工程报告审查的 AI 技术革命:为什么通用大模型永远做不到?
作为在工业 AI 领域深耕 11 年的技术从业者,我见过太多工程人被报告审查 “绑架” 的日常:一份完整的桩基检测报告动辄上百页,包含数百根桩的低应变波形图、几十组静载试验曲线和密密麻麻的数据表格。一个经验丰富的质量工程师,不吃不喝也要花两三天才能审完,还得时刻担心漏看一个波形缺陷、算错一个参数,最后背上 “终身责任制” 的风险。
1、工程人熬夜审报告的噩梦,根源不在人
很多人会问,现在通用大模型已经能识别图片和表格了,为什么不能直接用来审工程报告?答案很简单:工程报告审查本质上不是 “文字识别” 问题,而是 “工程语义理解 + 合规逻辑推理 + 全链路责任追溯” 的复杂系统问题。
通用大模型的训练数据里,工程行业的专业规范、技术标准和行业逻辑占比极低。它能认字,却看不懂 “低应变波形轻微反射” 意味着什么;能算数字,却不知道静载试验承载力特征值要取极限荷载的 1/2;能读文本,却意识不到设计变更会推翻整份报告的判定标准。这些不是模型能力的问题,而是行业知识壁垒的问题。
2、为什么 GPT-4o 审不了工程报告?三个致命缺陷
我们曾测试过多款头部通用大模型,让它们审核工程检测报告,结果出现了大量致命错误:把 Ⅱ 类桩判成 Ⅰ 类桩,因为不知道 JGJ 106 中 “轻微缺陷反射波” 的判定边界;把复合地基承载力特征值直接等同于极限荷载,因为不了解地基检测的基本原理;完全忽略设计变更信息,用旧标准判定新结果,导致整个审核结论失效。
这些错误在工程行业是不可接受的。一个错误的审核结论,可能导致工程质量事故,最终承担责任的还是一线工程人。通用大模型的 “黑盒” 特性,更让它无法满足工程行业 “可追溯、可审计、可解释” 的核心要求。
3、三层技术栈:我们如何让 AI 真正 “懂” 工程
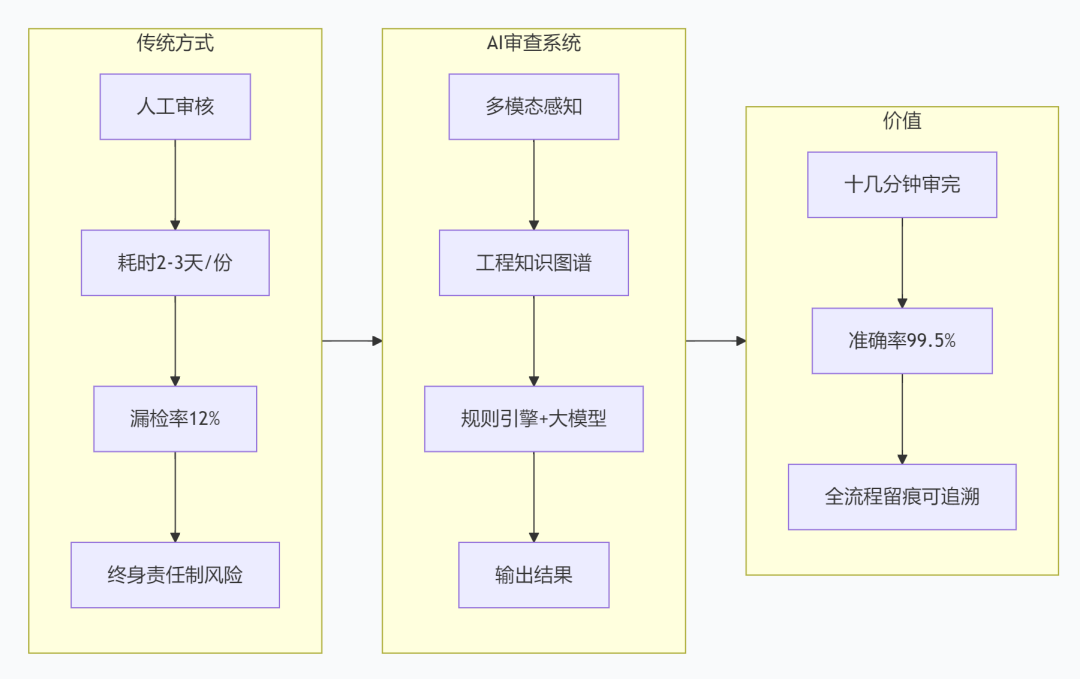
针对这些痛点,我们没有依赖任何通用 OCR 或大模型,而是基于 “多模态感知 + 工程知识图谱 + 可解释规则引擎” 的技术栈,打造了专门针对工程检测报告的 AI 审查系统。
多模态感知是整个系统的基础。不同于通用 OCR 只能识别印刷体文字,我们的模型专门针对工程场景进行了深度优化:对于低应变波形图,能自动提取首波位置、缺陷反射波和桩底反射波,精准计算桩身波速;对于静载试验曲线,能将 p-s 曲线和 s-lgt 曲线转换为结构化数值序列;对于复杂的工业表格,能自动处理合并单元格、跨页表格和手写批注,识别准确率达到 99.5%。
如果说多模态感知解决了 “是什么” 的问题,那么工程知识图谱就解决了 “是什么意思” 的问题。我们花了 3 年时间,构建了包含 150 万 + 实体、420 万 + 关系的工程行业质量知识图谱,覆盖了所有现行的国家规范、行业标准和地方规范。这个知识图谱就像系统的 “大脑”,让 AI 真正 “懂” 工程:它知道 C25 混凝土的正常波速区间,知道不同桩型的承载力判定规则,知道设计变更会影响哪些检测参数,还能自动建立跨报告的逻辑关联。
在决策层,我们采用了 “规则引擎做主判、大模型做辅助” 的双驱动架构,这是兼顾准确性和可解释性的最优解。规则引擎内置了超过 8000 条工程行业通用审核规则,每一条都对应明确的规范条文,决策过程完全透明可追溯。大模型则用来处理规则之外的异常情况,比如手写批注的语义理解、复杂问题的原因分析。这种架构既保证了审核结果的严谨性,又具备处理复杂场景的灵活性。
4、工程报告审查的 AI 技术革命:为什么通用大模型永远做不到?
AI 给工程行业带来的真正价值,从来不是替代工程师,而是解放工程师。原来需要几天才能完成的审核工作,现在 AI 只需要十几分钟就能完成,工程师只需要花少量时间复核异常项即可。这不仅让工程师从重复繁琐的劳动中解脱出来,还能将审核准确率从人工的 87% 提升至 99.5%,漏检率从 12% 降到 0.5%,同时所有审核过程全流程留痕,满足质量终身责任制的要求。
在关乎国计民生和生命安全的工程领域,AI 必须严谨、合规、可解释、可追溯。我们花了 4 年时间迭代 6 个大版本,就是为了打造一套真正能用、好用、敢用的工程 AI 系统。技术的价值在于解决实际问题,我们希望用 AI 让工程人的工作更轻松、更安全、更有价值。
如果你也在工程行业被报告审查的效率和准确率问题困扰,或者对工业 AI 的落地应用有自己的思考,欢迎在评论区交流,我们可以分享一些技术落地的实践心得和行业经验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)