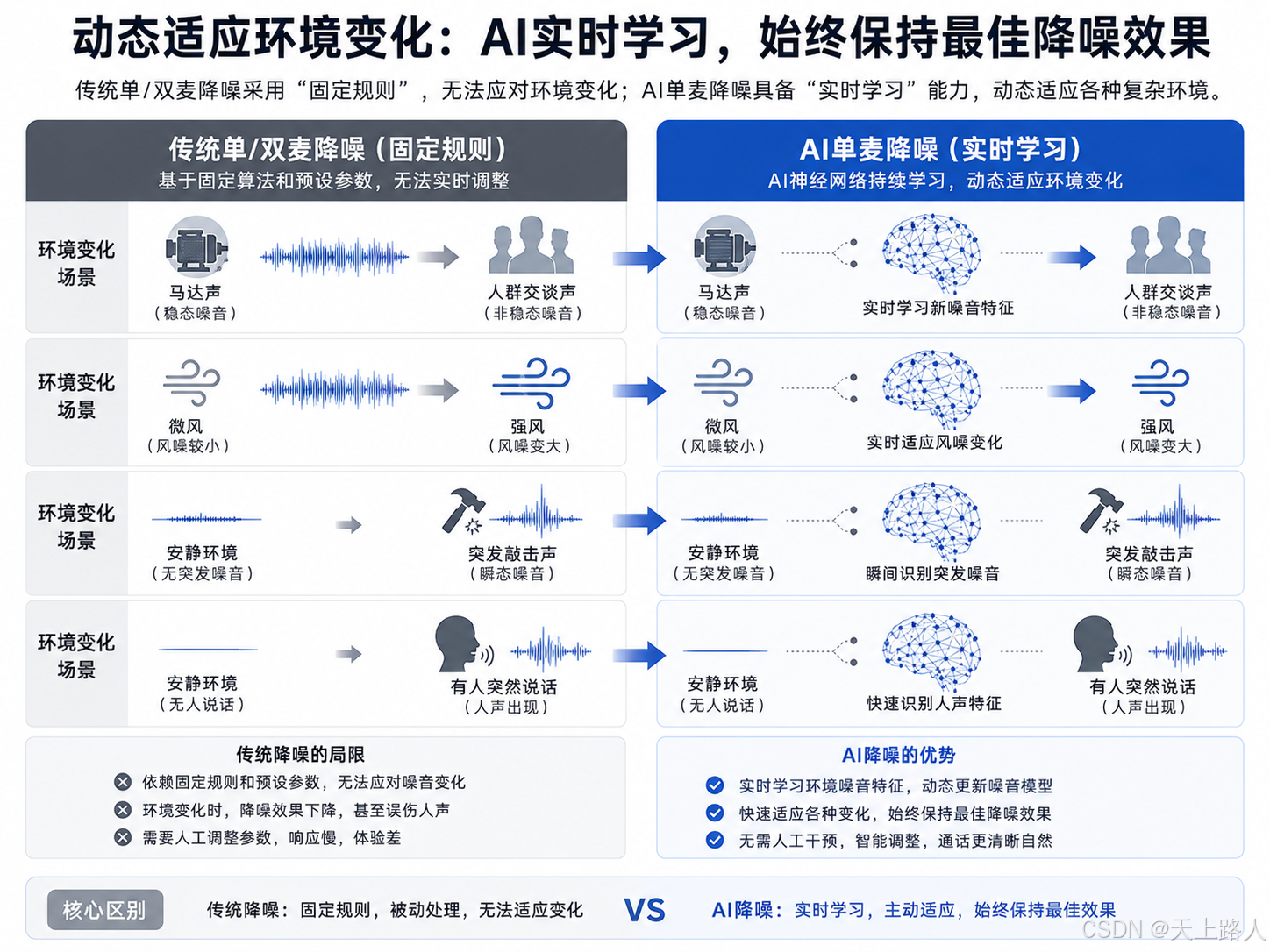
(四)自适应能力:实时动态调整,适配复杂环境变化
传统单/双麦克风降噪均采用“固定规则”降噪,一旦环境噪音发生变化(如从稳态的马达声变为非稳态的人群交谈声,或风突然变大),传统降噪算法无法实时调整,降噪效果会明显下降,甚至出现误伤人声的情况。
AI单麦降噪具备“实时学习”能力:AI神经网络会持续更新当前环境的噪音模型,动态适应环境变化——无论是风突然变大、有人突然说话,还是出现突发的敲击声,AI都能快速识别新的噪音特征,调整降噪强度和策略,始终保持最佳降噪效果,这是传统多麦克风降噪无法实现的核心优势。
三、总结
传统单麦克风降噪仅能处理简单稳态噪音,硬件简单但效果有限;传统双麦克风降噪(主副双麦、双麦阵列)虽能扩展降噪范围,处理部分非稳态噪音,甚至实现定向拾音,但高度依赖硬件摆放,无法应对风噪、瞬态噪音等复杂场景,且成本和集成难度较高。
AI神经网络单麦克风降噪的核心优势,在于其“深度学习+主动识别”的逻辑——无需额外麦克风辅助,通过提前训练的海量噪音样本,能精准区分各类噪音与人声,覆盖传统多麦降噪无法应对的复杂场景,同时具备实时自适应能力,摆脱了硬件摆放的局限,实现了“单麦胜多麦”的效果。这种“算法革新替代硬件堆砌”的模式,不仅降低了成本和集成难度,更推动了语音降噪技术的革新,让单麦克风设备也能实现高精度、全场景的降噪效果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)