智能语音技术(十)
语音标注的技术详解
1. 引言
语音标注是人工智能领域,特别是语音识别(ASR)、说话人识别、情感计算等任务中不可或缺的基础环节。简单来说,语音标注就是将一段音频文件,按照特定的规则和需求,转化为计算机可以理解和学习的结构化标签数据。高质量的语音标注数据,直接决定了上层模型的性能上限。本文将深入探讨语音标注的核心技术、常见类型、流程规范以及面临的挑战。
2. 语音标注的主要类型
根据应用场景的不同,语音标注可以分为以下几种主要类型:
2.1 语音转写(ASR 标注)
这是最常见的一种标注类型,目的是将音频中的语音内容逐字逐句地转写成文本。
- 规范转写:要求标注员严格按照听到的内容进行转写,包括语气词(如“嗯”、“啊”)、重复、修正等。
- 格式化转写:在规范转写的基础上,对数字、日期、英文单词等进行标准化处理(如“2024年”而非“二零二四年”)。
- 带时间戳转写:为每一句话或每一个词标注其在音频中的起始和结束时间点(即强制对齐),用于训练语音识别模型。
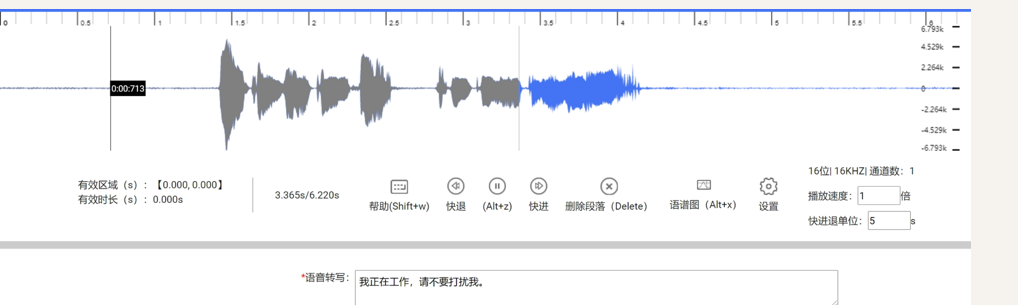
2.2 实战:使用 Whisper 进行语音转写
为了更直观地理解语音转写的过程,下面通过 Python 代码演示如何使用 OpenAI 的 Whisper 模型(轻量版)对一段音频进行转写。Whisper 支持多语言识别,且无需 GPU 也能运行。
环境准备
首先安装必要的库:
pip install openai-whisper ffmpeg-python
注意:Whisper 依赖
ffmpeg处理音频格式。如果未安装,请先安装 FFmpeg(Windows 用户可下载预编译包并配置环境变量,macOS 用户使用brew install ffmpeg,Linux 用户使用sudo apt install ffmpeg)。
完整代码示例
import whisper
import time
# 1. 加载模型(可选 tiny/base/small/medium/large)
# tiny 最快但精度较低,small 是精度与速度的平衡选择
model = whisper.load_model("small")
# 2. 指定音频文件路径(支持 mp3、wav、m4a 等常见格式)
audio_path = "meeting_recording.wav"
# 3. 开始转写
print("正在转写,请稍候...")
start_time = time.time()
result = model.transcribe(
audio_path,
language="zh", # 指定语言为中文,可提高准确率
task="transcribe", # "transcribe" 转写,"translate" 翻译为英文
verbose=False # True 会逐段打印中间结果
)
elapsed = time.time() - start_time
print(f"转写完成,耗时 {elapsed:.2f} 秒")
# 4. 输出完整文本
print("\n===== 转写结果 =====")
print(result["text"])
# 5. 输出带时间戳的片段(可选)
print("\n===== 详细片段(带时间戳) =====")
for segment in result["segments"]:
start = segment["start"]
end = segment["end"]
text = segment["text"]
print(f"[{start:.2f}s -> {end:.2f}s] {text}")
运行结果示例
正在转写,请稍候...
转写完成,耗时 12.35 秒
===== 转写结果 =====
大家好,今天我们来讨论一下第三季度的项目进展。首先,请市场部的同事汇报一下最近的推广情况。
===== 详细片段(带时间戳) =====
[0.00s -> 2.50s] 大家好,今天我们来讨论一下第三季度的项目进展。
[2.50s -> 5.80s] 首先,请市场部的同事汇报一下最近的推广情况。
常见错误与处理
| 错误现象 | 可能原因 | 解决方案 |
|---|---|---|
FileNotFoundError: ffmpeg not found |
系统未安装 FFmpeg 或未加入 PATH | 安装 FFmpeg 并确保 ffmpeg 命令可在终端执行 |
RuntimeError: model file not found |
首次运行需下载模型,网络不稳定 | 设置代理或手动下载模型文件放入 ~/.cache/whisper/ |
| 转写结果全是乱码或英文 | 未指定 language="zh",模型自动检测出错 |
显式传入 language="zh" |
| 音频时长很长时 OOM(内存溢出) | 模型过大或音频采样率过高 | 改用 tiny 模型,或先将音频降采样为 16kHz 单声道 |
| 转写结果中缺少标点 | Whisper 默认输出不带标点的纯文本 | 使用 model.transcribe(..., word_timestamps=True) 并自行后处理 |
使用 Vosk 的轻量替代方案
如果需要在离线、低资源环境下运行,也可以使用 Vosk 库(基于 Kaldi):
pip install vosk
import json
from vosk import Model, KaldiRecognizer
import wave
# 加载中文模型(需提前下载 vosk-model-small-cn-0.22)
model = Model("vosk-model-small-cn-0.22")
wf = wave.open("audio.wav", "rb")
rec = KaldiRecognizer(model, wf.getframerate())
while True:
data = wf.readframes(4000)
if len(data) == 0:
break
rec.AcceptWaveform(data)
result = json.loads(rec.FinalResult())
print(result["text"])
提示:Vosk 的模型体积更小(约 40MB),适合嵌入式设备或移动端部署,但识别准确率略低于 Whisper。
2.2 说话人标注(说话人分离与识别)
当音频中包含多个说话人时,需要标注出“谁在什么时候说话”。
- 说话人分离(Diarization):将音频按说话人身份切分成不同的片段,标注为 Speaker 1、Speaker 2 等。
- 说话人识别:在分离的基础上,将说话人片段与具体的身份信息(如姓名、ID)进行关联。
2.3 情感与副语言标注
这类标注关注的是说话人的语气、情绪和声音特质。
- 情感标注:为音频片段打上“高兴”、“悲伤”、“愤怒”、“中性”等情感标签。
- 副语言标注:标注笑声、哭声、咳嗽、叹息、语速变化、音量变化等非语言信息。
2.4 音素与韵律标注
- 音素标注:将语音转写为音素序列(如 /k/ /æ/ /t/ 对应 “cat”),常用于语音合成(TTS)和音素识别。
- 韵律标注:标注语句中的重音、停顿、语调升降等韵律特征,对于提升语音合成的自然度至关重要。
3. 语音标注的标准流程
一个标准的语音标注项目通常包含以下步骤:
- 数据采集与预处理:收集原始音频,进行降噪、归一化、格式统一(如统一采样率为 16kHz,单声道,WAV 格式)。
- 标注规范制定:编写详细的标注手册,明确转写规则、标签定义、边界判定标准等。
- 标注工具选择:选用专业的标注平台,如 Praat、Audacity、ELAN 或商业化的标注系统。
- 初标与质检:由标注员完成初标,质检员按一定比例(如 20%)进行抽检,确保准确率达标。
- 数据交付与格式转换:将标注结果导出为通用格式,如 JSON、TextGrid、CSV 等,供算法团队使用。

4. 关键技术挑战
4.1 边界判定模糊
语音是连续的信号,词与词、句与句之间往往没有明显的静音间隔。标注员在判断“一句话的结束”或“一个词的边界”时,主观性较强,容易导致标注不一致。
4.2 口音与方言处理
不同地区、不同背景的说话人带有浓重的口音或使用方言,这给转写和音素标注带来了巨大困难。需要标注员具备相应的语言能力,或借助方言词典辅助。
4.3 噪声与远场语音
在真实场景中,音频往往包含背景噪声、多人说话重叠、回声等干扰。标注员需要具备从嘈杂环境中分辨目标语音的能力,这对标注质量提出了极高要求。[SIL]:表示静默音 [PN]: 人声噪音 [KN]: 动作噪音 [WN]: 稳定的噪声
例:今天[PN]我去 [WN]吃饭了
4.4 标注一致性保障
多人协作时,不同标注员对同一段音频的理解可能存在差异。需要通过“交叉验证”、“仲裁机制”和“定期校准会议”来保证标注结果的一致性。
如发音为:“我是北北京人”;“北”字有重复现象,标注的时候要写成:我是北北京人。
5. 语音标注工具推荐
5.1 Praat:学术级语音分析与标注利器
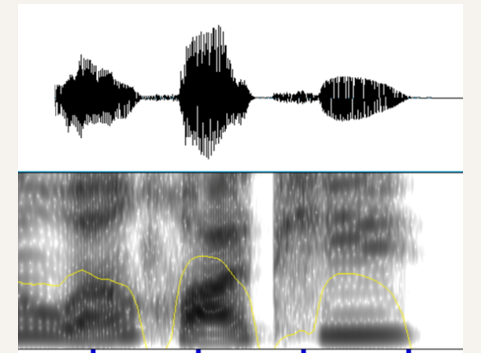
Praat 是语音学领域最权威的免费开源软件,由阿姆斯特丹大学开发。它支持音素标注、韵律标注、声学分析(基频、共振峰、语谱图)以及强大的脚本自动化,是语音标注和研究人员的必备工具。
安装与启动
- 官网下载:访问 https://www.fon.hum.uva.nl/praat/ 下载对应操作系统版本(Windows / macOS / Linux)。
- 启动:解压后双击
Praat.exe(Windows)或Praat.app(macOS)即可运行,无需安装。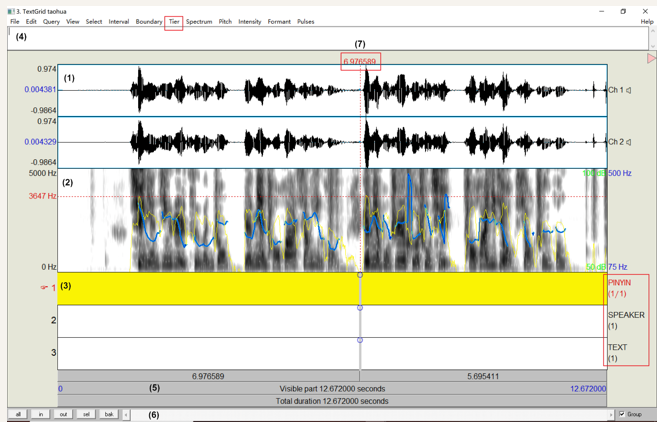
界面概览
启动后会出现两个窗口:
- Praat Objects:对象列表窗口,用于管理音频、标注文件、声谱图等对象。
- Praat Picture:绘图窗口,用于输出声学图表。
核心操作:打开音频与查看语谱图
- 在 Praat Objects 窗口中,点击
Open → Read from file...,选择你的音频文件(支持 WAV、MP3、AIFF 等格式)。 - 选中加载的音频对象,点击右侧的
View & Edit按钮,打开编辑窗口。 - 编辑窗口上半部分显示波形图(Waveform),下半部分显示宽带语谱图(Spectrogram),可直观看到声音的频率分布。
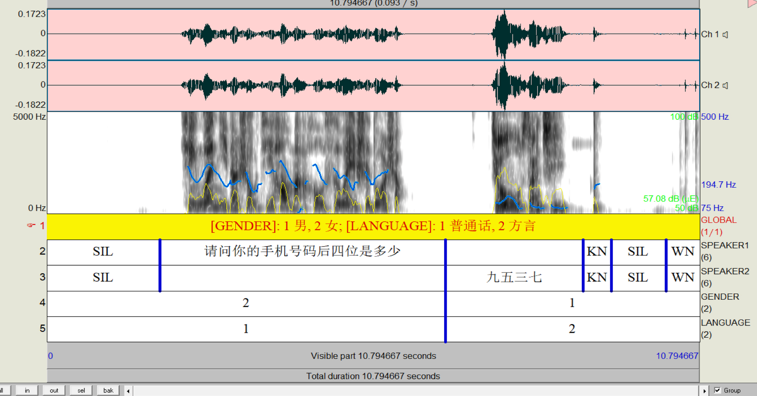
创建 TextGrid 标注文件
TextGrid 是 Praat 的标注文件格式,用于存储音素、词语、句子等层级的标注信息。
- 在 Praat Objects 窗口中,选中音频对象。
- 点击右侧的
Annotate → To TextGrid...。 - 在弹出的对话框中:
- All tier names:输入层级名称,用空格分隔。例如
phone word sentence表示创建音素、词语、句子三个层级。 - Which of these are point tiers?:如果某层级是时间点标注(而非区间),输入该层级名称;否则留空。
- 点击
OK生成 TextGrid 对象。
- All tier names:输入层级名称,用空格分隔。例如
手动标注操作指南
- 在 Praat Objects 中同时选中音频对象和 TextGrid 对象(按住 Shift 多选),点击
View & Edit。 - 编辑窗口中出现标注轨道:
- 选择区间:在轨道上点击并拖动鼠标,选中一段区域(会高亮显示)。
- 添加边界:在选中区域的边界处点击,即可添加一条分割线。
- 输入标签:选中一个区间后,在底部的文本框中输入标签内容(如音素
/a/、词语“你好”),按回车确认。 - 播放选中区域:按
Tab键或点击窗口下方的播放按钮,可试听当前选中区间。 - 放大/缩小:使用鼠标滚轮或窗口下方的缩放按钮,精细调整时间轴。
常用快捷键
| 快捷键 | 功能 |
|---|---|
Tab |
播放/停止当前选中区间 |
Ctrl+N |
新建一个边界点 |
Alt+←/→ |
跳到上一个/下一个边界 |
Ctrl+1/2/3 |
切换到第 1/2/3 个标注层级 |
Shift+鼠标拖动 |
精细调整边界位置 |
使用脚本批量处理
Praat 支持脚本语言(Praat Script),可大幅提升标注效率。以下是一个简单的脚本示例,用于批量提取所有标注区间的时长和标签:
# 批量提取 TextGrid 标注信息
form Extract_Intervals
sentence Directory ./audio/
sentence TextGrid_extension .TextGrid
endform
# 获取所有 TextGrid 文件
strings = Create Strings as file list: "fileList", directory$ + "*" + textGrid_extension$
numberOfFiles = Get number of strings
for i from 1 to numberOfFiles
selectObject: strings
fileName$ = Get string: i
baseName$ = fileName$ - textGrid_extension$
# 读取 TextGrid
tg = Read from file: directory$ + fileName$
# 获取第一个层级的区间数
numIntervals = Get number of intervals: 1
# 遍历每个区间
for j from 1 to numIntervals
label$ = Get label of interval: 1, j
start = Get starting point: 1, j
end = Get end point: 1, j
duration = end - start
# 输出到控制台
appendInfoLine: baseName$, tab$, fixed$(start, 3), tab$, fixed$(end, 3), tab$, fixed$(duration, 3), tab$, label$
endfor
removeObject: tg
endfor
removeObject: strings
运行脚本:在 Praat 菜单栏选择
Praat → Open Praat script...,粘贴上述代码,点击Run即可。
导出标注结果
标注完成后,可以将 TextGrid 导出为其他格式:
- 保存 TextGrid:在 Praat Objects 中选中 TextGrid 对象,点击
Save → Save as text file...。 - 导出为 CSV:使用上述脚本或第三方工具将标注信息导出为表格格式。
- 导出为 JSON:可编写 Praat 脚本将标注结果输出为 JSON 格式,方便与算法团队对接。
常见问题与技巧
| 问题 | 解决方法 |
|---|---|
| 语谱图显示不清晰 | 在编辑窗口点击 Spectrum → Spectrogram settings,调整动态范围(Dynamic range)为 50-70 dB |
| 标注边界对齐不准 | 放大波形图后,使用 Shift+鼠标拖动 微调边界线 |
| 需要多人协作标注 | 使用 TextGrid 的合并脚本,或借助 ELAN 等支持多用户协作的工具 |
| 音频采样率不统一 | 在 Praat Objects 中选中音频,点击 Convert → Resample... 统一为 16kHz |
5.2 其他工具简介
- Audacity:免费开源的音频编辑软件,适合进行简单的语音切割和转写。
- ELAN:多模态标注工具,支持音视频同步标注,适合说话人分离和副语言标注。
- Label Studio:开源数据标注平台,支持语音标注插件,可自定义标注界面和导出格式。
- 商业平台:如百度智能云数据标注、阿里云数据标注平台,提供一站式标注服务和项目管理功能。## 6. 总结与展望
语音标注是一项既需要语言学知识,又需要耐心和细致的工作。随着大模型和自监督学习的发展,虽然“无标注”或“弱标注”的语音技术正在兴起,但在高精度要求的垂直领域(如医疗听写、法律会议记录、金融客服质检),高质量的语音标注数据依然是不可替代的核心资产。未来,语音标注将朝着“人机协同”的方向发展,即由 AI 模型进行预标注,再由人工进行校验和修正,从而大幅提升标注效率和质量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)