从零开始学AI13——逻辑回归
本文系统解析了逻辑回归的核心原理与应用场景。逻辑回归虽名为"回归",实则是经典分类算法,通过线性计算+Sigmoid函数将数值转化为概率进行二分类决策。其核心流程包括:1)线性打分计算特征权重;2)Sigmoid函数压缩为0-1概率;3)以0.5为阈值进行分类。典型应用包括垃圾邮件检测、广告点击预测、金融风控和医疗诊断等二分类场景。相比线性/多项式回归预测数值,逻辑回归专长于类别判断,具有可解释性强但处理复杂数据能力有限的特性。作为机器学习基石算法,其"数值→概率→决策"的思维模式具有重要方法论意义。
分类算法的核心:逻辑回归 (Logistic Regression)
在机器学习的世界里,任务主要分为两类:预测具体数值的回归(Regression)(例如:预测明天的气温是23.5度),和预测类别的分类(Classification)(例如:预测明天是晴天还是雨天)。
线性回归、多项式回归、逻辑回归的区分:这三者是机器学习中最基础的算法,初学者很容易因为名字里都有“回归(Regression)”而混淆。
用一句话总结它们的本质区别:
- 线性回归:画一条直线来预测数值(比如房价)。
- 多项式回归:画一条曲线来预测数值(比如气温变化)。
- 逻辑回归:画一条S形曲线(或分界线)来做是非选择题(比如是否患病)。
下面是详细的对比解析:
1. 线性回归 (Linear Regression)
关键词: 直线、预测数值、简单关系
- 核心任务: 回归(预测连续的数值)。
- 直观理解: 想象你在坐标纸上有一堆点,你手里拿一把直尺,试图画一条直线,让这条线尽可能穿过或者靠近所有的点。
- 数学形状: 一条直线(或高维平面)。
- 公式简化: y=ax+by=ax+b
- 输出结果: 可能是任意数值(例如:250万,-10度,85分)。
- 适用场景: 简单的线性关系。
- 例子: 房子面积越大,房价越高;工作年限越长,工资越高。
2. 多项式回归 (Polynomial Regression)
关键词: 曲线、预测数值、复杂关系
- 核心任务: 回归(预测连续的数值)。
- 直观理解: 当数据点的分布不是直的,而是弯弯曲曲的(比如抛物线),直尺(线性回归)就不管用了。这时你需要一根可以弯曲的软尺,去贴合数据的走向。
- 数学形状: 一条曲线(抛物线、波浪线等)。
- 原理: 它是线性回归的升级版。通过引入 x2x2 (平方)、x3x3 (立方) 等项,让模型拥有了“拐弯”的能力。
- 公式简化: y=ax+bx2+cx3+...y=ax+bx2+cx3+...
- 输出结果: 任意数值。
- 适用场景: 非线性的复杂关系。
- 例子:
- 一天内的气温变化(早晚低,中午高,呈倒U型)。
- 细菌的生长速度(初期慢,中期快,后期趋于平缓)。
- 注意: 如果弯得太厉害(次数太高),容易出现过拟合(死记硬背数据点,反而预测不准)。
- 例子:
3. 逻辑回归 (Logistic Regression)
关键词: S形曲线、分类、概率、挂羊头卖狗肉
- 核心任务: 分类(预测类别)。(这是最大的区别!虽然名字叫回归,但干的是分类的活)
- 直观理解: 它的目的不是为了预测“具体是多少”,而是为了划出一条界限,把数据分成两拨(A类和B类)。它通过计算概率来做决定。
- 数学形状: S形曲线 (Sigmoid Function)。
- 原理: 它可以看作是“线性回归 + 一个压缩机”。先算出线性分数,再通过 Sigmoid 函数把分数压缩到 0~1 之间。
- 输出结果: 0 到 1 之间的概率(通常以 0.5 为界限,输出 0 或 1)。
- 适用场景: 二选一的问题。
- 例子:
- 这张照片是猫(1)还是狗(0)?
- 用户会点击广告(1)还是划走(0)?
- 这笔交易是欺诈(1)还是正常(0)?
- 例子:
总结对比表
| 特性 | 线性回归 (Linear) | 多项式回归 (Polynomial) | 逻辑回归 (Logistic) |
|---|---|---|---|
| 任务类型 | 回归 (Regression) | 回归 (Regression) | 分类 (Classification) |
| 输出内容 | 连续的数值 (如 100.5) | 连续的数值 (如 100.5) | 离散类别 (0 或 1) 或 概率 |
| 几何形状 | 直线 (Straight Line) | 曲线 (Curve) | S形曲线 (Sigmoid Curve) |
| 拟合能力 | 只能处理简单线性关系 | 能处理复杂的非线性关系 | 处理分类边界 |
| 典型例子 | 预测身高、房价 | 预测气温波动、病毒扩散 | 垃圾邮件检测、疾病诊断 |
一句话记住它们的区别:
想知道**“是多少”,简单的用线性,复杂的用多项式;想知道“是A还是B”**,用逻辑回归。
逻辑回归
逻辑回归虽然名字里带着“回归”,但它实际上是最经典、最基础的分类算法。
1. 核心原理:如何把“数值”变成“选择”?
逻辑回归的工作流程可以被看作是一个“三步走”的过程,它的目的就是将线性的计算结果,转化为一个二选一的决定。
-
第一步:线性打分(Linear Scoring)
- 机器首先会像做普通回归一样,根据输入特征(比如邮件里包含“中奖”的次数、发件人地址等)计算一个分数。
- 公式:z=wx+bz=wx+b
- 结果:这个分数 zz 可以是负无穷到正无穷之间的任何数值。比如,这封邮件的“垃圾分”是 5.8,或者 -3.2。
-
第二步:概率压缩(The Sigmoid Activation)
- 问题: 分数 5.8 并没有直观意义,我们需要一个概率(0% 到 100%)。
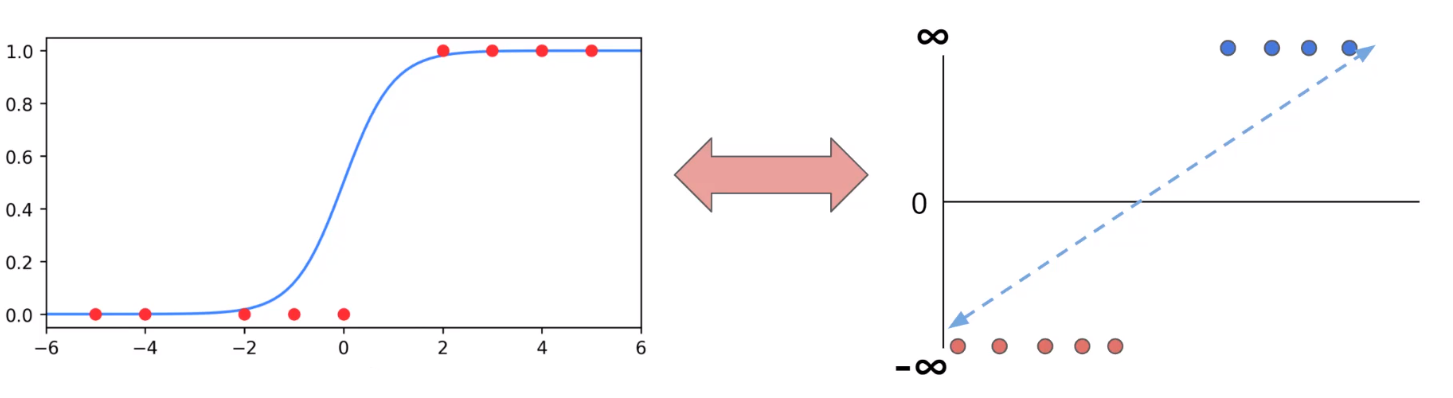
- 解决: 引入 Sigmoid 函数。这是一个 S 形的曲线函数,它能把任何数值(zz)强行压缩到 0 到 1 的区间内。
- 效果:
- 如果分数 zz 很大(比如 100),经过 Sigmoid 变换后,结果趋近于 1。
- 如果分数 zz 很小(比如 -100),结果趋近于 0。
- 如果分数 zz 是 0,结果正好是 0.5。
- 此时,输出的不再是分数,而是概率(比如:这封邮件是垃圾邮件的概率是 0.85)。
-
第三步:划定界限(Thresholding)
- 最后,我们需要做一个决断。通常默认以 0.5 为界限(阈值)。
- 决策规则:
- 概率 > 0.5 →→ 判为 类别 A (1)(是垃圾邮件)。
- 概率 < 0.5 →→ 判为 类别 B (0)(是正常邮件)。
2. 为什么叫“逻辑回归”?
这是一个历史遗留的命名误会。
- 回归的部分: 因为它的前半部分确实是在拟合一条直线(计算线性分数 zz)。
- 逻辑的部分: 因为它使用了逻辑函数(Logistic Function,即 Sigmoid)将直线弯曲成了 S 形曲线,从而实现了分类功能。
3. 典型应用场景
逻辑回归最适合解决二分类问题(Binary Classification),即答案只有“是”或“否”的场景。
A. 垃圾邮件检测 (Spam Detection)
- 输入特征: 邮件中是否包含“免费”、“发票”、“中奖”等词汇;发件人域名是否陌生。
- 预测目标: 是垃圾邮件(1) vs. 正常邮件(0)。
- 逻辑: 如果“中奖”这个词出现了,算法会给它赋予很高的权重,导致算出来的概率飙升超过 0.5,从而被拦截。
B. 广告点击率预估 (CTR Prediction)
- 输入特征: 用户的年龄、性别、历史浏览记录、广告的颜色、投放时间。
- 预测目标: 用户会点击(1) vs. 用户划走不看(0)。
- 商业价值: 这是互联网公司赚钱的核心。虽然逻辑回归输出的是分类,但平台更看重中间的那个概率值。如果模型预测用户点击的概率是 0.8,平台就会优先把这个广告推给你。
C. 金融风控 (Credit Scoring)
- 输入特征: 用户的收入、负债率、是否按时还款。
- 预测目标: 违约(1) vs. 守约(0)。
- 逻辑: 银行利用逻辑回归计算你违约的概率。如果概率过高,就会拒绝贷款申请。
D. 医疗诊断
- 输入特征: 肿瘤的大小、形状、密度。
- 预测目标: 恶性肿瘤(1) vs. 良性肿瘤(0)。
4. 逻辑回归的优缺点
- 优点(可解释性强): 它是透明的。我们可以清楚地看到每个特征的“权重”。比如模型判断你是高风险用户,我们可以直接看到是因为“负债率”这个特征的权重太高导致的。这对金融和医疗领域至关重要。
- 缺点: 它本质上是一个线性分类器。如果数据非常复杂(比如图片识别、语音识别),单纯的逻辑回归很难处理,需要更复杂的深度神经网络。
总结
逻辑回归是机器学习的入门基石。它不仅仅是一个算法,更是一种思维方式:将世界的复杂性量化为分数,再将分数转化为概率,最后根据概率做出决策。
抛开所有的公式符号(θ,α,Sigmoidθ,α,Sigmoid),用最通俗的大白话把**逻辑回归(Logistic Regression)**讲清楚。
你可以把逻辑回归看作是一个**“铁面无私的面试官”**。
它的工作只有一件事:做二选一的决定(比如:通过/淘汰,是猫/是狗,借钱/不借)。
这个面试官做决定分三步走:
第一步:算总分(心里有杆秤)
虽然最后结果只有“过”或“不过”,但在心里,面试官会先给你打个分数。
比如,银行用逻辑回归决定是否给你发信用卡。它会看你的各项资料,每一项都有一个权重(分值):
- 月薪 2 万: 这是一个加分项,权重很高,+50分。
- 名下有房: 也是加分项,+30分。
- 有过逾期记录: 这是严重的减分项,-100分。
- 年龄 18 岁: 中规中矩,+5分。
逻辑回归的第一步,就是把你所有的特征和对应的权重乘起来,算出一个总得分。
- 算出来的结果可能是 85 分,也可能是 -200 分。
这步叫:线性回归(Linear Regression)。
第二步:转概率(把分数变成百分比)
问题来了,银行系统不认识“85分”或“-200分”,它只认识概率(0% 到 100%)。而且,分数可能是无限大的,概率必须锁死在 0 到 1 之间。
这时,逻辑回归拿出了一件法宝(Sigmoid函数),你可以把它想象成一个**“超级压缩机”**:
- 它把 85分(很高的正分)压缩成 99%(极大概率会还钱)。
- 它把 -200分(很低的负分)压缩成 0.01%(极大概率会赖账)。
- 它把 0分(不好不坏)压缩成 50%(一半一半)。
不管你的原始分数多离谱,经过这个压缩机,出来的永远是 0% 到 100% 之间的一个数字。
这步叫:激活函数(Sigmoid Activation)。
第三步:一锤定音(划红线)
现在手里拿到了概率(比如算出你是 0.8,也就是 80% 的概率是好人)。但机器最终只能输出“发卡”或者“不发卡”。
于是,逻辑回归画了一条红线(通常是 0.5,也就是 50%):
- 概率 > 50%: 恭喜,发卡(分类为 1)。
- 概率 < 50%: 抱歉,拒单(分类为 0)。
这步叫:决策边界(Decision Boundary)。
总结:它和“线性回归”有什么不同?
想象你在做一个悬崖边的测试:
-
线性回归(直男思维):
它会告诉你:“你现在的安全得分是 5000 分,或者 -3000 分。”
它只会画直线,甚至会画出地球外去,不告诉你到底死没死。 -
逻辑回归(分类思维):
它会告诉你:“不管你得分多少,我只告诉你,你掉下去的概率是 99%。”
它会把直线掰弯成一个 S 形,最后只告诉你结果:死,还是没死。
一句话总结逻辑回归:
先打分(算数值),再压缩(变概率),最后划线(定结果)。
这里记住,逻辑回归套逻辑在深度神经网络中会再次得到应用,这也是深度神经网络的基础.
逻辑回归与激活函数
1. 激活函数 (Activation Function) —— “神经元的开关”
在神经网络或机器学习模型中,如果我们只有线性的计算(加法和乘法),无论叠加多少层,模型最终只能画直线。为了解决复杂问题(比如识别图片、分类),我们需要引入非线性因素。
激活函数的作用:
它位于神经元的输出端,负责对输入信号进行“加工”和“转换”,决定这个神经元是否被激活,或者以此什么样的方式输出。
- 如果没有它: 输入 z=wx+bz=wx+b。输出就是 zz。模型是线性的,很弱。
- 有了它: 输入 z=wx+bz=wx+b。输出 a=f(z)a=f(z)。模型变得灵活,可以拟合各种曲线。
常见的激活函数家族:
- Sigmoid (本次的主角)
- Tanh (Sigmoid 的改进版,输出范围是 -1 到 1)
- ReLU (深度学习中最常用的,只有正数部分)
- Softmax (用于多分类)
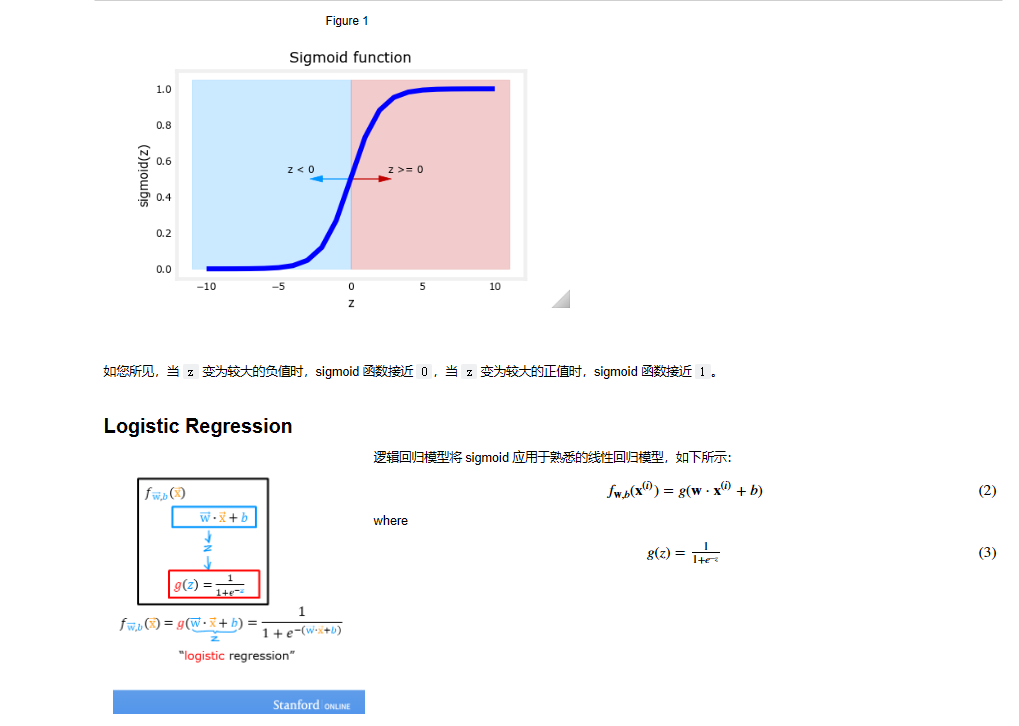
2. Sigmoid 函数 —— “概率压缩机”
Sigmoid 是最经典的一种激活函数。它的数学公式是 S(x)=11+e−xS(x)=1+e−x1。
它的两大特性:
- S形曲线: 它的图像呈现“S”形。
- 数值压缩: 它能把负无穷到正无穷的任意实数,强行压缩映射到 (0, 1) 的区间内。
- 输入很大很大 →→ 输出接近 1。
- 输入很小很小 →→ 输出接近 0。
- 输入是 0 →→ 输出正好是 0.5。
为什么它重要?
因为 概率 的范围正好也是 0 到 1。Sigmoid 天然适合把计算机算出来的枯燥分数,转化成人类能理解的概率值。
3. 逻辑回归 (Logistic Regression) —— “组装好的成品”
逻辑回归本质上就是一个**“线性回归 + Sigmoid 激活函数”的组合体。它可以被看作是最简单的、只有一个神经元的神经网络**。
工作流程(三部曲):
-
线性计算 (Linear Step):
先综合考虑所有特征(权重 ww 和偏差 bb),算出一个线性得分 zz。
z=w1x1+w2x2+...+bz=w1x1+w2x2+...+b
(此时,zz 可以是任意数值,比如 500 或 -20) -
激活 (Activation Step - 使用 Sigmoid):
将得分 zz 扔进 Sigmoid 函数里。
a=Sigmoid(z)a=Sigmoid(z)
(此时,输出变成了 0~1 之间的概率,比如 0.98) -
决策 (Decision Step):
如果 a>0.5a>0.5,预测为类别 1;否则预测为类别 0。
结论:
逻辑回归之所以叫“逻辑”回归,正是因为它使用了 Logistic 函数(也就是 Sigmoid 函数)作为它的核心组件(激活函数)。
4. 深度扩展:Sigmoid 的衰落与现状
虽然 Sigmoid 是逻辑回归的灵魂,但在现代**深度学习(Deep Learning)**的大型神经网络中,Sigmoid 已经不再受宠了(除了在输出层做二分类)。
为什么大家不再喜欢在中间层用 Sigmoid?
- 梯度消失 (Vanishing Gradient): 当输入值很大或很小时,Sigmoid 曲线非常平缓,斜率(梯度)几乎为 0。这会导致反向传播时,误差传不回去,深层网络学不动了。
- 非零中心化: 输出恒为正,收敛慢。
现在的霸主:ReLU
现在的深度神经网络中间层大多使用 ReLU (Rectified Linear Unit)。它非常简单(x>0x>0 时输出 xx,否则输出 00),计算快,且没有梯度消失问题。
总结三者关系:
- 逻辑回归 是一个经典的分类算法。
- 为了实现分类并输出概率,逻辑回归必须使用 Sigmoid。
- Sigmoid 充当了逻辑回归中的 激活函数 角色,负责引入非线性并将数值转化为概率。
逻辑回归的数学推导
逻辑回归的数学推导非常经典,它完美展示了机器学习中 “建模 →→ 定义损失函数 →→ 优化求解” 的标准流程。
推导的核心在于:为什么损失函数要用对数损失(Log Loss),而不是线性回归用的平方损失(MSE)?以及最后的梯度更新公式是如何得来的?
我们分三步来推导。
第一步:建立模型(Hypothesis)
目标:我们要寻找一个函数 hθ(x),输入特征 x,输出属于类别 1 的概率 P(y=1∣x)。
-
线性部分:
首先计算线性得分,假设权重向量为 θθ(包含了 ww 和偏置 bb),特征向量为 xx:
z=θTx=w1x1+w2x2+...+bz=θTx=w1x1+w2x2+...+b -
引入 Sigmoid:
为了将 zz 映射到 (0,1)(0,1) 区间,我们使用 Sigmoid 函数 g(z)g(z):
g(z)=11+e−zg(z)=1+e−z1 -
最终假设函数:
hθ(x)=g(θTx)=11+e−θTxhθ(x)=g(θTx)=1+e−θTx1
概率解释:
- P(y=1∣x;θ)=hθ(x)P(y=1∣x;θ)=hθ(x)
- P(y=0∣x;θ)=1−hθ(x)P(y=0∣x;θ)=1−hθ(x)
第二步:定义损失函数(Cost Function)
这是推导中最关键的一步。
为什么不用平方误差(MSE)?
如果我们像线性回归那样使用 J(θ)=12∑(hθ(x)−y)2J(θ)=21∑(hθ(x)−y)2,因为引入了 Sigmoid 这个非线性函数,导致 J(θ)J(θ) 变成一个非凸函数(Non-convex)。它的图像像一个波浪山谷,有无数个局部最低点,梯度下降法很容易卡住,找不到全局最优解。
正解:最大似然估计(MLE)
我们要找到一组 θθ,使得模型预测出来的概率分布最接近真实数据的分布。
-
合并概率表达式:
我们将 y=1y=1 和 y=0y=0 的两种情况写成一个公式(伯努利分布):
P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−yP(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y- 当 y=1y=1 时,结果是 hθ(x)hθ(x)。
- 当 y=0y=0 时,结果是 1−hθ(x)1−hθ(x)。
-
似然函数(Likelihood):
假设有 mm 个样本,且样本独立,总似然 L(θ)L(θ) 就是所有样本概率的乘积:
L(θ)=∏i=1mP(y(i)∣x(i);θ)=∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)L(θ)=∏i=1mP(y(i)∣x(i);θ)=∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i) -
对数似然(Log-Likelihood):
为了方便计算(变乘积为求和),取对数:
l(θ)=logL(θ)=∑i=1m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]l(θ)=logL(θ)=∑i=1m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))] -
损失函数(Cost Function):
我们的目标是最大化似然函数 L(θ)L(θ)。在机器学习中,我们习惯做最小化任务。所以,我们对 l(θ)l(θ) 取负数,并除以 mm(求平均),这就得到了著名的交叉熵损失函数(Cross Entropy Loss):J(θ)=−1ml(θ)=−1m∑i=1m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]J(θ)=−m1l(θ)=−m1∑i=1m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
这个函数是凸函数(Convex),保证了梯度下降能找到全局最优解。
第三步:梯度下降求导(Gradient Descent)
我们要通过最小化 J(θ)J(θ) 来更新参数 θθ。这需要计算 J(θ)J(θ) 对 θjθj 的偏导数。
准备工作:Sigmoid 函数的求导技巧
Sigmoid 函数 g(z)g(z) 有一个非常漂亮的导数性质:
g′(z)=g(z)(1−g(z))g′(z)=g(z)(1−g(z))
(这一步是微积分计算,略去中间过程,记住结论即可)
开始求导链式法则:
假设只有一个样本 (x,y)(x,y),为了简化,我们省略求和符号和 −1m−m1,只看损失部分的核心:
Cost=−[ylogh+(1−y)log(1−h)]Cost=−[ylogh+(1−y)log(1−h)]
其中 h=g(z)h=g(z),z=θTxz=θTx。
我们要算 ∂Cost∂θj∂θj∂Cost,根据链式法则:
∂Cost∂θj=∂Cost∂h⋅∂h∂z⋅∂z∂θj∂θj∂Cost=∂h∂Cost⋅∂z∂h⋅∂θj∂z
分步计算:
-
第一项 ∂Cost∂h∂h∂Cost:
∂∂h[−ylogh−(1−y)log(1−h)]=−yh+1−y1−h=h−yh(1−h)∂h∂[−ylogh−(1−y)log(1−h)]=−hy+1−h1−y=h(1−h)h−y -
第二项 ∂h∂z∂z∂h (Sigmoid 的导数):
h(1−h)h(1−h) -
第三项 ∂z∂θj∂θj∂z:
因为 z=θ0x0+...+θjxj+...z=θ0x0+...+θjxj+...,所以:
xjxj
三项相乘(见证奇迹的时刻):
∂Cost∂θj=(h−yh(1−h))⋅(h(1−h))⋅xj∂θj∂Cost=(h(1−h)h−y)⋅(h(1−h))⋅xj
分母 h(1−h)h(1−h) 和分子 h(1−h)h(1−h) 直接抵消了!
最终梯度公式:
∂J(θ)∂θj=1m∑i=1m(hθ(x(i))−y(i))xj(i)∂θj∂J(θ)=m1∑i=1m(hθ(x(i))−y(i))xj(i)
总结
逻辑回归的推导结论非常有意思:
虽然它的假设函数变了(加了 Sigmoid),损失函数变了(用了交叉熵),但最终算出来的梯度更新公式,竟然和线性回归一模一样:
θj:=θj−α1m∑i=1m(hθ(x(i))−y(i))xj(i)θj:=θj−αm1∑i=1m(hθ(x(i))−y(i))xj(i)
这里的 hθ(x)hθ(x) 是唯一的区别:
- 在线性回归中,h(x)=θTxh(x)=θTx
- 在逻辑回归中,h(x)=11+e−θTxh(x)=1+e−θTx1
这个巧合是因为逻辑回归属于**广义线性模型(GLM)**家族,且使用了指数族分布的标准形式推导,体现了数学上的优雅。
逻辑回归的案例应用
为了让你清晰地看到数学推导如何转化为代码,我们将使用经典的**乳腺癌数据集(Breast Cancer Dataset)**来进行二分类预测(良性 vs 恶性)。
在这个代码中,我将实现两个部分:
- 手写版(From Scratch):完全基于上文推导的梯度下降公式 (w:=w−α⋅dWw:=w−α⋅dW) 实现。
- 工程版(Sklearn):调用
sklearn库的标准接口。
案例背景:乳腺癌诊断
- 输入 (XX):肿瘤的半径、纹理、平滑度等30个特征。
- 输出 (yy):0 代表良性 (Benign),1 代表恶性 (Malignant)。
Python 代码实现
请确保你的环境中安装了 numpy 和 scikit-learn。
Python
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# ==========================================
# 第一部分:基于数学推导的手写逻辑回归
# ==========================================
class MyLogisticRegression:
def __init__(self, learning_rate=0.01, n_iterations=1000):
self.lr = learning_rate
self.n_iterations = n_iterations
self.weights = None
self.bias = None
self.losses = []
# 1. Sigmoid 激活函数
def _sigmoid(self, z):
return 1 / (1 + np.exp(-z))
# 2. 训练模型 (基于梯度下降推导)
def fit(self, X, y):
n_samples, n_features = X.shape
# 初始化参数 (权重设为0)
self.weights = np.zeros(n_features)
self.bias = 0
# 梯度下降迭代
for i in range(self.n_iterations):
# A. 线性计算 z = w*x + b
linear_model = np.dot(X, self.weights) + self.bias
# B. 激活预测 h = sigmoid(z)
y_predicted = self._sigmoid(linear_model)
# C. 计算梯度 (基于推导公式)
# dw = (1/m) * X.T * (h - y)
dw = (1 / n_samples) * np.dot(X.T, (y_predicted - y))
# db = (1/m) * sum(h - y)
db = (1 / n_samples) * np.sum(y_predicted - y)
# D. 更新参数
self.weights -= self.lr * dw
self.bias -= self.lr * db
# (可选) 记录损失函数值用于观察
# 这里的损失是 Log Loss (交叉熵)
# 加 1e-15 是为了防止 log(0) 报错
loss = -np.mean(y * np.log(y_predicted + 1e-15) + (1 - y) * np.log(1 - y_predicted + 1e-15))
self.losses.append(loss)
if i % 100 == 0:
print(f"迭代次数 {i}: Loss = {loss:.4f}")
# 3. 预测类别
def predict(self, X):
linear_model = np.dot(X, self.weights) + self.bias
y_predicted = self._sigmoid(linear_model)
# 如果概率 > 0.5 判为 1,否则为 0
y_predicted_cls = [1 if i > 0.5 else 0 for i in y_predicted]
return np.array(y_predicted_cls)
# ==========================================
# 数据准备与预处理
# ==========================================
# 1. 加载数据
data = datasets.load_breast_cancer()
X, y = data.data, data.target
# 2. 划分训练集和测试集 (80% 训练, 20% 测试)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234)
# 3. 特征缩放 (Standardization)
# 【非常重要】逻辑回归基于梯度下降,如果不缩放数据,收敛会非常慢甚至失败
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("-" * 30)
print(f"训练集样本数: {X_train.shape[0]}, 特征数: {X_train.shape[1]}")
print("-" * 30)
# ==========================================
# 运行对比
# ==========================================
# --- 1. 运行手写模型 ---
print("\n>>> 开始训练手写模型 (Gradient Descent)...")
model_scratch = MyLogisticRegression(learning_rate=0.1, n_iterations=1000)
model_scratch.fit(X_train_scaled, y_train)
predictions_scratch = model_scratch.predict(X_test_scaled)
acc_scratch = accuracy_score(y_test, predictions_scratch)
# --- 2. 运行 Sklearn 模型 ---
print("\n>>> 开始训练 Sklearn 模型...")
# C是正则化强度的倒数,这里设大一点以减少正则化影响,使其更接近原生推导
model_sklearn = LogisticRegression(C=1000, random_state=1234)
model_sklearn.fit(X_train_scaled, y_train)
predictions_sklearn = model_sklearn.predict(X_test_scaled)
acc_sklearn = accuracy_score(y_test, predictions_sklearn)
# ==========================================
# 结果对比
# ==========================================
print("\n" + "="*30)
print("最终结果对比")
print("="*30)
print(f"手写模型准确率: {acc_scratch * 100:.2f}%")
print(f"Sklearn 模型准确率: {acc_sklearn * 100:.2f}%")
print("\n模型参数对比 (前5个特征的权重):")
print(f"手写模型 Weights: {model_scratch.weights[:5]}")
print(f"Sklearn 模型 Weights: {model_sklearn.coef_[0][:5]}")代码核心解析
1. 关于手写实现 (MyLogisticRegression)
- 核心映射:
linear_model = np.dot(X, self.weights) + self.bias对应公式 z=θTxz=θTx。dw = (1 / n_samples) * np.dot(X.T, (y_predicted - y))这行代码直接对应了推导出的梯度公式 ∂J∂θ=1mXT(h−y)∂θ∂J=m1XT(h−y)。这是**向量化(Vectorization)**写法,比用for循环遍历样本快得多。
- 为什么要 Feature Scaling?
- 代码中使用了
StandardScaler。如果不做这一步,不同特征的取值范围差异巨大(例如半径是10-20,而面积是500-1000),会导致梯度下降走“之”字形路线,难以收敛。
- 代码中使用了
2. 关于 Sklearn 实现
- Sklearn 的
LogisticRegression默认使用更高级的优化算法(如lbfgs),而不是简单的梯度下降。 - 它默认带有 L2 正则化(参数
C)。 - 因此,你会发现 Sklearn 运行速度极快,且结果通常比简单的手写版更稳定。但在上述代码中,我们的手写版也能达到非常接近的准确率(通常都在 95% 以上)。
结果解读
运行上述代码,你通常会看到类似这样的结果:
- 准确率:两者都会很高,通常在 96% - 98% 之间。
- 权重差异:由于优化算法不同(SGD vs L-BFGS)以及正则化的存在,具体的系数值(Weights)可能会有细微差别,但正负方向通常是一致的(代表该特征对结果是正向影响还是负向影响)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)