这篇论文《3EED: Ground Everything Everywhere in 3D》聚焦于户外3D视觉定位(3D Visual Grounding)任务,提出了一个大规模、多平台、多模态的基准数据集和评估框架,旨在解决现有方法在真实户外环境中跨平台泛化能力不足的问题。
一、论文提出的核心问题
1. 现有3D视觉定位基准的局限性
| 问题 |
说明 |
| 局限于室内场景 |
现有基准(ScanRefer、Nr3D)基于室内RGB-D数据,场景小、对象种类有限 |
| 单一平台 |
大多基于车载传感器(如KITTI、nuScenes),缺乏无人机、四足机器人等平台 |
| 规模小 |
现有户外数据集(如Talk2Car、STRefer)对象数量少、表达方式单一 |
| 缺乏多模态对齐 |
往往只提供LiDAR或RGB之一,不提供同步的多模态监督 |
2. 户外3D定位的真实挑战
| 挑战 |
说明 |
| 远距离稀疏性 |
LiDAR点云随距离增加而稀疏,破坏室内模型假设 |
| 极端尺度变化 |
从交通锥到大型车辆,固定尺寸锚点失效 |
| 跨平台视角差异 |
车载(平视)、无人机(俯视)、四足机器人(仰视)视角完全不同 |
| 传感器高度差异 |
不同平台的LiDAR安装高度导致空间关系(上/下)需要重新理解 |
3. 核心研究问题
如何构建一个覆盖多平台、多模态、大规模的3D视觉定位基准,并设计能够跨平台泛化的模型?
二、论文的解决方案
整体思路:数据集 → 基准协议 → 统一基线模型
| 组件 |
名称 |
内容 |
| 数据集 |
3EED |
128K对象、22K表达、3平台(车载/无人机/四足) |
| 基准协议 |
4种评估设置 |
单平台/跨平台/多目标/多平台联合训练 |
| 基线模型 |
CPA + MSS + SAF |
平台对齐 + 多尺度采样 + 尺度自适应融合 |
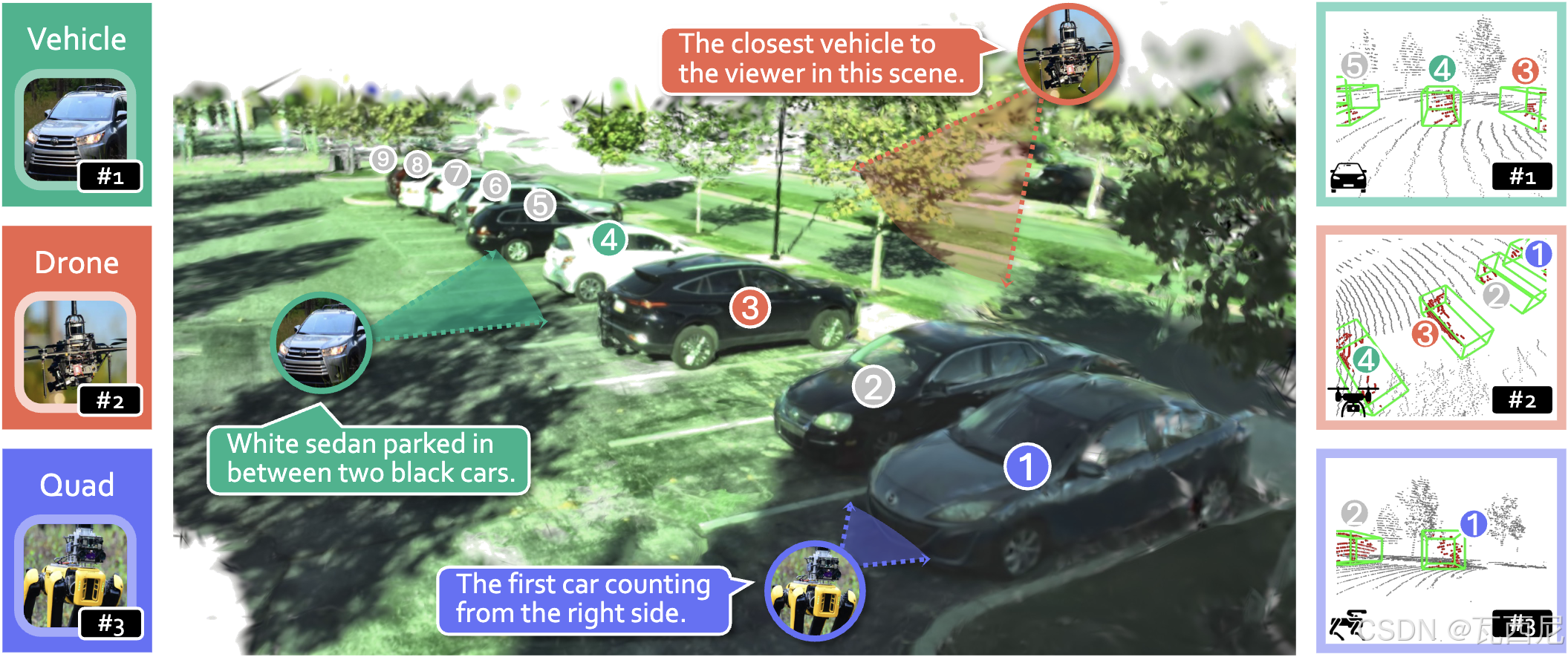
三、3EED数据集详解
1. 数据来源与平台
| 平台 |
数据来源 |
特点 |
| 车载(Vehicle) |
Waymo Open Dataset |
结构化道路、中等密度、水平视角 |
| 无人机(Drone) |
M3ED |
俯视、大视野、高密度、点云稀疏 |
| 四足机器人(Quadruped) |
M3ED |
低视角、近距离、仰视、人与环境交互 |
2. 数据规模
| 统计项 |
数量 |
| 场景总数 |
20,367 |
| 3D对象实例 |
128,735 |
| 指代表达 |
22,439 |
| 水平覆盖 |
280m × 240m |
| 垂直高差 |
80m |
比现有最大户外数据集大10倍
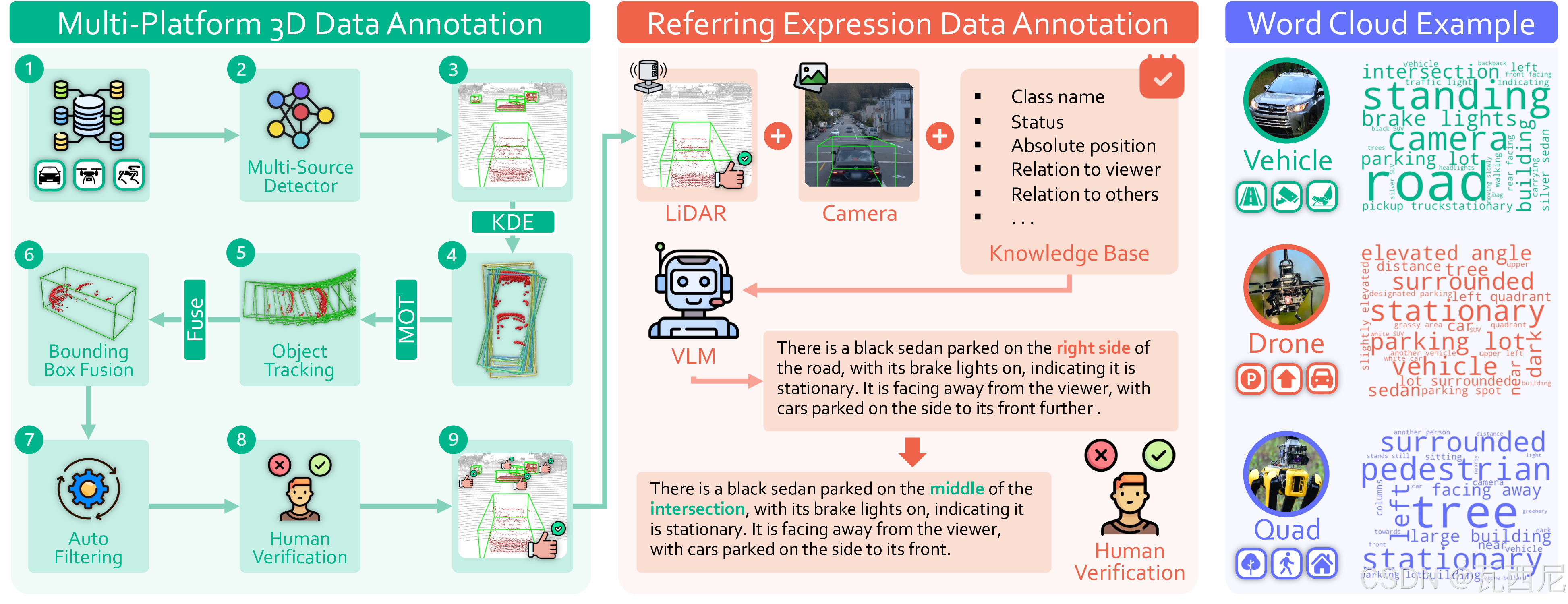
3. 标注流程(三阶段)
3D框标注(图2左)
- 伪标签种子:6个SOTA检测器(PV-RCNN、CenterPoint等)在外部数据预训练后推理
- 自动整合:KDE融合 + CTRL多目标跟踪 + Tokenize Anything验证类别
- 人工精修:人工校对修正
指代表达生成(图2中)
- 结构化提示:Qwen2-VL-72B基于5类模板生成描述(类别、状态、绝对位置、自中心位置、空间关系)
- 人工验证:人工检查语义正确性、空间忠实性、无歧义性
4. 平台差异分析(图4)
| 维度 |
车载 |
无人机 |
四足 |
| 俯仰角分布 |
近0° |
负大角度(俯视) |
宽范围 |
| 目标密度 |
中等 |
高(最拥挤) |
低 |
| LiDAR点数/目标 |
462 |
102 |
112 |
| 典型场景 |
街道 |
停车场、广场 |
人行道、公园 |
四、基准协议(4种评估设置)
| 设置 |
训练平台 |
测试平台 |
说明 |
| 单平台单目标 |
同平台 |
同平台 |
评估域内性能 |
| 跨平台迁移(零样本) |
车载 |
无人机/四足 |
评估跨平台泛化能力 |
| 多目标定位 |
同平台 |
同平台 |
一句话指多个目标,需全部定位正确 |
| 多平台联合 |
全部 |
各平台 |
评估多平台联合训练的协同效果 |
五、基线模型设计
1. 核心架构
LiDAR点云 → 多尺度PointNet++ → 视觉token
↓
语言表达 → RoBERTa(冻结)→ 语言token
↓
双向交叉注意力
↓
Transformer解码器 → 3D框
2. 三大创新模块
| 模块 |
名称 |
作用 |
技术细节 |
| CPA |
Cross-Platform Alignment |
消除平台视角差异 |
重力对齐 + 高度归一化 |
| MSS |
Multi-Scale Sampling |
解决远距离稀疏性 |
多半径采样(0.6~4.8m) |
| SAF |
Scale-Aware Fusion |
自适应选择最佳尺度 |
MLP动态融合多尺度特征 |
3. 损失函数
- 匈牙利匹配(类似DETR)
- 框回归损失(L1 + GIoU)
- 对比对齐损失(视觉↔语言)
六、实验结果
1. 单平台训练 → 跨平台测试(表2)
| 训练平台 |
测试平台 |
方法 |
Acc@25 |
提升 |
| 车载 |
车载(域内) |
Ours |
78.37% |
+25.99% |
| 车载 |
无人机(零样本) |
Ours |
18.16% |
+16.62% |
| 车载 |
四足(零样本) |
Ours |
36.04% |
+25.86% |
结论:跨平台性能差距大,但我们的方法显著缩小了差距。
2. 多平台联合训练(表2)
| 测试平台 |
方法 |
Acc@25 |
提升 |
| 车载 |
Ours |
80.86% |
+17.45% |
| 无人机 |
Ours |
53.45% |
+9.25% |
| 四足 |
Ours |
53.31% |
+10.17% |
结论:联合训练平衡了各平台性能,无人机提升最大。
3. 多目标定位(表3)
| 指标 |
基线最佳 |
Ours |
提升 |
| Acc@25 |
26.91% |
32.32% |
+5.41% |
| mIoU |
51.07% |
56.40% |
+5.33% |
结论:多目标定位更具挑战性(需要全部目标正确),我们的方法优势更明显。
4. 消融实验(表4)
| 配置 |
车载Acc@25 |
四足Acc@25 |
| -CPA(无平台对齐) |
71.76 |
49.93 |
| -MSS(无双尺度) |
75.65 |
51.40 |
| -SAF(无自适应融合) |
80.38 |
51.98 |
| 完整模型 |
80.86 |
53.31 |
结论:三个模块互补,共同提升性能。
七、与前面几篇论文的对比(重要)
| 维度 |
3EED |
M3D |
3D-RAD |
SpatialMed |
MedSG-Bench |
| 领域 |
自动驾驶/机器人 |
医学 |
医学 |
医学 |
医学 |
| 输入 |
LiDAR点云+RGB |
3D CT |
3D CT |
3D CT |
2D图像序列 |
| 任务 |
3D视觉定位 |
通用3D分析 |
VQA诊断 |
空间推理 |
序列定位 |
| 平台 |
车载/无人机/四足 |
固定 |
固定 |
固定 |
固定 |
| 输出 |
3D框 |
文本/3D框/mask |
文本 |
数值/选项 |
2D框 |
| 规模 |
128K对象 |
120K图文对 |
34K QA |
9.8K QA |
9.6K QA |
| 核心贡献 |
跨平台泛化 |
3D通用模型 |
多时间诊断 |
空间量化评估 |
序列定位 |
一句话区分:
- M3D:一个模型做所有3D医学任务
- 3EED:一个模型在车载/无人机/四足上都能准确定位“左边那辆车”
八、总结
| 项目 |
内容 |
| 问题 |
户外3D视觉定位缺乏多平台、大规模基准,现有模型跨平台泛化能力差 |
| 方法 |
构建3EED数据集(3平台、128K对象、22K表达)+ 4种基准协议 + CPA/MSS/SAF基线模型 |
| 核心发现 |
跨平台性能差距大(车载→无人机从52%→1.5%);联合训练可显著提升;稀疏性是无人机最大挑战 |
| 意义 |
首个面向多平台户外3D视觉定位的大规模基准,推动跨平台泛化研究 |
开源地址
https://project-3eed.github.io/




 12
12 0
0


 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)