大模型“备案“和“登记“是不是一回事,千万别搞错
1. 备案和登记,是两套完全不同的程序
备案和登记,对应的是两套不同的法规、两个不同的系统、两份不同的材料要求。
备案的依据是《生成式人工智能服务管理暂行办法》。你要是自己训练、研发了一个大模型,或者在开源模型基础上做了二次训练、微调,你需要向监管证明:这个模型是安全的,我可以负责。并且大模型备案通常都是有政策补贴的,根据每个地区是不一样的。
登记的依据是同一部法规,但针对的是另一种情况:你没有自己训练模型,是调用了一个已经备案通过的第三方模型API,你没有对模型做任何修改。你只需要证明:我是合规使用这个模型的。
区别在哪里?
- 备案
:你要证明的是"我这个模型是安全的"
- 登记
:你要证明的是"我是合规使用别人模型的"
一个是要证明"我自己造的车能上路",一个是要证明"我打的车是正规平台的"。监管盯的重点完全不一样。
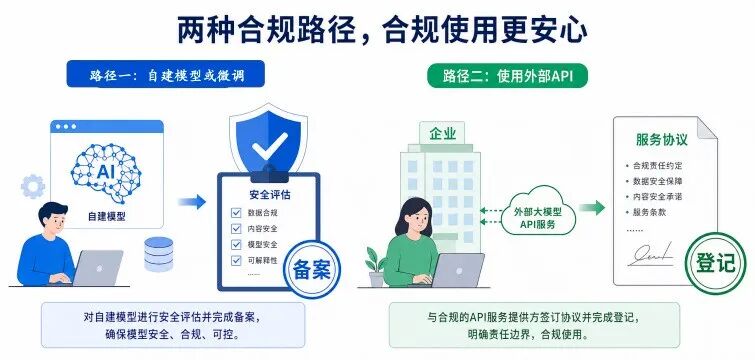
2. 一个比喻,让你一分钟搞懂
备案,相当于你自己考驾照、自己买车、自己上牌。登记,相当于你打车,平台和司机都是合规的,你只是乘客。监管盯的重点不一样,你需要证明的东西也不一样。
备案 = 自己开车
你自己去考驾照,买车,上牌。这个车从设计到生产到上路,全是你负责的。出了事故,交警找你,因为你是车主、驾驶员。
对应到大模型:你自己训练了模型,或者在开源模型基础上做了二次训练。模型是你的,你要对模型产生的所有行为负责。监管要审查你的算法、安全措施、数据来源,确保你这个"司机"能上路。
登记 = 打车
你打开出行软件,叫了一辆车。车是平台的、司机有合规执照、平台已经备案过了。你只是乘客,你不需要证明你会开车,只需要证明你是合规使用这个服务的。
衍生知识点:算法备案是什么?
算法备案是第三套程序,依据是《互联网信息服务算法推荐管理规定》。这是针对推荐算法、搜索排序、调度决策类服务的。如果你的产品涉及这类功能,可能需要同时做算法备案。
-
你自己训练大模型 → 做大模型备案
-
你调用别人大模型API,没改模型 → 做大模型登记
-
你的产品涉及推荐算法功能 → 可能还要做算法备案
这三个是完全不同的程序,别混为一谈。
3. 搞混了,后果不只是材料白写
做了备案的材料去走登记,退回重来;该备案却做了登记,被查到直接下架。代价不只是重新准备材料,是产品上线窗口期全耽误了,这才是最大的损失。
场景一:做了备案的材料,去走登记
按照大模型备案准备了一大堆材料,结果一提交,审核人员发现你们的产品是纯调用别人API的,不是自己训练模型的——材料方向完全不对,退回。
这时候你面临两个选择:
-
重新准备材料,再等几个月
场景二:应该做备案,做了登记
你的产品明明是在开源模型基础上做了微调的,按规定应该做备案。但你以为"只要用了大模型就做登记",结果走了登记通道,材料也交了,审核也过了,备案编号也拿到了。
然后,监管查到你了。
因为微调后的模型在监管眼里属于"自己训练的模型",走登记通道是合规的漏洞。一旦被查,不是整改,是直接下架。
📌 两者审核周期不一致
备案的平均周期:3-6个月。登记的平均周期:1-2.5个月。搞混一次,浪费的时间少则一两个月,多则半年。而这半年里,你的竞品可能已经上线了。
4. 一张表对号入座,不用再问人
表格直接看,自己属于哪种情况,对应做什么。简单直接。

备案和登记的主要区别

5. 三个边界情况,问得最多,错得也最多
用开源模型算"自己造"吗?内测阶段要不要做?B端产品要不要做?这三个问题搞清楚,能少走很多弯路。 如需咨询,可添加:daibanzzfw
边界情况一:用开源模型,算"自己造"吗?
看情况。如果你把开源模型API拿来直接用,没有做任何预训练或微调,那属于"纯调用",做登记就够了。
但如果你是用开源模型做预训练,比如在一个行业领域数据集上继续训练,这就是"自己训练"了,必须做备案。
核心判断标准是:模型的控制权在谁手里。
你只是调用它的输出,没动它的参数 → 登记。
你在它的基础上继续训练、改它的参数 → 备案。
同样的开源模型,行为不一样,要求就不一样。
边界情况二:还在内测阶段,要不要做?
只要外部用户能访问,不管内测还是正式上线,都要登记或备案。
监管看的是"产品能力",不是"产品阶段"。你的产品能提供大模型能力,这个能力已经存在了,不因为你还没正式宣布上线就不存在了。
边界情况三:B端产品要给企业客户用,要不要做?
这个要看具体情况。
如果你的B端客户使用产品时,只会接触到你的产品界面,而不会产生面向他们终端用户(也就是普通消费者)的内容,通常风险较低。
但如果你的B端客户用产品时,会产生面向他们终端用户的内容,理论上需要做登记或备案。
拿不准的,建议直接打电话问当地网信办。你公司注册地的省级网信办,电话打过去说清楚你的产品形态,让他们给一个官方口径的回复。保留这个沟通记录,这是你"已尽到注意义务"的证明。
6. 全流程拆解:备案和登记各是怎么走的
把两边的全流程拆开讲,流程和材料对照着看,你自己就能判断走到哪一步了。
大模型备案:四个阶段
第 1 周:项目启动与路径判断。这一周主要判断产品是否属于生成式人工智能服务,是否面向中国境内公众提供,是否具有舆论属性或社会动员能力。同时要判断项目应走“大模型备案”还是“大模型上线登记”。如果模型是自研、训练或深度微调,并且由企业自己控制模型能力,通常应按大模型备案路径推进。
第 2 周:准备主体和产品基础材料。这一周整理企业主体材料,包括营业执照、法定代表人信息、联系人信息、ICP备案、域名、服务器、APP、小程序或网站入口等。同时准备产品说明材料,包括产品名称、服务对象、功能介绍、应用场景、上线范围、用户协议和隐私政策。
第 3 周:准备模型技术材料。这一周重点梳理模型本身的信息,包括模型名称、版本、模型架构、训练方式、基础模型来源、是否微调、部署方式、推理链路、能力边界和接口调用方式。通常还需要形成模型说明书、技术架构图和系统调用链路图。
第 4 周:准备训练数据与语料合规材料。这一周要说明训练数据来源是否合法,是否涉及公开数据、授权数据、企业自有数据、用户数据或第三方数据。还要整理数据清洗规则、标注规则、个人信息处理方式、知识产权风险说明和训练数据质量控制机制。
第 5 周:建立安全管理和内容治理机制。这一周重点准备内容安全制度,包括违法不良信息拦截机制、敏感问题拒答机制、人工审核机制、用户投诉举报机制、日志留存机制、应急处置机制和用户管理机制。这个阶段要把“产品出了问题后怎么发现、怎么处理、谁负责”说清楚。
第 6 周:开展安全测试和自评估。这一周进行模型安全测试,包括政治安全、违法违规内容、色情暴恐、歧视偏见、个人信息泄露、版权风险、越狱攻击、多轮诱导等测试。测试完成后形成安全自评估报告、测试题库、测试结果和整改记录。
第 7 周:并行准备算法备案、深度合成和内容标识材料。如果产品具有舆论属性或社会动员能力,通常需要同步准备算法备案材料。如果涉及图片、视频、音频、人脸、人声等生成或合成能力,还要准备深度合成相关说明。同时,需要设计 AI 生成内容的显式标识、隐式标识、水印或元数据标识方案。
第 8 周:与属地网信办预沟通。这一周建议和属地网信办或主管窗口进行预沟通,提交初版材料目录或核心材料,确认申报路径、材料清单、测试账号、测试入口和是否存在明显缺项。预沟通后,根据反馈修改材料。
第 9 周:正式提交备案材料。这一周向属地网信办正式提交备案材料,包括主体材料、产品材料、模型材料、训练数据材料、安全评估材料、算法备案材料、内容标识方案、测试账号、测试入口和相关证明文件。
第 10–12 周:接受材料审查和技术测试。监管侧会对材料进行审查,也可能对产品或模型进行测试。企业需要配合解释模型机制、训练数据来源、安全措施、内容审核机制和风险处置流程。如果发现问题,监管侧可能要求补充说明或整改。
第 13–14 周:根据反馈补正和复测。这一阶段主要根据监管反馈修改材料、补充证明、优化内容拦截策略、完善标识方案、调整产品页面、增加测试样本,并提交整改说明和复测结果。
第 15–16 周:取得备案结果并准备上线。备案通过后,企业需要在产品页面、服务详情页或显著位置展示模型名称、备案号等信息。上线前还应进行灰度测试、风控复核、日志检查、投诉举报通道检查和应急预案演练。
备案需要的材料清单(简化版):
-
企业营业执照
-
算法机制机理说明
-
安全自评估报告
-
训练数据来源说明
-
数据标注规则
-
关键词拦截列表
-
内容安全管理制度
-
服务协议 / 用户协议
-
第三方安全评测报告
大模型上线登记:
大模型上线登记整体建议按 4–8 周安排。如果只是调用已经备案的大模型 API,且应用场景较简单,可能 2–4 周完成;如果涉及复杂智能体、多模型混用、内容发布传播或重点行业场景,可能需要 8–12 周。
第 1 周:确认模型调用关系。这一周首先确认应用调用的大模型是否已经完成备案。企业需要向模型供应商索要模型名称、备案号、备案主体、API 调用证明、合作协议或授权文件。同时要确认自己是否只是调用模型能力,还是对模型做了训练、微调或能力改造。如果只是直接调用已备案模型,通常可以走上线登记;如果做了实质性模型改造,可能要转为大模型备案。
第 2 周:准备应用基础材料。这一周准备应用层材料,包括应用名称、产品介绍、服务入口、功能说明、用户群体、业务场景、是否面向公众、是否有内容发布或传播能力、是否涉及重点行业。还需要准备用户协议、隐私政策、产品页面截图和测试账号。
第 3 周:完善应用层安全机制。这一周重点不是证明模型本身安全,而是证明应用层有安全管理能力。需要配置敏感内容拦截、风险提示、人工审核、投诉举报、日志留存、用户管理、异常处置和应急响应机制。如果应用允许用户发布、分享或传播 AI 生成内容,还要加强内容审核和追溯机制。
第 4 周:准备内容标识和页面公示方案。这一周要在产品中加入 AI 生成内容提示、显式标识、隐式标识、水印或其他标识方案。同时要准备产品详情页或显著位置的公示方案,用于展示所调用模型的名称、备案号,以及上线登记通过后的上线编号。
第 5 周:向地方网信办提交上线登记材料。这一周正式提交上线登记材料,包括企业主体材料、应用说明、服务入口、调用模型备案号、供应商授权证明、API 调用证明、安全管理制度、内容标识方案、用户协议、隐私政策、测试账号和测试入口。
第 6 周:接受审查和产品测试。地方网信办会审查材料并测试应用。重点通常包括:是否真实调用已备案模型,是否超出模型备案范围,是否存在未披露的微调或二次训练,是否具备内容安全措施,是否有投诉举报机制,是否落实 AI 生成内容标识。
第 7 周:根据反馈补正和整改。如果监管侧提出问题,企业需要补充供应商证明、修改产品说明、完善安全策略、调整页面公示、补充内容标识、优化风险拦截机制,并提交整改说明。
第 8 周:取得上线编号并正式上线。上线登记通过后,企业取得上线编号。正式上线时,应在产品显著位置或产品详情页展示调用模型的名称、模型备案号或上线编号。上线后还要持续保留日志、处理投诉举报、监控异常输出,并根据监管要求及时更新登记信息。
登记需要的材料清单(简化版):
-
企业营业执照
-
服务登记表
-
产品服务协议
-
内容安全管理制度
-
拦截关键词列表
-
模型调用情况说明
一个重要的共同点:不管备案还是登记,备案编号 / 登记编号都需要在产品界面公示。这是监管检查的必查项,没有公示等于没有完成。
7. 几个最容易忽略的细节
材料盖不盖公章、服务协议和产品实际对不对得上、日志留存够不够6个月……这些不是形式,是决定审查结论的细节。
这些细节,第一次做备案的人几乎都会忽略。等到被审核人员追问了,才发现自己没准备。
细节一:材料必须盖公章
所有提交的纸质或电子材料,必须加盖公章。没有公章的材料,审核人员会直接退回。注意:是公司的公章,不是合同专用章,也不是部门章。
细节二:服务协议必须和产品实际一致
这是被退回最多的原因之一。
比如:协议写"我们不会用用户数据训练模型",但产品实际上做了fine-tuning;协议写"模型输出仅供参考",但产品宣传页写的是"AI给出专业建议"。
审核人员会把你写的协议和产品实际功能对比,一经发现不一致,直接打回。
写服务协议之前,先和技术团队确认清楚产品实际做了什么。
细节三:内容安全制度要"落地"
不是你写一份文件放在内网里,就叫"有制度"了。
审核人员会问:
-
这个制度什么时候发的?
-
谁负责内容安全?
-
有执行记录吗?
-
多久更新一次?
答不上来,制度就只是纸面上的东西,不算数。
制度要正式发文,责任要落实到具体人,执行要有记录。
细节四:日志留存要够6个月
法规要求:用户操作日志、内容日志,必须留存至少6个月。
很多公司产品上线前没想到这件事,等备案审查人员问到,才发现自己没有日志留存机制。临时搭建,耽误时间。
如果你的产品还在开发阶段,现在就把日志留存机制考虑进去。
细节五:拦截关键词列表要分类分级
很多人觉得"我有拦截能力"就行了,写个"包含敏感词过滤"就交上去了。
审核人员要看的不是"你有没有",是你"有多少、覆盖哪些、怎么更新"。
关键词列表要分类、分级,比如:政治敏感类、暴力血腥类、色情低俗类、违法犯罪类……每类要有具体的拦截词,不能只写一句"已覆盖敏感词"。
希望这篇东西能帮你省掉一些摸索的时间。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)