数据结构-带你详细解析二叉树-堆
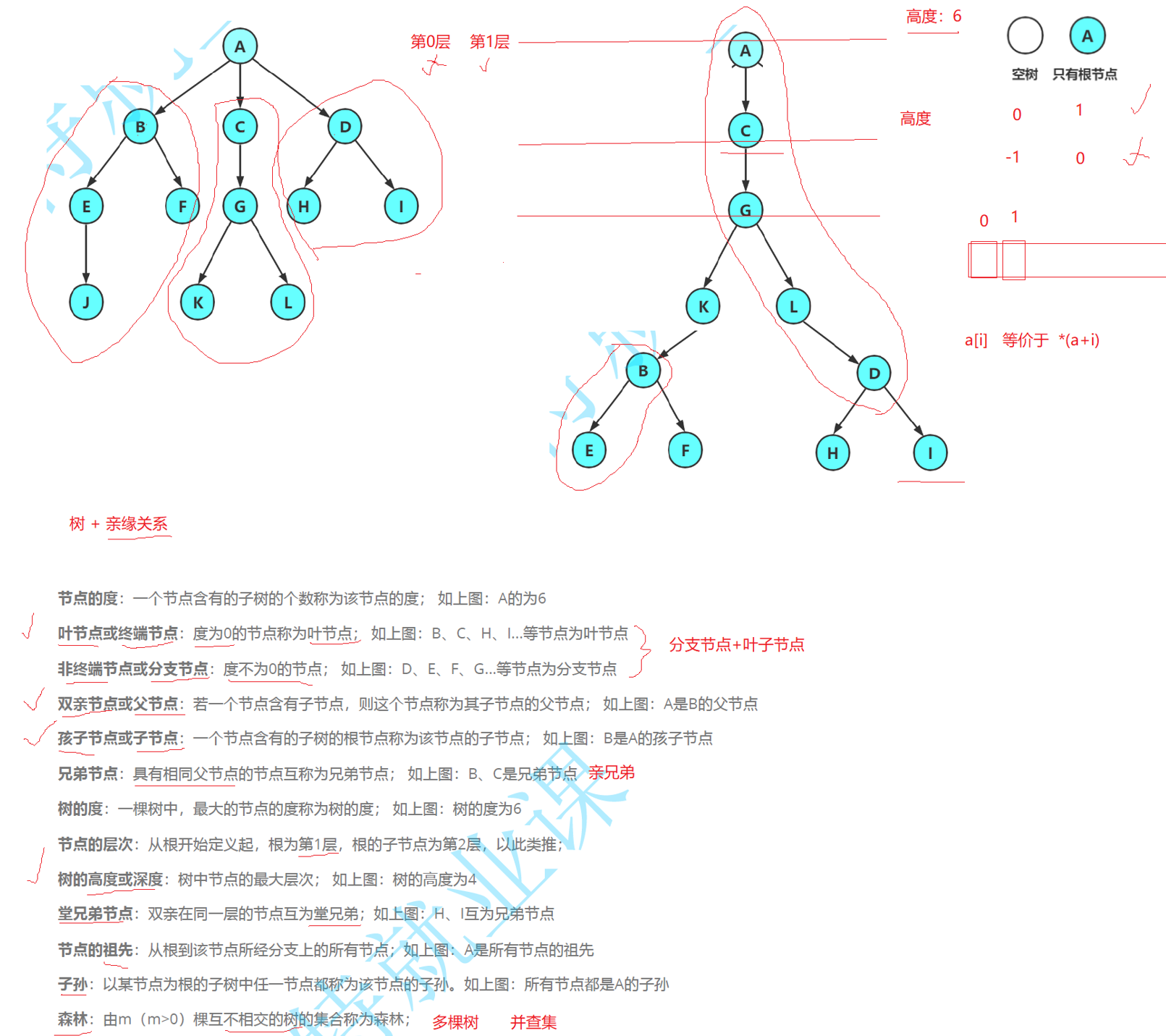
我们先来了解什么是二叉树?
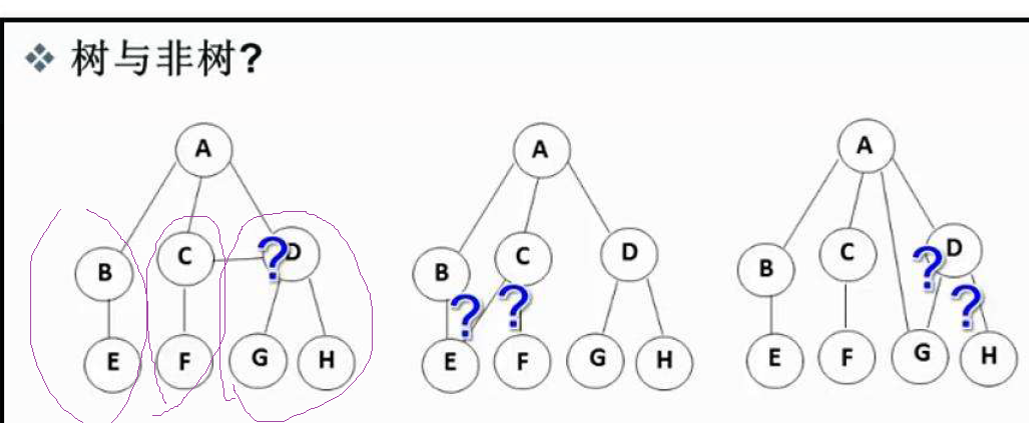
如何判断一颗树
树一定数单个父亲带着多个孩子
二叉树:每个节点最多只有 2 个子节点(左孩子、右孩子),不能有 3 个及以上。
- 左边叫左子树,右边叫右子树,左右不能互换(有序)。
- 节点:数据 + 左指针 + 右指针

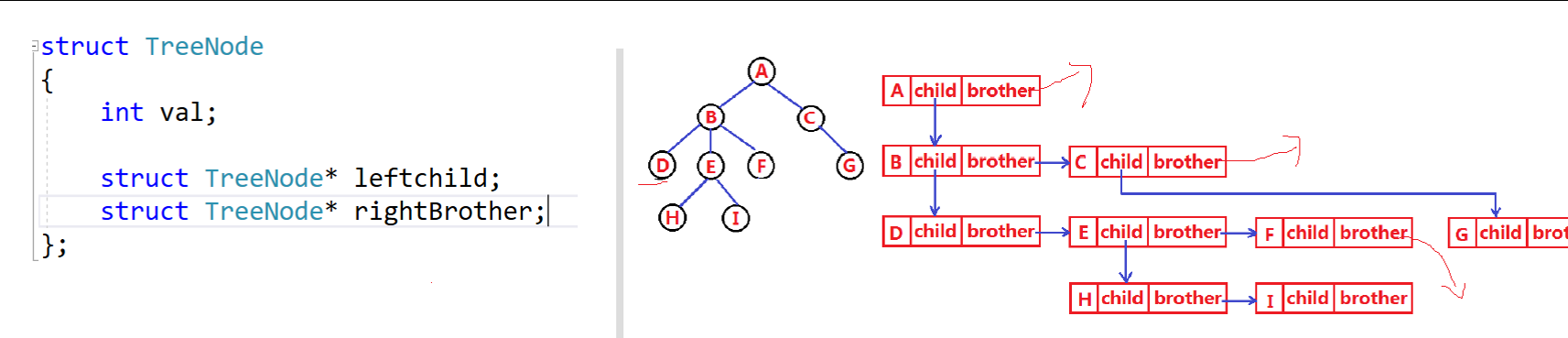
那么二叉树是逻辑结构
内层物理结构是什么呢?
树实际上是数组排列
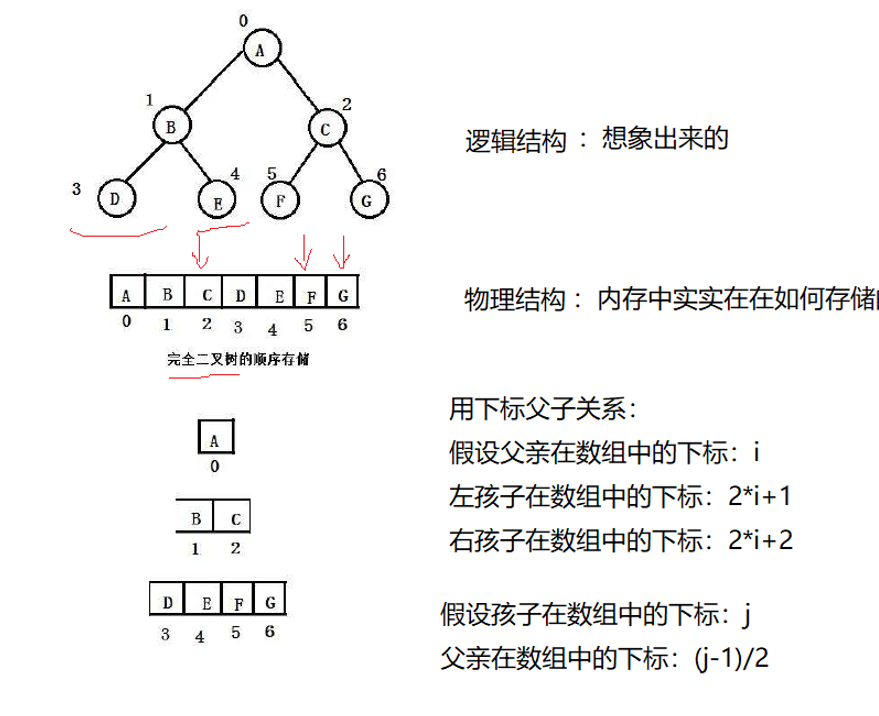
测试当前数组: [2, 4] 下标0(值2)的左孩子是下标1(值4) → 2*0+1=1
下标1(值4)的父节点是下标0(值2) → (1-1)/2=0
当前数组: [1, 2, 6, 4, 3] 下标1(值2)的右孩子是下标4(值3) → 2*1+2=4
下标4(值3)的父节点是下标1(值2) → (4-1)/2=1
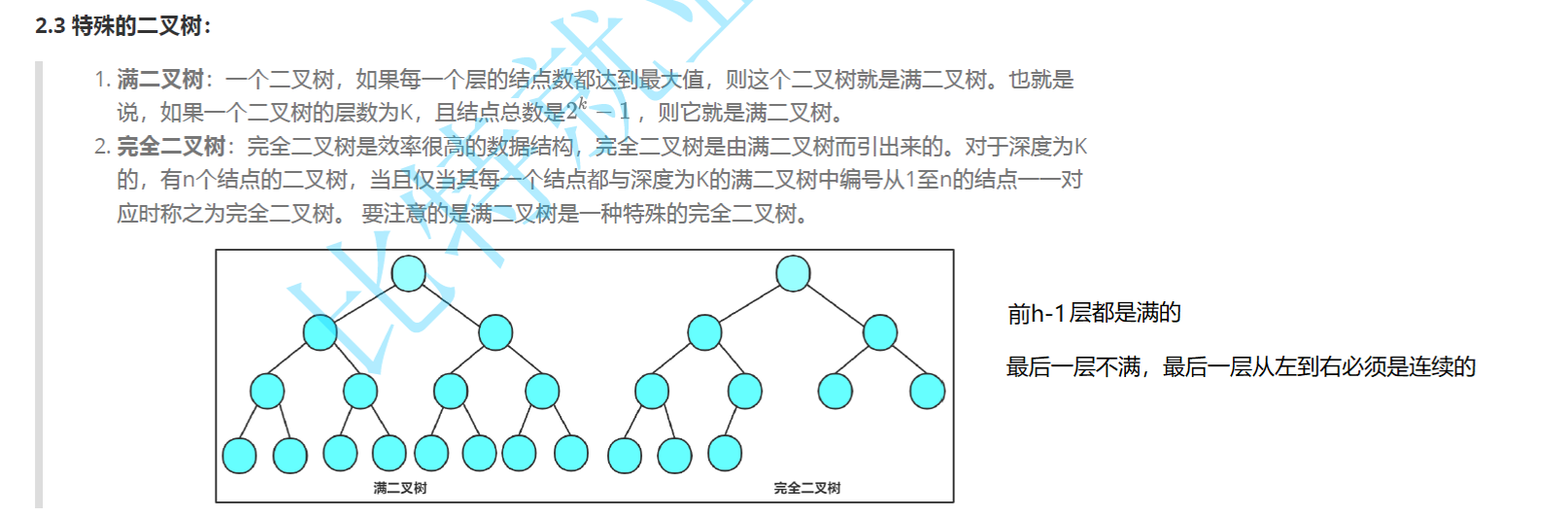
① 满二叉树
每一层节点都拉满,没有空缺。
- 高度为 h,节点总数:2h−1
② 完全二叉树
按顺序从上到下、从左到右放节点,最后一层可以不满,但只能右边缺
那么二叉树中怎么进行排列大小呢?
小堆结构和大堆结构可以解决
小堆的特点就是每一个节点的父亲都比他的孩子小
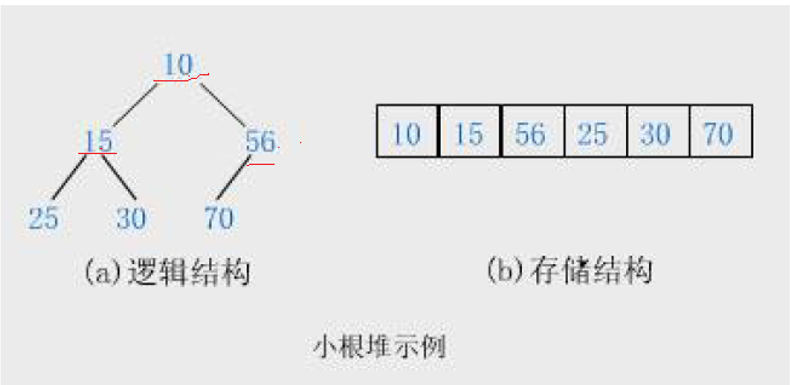
下面是小堆的实现
// 核心:向下调整(删除堆顶后,维持小堆结构)
// a: 堆数组, size: 有效元素个数, parent: 要调整的父节点下标
void AdjustDown(HPDataType* a, int size, int parent)
{
// 先假设左孩子是更小的那个(对应你图里的 2*i+1)
int child = parent * 2 + 1;
while (child < size)
{
// 如果右孩子存在,且右孩子 < 左孩子 → 选择更小的右孩子
if (child + 1 < size && a[child + 1] < a[child])
{
child++; // 切换到右孩子下标(对应你图里的 2*i+2)
}
// 小堆规则:孩子 < 父节点 → 交换
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
// 交换后,继续向下检查
parent = child;
child = parent * 2 + 1;
}
else
{
// 满足小堆规则,无需调整
break;
}
}
}// 核心:向上调整(插入元素后,维持小堆结构)
// a: 堆数组, child: 新插入元素的下标
void AdjustUp(HPDataType* a, int child)
{
// 计算父节点下标(对应你图里的 (j-1)/2)
int parent = (child - 1) / 2;
// 孩子下标>0,说明还没到根节点
while (child > 0)
{
// 小堆规则:孩子 < 父节点 → 交换
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
// 交换后,继续向上检查
child = parent;
parent = (child - 1) / 2;
}
else
{
// 满足小堆规则,无需调整
break;
}
}
}- 父节点下标
i→ 左孩子2*i+1、右孩子2*i+2 - 孩子节点下标
j→ 父节点(j-1)/2 - 小顶堆的核心是父≤子,堆顶永远是最小值,依赖完全二叉树的数组下标规则实现。
- 插入用向上调整,删除堆顶用向下调整,两个核心函数是实现小堆的关键。
- 小堆的插入、删除时间复杂度都是 \(O(logN)\),效率远高于普通数组排序。
// 辅助函数:交换两个元素(地址传递) void Swap(HPDataType* x, HPDataType* y) { HPDataType tmp = *x; *x = *y; *y = tmp; } // 核心:向上调整(插入元素后,维持大堆结构) // 【和小堆的唯一区别:把 < 改成 >】 void AdjustUp(HPDataType* a, int child) { int parent = (child - 1) / 2; while (child > 0) { // 大堆规则:孩子 > 父节点 → 交换 if (a[child] > a[parent]) { Swap(&a[child], &a[parent]); child = parent; parent = (child - 1) / 2; } else { break; } } } // 核心:向下调整(删除堆顶后,维持大堆结构) // 【和小堆的唯一区别:把 < 改成 >】 void AdjustDown(HPDataType* a, int size, int parent) { int child = parent * 2 + 1; // 先假设左孩子更大 while (child < size) { // 如果右孩子存在,且右孩子 > 左孩子 → 选择更大的右孩子 if (child + 1 < size && a[child + 1] > a[child]) { child++; } // 大堆规则:孩子 > 父节点 → 交换 if (a[child] > a[parent]) { Swap(&a[child], &a[parent]); parent = child; child = parent * 2 + 1; } else { break; } } }这个是大堆的实现,只改变了父子的符号
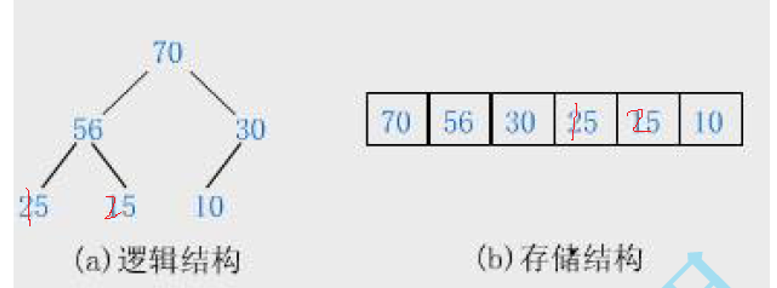
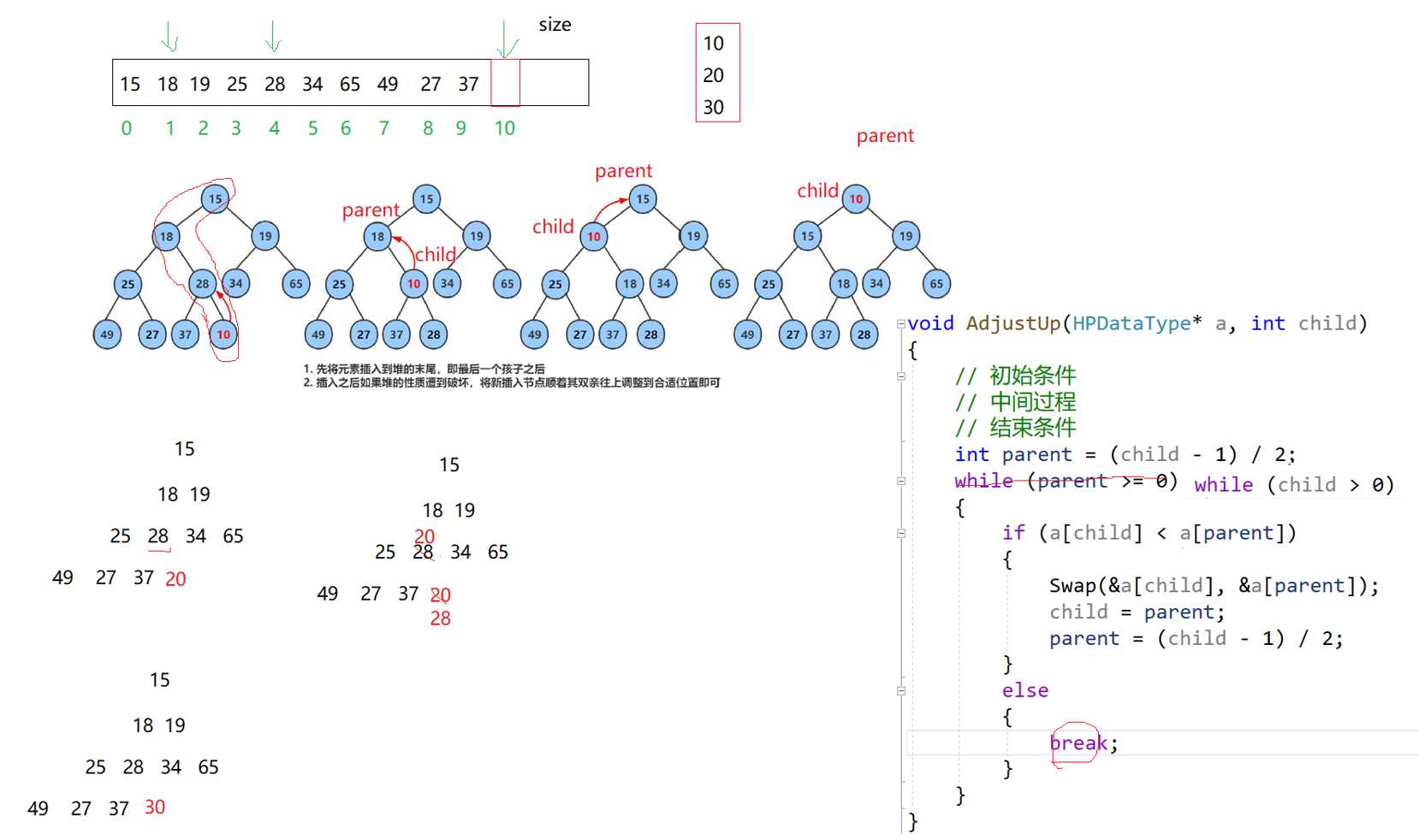
二、完整走一遍图里的流程(插入 10)
步骤 1:插入末尾
数组最后插入 10,child=10,parent=(10-1)/2=4
a[child]=10,a[parent]=28- 小堆规则:孩子 < 父节点,必须交换交换后:10 跑到下标 4,28 跑到下标 10
步骤 2:继续往上
现在 child=4,重新算父:parent=(4-1)/2=1
a[child]=10,a[parent]=18- 10 < 18,继续交换交换后:10 跑到下标 1,18 跑到下标 4
步骤 3:继续往上
child=1,父:parent=0
a[child]=10,a[parent]=15- 10 < 15,继续交换交换后:10 跑到下标 0(堆顶),15 跑到下标 1
步骤 4:结束
child=0,到根节点,循环停止
void AdjustUp(HPDataType* a, int child)
{
// 1. 先找到新节点的父节点
int parent = (child - 1) / 2;
// 2. 循环条件:child>0 只要不是根节点,就继续往上比
while (child > 0)
{
// 3. 小堆规则:孩子比父亲小 → 交换
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
// 交换后,child移到父位置,继续往上
child = parent;
parent = (child - 1) / 2;
}
else
{
// 4. 孩子≥父亲,满足小堆,不用调了,直接退出
break;
}
}
}接下来到了最难理解的环节,删除堆
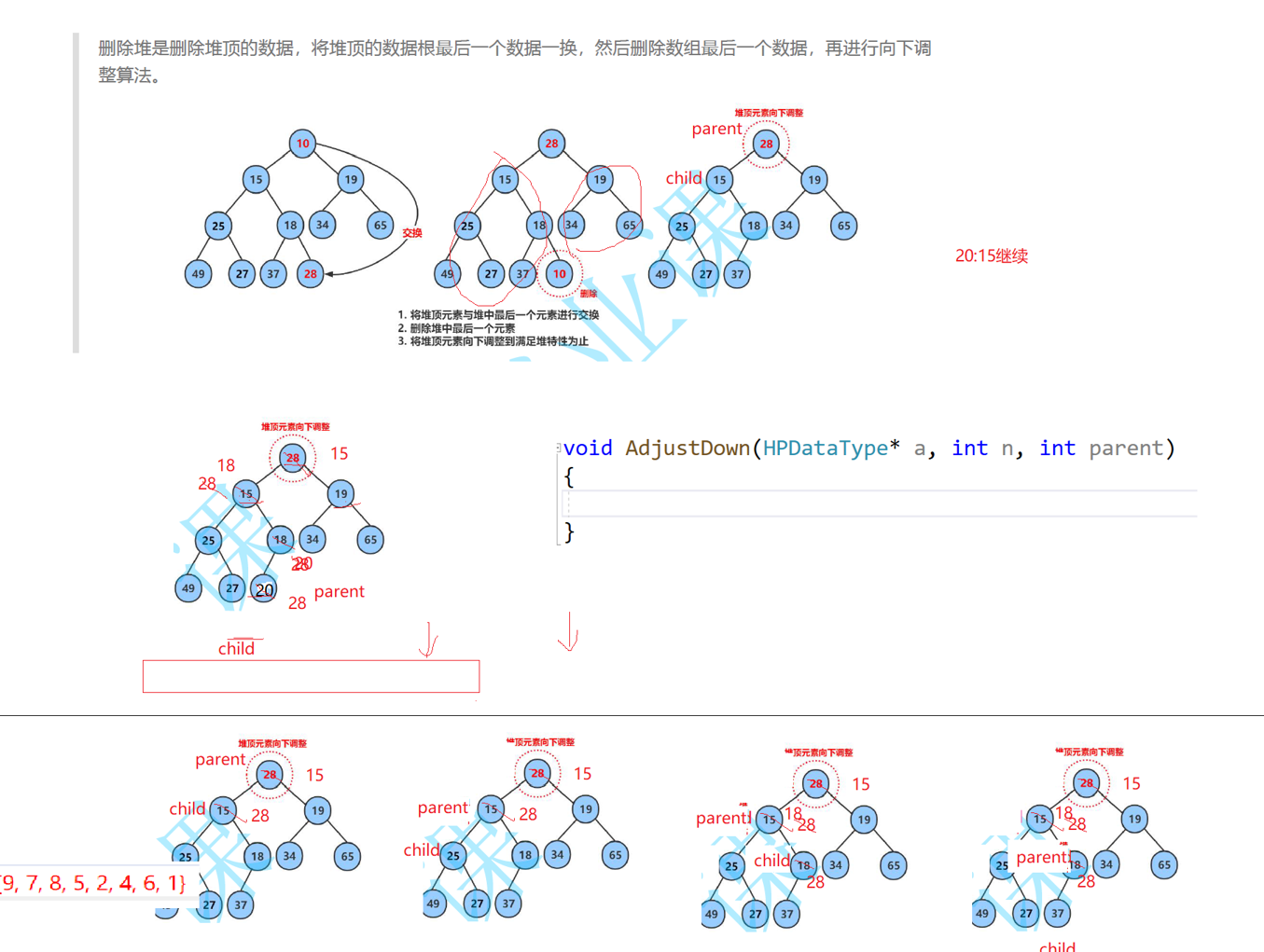
- 交换:堆顶(下标 0,值 10) ↔ 数组最后一个元素(下标 10,值 28)
- 删除:有效个数
size--,直接删掉原来的堆顶 10(现在在数组末尾) - 向下调整:把新堆顶 28,往下和孩子比较,一路交换到正确位置
void HeapPop(Heap * hp) {
assert(hp);
assert(hp->_size > 0);
// 堆顶和最后一个元素交换
Swap(&hp->_a[0], &hp->_a[hp->_size - 1]);
hp->_size--;
// 向下调整
AdjustDown(hp->_a, hp->_size, 0);
}
初始状态
交换后堆顶是 28,需要向下调整
parent = 0(堆顶)- 左孩子
child = 2*0+1 = 1(值 15),右孩子2*0+2=2(值 19)
步骤 1:选更小的孩子
小堆规则:找左右孩子里更小的那个
- 左 15 < 右 19 → 选左孩子
child=1 - 父 28 > 子 15 → 交换 28 和 15
- 现在
parent=1,继续向下
步骤 2:继续找更小孩子
parent=1,左孩子 = 3(25),右孩子 = 4(18)
- 右 18 < 左 25 → 选右孩子
child=4 - 父 28 > 子 18 → 交换 28 和 18
- 现在
parent=4,继续向下
步骤 3:到底结束
parent=4,孩子都比 28 大,满足小堆规则,停止调整
#include"test.c"
void HeapInit(Heap* php) {
assert(php);
php->_a = NULL;
php->_capacity = php->_size = 0;
}
void HeapDestory(Heap* hp) {
assert(hp->_a);
assert(hp);
free(hp->_a);
hp->_a = NULL;
hp->_capacity = hp->_size = 0;
}
void Swap(HPDataType* x, HPDataType* y) {
int tt =* x;
*x = *y;
*y = tt;
}
void Adjustup(HPDataType* a, int child) {
int parent = (child - 1) / 2;
while (child > 0) {
if (a[child] > a[parent]) {
Swap(&a[child], &a[parent]);
child = parent;
parent = child;
}
else {
break;
}
}
}
void HeapPush(Heap* hp, HPDataType x) {
assert(hp->_a);
assert(hp);
if (hp->_size == hp->_capacity) {
int newcapacity = hp->_capacity == 0 ? 4 : 2 * hp->_capacity;
int temp = (HPDataType*)realloc(hp->_a, newcapacity * sizeof(HPDataType));
if (temp == NULL) {
perror(temp);
}
hp->_a = temp;
hp->_capacity = newcapacity;
}
hp->_a[hp->_size] = x;
hp->_size++;
Adjustup(hp->_a, hp->_size - 1);
}
void AdjustDown(HPDataType * a, int size, int parent) {
int child = parent * 2 + 1;//假设左孩子小
//接下来判断左右孩子那个小
if (child + 1 < size || a[child + 1] < a[child]) {
child++;
}
if (a[child] < a[parent]) {
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else {
return;
}
}
void HeapPop(Heap * hp) {
assert(hp);
assert(hp->_size > 0);
// 堆顶和最后一个元素交换
Swap(&hp->_a[0], &hp->_a[hp->_size - 1]);
hp->_size--;
// 向下调整
AdjustDown(hp->_a, hp->_size, 0);
}
//取对顶数据
HPDataType HeapTop(Heap* hp) {
assert(hp->_a);
assert(hp->_size > 0);
return hp->_a[0];
}
int HeapSize(Heap* hp) {
assert(hp);
return hp->_size;
}
int HeapEmpty(Heap* hp) {
assert(hp);
return hp->_size == 0;
}
int main() {
Heap hp;
HeapInit(&hp);
// 插入数据
HeapPush(&hp, 4);
HeapPush(&hp, 2);
HeapPush(&hp, 6);
HeapPush(&hp, 1);
HeapPush(&hp, 3);
// 依次弹出堆顶(小顶堆 → 升序输出)
while (!HeapEmpty(&hp)) {
printf("%d ", HeapTop(&hp));
HeapPop(&hp);
}
printf("\n");
HeapDestory(&hp);
return 0;
}堆的建立
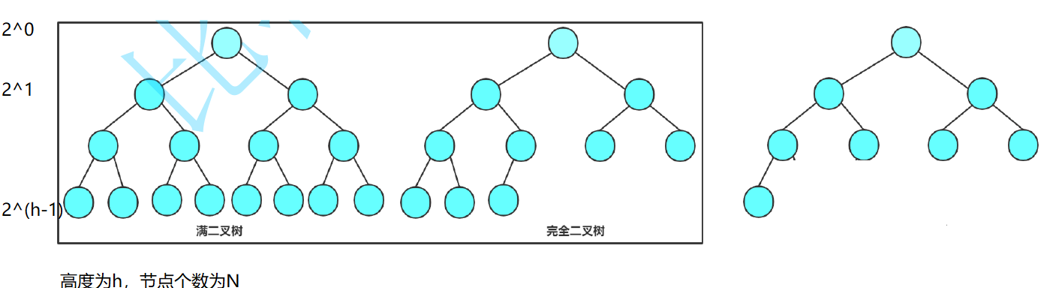
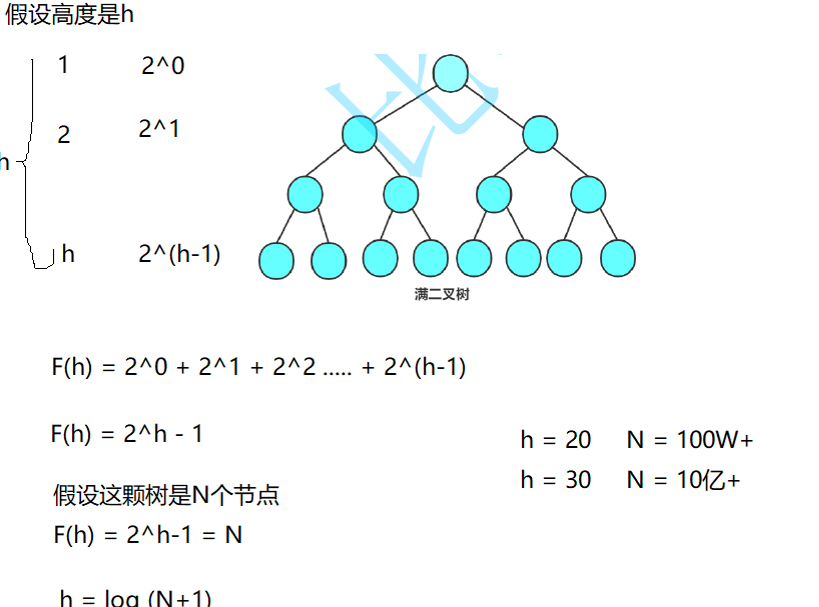
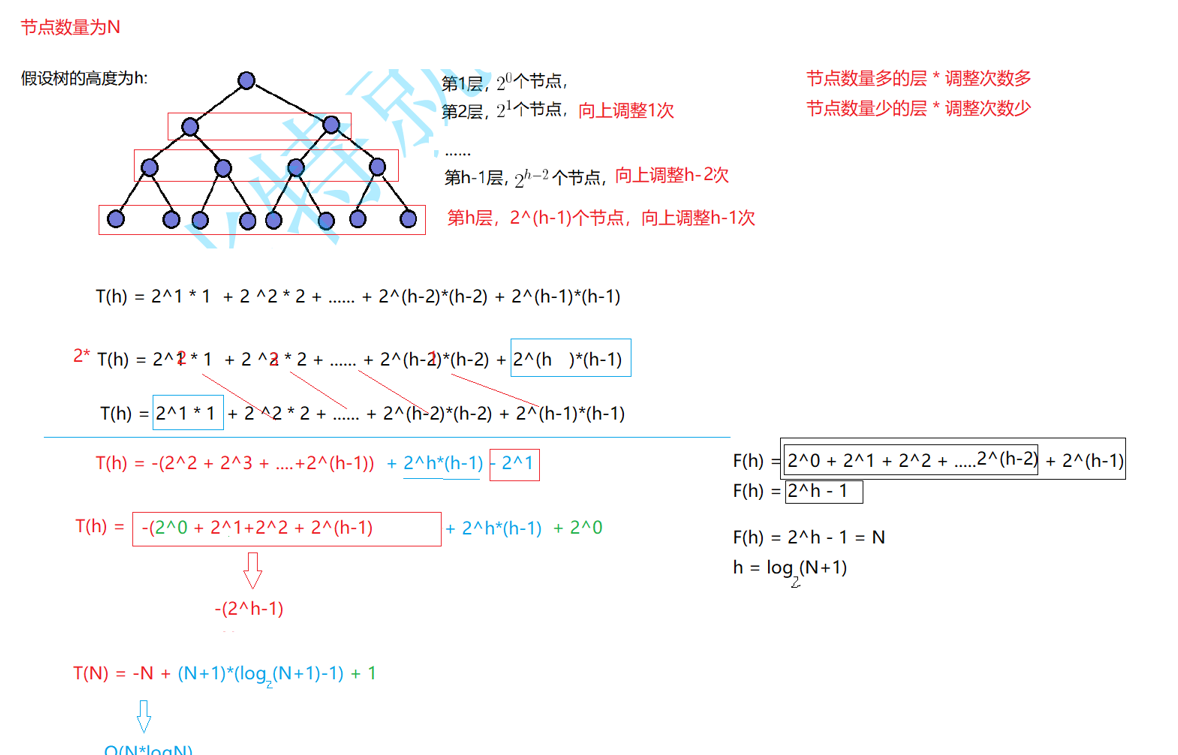
满二叉树的节点数F(h)=2*0+2*1+.....+2*(h-1);然后进行等比数列求和2h−1=N
求出满状态下
高度:
\(h=\log_2(N+1)\)
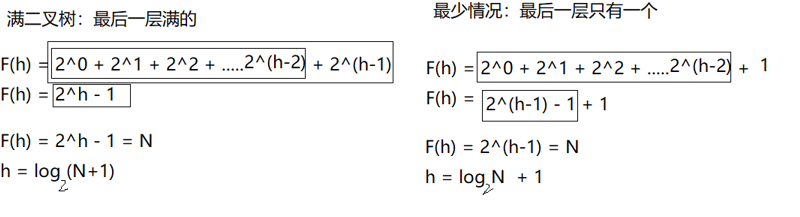
那么完全二叉树和他区别在哪里呢?
完全二叉树的为什么叫完全二叉树?因为最后一层没有排满,
(2)完全二叉树最少节点(最后一层只有 1 个)
\(F(h)=2^{h-1}\)
高度:
\(h=\log_2N+1\)
downdui
1. 向下调整(建堆,下沉)—— 时间复杂度 O (N)
原理对对倒数第二层开始进行调整最后一层叶子节点不参与建堆调整,
先看节点数
- 第 1 层(根节点):\(2^0\) 个节点
- 第 2 层:\(2^1\) 个节点
- ……
- 第 i 层:\(2^{i-1}\) 个节点
- 第 \(h-1\) 层:\(2^{h-2}\) 个节点
步骤 1:调整倒数第二层最右侧节点 2
plaintext
3
/ \
1 2 ← 开始调整这里
/ \ / \
5 4 7 6
/
0
2 和孩子 7、6 比,7 最大,交换
plaintext
3
/ \
1 7
/ \ / \
5 4 2 6
/
0
调整完成,只向下 1 次
步骤 2:调整倒数第二层左侧节点 1
plaintext
3
/ \
1 7 ← 调整完
/ \ / \
5 4 2 6
/
0
1 和孩子 5、4 比,5 最大,交换
plaintext
3
/ \
5 7
/ \ / \
1 4 2 6
/
0
调整完成,只向下 1 次
步骤 3:调整根节点 3(第一层)
plaintext
3 ← 最后调整根节点
/ \
5 7
/ \ / \
1 4 2 6
/
0
3 和孩子 5、7 比,7 最大,交换
plaintext
7
/ \
5 3
/ \ / \
1 4 2 6
/
0
3 继续向下,和孩子 2、6 比,6 最大,交换
plaintext
7
/ \
5 6
/ \ / \
1 4 2 3
/
0
根节点一共向下 2 次
✅ 建堆完成,最终大顶堆:
plaintext
7
/ \
5 6
/ \ / \
1 4 2 3
/
0
- 第 1 层(根):\(2^0\) 个节点,最坏向下调整 \(h-1\) 次
- 第 2 层:\(2^1\) 个节点,最坏向下调整 \(h-2\) 次
- ……
- 第 \(h-1\) 层:\(2^{h-2}\) 个节点,最坏向下调整 1 次
- 比较来看节点数上面是a次方,那么就要向下移动h-(a+1)层
- 上层节点少,但调整次数多;下层节点多,但调整次数少,最终总和是线性级。
-
二、举例画图:8 个节点数组
[3,1,2,5,4,7,6,0]建大顶堆树初始结构(数组直接映射完全二叉树)
plaintext
3 / \ 1 2 / \ / \ 5 4 7 6 / 0 - 总高度 h=4
- 叶子节点:
5、4、7、6、0→ 最后一层,不用调整 - 要调整的节点:
1、2、3(倒数第二层及以上) -
3. 错位相减法计算(核心推导)
第一步:原式 × 2
\(2T(h)=2^1(h-1)+2^2(h-2)+2^3(h-3)+…+2^{h-2}·2+2^{h-1}·1 \quad ①\)第二步:原式 - ①式(错位相减)
\(\begin{align*} 2T(h)-T(h)&=\big[2^1(h-1)+2^2(h-2)+…+2^{h-1}·1\big] - \big[2^0(h-1)+2^1(h-2)+…+2^{h-2}·1\big]\\ T(h)&= -2^0(h-1)+2^1+2^2+…+2^{h-2}+2^{h-1} \end{align*}\)第三步:对等比数列求和
等比数列公式:\(2^1+2^2+…+2^{h-1}=2^h-2\)代入化简:
\(\begin{align*} T(h)&= -(h-1)+(2^h-2)\\ &=\boldsymbol{2^h - h -1} \end{align*}\)
4. 把高度 h 换成节点总数 N
满二叉树节点总数:
\(N=2^h-1 \quad \Rightarrow \quad 2^h=N+1,\quad h=\log_2(N+1)\)代入 \(T(h)\):
\(\begin{align*} T(N)&=(N+1)-\log_2(N+1)-1\\ &=\boldsymbol{N-\log_2(N+1)} \end{align*}\)复杂度结论
\(T(N)=N-\log_2(N+1)\),低阶项 \(\log_2(N+1)\) 可忽略
\(\boldsymbol{T(N)=O(N)}\) 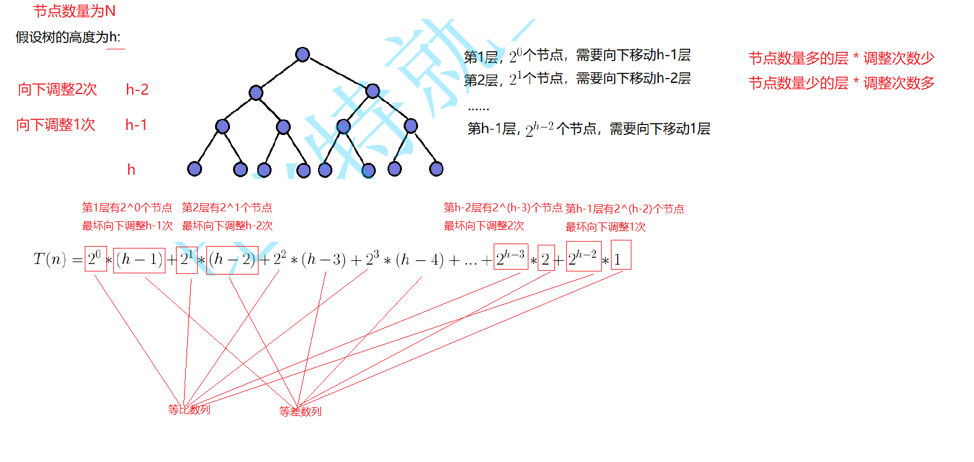
很多人会误以为建堆是 \(O(N\log N)\),是因为错误套用了「每次调整 \(O(\log N)\)」。但实际:
- 底层占了绝大多数节点(一半以上),只需要调整 1 次;
- 只有顶层极少数节点,才需要调整 \(\log N\) 次;
- 加权平均后,总次数是线性级别 O (N)。
对比:逐个插入建堆(向上调整)是 \(O(N\log N)\),批量下沉建堆是 \(O(N)\),下沉建堆更快。
向上调整建堆 = 一个一个往堆尾加节点,每个新节点从叶子往上 “冒泡”,和父节点比较交换
- 新节点永远加在最底层最右侧(完全二叉树性质)
- 调整方向:从下往上(叶子→根)
- 层数规律:越底层,节点越多,调整次数越多(复杂度高的根源)
二、以【8 个节点的小顶堆】为例,分步画图演示
数组:[3, 1, 2, 5, 4, 7, 6, 0],逐个插入建小顶堆
步骤 1:插入第 1 个节点 3
plaintext
3
只有根节点,无需调整
步骤 2:插入第 2 个节点 1(第 2 层)
plaintext
3
/
1
向上调整:1 < 父 3,交换
plaintext
1
/
3
👉 第 2 层节点:2 个节点,每个最多调 1 次
步骤 3:插入第 3 个节点 2(第 2 层)
plaintext
1
/ \
3 2
2 < 父 1?不小于,无需调整
步骤 4:插入第 4 个节点 5(第 3 层)
plaintext
1
/ \
3 2
/
5
5 > 父 3,无需调整
步骤 5:插入第 5 个节点 4(第 3 层)
plaintext
1
/ \
3 2
/ \
5 4
4 < 父 3,交换
plaintext
1
/ \
4 2
/ \
5 3
👉 第 3 层节点:4 个节点,每个最多调 2 次
步骤 6:插入第 6 个节点 7(第 3 层)
plaintext
1
/ \
4 2
/ \ /
5 3 7
7 > 父 2,无需调整
步骤 7:插入第 7 个节点 6(第 3 层)
plaintext
1
/ \
4 2
/ \ / \
5 3 7 6
6 > 父 2,无需调整
步骤 8:插入第 8 个节点 0(第 4 层,最底层!)
plaintext
1
/ \
4 2
/ \ / \
5 3 7 6
/
0
向上调整全过程:0 一路冒泡到根
- 0 < 父 5 → 交换
plaintext
1
/ \
4 2
/ \ / \
0 3 7 6
/
5
- 0 < 父 4 → 交换
plaintext
1
/ \
0 2
/ \ / \
4 3 7 6
/
5
- 0 < 父 1 → 交换
plaintext
0
/ \
1 2
/ \ / \
4 3 7 6
/
5只要子大于父亲就不用交换
最后对比一下两者区别用画图方式看一下哪个方便
一、向下调整(批量建堆・下沉法)O (N)
调整方向:父节点向下沉,从上层→下层
每层调整次数
plaintext
层数 节点数 向下调整次数
1 1 3次(最多沉到底)
2 2 2次
3 4 1次
4 8 0次(叶子不调整!!)
树结构 + 调整示意
text
○ ← 调3次
/ \
○ ○ ← 各调2次
/ \ / \
○ ○ ○ ○ ← 各调1次
/\/\/\/\/\
○○○○○○○○ ← 8个叶子,完全不动
总次数
\(T=1×3 + 2×2 + 4×1 = 11\)
下层节点最多,但不调整;上层节点极少,调整次数多 → 总和 O (N)
二、向上调整(逐个插入・上浮法)O (NlogN)
调整方向:新节点从叶子向上浮,下层→上层
每层调整次数
plaintext
层数 节点数 向上调整次数
1 1 0次(根)
2 2 1次
3 4 2次
4 8 3次(底层节点最多,每个调最多!!)
树结构 + 调整示意
text
○ ← 终点
/ \
○ ○ ← 上浮1次
/ \ / \
○ ○ ○ ○ ← 上浮2次
/\/\/\/\/\
○○○○○○○○ ← 8个底层,每个要上浮3次
总次数
\(T=2×1 + 4×2 + 8×3 = 34\)
下层节点最多,且调整次数最多 → 总和 O (NlogN)
0. 先记住一个常识
完全二叉树的高度 = log₂N(非常小)
- N=10 亿 → logN ≈ 30
- N=1 万 → logN ≈ 14
logN 是很小的数!
1. 向上调整建堆:O(N logN)
对应代码:
c
运行
// 逐个插入 → 向上调整
for (int i = 0; i < n; i++)
{
HPPush(&hp, a[i]); // 内部 AdjustUp
}
时间怎么算?
- 循环 N 次
- 每次
AdjustUp是从叶子往上走到根,走 logN 步
总次数:
plaintext
N 次 × logN 步 = O(N logN)
为什么这么慢?
最底层节点最多,每个都要往上走 logN 步一半节点都要走 logN 步,自然慢。
2. 向下调整建堆:O(N)
对应代码:
c
运行
// 批量建堆:向下调整
for (int i = (n-1)/2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
为什么是 O(N)?(最关键)
- 叶子节点不调整(占一半节点)
- 倒数第二层:只调整 1 步
- 倒数第三层:调整 2 步
- 最顶层(根):调整 logN 步
总步数
plaintext
一半节点:0 步
1/4节点:1 步
1/8节点:2 步
...
根节点:logN 步
加起来 ≈ N 步
人话总结
大部分节点不用动,少部分节点动几下,总和是线性的!
3. 堆排序 HeapSort:O(N logN)
c
运行
// 建堆 O(N)
for (int i = (n-1)/2; i >= 0; i--)
AdjustDown(a, n, i);
// 排序 O(N logN)
while (end > 0)
{
Swap(a[0], a[end]);
AdjustDown(a, end, 0); // logN
end--;
}
时间计算
- 建堆:O(N)(可忽略)
- 循环 N 次
- 每次
AdjustDown:logN
总时间:
plaintext
O(N) + O(N logN) = O(N logN)
4. TopK 海量数据:O(N logK)
c
运行
// 建 K 个元素的小堆 O(K)
for (int i = (k-1)/2; i >=0; i--)
AdjustDown(kminheap, k, i);
// 遍历剩下 N-K 个数 O(N logK)
while (读取x)
{
if (x > 堆顶) {
替换堆顶;
AdjustDown(堆, k, 0); // logK
}
}
时间计算
- 遍历 N 个数
- 每次调整堆只用 logK(K 很小)
总时间:
plaintext
O(N logK)
超级优势
N=10 亿,K=100logK ≈ 7总操作:10 亿 ×7 = 很快!
5. 最终总结(背这张表就够了)
表格
| 代码场景 | 复杂度 | 为什么 |
|---|---|---|
| 逐个插入 + 向上调整建堆 | O(N logN) | 每个新元素往上走 logN 步 |
| 批量向下调整建堆 | O(N) | 大部分节点不用动 |
| 堆排序 | O(N logN) | 换 N 次,每次 logN 调整 |
| 海量数据 TopK | O(N logK) | 只存 K 个,每次调整 logK |
2️⃣ HeapSort —— 堆排序(核心!)
c
运行
void HeapSort(int* a, int n)
{
// 向下调整建堆 O(N)
for (int i = (n-1-1)/2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
// 堆排序核心 O(N logN)
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]); // 堆顶和最后一个交换
AdjustDown(a, end, 0); // 重新调整堆
--end;
}
}
🔥 最重要口诀(背会就懂堆排序)
升序 → 建大堆降序 → 建小堆
堆排序步骤图解(超清晰)
- 把整个数组建成大堆堆顶 = 最大值
- 堆顶 和 最后一个位置交换最大值放到最后,不动了
- 前 end 个元素重新向下调整成堆
- 重复 2~3,直到全部有序
最终数组:升序
复杂度
- 建堆:O(N)
- 排序:O(N logN)
- 整体:O(N logN)
比冒泡 O (N²) 快得多!
3️⃣ TestHeap3 —— 海量数据找 TopK(面试必考)
c
运行
void TestHeap3()
{
int k;
printf("请输入k>:");
scanf("%d", &k);
// 只开 k 个空间!!!
int* kminheap = (int*)malloc(sizeof(int) * k);
// 读前 k 个数
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &kminheap[i]);
}
// 建一个 小堆
for (int i = (k-1-1)/2; i>=0 ; i--)
{
AdjustDown(kminheap, k, i);
}
// 遍历剩下所有数(几百万、几亿都可以)
int x = 0;
while (fscanf(fout, "%d", &x) > 0)
{
// 比堆顶大,就替换堆顶,重新调整
if (x > kminheap[0])
{
kminheap[0] = x;
AdjustDown(kminheap, k, 0);
}
}
// 最后堆里就是最大的 K 个数
for (int i = 0; i < k; i++)
{
printf("%d ", kminheap[i]);
}
}
🔥 核心思想(秒懂)
找最大前 K 个 → 建大小为 K 的小堆
为什么?
- 小堆的堆顶是 K 个数里最小的
- 来一个更大的数,就换掉堆顶
- 最后堆里自然保留最大的 K 个数
优点
- 内存只需要存 K 个数
- 数据量再大(10 亿)都能处理
- 时间复杂度 O(N logK)
三、两个关键函数(必须懂)
1. AdjustUp 向上调整
c
运行
AdjustUp(a, i);
- 子节点比父节点大 / 小,就往上交换
- 逐个插入建堆用
- 复杂度 O(N logN)
2. AdjustDown 向下调整
c
运行
AdjustDown(a, n, i);
- 父节点和孩子比较,往下沉
- 批量建堆、堆排序、TopK 都用它
- 建堆复杂度 O(N)
四、一张图总结整套代码
plaintext
TestHeap1 → 堆的基本使用(向上调整)
HeapSort → 堆排序(向下建堆 + 交换堆顶)
TestHeap3 → 海量数据 TopK(小堆找最大前K)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 38
38 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)