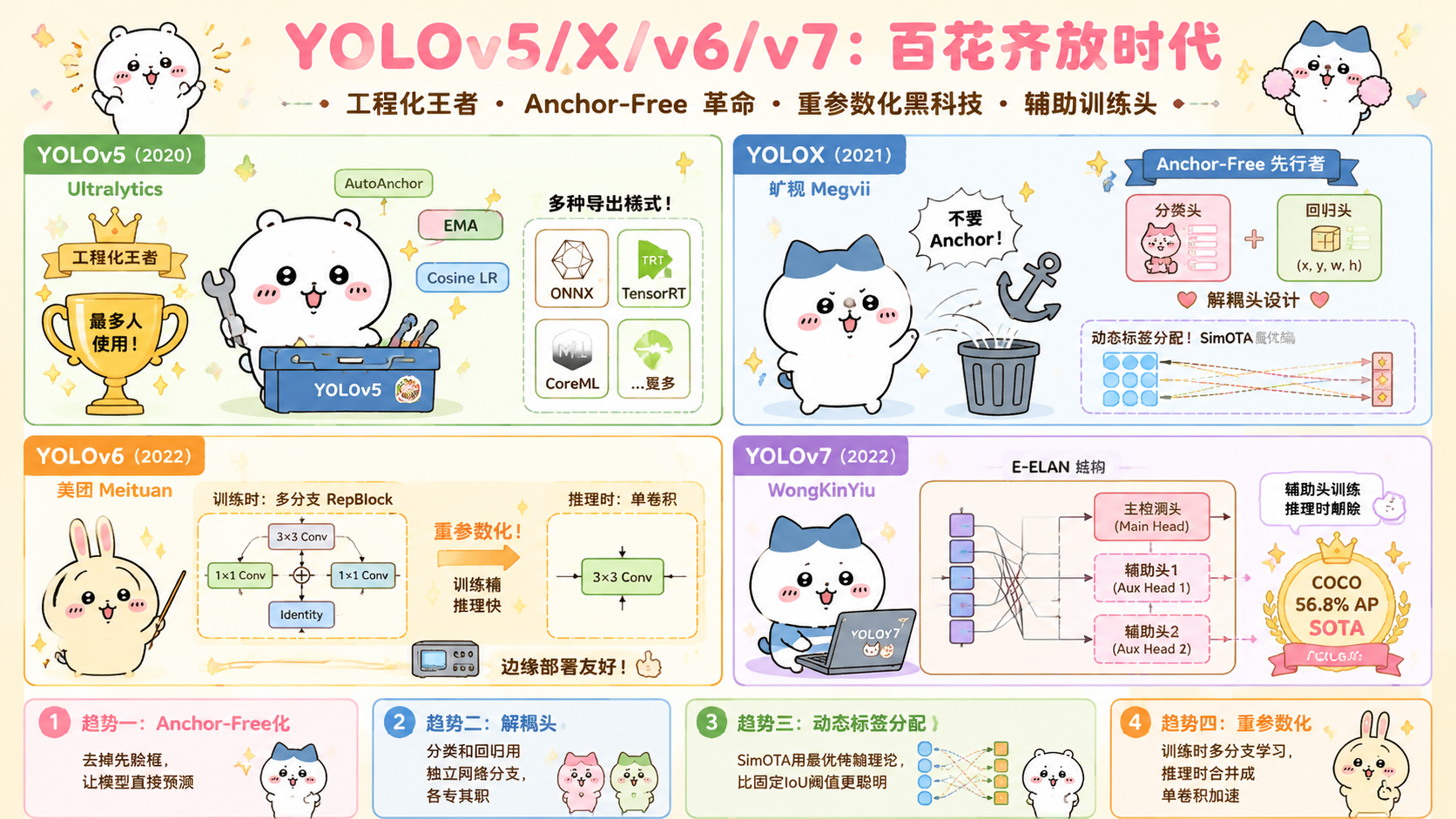
【深入浅出 YOLO 系列·第三篇】YOLOv5/X/v6/v7:百花齐放时代——工程化王者、Anchor-Free 革命、重参数化黑科技与辅助训练头(含完整代码)
【深入浅出 YOLO 系列·第三篇】YOLOv5/X/v6/v7:百花齐放时代——工程化王者、Anchor-Free 革命、重参数化黑科技与辅助训练头(含完整代码)
作者:技术博主 | 更新时间:2026-05-11 | 阅读时长:约 28 分钟
系列:深入浅出 YOLO 系列(共 4 篇)
标签:YOLOv5YOLOXYOLOv6YOLOv7Anchor-FreeDecoupledHeadSimOTARepVGG重参数化
🔥 本篇导读:2021-2022 年是 YOLO 历史上最热闹的两年——多个团队同时发力。Ultralytics 用 YOLOv5 建立了工程化标准,旷视用 YOLOX 发动了 Anchor-Free 革命,美团用 YOLOv6 把重参数化搬进检测器,YOLOv4 原班人马用 YOLOv7 把辅助训练头和 E-ELAN 推到新高度。本篇逐一拆解四个模型的核心技术,重点深讲 Anchor-Free 的设计哲学、SimOTA 标签分配和重参数化原理。
系列进度
| 篇次 | 主题 | 状态 |
|---|---|---|
| 第一篇 | YOLOv1/v2:回归范式,Anchor Box 原理 | ✅ 已发布 |
| 第二篇 | YOLOv3/v4:多尺度 FPN/PANet,CIoU,Mosaic | ✅ 已发布 |
| 第三篇(本篇) | YOLOv5/X/v6/v7:百花齐放,Anchor-Free 革命 | — |
| 第四篇 | YOLOv8/v9/v10/v11/v26:端到端,NMS-Free | 即将发布 |
目录
- 一、2021-2022:为什么 YOLO 突然百花齐放?
- 二、YOLOv5:工程化王者,让 YOLO 飞入千家万户
- 三、C3 模块与 SPPF:轻量化设计的精髓
- 四、YOLOX:Anchor-Free 进入 YOLO,三项革命性改变
- 五、Decoupled Head(解耦头):为什么分类和回归不能共用一个头?
- 六、SimOTA:用最优传输理论解决标签分配问题
- 七、Anchor-Free 的完整预测格式:从 Anchor 到中心点
- 八、YOLOv6(美团):重参数化骨干与工业部署优化
- 九、重参数化(Re-Parameterization)深度解析:训练时多分支,推理时单卷积
- 十、YOLOv7:E-ELAN + 辅助训练头,可训练的技巧大礼包
- 十一、关键公式汇总与代码实战
- 十二、四模型横向对比与选型指南
一、2021-2022:为什么 YOLO 突然百花齐放?
这两年发生了一件关键事情:Joseph Redmon(YOLO 原作者)宣布退出 CV 研究,放弃了 YOLO 商标,YOLO 系列成为事实上的开放社区项目。
原作者退出后,三方同时发力:
Ultralytics(Glenn Jocher):
YOLOv5(2020)— 工程化极致,PyTorch 原生
"最多人在生产中使用的 YOLO 版本"
旷视(Megvii):
YOLOX(2021)— 第一个将 Anchor-Free 引入 YOLO 的版本
"YOLO 系列的 Anchor-Free 革命"
美团技术团队:
YOLOv6(2022)— 针对工业部署优化,重参数化骨干
"为边缘设备而生"
YOLOv4 原班人马(WongKinYiu + Alexey):
YOLOv7(2022)— 可训练技巧大礼包,E-ELAN
"实时检测器新的 SOTA"
每个版本都有独立的技术主线,合在一起就是这两年 CV 社区的主要进展。
二、YOLOv5:工程化王者,让 YOLO 飞入千家万户
YOLOv5 从未有过正式学术论文(至今仍以 GitHub 仓库形式存在),但这不妨碍它成为史上被部署最多的目标检测模型。它的核心贡献不是单项技术突破,而是系统性的工程化。
2.1 整体架构
YOLOv5 架构(以 YOLOv5l 为例):
骨干(Backbone):CSPDarknet + C3 模块 + SPPF
颈部(Neck):PANet(CSP 版本)
检测头(Head):YOLOv3 Head(Anchor-Based,三尺度)
关键设计:
Focus 模块(早期)→ 6×6 Conv2d(后来替换)
C3 模块(CSP 的 YOLOv5 版本)
SPPF(SPP 的快速版本)
模型规模系列:
YOLOv5n(Nano): 1.9M 参数,最轻量,边缘设备
YOLOv5s(Small): 7.2M 参数,速度优先
YOLOv5m(Medium): 21.2M 参数,均衡
YOLOv5l(Large): 46.5M 参数,精度优先
YOLOv5x(XLarge): 86.7M 参数,最高精度
2.2 AutoAnchor:自动优化先验框
YOLOv5 引入了 AutoAnchor 机制,在训练前自动检查和优化 Anchor 配置:
# AutoAnchor 的核心逻辑(简化版)
def check_anchors(dataset, model, thr=4.0, imgsz=640):
"""
检查 Anchor 是否适合当前数据集
thr: 匹配阈值,每个目标至少需要与一个 Anchor 的宽高比 < thr
"""
anchors = model.anchors # 当前模型的 Anchor
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1))
wh = torch.tensor(
np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])
).float()
def metric(k):
"""计算当前 Anchor k 的最佳可能召回率(BPR)"""
r = wh[:, None] / k[None] # 真实框与每个 Anchor 的宽高比
x = torch.min(r, 1./r).min(2)[0] # 取最小的宽高比(越接近1越匹配)
best = x.max(1)[0] # 每个真实框最匹配的 Anchor
bpr = (best > 1./thr).float().mean() # 比例 > 阈值的框的比例
return bpr
bpr = metric(anchors)
print(f"AutoAnchor: BPR={bpr:.3f}")
if bpr < 0.98:
print("正在重新生成更合适的 Anchor...")
# 用 K-Means 重新聚类 Anchor
new_anchors = kmeans_anchors(dataset, n=9, img_size=imgsz)
new_bpr = metric(new_anchors)
if new_bpr > bpr:
model.anchors = new_anchors
print(f"新 Anchor BPR={new_bpr:.3f} ✅")
AutoAnchor 的价值:
传统做法(YOLOv2/v3):
用 COCO 数据集做 K-Means 得到固定 Anchor
在自定义数据集上直接使用
问题:
自定义数据集的目标形状可能与 COCO 差异极大
(医疗图像、遥感图像、工业检测)
使用 COCO Anchor → 大量目标无法被任何 Anchor 覆盖
→ BPR(最佳可能召回率)极低
→ 模型天花板很低
AutoAnchor 的优势:
训练开始前自动评估 Anchor 适合度(BPR)
如果 BPR < 0.98,自动用 K-Means 重新聚类
确保每个目标至少有一个合适的 Anchor 能覆盖它
→ 不需要用户手动调整 Anchor
→ 迁移到自定义数据集开箱即用
2.3 其他工程化改进
EMA(指数移动平均)权重:
维护一份"影子模型",参数是训练过程中各时刻参数的加权平均
W_ema = decay × W_ema + (1-decay) × W_current
推理时使用 EMA 权重,比瞬时权重更稳定
→ 减少训练后期的抖动,提升泛化能力
Warmup + Cosine LR:
训练初期(前几个 epoch)学习率从 0 逐渐增大
避免初始大梯度破坏预训练特征
之后用余弦退火衰减到最小值
混合精度训练(FP16):
自动将大部分计算从 FP32 换为 FP16
内存减半,速度提升 2×,精度损失极小
超参数进化(Hyperparameter Evolution):
用遗传算法自动搜索最优超参数
包括学习率、数据增强强度、损失权重等
对自定义数据集迁移效果显著
三、C3 模块与 SPPF:轻量化设计的精髓
3.1 C3 模块:YOLOv5 版本的 CSP
标准 CSP(YOLOv4 版本):
输入 → 分两路 → 一路过 N 个残差块 → 拼接 → 1×1 卷积
C3 模块(YOLOv5 的改进版):
输入 → 1×1 Conv → N 个 Bottleneck → |
拼接 → 1×1 Conv → 输出
输入 → 1×1 Conv ──────────────────── |
Bottleneck 结构:
x → Conv(1×1) → Conv(3×3) → + x(残差)
关键参数 shortcut:
True(默认):有残差连接,适合骨干网络(保留梯度流)
False:无残差,适合颈部网络(更多特征变换)
class C3(nn.Module):
"""YOLOv5 的 C3 模块(CSP Bottleneck with 3 convolutions)"""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # 隐藏层通道数
self.cv1 = Conv(c1, c_, 1, 1) # 1×1 卷积,降维
self.cv2 = Conv(c1, c_, 1, 1) # 跳跃路径
self.cv3 = Conv(2 * c_, c2, 1) # 融合后的 1×1 卷积
self.m = nn.Sequential(*(
Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)
))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
3.2 SPPF:SPP 的 2 倍加速版本
YOLOv5 将 YOLOv4 的 SPP(三路并行 MaxPool)改为 SPPF(串行三次 MaxPool):
SPP(原版,三路并行):
输入 → MaxPool(k=5) ─── |
→ MaxPool(k=9) ─── 拼接 → 融合
→ MaxPool(k=13) ─── |
→ 原始输入 ─── |
问题:三个 MaxPool 并行计算,内存占用高
SPPF(快速版,串行):
输入 → MaxPool(k=5) → MaxPool(k=5) → MaxPool(k=5)
↓ ↓ ↓ ↓
拼接全部四个输出(原始 + 三次池化)→ 融合
关键等价性:
MaxPool(k=5) × 3 次串行 = MaxPool(k=13) 一次
MaxPool(k=5) × 2 次串行 ≈ MaxPool(k=9) 效果
优势:
三次 MaxPool 共享输入特征,内存减少约 50%
速度提升约 2 倍(GPU 并行利用率更高)
感受野覆盖完全等价
四、YOLOX:Anchor-Free 进入 YOLO,三项革命性改变
2021 年 7 月,旷视(Megvii)发布 YOLOX,以 YOLOX-L 在 COCO 上取得 50.0% AP(68.9 FPS),首次在 YOLO 系列中全面超越 YOLOv5 的同规模版本。
YOLOX 的核心论点:YOLOv4/v5 是"过度优化"的 Anchor-Based 方案,而 Anchor-Free 才是更简洁、更通用的方向。
三项核心改变:
改变一:去掉 Anchor Box(Anchor-Free)
不再预定义 Anchor 形状
每个位置直接预测目标中心、偏移量和宽高
改变二:解耦检测头(Decoupled Head)
分类和回归用独立的网络分支
而不是共享同一组卷积层
改变三:SimOTA 动态标签分配
抛弃基于 IoU 阈值的静态分配
用最优传输理论动态决定每个目标由哪些位置预测
4.1 YOLOX 的架构总览
YOLOX 架构:
骨干:CSPDarknet(与 YOLOv5 相同)
颈部:YOLOPAFPN(PANet 变体)
检测头:Decoupled Head(分类头 + 回归头,独立)
三尺度输出:8×stride、16×stride、32×stride
(对应 52×52、26×26、13×13,输入 416×416)
从 YOLOv3 到 YOLOX 的改进路线图(论文 Table 2):
| 基线 | YOLOX-Darknet53 AP |
|---|---|
| YOLOv3 基线 | 38.5% |
| + Decoupled Head | 39.6%(+1.1%) |
| + Anchor-Free | 42.9%(+3.3%) |
| + SimOTA | 47.3%(+4.4%) |
| + 强数据增强 | 50.1%(+2.8%) |
每一步改进都带来显著提升,SimOTA 单项贡献 4.4%,是最大的单项改进。
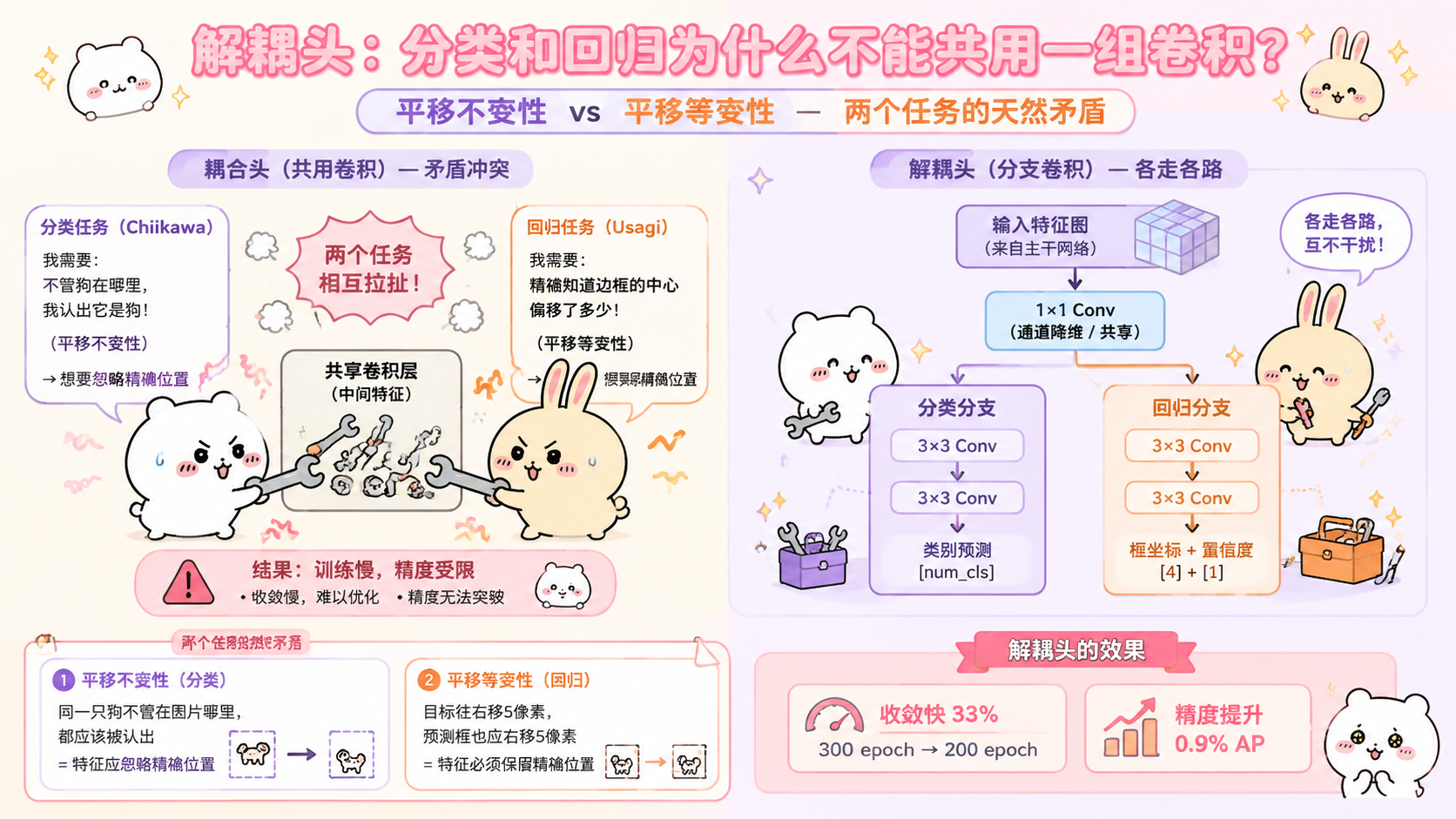
五、Decoupled Head(解耦头):为什么分类和回归不能共用一个头?
这是 YOLOX 中最直观、也是最重要的改进之一。
5.1 耦合头(Coupled Head)的问题
YOLOv1 到 YOLOv5,检测头都是"耦合"的:
耦合头(YOLOv3 风格):
输入特征图
↓
3×3 Conv(共享)
↓
1×1 Conv(输出)
↓
[conf, cx, cy, w, h, cls1, cls2, ..., clsC]
↑ ↑
回归任务 分类任务
同一组权重 ───────────
为什么这样有问题?
分类任务和回归任务的特性冲突:
分类任务:
需要"平移不变性"(Translation Invariance)
"这个位置是不是狗" 不管狗在格子的左边还是右边,答案一样
→ 卷积特征要尽量忽略精确位置信息
回归任务:
需要"平移等变性"(Translation Equivariance)
"框的中心偏移量" 必须精确感知位置
→ 卷积特征要精确保留位置信息
矛盾:
同一组卷积层不可能同时追求"忽略位置"和"精确位置"
→ 两个任务相互拉扯
→ 训练收敛慢,最终精度受限
5.2 解耦头(Decoupled Head)的设计
class DecoupledHead(nn.Module):
"""YOLOX 解耦检测头"""
def __init__(self, num_classes, width=1.0, in_channels=[256, 512, 1024]):
super().__init__()
self.cls_convs = nn.ModuleList() # 分类分支
self.reg_convs = nn.ModuleList() # 回归分支
self.cls_preds = nn.ModuleList() # 分类预测
self.reg_preds = nn.ModuleList() # 框回归预测
self.obj_preds = nn.ModuleList() # 置信度预测
for in_ch in in_channels:
ch = int(256 * width)
# 分类分支:两层 3×3 卷积 → 1×1 输出
self.cls_convs.append(nn.Sequential(
DWConv(in_ch, ch, 3),
DWConv(ch, ch, 3),
))
self.cls_preds.append(nn.Conv2d(ch, num_classes, 1, 1, 0))
# 回归分支:两层 3×3 卷积 → 两个 1×1 输出(框 + 置信度)
self.reg_convs.append(nn.Sequential(
DWConv(in_ch, ch, 3),
DWConv(ch, ch, 3),
))
self.reg_preds.append(nn.Conv2d(ch, 4, 1, 1, 0)) # cx, cy, w, h
self.obj_preds.append(nn.Conv2d(ch, 1, 1, 1, 0)) # objectness
def forward(self, xin):
outputs = []
for k, x in enumerate(xin):
cls_feat = self.cls_convs[k](x)
reg_feat = self.reg_convs[k](x)
cls_out = self.cls_preds[k](cls_feat) # [B, num_cls, H, W]
reg_out = self.reg_preds[k](reg_feat) # [B, 4, H, W]
obj_out = self.obj_preds[k](reg_feat) # [B, 1, H, W]
output = torch.cat([reg_out, obj_out, cls_out], dim=1)
outputs.append(output)
return outputs
解耦头带来的收益:
YOLOX 论文实验数据:
耦合头(YOLOv3 风格):39.6% AP,完全收敛需要 300 epoch
解耦头:40.5% AP, 收敛只需约 200 epoch
收敛加速约 33%,最终精度提升 0.9%
代价:参数量略微增加(两套卷积分支)
但推理速度影响很小(两分支并行)
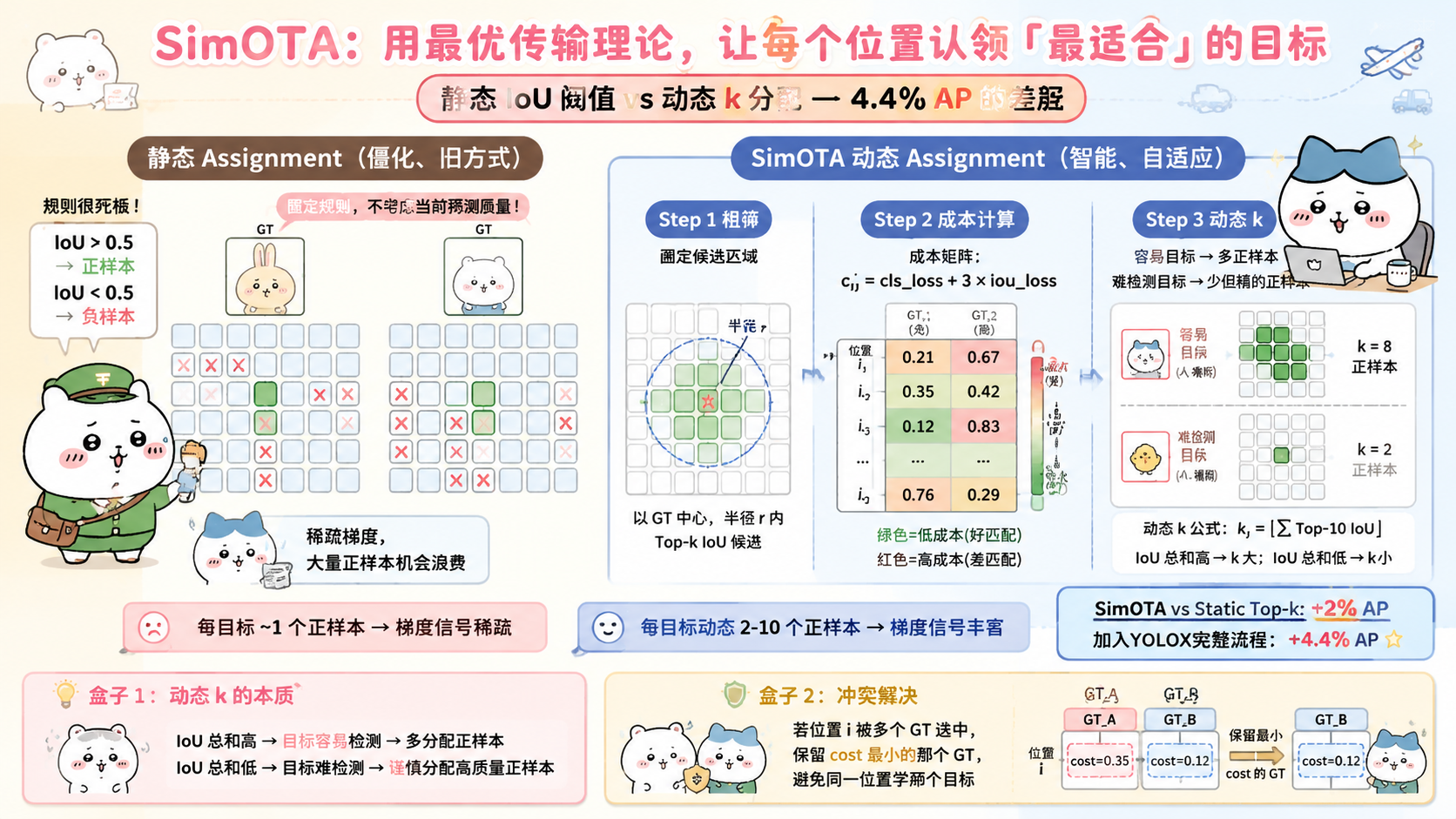
六、SimOTA:用最优传输理论解决标签分配问题
标签分配(Label Assignment)是目标检测训练中最关键的问题之一:给定一张图,每个位置(或 Anchor)应该负责预测哪个目标?
6.1 传统标签分配的问题
静态规则(YOLOv1-v5 的方法):
规则一(YOLOv2/v3):
某个 Anchor 与真实框 IoU 最大 → 正样本
所有其他 Anchor → 负样本
问题:每个目标只有 1 个正样本,
梯度信号极稀疏,训练效率低
规则二(YOLOv5):
同一目标,落在哪个格子就让哪个格子负责
同时也让相邻格子参与(跨格子匹配)
问题:完全基于几何位置,忽略了当前模型的预测能力
有时预测能力很强的位置反而不被选中
有时预测能力很弱的位置被强制分配目标
6.2 OTA:把标签分配变成最优传输问题
OTA(Optimal Transport Assignment)的思路:
将标签分配建模为最优传输问题:
供应方(Supplier):每个真实框 gt_j,提供 k 个正样本的"配额"
需求方(Receiver):每个候选位置 anchor_i,"消费"正样本
运输成本(Cost):c_{ij} = 位置 i 预测目标 j 的难度
目标:找到一个分配方案,使总运输成本最小
成本矩阵 c_{ij}:
c_{ij} = L_cls(pred_i, cls_j) # 分类损失
+ λ × L_reg(pred_i, box_j) # 回归损失
解法:Sinkhorn-Knopp 算法(迭代求解)
OTA 的问题: Sinkhorn-Knopp 迭代计算量大,在 GPU 上批量计算效率低。
6.3 SimOTA:简化版最优传输,实用又高效
SimOTA 的核心简化思路:
SimOTA 的三步分配:
Step 1:初始候选集(粗筛)
对每个真实框 gt_j,选取候选位置:
① 在以 gt 中心为圆心、半径 r 的圆内的所有位置(几何约束)
② 固定取前 10 个 IoU 最高的位置(Top-k 预选)
合并两个候选集
Step 2:计算成本矩阵
对候选集中每个位置 i,计算分配给目标 j 的成本:
c_{ij} = L_cls(pred_i, cls_j) + 3 × L_iou(pred_i, box_j)
+ λ × background_penalty(若该位置是背景)
Step 3:动态 Top-k 分配
对每个真实框 j,选取成本最小的 k_j 个位置作为正样本
k_j 不是固定值,而是动态计算:
选取与目标 j IoU 最高的前 10 个候选位置
k_j = ⌈sum of top-10 IoU values⌉
(IoU 总和越大 → 该目标越容易检测 → 分配更多正样本)
冲突解决:
如果某位置 i 被多个目标 j 选中
保留 cost 最低的那个目标,其他视为背景
SimOTA 的数学表达:
k j = ⌊ ∑ i ∈ Ω j IoU ( b ^ i , g j ) ⌉ k_j = \left\lfloor \sum_{i \in \Omega_j} \text{IoU}(\hat{b}_i, g_j) \right\rceil kj= i∈Ωj∑IoU(b^i,gj)
k_j = \left\lfloor \sum_{i \in \Omega_j} \mathrm{IoU}(\hat{b}_i,\, g_j) \right\rceil
其中 Ω j \Omega_j Ωj 是真实框 g j g_j gj 的前 10 个高 IoU 候选位置集合。
效果:
静态 Top-k(固定每个目标 k=10 个正样本):
所有目标一视同仁,简单但不够准确
SimOTA 动态 k:
容易检测的目标(与候选位置 IoU 普遍高)→ 分配更多正样本
难以检测的目标(IoU 普遍低)→ 分配少量高质量正样本
→ 自适应于数据集特性
→ mAP 相比静态 Top-k 提升约 2%
七、Anchor-Free 的完整预测格式
理解了 Decoupled Head 和 SimOTA,再看 Anchor-Free 的预测格式就很清晰了。
7.1 Anchor-Based vs Anchor-Free 预测对比
Anchor-Based(YOLOv3/v5):
每个位置 (i,j) 有 k 个 Anchor(k=3)
预测"相对于 Anchor 的偏移量":
bx = σ(tx) + cx
by = σ(ty) + cy
bw = pw × e^tw ← 依赖 Anchor 先验宽高 pw
bh = ph × e^th ← 依赖 Anchor 先验高度 ph
需要:Anchor 设计(K-Means) + AutoAnchor 验证
Anchor-Free(YOLOX):
每个位置 (i,j) 只有 1 个预测
直接预测中心点偏移和绝对宽高:
cx = stride × (j + σ(tx)) ← 中心 x(图像像素坐标)
cy = stride × (i + σ(ty)) ← 中心 y(图像像素坐标)
w = stride × e^tw ← 宽度(直接预测,不依赖 Anchor)
h = stride × e^th ← 高度
不需要:Anchor 设计,直接迁移到新数据集
7.2 Anchor-Free 的优缺点
优点:
✅ 无需 K-Means 聚类设计 Anchor
✅ 无需 AutoAnchor 验证适配性
✅ 对形状极端的目标(超宽/超高)也能预测
✅ 迁移到新数据集更方便
缺点(已被后续版本解决):
⚠️ 每个位置只有 1 个预测,总候选框数减少
(10647 → 3549)
→ 理论上召回率会降低
→ YOLOX 用更好的 SimOTA 抵消了这个损失
⚠️ 对密集小目标场景,预测冗余度更低
(Anchor-Based 有 3 个 Anchor 覆盖每个位置)
八、YOLOv6(美团):重参数化骨干与工业部署优化
2022 年,美团技术团队发布 YOLOv6,核心目标是工业部署友好——在边缘设备和移动端上实现更快的推理速度。
8.1 EfficientRep 骨干
YOLOv6 的核心骨干:EfficientRep
基于 RepVGG 思想,专为推理速度优化
小模型(N/S):RepBlock 骨干
训练时:多分支(3×3 Conv + 1×1 Conv + Identity)
推理时:合并为单个 3×3 Conv(重参数化)
→ 训练精度 + 推理速度两全其美
大模型(M/L):CSPStackRep 骨干
RepBlock + CSP 结合
提供更强的特征提取能力
8.2 BiC 模块(双向拼接)
YOLOv6 在颈部引入了 BiC(Bi-directional Concatenation)模块:
传统 PANet 上采样路径:
低分辨率特征图 → 上采样 → 与高分辨率特征拼接
BiC 模块的改进:
上采样后拼接时,额外引入来自更前一层的特征
[P_{i-1}] ─┐
[P_i↑] ─┤── 拼接 ── Conv ── [N_i]
[P_i] ─┘
P_{i-1}:前一层级的特征(更低分辨率,更高语义)
P_i↑:当前层上采样后的特征
P_i:当前层原始特征
好处:
为特征融合提供更准确的定位信号
以极小的速度代价换来更好的定位精度
8.3 AAT(Anchor-Aided Training)
YOLOv6 的一个独特设计:训练时辅助 Anchor,推理时 Anchor-Free。
AAT 的逻辑:
Anchor-Free 在训练初期收敛较慢
(没有先验知识,模型需要从头学习目标形状)
解决方案:
训练时同时训练两个头:
主头(Anchor-Free):正常 Anchor-Free 预测
辅助头(Anchor-Based):使用传统 Anchor 帮助提供梯度信号
推理时只使用主头(Anchor-Free)
→ 训练更稳定,推理更简洁
效果:
相比纯 Anchor-Free:训练收敛更快,最终精度更高
相比纯 Anchor-Based:推理部署更简单
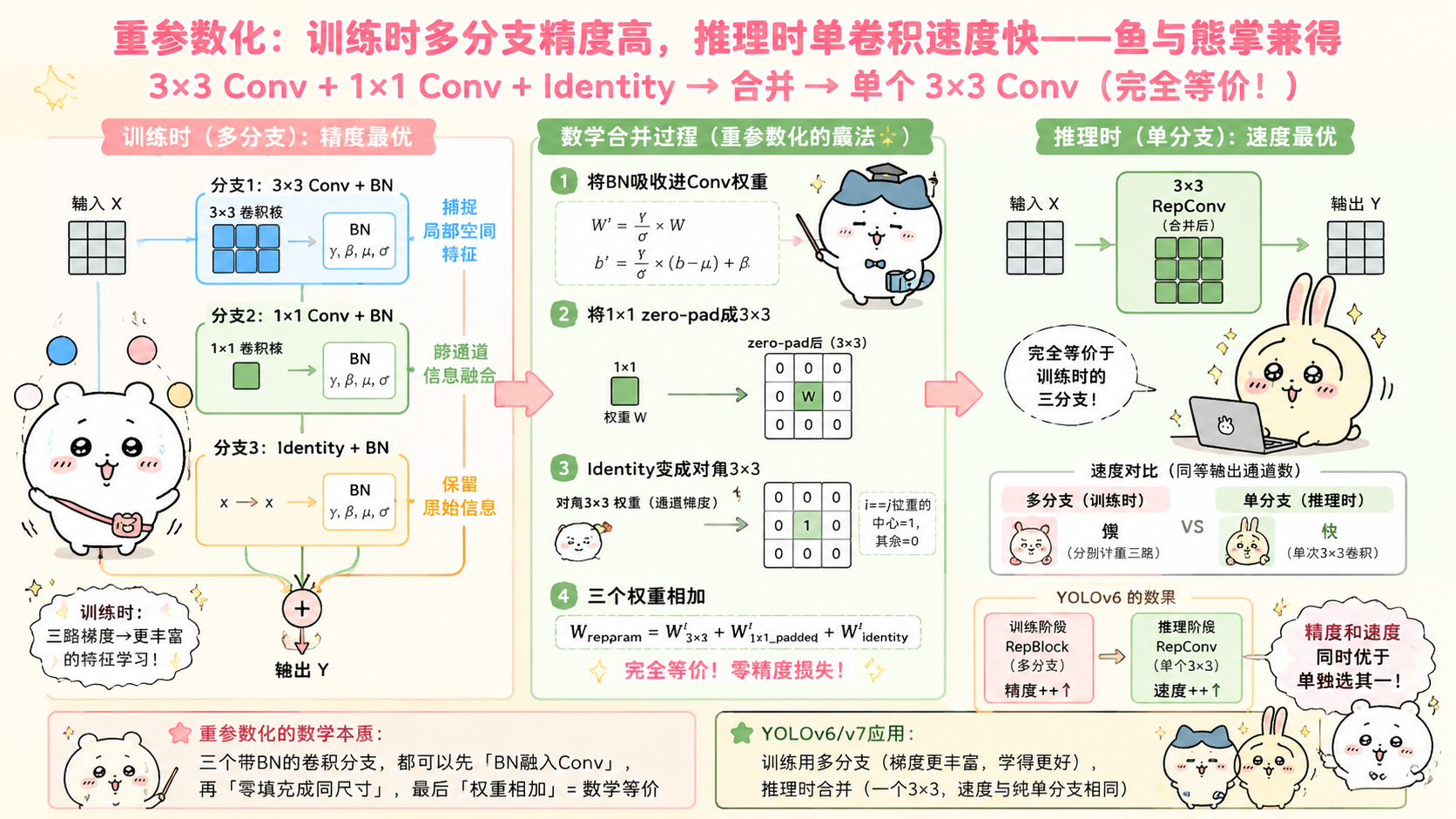
九、重参数化(Re-Parameterization)深度解析
重参数化是 YOLOv6/v7 引入的核心技术,也是近年来 CV 领域最聪明的工程技巧之一。
9.1 核心思想
核心洞察:
训练时需要"多分支"(多种卷积核大小 + 跳跃连接)
→ 提供丰富的梯度信号,模型学得好
推理时需要"单卷积"(只有一个分支)
→ 简洁,GPU 友好,速度快
能不能两者都要?
→ 训练时多分支,推理时合并成等价的单卷积
→ 数学上完全等价,精度不损失
9.2 RepVGG 的数学推导
一个 RepVGG Block 在训练时的结构:
y = Conv 3 × 3 ( x ) + Conv 1 × 1 ( x ) + x y = \text{Conv}_{3\times3}(x) + \text{Conv}_{1\times1}(x) + x y=Conv3×3(x)+Conv1×1(x)+x
y = \mathrm{Conv}_{3\times3}(x) + \mathrm{Conv}_{1\times1}(x) + x
三路融合成一路的方法:
推理时,将三个分支等价地合并为一个 3×3 卷积:
分支1:3×3 卷积 + BN
合并 BN 到卷积权重:
W'_3x3 = γ/σ × W_3x3
b'_3x3 = γ/σ × (b_3x3 - μ) + β
分支2:1×1 卷积 + BN
1×1 卷积等价于 3×3 卷积(中心有值,周围 padding 为 0)
W'_1x1_padded:将 1×1 权重 zero-pad 到 3×3
同样合并 BN
分支3:Identity(恒等连接,x → x)
等价于单位矩阵的 3×3 卷积(仅当 in_channels == out_channels)
W_identity:对角线为 1 的 3×3 滤波器
最终合并:
W_reparam = W'_3x3 + W'_1x1_padded + W_identity
b_reparam = b'_3x3 + b'_1x1 + 0
三个分支 → 一个等价的 3×3 卷积 + 偏置
数学上完全等价!
def reparam_conv(conv_3x3, conv_1x1, bn_3x3, bn_1x1, bn_id,
in_channels, out_channels):
"""
将 RepVGG 三分支融合为单个 3×3 卷积
"""
def fuse_conv_bn(conv, bn):
"""将 BN 层吸收进卷积层"""
std = (bn.running_var + bn.eps).sqrt()
scale = bn.weight / std
# 卷积权重缩放
fused_weight = conv.weight * scale[:, None, None, None]
# 偏置融合
fused_bias = (conv.bias - bn.running_mean) * scale + bn.bias
return fused_weight, fused_bias
# 分支1:3×3 conv + BN
w3, b3 = fuse_conv_bn(conv_3x3, bn_3x3)
# 分支2:1×1 conv + BN,padding 成 3×3
w1, b1 = fuse_conv_bn(conv_1x1, bn_1x1)
w1_padded = F.pad(w1, [1, 1, 1, 1]) # zero-pad 到 3×3
# 分支3:identity(仅当 in == out)
if in_channels == out_channels:
# 单位矩阵变成 3×3 卷积(每个输出通道只关注对应输入通道的中心)
w_id = torch.zeros_like(w3)
for i in range(in_channels):
w_id[i, i, 1, 1] = 1.0 # 中心点为 1
# identity 的 BN
std_id = (bn_id.running_var + bn_id.eps).sqrt()
scale_id = bn_id.weight / std_id
w_id = w_id * scale_id[:, None, None, None]
b_id = (0 - bn_id.running_mean) * scale_id + bn_id.bias
else:
w_id = torch.zeros_like(w3)
b_id = torch.zeros_like(b3)
# 合并
w_reparam = w3 + w1_padded + w_id
b_reparam = b3 + b1 + b_id
return w_reparam, b_reparam
9.3 重参数化的实际效果
RepVGG 实验结果(ImageNet 分类):
普通 VGG 单分支(推理): Top-1 = 72.4%
多分支训练 + 推理时保留多分支:Top-1 = 74.8%(更准)
多分支训练 + 重参数化合并: Top-1 = 74.8%(同样准!)
合并前后精度完全一致!
但合并后推理速度与单分支相同
YOLOv6 中的效果:
训练用 RepBlock(多分支)→ 精度更高(多路梯度)
推理用 RepConv(单分支)→ 速度更快
两全其美!
十、YOLOv7:E-ELAN + 辅助训练头
10.1 E-ELAN(扩展高效层聚合网络)
E-ELAN 的设计目标是在不改变梯度传输路径的前提下,提升特征的多样性:
ELAN(基础版):
输入 → 两路分流
路径1:一系列计算模块 (Block 1, 2, 3, 4)
路径2:直接传递
拼接 → 融合
E-ELAN(扩展版):
使用"分组卷积"扩展特征的基数(cardinality)
输入 → 四路分流(用分组卷积实现)
路径1:Block 序列,第 1 组特征
路径2:Block 序列,第 2 组特征
路径3:直接传递,第 3 组
路径4:直接传递,第 4 组
↓
混洗(Shuffle)+ 拼接
→ 不同路径的特征互相混合
→ 提升特征多样性
关键性质:
E-ELAN 不改变原始 ELAN 的梯度传输路径
只是"扩展"了学习的特征基数
→ 在不破坏已有训练稳定性的前提下提升能力
E-ELAN 与 ELAN 的关系(论文 Figure 2):
o u t = Transition ( Concat ( c 1 , c 2 , … , c k ) ) \mathbf{out} = \text{Transition}(\text{Concat}(\mathbf{c}_1, \mathbf{c}_2, \ldots, \mathbf{c}_k)) out=Transition(Concat(c1,c2,…,ck))
\text{out} = \text{Trans}\!\left(\mathrm{Concat}(\mathbf{c}_1,\ldots,\mathbf{c}_k)\right)
其中每个 c i \mathbf{c}_i ci 是通过独立的计算路径得到的特征,E-ELAN 用分组卷积增加了路径数量。
10.2 辅助训练头(Auxiliary Head)
核心思想:
深层网络的浅层对最终 Loss 的梯度很稀疏(梯度消失)
→ 浅层学习慢
解决:在浅层也加入辅助检测头(Auxiliary Head)
→ 浅层直接接收检测损失的梯度
→ 浅层也能学到有用的检测特征
训练时的两级监督:
主头(Lead Head):网络末端的正式检测头,推理时使用
辅助头(Auxiliary Head):中间层的额外检测头,仅训练时使用
总损失:
L = L_lead + 0.5 × L_aux(辅助头损失权重为 0.5)
推理时:
直接去掉辅助头
只保留主头,无额外计算开销!
效果:
辅助训练头相当于"深监督"(Deep Supervision)
类似于早期 GoogLeNet 的辅助分类器思路
在 YOLOv7 中:AP 提升约 0.9-1.2%
10.3 YOLOv7 的其他技巧
模型重参数化(RepConv):
E-ELAN 的计算模块中集成了 RepConv(RepVGG 思路)
训练时:3×3 + 1×1 + Identity
推理时:融合为单个 3×3
标签分配改进:
结合 YOLOv5 的跨格子匹配 + YOLOX 的最优传输思路
形成混合标签分配策略
最终性能(COCO test-dev,V100 GPU):
YOLOv7:56.8% AP,30 FPS(高精度版本)
YOLOv7-Tiny:35.2% AP,286 FPS(轻量版本)
YOLOv7-X(与 YOLOv5-X 对比):
速度快 31 FPS,精度高 3.9% AP
十一、关键公式汇总与代码实战
11.1 Anchor-Free 解码
def decode_anchor_free(raw_output, stride):
"""
YOLOX 风格的 Anchor-Free 解码
raw_output: [B, 5+num_cls, H, W]
前4个通道是 tx, ty, tw, th(回归)
第5个通道是 objectness(置信度)
后面是类别分数
stride: 当前特征图步长(8/16/32)
"""
B, _, H, W = raw_output.shape
# 生成格子坐标
grid_y, grid_x = torch.meshgrid(
torch.arange(H, dtype=torch.float32),
torch.arange(W, dtype=torch.float32),
indexing='ij',
) # [H, W]
grid_xy = torch.stack([grid_x, grid_y], dim=0) # [2, H, W]
grid_xy = grid_xy[None].to(raw_output.device) # [1, 2, H, W]
# 分离各部分
pred_xy = raw_output[:, :2] # [B, 2, H, W]
pred_wh = raw_output[:, 2:4] # [B, 2, H, W]
pred_obj = raw_output[:, 4:5] # [B, 1, H, W]
pred_cls = raw_output[:, 5:] # [B, num_cls, H, W]
# 解码中心点(Anchor-Free:直接加格子坐标)
bxy = (pred_xy.sigmoid() + grid_xy) * stride # 图像像素坐标
# 解码宽高(直接 exp,不依赖任何 Anchor 先验)
bwh = pred_wh.exp() * stride
# 置信度和类别
obj_conf = pred_obj.sigmoid()
cls_score = pred_cls.sigmoid()
scores = obj_conf * cls_score # [B, num_cls, H, W]
return bxy, bwh, scores
11.2 SimOTA 简化实现
def simota_assign(pred_bboxes, pred_scores, gt_bboxes, gt_labels,
num_classes, r=2.5, top_k=10):
"""
SimOTA 标签分配(简化版)
pred_bboxes: [N, 4],所有候选位置的预测框(cx,cy,w,h)
pred_scores: [N, num_classes],所有候选位置的分类分数
gt_bboxes: [G, 4],真实框
gt_labels: [G],真实类别
"""
N = pred_bboxes.shape[0]
G = gt_bboxes.shape[0]
# Step 1:计算所有位置与所有真实框的 IoU
iou_matrix = iou_pairwise(pred_bboxes, gt_bboxes) # [N, G]
# Step 2:计算成本矩阵
cls_target = F.one_hot(gt_labels, num_classes).float() # [G, C]
cls_cost = F.binary_cross_entropy(
pred_scores.unsqueeze(1).expand(-1, G, -1), # [N, G, C]
cls_target.unsqueeze(0).expand(N, -1, -1), # [N, G, C]
reduction='none'
).sum(-1) # [N, G]
iou_cost = -torch.log(iou_matrix + 1e-8) # IoU 越大,成本越小
cost_matrix = cls_cost + 3.0 * iou_cost # [N, G]
# Step 3:动态 k(每个 gt 分配的正样本数量)
# 取每个 gt 的前 top_k 个 IoU,求和取整
topk_iou, _ = iou_matrix.topk(min(top_k, N), dim=0) # [top_k, G]
dynamic_k = topk_iou.sum(0).int().clamp(min=1) # [G]
# Step 4:对每个 gt,选取 cost 最小的 dynamic_k 个位置
assign = torch.full((N,), -1, dtype=torch.long) # -1 = 背景
for g in range(G):
k = dynamic_k[g].item()
_, pos_idx = cost_matrix[:, g].topk(k, largest=False) # cost 最小的 k 个
assign[pos_idx] = g # 暂时分配给第 g 个 gt
# Step 5:冲突解决(同一位置被多个 gt 选中,保留 cost 最低的)
for i in range(N):
if (assign == -1).all():
break
# 找所有分配到同一位置的 gt(这里已经在循环中处理,实际用矩阵运算更高效)
return assign # [N],-1=背景,>=0=对应第几个 gt
十二、四模型横向对比与选型指南
| 维度 | YOLOv5 | YOLOX | YOLOv6 | YOLOv7 |
|---|---|---|---|---|
| 发布机构 | Ultralytics | 旷视 | 美团 | WongKinYiu |
| 发布年份 | 2020 | 2021 | 2022 | 2022 |
| Anchor 策略 | Anchor-Based(AutoAnchor) | Anchor-Free | Anchor-Free(AAT 辅助训练) | Anchor-Based |
| 检测头 | 耦合头 | 解耦头 | 解耦头 | 解耦头 |
| 骨干 | CSPDarknet + C3 | CSPDarknet | EfficientRep(重参数化) | E-ELAN |
| 标签分配 | 跨格子匹配 | SimOTA | SimOTA | OTA 混合 |
| 重参数化 | ❌ | ❌ | ✅ | ✅ |
| 辅助训练头 | ❌ | ❌ | ✅(AAT) | ✅ |
| COCO AP (L) | 49.0% | 50.0% | 52.8% | 56.8%(E6E) |
| 生态成熟度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
选型建议:
选 YOLOv5:
工程部署首选,生态最成熟
有大量自定义训练教程和部署工具
对新手和快速落地最友好
选 YOLOX:
学术研究首选(架构简洁,便于改造)
自定义数据集(无需调 Anchor)
作为论文 Baseline
选 YOLOv6:
边缘设备部署(移动端/嵌入式)
需要重参数化加速推理
工业质检等实时场景
选 YOLOv7:
追求 COCO 精度的生产系统
有充足 GPU 算力支持更长训练
需要最高精度时的首选(当时 SOTA)
注:以上四个版本在 YOLOv8 发布后(2023年)
已陆续被后者的架构统一,但仍是理解
v8+ 设计思想的重要基础
预告:第四篇(收官)
《深入浅出 YOLO 系列·第四篇:YOLOv8/v9/v10/v11/v26——端到端检测,NMS-Free,以及 YOLO 的最终形态》
将要讲的内容:
- YOLOv8:Ultralytics 全面 Anchor-Free 化,C2f 模块,多任务统一框架
- YOLOv9:GELAN + PGI(可编程梯度信息)解决深层网络信息损耗
- YOLOv10:NMS-Free 的完整设计,双重分配策略
- YOLO11/v26:注意力机制集成,Progressive Loss,最新 SOTA
💬 你在项目里用过 Anchor-Free 的方案吗?切换后精度有提升还是下降? 欢迎评论区分享!
🙏 如果这篇帮到你,一键三连(点赞👍 + 收藏⭐ + 关注)!收官篇第四篇即将发布!
参考资料
- Ge Z. et al.《YOLOX: Exceeding YOLO Series in 2021》arXiv:2107.08430
- Li C. et al.《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》arXiv:2209.02976
- Wang C-Y. et al.《YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors》CVPR 2023, arXiv:2207.02696
- Ding X. et al.《RepVGG: Making VGG-style ConvNets Great Again》CVPR 2021
- Ge Z. et al.《OTA: Optimal Transport Assignment for Object Detection》CVPR 2021
- Ultralytics YOLOv5 文档:https://docs.ultralytics.com/yolov5/
本文为原创技术分享。转载请注明出处。最后更新:2026-05-11

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献202条内容
已为社区贡献202条内容

所有评论(0)