计算与分析-深度学习
·
正则化在深度神经网络训练的作用,并说明L1和L2正则化特点

激活函数的作用,sigmoid和ReLU的优缺点
激活函数的作用:引入非线性能力,使模型可以学习更复杂映射关系
sigmoid函数:优点:输出范围在 (0,1),适合处理概率类问题或二分类输出层;连续可导,可以反向传播更新参数
缺点:输入绝对值较大时,梯度趋近于 0,导致深层网络训练困难;因为非0中心化后层神经元输入偏向正数,导致梯度方向单一(如全为正或负),影响收敛效率;含指数运算,相比其他函数计算更耗时
ReLU函数:
优点:
- 缓解梯度消失:输入正数时梯度为 1,避免深层网络训练中的梯度衰减问题。
- 计算高效:仅需判断输入是否大于 0,无复杂运算,加速训练和推理。
- 稀疏性诱导:输入负数时输出为 0,使部分神经元 “休眠”,增强模型鲁棒性
缺点:
- 神经元死亡问题:输入负数时梯度为 0,若参数更新不当,神经元可能永久不激活(如输入始终为负)。
- 输出非零中心化:与 sigmoid 类似,输出全为正数,可能导致后层输入偏移。
如何判断过拟合和欠拟合,解决方案及原理
一、判断方法
- 指标对比:
- 过拟合:训练集损失低、测试集损失高(模型 “记忆” 噪声,泛化差)。
- 欠拟合:训练集和测试集损失均高(模型未捕获数据基本规律)。
- 可视化:
- 过拟合:模型在训练数据上拟合曲线过于复杂(如高次多项式拟合)。
- 欠拟合:拟合曲线过于简单,无法覆盖数据分布。


什么叫做迁移学习,有几种,分别对应的应用场景(目的及方法)
迁移学习的定义
迁移学习指将在源任务上训练好的模型 / 知识,应用于目标任务的学习过程,旨在利用已有知识提升新任务的学习效率或性能。
迁移学习的类型、应用场景及方法
1. 基于数据的迁移学习
- 目的:解决目标任务数据稀缺问题,利用源任务的大量数据。
- 方法:
- 数据增强:对目标任务数据做旋转、缩放等变换,扩充样本量。
- 领域自适应:通过对齐源域与目标域的数据分布(如对抗训练),减少域差异。
- 场景:医疗影像分析(目标任务数据少,源任务为自然图像)、小语种 NLP。
2. 基于模型的迁移学习
- 目的:复用预训练模型的特征提取能力,避免从头训练。
- 方法:
- 微调(Fine-tuning):冻结预训练模型底层参数,仅训练顶层分类器(如 BERT 用于情感分析)。
- 特征提取:直接使用预训练模型的中间层输出作为特征,输入新模型。
- 场景:
- 计算机视觉:ImageNet 预训练的 ResNet 用于目标检测。
- NLP:GPT 预训练模型用于文本生成任务。
简要说明Bagging 和 Boosting的区别
Boosting:个体学习器存在强依赖关系;串行生成;每次调整训练数据的样本分布
Bagging:个体学习器不存在强依赖关系;并行化生成;自助采样法
给出梯度爆炸和梯度消失定义及解决方案
梯度爆炸:反向传播中梯度值持续增大,导致参数更新幅度过大,模型无法收敛
解决方法:梯度截断;权重初始化优化;正则化与参数约束
梯度消失:反向传播中梯度值逐层衰减至接近 0,导致底层参数无法更新,模型性能停滞
解决方法:更换激活函数;门控机制;残差连接;批量归一化
在训练用于图像分类的深度CNN时
1 如何构建训练集、验证集和测试集
2 不同类别数量分布不均匀,会影响网络识别率吗,有影响的话如何处理
3 如何判断深度CNN过拟合,处理方法有哪些?
1. 构建训练集、验证集和测试集
- 划分逻辑:
- 训练集:约 70%-80%,用于模型参数学习。
- 验证集:约 10%-15%,用于调参(如学习率、正则化强度)。
- 测试集:约 10%-15%,独立评估模型泛化能力,仅在最终阶段使用。
2. 类别不平衡对识别率的影响及处理方法
- 影响:模型倾向于预测样本多的类别,少数类识别率显著下降。
- 处理方法:
- 数据层面:
- 过采样:对少数类复制、旋转、缩放等增强(如 SMOTE 算法)。
- 欠采样:随机删除多数类样本(需避免信息丢失)。
- 模型层面:
- 类别加权损失:给少数类分配更高权重(如交叉熵损失乘权重系数)。
- 焦点损失(Focal Loss):降低易分类样本的权重,聚焦难分类的少数类。
- 数据层面:
3. 过拟合判断及处理方法
- 判断依据:
- 训练集准确率持续上升,验证集准确率停滞或下降。
- 训练集损失低,验证集损失显著更高。
- 处理方法:
- 数据增强:旋转、翻转、裁剪、加噪声等扩充样本多样性。
- 正则化:
- L2 正则化:抑制大参数,避免模型过度复杂。
- Dropout:训练时随机丢弃神经元,减少对特定特征的依赖。
- 早停法:监控验证集损失,若连续若干轮不下降则停止训练。
- 集成学习:组合多个模型(如不同初始化的网络),降低单一模型过拟合风险。
卷积神经网络的层次结构及各部分的作用
1. 输入层(Input Layer)
- 作用:接收原始图像数据(如尺寸为 H×W×C 的矩阵,C 为通道数)。
- 示例:输入 224×224×3 的 RGB 图像。
2. 卷积层(Convolutional Layer)
- 核心作用:通过卷积核(滤波器)提取图像局部特征(如边缘、纹理、形状)。
- 关键参数:
- 卷积核大小(如 3×3、5×5):决定提取特征的尺度。
- 步长(Stride):控制卷积核移动步幅,影响输出特征图尺寸。
- 填充(Padding):保持特征图尺寸(如 Same Padding)。
- 输出:特征图(Feature Map),深度由卷积核数量决定。
3. 激活函数层(Activation Layer)
- 作用:为网络引入非线性能力,避免多层线性运算等价于单层的问题。
- 常见类型:
- ReLU:解决梯度消失问题,计算高效(输出 x>0 时为 x,否则为 0)。
- Sigmoid/Softmax:用于二分类或多分类的输出层。
4. 池化层(Pooling Layer)
- 作用:
- 降维:减小特征图尺寸,降低计算量。
- 增强鲁棒性:通过下采样(如最大池化、平均池化)保留关键特征。
- 示例:2×2 最大池化将特征图尺寸减半,取区域内最大值。
5. 批量归一化层(BatchNorm Layer,BN)
- 作用:对各层输入归一化(均值为 0,方差为 1),稳定训练过程,加速收敛。
- 原理:减少 “内部协变量偏移”,允许更大学习率,缓解梯度消失。
6. 全连接层(Fully Connected Layer,FC)
- 作用:整合全局特征,用于最终分类或回归。
- 特点:神经元与前一层所有输出相连,参数量大(如 ResNet 最后一层 FC 连接 1000 个类别)。
7. 输出层(Output Layer)
- 作用:根据任务输出预测结果。
- 常见类型:
- 分类任务:Softmax 层输出各类别概率。
- 回归任务:线性层直接输出数值。
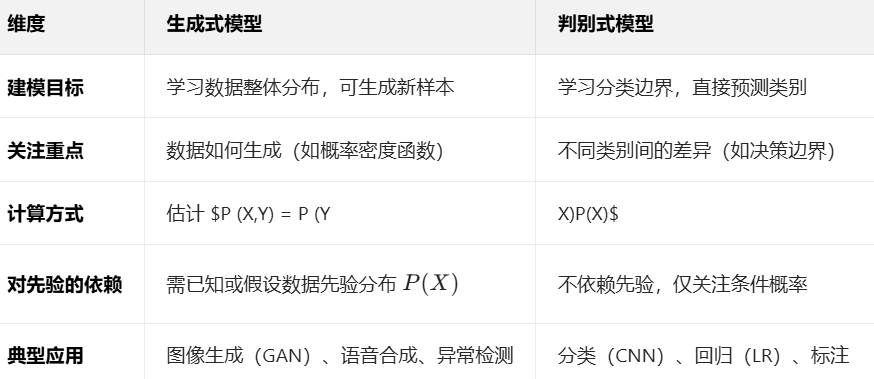
简要说明生成式模型和判别式模型的区别,有哪些?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)