MySQL索引设计避坑-失效场景与深分页优化
索引能让查询变快,但索引建错了、用错了,反而会拖慢写入,还可能让查询根本用不上。真正实战时,最重要的不是背“索引有哪些”,而是能判断:什么时候该建索引、怎么建、为什么失效、深分页为什么慢。
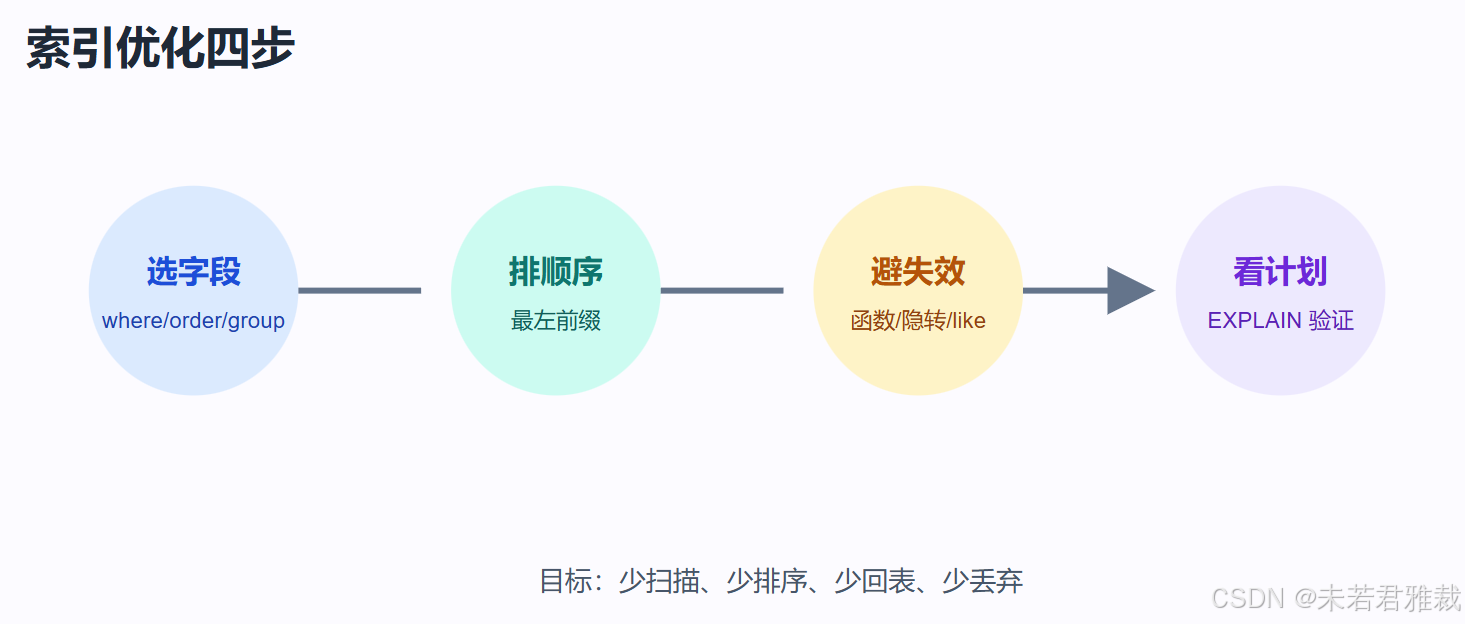
什么时候适合建索引
建索引前先问三个问题:
- 表数据量是否足够大?
- 这个字段是否经常用于查询、排序、分组?
- 字段区分度是否足够高?
如果一张表只有几百行,索引收益通常不明显。如果一个字段只有“男/女”或“启用/禁用”几种值,单独建索引也不一定划算。
常见原则如下:
| 原则 | 说明 |
|---|---|
| 大表高频查询字段优先 | 数据量越大,索引收益越明显 |
| WHERE、ORDER BY、GROUP BY 字段优先 | 这些字段直接影响过滤和排序成本 |
| 选择区分度高的列 | 区分度越高,扫描范围越小 |
| 长字符串考虑前缀索引 | 降低索引体积 |
| 优先考虑联合索引 | 兼顾过滤、排序和覆盖索引 |
| 控制索引数量 | 索引会增加写入和维护成本 |
| 索引列尽量 NOT NULL | 便于优化器判断和使用索引 |
联合索引与最左前缀法则
假设有联合索引:
CREATE INDEX idx_name_status_address
ON tb_seller(name, status, address);
它的顺序是 name -> status -> address。查询必须从最左列开始匹配,不能跳过中间列。
| 查询条件 | 是否充分使用索引 |
|---|---|
where name = ? |
可以使用 name |
where name = ? and status = ? |
可以使用 name,status |
where name = ? and status = ? and address = ? |
可以使用三列 |
where status = ? |
不满足最左前缀 |
where name = ? and address = ? |
status 被跳过,后续列利用受限 |
最左前缀不是死记硬背,它来自 B+ 树联合排序的规则。联合索引先按第一列排序,第一列相同再按第二列排序,第二列相同再按第三列排序。
索引失效的常见场景
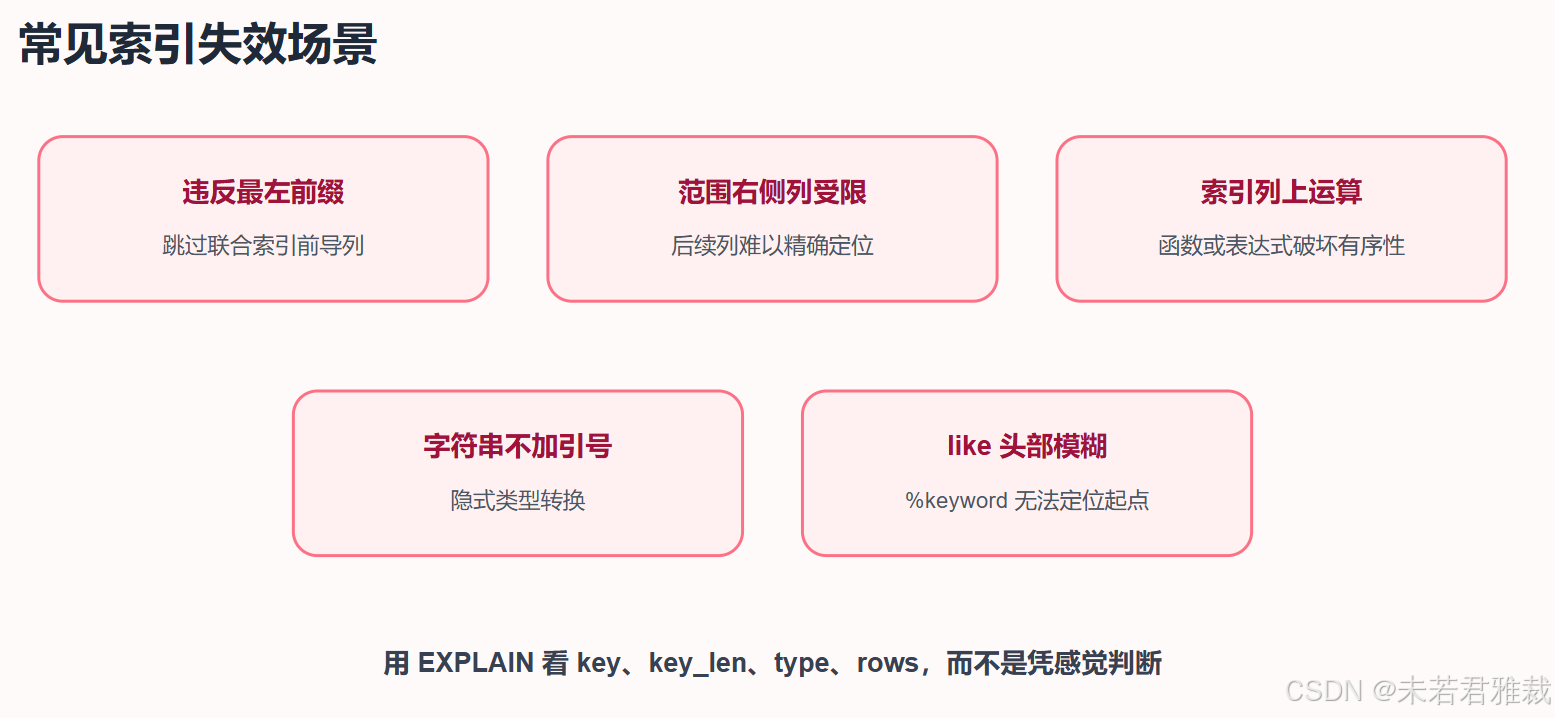
判断一条 SQL 为什么没用好索引,可以先按下面这棵树走一遍:
1. 违反最左前缀法则
联合索引没有从最左列开始使用,或者中间跳过某列,会导致索引无法完整使用。
2. 范围查询右侧列难以继续使用
WHERE name = 'Tom'
AND status > 1
AND address = 'Shanghai'
如果 status 是范围查询,那么它右边的 address 通常难以继续利用索引进行精确定位。
3. 在索引列上做运算或函数
WHERE substring(phone, 1, 3) = '138'
这类写法会让优化器难以直接利用原始索引值。更好的方式是改写查询,或增加额外字段保存可索引的结果。
4. 字符串不加引号
WHERE phone = 13800138000
如果 phone 是字符串类型,MySQL 可能发生隐式类型转换,导致索引使用异常。应该写成:
WHERE phone = '13800138000'
5. like 以百分号开头
WHERE name LIKE '%Tom'
B+ 树索引适合从左到右匹配。头部模糊时,无法确定从索引哪个位置开始查。
尾部模糊通常更友好:
WHERE name LIKE 'Tom%'
用 EXPLAIN 快速验证
判断索引是否生效,别靠感觉,直接看执行计划:
EXPLAIN
SELECT id, name
FROM tb_seller
WHERE name = 'Tom' AND status = 1;
重点观察:
| 字段 | 怎么看 |
|---|---|
key |
实际使用的索引 |
key_len |
联合索引用到了多少 |
type |
是否出现 all、index |
rows |
预估扫描行数是否过大 |
Extra |
是否出现额外排序、临时表、覆盖索引等信息 |
深分页为什么慢
普通分页常这样写:
SELECT *
FROM tb_sku
ORDER BY id
LIMIT 9000000, 10;
它并不是直接跳到第 9000000 行再取 10 条,而是要先找到并排序前 9000010 条记录,再丢弃前 9000000 条。页码越深,丢弃成本越高。
覆盖索引加子查询优化
一种常见优化思路是先用覆盖索引查出目标页的主键,再回表取完整数据。
SELECT t.*
FROM tb_sku t
JOIN (
SELECT id
FROM tb_sku
ORDER BY id
LIMIT 9000000, 10
) a ON t.id = a.id;
这个写法的关键是:子查询只扫描主键或覆盖索引,减少排序和回表的数据量。

深分页优化的关键,是先让 MySQL 少搬数据:
如果业务允许,也可以改成游标分页:
SELECT id, title, price
FROM tb_sku
WHERE id > ?
ORDER BY id
LIMIT 10;
游标分页不适合任意跳页,但非常适合信息流、列表向下加载等场景。
面试回答模板
可以这样回答:
索引设计要结合数据量、查询频率、字段区分度和排序分组场景。常用作 where、order by、group by 的高区分度字段适合建索引,长字符串可以考虑前缀索引,高频组合查询可以建联合索引并尽量覆盖查询字段。索引失效常见原因有违反最左前缀、范围查询右侧列无法继续使用、在索引列上做函数或运算、字符串不加引号、like 以百分号开头。深分页慢是因为 MySQL 需要扫描并丢弃大量前置记录,可以用覆盖索引加子查询,或者改成基于游标的分页。
小结
索引优化的核心是“让 MySQL 少扫描、少排序、少回表”。建索引前先看业务查询,写 SQL 时避免破坏索引使用,遇到深分页时减少无效扫描。最后一定用 EXPLAIN 验证,而不是凭感觉判断。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)