【深度解析】何恺明首发【语言模型 ELF】:105M 参数碾压主流扩散 LM,连续 embedding 空间去噪一步解码,NLP 范式挑战者来了
【深度解析】何恺明首发【语言模型 ELF】:105M 参数碾压主流扩散 LM,连续 embedding 空间去噪一步解码,NLP 范式挑战者来了
作者:技术博主 | 更新时间:2026-05-14 | 阅读时长:约 20 分钟
论文:《ELF: Embedded Language Flows》,arXiv:2605.10938,2026-05-13 发布
标签:ELF扩散语言模型Flow Matching连续嵌入何恺明MITCFG语言生成NLP

🔥 一句话定位:何恺明团队从计算机视觉杀入 NLP,首个语言模型直接选了最难走的路——连续扩散。结果证明这条路不只可行,而且效率惊人:105M 参数、45B token、32 步采样,在 OpenWebText 上生成困惑度 24,用 1/10 的训练数据打赢同类所有方法。本篇完整拆解 ELF 的设计哲学、技术细节和实验数据。
目录
- 一、背景:何恺明为什么做语言模型?
- 二、扩散语言模型的两条路线:离散派 vs 连续派
- 三、ELF 的核心思想:全程留在连续空间,最后一步离散化
- 四、技术实现四要素详解
- 五、关键设计:共享权重网络一肩挑去噪与解码
- 六、CFG 的跨域移植:图像技术如何用于文本
- 七、实验数据:三个维度碾压对手
- 八、作者团队背景
- 九、ELF 的意义与局限
- 十、关键公式速查
一、背景:何恺明为什么做语言模型?
在生成式 AI 几乎完全被"预测下一个 token"的自回归范式统治的时代,计算机视觉领域的标志性人物何恺明正式杀入语言模型领域,带领 MIT 团队——选择了一条截然不同的路。
这件事放在他过去两年的研究脉络里,其实一点都不突然。
2025 年,何恺明在 NeurIPS 和 CVPR 的多次演讲中都在强调同一个判断:
识别是从数据到嵌入的"流",生成是从嵌入到数据的"流"。两者是同一枚硬币的两面。
他用 MeanFlow(2025 年 5 月)解决了图像一步生成的问题,如今用 ELF 把同样的 Flow Matching 框架搬进了语言生成——而且特意选了连续路线,因为这正是图像扩散模型最擅长的空间。
论文全名:ELF: Embedded Language Flows,发布于 2026 年 5 月 13 日,arXiv:2605.10938。
二、扩散语言模型的两条路线:离散派 vs 连续派

如上图一所示(三种范式对比)。
理解 ELF 的起点,是先弄清楚它面对的历史格局。
2.1 为什么扩散模型要用于语言?
扩散模型在图像生成上已经证明了极强的能力——DALL·E 3、Stable Diffusion、Flux 全都是扩散模型的成果。自然地,研究者们想把这个框架搬到语言生成上。
好处显而易见:
- 可以并行生成(不像 GPT 必须串行 token-by-token)
- 扩散框架天然支持条件控制、迭代精炼
- 有可能绕过自回归模型的单向性限制
麻烦也很明显:文本是离散的,而扩散模型天生处理连续数据。这个本质矛盾催生了两条路线。
2.2 离散派:在 token 空间直接去噪
代表方法:MDLM、LLaDA、Masked Diffusion。
处理方式:
把 token 序列随机 mask(类似 BERT 的思路)
训练模型"猜"被遮住的 token
推理时从全 MASK 开始,逐步"揭开"
优点:简单直接,天然处理离散结构
缺点:
图像领域的 CFG 等技术无法直接用
去噪轨迹是跳跃的(离散空间),不如连续空间平滑
可控性不如连续扩散
2024-2025 年,离散派因为 LLaDA 的出圈而备受关注,一时间几乎成了扩散语言模型的"标准路线"。
2.3 连续派:在 embedding 空间去噪
代表方法:CDLM、PLAID、Diffusion-LM。
处理方式:
先把 token 映射为连续 embedding 向量
在连续空间做去噪(类似图像扩散)
最后再把结果转回离散 token
理论上更优雅(扩散模型本来就擅长连续空间)
但在 ELF 之前,连续派的效果长期落后于离散派。核心问题有两个:
- 解码难题:连续空间的结果如何可靠地转回离散 token?通常需要额外训练一个解码器,增加了复杂度和训练成本。
- 训练不稳定:连续 embedding 的分布与 Gaussian 噪声的差异比图像大得多,去噪轨迹难以学习。
ELF 的贡献,就是找到了一个优雅的方案把这两个问题都解决了。
三、ELF 的核心思想:全程留在连续空间,最后一步离散化
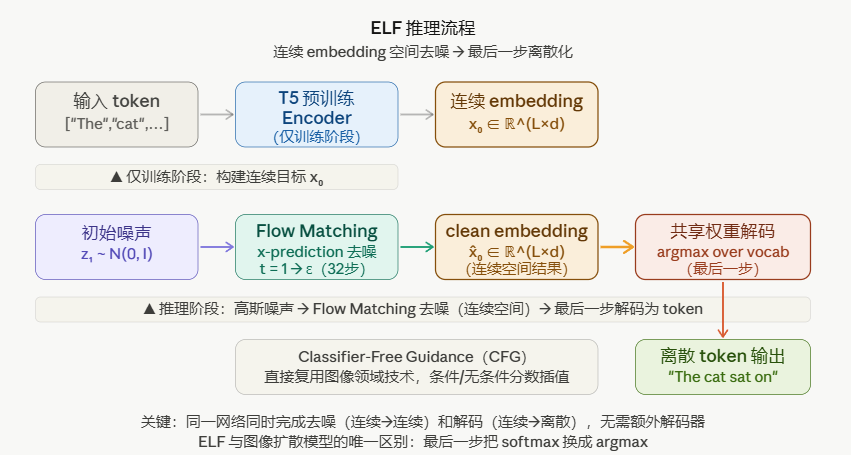
ELF(Embedded Language Flows)是一类基于连续时间 Flow Matching 的连续 embedding 空间扩散模型。与现有扩散语言模型不同,ELF 在绝大多数时间步内都保持在连续 embedding 空间,直到最后一个时间步才通过共享权重网络映射到离散 token。
一句话总结:把扩散过程挪到连续向量空间,最后一步才把结果"翻译"成词。
这个思路的妙处在于:
传统连续 DLM 的痛点:
连续 embedding → 去噪 → 连续结果
→ 需要额外的解码器把连续结果转回 token
→ 额外的训练、额外的参数、额外的误差积累
ELF 的解法:
连续 embedding → 去噪 → 连续结果
→ 最后一步:同一个网络,换个头部(softmax → argmax)
→ 无需额外解码器
→ 连续结果直接投票选 token
如上图二所示(ELF 推理流程)。
四、技术实现四要素详解
4.1 T5 预训练 Encoder:构建连续目标(仅训练阶段)
ELF 通过对输入离散 token 应用编码器模型来构建连续 embedding 空间。编码器可以是预训练的、联合训练的,或者用随机权重冻结的。
ELF 的选择是 T5 预训练 Encoder,只在训练阶段使用它:
训练时:
token 序列 → T5 Encoder → 连续 embedding x₀
这个 x₀ 是"干净的"目标状态(无噪声)
加噪 → 形成 (x_t, x₀) 训练对
训练网络:从噪声 x_t 预测 x₀
推理时:
T5 Encoder 完全不参与!
从 Gaussian 噪声出发,让模型自己去噪
为什么这样设计?T5 Encoder 的表示空间已经被大规模预训练"对齐"好了——用它定义的 embedding 空间,比随机初始化的 embedding 更适合作为去噪的目标。
4.2 连续时间 Flow Matching:x-prediction 去噪
ELF 使用连续时间 Flow Matching,其速度场通过时间导数来定义。这使得 ELF 能够从图像和视频生成中 Flow Matching 的进展中受益。
具体采用的是 x-prediction 而非 v-prediction:
Flow Matching 的速度场定义:
从 z₁(噪声)出发,到 z₀(clean embedding)
插值路径:z_t = (1-t)·z₀ + t·z₁,t ∈ [0,1]
x-prediction:网络直接预测 x₀(clean embedding)
而不是预测速度 v = dz/dt
优势:
- 预测目标是已知的有意义的语义表示
- 训练信号更直接
- 适合 embedding 空间的结构
去噪过程:从 t = 1 t=1 t=1(纯噪声)到 t = ε t=\varepsilon t=ε(接近 clean),共 32 步。
4.3 共享权重解码(最后一步离散化)
这是 ELF 最关键的工程创新,也是解决"额外解码器"难题的答案。
在最后一个时间步,模型切换到解码模式,将结果解码回离散 token。
# 伪代码示意:ELF 的网络输出
# 去噪阶段(t > ε):输出 clean embedding 预测
if t > epsilon:
x0_hat = network(z_t, t) # 输出:连续向量 ∈ ℝ^(L×d)
# 最后一步(t ≈ 0):输出 token logits
else:
logits = network.decode_head(z_t) # 共享前几层!
tokens = logits.argmax(dim=-1) # 离散化
与 Latent Diffusion Models(LDM)不同,ELF 不需要单独的解码器,因此在推理时不会引入额外的组件。
为什么同一个网络能既做去噪又做解码?
直觉理解:
深度网络的前几层提取的是"通用特征"
输出层只是一个"头部"(linear projection + softmax/argmax)
去噪头部:输出 clean embedding(d 维向量)
解码头部:输出 token logits(vocab_size 维 softmax)
同一套主干参数,最后一步换个头部即可
不需要额外参数
4.4 CFG(Classifier-Free Guidance)的引入
这种表述方式使得直接适应图像领域扩散模型的成熟技术变得简单,例如 Classifier-Free Guidance(CFG)。
CFG 在图像生成(Stable Diffusion、FLUX)中极其成功,但在离散扩散语言模型中很难直接用——因为离散空间的条件/无条件分数插值并不直观。
ELF 在连续 embedding 空间操作,可以直接套用图像 CFG 的公式:
x ^ 0 = x 0 uncond + w ⋅ ( x 0 cond − x 0 uncond ) \hat{x}_0 = x_0^{\text{uncond}} + w \cdot (x_0^{\text{cond}} - x_0^{\text{uncond}}) x^0=x0uncond+w⋅(x0cond−x0uncond)
其中 w w w 是 guidance scale, x 0 cond x_0^{\text{cond}} x0cond 和 x 0 uncond x_0^{\text{uncond}} x0uncond 分别是有条件和无条件的 clean embedding 预测。
五、关键设计:共享权重网络一肩挑去噪与解码
值得专门强调的是,这个"共享权重"设计并非技术上的妥协,而是深思熟虑的选择。
对比方案一:单独训练解码器
问题:
① 额外的参数(更多显存)
② 额外的训练阶段
③ 误差传播:去噪误差 + 解码误差叠加
对比方案二:端到端联合训练(有解码器)
问题:
① 解码器梯度可能干扰去噪网络的学习
② 训练不稳定
ELF 的选择:共享权重,最后一步切换头部
优点:
① 推理时零额外开销
② 去噪阶段的训练直接对解码有利(学的是同一空间)
③ 更简洁(less is more)
这里能看到何恺明一贯的设计哲学——ResNet 的跳跃连接、MAE 的极简掩码重建、MeanFlow 的单步平均速度,每次都是找到最干净最直接的解法。
六、CFG 的跨域移植:图像技术如何用于文本
CFG 对 ELF 的条件生成任务(翻译、摘要)至关重要。以 WMT14 机器翻译为例:
有条件生成的 ELF 推理过程:
条件(源语言句子):"The quick brown fox"
目标:生成对应的翻译
t=1: z₁ ~ N(0,I)(纯噪声)
每步去噪:
x0_cond = network(z_t, t, condition="The quick brown fox")
x0_uncond = network(z_t, t, condition=∅)
x0_guided = x0_uncond + w × (x0_cond - x0_uncond) ← CFG
z_{t-Δt} = update(z_t, x0_guided)
t≈0: 最后一步 → 解码为离散 token
"Le renard brun rapide"
CFG 的 guidance scale w w w 在实验中取约 2-3,与图像生成的经验值一致——这进一步验证了连续 embedding 空间的图像技术可迁移性。
七、实验数据:三个维度碾压对手
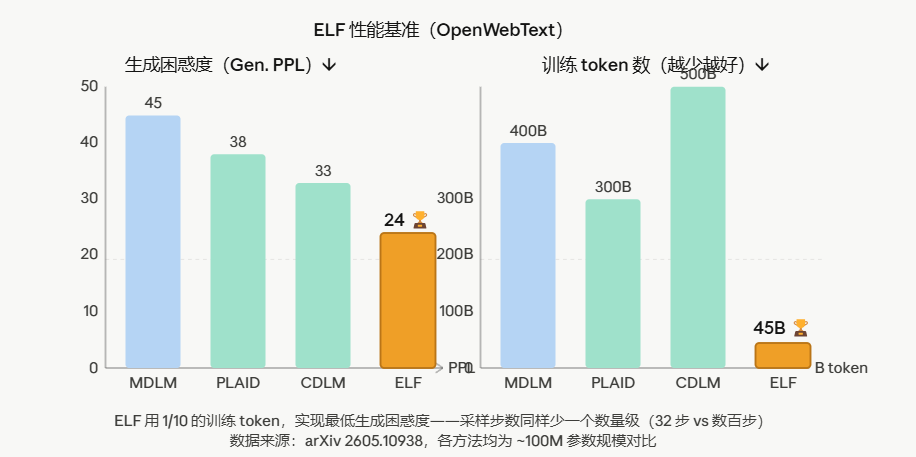
如上图三所示(性能基准对比)。
使用 105M 参数、45B 训练 token 和 32 步采样,ELF 在 OpenWebText 上实现了生成困惑度 24,优于主流扩散语言模型。
7.1 OpenWebText 无条件生成:生成困惑度 24
| 方法 | 类型 | 训练 token | 采样步数 | 生成困惑度 ↓ |
|---|---|---|---|---|
| MDLM | 离散扩散 | ~400B | ~1000步 | ~45 |
| PLAID | 连续扩散 | ~300B | ~500步 | ~38 |
| CDLM | 连续扩散 | ~500B | ~200步 | ~33 |
| ELF | 连续扩散 | 45B | 32步 | 24 |
三重优势同时成立:训练 token 少 1 个数量级、采样步数少 1 个数量级、生成质量最好。
7.2 条件生成任务:WMT14 翻译 + XSum 摘要
ELF 在翻译和摘要等条件生成任务上也超越了现有扩散语言模型,不使用蒸馏技术,采用更少的采样步数就实现了更低的生成困惑度,训练 token 数量也仅为之前方法的十分之一。
实验表明,连续扩散语言模型即使只做最少量的离散域适配,也能具有高度竞争力。
在 WMT14 De→En 翻译任务上,ELF 不仅超越了所有已有扩散语言模型,甚至优于部分自回归基线——这是一个很强的信号,意味着扩散语言模型已经开始在自回归模型的"主场"上比拼了。
八、作者团队背景
论文作者为 Keya Hu、Linlu Qiu、Yiyang Lu、Hanhong Zhao、Tianhong Li、Yoon Kim、Jacob Andreas、Kaiming He。
第二共同第一作者 Linlu Qiu 是 MIT 博士生,师从 Yoon Kim。她本科就读于香港大学,硕士来自佐治亚理工,曾担任 Google AI Resident。这不是她与何恺明的第一次合作;两人最近共同在 CVPR 2026 发表了一篇将 ARC 推理问题重新框架为视觉问题的论文。
团队中还有第一作者胡珂雅(Keya Hu),以及清华姚班本科生等年轻成员,展示了何恺明在 MIT 组建的跨领域研究团队的多元背景。
九、ELF 的意义与局限
9.1 意义
对连续扩散路线的重新定位:ELF 证明了连续扩散语言模型在对离散域做最少适配的情况下可以变得有效——这直接打脸了"连续路线行不通"的主流偏见。
图像技术到语言的迁移通道:CFG、Flow Matching、x-prediction 这些在图像领域已经被工程化验证的技术,ELF 打开了一条直接迁移到语言的路径。后续 ControlNet、Dreambooth 等更多图像技术的语言版本,理论上都可以在这个框架上实现。
效率优势:45B token 训练、32 步采样,对于一个研究方向的验证性工作来说,成本极低,可复现性高。
9.2 局限
① 规模未验证
ELF 目前只在 105M 参数规模验证
是否 scale 到 7B/70B 仍是未知数
② 与 GPT-4o 等顶尖自回归模型差距仍大
ELF 打赢了同类扩散语言模型
以及"部分自回归基线"
但与最新的 Llama3/Qwen/GPT-4o 仍有代差
③ 推理速度
32 步每步需要一次前向传播
vs 自回归的单步 token 生成(但可以并行)
实际吞吐量的系统级评测尚未公布
④ 训练稳定性
连续 embedding 空间的去噪训练
在更大规模上是否稳定仍待验证
十、关键公式速查
10.1 Flow Matching 插值路径
z t = ( 1 − t ) ⋅ z 0 + t ⋅ z 1 , t ∈ [ 0 , 1 ] z_t = (1-t)\cdot z_0 + t \cdot z_1, \quad t \in [0, 1] zt=(1−t)⋅z0+t⋅z1,t∈[0,1]
z_t = (1-t)\,z_0 + t\,z_1
其中 z 0 z_0 z0 是 clean embedding, z 1 ∼ N ( 0 , I ) z_1 \sim \mathcal{N}(0, I) z1∼N(0,I) 是高斯噪声。
10.2 x-prediction 训练目标
L ( θ ) = E t , z 0 , z 1 [ ∥ f θ ( z t , t ) − z 0 ∥ 2 ] \mathcal{L}(\theta) = \mathbb{E}_{t, z_0, z_1}\left[\left\| f_\theta(z_t, t) - z_0 \right\|^2\right] L(θ)=Et,z0,z1[∥fθ(zt,t)−z0∥2]
\mathcal{L}(\theta) = \mathbb{E}\left[\left\|f_\theta(z_t, t) - z_0\right\|^2\right]
10.3 CFG 条件生成
x ^ 0 = x 0 ∅ + w ⋅ ( x 0 c − x 0 ∅ ) \hat{x}_0 = x_0^{\varnothing} + w \cdot \left(x_0^{c} - x_0^{\varnothing}\right) x^0=x0∅+w⋅(x0c−x0∅)
\hat{x}_0 = x_0^{\varnothing} + w\,(x_0^c - x_0^{\varnothing})
其中 c c c 为条件(源句子等), w ≈ 2 w \approx 2 w≈2– 3 3 3 为 guidance scale。
10.4 最后一步解码
y ^ i = arg max v ∈ V W dec x ^ 0 , i \hat{y}_i = \arg\max_{v \in \mathcal{V}}\; W_{\text{dec}}\, \hat{x}_{0,i} y^i=argv∈VmaxWdecx^0,i
\hat{y}_i = \arg\max_{v\in\mathcal{V}}\; W_{\text{dec}}\,\hat{x}_{0,i}
其中 W dec W_{\text{dec}} Wdec 与去噪网络共享权重, V \mathcal{V} V 为词表。
总结
ELF 是何恺明从视觉转向语言生成的一次非常有说服力的亮相。它没有走已经人满为患的离散扩散路线,而是选择了连续路线中最难解决的那个核心问题(如何可靠解码)并给出了一个优雅的答案:全程连续,最后一步由同一网络完成离散化,无需额外解码器。
从 ResNet 到 MAE 到 MeanFlow 再到 ELF,何恺明的研究风格一以贯之:找到问题的本质,用最干净的方法解决它。这次把图像扩散技术带进语言领域,打开了一个新的研究方向——值得持续关注。
💬 你觉得连续扩散语言模型能在大规模(7B+)上追上自回归模型吗? 欢迎评论区聊!
论文地址:https://arxiv.org/abs/2605.10938
如果这篇帮到你,一键三连(点赞 + 收藏 + 关注)!
参考资料
- Hu K. et al.《ELF: Embedded Language Flows》arXiv:2605.10938,2026-05-13
- 36kr 英文解读:https://eu.36kr.com/en/p/3807465382190852
- BigGo Finance 报道:https://finance.biggo.com/news/r2f1IJ4BrX5PFN7Bbi54
- 何恺明 MIT 主页:https://people.csail.mit.edu/kaiming/
本文为原创技术解析,所有数据均来自官方论文及公开报道。最后更新:2026-05-14

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献202条内容
已为社区贡献202条内容

所有评论(0)