客户洞察从“拍脑袋“到“算得清“:帮市场研究部重新认识用户
引言:你自以为了解客户,其实差得远
市场研究部的同事大概都经历过这样的时刻——产品经理跑来问:"我们核心用户到底是谁?"你翻出半年前做的那份用户画像报告,上面写着"25-40岁、一二线城市、月收入8000-15000元、关注性价比"。
说实话,这种描述放到大多数消费品牌上都成立。它更像是一个"安全答案",而不是一个"有效答案"。
我见过不少企业的用户画像,写来写去都是那几条——年龄区间、收入范围、地域分布、消费偏好。精细一点的加上"社交活跃""品牌忠诚"之类的定性标签,再精细一点的画个人物角色卡(Persona),配上头像和一句话简介。但这些画像到底有多准?没人敢打包票。
更尴尬的是,很多时候画像做完了,业务团队并不买账。销售觉得"这跟我在前线看到的客户不一样",运营觉得"这些标签太泛了没法用",产品觉得"这跟我们的数据对不上"。画像归画像,决策归决策,两者之间的鸿沟一直没填上。
"知道客户是谁但说不清、想细分但分不准、有数据但用不起来"。围绕多源数据自动聚合、行为标签自动生成、人群自动聚类、趋势预测这几条线,帮市场研究部从"凭经验拍"过渡到"拿数据说话"。
一、痛点拆解:市场研究到底卡在哪?
跟十几个市场研究团队聊过之后,我觉得反复出现的问题主要有四个。它们彼此缠绕,导致市场研究部门产出的洞察越来越"钝"。
1.1 用户画像太粗:颗粒度撑不起业务决策
这是最直接的痛点。大部分企业现有的用户画像,还停留在"人口统计学"层面——性别、年龄、地域、收入。这些信息当然有用,但问题在于,同年龄段、同城市、同收入水平的人,消费行为可能天差地别。
一个30岁的上海女性,可能是每天精打细算比价的宝妈,也可能是随手下单不看价格的白领——光看人口统计学标签,你根本分不出来。
画像粗的根源大概有几个:
• 数据维度单一:只靠问卷或CRM里的注册信息,行为数据大量缺失
• 标签体系手工维护:标签是人拍的,主观性强,更新慢,标准也不统一
• 画像更新频率低:半年更新一次算勤快的,很多是一年一版
画像粗的结果是什么?营销投放照着"25-35岁女性"这个宽泛条件去投,ROI惨淡;产品功能按"主流用户"偏好来设计,结果发现"主流用户"根本不是你以为的那群人。我自己就见过一个案例——某护肤品牌把核心用户定义为"25-35岁一二线城市女性",投放了两个月没效果,后来拿行为数据一看,真正复购的核心群体其实是"18-24岁下沉市场学生党",跟原来的画像差了十万八千里。
1.2 调研周期太长:洞察总是慢市场一步
传统调研的流程大致是:确定调研目标→设计问卷→投放回收→数据清洗→统计分析→撰写报告。这个周期短则两周,长则两月。
等你把报告交上去,市场可能早就变了。
举个我听来的例子:有个朋友花了三周做了一份消费者价格敏感度调研,报告出来后发现——竞品上周刚调过价,他那份价格敏感度结论已经部分失效了。这不是调研做得不好,而是速度跟不上变化。
调研周期长的原因也不复杂:
• 问卷设计反复修改:问题措辞、选项设置、样本配额,每个环节都要来回确认
• 数据回收慢:线上问卷还好,线下访问和焦点小组排期以周为单位
• 分析依赖人力:交叉分析、差异检验、因子分析……统计方法本身不慢,慢的是人在不同工具之间切换、反复调整口径
那个做快消品调研的朋友还跟我吐槽过一句:"我们季度报告出来的时候,竞品新品都上了两轮了。"话虽夸张,但确实反映了很多人心里的焦虑。
1.3 数据源割裂:知道数据在那,就是用不上

这可能是最让市场研究人员憋屈的问题。
客户数据散落在至少四五个系统里:CRM存着客户基本信息和销售跟进记录,电商后台有购买行为和订单数据,客服系统记录着投诉和咨询,社交媒体上有用户自发讨论和评价,线下渠道还有门店POS和会员卡数据。
每个系统都像一口深井,井里有水,但井与井之间没有管道。你想做一次完整的客户分析,得先从五六个系统里分别导数据,再花大量时间做数据清洗和对齐——光是把不同系统里的"用户ID"匹配上,就可能耗掉一整天。
数据割裂的直接后果:
• 分析维度受限:只能用单一系统内的数据做分析,跨系统关联分析做不了
• 结论可能有偏差:只看购买数据不看社交数据,可能误判用户动机;只看CRM不看客服,可能忽视流失预警信号
• 重复劳动严重:不同项目反复导数据、清数据、对数据,效率极低
有个说法挺形象:"数据孤岛不可怕,可怕的是你知道岛上有宝,就是搬不过来。"我第一次听到这话的时候还笑了一下,想想确实这么回事。
1.4 人群细分靠经验:分群逻辑经不起检验
市场研究人员做人群细分,常用的方法有两种:一种是按经验拍——"我们把用户分为高端、中端、入门三档";另一种是按某个单一维度切——按消费金额分RFM,按活跃度分高低,按地域分南北。
这两种方法都有问题。
经验分群的问题是"不可复现、不可验证"。你说高端用户是这样一群人,依据是什么?凭什么不是另一种分法?换了个人来做,分群结果可能完全不同。
单一维度分群的问题是"忽略了多维交叉"。消费金额高的用户,可能活跃度很低(囤货型);活跃度高的用户,可能客单价很低(薅羊毛型)。只看一个维度,分出来的群内部差异依然很大。
更深层的问题其实是:分群的目的是什么? 如果分群只是为了让报告看起来更有结构,那怎么分都行。但如果分群是为了指导差异化运营——不同人群用什么话术、推什么产品、在什么渠道触达——那分群的逻辑必须跟业务目标挂钩,而不能只是"看起来合理"。
这四个痛点不是孤立的。画像粗是因为数据源割裂,调研周期长是因为人工处理多,人群细分靠经验是因为缺乏自动化分析能力。它们共同指向一个问题:市场研究的方法论和工具,没有跟上数据量和业务复杂度的增长。
二、53AI的解法:从数据聚合到洞察产出
面对上面这些痛点,53AI提供了一套从数据层到应用层的方案。我想强调一点——这不是单点工具的堆砌,而是尽量打通从"数据进来"到"洞察出来"的完整流程。
2.1 多源数据自动聚合:先把数据搬过来
先把最基础的问题解决——数据散落各处,用不上。
53AI的做法是:将CRM、电商、客服、社交媒体、线下渠道等多源数据自动接入,完成ID融合和数据对齐。
第一步:数据源接入。 53AI支持常见数据源的标准化接入,包括数据库直连、API对接、文件导入(CSV/Excel)等。不需要IT部门写ETL脚本,市场研究人员自己就能配置数据源。当然,第一次配置的时候可能还是要跟IT确认一下权限,但后续维护基本不需要技术介入了。
第二步:ID融合。 这是整个流程里最难也最关键的一步。不同系统里的同一个人,可能用手机号注册了CRM,用邮箱下了单,用微信ID做了咨询。53AI通过规则匹配(手机号/邮箱/设备ID等)和AI模糊匹配(行为相似度、时间窗口关联等),把这些分散的身份尽量归一化。
说实话,不是100%精准——实际匹配率通常在85%左右。但比起手工匹配,速度和准确度都好不少。剩下的15%怎么办?我觉得可以接受先放着,后续有更多行为数据进来,匹配率会慢慢提高。
第三步:数据标准化。 不同系统的字段命名、数据格式、编码规则各不相同。53AI自动完成字段映射和格式统一,比如把"性别"字段的"M/F"和"1/2"统一为"男/女"。这种活儿以前最耗时间,现在基本不用人管了。
数据聚合完成后,你第一次拥有了"一个人在所有触点上的完整行为轨迹"。这种感觉,大概像是把拼图从各个角落找齐,终于能拼出全貌了。
2.2 行为标签体系自动生成:让标签从"拍脑袋"变成"算出来"
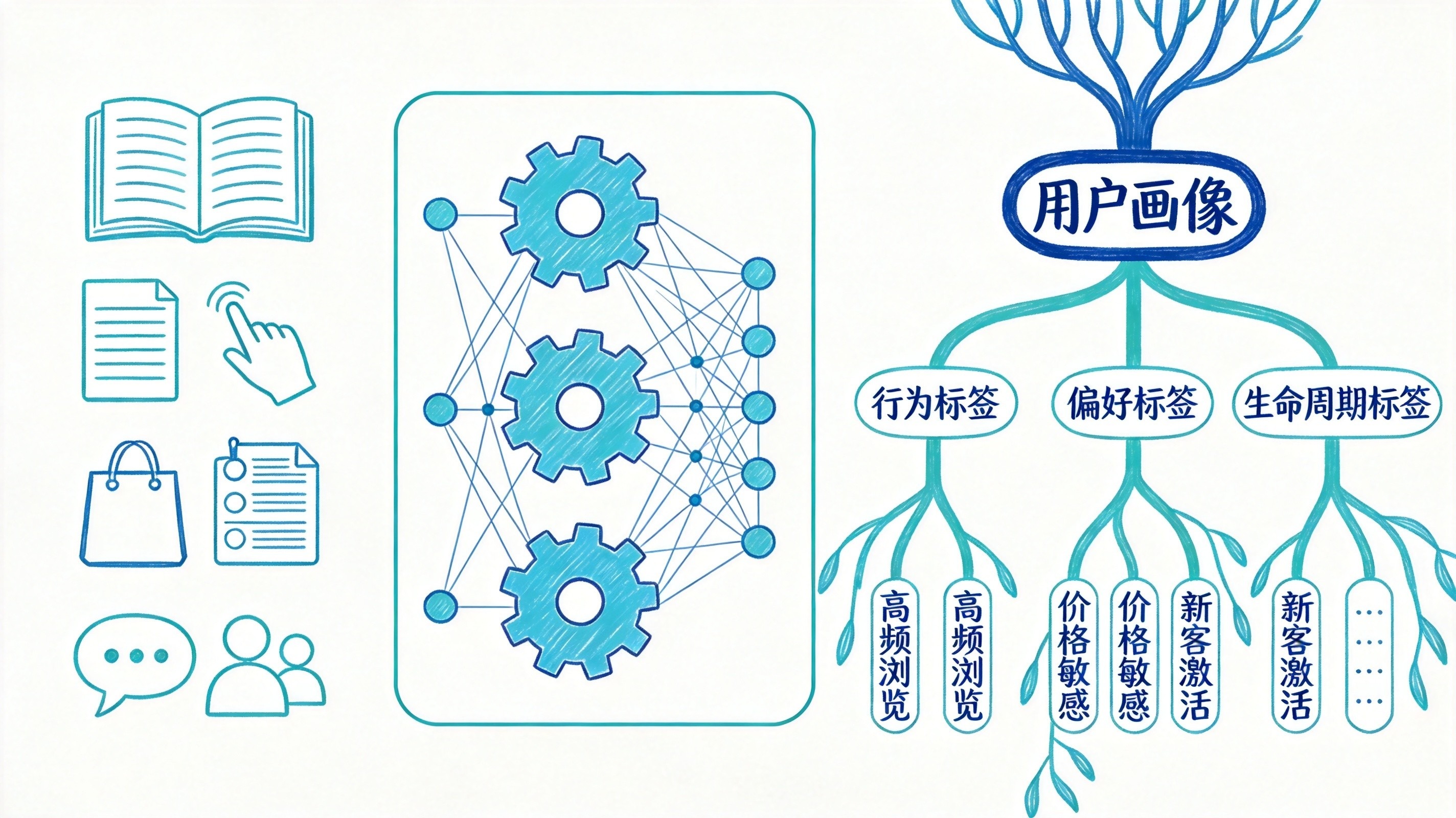
传统标签体系的问题,前面说过了——人工定义、手动打标、更新慢、标准乱。53AI的做法完全不同:系统根据用户行为数据,自动提取特征并生成结构化标签。
自动标签挖掘。 系统分析用户行为数据,自动识别有区分度的行为模式,生成标签。比如发现一批用户"每次大促前7天开始频繁浏览比较页面,但下单集中在活动当天最后2小时",系统会自动生成"大促观望型"标签。
这种标签是你想不到去定义的——因为人很难从海量行为数据里直观地看出这种模式。但算法可以。我第一次看到系统生成的标签时,有好几个都是我没想到的,回头想想又确实有道理。
分层标签架构。 标签不是扁平的一层,而是有层级关系。一级标签是大的行为分类(如"购买行为""浏览行为""互动行为"),二级标签是具体维度(如"购买频次""浏览深度""社交活跃度"),三级标签是细粒度特征值(如"月均购买3次以上""平均浏览5页以上""每周评论1次以上")。这种分层结构方便筛选,也便于做聚合分析。
动态更新机制。 标签不是打完就固定了。用户行为在变,标签也应该跟着变。53AI设定了标签更新的频率和规则——有些标签按天更新(如"近7天活跃"),有些按周更新(如"月度消费等级"),有些触发式更新(如"首次购买"标签在用户完成首单后自动打上)。
有个值得说的点:自动生成的标签,可能跟市场研究人员主观定义的不完全一致。这恰恰是它的价值——它能发现人脑不容易注意到的行为模式。当然,人工经验仍然重要,AI生成的标签需要人来审核和校准。这不是替代,是补充。
2.3 细分人群自动聚类:让数据来告诉你"用户分几群"
这是整个方案里我觉得最有意思的部分——分群不再由人来定义,而是由算法来发现。
输入特征选择。 从标签体系中选取跟业务目标相关的特征作为聚类输入。比如想做差异化运营,就选"消费频次""客单价""品类偏好""活跃度""渠道偏好"这几个维度;想做流失预警,就侧重"最近购买时间""访问频次变化""投诉记录"等。
算法自动聚类。 53AI内置了多种聚类算法(K-Means、DBSCAN、层次聚类等),会自动尝试不同的算法和参数组合,评估聚类效果(轮廓系数、组间差异、组内一致性),选择相对最优的方案。注意我说的是"相对最优"——聚类这东西,不存在绝对正确的答案,不同算法可能给出不同结果,重要的是结果在业务上讲得通。
特征自动解读。 聚类结果出来后,系统会自动生成每个群的"画像卡片"——该群的核心特征标签、与整体人群的差异点、群规模和占比、关键行为指标。市场研究人员不需要自己去跑交叉表和做差异检验,系统都算好了。
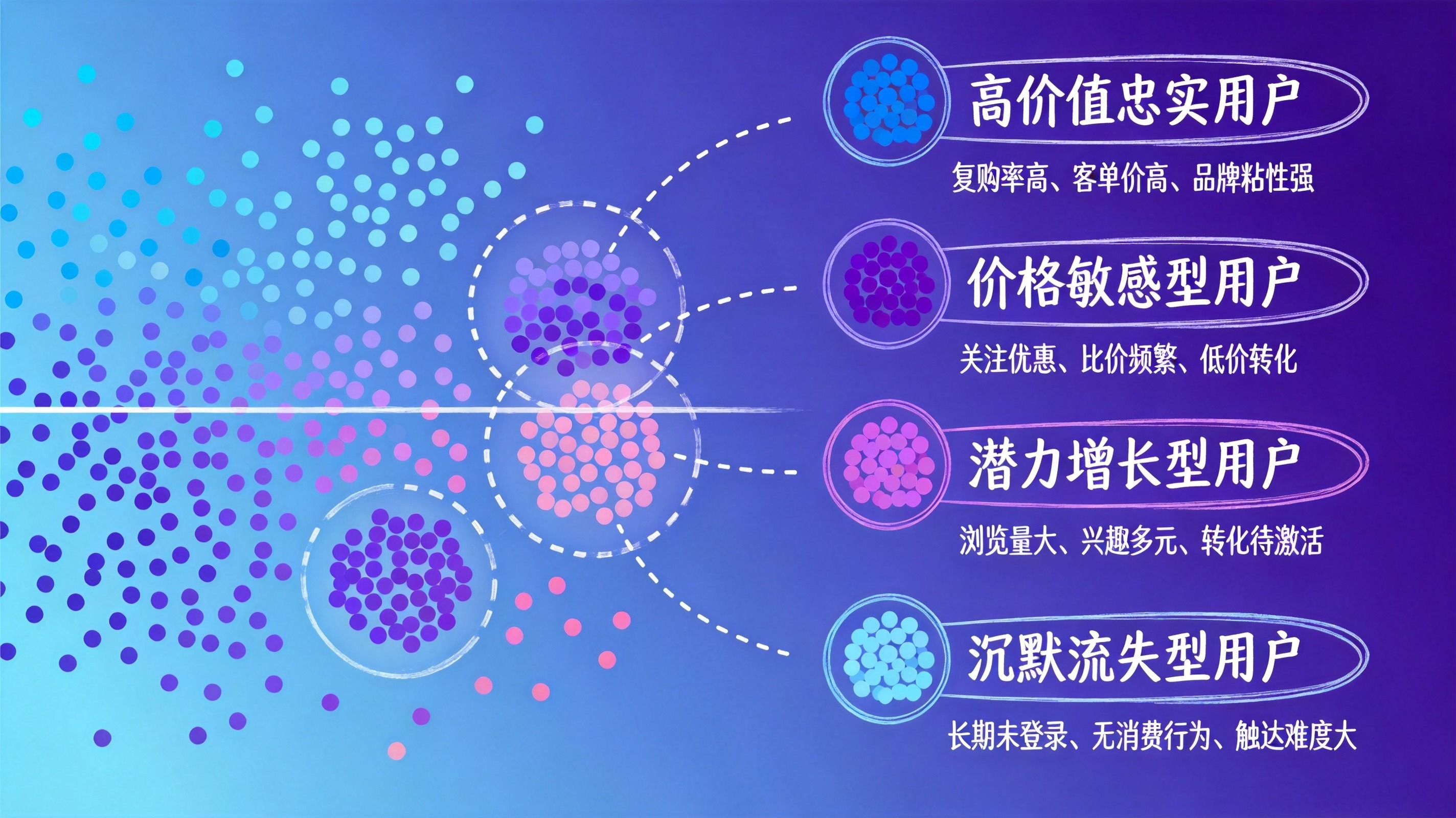
举个实际案例。 某母婴品牌的用户数据跑完聚类后,系统识别出5个细分人群——
1. 科学育儿型(18%):高学历妈妈,爱看测评内容,购买决策周期长但客单价高
2. 囤货型妈妈(25%):大促时集中购买,日常几乎不活跃,价格敏感度高
3. 新手焦虑型(15%):孕期或0-6月龄宝宝妈妈,频繁咨询,购买品类广但单次金额低
4. 品牌忠诚型(22%):复购率高,对品牌活动参与积极,社交分享意愿强
5. 沉默流失型(20%):历史有购买但近3个月无任何互动,退款率偏高
这个分群结果刚出来的时候,市场部的人觉得"科学育儿型"和"新手焦虑型"是不是有重叠。仔细一看数据才发现,前者更多是二胎以上的经验型妈妈,方法论驱动;后者是头胎的新手,情绪驱动——行为模式确实很不一样。这种差别,光凭经验很难分出来。
每个群背后的运营方向也完全不同——科学育儿型需要内容种草和专业背书,囤货型需要大促触达和组合优惠,新手焦虑型需要使用指导和情感关怀。比原来"高端/中端/入门"的三分法有用得多。
不过聚类不是一劳永逸的。用户行为会变化,人群结构也会变化。53AI支持定期重新聚类(比如每季度一次),追踪人群规模和特征的动态变化。上季度还占25%的"囤货型妈妈",这季度可能就变成20%了——这种变化趋势本身就是很重要的洞察。
2.4 趋势预测:从"事后描述"往前推一步
传统的市场研究,本质上是在做"事后描述"——过去发生了什么,为什么发生。趋势预测想做的,是把时间线往前推:未来可能发生什么,现在也许可以做点什么。
53AI的趋势预测覆盖几个层面:
用户规模预测。 基于获客速度、留存率、流失率的历史趋势,预测未来3-6个月的活跃用户规模变化。如果预测显示活跃用户即将出现下滑拐点,可以提前启动挽回措施。当然,预测不一定准——但如果趋势确实在走下坡,早一点知道总比晚一点知道好。
品类需求预测。 结合季节性因素、历史销售趋势、社交媒体热度变化等,预测特定品类在未来一段时间的需求变化。比如系统可能提示"纸尿裤L码需求预计2周后上升15%,建议提前备货"。这个15%是粗略估计,但方向性的判断通常是有参考价值的。
人群迁移预测。 追踪用户在细分人群之间的迁移趋势。比如"科学育儿型"用户在宝宝6个月后开始向"品牌忠诚型"迁移的比例,以及迁移的时间窗口。这能帮你在迁移窗口期内做精准的承接策略——如果知道用户大概率会在第5-7个月迁移,那第4个月就是最好的运营介入点。
流失预警。 识别出有流失风险的用户,给出流失概率和可能原因。这不再是"近3个月未购买"这种简单规则,而是综合了行为变化趋势、客诉记录、活跃度衰减曲线等多维信号的判断。不过我也要说,流失预警的准确率跟数据质量强相关——如果行为数据本身就缺得多,预警效果会打折扣。
坦率地说,预测不可能100%准确。但一个方向大致对的模糊预测,比一个精确的事后描述对决策更有用。关键是:预测结果要透明——系统要告诉你预测依据是什么、置信区间多大,而不是丢一个黑箱数字让你"信不信由你"。
三、怎么落地?三步走,别想一口气吃成胖子
知道了方案长什么样,接下来是怎么落地。
第一步:数据打通与标签基建(4-6周)
这个阶段的核心任务是把数据聚合起来,搭好标签体系的骨架。
1. 梳理数据源清单:盘点企业内所有客户相关数据源,评估数据质量和可接入性
2. 先接入CRM和电商数据:这两块数据最结构化,价值也最高,其他数据源第二期再接
3. ID融合试跑:先用规则匹配跑一版,看匹配率如何,再决定是否启用AI模糊匹配
4. 定义标签体系框架:确定一级和二级标签的分类结构,三级标签可以先让系统自动挖掘,人工审核校准
这个阶段的目标不是完美,而是"从0到1"。数据有缺失没关系,标签不够精准也没关系,先把框架搭起来,后面迭代才有基础。我见过有的团队在这步卡了三个月,就是因为想一步到位——先把所有数据源都接进来、标签全部定义好。结果就是一直"准备中",什么也跑不起来。
第二步:聚类试点与洞察验证(3-4周)
数据通了、标签有了,接下来验证"AI分群到底比经验分群好在哪"。
1. 选一个业务场景做试点:比如"大促期间的用户差异化运营策略",目标明确、数据丰富、效果也好衡量
2. 跑聚类分析:输入选定的特征维度,让系统自动聚类,生成人群画像
3. 跟经验分群对比:让市场研究人员先凭经验做一版分群,再跟AI分群结果对比。重点看:AI发现了哪些经验没覆盖到的群体?两者的策略含义有什么差异?
4. 小范围验证:基于AI分群结果设计差异化策略,在一个渠道或一个区域小范围测试,看效果
这个阶段的关键是"建立信任"。市场研究人员对AI分群的接受度,取决于试点结果的说服力。如果AI分群确实发现了被忽略的高价值群体,或者预测了经验判断没捕捉到的趋势,信任自然就来了。反之,如果试点结果跟经验判断差不多,那可能得回头看看是数据问题还是特征选择问题。
第三步:常态化运营与持续迭代
试点验证完成后,进入常态化运营。
1. 接入更多数据源:把社交媒体、客服、线下渠道等数据逐步接入,丰富分析维度
2. 标签体系迭代:根据业务反馈,调整标签定义、增加新标签、淘汰没什么用的标签
3. 定期重新聚类:每季度重新跑聚类,追踪人群结构变化
4. 趋势预测纳入决策流程:把预测结果作为月度经营分析会的固定输入项,而不是偶尔翻翻的"附加信息"
5. 搭一个洞察看板:把核心指标、人群分布、趋势预测整合到一个实时看板上,让管理层和业务团队随时能看
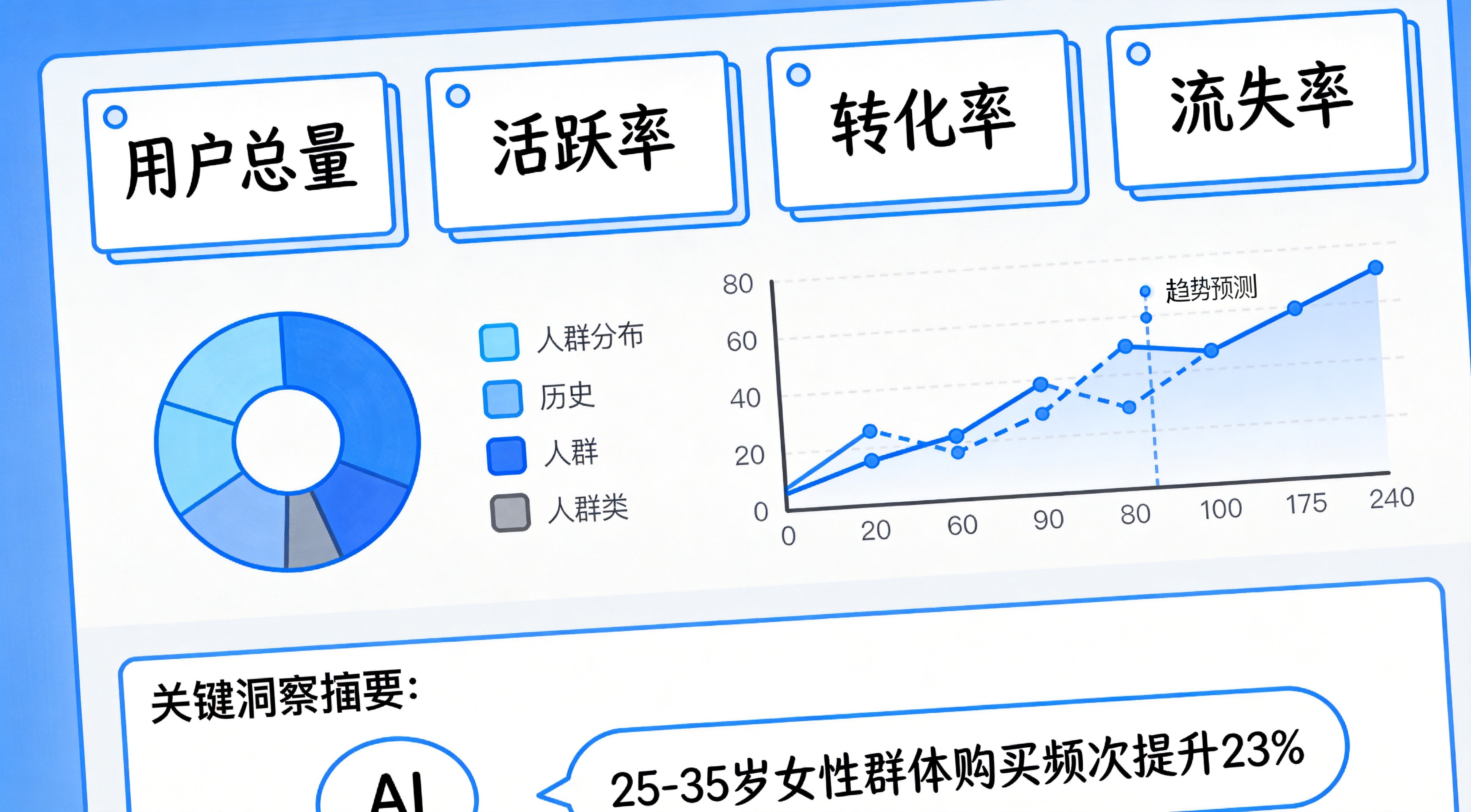
四、效果怎么衡量?
做客户洞察升级,效果怎么衡量?我建议从三个层面看,别一上来就看ROI,那个太远了。
效率层面:
• 调研报告产出周期是否缩短?目标是从"周"级缩短到"天"级
• 数据准备时间占比是否下降?如果分析师花60%时间在导数据清数据,说明基础设施还没到位
• 画像更新频率是否提高?从半年一版到至少月度更新
质量层面:
• 人群细分的颗粒度是否变细了?能不能从3-4个粗分人群细化到8-10个?
• 洞察是否被业务团队采纳?如果做出来的洞察只是"放着好看",那说明洞察跟业务脱节了
• 预测方向是否大致正确?不需要100%精准,但方向对不对心里要有数
业务层面:
• 差异化运营策略的覆盖率是否提升?从"一刀切"到"按人群差异化"的比例
• 营销ROI是否改善?更精准的人群定位应该带来更高的转化率
• 流失预警命中率是否达标?能提前2-4周识别出高流失风险用户
说实话,这些指标不一定一开始就能全部达标。客户洞察升级不是开关,是旋钮——需要持续调。重要的是方向对、节奏稳、有反馈。
写在最后
回到最开始的问题:市场研究部的价值在哪?
我觉得不是"收集数据",也不是"产出报告",而是"看见别人看不见的东西"——在数据里识别模式,在变化中捕捉趋势,在噪声里提取信号。
传统方法的问题是,大量的时间和精力被消耗在数据搬运、清洗、对齐这些低价值环节上,真正留给"思考"的时间反而很少。数据源割裂让人看不到全貌,画像粗糙让人看不清细节,调研周期长让人看不准当下,经验分群让人看不到盲区。
53AI做的事情,说到底是帮市场研究人员把"看"的能力释放出来。多源数据聚合让你看到全貌,自动标签体系让你看到细节,聚类分群让你看到结构,趋势预测让你看到方向。
但工具终究是工具。洞察力的来源,还是人对业务的理解、对消费者的同理心、对数据的敏感度。AI能加速这个过程,但不能替代人做判断——至少目前还不能。
客户洞察这件事,也许永远没有"做完"的那一天。用户在变,市场在变,技术在变。但至少,我们可以让自己"看"得更清楚一点、更快一点、更系统一点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)