图像识别:使用各种CNN经典模型对FashionMNIST数据集识别、评估、调优、对比
前言: 继上文“成功实现首个pytorch编写的softmax模型并调优的记录”FashionMNIST图像识别中,最终训练准确率 、测试准确率分别为89%和86%。 明显准确率偏低,这次将全连接网络换成图像识别专用网络:CNN网络逐个测试并评估,看看能有什么惊讶的发现吧!
代码获取地址:深度学习“Dive-into-DL-Pytorch”https://github.com/ShusenTang/Dive-into-DL-PyTorch
(提示: LeNet在普通的办公电脑跑过了,速度约25s/epoch,但是AlexNet我在普通电脑上没跑成功,AlexNet开始我改为在gpu上跑。 学生或个人实验者,有些提供免费限额的gpu平台,详见在腾讯云 Cloud Studio平台,使用免费限额的GPU操作手册-CSDN博客、 在Kaggle平台,使用免费限额的GPU操作手册-CSDN博客)
开始实验:
第一轮:使用LetNet网络
LetNet网络简单介绍:1998年杨立昆领导的团队建立, 网络共5层(2个卷积+ 3个全连接),6万参数, 定义了CNN基本架构, 将卷积神经网络推上历史舞台。
运行配置 : batchsize=256, epoch=10, 使用Adam优化器, 学习率0.001, 模型LeNet
运行结果: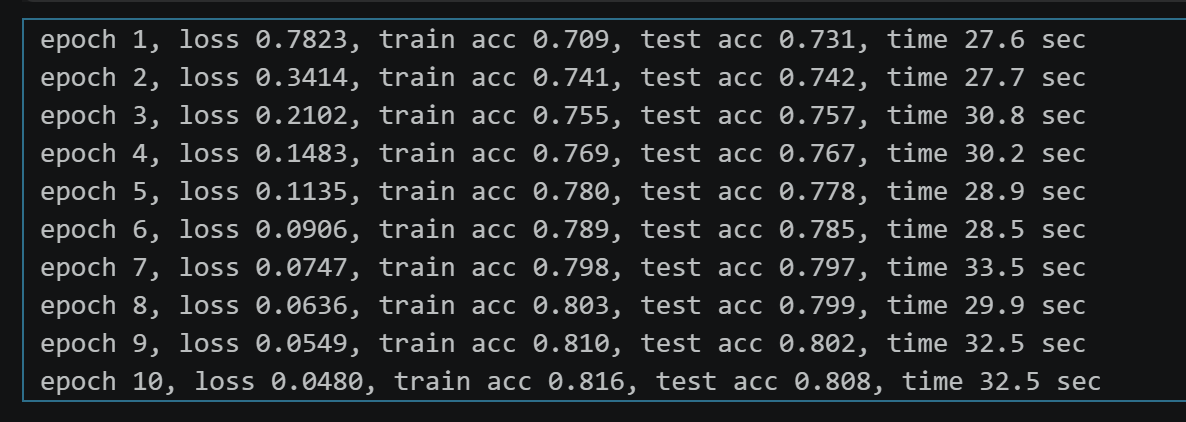
结果思考:可以发现LeNet的train acc=0.816比全连接网络更低,学习能力还是较低, 但是train acc 和 test acc 基本一致, 说明泛化能力强。LeNet学习的它学到的是更本质、更具泛化能力的图像特征,因此在最终的测试集上表现得更稳定、更可靠。
第二轮:使用AlexNet网络
AlexNet网络简单介绍:2012年辛盾团队建立, 网络共8层( 5卷积+3全连接), 6000万参数 , imageNet大赛 上Top-5错误率16.4% 。 引入Relu解决梯度消失、dropout防止过拟合、GPU并行计算。AlexNet在2012年的ImageNet上 夺冠,开启了深度学习的热潮。
运行配置 : batchsize=256, epoch=10, 使用Adam优化器, 学习率0.001, 模型AlexNet
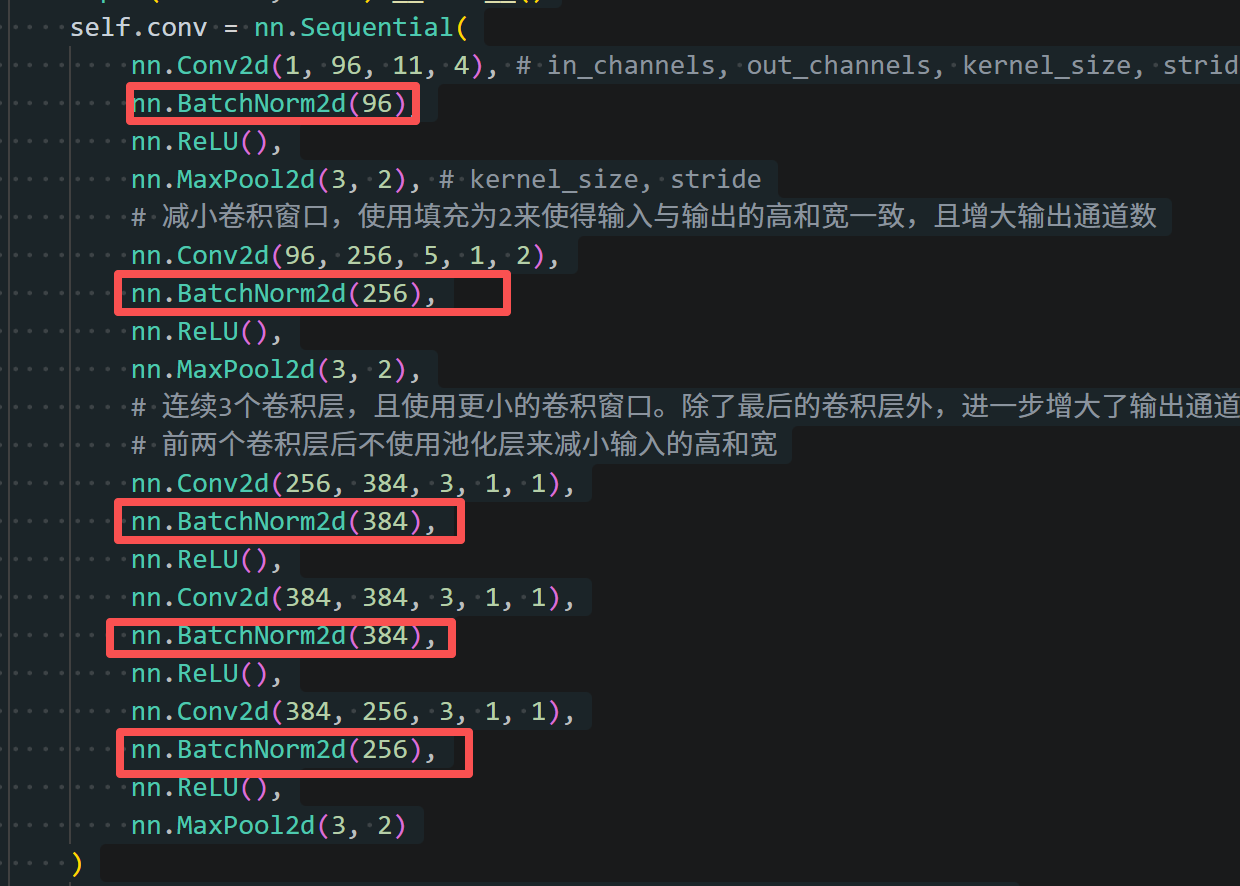
另外:我在原来AlexNet的基础上加入了BatchNorm归一化,来加快收敛速度
运行结果:
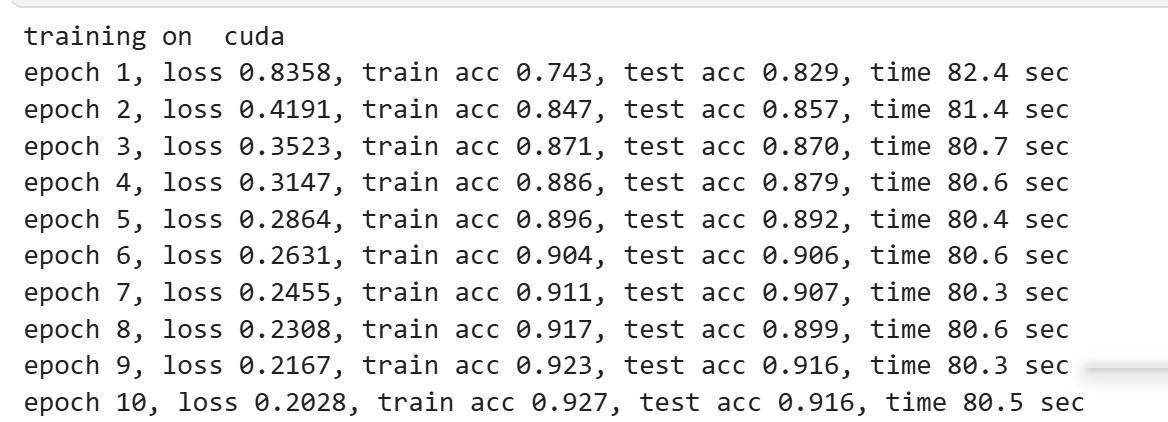
结果思考:发现AlexNet的最终训练准确率train acc =0.927 ,比LeNet提升了11%, 说明提取特征的能力远强于 LeNet, 原因主要是AlexNet使用更深的网络、并引入relu(其梯度恒为1,不存在sigmoid梯度消失问题)允许网络训练的更深。 ALexNet的test acc=0.916与train acc有些差异,说明ALexNet存在些过拟合情况,可以在网络中加入DropOut或权重衰减看看。
第三轮:使用VGGNet网络
VGGNet网络简单介绍:2014年牛津大学VGG组建立,网络16-19层 (16层时:13个卷积+3个全连接),1.38亿参数 ,imageNet大赛 上Top-5错误率7.32% ,证明网络深度的重要性 。
VGGNet 的核心思想是:通过堆叠多个小卷积核(3x3)来替代大卷积核(如 5x5, 7x7),在减少参数量的同时增加了网络深度和非线性表达能力。
运行配置 : batchsize=256, epoch=10, 使用Adam优化器, 学习率0.001, 模型VGGNet
运行结果:

结果思考:vggnet的最终训练准确率train acc =0.941 ,比AlexNet提升了1.4%,证明加深网络深度确实能提高网络性能。
第四轮:使用GoogleNet网络
GoogleNet网络简单介绍: 2014年google团队建立,网络共 22层, 500万参数, imageNet大赛 上Top-5错误率6.67% ,引入inception模块,多尺度卷积 。
亮点主要是Inception 模块设计:并行使用 1×1、3×3、5×5 的卷积核多,多感受野; 引入 1×1 卷积来降维,大幅降低计算量 。它标志着卷积神经网络的设计从“暴力堆叠层数”正式迈向了“结构精巧、计算高效”的新阶段。
运行配置 : batchsize=256, epoch=10, 使用Adam优化器, 学习率0.001, 模型GoogleNet
运行结果:
第五轮:使用ResNet网络
ResNet网络简单介绍:2015年由何恺明、张祥雨、任少卿、孙剑(微软亚洲研究院)提出, 网络共152+层 ,6000万参数, imageNet大赛 上Top-5错误率3.57%。 引入“残差连接(Residual Connection)”,解决梯度消失问题 ,革命性地解决了超深网络难以训练的问题。
在 ResNet 出现之前,传统的深层网络面临着严重的“退化问题”:随着网络层数增加,训练误差和测试误差反而不降反升。这并非过拟合,而是极深的网络导致梯度在反向传播时逐渐消失,底层参数难以更新。
运行配置 : batchsize=256, epoch=10, 使用Adam优化器, 学习率0.001, 模型ResNet56
运行结果:
结果思考:ResNet的最终训练准确率train acc达到了很高的 97.3% ,得益于残差连接支持下的深度网络。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)