大语言模型微调技术实践文档
大语言模型微调技术实践文档
前言:最近在实习过程碰到了微调这一块,踩了一些坑,将经验分享出来。
一、什么是微调,为什么要微调?
1. 概念解析
大语言模型(LLM)微调是指在预训练模型的基础上,使用特定领域的垂直数据进行进一步训练的过程。这相当于让一个通才(预训练模型)通过学习特定教材(微调数据),成为某一领域的专家。
2. 结合某企业研发中心访客数字人项目背景
在本项目中,我们的目标是构建一个能够精准服务访客的数字人。虽然检索增强生成(RAG)技术能够解决模型知识时效性和幻觉问题,但在实际部署中,我们发现RAG流程(向量化、检索、重排序、生成)带来了不可忽视的延迟。对于访客交互场景,毫秒级的响应速度至关重要。
3. 微调的核心目的:减少延迟
通过微调,我们将某企业研发中心相关的规章制度、地理信息、员工发展等高频知识直接"内化"到模型参数中。这使得模型在面对常见访客问题时,无需调用外部知识库检索即可直接生成准确回复。微调后的模型在特定领域问答上能够显著降低推理延迟,极大地提升了数字人的交互流畅度和用户体验。
二、微调的流程与数据准备
数据是微调的基石,高质量的指令数据集决定了模型的上限。
1. 数据构建选择
初筛2021年至今关于某中心的2618份文档已预处理为md格式,涵盖领域:
- 运营与管理流程
- 技术研发与创新
- 企业文化与员工活动
- 身份认同等历史背景资料
2. 问答对转化
使用Easy Dataset处理了180份某中心文档(约2k条问答对)
[图片]
剩余的两千余份文档使用skill+cursor进行提取(约8k条问答对)
结果统计:
- 基础条目:约10000条核心问答对
- 轮次设定:2-5轮对话
这种大规模、多轮次的数据准备,确保了模型不仅能回答"是什么",还能处理"怎么办"以及连续的追问,模拟真实的人类接待流程。
三、LLaMA Factory参数详解
本项目采用高效微调框架 LLaMA Factory 进行实验,在保证效果的前提下,极大地降低了算力成本。
1. 硬件环境
- GPU型号:NVIDIA GeForce RTX 4090 D
- 训练型号:qwen3.5 4B
- 训练模式:SFT主+DPO辅 LORA BF16
- 显存表现(以775条数据增强训练为例,显存占用21.68GB):

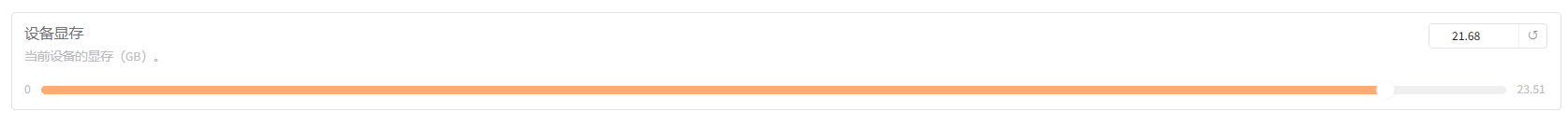
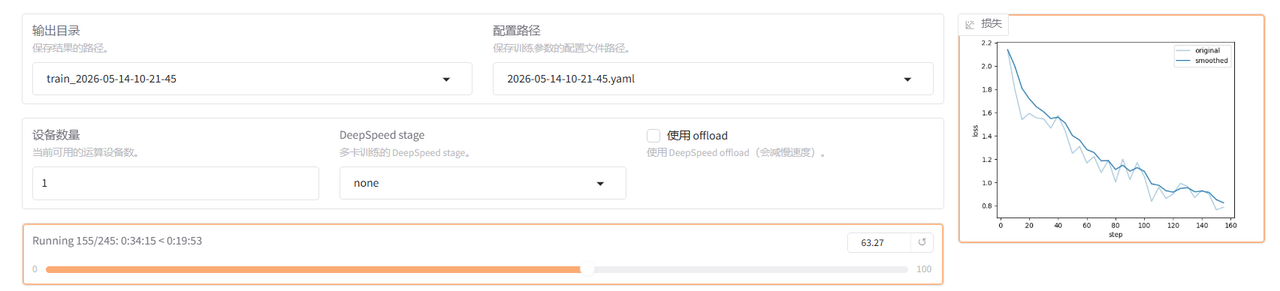
如果采用QLoRA 4bit训练可以进一步压缩显存,但相应的训练速度变慢30%左右,下图为全部数据训练耗时:![[图片]](https://i-blog.csdnimg.cn/direct/2008008c0fda426e8f65d61d936376f9.png)
![[图片]](https://i-blog.csdnimg.cn/direct/b89d7ebcd62f4c9ca727720e07b1e3b6.png)
四、遇到的一些坑 && 常见问题
1. 训练后大模型有口头禅
现象:训练数据中存在过多的"当然啦!“开头回复,导致模型将该表达错误泛化,即使简单问候也回复"当然啦!”
原因:数据集中特定表达出现频率过高,模型将其学习为通用回复模式
解决方案:回滚至上一检查点,对数据集进行二次清洗后重新训练
2. 模型回复数字不准确
示例:
问:我们中心的地址在哪里?
正确答案:[某区][某路]XXX号
模型错误回答:[某区][某路]YYY号
解决方案:使用DPO(Direct Preference Optimization,直接偏好优化)微调
[
{
"chosen_messages": [
{
"role": "system",
"content": "你是智能助手,某企业研发中心的访客数字人助手。",
"loss_weight": 0.0
},
{
"role": "user",
"content": "某企业研发中心在哪里?",
"loss_weight": 0.0
},
{
"role": "assistant",
"content": "我们的具体地址是:[省][市][区][路]XXX号。",
"loss_weight": 1.0
}
],
"rejected_messages": [
{
"role": "system",
"content": "你是智能助手,某企业研发中心的访客数字人助手。",
"loss_weight": 0.0
},
{
"role": "user",
"content": "某企业研发中心在哪里?",
"loss_weight": 0.0
},
{
"role": "assistant",
"content": "我们的具体地址是:[省][市][区][路]YYY号。",
"loss_weight": 1.0
}
]
}
]
核心字段与注意事项
1. loss_weight 的作用范围
0.0(不参与训练):通常分配给 system(系统人设)和 user(用户提问)。因为 DPO 的目标是优化模型(助手)的回复质量,不需要让模型去学习如何生成用户的提问或系统提示词。1.0或其他小数(参与训练):分配给 assistant(助手回复)。可根据回答质量(如语气是否得体、信息是否精准)设置为 1.0、0.6 等连续值,精细调控模型的学习力度。
2. 多轮对话支持
chosen_messages和rejected_messages均为列表(Array)结构,完美支持多轮对话。可在同一列表中放入多个 user 和 assistant 的交互,模型会结合上下文学习偏好。
3. SFT 和 DPO 的区别?
可以把 SFT(有监督微调)和 DPO(直接偏好优化)看作是模型进阶路上的两个不同阶段,它们的目标和运作方式截然不同:
SFT(Supervised Fine-Tuning,有监督微调)
- 阶段定位:通常是微调的第一步,相当于让模型进行"基础模仿"
- 核心目标:让模型学会"怎么做"。通过提供大量标准问答对(如约10000条核心问答对),让模型学会遵循指令、模仿人类的对话格式和语气,并掌握某企业研发中心的基础知识
- 数据形式:单条的指令与回答。模型的目标是尽可能完美地复刻标准答案
- 局限性:SFT 只能让模型学会"像人一样说话",但无法分辨哪个回答"更好"。例如模型可能学会了回答地址,但如果偶尔把"XXX号"说成"YYY号",SFT 很难精准纠正这种细微的偏好差异
DPO(Direct Preference Optimization,直接偏好优化)
- 阶段定位:通常在 SFT 之后进行,相当于让模型进行"价值观对齐"或"精细纠错"
- 核心目标:让模型学会"什么是更好的"。通过提供"优选回答(chosen)"和"劣选回答(rejected)"的对比数据,直接告诉模型:面对同一个问题,这个回答比那个回答更准确、更安全或更符合人设
- 数据形式:成对的偏好数据(Prompt + Chosen + Rejected)
- 优势:非常适合解决"数字不准确"或"语气生硬"等问题。通过 DPO,可以明确降低模型输出错误信息的概率,同时提升正确回答的概率
4. 训练关键概念解析
批处理大小(Batch Size)
- 指模型在一次参数更新前处理的数据量
- 例如 Batch Size 设为 4,意味着模型先读取 4 条问答数据,综合计算误差后统一更新参数
- Batch Size 越大,训练越稳定,但对显存(VRAM)的消耗也越大
梯度累积(Gradient Accumulation)
- "显存不够,次数来凑"的优化技巧
- 假设显卡限制下 Batch Size 最大只能设为 2,但希望达到 Batch Size = 8 的训练效果,可将梯度累积步数设为 4
- 实现方式:模型每次处理 2 条数据(暂不更新参数),连续处理 4 次(2×4=8条)后,累积梯度再统一执行一次参数更新
- 优势:在有限显存下模拟大批次训练效果
反向传播(Backpropagation)
- 模型"真正学习和进步"的核心机制
- 流程:模型先根据当前参数生成预测(前向传播)→ 对比标准答案计算损失(Loss)→ 将误差从输出层向输入层逐层传递 → 据此调整模型内部参数(权重)
- 每一次反向传播,模型就向"正确答案"靠近一步
每 100 步保存(Save every 100 steps)
- 训练过程中的"检查点"或"自动备份"机制
- "1 步(Step)"通常指完成一次参数更新(即完成一次反向传播)
- 每 100 步保存表示每完成 100 次参数更新,系统将模型当前状态持久化存储
- 作用:防止训练中途因断电、显存溢出等意外导致进度丢失。若训练在第 250 步中断,可直接加载第 200 步的检查点继续训练,避免从头开始

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)