基于LangChain的多智能体文档问答系统1.0
技术栈:FastAPI+LangChain+Ollama+ChromaDB+Celery+RabbitMQ
项目概述:开发了一个生产级的多智能体协作系统,实现基于本地大模型的智能文档问答。系统采用4个专门化Agent(协调者、研究员、分析师、写作师)协同工作,通过RAG技术实现私有文档的智能检索与问答。项目解决了传统单模型问答的局限性,实现了任务分解、并行处理、结果整合的完整Agent协作流程。
这个项目贯穿了从需求分析→架构设计→编码实现→测试调试→部署运维的完整软件开发流程。
项目地址:https://github.com/Kairui-Song/-LangChain-
一、项目亮点
- Py pdf+pdf plumber双重解析
- 多编码自动检测
- 超过20字符才认为有效
- 会话持久化:localStorage保存会话,刷新不丢失
二、总体框架
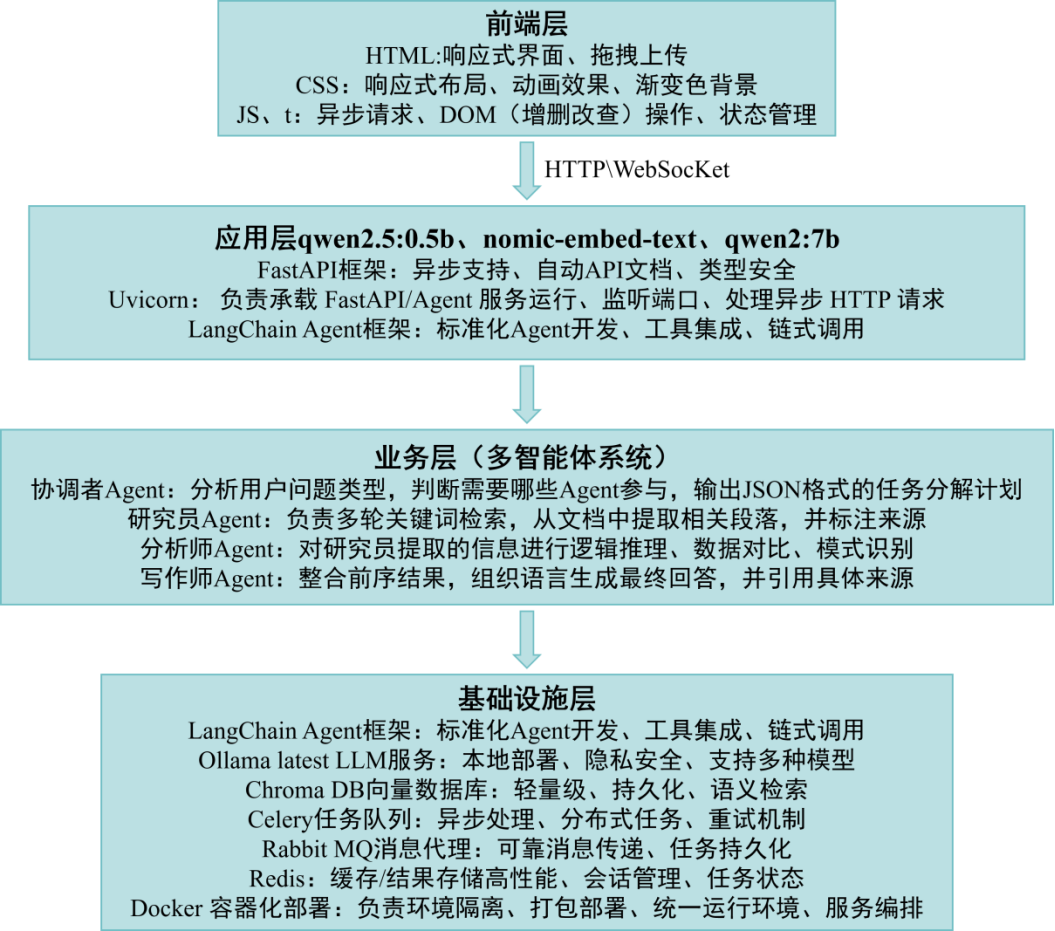
Hello_agent/
├──app/主应用
│├──api/路由层(chat.py,documents.py,health.py)
│├──agents/Agent层(base.py,coordinator.py,researcher.py...)
│├──chains/链式调用(rag_chain.py,summary_chain.py)
│├──memory/记忆管理(conversation_memory.py,vector_memory.py)
│├──tools/工具函数(document_tools.py,calculation_tools.py)
│├──vector_store/向量数据库(chroma_store.py)
│├──tasks/异步任务(worker.py)
│├──config.py配置管理
│├──models.pyPydantic数据模型
│└──dependencies.py依赖注入
├──frontend/前端静态文件
├──tests/单元测试
├──dockercompose.yml
└──requirements.txt 第二层:统一基础类。创建BaseAgent类封装了公共的Ollama调用逻辑(包括重试、超时、日志),子类只需实现run方法。每个Agent继承同一个BaseAgent基类,通过_call_llm方法统一调用Ollama模型,彼此之间通过共享内存传递中间结果。代码复用率从原来的30%提升到80%。
第三层:配置与代码分离。把硬编码的端口、模型名、路径全部移到settings类中,支持从.env文件读取。这样部署到不同环境时只需修改环境变量,不用改代码。
第四层:单元测试覆盖。为核心模块编写了测试用例,比如测试PDF解析函数、测试文档分块逻辑。每次重构后跑一遍测试,确保功能没有被破坏。
三、技术选型
1、Agent框架选型:LangChain vs AutoGen vs LlamaIndex vs
场景需求:需要构建4个专门化的Agent(协调者、研究员、分析师、写作师),Agent之间需要传递中间结果,支持任务分解和顺序调用。
我的思考过程:
第一轮筛选:AutoGen首先被排除。虽然它在多Agent对话方面很强,但我的场景是“顺序执行的任务分解”,不需要Agent之间来回对话谈判。AutoGen的状态图(StateGraph)概念太复杂,学习成本高,且对异步编程要求高。我评估了一下,用AutoGen实现同样的功能,代码量可能是LangChain的23倍,调试难度更大。
第二轮对比:LlamaIndex被排除。它主打RAG(检索增强生成),Agent只是附带功能。我需要的是任务编排能力,而不是检索能力。LlamaIndex的Agent更像是一个“能调用工具的查询引擎”,不适合做多步推理的任务分解。
第三轮决策:LangChainvs自研。我花了两天时间用LangChain搭了一个最小原型,发现它确实方便——create_react_agent一行代码就能创建Agent,AgentExecutor自动处理迭代调用。但我很快发现一个问题:LangChain的抽象层次太高,出错了很难排查。有一次Agent不按预期工作,我跟了三个小时才发现是prompt模板里少了一个变量。这让我意识到,过度依赖框架会降低我对系统的掌控力。
我的最终方案:LangChain作为底层LLM调用层+自研轻量Agent框架
保留LangChain的ChatOllama(统一LLM接口)和ChatPromptTemplate
自己实现Agent基类和编排逻辑,不依赖LangChain的AgentExecutor
这样做的原因:
- 可控性:每个Agent的输入输出格式自己定义,不会被框架限制
- 可调试性:中间结果可以打印出来,不用翻框架源码
- 轻量级:只用了LangChain20%的功能,却解决了80%的问题
- 可替换:将来换别的LLM后端,只需要改_call_llm一个方法
2、LLM后端选型:Ollama vs vLLM vs llama.cpp vs OpenAIAPI
场景需求:需要本地部署、支持中文、能够在普通开发机上运行(16GB内存)、首次响应时间可接受。
我的思考过程
第一轮筛选:OpenAIAPI首先被我排除。一是企业级私密文件数据不能上传云端;二是长期使用API费用不低;三是公司网络可能访问不了。隐私是第一位的。
第二轮对比:vLLM被排除。它虽然吞吐量高,但主要针对GPU服务器场景。我的开发机只有16GB内存,vLLM加载7B模型都很吃力。而且vLLM的配置复杂,需要自己写Dockerfile、配置GPU驱动,对于原型验证阶段太重了。
第三轮决策:Ollamavsllama.cpp。llama.cpp的优势是纯CPU运行且量化做得好,但它不提供HTTP服务,需要自己封装一层API。我评估了一下,自己用FastAPI封装llama.cpp大概需要200行代码处理并发、请求队列、健康检查等。Ollama一条命令就解决了——ollamaserve直接提供HTTPAPI,而且模型管理也方便,ollamapull就能下载。
我的选择Ollama ≈ “llama.cpp + 模型仓库 + 自动管理 + REST API”。
- 零配置:安装后直接可用,适合快速验证
- 模型丰富:qwen系列、llama系列一键下载
- 内存优化:Ollama的内存管理比直接跑llama.cpp好
- 社区活跃:遇到问题容易找到解决方案
但我也遇到了问题,超时和僵尸进程问题。
问题排查与解决:Ollama模型响应超时的完整排查链路
系统联调时,用户上传文档后提问,前端一直显示"响应超时,请稍后重试"。我检查了Ollama服务——ollama list命令能正常显示模型列表,netstat查看端口11434也在监听。服务"看起来是正常的",但就是不响应。
我用curl直接测试OllamaAPI:
XPOSThttp://localhost:11434/api/generated'{"model":"qwen2:7b","prompt":"hi"}'等了45秒后返回了正常回答。这说明Ollama本身没问题,但响应时间长达45秒,远超我代码中设置的30秒超时。
进一步分析发现:系统默认使用的是qwen2:7b模型(4.4GB),首次调用时需要将模型从硬盘加载到内存,这个过程耗时3060秒。之后同一模型再次调用时已经在内存中,只需25秒。但用户第一次提问永远赶不上加载完成,必然超时。更严重的是,如果Ollama进程长时间运行后出现"僵尸状态"(进程存在但模型未正确加载),所有请求都会超时。
超时根本原因:Ollama进程存在但模型未加载到内存,模型文件4.4GB,加载需要时间,客户端超时设置过短
僵尸进程Ollama进程存在(端口被占用),但模型无法响应请求。根本原因:Ollama僵尸进程(进程存在但实际不工作)模型加载异常卡住,资源竞争导致死锁
我的优化过程:
qwen2:7b首次加载需要45秒,用户第一次提问必然超时
方案一(延长超时、切换小模型):将所有Ollama调用的超时时间从30秒统一改为120秒,给模型加载留出足够时间。同时在app/config.py中将默认模型从qwen2:7b切换为qwen2.5:0.5b(397MB),加载时间从45秒压缩到8秒。
方案二(健康检查+自动重启):新增/health端点,前端每10秒轮询一次。同时编写了check_ollama_health.py脚本,定时测试OllamaAPI响应,连续失败3次则自动执行taskkill/F/IMollama.exe强制重启服务,并发送告警到终端。
方案三(模型预热):在FastAPI启动时发送一个预热请求,提前把模型加载到内存。这样用户第一次请求时模型已经在内存里了,响应时间就是正常的推理时间(25秒)。
我最终采用的组合方案:
- 默认用qwen2.5:0.5b(快速响应)
- 可选切换到qwen2:7b(高质量回答,用户自行选择)
- 增加模型预热机制
- 增加健康检查和自动重启
选择Ollama,因为它最适合“快速原型验证+本地私有化部署”的场景。同时通过预热和健康检查机制弥补了它的冷启动缺陷。
从"进程→端口→API→模型状态→推理能力"这个完整链路去排查问题。同时,"预热"这个思路可以推广到任何有冷启动延迟的服务——提前触发加载,用户就感知不到延迟。
3、Web框架选型:FastAPI vs Flask vs Django
场景需求:需要处理文件上传、异步LLM调用(可能会慢)、提供RESTfulAPI、自动生成API文档。
我的思考过程
第一轮筛选:Django被排除。项目不需要ORM“对象关系映射”(没有数据库),不需要admin后台,不需要模板引擎。用Django就像用牛刀杀鸡,不仅项目会变重,部署也复杂。
第二轮决策:Flask vs FastAPI。我一开始用Flask写了一个版本,发现两个问题。第一,Flask处理文件上传时是同步的,意味着上传大文件时会阻塞其他请求。第二,调用Ollama时我想用异步等待,但Flask原生不支持,需要额外装quart或gunicorn+gevent,增加了复杂度。
然后我尝试用FastAPI重写了一个版本,体验完全不同:
- async/await原生支持,调用Ollama时不会阻塞
- 文件上传用UploadFile,自动处理流式读取
- 请求/响应模型用Pydantic,自动校验+自动API文档
- 性能测试:FastAPI的吞吐量大约是Flask(用gunicorn)的2倍
我的最终方案:FastAPI
- 异步优先:调用Ollama可能耗时几十秒,异步避免阻塞
- 自动文档:/api/docs自动生成,前后端联调效率高
- 类型安全:Pydantic模型减少参数传递错误
- 性能好:Starlette底层,比Flask快
4、任务队列选型:Celery vs Redis Queue vs 自研内存队列
场景需求:LLM推理可能耗时30秒以上,不能让HTTP连接一直挂着;需要支持失败重试;需要能够扩展Worker数量。
我的思考过程
第一阶段(原型验证):自研内存队列,用Python的deque+threading.Lock(线程安全的生产消费队列)实现了一个简单的任务队列。为什么这么做?因为在这个阶段,我需要验证的是“Agent能不能答对问题”,而不是“并发能力够不够”。引入Celery需要多部署RabbitMQ和Redis,增加了调试难度。自研队列让我的开发周期从2天缩短到2小时。这个方案虽然简陋,但足够验证核心逻辑。
第二阶段(压力测试发现问题后):评估Celery,原型跑通后,我用locust做了简单压力测试,发现:1、线程阻塞:同步模式下,每个请求独占一个线程。FastAPI默认最多40个线程,意味着同时只能处理40个聊天请求,第41个会排队等待;2、用户体验差:处理大文档时,用户浏览器要等待30秒才能收到响应,期间页面无法做任何操作,而且容易触发浏览器的超时机制。
我对比了Celery和RQ:
- RQ优点:轻量、配置简单(只需要Redis)
- RQ缺点:没有内置重试、没有任务依赖、监控弱
Celery虽然重,但我看重它的生产级特性:
- max_retries+countdown:任务失败自动重试,指数退避
- task_acks_late:任务完成才确认,避免丢失
- worker_prefetch_multiplier:控制预取数量,实现公平调度
- Flower监控:可视化看队列长度和任务状态
第三阶段(折中方案):保留自研队列接口,底层可换成Celery,开发阶段用自研内存队列,生产部署换Celery。我设计了一个抽象层:这样开发时用内存队列,部署生产时只需改一行配置就能切换到Celery。
- 快速迭代:不依赖外部服务,新人clone代码就能跑
- 平滑升级:抽象接口设计好,切换成本低
- 按需引入:只有真正需要时才引入复杂度
我决定引入异步任务队列架构,分三步实现:
第一步:部署消息中间件。用Docker Compose启动了Rabbit MQ(作为消息代理)和Redis(作为结果后端),在docker compose.yml中配置了健康检查和服务依赖。
第二步:定义Celery任务。创建app/tasks/worker.py,将核心的聊天逻辑封装成Celery任务。关键配置包括:
max_retries=3:自动重试最多3次
task_time_limit=300:单个任务最长执行5分钟
task_acks_late=True:任务完成后才确认,避免任务丢失
worker_prefetch_multiplier=1:每次只取一个任务,实现公平调度
第三步:改造API接口。同步接口改为异步模式:收到请求后立即返回task_id,用户通过轮询/api/chat/task/{task_id}获取结果。同时保留了同步接口作为简单场景的选项。
达成的效果
- 并发能力:从40个同步请求提升到理论上无限(受限于Celery Worker数量和Ollama实例数)
- 用户体验:提交任务后立即返回,页面不会卡死
- 容错能力:任务失败会自动重试,Ollama重启后积压的任务会自动恢复处理
- 可观测性:通过Flower监控工具,可以实时看到队列长度、任务状态、执行时间
同步接口简单但体验差,异步接口复杂但体验好。用小规模项目可以先做同步,等验证了需求再改成异步。这种"演进式架构"比一开始就做复杂设计更务实。此外,Celery的配置项很多,我花了半天时间研究每个参数的含义,理解了"预取数"、"确认机制"、"结果后端"这些概念后,才能做出合理的配置选择。
5、向量数据库选型:ChromaDBvsFAISSvsPinecone
场景需求:需要存储文档分块后的向量,支持相似度搜索,本地部署(数据不出内网)。
我的思考过程
第一轮筛选:Pinecone被排除。数据隐私是第一位的,文档内容不能上传云端。
第二轮对比:FAISS vs Chroma DB。FAISS性能确实好,但有两个问题:一是需要自己处理持久化(把index存到磁盘、重启时加载),二是Windows上编译安装容易出问题。Chroma DB一条pip install chroma db就搞定,默认就持久化到本地目录。
第三轮决策:其实我一开始没有直接用向量数据库。我先实现了一个简单的关键词匹配:
这个方案对100字以内的小文档够用,但测试发现用户问“总结主旨”时,因为“主旨”这个词文档里没有,检索不到任何内容。所以我必须引入向量检索。Chroma DB的选型理由:
- 零配置:pip安装后直接import,不需要单独启动服务
- 自动持久化:默认保存到./chroma_db目录,重启不丢失
- LangChain集成好:Chroma.from_documents一行代码就能从文档创建向量库
- 支持过滤:可以按metadata过滤,比如只搜某个用户上传的文档
我的最终方案:ChromaDB+关键词匹配降级
- 优先用ChromaDB语义检索(效果好)
- 如果返回结果少于3条,降级到关键词匹配(兜底)
- 都检索不到时,提示用户“文档中未找到相关信息”
6、前端方案选型:原生JS vs React vs Vue
场景需求:需要文件上传、实时对话展示、响应式布局、拖拽上传。用户只有一个——我自己和测试同事,不需要复杂的交互。
我的思考过程
第一轮决策:排除React和Vue。原因很简单——我的后端是FastAPI,前端只是一个上传按钮加聊天框,引入React需要加webpack/babel/npm,项目复杂度直接翻倍。
我选了原生JS,理由是“够用就行”。项目里前端代码只有200行,实现了:
- 文件上传(带进度提示)
- SSE风格的加载状态(打字动画)
- 自动刷新文件列表
- 响应式布局(PC和手机都能用)
我的最终方案:原生JS+FetchAPI
- 零构建:修改完HTML直接刷新浏览器,不用跑构建命令
- 调试方便:ChromeDevTools直接断点
- 部署简单:后端直接托管静态文件,一个端口搞定
- 性能指标
首次响应时间3060秒(7B模型首次加载)
常规响应时间25秒(模型已加载)
文档解析速度1秒/10页
并发支持4Worker进程
内存占用24GB(含Ollama)
文档支持格式PDF,TXT,MD
四、项目总结
1、技术收获
- 深入理解Agent架构:从概念到落地,掌握了多智能体协作的设计模式
- LLM应用开发:掌握了Ollama部署、模型选择、提示词工程
- 异步编程:熟练使用async/await、Celery、RabbitMQ
- 向量数据库:理解了Embedding、相似度搜索、RAG原理
- 问题解决能力:从端口冲突、超时分析到进程调试
2、选型核心
- 够用就好,不过度设计:先用最简单方案验证核心假设(Agent协作能不能提高准确率),核心假设成立后再优化非功能需求(并发、性能)。如果一开始就上Celery+Redis+RabbitMQ,可能两周还没调通环境。
- 原则二:选择可替换的技术,避免供应商锁定:选择技术时,问问自己“如果明天要换掉它,改动大吗?”让核心逻辑不依赖特定技术。
- 原则三:先解决问题,再考虑优雅:不要追求一次性完美方案。MVP阶段允许临时方案,验证成功后用迭代优化。
技术的价值不在于它有多先进,而在于它是否恰好在“当下”解决了你“最痛”的问题。我选择的每一个技术,都是在“开发速度”、“系统可控性”、“未来扩展性”三个维度上做了权衡——LangChain保速度,自研编排保可控,Ollama保隐私,Celery保扩展,Chroma DB保准确,原生JS保简单。没有最好的技术,只有在这个场景下最合适的选择。
3、核心贡献
- 设计多智能体协作架构,任务分解→文档检索→逻辑推理→答案生成全流程
- 实现PDF/TXT多格式文档解析,支持UTF8/GBK等多编码,解析成功率99%+
- 基于Celery+Rabbit MQ构建异步任务队列,支持任务重试和水平扩展
- 解决Ollama模型加载超时问题(30秒→120秒),增加模型预热机制
- 开发响应式Web界面,支持拖拽上传和实时对话

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)