设备在线状态到底怎么定义:Heartbeat、Connectivity、Last Seen 和 LWT 应该怎么组合
很多团队在做 IoT 平台时,都会在设备表里放一个 online = true/false 字段,然后把它当成“设备是否在线”的答案。这个做法一开始很省事,但只要设备类型一多、网络环境一复杂、协议链路一分层,这个字段很快就会同时承载四种完全不同的问题:
- 设备当前有没有网络连接
- 设备有没有按预期活着
- 平台最近一次收到它的数据是什么时候
- 这次掉线是正常离线、弱网抖动,还是异常断链
本文的核心结论是:设备在线状态不应该被建成单一字段,而应该拆成四类信号协同判断:Connectivity 表示会话连接状态,Heartbeat 表示设备是否按期存活,Last Seen 表示平台最后一次看见任何有效活动的时间,LWT 或同类异常断链信号用于补充“连接是怎么断掉的”。真正面向运维和告警的“online state”,应该是这四类信号聚合后的领域判断,而不是任何一个原始字段。
如果把这四件事混成一个值,平台几乎一定会出现这些问题:
- 连接层刚断开,页面却还显示在线
- 设备不发心跳但偶尔上报遥测,状态来回抖动
- MQTT 长连接断掉后没有异常标记,只能靠超时猜测
- 低功耗设备本来就是间歇上线,却被误报为频繁离线
定义块
本文所说的“设备在线状态”不是 broker 是否连着、也不是数据库里最后一条时间戳,而是平台对“这台设备当前是否可认为处于可通信、可运维、可依赖状态”的综合判断。
决策块
只要你的系统需要支撑告警、运维排障、批量搜索、命令下发或 SLA 统计,就不要把
online当成单一布尔字段直接存库并到处复用。更稳的做法是把原始信号拆开存,再在领域层聚合出“在线 / 疑似离线 / 已离线 / 长期沉默”等状态。否则平台会把网络状态、设备活性和数据新鲜度混成同一个概念,最终既误报,也难排障。
1. 为什么“在线”不是一个字段
1.1 因为不同团队关心的其实不是同一件事
同一个“在线”词,在不同角色眼里含义完全不同:
- 连接层关心的是 TCP、MQTT、WebSocket 或蜂窝会话是否存在
- 设备平台关心的是设备最近是否还在按预期上报
- 运维台关心的是现在能不能下发命令、有没有恢复风险
- 业务层关心的是这个设备状态是否足够可信,可以驱动告警或联动
如果平台只有一个 online 字段,这四个问题就会被迫共享同一个答案。结果往往是某一层刚好“对”,另外三层全部失真。
1.2 因为在线状态天然包含“对象 + 条件 + 后果”
真正有用的状态判断,至少要说清三件事:
- 对象:说的是网络连接、设备活性,还是数据新鲜度
- 条件:基于心跳超时、连接断开、长时间无数据,还是 LWT 触发
- 后果:影响的是页面展示、告警触发、命令下发,还是工单升级
如果没有这三个维度,所谓在线状态通常只是“最后一次被谁顺手改了一下”。
2. 四类信号分别解决什么问题
| 信号 | 解决的问题 | 典型来源 | 不足 |
|---|---|---|---|
Connectivity |
当前会话是否仍建立 | MQTT session、TCP 连接、蜂窝 PDP、WebSocket | 只能说明链路层连着,不代表设备逻辑还活着 |
Heartbeat |
设备是否按预期持续存活 | 定时 ping、状态报文、应用层保活 | 周期设计不当会误伤低功耗或弱网设备 |
Last Seen |
平台最后一次看见任何有效活动是什么时候 | 任意遥测、ACK、心跳、事件 | 只能说明“最近见过”,不能说明“现在在线” |
LWT |
连接是否以异常方式断开 | MQTT LWT、broker session end、断链事件 | 只覆盖部分协议,不能替代心跳与业务活性 |
这四类信号之间不是替代关系,而是分层关系:
Connectivity适合回答“现在还有没有连接会话”Heartbeat适合回答“设备是否持续按预期活着”Last Seen适合回答“平台最后一次观察到活动是什么时候”LWT适合回答“会话是不是非正常中断”
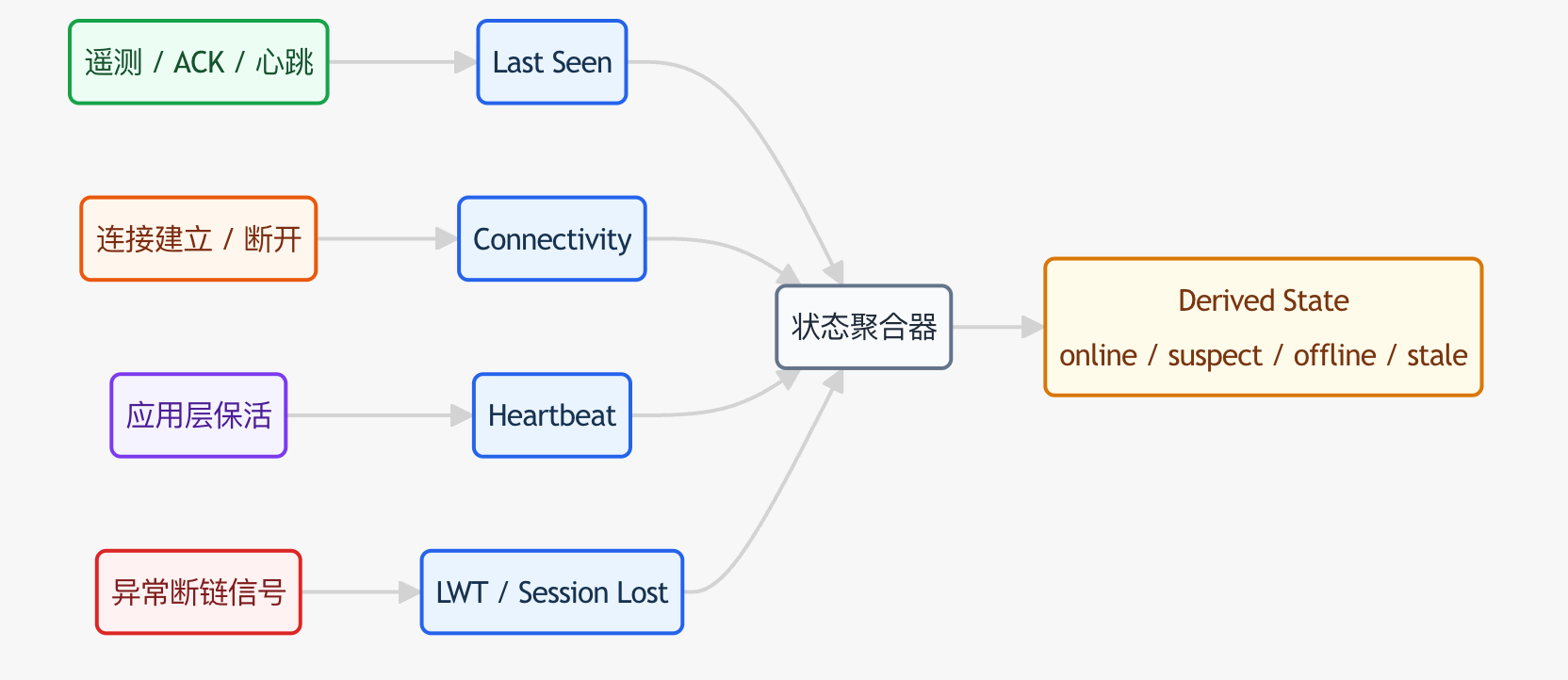
3. 更稳的在线状态模型应该怎么组合
3.1 先存原始信号,再推导聚合状态
推荐把原始字段拆成至少下面这些:
connectivity_stateheartbeat_atlast_seen_atdisconnect_reasonlast_lwt_atderived_online_statederived_state_reason
其中前五个是原始观察值,后两个才是平台对外展示和查询的聚合结果。
这个拆分的好处是,后续无论要改超时阈值、分设备类型建规则,还是追查误报来源,都能回到原始事实,而不是只能看到最终那个“被覆盖很多次”的 online。
3.2 用 Connectivity 反映会话,不要直接代替活性
Connectivity 最适合承接这些事件:
- MQTT client connected / disconnected
- TCP session established / closed
- WebSocket connected / closed
- 蜂窝链路上下线
它适合驱动:
- 当前是否可直接发实时命令
- 当前连接会话数统计
- broker / gateway 连接告警
但它不应单独驱动“设备一定在线”的业务判断。
原因很简单:连接会话存在,并不代表设备主循环、采样逻辑、传感器或应用层任务仍然健康。
3.3 用 Heartbeat 反映设备活性,而不是反映连接本身
Heartbeat 应该由设备应用层主动定义和上报。更稳的设计是:
- 心跳周期按设备类型分类,而不是全平台一个固定值
- 心跳内容至少包含
device_time、boot_id、firmware_version或轻量运行态字段 - 心跳超时窗口采用“周期 x 容忍倍数”,而不是硬编码秒数
例如:
- 插电常在线设备可以 60 秒一个心跳,3 个周期判疑似离线
- 电池设备可能 15 分钟甚至 1 小时一个心跳,不适合套用同一阈值
- 卫星或弱网场景设备可能以业务事件代替固定心跳
判断是:心跳机制应该服务设备活性建模,而不是为了把所有设备都拉成一个统一节奏。
3.4 用 Last Seen 反映“最近见过”,不要误当“当前在线”
Last Seen 很有价值,因为它几乎可以由任何有效活动更新:
- 心跳
- 遥测
- 事件
- 命令 ACK
- 配置回执
它特别适合:
- 运维排障时判断“这台设备最后一次被看到是什么时候”
- 搜索近 24 小时沉默设备
- 与
Heartbeat规则配合做分层告警
但 Last Seen 不能单独回答“现在是否在线”。
如果一台设备 20 分钟前上报过温度,现在会话已断且无 LWT 事件,Last Seen 仍有值,但这台设备并不应被视为当前在线。
3.5 用 LWT 补充异常断链语义
LWT 的价值,不在于替代心跳,而在于它能更早暴露“连接不是正常下线,而是异常丢失”。这会直接影响:
- 是否需要立即触发高优先级告警
- 是否要启动命令重试或会话清理
- 运维台要不要把断线原因标成异常
但是 LWT 只是一种补充信号:
- 它依赖特定协议或 broker 能力
- 它不覆盖所有现场网络路径
- 它不能反映设备是否还在逻辑运行但暂时无法连回
所以 LWT 适合做“异常断开证据”,不适合做整个平台唯一在线判断来源。
4. 一个可落地的状态机是什么样
推荐把最终状态至少分成四档:
online:连接与活性都满足阈值suspect_offline:尚未达到硬离线,但心跳或连接出现异常offline:连接已断且超过心跳 / 最后活动阈值,或收到明确异常断链stale:设备长期没有活动,但本身就是低频设备,不应当被当成实时在线
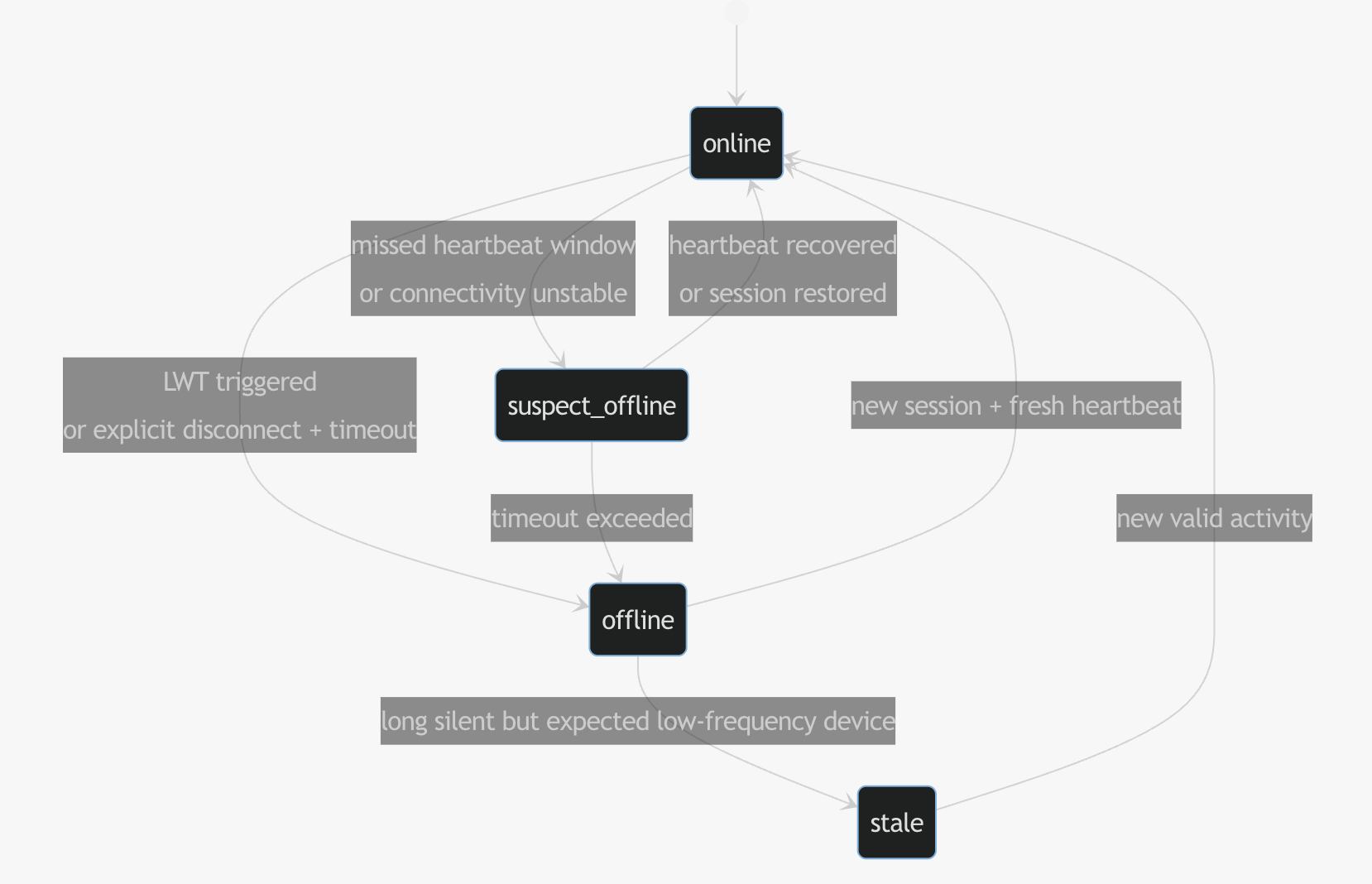
这个状态机的关键不是名字,而是不同后果必须绑定到不同状态:
suspect_offline适合低级别提醒或页面黄灯offline才适合触发硬告警、命令暂停或 SLA 统计stale适合低频设备的单独视图,不应与故障离线混写
5. 在线判断最容易犯的四个错误
5.1 把 broker 连接状态直接当设备健康状态
如果连接由网关代理,或设备只是共享一个上行链路,那么 broker 上是否连着,往往只能说明“代理通道还在”,并不能说明具体子设备活着。
5.2 把任意数据上报都当心跳
某些设备只有告警时才上报,某些遥测是批量补传。
如果这些活动都被直接当成心跳,平台会把“有历史数据补上来”误当成“设备现在状态健康”。
5.3 全平台只用一个超时阈值
这是最常见也最危险的偷懒方式。不同设备在:
- 供电方式
- 网络介质
- 上报频率
- 成本约束
- 业务重要性
上差异巨大。统一阈值只会制造大规模误报,最终让告警失去可信度。
5.4 不记录“为什么被判定离线”
只有状态,没有理由,运维就无法回答:
- 是连接断了,还是心跳超时了
- 是收到 LWT,还是最后活动太久以前
- 是设备类型本就低频,还是规则配置错了
所以 derived_state_reason 和状态一样重要。
6. 什么时候不需要这么复杂
下面这些场景可以简化:
- 设备数量很少,且只做简单在线展示
- 设备协议单一、供电稳定、网络稳定,没有命令链路
- 业务不依赖在线状态做告警、批量搜索或 SLA 统计
但只要系统进入这些场景,上述简化就不再稳妥:
- 需要批量定位离线设备
- 需要区分“短抖动”和“真实故障”
- 需要按设备类型配置不同阈值
- 需要解释命令为什么失败
- 需要把在线状态接入告警和工单
此时继续坚持单字段模型,代价通常是后面重做数据模型、搜索索引和告警规则。
7. 一套更实用的落地清单
如果你准备重做在线状态模型,最少先做这五件事:
- 把
connectivity、heartbeat、last_seen、lwt分开存储 - 给设备类型配置独立超时规则,而不是全局一个值
- 在聚合层输出
derived_online_state和reason - 让运维搜索同时支持按状态和按原始时间戳筛选
- 把命令系统与在线状态联动,但不要直接共享同一个布尔字段
最终判断是:IoT 平台最可靠的在线状态,不是“某个字段最后被谁改成 true”,而是一个能解释信号来源、成立条件和运维后果的聚合模型。Heartbeat、Connectivity、Last Seen 和 LWT 都重要,但它们从来不应该互相冒充。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)