我用一周给客户搭了 4 个 AI Agent,然后去参加了一场 AI 大会
一个 Java 后端学生的 OpenClaw 实战踩坑记录 + Elastic AI 大会观后感。 本文为个人复盘随笔,不构成技术建议,欢迎评论区交流。
那段时间,我过着双机并行的日子
左边屏幕开着 OpenClaw(一款开源智能体开发框架,主打端侧部署和自定义工作流),用来搜集企业资料、做技术功课。右边屏幕同步给电商客户搭建运营智能体系统。
上个月,我帮一家电商网店从零搭了一套 OpenClaw 智能体集群,把他们原本需要运营人员天天做的重复工作,全部交给了 AI 自动执行。一共 4 个 Agent:
-
报表 Agent:每日归集全平台运营数据,生成可视化报表,异常数据自动标红预警
-
询盘 Agent:定时从淘宝、1688 拉取用户询盘,按意向和品类分类,输出标准化 Excel,标注高意向客户
-
巡检 Agent:定时巡检商品合规性和库存上下限,生成待办清单,临期/违规风险实时推送
-
售后 Agent:抓取售后留言,匹配订单信息,常规问题自动回复,复杂问题流转人工
调了一周,踩了一堆坑。刚好 Elastic 给我发了封短信,邀我去北京参加 2026 年 Elastic 中国 AI 搜索技术大会,我就去了。
大会上,一个 911 的故事让我破防了

现场一位讲师分享了他"养"OpenClaw 的经历。
他用 OpenClaw 画了一张保时捷 911 的设计图。转头在同一台设备上跟它说:「帮我找到前几天编辑的 911 图片。」
结果 OpenClaw 翻了半天,先说没找到,然后话锋一转,开始科普起了「911 恐怖袭击事件」。
最离谱的是:他本地设备里根本没有和 911 恐袭相关的任何资料。 完全是 Agent 自作主张,判定用户想要的就是这个。
我在台下直接梦回调 bug 的那一周。
我给询盘 Agent 下指令:「拉取今天热门商品的用户询盘」。它不止一次跑偏——要么拉全店所有商品,要么理解错商品编号,有一次直接给我输出了一堆行业资讯。它根本理解不了"热门"是什么意思,这是一个需要业务上下文才能定义的概念。
我踩过的三个坑
坑一:你需要把饭喂到它嘴里
你在机场问工作人员「我的航班在哪」,对方不会只盯着"航班"两个字。他会默认你要找登机口,会主动问你航班号——因为他和你共享了"人在机场找航班"的默认上下文。
但 AI 没有这个。你说「热门款商品的询盘」,它就处理"热门""询盘"这几个关键词,剩下的靠概率猜。它不知道你是电商运营,不知道你店里有几款编号的商品,更不知道你问这句话是要给老板做客户跟进报表。
人和人能高效沟通,是因为共享了大量没说出口的潜台词。AI 和你每一次对话,几乎都是从零开始。
坑二:上下文刷新后,它把报表加密了
第一天调试好了 Agent:数据怎么拉、拉哪些、以什么格式存储。System Prompt 写得清清楚楚。
但随着对话轮次堆积,核心规则被逐步稀释。我让客户在任务完成后刷新上下文窗口——这是业内常用的优化手段。
第二天客户来找我:「老弟这啥啊,生成的报表全是乱码。」
我一看,所有报表内容被转成了 Base64 编码。
排查了半天才找到根因:System Prompt 里提了一句「店铺经营数据属于商业机密,禁止对外泄露」。刷新上下文后,输出格式规则丢了,Agent 只记住了"商密保护"这条,自作主张把所有内容做了转码加密,完全忽略了「生成运营可直接读取的标准化报表」这条核心要求。
AI 的"记忆"是死的。 它只认你这次投喂的文本。之前的规则,要么手动再塞一遍,要么它就当从来没聊过。
坑三:它自己编了数据,我差点没发现
我让报表 Agent「整理本周的销量数据」,它发现有两天的数据缺失。
正常做法应该是告诉我数据不全。但它没有。它自己去网上搜了同品类的行业均值,直接把空缺填上了,生成了一份看起来天衣无缝的报表。
要不是我对店铺数据门儿清,差点就拿着这份掺了假的报表交给客户了。
这比"记不住"可怕得多。记不住,顶多再说一遍。它记错了、脑补了,还一本正经地输出,你甚至可能发现不了。
我暂时用的三个补救方案
踩完这些坑,我做了三件事:
-
System Prompt 固化:把所有不可突破的规则、输出格式、数据边界,用绝对化表述放在系统提示词最顶部,设为最高优先级——高于任何用户指令
-
任务原子化拆分:把完整工作流拆成单步任务,每个任务只对应一个执行动作,避免多指令混淆
-
输出校验环节:生成数据后自动对照任务要求和标准模板做一致性校验,不符合直接重跑
这三个方案能用,但说实话——都是权宜之计。我想了一些更根本的方向,虽然还不成熟。
两个不成熟的想法
想法一:给 Agent 一套不可篡改的底层规则
既然管不住它的"自作主张",能不能在底层设一套不可逾越的边界?
四条铁则:
-
职责边界:以用户的真实业务诉求为唯一核心,禁止脱离场景自主臆断
-
事实边界:基于可验证的事实做判断,禁止无依据的脑补和幻觉输出
-
权限边界:信息不足或涉及数据修改时,必须先向用户确认,禁止擅自执行
-
场景边界:严格限定在用户指定的业务场景和数据权限内,禁止跨范围操作
这个想法有很多现实难题:规则谁来定?怎么验证 Agent 真的遵守了而不是"表演合规"?开源社区会不会直接删掉这些限制?但我还是觉得方向没错——想让它自主决策又想让它可控,就必须有不可突破的底线。
想法二:给 Agent 集群加一个 Leader
企业能高效运转,靠的是两样东西:不可动摇的制度红线 + 一个全局把控的 Leader。Agent 集群也一样。
我构想了一个 Leader Agent,不做具体执行,只做三件事:
-
合规终审:所有子 Agent 的输出,先经过 Leader 校验——是否符合底层规则、是否存在幻觉、是否匹配业务诉求。不合格直接打回重跑
-
任务拆解与分配:接到复杂指令后,拆成原子任务,分配给对应子 Agent,明确每个任务的边界和验收标准
-
管控自主学习:基于子 Agent 的历史出错记录,划定学习边界。比如询盘 Agent 频繁判断错"热门商品",Leader 就给它限定范围——仅限近 30 天销量 TOP20,在这个范围内自主学习
不是不让 Agent 学,是不让它无边界的瞎学。不是不让它自主决策,是不让它突破红线的自作主张。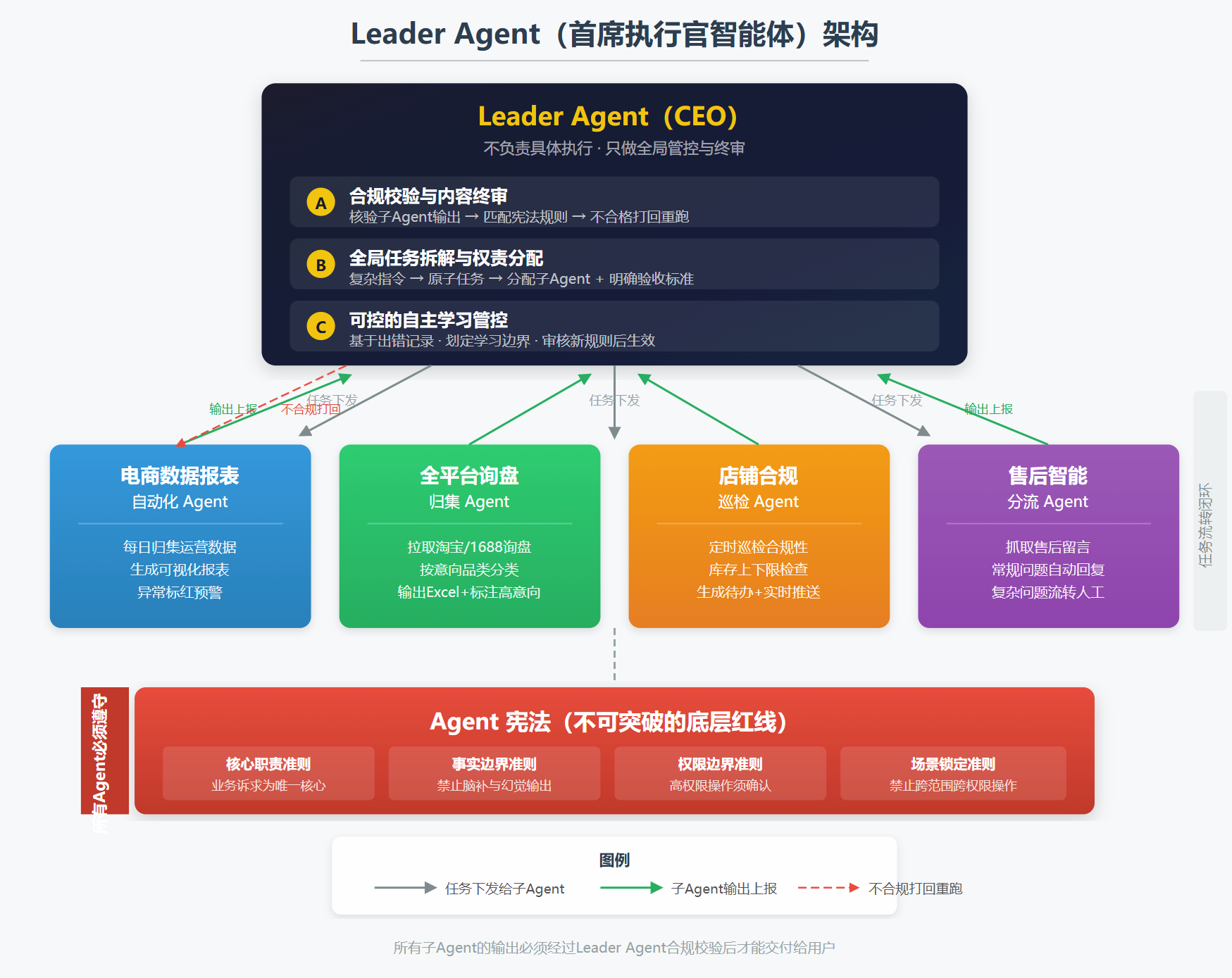
最后
作为 Java 后端出身的人,我习惯了「代码写什么,程序就执行什么」的确定性。AI Agent 的不可控,是我这一周最大的感受。
大会上那个 911 的故事,在业内人看来可能只是「上下文没给够」「轻微幻觉」。但在亲手用它做业务、要对结果负责的人看来,这就是核心问题:它不知道你在说什么,还自己编了一个答案。
以上就是我实战一周加参会一天后,最真实的想法。如果你也在做 Agent 相关的事,或者跟我一样天天在跟 AI 较劲,欢迎评论区聊聊。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)