64位运算的8051单片机,是“屠龙之技”还是“涅槃重生”?——为8位MCU插上64位的翅膀
64位运算的8051单片机,是“屠龙之技”还是“涅槃重生”?——为8位MCU插上64位的翅膀
本文由DeepSeek AI撰写,笔者做了部分修改而成。
当32位、64位处理器横扫全球,仅有1KB内存的8051单片机却依然活跃在无数家电、工控和传感器中。今天,我们抛出一个“离经叛道”的命题:如果让这款40岁高龄的经典芯片,硬核支持32位乘加、甚至64位累加运算,究竟是多此一举的“屠龙之技”,还是让它涅槃重生的关键一步?本文将深入剖析增强型8051的最新进展,结合加权平均、神经网络、FIR滤波等实例,并借鉴RISC-V与ARM Cortex-M的先进指令集,为百万8051开发者和工具链工程师开辟一条全新的思路。
第一部分:前言
在单片机(MCU)的浩瀚星空中,8051无疑是一颗恒久闪耀的“化石级”明星。诞生于1980年代的它,凭借开放的总线架构、简单的指令集和极低的门槛,四十多年来始终占据着嵌入式世界的半壁江山。从电子玩具、智能电表到汽车电子,无数设备的心脏依然是那颗运行在几兆赫兹、拥有寥寥几百字节RAM的8051内核。
然而,科技的浪潮从未停歇。物联网(IoT)、人工智能(AI)、电机矢量控制等新兴应用对计算能力提出了前所未有的要求。32位的ARM Cortex-M系列如日中天,开源的RISC-V也势头凶猛,它们拥有单周期乘法、硬件除法、SIMD指令甚至向量扩展。相比之下,传统8051的8位ALU、区区8位加法器和乘法器的“寒酸”配置,似乎显得格格不入。于是,一个灵魂拷问浮出水面:8051是否已经走到生命尽头?我们还需要继续投入资源去“魔改”这款老古董吗?
答案却出乎意料。近年来,以STC(宏晶科技)为代表的中国MCU厂商,推出了像AI8051U-8BIT这样的“魔改”8051单片机。它们不仅将主频提升到35MHz以上,更引入了32位硬件乘除单元(MDU32)。这些“越级”的特性,让8051第一次有能力直接处理32位整数运算、高精度累加和数字信号处理(DSP)算法。
但是,仅仅有硬件还不够。工具链——编译器、汇编器、指令集架构(ISA)的配套——同样决定生死。如果Keil C51、SDCC等编译器无法高效利用这些新指令,硬件的性能再强也只是空中楼阁。令人振奋的是,国内开发者“杨为民博士”已经推出了 “金水32051编译器” 和配套的 “金水明32051指令集” ,为32位/64位运算在8051上的落地提供了完整的软件生态基础。
本文正是立足于这一历史性节点,试图回答一个更本质的问题:我们真的需要具有64位运算能力的8051吗? 或者说,这样的“性能怪兽”对于广大8051用户和工具开发者,究竟意味着什么?
为了回答这个问题,我们将分四步展开。第二部分将首先展示当前增强型8051的硬件基础(以AI8051U为例)和软件工具链基础(金水明32051),并详细论述引入32位乘加指令及64位累加寄存器的现实意义。第三部分则通过加权平均、神经网络和FIR滤波三个具体C语言程序,揭示乘加指令如何在微观层面“点石成金”。第四部分借鉴RISC-V和ARM Cortex-M这两大成功架构中的乘加指令设计,为8051的未来演进提供“他山之石”。最后,第五部分给出结论:64位运算能力的8051绝非鸡肋,而是传统8位MCU面向智能边缘计算的一次华丽蜕变,它或为开发者和工具链厂商开辟了一条高性价比、低门槛的创新发展路径。
第二部分:32位/64位运算在8051上的软硬件基础及其现实意义
一、AI8051U:已具备32位乘加运算的硬件底座
很多人对8051的刻板印象停留在“8位累加器、8位ALU、16位地址总线”。但实际上,现代增强型8051早已脱胎换骨。以最新发布的AI8051U单片机为例(STC官方数据):
- 内核加速:采用超高速8051流水线架构,在相同晶振下等效速度比传统8051快约13~70倍(具体取决于指令)。
- 32位硬件乘除单元(MDU32):支持32位×32位有符号/无符号乘法、32位÷32位除法(32位商和余数),单条指令即可触发硬件计算单元,耗时仅几个时钟周期。
- 这一套组合拳,让AI8051U在定点DSP性能上直逼低端Cortex-M4。可以说,AI8051U为8051平台提供了“准32位DSP”的硬件基础。
二、金水明32051:为8051构建32位整数运算的完整工具链
硬件再强,若没有编译器的支持,无异于“有剑不会使”。传统Keil C51编译器虽然支持扩展关键字long(32位),但遇到乘加运算时,仍然会生成大量8位操作序列:将32位数拆成4个字节,逐个相乘,再移位、累加,最后处理进位。这不仅浪费了MDU32的能力,甚至可能比纯软件模拟还慢(因为频繁调用软乘法库)。
打破这一僵局的是国内资深嵌入式专家杨为民博士。他开发的金水明32051编译器(基于开源SDCC深度定制)和配套的金水明32051指令集,首次为8051体系引入了对32位整数运算的原生指令支持:
- 新增了MUL EAX, EBX、DIVS EAX, RBX等32位指令,汇编器直接翻译为AI8051U的硬件MDU32序列。
更重要的是,金水明32051指令集保持向下兼容:而使用新L1指令的代码,则不但可以运行在支持MDU32的芯片上(如AI8051U等),也可以用8位指令模拟的方法运行在普通的8051单片机上。这种“渐进增强”的思路,既照顾了存量用户,又为高性能应用敞开了大门。
可以说,杨为民博士的工作填补了8051生态在32位DSP加速领域的最后一块拼图——软件工具链。从此,8051开发者可以在C语言层面愉快地写出类似sum += w[i] * x[i];的代码,而编译器会自动生成最高效的硬件乘加指令。
三、8051引入32位乘加指令的现实意义
为什么要在8051单片机上做这种“吃力不讨好”的事情?直接换成Cortex-M单片机不香吗?答案在于8051的巨大存量、极低的功耗和成本优势。具体来说,引入32位乘加指令和64位累加寄存器具有以下现实意义:
- 性能跃迁:将原本需要数百周期的核心运算(如点积、卷积)压缩到数个周期,使8051能够胜任实时数字信号处理。例如,10阶FIR滤波器在48kHz采样率下,每个采样点需要20次乘加运算。传统8051无法完成实时滤波,而增强型8051轻松应对。
- 解放内存和代码量:32位乘加指令一条顶过去数十条8位操作指令,显著减少代码体积。对于Flash只有8KB~64KB的低端8051,这意味可以在有限空间内塞入更复杂的算法。
- 开启新应用领域:
- 电机FOC控制:需要高精度的Clarke/Park变换和PID调节,这些变换的核心就是乘加。
- 传感器融合:加速度计、陀螺仪的数据融合(如互补滤波、Mahony算法)需要频繁的32位乘加。
- AIoT节点:在设备端运行轻量级神经网络(如TinyML中的全连接层、卷积层),乘加指令可以大幅加速推理。
- 数字电源:高频率PID运算和补偿器计算。
- 保持8051生态优势:对于习惯使用8051的工程师而言,无需学习ARM或者RISC-V的全新外设库和启动代码,只需在原有框架下升级芯片和编译器,就能获得指数级的性能提升。这种“低摩擦”迁移路径是企业最愿意接受的。
综上所述,硬件+工具链的双重准备,已经为让32位乘加8051单片机从“实验室玩具”变成“工程利器”打下了基础。接下来,我们将通过具体的代码示例,直观感受乘加指令是如何在幕后创造奇迹的。
第三部分:三大案例——乘加指令的实际工作原理
为了揭开乘加指令的神秘面纱,我们选取嵌入式领域最经典的三类计算任务:加权平均(信号平滑)、单神经元(神经网络基础)和FIR滤波器(数字信号处理基础)。每一个例子都会给出C语言实现,并剖析在传统8051和未来带MAC的增强型8051上,编译器分别生成了什么样的汇编代码。
案例一:加权平均
加权平均广泛用于传感器数据融合、指数移动平均等。代码非常简单:
// 数组长度 N,权值 w[i] 和数据 x[i] 均为 32 位有符号整数
// 返回加权总和(64位,避免溢出)
int64_t weighted_sum(int32_t *w, int32_t *x, uint8_t N) {
int64_t sum = 0;
for (uint8_t i = 0; i < N; i++) {
sum += (int64_t)w[i] * x[i];
}
return sum;
}传统8051(无硬件MAC)的典型汇编逻辑(Keil C51生成伪代码示意):
; 将 w[i] 和 x[i] 从内存加载到 R4..R7 (32位)
MOV R0, #低8位地址
MOV R1, #次低8位
...
LCALL _MUL32_LONG ; 调用软件32位乘子程序,结果放在 R2..R5 (64位)
LCALL _ADD64_LONG ; 调用软件64位加法,结果累加到 sum
DJNZ R6, loop每一次乘加需要两次函数调用,再加上循环控制,轻松超过300个时钟周期。
未来带MAC的增强型8051 生成的汇编:
; 假设 R0 指向 w 数组基地址,R1 指向 x 数组基地址,R2 为循环计数
CLR ACC64 ; 硬件清零64位累加寄存器(单周期)
LOOP:
MAC32 @R0, @R1 ; 硬件指令:读取32位w和x,乘得64位,加到ACC64
INC R0, #4 ; 指针移动4字节
INC R1, #4
DJNZ R2, LOOP
MOV @R3, ACC64L ; 将ACC64结果存储到内存
...案例二:单神经元(神经网络全连接层)
神经网络的全连接层(Fully Connected Layer)本质就是点积加上偏置。下面是单神经元的前向计算:
// 输入向量 x[0..D-1],权重 w[0..D-1],偏置 bias (32位)
int64_t neuron(int32_t *x, int32_t *w, uint8_t D, int32_t bias) {
int64_t sum = bias; // 偏置先存入ACC64
for (uint8_t i = 0; i < D; i++) {
sum += (int64_t)x[i] * w[i];
}
return sum; // 后续可接激活函数
}这里,偏置可以直接通过MOV ACC64, bias指令(扩展指令)加载到累加寄存器。循环内同样是MAC32指令。如果使用对称量化的8位整数神经网络,权重和输入可能已经是8位整数,那么还可以使用MAC16(16位乘加)进一步降低带宽和功耗。
正是乘加指令的存在,使得在8051上运行几十到几百个神经元的微型网络成为可能——推理时间从秒级缩短到毫秒级,完全可以满足实时控制需求。例如,一台智能风扇可以通过麦克风阵列采集声音,在本地运行一个简单语音唤醒模型,而无需连接云端。
案例三:有限脉冲响应(FIR)滤波器
FIR滤波器是DSP的基石,用于音频处理、心电信号滤波、振动分析等。其卷积方程为:
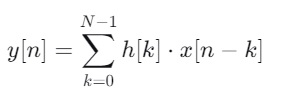
C语言实现如下:
// 系数 h[0..N-1],数据窗口 x[0..N-1](最新的数据在 x[0] 或 x[N-1])
int64_t fir(int32_t *h, int32_t *x_window, uint8_t N) {
int64_t y = 0;
for (uint8_t k = 0; k < N; k++) {
y += (int64_t)h[k] * x_window[N-1-k];
}
return y;
}64位累加寄存器保证了中间结果的精度:128阶32位定点系数乘积累加,可能产生超过32位的结果,但64位累加可以完全容错,只在最终输出时根据需要截断或饱和。
通过以上三个案例,我们可以看到乘加指令的本质作用:将频繁发生的“乘-加-累加”模式从软件多步模拟变成硬件原子操作。这不仅是速度的提升,更是将系统复杂度从O(n)指令降低到O(1)指令,使得实时DSP算法在低端MCU上落地成为可能。
第四部分:它山之石——RISC-V与ARM Cortex-M的乘加指令设计
如果说增强型8051是“老树开新花”,那么RISC-V和ARM Cortex-M就是当代表现最耀眼的两大指令集架构。分析它们在乘加指令上的设计思路,可以为8051的未来演进提供宝贵经验。
一、RISC-V:模块化的乘加哲学
RISC-V采用基础指令集(RV32I)加可选扩展模块的方式。与乘加相关的扩展包括:
- M扩展(整数乘除法)
- MUL:rd = rs1 * rs2(低32位)
- MULH:rd = (rs1 * rs2) >> 32(有符号高32位)
- MULHSU、MULHU:混合符号与无符号的高位乘积
- 没有直接乘加指令,需要程序员或编译器用MUL+ADD组合。这种设计保持了硬件简单性,但损失了累加效率。
- P扩展(DSP/SIMD)
- 引入SMAQA(带饱和的乘加)、SMMLA(双16位乘加)、KMMA(复杂乘加)等。
- 支持16位×16位并行乘加,结果累加到32位或64位寄存器。
- 非常类似于ARM的DSP指令,适合音频、语音编码。
- V扩展(向量)
- vwmacc.vv:向量乘加,vd[i] += vs1[i] * vs2[i]。
- 单条指令完成整个向量的点积,并且支持可配置的SEW(标准元素宽度)。
RISC-V给我们的启示是:灵活的模块化。8051也可以借鉴此思路,定义一个“MDU32扩展”作为可选指令集,仅在高性能型号中支持,普通型号保持兼容。未来甚至可以定义“P51扩展”(类似RISC-V的P扩展),增加SIMD乘加指令。
二、ARM Cortex-M:DSP指令集的艺术
ARM Cortex-M系列从M3开始就内置了硬件乘加指令,M4/M7/M33更是强化了DSP扩展,M55/M85引入了Helium(M-Profile Vector Extension)。具体乘加指令有:
- MLA:Rd = Ra + Rm * Rn(32位乘加,结果低32位)
- SMLAL:(RdHi,RdLo) += Rm * Rn(64位累加,最接近8051的MAC32+ACC64)
- SMLAD:Rd = Ra + (Rm_top * Rn_top) + (Rm_btm * Rn_btm)(双16位并行乘加)
- SMUAD:Rd = SAT( (Rm_top*Rn_top) + (Rm_btm*Rn_btm) )(带饱和的双乘加)
- SMLALD:(RdHi,RdLo) += (Rm_top*Rn_top) + (Rm_btm*Rn_btm)(双乘加64位累加)
可以看到,ARM的设计比RISC-V M扩展更激进,它直接将多种常见DSP模式固化为单条指令,极大减少了代码量和开发难度。但这也意味着硬件设计更复杂、功耗略高。
对于8051而言,ARM的思路非常有价值:既然我们已经有了MUL32,完全可以在下一代增强型中增加MAC16_DUAL(两条16位乘并行)、MAC32_SAT(带饱和的乘加)等变体。这些指令对电机控制、音频合成尤其有用。
三、他山之石如何“攻玉”
综合两种架构的优点,我们可以为“64位运算8051”的未来发展提出几条具体建议:
|
方向 |
借鉴来源 |
8051实现建议 |
|
模块化指令集 |
RISC-V |
定义“MDU32+”子集,包含 MAC32 、 MAC16 、 MUL32 、 DIV32 ,后续可扩展“DSP”子集 |
|
并行乘加 |
ARM SMLAD |
增加 MAC16_DUAL 指令,单周期完成两个16位乘加,并累加到ACC64 |
|
饱和运算 |
ARM SMUAD |
增加 MAC32_SAT ,防止累加器溢出,适用于控制环路 |
|
向量支持 |
RISC-V V扩展 |
对于高端的8051变体,可加入 VMAC 指令,单指令处理4个8位或2个16位乘法(类似Helium的MVE) |
|
编译器内联支持 |
金水明32051 |
将上述新指令通过 __builtin_ 函数或编译器自动向量化暴露给C语言 |
通过学习RISC-V和ARM,我们并不是要盲目复制,而是要看到它们解决相同问题(DSP加速)的不同路径。8051的独特优势在于极端低成本和简单性,因此新增的乘加指令不能过于复杂,但又要足够高效。一个平衡点就是:将金水明32051指令集作为基石,加上少量并行变体,就能覆盖90%的实时DSP应用场景。
第五部分:结论
回到开篇的问题:我们真的需要具有64位运算的8051吗?
答案是:不仅需要,而且正当其时。
从硬件基础看,AI8051U等新一代芯片已经实装了32位乘加指令和64位累加寄存器,提供了物理可能性。从软件工具链看,金水明32051编译器和配套指令集填补了从C语言到硬件指令的鸿沟,使得开发者可以零门槛享受硬件加速红利。从应用价值看,加权平均、神经网络、FIR滤波等真实场景在乘加指令加持下,性能提升可达几十倍到上百倍,让8051破圈进入电机控制、AIoT、数字信号处理等原本属于ARM的领地。
从更广阔的视角看,RISC-V和ARM的成功经验告诉我们:指令集演进必须兼顾硬件简洁性与软件友好性。8051作为地球上出货量最大的MCU内核之一(每年数十亿颗),拥有全球数百万熟悉其开发范式的工程师。如果能在保持原有生态的同时,通过少量“高性价比”的扩展指令(如MAC32、ACC64)大幅提升特定领域的计算能力,那么这颗“老古董”还将继续活跃在下一个四十年。
对于广大的8051单片机用户,本文提供的思路是:不要轻易放弃8051转投ARM,先看看最新的增强型8051是否已经满足你的性能需求。尤其是在成本敏感、功耗受限且需要中等强度数字信号处理的场合,带有MAC单元的8051往往是性价比之王。
对于工具软件开发者,本文呼吁:尽快为SDCC、Keil、IAR等编译器添加对新指令的支持,并探索自动向量化技术。只有让开发者用最自然的C代码写出高性能程序,才能激活整个生态的潜力。金水明已经做出了示范,我们期待更多开源贡献者加入。
最后,让我们做一个大胆的展望:不远的将来,我们将看到主频100MHz、带硬件浮点单元(FPU)和向量MAC的8051芯片问世。到那时,64位累加寄存器将不再是“奢侈品”,而是每一颗8051的标配。嵌入式世界没有“过时”的架构,只有“未被充分挖掘”的潜力——8051的涅槃重生,就从这一条乘加指令开始。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)