港科大提出KGPFN:让知识图谱基础模型真正学会“看上下文”

01|相关背景
知识图谱基础模型的目标,是让一个模型能够迁移到没见过的新图谱、新实体,甚至新关系上进行推理。
过去的知识图谱基础模型通常更强调一种能力:
从大量图谱中学习可迁移的关系结构规律。
但作者指出,这还不够。
真正的基础模型不应该只会“记住通用规律”,还应该能在推理时根据当前任务给出的上下文进行适应。也就是说,模型不仅要知道某类关系通常怎么出现,还要能判断:
- 这个规律在当前图谱里是否成立?
- 当前查询附近的结构是否支持这个规律?
- 同一个关系在大量实例中呈现出怎样的整体模式?
- 当局部证据和通用规律冲突时,模型应该相信哪一个?
为了解决这个问题,Gao 等作者提出了 KGPFN。
它把 Prior-data Fitted Network(PFN) 的上下文学习思想引入知识图谱推理中,让模型在不微调参数的情况下,直接利用推理时提供的结构化上下文完成适应。
一句话概括:
KGPFN 想解决的不是“模型能不能学到关系规律”,而是“模型能不能在新图谱里根据上下文临场判断这些规律该怎么用”。
02|问题背景:KG 基础模型缺了哪块拼图
知识图谱由大量三元组构成,例如:
(人物, 出生于, 城市)
(城市, 位于, 国家)
(人物, 国籍, 国家)
知识图谱推理中的典型任务是链接预测。
给定一个不完整三元组:
(h, r, ?)
模型需要从候选实体中预测最可能的尾实体 t。
例如:
(Demis Hassabis, nationality, ?)
模型需要判断答案更可能是 UK、USA,还是其他国家。
传统知识图谱嵌入方法往往依赖特定图谱中的实体表示,因此当模型面对一个新图谱时,通常需要重新训练或微调。知识图谱基础模型的出现,就是为了让模型获得更强的跨图谱迁移能力。
不过,作者认为,现有知识图谱基础模型存在一个明显短板:
它们更擅长学习“通用关系模式”,但不够擅长利用“推理时上下文”。
这会带来一个问题:
模型可能会把某个常见结构模式过度泛化。
比如,很多情况下:
某人出生于某城市
某城市位于某国家
可以推断:
某人的国籍是该国家
但这个规律并不总是成立。
一个人出生在某个国家,并不意味着其国籍一定是这个国家。此时,工作地点、教育背景、职业经历等局部关系可能会改变最终判断。
所以,知识图谱推理不能只依赖抽象规律,还需要看具体上下文。
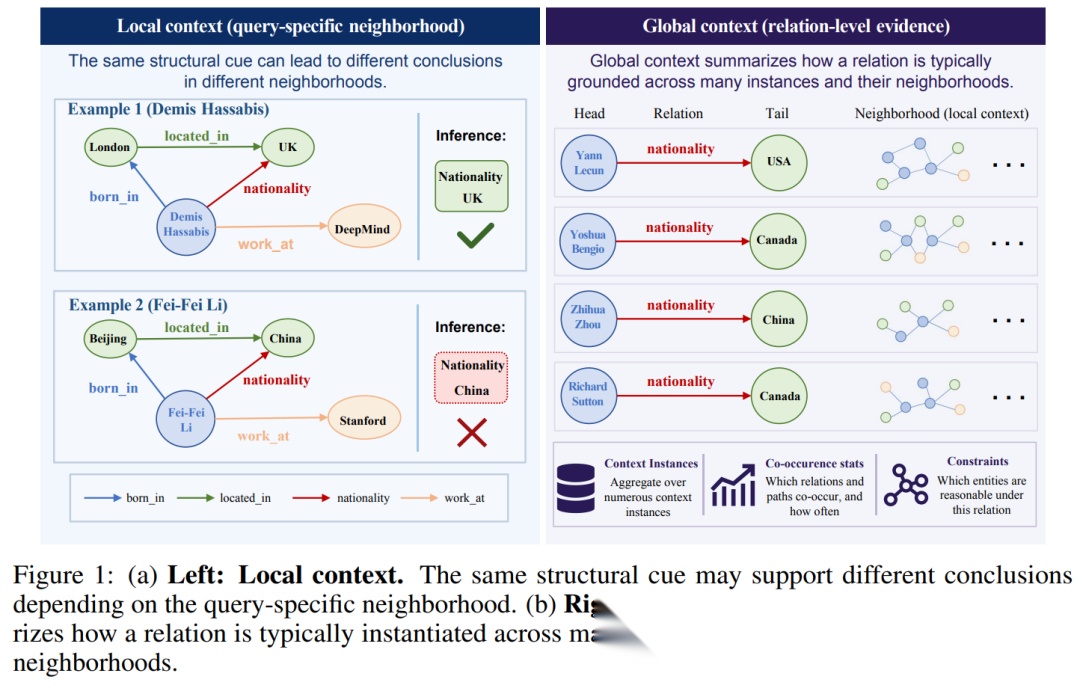
03|核心洞察:知识图谱里的上下文不是一段文本
在大语言模型中,上下文通常是一段文本,模型通过提示词或示例来理解任务。
但知识图谱里的上下文完全不同。
作者强调,知识图谱上下文具有两个特点:
结构化
异质化
它不是一段线性文本,而是由实体、关系、路径、子图、正负样本共同组成的复杂结构。
因此,作者把知识图谱上下文拆成两个互补部分:
· 局部上下文 Local Context
局部上下文指的是当前查询实体附近的子图结构。
例如,在预测某个人的国籍时,模型不仅要看:
出生地 → 所在国家
还可能要看:
工作机构
居住地
教育经历
合作关系
所属组织
这些局部结构能帮助模型判断:
某个通用规律在当前实体身上是否可靠。
换句话说,局部上下文负责回答:
当前这个查询附近发生了什么?
· 全局上下文 Global Context
全局上下文指的是同一个关系在图谱中大量实例上的整体规律。
例如,对于 nationality 关系,模型可以观察许多已有实例:
(Yann LeCun, nationality, USA)
(Yoshua Bengio, nationality, Canada)
(Zhihua Zhou, nationality, China)
(Richard Sutton, nationality, Canada)
这些实例及其周围子图可以帮助模型理解:
- 这个关系通常和哪些辅助关系共现?
- 哪些路径经常支持这个关系?
- 哪些实体类型更可能作为尾实体?
- 正样本和负样本之间的差异在哪里?
全局上下文负责回答:
这个关系在整个图谱里通常怎么表现?
· KGPFN 的关键判断
Gao 等作者的核心判断可以概括为:
关系普适性 ≠ 上下文适应性
关系普适性告诉模型:
哪些结构规律可以跨图谱复用。
上下文适应性告诉模型:
这些规律在当前图谱、当前关系、当前实体附近应该如何使用。
KGPFN 正是围绕这两类上下文设计的。
04|方法框架:KGPFN 如何把上下文用起来
KGPFN 的整体流程可以拆成四个步骤:
① 构造全局上下文
② 构造局部上下文
③ 编码关系与局部结构
④ 用 PFN 做上下文学习
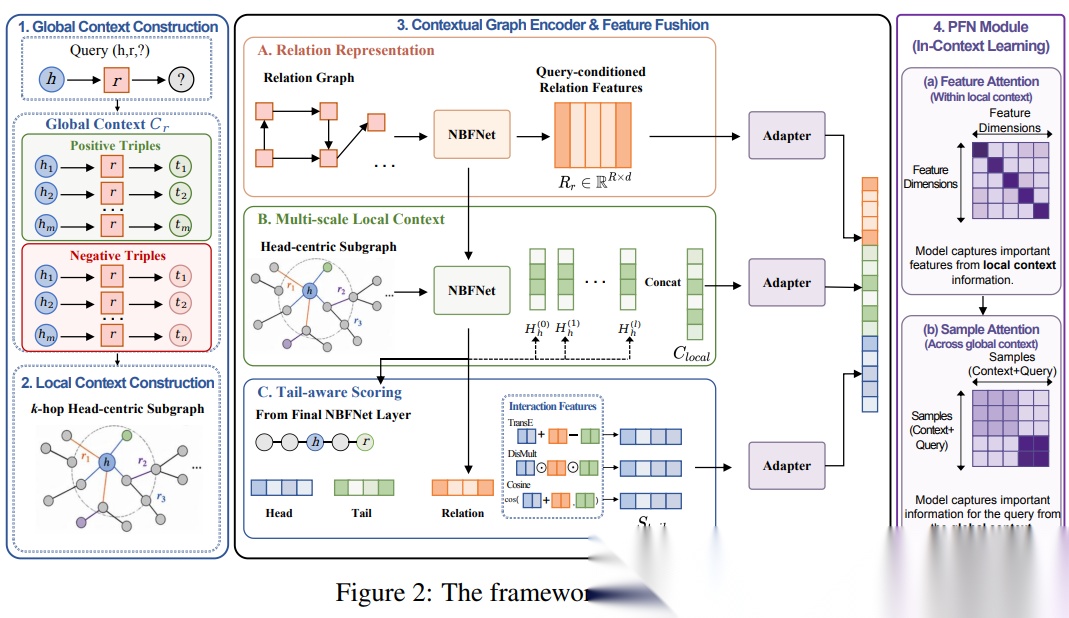
第一步:构造全局上下文
对于一个查询:
(h, r, ?)
KGPFN 会在目标图谱中找到一批具有相同关系 r 的已知三元组,作为正样本:
(h1, r, t1)
(h2, r, t2)
...
同时,模型还会通过负采样构造一批不成立的负样本:
(h1, r, t'1)
(h2, r, t'2)
...
最后,正样本和负样本共同组成该关系的全局上下文:
Cr = {((hk, r, tk), yk)}
其中:
yk = 1 表示正样本
yk = 0 表示负样本
这一步的意义在于:
模型不只是看到一个孤立查询,而是能看到这个关系在目标图谱中的一组代表性案例。
第二步:构造局部上下文
对于每个三元组,KGPFN 会围绕头实体 h 提取一个 k-hop 邻域子图。
论文中特别强调,模型没有对头实体和候选尾实体同时提取联合子图,而是采用头实体中心的局部子图。
原因很现实:
如果每个候选尾实体都要重新提取子图,
那么大规模训练和推理会非常昂贵。
因此,作者选择只围绕头实体构造局部上下文。
这样做的优势是:
- 更容易批处理;
- 推理速度更快;
- 对大量候选尾实体更友好;
- 仍然能够保留查询实体附近的重要结构证据。
第三步:编码关系、局部结构和尾实体交互
KGPFN 的编码部分包含三类信息。
第一类:关系表示。
作者先构建一个关系图。
在这个关系图中,每个节点是一种关系,边表示两个关系之间通过实体端点形成的交互方式。
论文中考虑了四种基础关系交互:
tail-to-head
head-to-head
head-to-tail
tail-to-tail
随后,模型在关系图上进行消息传递,得到与查询关系相关的关系表示。
第二类:多尺度局部上下文表示。
KGPFN 使用多层 NBFNet 编码头实体附近的局部子图。
NBFNet 的一个重要特性是,不同层可以聚合不同跳数范围内的信息。
因此,作者把每一层得到的头实体表示都看作一种局部上下文摘要:
第 1 层:偏 1-hop 信息
第 2 层:偏 2-hop 信息
第 3 层:偏 3-hop 信息
...
这样,模型能够同时利用浅层邻居信息和更深层的多跳组合证据。
第三类:尾实体感知的打分表示。
只看头实体局部结构还不够,因为链接预测最终要区分不同候选尾实体。
因此,KGPFN 进一步取出尾实体在 NBFNet 最后一层的表示,并构造三类交互特征:
TransE 风格特征
DistMult 风格特征
Cosine 相似度特征
这些特征分别从平移、乘性交互和相似度角度刻画:
(h, r, t)
这个候选三元组是否合理。
最后,模型使用轻量 MLP adapter 把不同来源的特征对齐到同一个潜在空间,再拼接成一个融合表示。
第四步:用 PFN 做上下文学习
PFN 是 KGPFN 的核心。
在 KGPFN 中,PFN 接收两类输入:
查询三元组的表示 xq
关系相关的上下文集合 Cr
然后输出候选三元组的合理性分数。
论文中的 PFN 模块包含两个关键注意力机制:
Feature-level Attention
Sample-level Attention
也就是:
特征维度内部看重点
样本集合之间找证据
Feature-level Attention 负责在单个样本内部识别哪些结构特征更重要。
例如,某些路径、关系组合或尾实体交互信号可能比其他特征更关键。
Sample-level Attention 负责在全局上下文样本之间寻找对当前查询最有帮助的案例。
例如,某个正样本可能和当前查询高度相似,某些负样本则可以帮助模型排除错误候选。
这就是 KGPFN 的上下文学习能力来源:
模型不是通过更新参数来适应新图谱,而是通过注意力机制在推理时读取上下文,并据此改变预测。
05|理论解释:从“看见结构”到“临场组合规则”
作者还给出了一个理论视角,用来解释 KGPFN 为什么比只学习结构模式的模型更进一步。
已有知识图谱基础模型通常更关注:
结构表达能力
也就是模型能不能识别出某种 motif、路径或关系组合模式。
但作者指出,真正困难的问题不只是识别结构,而是:
这些结构在当前关系下应该如何组合成决策规则?
例如,同样是:
出生地 → 所在国家
这个结构在某些关系预测中很有用,在另一些情况下可能会误导模型。
因此,KGPFN 通过全局上下文让模型临场估计某个结构模式的重要性。
论文中的理论结论可以直观理解为:
一个结构模式真正发挥作用,需要同时满足两个条件:
① 它出现在当前查询附近;
② 它在当前关系的上下文样本中也很显著。
这就像一种“软逻辑合取”:
当前查询有这个模式
+
上下文证明这个模式对该关系重要
=
该模式对预测产生更强贡献
所以,KGPFN 并不是给每种关系预先固定一套规则,而是在推理时根据上下文动态组合规则。
这也是它能适应未见关系的重要原因。
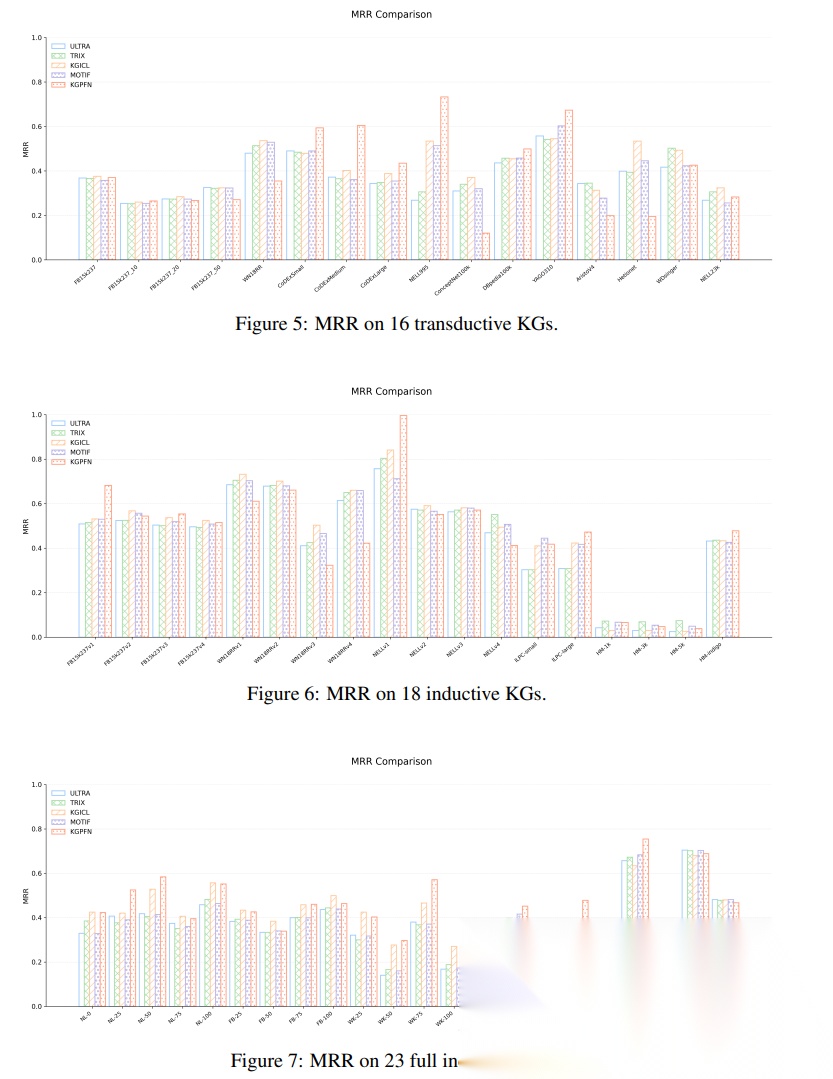
06|实验设计:57 个知识图谱上的检验
为了验证 KGPFN 的泛化能力,作者在 57 个知识图谱上进行了实验。
这些数据集分为三类:
① Transductive:16 个图谱
② Inductive e:18 个图谱
③ Inductive e, r:23 个图谱
其中,最难的是第三类:
Inductive e, r
因为测试时不仅实体没见过,连关系类型也没见过。
这对知识图谱基础模型非常关键。
如果模型只能处理见过的关系,那它的“基础模型”属性就会受到限制。
而 KGPFN 的目标正是让模型能够迁移到新实体、新关系和新图谱中。
实验对比对象
论文中将 KGPFN 与多个强基线进行比较:
ULTRA
KG-ICL
MOTIF
TRIX
这些模型都属于较有代表性的知识图谱基础模型或上下文学习模型。
其中,KGPFN 的一个重要特点是:
不进行目标数据集微调
只使用推理时上下文
也就是说,模型预训练完成后,面对新图谱时直接通过上下文进行适应。
实验设置重点
论文中的主要实现细节包括:
关系编码器:6 层 NBFNet
局部上下文编码器:6 层 NBFNet
隐藏维度:64
局部上下文:头实体 3-hop 子图
全局上下文:20 个正样本 + 60 个负样本
优化器:AdamW
训练负样本:每个正样本 64 个负样本
评估方式:对所有实体排序
实验硬件:8 张 NVIDIA A800 80GB GPU
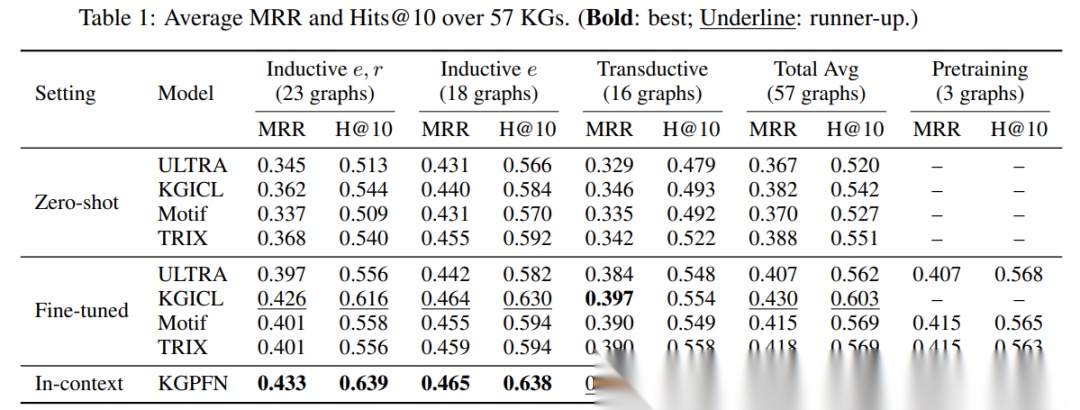
07|结果解读:为什么说 ICL 真的发挥作用
从主实验结果看,KGPFN 的优势非常明确。
在 57 个图谱的总平均结果上,KGPFN 达到:
MRR:0.432
Hits@10:0.628
而最强的 fine-tuned 基线 KG-ICL 的总平均结果为:
MRR:0.430
Hits@10:0.603
这意味着,KGPFN 即使不在目标数据集上微调,也能超过经过微调的竞争模型。
更值得注意的是,在最困难的 full-inductive 设置中,也就是实体和关系都未见过的场景下,KGPFN 取得:
MRR:0.433
Hits@10:0.639
相比之下,fine-tuned KG-ICL 的结果是:
MRR:0.426
Hits@10:0.616
这说明 KGPFN 的上下文学习能力并不是装饰性的,而是确实帮助模型完成了新图谱适应。
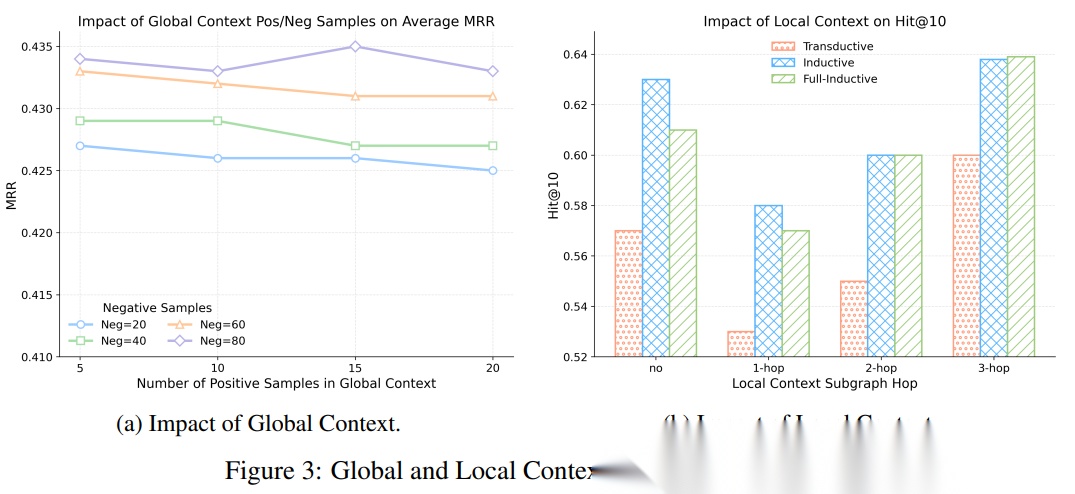
· 全局上下文越多越好吗?
论文进一步分析了全局上下文数量的影响。
作者改变正样本数量:
5 / 10 / 15 / 20
以及负样本数量:
20 / 40 / 60 / 80
结果显示,正样本数量变化对性能影响不明显,但负样本数量增加通常能带来更好的表现。
这很有启发性。
在链接预测任务中,模型不仅要知道什么是正确答案,还要能在大量相似候选中排除错误答案。
因此,更多负样本可以帮助模型更好地区分“看起来像但其实不成立”的候选三元组。
总结
当然,论文也提到一个局限:
由于计算资源限制,作者没有系统验证知识图谱任务上的 scaling law。也就是说,KGPFN 在更大模型、更大预训练图谱、更大上下文规模下是否会继续稳定提升,还有待进一步研究。
但总体来看,KGPFN 给知识图谱基础模型提供了一个非常清晰的新方向:
未来的知识图谱基础模型,不仅要学会迁移关系结构,还要学会在推理现场读懂上下文。
它的意义不只是提出了一个新模型,更在于强调了一种新的建模范式
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献174条内容
已为社区贡献174条内容

所有评论(0)