必读高引顶刊!近5年无人机强化学习路径规划经典论文盘点

「从单机竞速到多机协同」
当一架无人机以超过 100 km/h 的速度穿越密林,或在没有 GPS 信号的室内环境中精准避开移动障碍物,背后依靠的早已不是工程师手写的规则,而是通过数百万次仿真试错"练"出来的深度强化学习策略。
本文精选近5年内发表于 Nature、Science Robotics、IEEE Transactions 系列等顶级期刊,且被引量均在 250 次以上的代表性论文,从极限竞速、野外高速飞行、通信辅助轨迹规划到多机协同数据采集,带你系统梳理这一领域的研究脉络与前沿进展。
目录
论文三:通信赋能的轨迹规划——DRL 优化 UAV 辅助移动边缘计算
论文四:多机协同数据采集——去中心化 MARL 应对 IoT 场景
无人机路径规划的核心挑战,在于如何在动态、未知、高维的真实环境中实时生成安全且高效的飞行轨迹。传统方法,无论是基于图搜索的 A* 算法、基于梯度的人工势场法、还是基于采样的 RRT 系列,在面对以下三类场景时往往力不从心:
- 高动态障碍物(如行人、车辆):重规划延迟高,难以满足实时性要求
- 未知或部分可观测环境:依赖完整地图,无法在线更新
- 多机协同(通信受限):集中式规划通信开销大,分布式方法收敛慢
深度强化学习的出现为上述困境提供了新的解法。其核心思路是:将无人机视为"智能体",将飞行环境建模为马尔可夫决策过程(MDP),通过与仿真环境的大量交互,让智能体自主学习出一套从感知输入到控制指令的端到端策略。近年来,随着仿真平台的成熟(如 Flightmare、AirSim)和算法的进步(PPO、SAC、MADDPG 等),DRL 已在多个无人机任务上实现了对传统方法乃至人类专家的超越。
02 论文盘点
论文一:击败人类世界冠军——DRL 赋能极限竞速
论文信息
论文标题:Champion-level drone racing using deep reinforcement learning
核心算法:PPO + 经验噪声模型
应用场景:极限竞速(Sim-to-Real)
被引量:1070次
这是迄今为止强化学习在无人机领域影响力最大的一项工作,发表于全球顶级综合性期刊 Nature,被引量在发表后不到两年内即突破 1000次。该工作的历史性意义在于:这是首次有自主移动机器人在真实世界竞技运动中达到人类世界冠军水平。
核心方法
研究团队来自苏黎世大学与 Intel Labs,提出了名为 Swift 的自主竞速系统。Swift 由两个核心模块构成:一是将机载相机与惯性测量单元(IMU)的高维感知信息压缩为低维状态表征的感知模块;二是由前馈神经网络表示、在仿真中通过无模型在线策略强化学习(PPO 算法)训练的控制策略模块。
为解决仿真与现实之间的"Sim-to-Real Gap"问题,研究团队从真实系统采集数据,构建了非参数经验噪声模型,并将其注入仿真训练过程,从而使策略在真实飞行中保持鲁棒性。
实验结果
Swift 在一条由职业竞速飞手设计的赛道上(7 个方形门框,单圈 75 m,飞行空间 30×30×8 m)与三位人类世界冠军展开正面对决:2019 年 Drone Racing League 世界冠军 Alex Vanover、两届 MultiGP 国际公开赛冠军 Thomas Bitmatta,以及三届瑞士全国冠军 Marvin Schaepper。Swift 赢得了对阵每位飞手的多场比赛,并创造了本次赛事的最快单圈纪录。飞行过程中,无人机速度超过 100 km/h,承受的加速度超过自身重力的 5 倍,全程仅依赖机载传感器,无需外部运动捕捉系统。

图1 | Swift 自主无人机与人类冠军飞手的正面对决场景。上图为赛道俯视图,蓝色轨迹为 Swift(自主),红色轨迹为人类飞手;左下为无人机穿越方形门框的近景;右下为参赛的三位人类世界冠军(从左至右:Thomas Bitmatta、Marvin Schaepper、Alex Vanover)。
论文二:野外高速飞行——从感知到决策的端到端学习
论文信息
论文标题:Learning High-Speed Flight in the Wild
核心算法:特权学习 + 模仿蒸馏
应用场景:野外高速飞行
被引量:508次
Science Robotics 是机器人领域的旗舰期刊,影响因子长期位居全球机器人类期刊前列。本文被引量超过 500 次,是近年来无人机自主飞行领域引用最为广泛的论文之一,同样来自苏黎世大学 Scaramuzza 团队。
核心方法
与 Swift 的竞速场景不同,本文聚焦于非结构化野外环境中的高速自主飞行——树林、建筑工地、山地等人类难以预先建图的复杂场景。研究团队提出了一种输入融合的端到端学习框架:系统接收来自机载深度相机的深度图像和 IMU 数据,通过深度神经网络直接输出飞行控制指令,无需显式的地图构建或路径规划模块。
训练过程采用特权学习(Privileged Learning)策略:在仿真阶段,教师网络可访问完整的环境状态信息(如精确障碍物位置),学生网络则仅能访问传感器数据;通过模仿学习将教师策略蒸馏到学生网络,再将学生网络部署到真实无人机上。
实验结果
系统在多种真实野外环境中以 5–10 m/s 的速度飞行,在 7 m/s 以下速度时成功率超过 90%,在 10 m/s 时仍能保持约 60% 的成功率,显著优于当时的最先进方法。
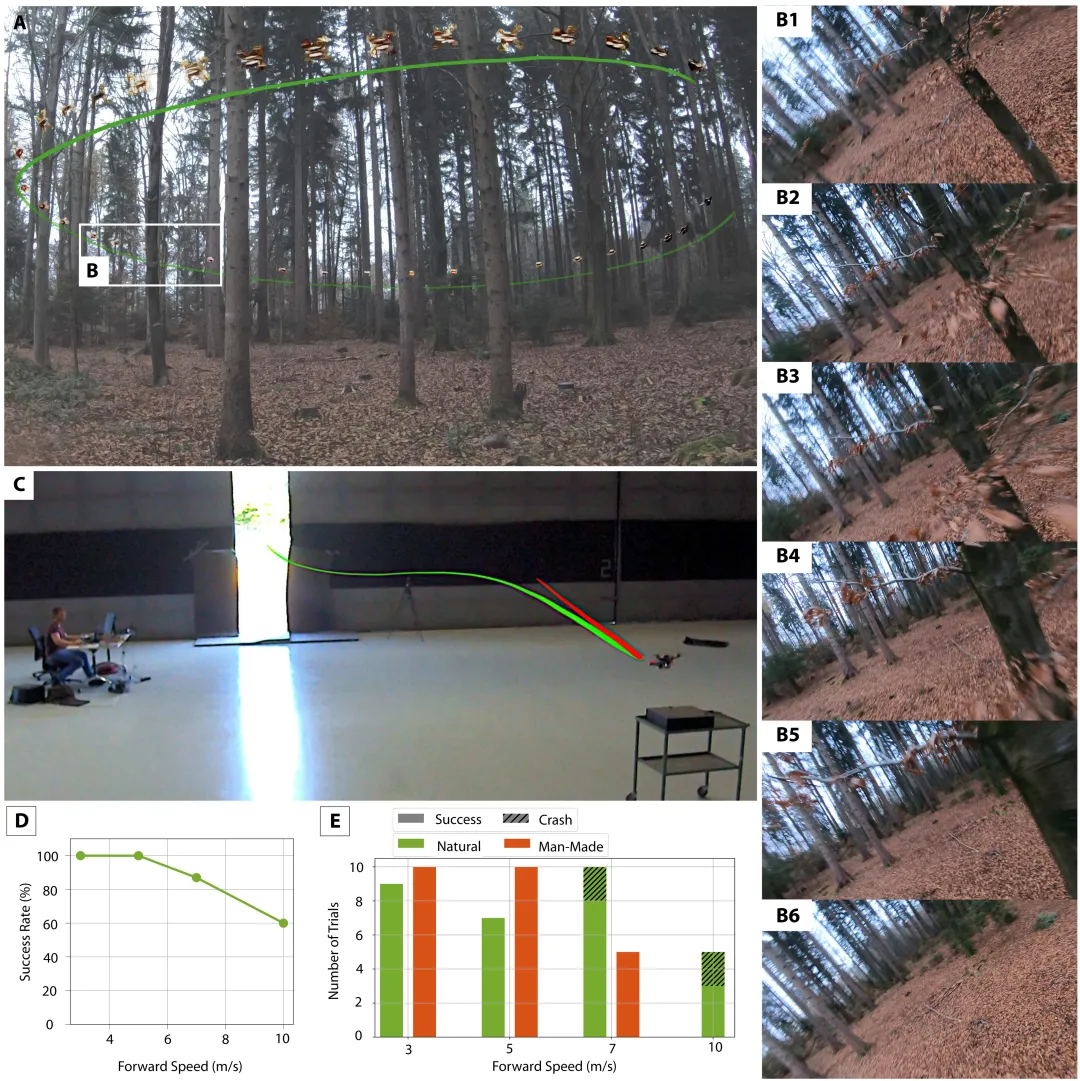
图2 | 野外高速飞行实验场景与结果。A 图展示了无人机在树林中的飞行轨迹(绿色曲线);B1–B6 为机载相机在飞行过程中拍摄的第一视角序列帧;C 图为室内实验对比场景;D 图显示随飞行速度提升成功率的变化趋势;E 图对比了自然环境与人工建筑环境中不同速度下的成功/坠毁次数。
论文三:通信赋能的轨迹规划——DRL 优化 UAV 辅助移动边缘计算
论文信息
论文标题:Deep Reinforcement Learning Based Dynamic Trajectory Control for UAV-assisted Mobile Edge Computing
核心算法:DDPG(Actor-Critic)
应用场景:UAV 辅助 MEC 轨迹优化
被引量:365次
IEEE Transactions on Mobile Computing(IEEE TMC)是无线通信与移动计算领域的顶级期刊,影响因子超过 7。本文被引量已达 365 次,是将 DRL 应用于 UAV 辅助通信与计算场景的高度代表性工作,也是目前该细分方向引用最多的论文之一。
核心方法
本文针对的场景是:多架无人机携带移动边缘计算(MEC)服务器,为地面移动用户提供计算卸载服务,同时需要动态规划飞行轨迹以最大化系统吞吐量、最小化任务时延。
研究团队提出了一种基于深度确定性策略梯度(DDPG)算法的动态轨迹控制框架。该框架将无人机的三维位置、用户的任务卸载需求和信道状态信息共同编码为状态空间,将无人机的飞行方向和速度作为连续动作空间,通过 Actor-Critic 结构学习最优轨迹策略。
实验结果
与传统的固定轨迹方案(圆形、直线)和启发式方法相比,所提 DRL 方法在系统吞吐量上提升了 20%–35%,同时有效降低了任务处理时延,验证了在动态用户分布下的自适应轨迹规划能力。
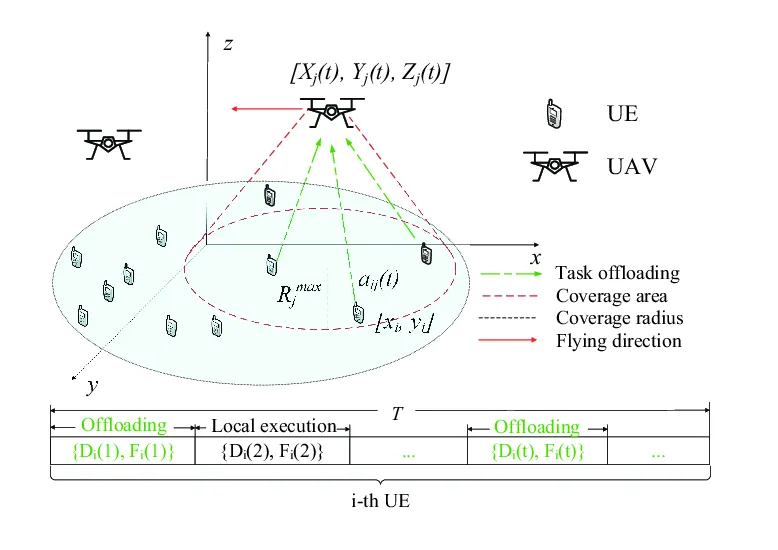
图3 | 多无人机辅助移动边缘计算(F-MEC)系统模型示意图。无人机在三维空间中动态飞行,通过任务卸载链路(绿色箭头)为覆盖区域内的地面用户(UE)提供计算服务,飞行方向由红色箭头标注,覆盖半径由虚线圆圈表示。
论文四:多机协同数据采集——去中心化 MARL 应对 IoT 场景
论文信息
论文标题:Multi-UAV Path Planning for Wireless Data Harvesting with Deep Reinforcement Learning
核心算法:Dec-POMDP + CNN
应用场景:多机协同 IoT 数据采集
被引量:258次
本文发表于 IEEE 旗下的开放获取期刊 IEEE Open Journal of the Communications Society,作者来自欧洲顶级通信研究机构 EURECOM(法国)和慕尼黑工业大学(TUM)。被引量 258 次,是多无人机协同路径规划与无线通信交叉领域的标志性工作。
核心方法
本文面向的任务是:多架无人机协同从分布式物联网(IoT)传感器节点采集数据,同时需要满足飞行时间约束和碰撞避免约束。研究团队将该问题建模为去中心化部分可观测马尔可夫决策过程(Dec-POMDP),并提出了一种基于 DRL 的多智能体路径规划方法。
该方法的核心创新在于:利用以智能体为中心的全局地图与局部地图的双重表征,通过卷积神经网络(CNN)提取空间特征,使各无人机在无通信的条件下仍能有效协作,自主分配数据采集任务。更重要的是,该策略能够泛化到训练时未见过的场景参数(如无人机数量、IoT 节点位置和数据量的变化),无需重新训练。
实验结果
在多种城市环境仿真场景中,所提方法在数据采集效率上显著优于贪心算法和传统规划方法,且在无人机数量从 2 架扩展到 6 架时仍保持良好的泛化性能,展示了强化学习策略在多机协同场景下的可扩展性。
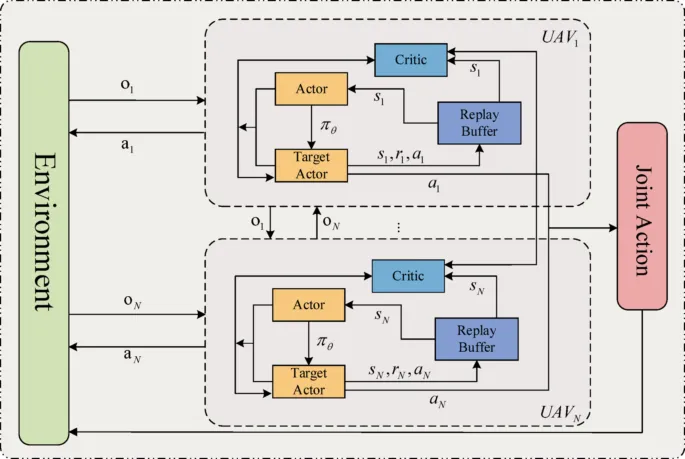
图4 | 多无人机协同强化学习框架示意图。每架无人机(UAV₁ 至 UAVₙ)各自维护独立的 Actor-Critic 网络和经验回放缓冲区,从环境中接收局部观测(oᵢ)并输出动作(aᵢ),所有智能体的动作汇聚为联合动作(Joint Action)共同影响环境状态。
论文五:有限感知下的记忆增强避障——LSTM 赋能室内导航
论文信息
论文标题:Memory-based Deep Reinforcement Learning for Obstacle Avoidance in UAV with Limited Environment Knowledge
核心算法:LSTM + 注意力门控 DQN
应用场景:有限感知室内避障
被引量:379次
IEEE Transactions on Intelligent Transportation Systems(IEEE TITS)是智能交通系统领域的顶级期刊,影响因子超过 8。本文来自印度科学院(IISc Bangalore),被引量 379次,是将记忆机制(LSTM)引入无人机 DRL 避障的奠基性工作之一,对后续大量研究产生了深远影响。
核心方法
本文针对的核心挑战是:在感知信息极为有限(仅有机载前视摄像头,无雷达、无地图)的室内环境中,无人机如何通过强化学习实现可靠的障碍物规避。
研究团队提出了 AG-DGN(Attention-Gated Deep Q-Network) 框架,其核心创新包含三个层次:
1.Glimpse 网络:通过空间变换机制(Spatial Transformer)从原始图像中提取若干关键局部区域(Glimpses),聚焦于障碍物所在位置,而非处理整张高分辨率图像,大幅降低计算量。
2.循环网络(LSTM):对历史 Glimpse 特征序列进行时序建模,赋予智能体对障碍物运动趋势的"记忆"能力,弥补单帧观测的信息不足。
3.注意力门控机制:动态加权不同时刻的历史特征,使网络聚焦于最相关的历史信息。
实验结果
在仿真室内环境中,AG-DGN 在面对静态和动态障碍物时均显著优于不含记忆机制的基线 DQN,在动态障碍物场景下的任务成功率提升超过 20 个百分点,验证了记忆机制在部分可观测环境中的关键作用。
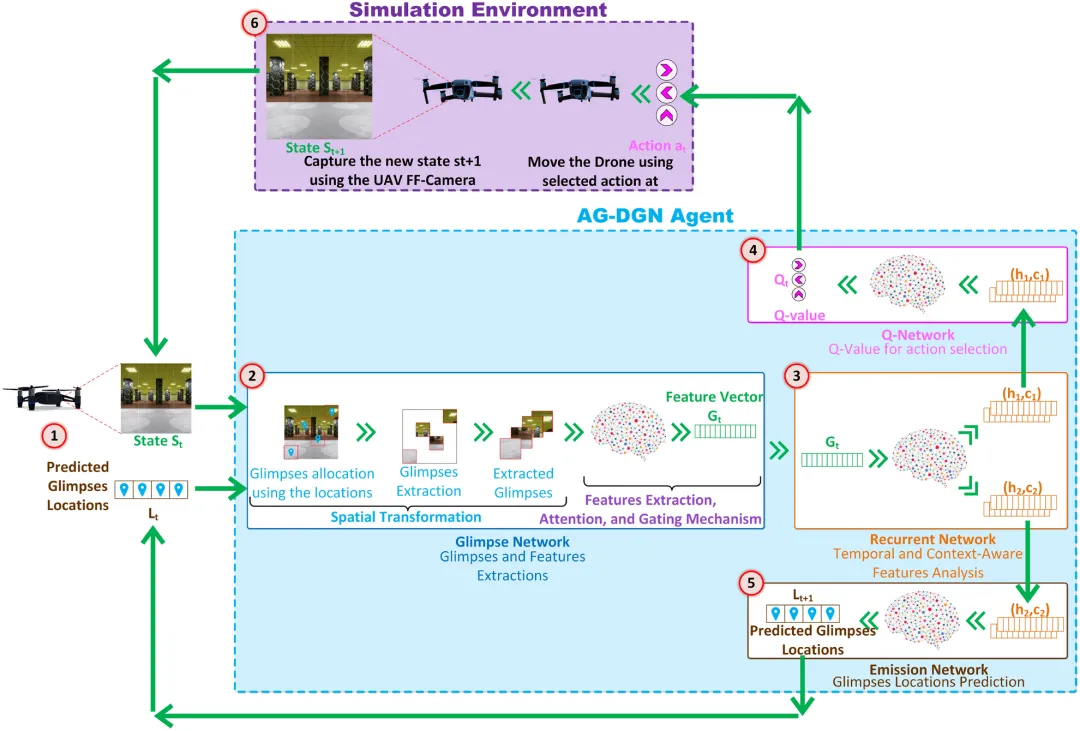
图5 | AG-DGN 系统整体框架。无人机机载摄像头捕获当前状态帧(左上),经 Glimpse 网络提取关键局部特征后,由 LSTM 循环网络进行时序建模,最终由 Q 网络输出动作价值并选择最优飞行指令(上/下/左/右/前进)。
03 总结与展望
纵观这五篇高引论文,一条清晰的演进脉络浮现出来:DRL 正在把无人机从“会飞的工具”变成“会学习的飞行智能体”。
从击败人类冠军的极限竞速,到不依赖地图的野外高速穿行,再到自主协同的多机数据采集——短短五年间,强化学习已经突破了传统方法几十年未能攻克的瓶颈。背后的驱动力,是仿真平台、算法架构和Sim-to-Real技术的同步成熟。
当然,这五篇论文也暴露了当前路线的短板:训练需要数百万次交互、策略缺乏安全可解释性、极端条件下鲁棒性不足。但随着大模型与强化学习的深度融合,以及具身智能的持续推进,一个更值得期待的未来正在浮现:无人机或许将不再只是“被训练的飞行器”,而是能够理解语义、预判风险、自主决策的“空中智能体”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)