从零开始训练大模型:小白也能搞定的完整教程——mini_Qwen_1B
从零开始训练大模型:小白也能搞定的完整教程
你是否曾经好奇过那些智能对话机器人是如何诞生的?今天,我将带你一步步从零开始训练属于自己的大模型!不需要顶级显卡,普通的T4显卡就能开启你的AI训练之旅~
前言
最近学习了一个超有趣的项目——从头训练了一个1B参数的大语言模型(LLM)!整个过程包括预训练(PT)、微调(SFT)和直接偏好优化(DPO)三个阶段。最棒的是,预训练和微调只需要12G显存,偏好优化只需要14G显存,这意味着使用普通的T4显卡就能完成训练!
把这个好项目分享给大家,希望能帮助更多对AI感兴趣的小伙伴入门大模型训练~
项目介绍
项目叫做mini_qwen,是以Qwen2.5-0.5B-Instruct模型为基础,通过扩充模型结构,增加参数量到1B,并进行参数随机初始化后训练的。训练数据使用了北京智源人工智能研究院的预训练(16B token)、微调(9M条)和偏好数据(60K条)。
整个训练过程使用了flash_attention_2进行加速,在6张H800上完成了训练,耗时:
- 预训练:25小时(1epoch)
- 微调:43小时(3epoch)
- DPO优化:1小时(3epoch)
但别担心!我们的教程会提供精简版数据和代码,让你在单张显卡上也能体验完整训练流程!
️ 环境准备
硬件需求
- GPU:至少8GB显存(推荐12GB以上)
- CPU:8核以上
- 内存:16GB以上
- 硬盘:至少50GB空闲空间(完整数据集需要更多)
软件环境
# 克隆项目代码
git clone https://github.com/qiufengqijun/mini_qwen.git
cd mini_qwen
# 安装必要的Python包
pip install flash-attn
pip install trl==0.11.4
pip install transformers==4.45.0⚠️ 注意:版本很重要!特别是trl和transformers的版本,不同版本的参数设置可能不同,导致代码无法运行。
快速开始
如果你只想体验模型训练流程,不需要下载完整数据集,可以直接使用项目中的mini_data和demo代码:
# 运行预训练demo
python demo/demo_pt.py
# 运行微调demo
python demo/demo_sft.py
# 运行DPO优化demo
python demo/demo_dpo.pydemo代码与完整训练代码基本一致,只是做了以下调整以减少显存占用:
- 使用mini_data替代完整数据集
- 设置较小的batch_size和梯度累积步数
- 减小序列长度
数据准备
预训练数据
预训练数据来自智源的IndustryCorpus2,这是一个按行业-语言-质量分层的高质量预训练数据集。
选择了10个行业的中英文高质量数据,总计约16B token。数据示例:
{
"text": "马亮:如何破解外卖骑手的\"生死劫\"\n在消费至上的今天,企业不应道德绑架消费者,让消费者为企业的伪善埋单。。。。。。",
"alnum_ratio": 0.9146919431,
"quality_score": 4.0625,
"industry_type": "住宿_餐饮_酒店"
}微调数据
微调数据来自智源的Infinity-Instruct,选择了基础数据集中的7M和聊天数据集中的Gen混合作为微调数据,约9M条样例。数据示例:
{
"conversations": [
{
"from": "human",
"value": "因果联系原则是法律责任归责的一个重要原则,它的含义是( )\nA. 在认定行为人违法责任之前,应当确认主体的行为与损害结果之间的因果联系\nB. 。。。。。。"
},
{
"from": "gpt",
"value": "刑事责任为例分析。如果危害行为。。。。。。有意义。据此,选项ABD正确。行为人的权利能力。。。。。。当然无庸确认。据此,排除选项C。"
}
]
}偏好数据
偏好数据来自智源的Infinity-Preference,约60K条样例。数据示例:
{
"prompt": "请详细介绍一道具有。。。。。。的烹饪食谱。",
"chosen": [
{
"content": "请详细介绍一道具有。。。。。。的烹饪食谱。",
"role": "user"
},
{
"content": "## 苏州松鼠鳜鱼。。。。。。希望这份详细的介绍和食谱能帮助您在家中成功制作这道经典的苏州名菜!",
"role": "assistant"
}
],
"rejected": [...]
}
小技巧:如果你想查看数据内容,可以使用项目中的 utils/demo_view_data.py脚本。
书籍PDF及配套代码可点赞文章后添加小助手获取

模型训练详解
第一阶段:预训练(PT)
预训练是从头开始训练模型的第一步,目标是让模型学习语言的基本规律和知识。
模型结构调整
我们基于Qwen2.5-0.5B-Instruct模型配置,调整了以下参数将模型扩充到1B:
config.num_attention_heads = 16 # 注意力头数
config.num_key_value_heads = 4 # KV注意力头数
config.hidden_size = 1024 # 隐藏层维度
config.num_hidden_layers = 48 # 隐藏层数量数据处理
预训练数据需要添加结束符:
text = text + "<|im_end|>"我们还使用了序列打包技术,将多个短文本拼接成长序列,提高训练效率:
def preprocess_dataset(examples):
eos_token = "<|im_end|>"
text_examples = [text + eos_token for text in examples["text"]]
tokenized_examples = tokenizer(text_examples, add_special_tokens=False)
# 将分词结果拼接并分块
concatenated_examples = {
k: list(chain(*tokenized_examples[k])) for k in tokenized_examples.keys()
}
total_length = len(concatenated_examples[list(concatenated_examples.keys())[0]])
block_size = 1024 # 分块大小
total_length = (total_length // block_size) * block_size
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
return result训练参数配置
training_args = TrainingArguments(
output_dir=output_path,
learning_rate=1e-4, # 学习率
warmup_ratio=0.1, # 预热比例
lr_scheduler_type="cosine", # 学习率调度器
num_train_epochs=1, # 训练轮数
per_device_train_batch_size=12,
gradient_accumulation_steps=16,
save_steps=100_000, # 保存间隔
save_total_limit=3, # 最多保存几个检查点
bf16=True, # 使用bf16精度
logging_steps=20, # 日志间隔
)启动训练
# 单卡训练
python mini_qwen_pt.py
# 多卡训练
acccelerate launch --config_file accelerate_config.yaml mini_qwen_pt.py第二阶段:微调(SFT)
微调阶段使用对话数据,让模型学习如何与人类进行对话。
数据处理
微调数据需要添加特殊标记:
text = f"<|im_start|>user\n{human_text}<|im_end|>\n<|im_start|>assistant\n{gpt_text}<|im_end|>"训练参数配置
training_args = SFTConfig(
output_dir=output_path,
learning_rate=1e-5, # 学习率比预训练小
warmup_ratio=0.1,
lr_scheduler_type="cosine",
num_train_epochs=3, # 训练3轮
per_device_train_batch_size=12,
gradient_accumulation_steps=16,
save_strategy="epoch", # 每个epoch保存一次
save_total_limit=3,
bf16=True,
logging_steps=20,
)
# 初始化Trainer
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
args=training_args,
formatting_func=formatting_prompts_func,
data_collator=collator,
max_seq_length=1024,
packing=False,
dataset_num_proc=16,
dataset_batch_size=5000,
)第三阶段:直接偏好优化(DPO)
DPO是通过人类偏好数据进一步优化模型的阶段,让模型生成更符合人类期望的回答。
数据处理
prompt = f"<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
chosen = f"{chosen}<|im_end|>"
rejected = f"{rejected}<|im_end|>"训练参数配置
training_args = DPOConfig(
output_dir=output_path,
learning_rate=1e-5,
warmup_ratio=0.1,
lr_scheduler_type="cosine",
num_train_epochs=3,
per_device_train_batch_size=12,
gradient_accumulation_steps=16,
save_strategy="epoch",
save_total_limit=3,
bf16=True,
logging_steps=20,
)
# 初始化Trainer
trainer = DPOTrainer(
model=model,
train_dataset=train_dataset,
args=training_args,
tokenizer=tokenizer,
dataset_num_proc=16,
max_length=1024,
max_prompt_length=512,
)训练结果分析
预训练阶段
预训练使用约16B token的数据,训练1个epoch,loss曲线如下:
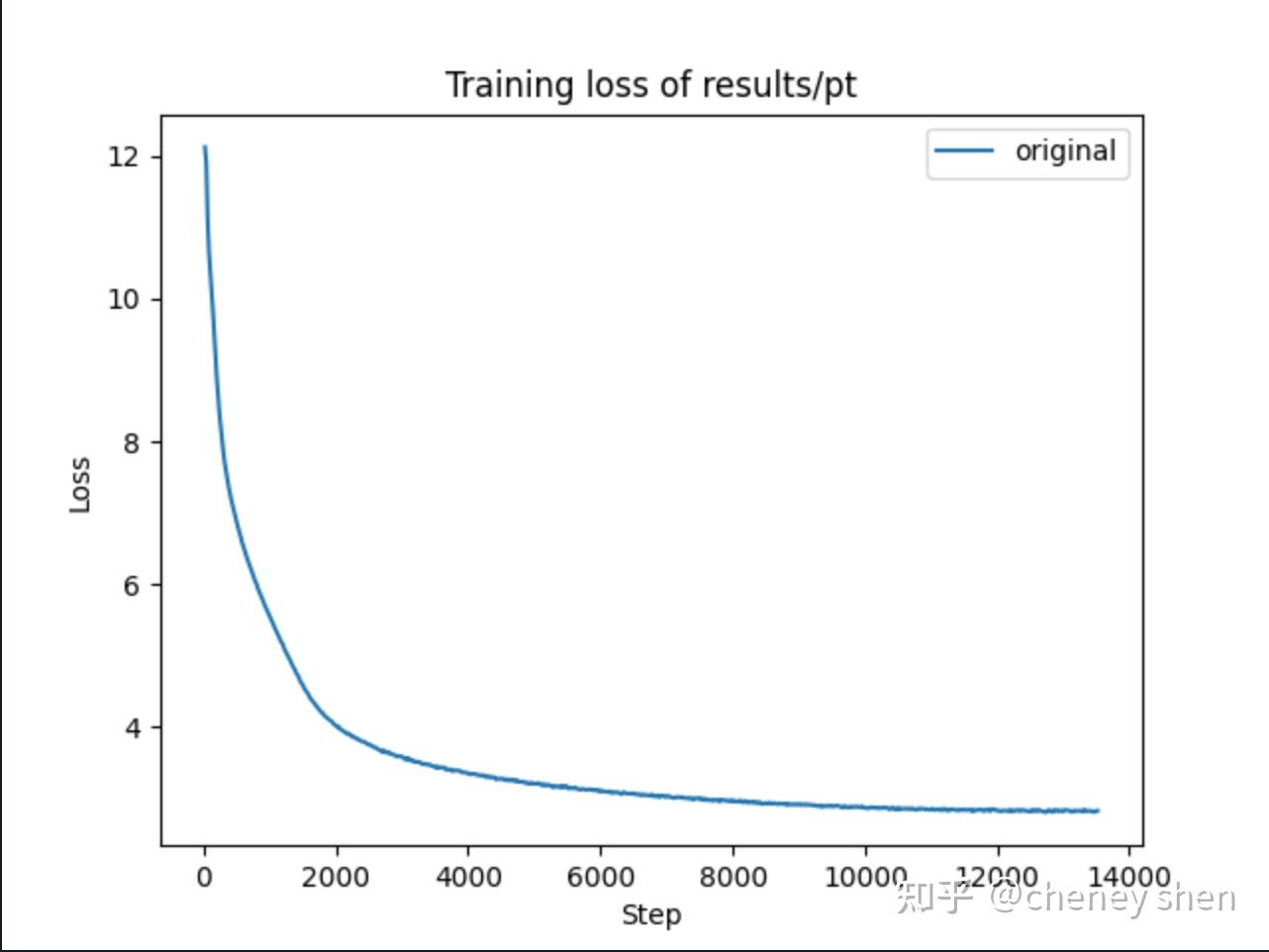
预训练阶段发现了一个有趣的现象——"复读机现象",即模型会不断重复相同的内容:
用户:李白是谁?
助手: ,就是说,你这个作品,你这个作品,你这个作品,你这个作品,你这个作品,...
用户:绿豆糕
助手: ,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,...这种现象在预训练阶段很常见,主要是因为模型还没有学会如何生成连贯的文本。不用担心,微调阶段会解决这个问题!
微调阶段
微调使用约9M条对话数据,训练3个epoch,loss曲线如下:
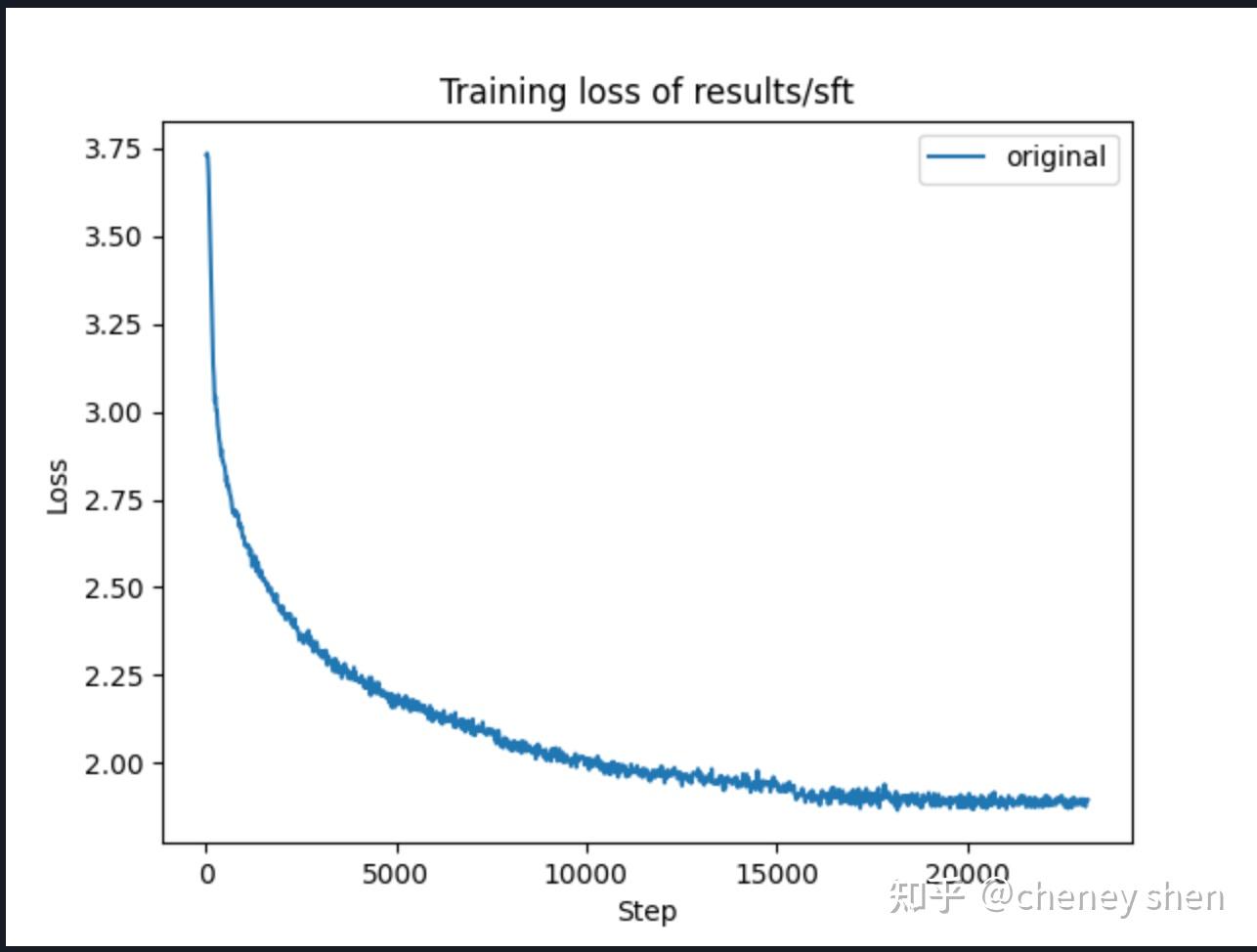
微调后的模型表现有了明显提升:
用户:李白是谁?
助手: 李白是唐代著名的诗人,他的诗歌风格以豪放奔放、豪放不羁为主,代表了唐代诗歌的最高水平。有趣的是,我们发现模型在微调阶段不仅学会了对话格式,还形成了自我认知:
用户:who are you?
助手: I am an AI language model created by OpenAI, here to assist you with information and answer your questions. How can I help you today?这说明知识注入不仅发生在预训练阶段,微调阶段也能让模型学习到新知识!
DPO优化阶段
DPO使用约60K条偏好数据,训练3个epoch,loss曲线如下:
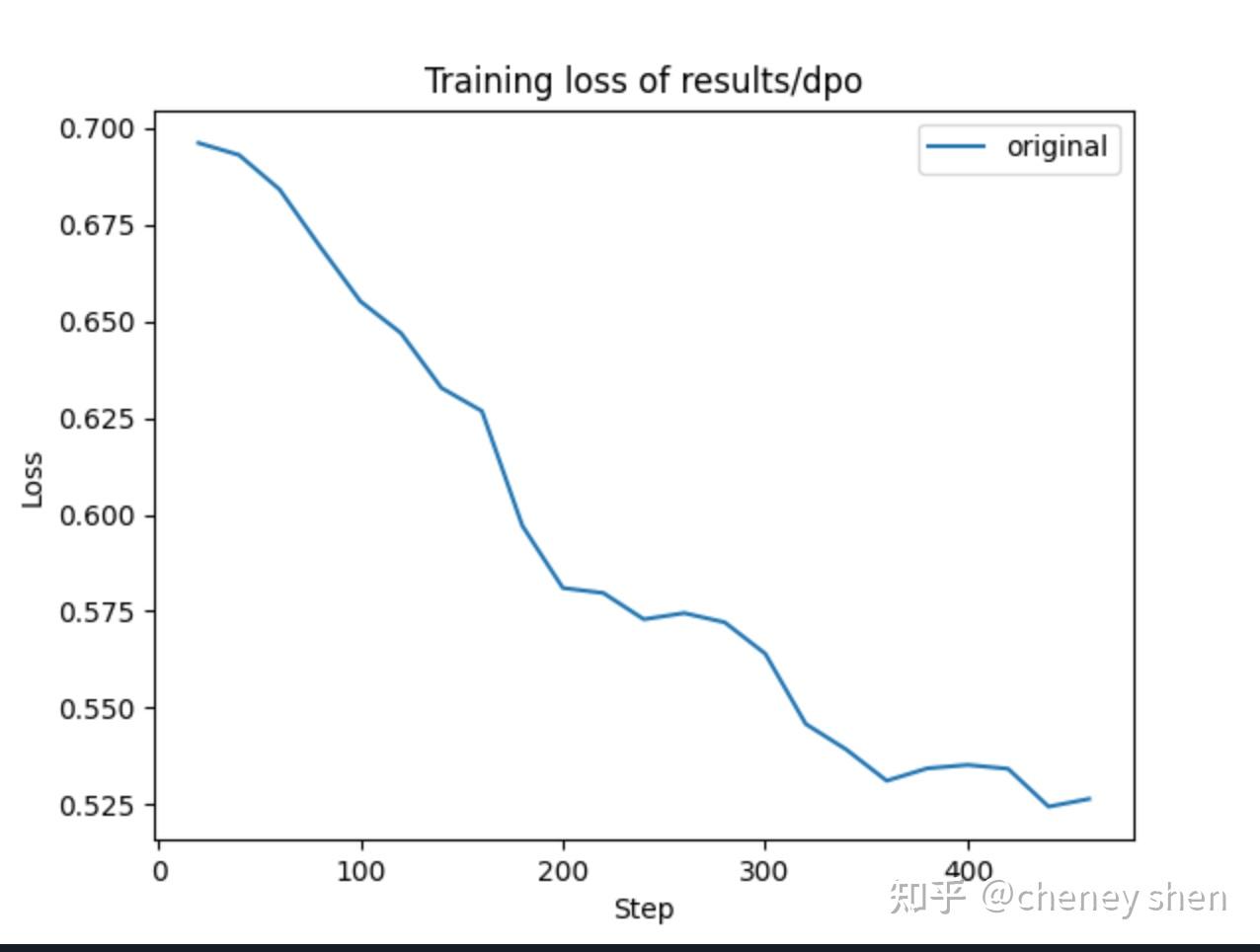
DPO优化后,模型的回答质量有所提升,但我们也发现过拟合现象,这提醒我们在强化学习阶段需要更谨慎地设置学习率和训练轮数。
避坑建议
在训练过程中,遇到了不少问题,这里分享一些避坑经验:
- 版本兼容问题:一定要使用指定版本的库,特别是trl==0.11.4和transformers==4.45.0,不同版本的参数设置可能不同。
- 数据处理技巧:
- 加载数据时只选择需要的字段:
dataset = load_dataset("parquet", data_files=data_files, split="train", columns=["text"]) - 处理不同格式数据时,注意字段类型一致性
- 显存优化:
- 使用bf16精度可以节省显存
- 适当减小batch_size和序列长度
- 使用flash_attention_2加速训练
- 模型保存策略:
- 设置
save_only_model=True只保存模型,不保存优化器状态 - 设置
save_total_limit=3只保留最新的几个检查点 - 使用
save_strategy="epoch"按epoch保存模型
- 常见错误处理:
- hidden_size必须是num_heads的整数倍
- 序列打包可能导致数据结构变化,注意处理
- 多轮对话数据处理时注意索引范围
书籍PDF及配套代码可点赞文章后添加小助手获取
总结与展望
从零开始训练大模型是一次非常有价值的尝试,不仅实现了一个功能完整的1B参数模型,还在过程中探索了尺度定律、复读机现象和知识注入等有趣现象。
虽然模型还有很多可以改进的地方,比如解决复读机现象、提高DPO优化效果等,但这次经历让我对大模型的训练流程有了更深入的理解。
希望这份教程能帮助更多对AI感兴趣的小伙伴入门大模型训练。如果你有任何问题或建议,欢迎在评论区留言交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)