告别“盲读”时代:AI 代码分析的范式转移与开发者认知的深度解构
目录
核心发现一:AI 不必读完所有代码——8.2 倍的“令牌节约术”
核心发现二:预计算的“爆炸半径”分析——在破坏发生前预知后果
引言:面对 20 万行代码的“认知过载”
想象你刚刚加入一个新团队,接手了一个拥有 20 万行代码的庞大单体架构(Monorepo)。你的第一个任务是修复一个涉及身份验证流的深层 Bug。当你打开 IDE,那种“盲读代码”的无力感会瞬间袭来:文件之间交织着复杂的依赖,函数调用链深不可测。每一个微小的改动都像是在黑暗中拨动蛛网,你根本不知道哪里会引起连锁反应。这种“开发者认知的过度负载”正是现代大规模软件开发的头号杀手。
目前,开发者普遍求助于 Cursor 或 Claude 等 AI 工具。然而,在处理此类复杂任务时,这些工具往往表现得“烧钱”且低效。它们要么尝试暴力吞下整个代码库导致 Token 爆炸,要么因为缺乏全局结构感而给出“瞎猜”的建议。其根源在于:AI 缺乏对代码库的结构化理解。
现在,以 GitNexus、code-review-graph 和 Understand-Anything 为代表的工具正在引领一场范式转移——通过构建“代码知识图谱”,为 AI 装上中枢神经,实现从“感知代码”到“认知系统”的跃迁。
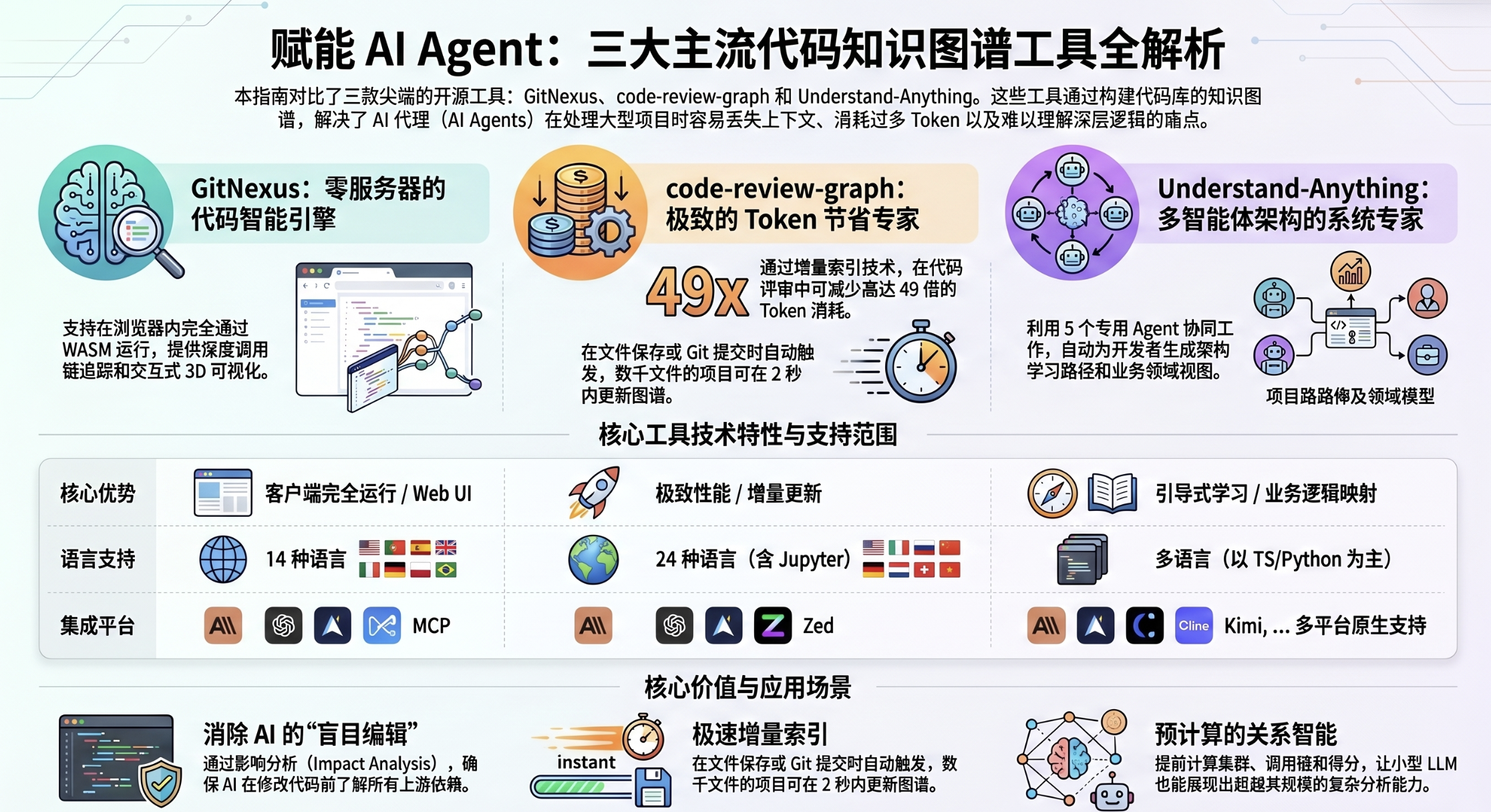
核心发现一:AI 不必读完所有代码——8.2 倍的“令牌节约术”
传统的 AI 辅助工具倾向于重复阅读整个代码库以获取上下文,这不仅造成了严重的 Token 浪费,也极大地延长了反馈周期。资深架构师明白,卓越的开发者体验(DevEx)源于对“注意力带宽”的精准分配。
通过使用 Tree-sitter 解析器构建结构化地图,新一代工具能精确地引导 AI:只阅读那 15 个相关的节点,而不是扫描 monorepo 中的 27,000 个文件。根据 code-review-graph 对 6 个真实开源仓库的基准测试,这种基于图谱的分析实现了平均 8.2 倍的 Token 减省。
|
仓库 (Repo) |
传统方式 Token (平均) |
知识图谱 Token (平均) |
令牌减省比例 |
|
FastAPI |
4,944 |
614 |
8.1x |
|
Flask |
44,751 |
4,252 |
9.1x |
|
Gin |
21,972 |
1,153 |
16.4x |
|
Next.js |
9,882 |
1,249 |
8.0x |
|
平均水平 |
- |
- |
8.2x |
架构师视角的行业洞察: 值得注意的是,这种优化并非万能药。在 Express 等小型单文件变动较多的仓库中,由于需要注入额外的结构化元数据和关系索引,Token 消耗反而可能出现 0.7x 的反向增长。但在处理多文件协同的复杂逻辑时,图谱带来的成本优势是压倒性的。这种“令牌经济学”的本质是将昂贵的实时推理成本转化为了廉价的预计算结构。
核心发现二:预计算的“爆炸半径”分析——在破坏发生前预知后果
在复杂架构中,最危险的动作就是“看似微小”的底层改动。GitNexus 和 code-review-graph 引入了“爆炸半径(Blast Radius)”分析,通过“中介中心性(Betweenness Centrality)”等图算法,识别系统中的架构关口。
与传统的 Graph RAG(仅提供原始边信息)不同,这些工具在索引阶段就完成了关系的预计算。它们对依赖关系提供三级置信度评分(EXTRACTED/INFERRED/AMBIGUOUS),让开发者能够一眼看穿风险。
“AI 修改了 UserService.validate(),却不知道有 47 个函数依赖于它的返回类型,结果破坏性变更上线了。”
这种预计算能力让 AI 助手能够直接调取 impact 深度报告。这种技术上的“降维打击”使得即使是参数规模较小的本地 LLM,也能在处理复杂系统架构时展现出与 GPT-4 不相上下的理解深度,极大地缓解了值班(On-call)时的认知压力。
核心发现三:零服务器架构——代码资产的本地主权
对于企业级应用,隐私性是不可逾越的红线。GitNexus 展示了一种令人惊叹的“零服务器(Zero-Server)”架构,利用 WebAssembly (WASM) 将 Tree-sitter 解析器和 LadybugDB(支持向量检索的嵌入式图数据库)直接运行在浏览器或本地。
这种架构通过 MCP (Model Context Protocol) 协议与 Cursor 或 Claude Code 实现无缝对接。这种“插件化(Drop-in)”模式彻底颠覆了代码审计的流程:
Web UI 模式(极速探索): 利用浏览器内存运行 WASM 版 LadybugDB,无需安装,直接拖入 ZIP 或 GitHub 仓库进行即时可视化探索。
CLI + MCP 模式(深度协同): 作为 AI 助手的“外部大脑”,在本地持久化索引无限规模的代码库,通过标准协议为 IDE 提供实时的架构洞察。
核心发现四:多智能体协作——桥接“代码实现”与“业务意图”
如果说解析 AST 是“感知”,那么 Understand-Anything 的多智能体架构则标志着向“认知”的迈进。该系统通过 7 个分工明确的智能体协同工作:
project-scanner:环境感知,检测框架栈。
file-analyzer:结构提取,生成原子节点。
architecture-analyzer:层级识别。
tour-builder:构建引导式学习路径。
graph-reviewer:引用一致性校验。
domain-analyzer:提取业务领域逻辑(核心价值所在)。
article-analyzer:从非结构化文档中挖掘隐式关系。
对于 DevEx 专家来说,最令人振奋的是其“领域视图”。它不仅展示函数调用,更将代码映射回“用户下单”或“结算流程”等真实业务逻辑。这种从代码实现到业务意图的对齐,是解决新人入职(Onboarding)难题的关键。它通过 Leiden 社区发现算法 自动对功能模块进行聚类,让新人能按部就班地建立起与系统一致的精神模型(Mental Model)。
核心发现五:增量更新的奇迹——2 秒钟完成 2900 个文件的重索引
在大型单体仓库中,索引的“时效性”决定了 AI 是否会给出过时的误导建议。code-review-graph 实现了基于 SHA-256 哈希检查的增量解析技术。
在实际生产测试中,一个包含 2,900 个文件的项目,其增量重索引过程在 2 秒钟内即可完成。这种即时反馈的能力彻底改变了日常流:每当你完成一次 git commit,后台挂钩(Hook)就会自动刷新图谱。这种“无感更新”让 AI 助手始终拥有最鲜活的代码语境,消除了手动重索引带来的中断感。
结语:从“构建者”到“图谱策展人”的跃迁
通过将代码库转化为可交互、可计算的知识图谱,我们正在见证 AI 从简单的“代码补全器”演变为代码库的“中枢神经系统”。正如 GitNexus 的愿景所言:
“构建智能体的神经系统 (Building nervous system for agent context)。”
当 AI 维护的“架构地图”比任何开发者的记忆都更精确、更实时时,人类工程师的核心价值将被重新定义。我们不再是逐行敲击代码的泥瓦匠,而是进化为真正的系统架构师,将精力集中在更高维度的业务设计与系统决策上。
最终的问题是:当 AI 能够比你更深刻地理解代码库的每一个角落时,你是否准备好从代码的“编写者”转型为知识图谱的“策展人”?
作者:道一云低代码
作者想说:喜欢本文请点点关注~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)