教学课件:化工过程网络的网络攻击检测(LSTM 多标签分类,中文教学版)
文章目录
- 前言
- 一、先把题目翻成人话
- 二、为什么这是“多标签分类”而不是普通分类?
- 三、题目里的数据长什么样?
- 四、这道题到底在做什么?
- 五、先导入库
- 六、先加载每个攻击场景的数据
- 七、这些输入数组的 shape 应该怎么理解?
- 八、先构造输出标签 `RNN_output`
- 九、把所有场景拼成统一数据集
- 十、为什么标准化时要先 reshape?
- 十一、为什么这里只标准化输入,不标准化输出?
- 十二、为什么训练集和测试集划分时要注意“攻击组合都要被看到”?
- 十三、为什么这里选择 LSTM 而不是普通全连接网络?
- 十四、建立 LSTM 模型:每一层为什么这样写?
- 十五、为什么损失函数是 `BinaryCrossentropy`?
- 十六、为什么训练时的 accuracy 不等于最终 Exact-Match Accuracy?
- 十七、开始训练模型
- 十八、画训练损失和验证损失曲线
- 十九、在测试集上评估模型
- 二十、为什么还要手动把概率变成 0/1 标签?
- 二十一、计算 Exact-Match Accuracy
- 二十二、计算每个标签的 F1-score 和宏平均 F1
- 二十三、计算“每种具体攻击组合”的准确率
- 二十四、为什么多标签混淆矩阵不能直接用普通 confusion matrix?
- 二十五、画多标签混淆矩阵热图
- 二十六、可选任务:二分类攻击检测
- 二十七、这道题以后怎么快速拆解?
- 二十八、学生最容易犯的错
- 二十九、课堂追问
- 总结
前言
本文是一份面向代码基础较弱学生的中文教学版 notebook,主题为化工过程网络的网络攻击检测。文章特点如下:
- 全中文解释
- 说明框和代码框完全分开
- 每一步都讲“为什么这样做”
- 不只告诉你代码是什么,还会告诉你:
- 这一步在整道题里起什么作用
- 这个函数接收什么类型的数据
- 为什么这里要这样处理 3D 时序数据
- 为什么这是多标签分类而不是普通分类
- 加入常见错误、课堂追问、可迁移思路
通过本文,你将学会如何使用 LSTM 构建多标签分类模型,来检测化工过程网络中哪些传感器受到了攻击。
一、先把题目翻成人话
这道题的背景是:
我们研究一个两台串联 CSTR 的化工过程网络。
系统里有 4 个关键状态变量:
x = [ C E B 1 , T 1 , C E B 2 , T 2 ] x = [C_{EB1},\; T_1,\; C_{EB2},\; T_2] x=[CEB1,T1,CEB2,T2]
它们分别表示:
- 反应器 1 中乙苯浓度 C E B 1 C_{EB1} CEB1
- 反应器 1 温度 T 1 T_1 T1
- 反应器 2 中乙苯浓度 C E B 2 C_{EB2} CEB2
- 反应器 2 温度 T 2 T_2 T2
同时还有 4 个操纵输入:
u = [ F 1 , F 2 , C F 1 , C F 2 ] u = [F_1,\; F_2,\; CF_1,\; CF_2] u=[F1,F2,CF1,CF2]
也就是:
- 两个进料流量
- 两个冷却介质流量
题目说:黑客可能会攻击这些关键传感器,篡改传输给控制系统的测量值。
我们的目标是根据一段时间序列数据,判断:
- 系统是否遭到攻击
- 哪一个或哪几个传感器被攻击了
二、为什么这是“多标签分类”而不是普通分类?
这是这道题最核心的理解点之一。
普通单标签分类
普通分类通常是:
一个样本只属于一个类别
例如:
- 猫 / 狗
- 合格 / 不合格
这道题不是这样
这道题里,一个样本可能对应:
- 没有攻击:
[0,0,0,0] - 只攻击 C E B 1 C_{EB1} CEB1:
[1,0,0,0] - 只攻击 T 1 T_1 T1:
[0,1,0,0] - 同时攻击 T 1 T_1 T1 和 T 2 T_2 T2:
[0,1,0,1]
也就是说:
每个输出向量里的 4 个位置,都要单独判断 0 或 1
所以这不是“从很多类里选一个”,而是:
4 个标签同时判断,每个标签都可以独立是 0 或 1
这就叫 multi-label classification(多标签分类)。
三、题目里的数据长什么样?
题目说每个样本是一个三维数组,维度是:
( N , T , F ) (N,\; T,\; F) (N,T,F)
其中:
- N N N:样本数
- T T T:时间步长度
- F F F:特征数
在这道题里:
- 每个时间步的特征数是 8
因为有 4 个状态变量 + 4 个输入变量 - 输出标签维度是 4
因为有 4 个传感器是否被攻击
从参考解还能看到,最终拼接后的数据 shape 是:
RNN_input shape = (640, 5, 8)RNN_output shape = (640, 4)
这说明:
- 一共有 640 个样本
- 每个样本长度是 5 个时间步
- 每个时间步有 8 个输入特征
- 每个样本对应 4 维多标签输出
四、这道题到底在做什么?
你可以把整道题拆成 5 步:
第一步:数据集构建
把不同攻击场景的数据拼接起来,并为每个场景建立对应标签。
第二步:数据划分
把数据分成训练集和测试集,而且要尽量保证各种攻击类型都出现在两边。
第三步:模型训练
使用 LSTM 读取时间序列数据,输出 4 维攻击标签概率。
第四步:模型评价
除了看训练时的 accuracy,还要看:
- Exact-Match Accuracy
- 每个标签的 F1-score
- 每种具体攻击组合的识别准确率
第五步:结果可视化
画出多标签混淆矩阵热图,并讨论模型到底错在什么地方。
五、先导入库
这一步是在做“工具准备”。
为什么要导入这些库?
numpy:加载.npy文件、处理数组matplotlib:画训练损失曲线train_test_split:划分训练集和测试集StandardScaler:标准化输入tensorflow.keras:建立 LSTM 模型sklearn.metrics:评价多标签分类效果seaborn、pandas:画混淆矩阵热图
小白提醒
先不要急着写模型。
这种题里,真正最容易错的是:
- 数据 shape
- 标签构造
- 标准化
- 评价指标
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import (
accuracy_score,
precision_score,
recall_score,
f1_score
)
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Input, LSTM, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.metrics import Precision, Recall, BinaryAccuracy
六、先加载每个攻击场景的数据
根据参考解,这道题有 6 种场景数据文件:
- 无攻击
- 攻击 C E B 1 C_{EB1} CEB1
- 攻击 T 1 T_1 T1
- 攻击 C E B 2 C_{EB2} CEB2
- 攻击 T 2 T_2 T2
- 同时攻击 T 1 T_1 T1 和 T 2 T_2 T2
为什么要分场景加载?
因为这些 .npy 文件本身并没有自动带标签。
所以我们要先知道:
- 这个文件对应什么攻击场景
- 然后再手动给它配标签
RNN_input_Noattack = np.load('RNN_input_Noattack.npy')
RNN_input_attack_CEB1 = np.load('RNN_input_attack_CEB1.npy')
RNN_input_attack_T1 = np.load('RNN_input_attack_T1.npy')
RNN_input_attack_CEB2 = np.load('RNN_input_attack_CEB2.npy')
RNN_input_attack_T2 = np.load('RNN_input_attack_T2.npy')
RNN_input_attack_T1_T2 = np.load('RNN_input_attack_T1_T2.npy')
print("RNN_input_Noattack shape =", RNN_input_Noattack.shape)
print("RNN_input_attack_CEB1 shape =", RNN_input_attack_CEB1.shape)
print("RNN_input_attack_T1 shape =", RNN_input_attack_T1.shape)
print("RNN_input_attack_CEB2 shape =", RNN_input_attack_CEB2.shape)
print("RNN_input_attack_T2 shape =", RNN_input_attack_T2.shape)
print("RNN_input_attack_T1_T2 shape =", RNN_input_attack_T1_T2.shape)
七、这些输入数组的 shape 应该怎么理解?
假设其中一个文件 shape 是:
(80, 5, 8)
它的意思是:
- 80 个样本
- 每个样本有 5 个时间步
- 每个时间步有 8 个特征
为什么是 8 个特征?
因为每个时间步包含:
- 4 个状态量: [ C E B 1 , T 1 , C E B 2 , T 2 ] [C_{EB1}, T_1, C_{EB2}, T_2] [CEB1,T1,CEB2,T2]
- 4 个输入量: [ F 1 , F 2 , C F 1 , C F 2 ] [F_1, F_2, CF_1, CF_2] [F1,F2,CF1,CF2]
所以总共 8 个输入特征。
八、先构造输出标签 RNN_output
这是整道题最关键的“读题翻译”步骤之一。
题目要求输出标签表示:
- 哪些传感器被攻击了
标签顺序固定为:
[ C E B 1 , T 1 , C E B 2 , T 2 ] [CEB1,\; T1,\; CEB2,\; T2] [CEB1,T1,CEB2,T2]
所以:
- 无攻击 →
[0,0,0,0] - 只攻击
CEB1→[1,0,0,0] - 只攻击
T1→[0,1,0,0] - 同时攻击
T1和T2→[0,1,0,1]
为什么这里是多标签,不是 one-hot?
因为 one-hot 是“只能有一个 1”。
而这里允许多个传感器同时被攻击,所以可以同时有多个 1。
num_sensors = 4
# 1) 无攻击
RNN_output_nominal = np.zeros((RNN_input_Noattack.shape[0], num_sensors))
# 2) 攻击 CEB1
RNN_output_attack_CEB1 = np.zeros((RNN_input_attack_CEB1.shape[0], num_sensors))
RNN_output_attack_CEB1[:, 0] = 1
# 3) 攻击 T1
RNN_output_attack_T1 = np.zeros((RNN_input_attack_T1.shape[0], num_sensors))
RNN_output_attack_T1[:, 1] = 1
# 4) 攻击 CEB2
RNN_output_attack_CEB2 = np.zeros((RNN_input_attack_CEB2.shape[0], num_sensors))
RNN_output_attack_CEB2[:, 2] = 1
# 5) 攻击 T2
RNN_output_attack_T2 = np.zeros((RNN_input_attack_T2.shape[0], num_sensors))
RNN_output_attack_T2[:, 3] = 1
# 6) 同时攻击 T1 和 T2
RNN_output_attack_T1_T2 = np.zeros((RNN_input_attack_T1_T2.shape[0], num_sensors))
RNN_output_attack_T1_T2[:, 1] = 1
RNN_output_attack_T1_T2[:, 3] = 1
九、把所有场景拼成统一数据集
这一步的作用是:
把“分散在不同文件里的场景数据”合并成一个完整训练集
为什么输入和输出要一起拼?
因为每个输入样本都必须对应自己的标签。
所以:
- 输入怎么拼
- 标签就必须按同样顺序拼
RNN_input = np.concatenate((
RNN_input_Noattack,
RNN_input_attack_CEB1,
RNN_input_attack_T1,
RNN_input_attack_CEB2,
RNN_input_attack_T2,
RNN_input_attack_T1_T2
), axis=0)
RNN_output = np.concatenate((
RNN_output_nominal,
RNN_output_attack_CEB1,
RNN_output_attack_T1,
RNN_output_attack_CEB2,
RNN_output_attack_T2,
RNN_output_attack_T1_T2
), axis=0)
print("RNN_input shape =", RNN_input.shape)
print("RNN_output shape =", RNN_output.shape)
十、为什么标准化时要先 reshape?
这是时序题里最常见的疑问之一。
现在输入 RNN_input 是 3D:
(样本数, 时间步, 特征数)
但 StandardScaler() 只能直接处理二维数据:
(样本数, 特征数)
那怎么办?
先把 3D 拉平成 2D:
RNN_input.reshape(-1, 8)
这里的意思是:
- 前面多少行自动算
- 每一行保留 8 个特征
为什么这样是合理的?
因为标准化本质上是:
对每个特征列单独做均值为 0、方差为 1 的变换
而我们并不需要保留“样本-时间步”的层级结构来学均值和方差。
只要保证每一列对应的是同一个物理特征即可。
十一、为什么这里只标准化输入,不标准化输出?
在这道题里,输出 RNN_output 是 4 维 0/1 标签。
例如:
[0,0,0,0][1,0,0,0]
这种二元标签本身就已经是分类目标,所以不应该再做 StandardScaler。
否则标签就不再是清晰的 0/1 语义了。
所以这题和前面你做的 RNN 回归题不同:
- 回归题:输入和输出都可能标准化
- 这道多标签分类题:通常只标准化输入,不标准化输出
scaler_X = StandardScaler().fit(RNN_input.reshape(-1, 8))
print("Input mean =", scaler_X.mean_)
print("Input var =", scaler_X.var_)
mean_x = scaler_X.mean_
std_x = np.sqrt(scaler_X.var_)
np.save('mean_x.npy', mean_x)
np.save('std_x.npy', std_x)
RNN_input = scaler_X.transform(RNN_input.reshape(-1, 8)).reshape(-1, 5, 8)
十二、为什么训练集和测试集划分时要注意“攻击组合都要被看到”?
题目明确要求:
训练集和测试集划分时,要保证所有攻击类别都在两边出现。
如果你只是随便随机切,有可能出现:
- 某种攻击组合只出现在训练集
- 或只出现在测试集
这样评价就不公平。
更稳的做法
对于多标签问题,可以把每个 4 维标签先编码成一个“组合字符串”,比如:
[0,0,0,0]→"0000"[1,0,0,0]→"1000"[0,1,0,1]→"0101"
然后用这个字符串去做分层划分。
label_combo = np.array([''.join(map(str, row.astype(int))) for row in RNN_output])
X_train, X_test, y_train, y_test = train_test_split(
RNN_input,
RNN_output,
test_size=0.3,
random_state=123,
stratify=label_combo
)
print("X_train shape =", X_train.shape)
print("X_test shape =", X_test.shape)
print("y_train shape =", y_train.shape)
print("y_test shape =", y_test.shape)
十三、为什么这里选择 LSTM 而不是普通全连接网络?
因为这道题的数据是时间序列。
每个样本不是“一行平面特征”,而是:
一段长度为 5 的多变量序列
LSTM 的优点在于:
- 能处理时间顺序
- 能学习前后时间步之间的依赖关系
- 比普通全连接层更适合这种动态过程建模
为什么不是一定要用普通 RNN?
普通 RNN 也可以,但 LSTM 往往更稳定,尤其在有时间依赖的系统里更常见。
十四、建立 LSTM 模型:每一层为什么这样写?
参考解里使用的是两层 LSTM:
- 第一层
LSTM(64, return_sequences=True) - 第二层
LSTM(32, return_sequences=False) - 再接
Dropout(0.2) - 最后输出层
Dense(4, activation='sigmoid')
为什么输入 shape 是 (timesteps, features)?
因为 Keras 中时序模型的输入格式是:
(时间步数, 特征数)
这道题里就是:
(5, 8)
为什么第一层 return_sequences=True?
因为第二层 LSTM 还需要接收整段序列,而不是只接收最后一个时间点。
为什么第二层 return_sequences=False?
因为我们最终要压缩成一个整体特征向量,再输出 4 维标签。
为什么输出层是 Dense(4, activation='sigmoid')?
因为:
- 一共有 4 个标签
- 每个标签都独立判断 0/1
- 所以每个输出都应该是一个独立概率
- 这正是
sigmoid的典型用法
model = Sequential()
model.add(Input(shape=(X_train.shape[1], X_train.shape[2])))
model.add(LSTM(64, activation='tanh', return_sequences=True))
model.add(LSTM(32, activation='tanh', return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(4, activation='sigmoid'))
model.compile(
optimizer=Adam(learning_rate=1e-3),
loss=BinaryCrossentropy(),
metrics=[
BinaryAccuracy(name='accuracy'),
Precision(name='precision'),
Recall(name='recall')
]
)
model.summary()
十五、为什么损失函数是 BinaryCrossentropy?
因为这是多标签二分类问题。
对每一个标签来说,本质上都在问:
这个传感器有没有被攻击?
也就是一个个独立的 0/1 判断。
所以用:
BinaryCrossentropy()
是非常自然的。
为什么不是 CategoricalCrossentropy?
因为 CategoricalCrossentropy 更适合“单标签多分类”,也就是很多类里选一个。
而这里允许多个标签同时为 1,所以不适合。
十六、为什么训练时的 accuracy 不等于最终 Exact-Match Accuracy?
这是整道题里非常值得讲清楚的点。
训练时 Keras 里的 BinaryAccuracy 是:
逐元素 看每一个标签位置预测得对不对
也就是说,如果一个样本真实标签是:
[0,1,0,1]
预测成:
[0,1,0,0]
那它仍然会有 3/4 的位置预测正确。
但题目要求的 Exact-Match Accuracy 是:
一个样本只有当 4 个标签全部正确 时,才算对
所以上面那个例子,在 Exact-Match 下就是 完全错误。
这也是为什么:
- 训练 accuracy 看起来可能很高
- 但 Exact-Match Accuracy 往往更严格、更低
十七、开始训练模型
这一步的参数和参考解保持一致:
epochs=100batch_size=64validation_split=0.1verbose=2
为什么要画 loss curve?
因为 loss 曲线能帮助你判断:
- 模型是不是在正常收敛
- 是不是可能过拟合
history = model.fit(
X_train, y_train,
epochs=100,
batch_size=64,
validation_split=0.1,
verbose=2
)
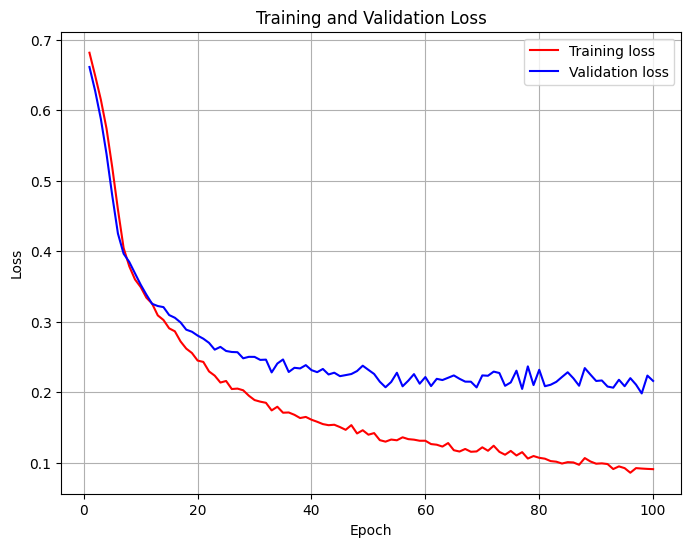
十八、画训练损失和验证损失曲线
这张图最主要是帮助学生看:
- 训练损失是否持续下降
- 验证损失是否也同步下降
- 两者是否出现明显分离
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.figure(figsize=(8, 6))
plt.plot(epochs, loss, 'r', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.show()
十九、在测试集上评估模型
这一步是看模型在“没见过的数据”上的表现。
注意这里输出的:
lossaccuracyprecisionrecall
都是基于模型编译时设定的指标。
print("=== Test Evaluation ===")
test_results = model.evaluate(X_test, y_test, verbose=0)
for name, val in zip(model.metrics_names, test_results):
print(f"{name}: {val:.4f}")
二十、为什么还要手动把概率变成 0/1 标签?
模型最后输出的是 4 个 sigmoid 概率,例如:
[0.02, 0.91, 0.11, 0.84]
这表示模型认为:
- 第 1 个标签为 1 的概率是 0.02
- 第 2 个标签为 1 的概率是 0.91
- 第 3 个标签为 1 的概率是 0.11
- 第 4 个标签为 1 的概率是 0.84
但最终评价时,我们需要明确的 0/1 结果。
所以通常会设一个阈值,比如 0.5:
- 概率 > 0.5 → 判成 1
- 否则 → 判成 0
y_prob = model.predict(X_test, batch_size=256, verbose=0)
y_pred = (y_prob > 0.5).astype('int32')
print("前 5 个预测结果:")
print(y_pred[:5])
二十一、计算 Exact-Match Accuracy
这一步正是题目要求的核心评价指标之一。
它在问什么?
对于一个样本,4 个标签是否全部同时预测正确?
如果 4 个标签只错一个,也算整条样本预测失败。
exact_match_acc = accuracy_score(y_test, y_pred)
print(f"Exact-Match Accuracy = {exact_match_acc:.4f}")
二十二、计算每个标签的 F1-score 和宏平均 F1
为什么还要算 F1-score?
因为多标签分类里,如果某些攻击类别比较少,光看 accuracy 可能不够。
F1-score 综合考虑了:
- Precision
- Recall
所以更能反映每个标签的识别质量。
f1_per_label = f1_score(y_test, y_pred, average=None)
f1_macro = f1_score(y_test, y_pred, average='macro')
print("F1 Score (per label) =", np.round(f1_per_label, 4))
print("F1 Score (macro avg) =", f1_macro)
二十三、计算“每种具体攻击组合”的准确率
题目还要求:
对具体标签组合分别看识别效果
例如:
[1,0,0,0][0,1,0,0][0,1,0,1]
这样做的意义是:
看模型到底是在哪些攻击场景上表现好,哪些场景上表现差。
def calc_specific_accuracy(y_true, y_pred, target):
target = np.array(target)
mask = np.all(y_true == target, axis=1)
total = np.sum(mask)
if total == 0:
return 0.0, 0, 0
correct = np.sum(np.all(y_pred[mask] == target, axis=1))
acc = correct / total
return acc, correct, total
targets = {
"[1,0,0,0]": [1,0,0,0],
"[0,1,0,0]": [0,1,0,0],
"[0,0,1,0]": [0,0,1,0],
"[0,0,0,1]": [0,0,0,1],
"[0,0,0,0]": [0,0,0,0],
"[0,1,0,1]": [0,1,0,1],
}
print("Detailed Accuracy by Label Combination")
print("=====================================")
for name, vec in targets.items():
acc, correct, total = calc_specific_accuracy(y_test, y_pred, vec)
print(f"Accuracy for {name}: {correct}/{total} = {acc:.4f}")
二十四、为什么多标签混淆矩阵不能直接用普通 confusion matrix?
普通 confusion matrix 适用于:
一个样本只属于一个类别
但这里每个样本是一个 4 维二进制向量。
所以我们不能直接用标准单标签混淆矩阵。
解决办法
把每一种“真实标签组合”和“预测标签组合”都当成一个整体模式,
然后自己统计:
- 真值是某种组合
- 预测成了哪种组合
这就是参考解里手工构造 confusion matrix 的原因。
true_labels = np.array([
[0,0,0,0], # 无攻击
[1,0,0,0], # 攻击 CEB1
[0,1,0,0], # 攻击 T1
[0,0,1,0], # 攻击 CEB2
[0,0,0,1], # 攻击 T2
[0,1,0,1] # 同时攻击 T1 和 T2
], dtype=int)
predicted_labels_all_combinations = np.array([
[0,0,0,0],[1,0,0,0],[1,1,0,0],[1,1,1,0],[1,1,1,1],
[0,1,0,0],[0,1,1,0],[0,1,1,1],
[0,0,1,0],[0,0,1,1],[1,1,0,1],[1,0,1,1],
[0,0,0,1],[1,0,1,0],[1,0,0,1],[0,1,0,1]
], dtype=int)
confusion_matrix = np.zeros((len(true_labels), len(predicted_labels_all_combinations)), dtype=int)
for idx in range(len(y_test)):
true_idx, pred_idx = None, None
for i, true_label in enumerate(true_labels):
if np.array_equal(y_test[idx], true_label):
true_idx = i
break
for j, pred_label in enumerate(predicted_labels_all_combinations):
if np.array_equal(y_pred[idx], pred_label):
pred_idx = j
break
if true_idx is not None and pred_idx is not None:
confusion_matrix[true_idx, pred_idx] += 1
df_confusion_matrix = pd.DataFrame(
confusion_matrix,
index=[str(label.tolist()) for label in true_labels],
columns=[str(label.tolist()) for label in predicted_labels_all_combinations]
)
display(df_confusion_matrix)
二十五、画多标签混淆矩阵热图
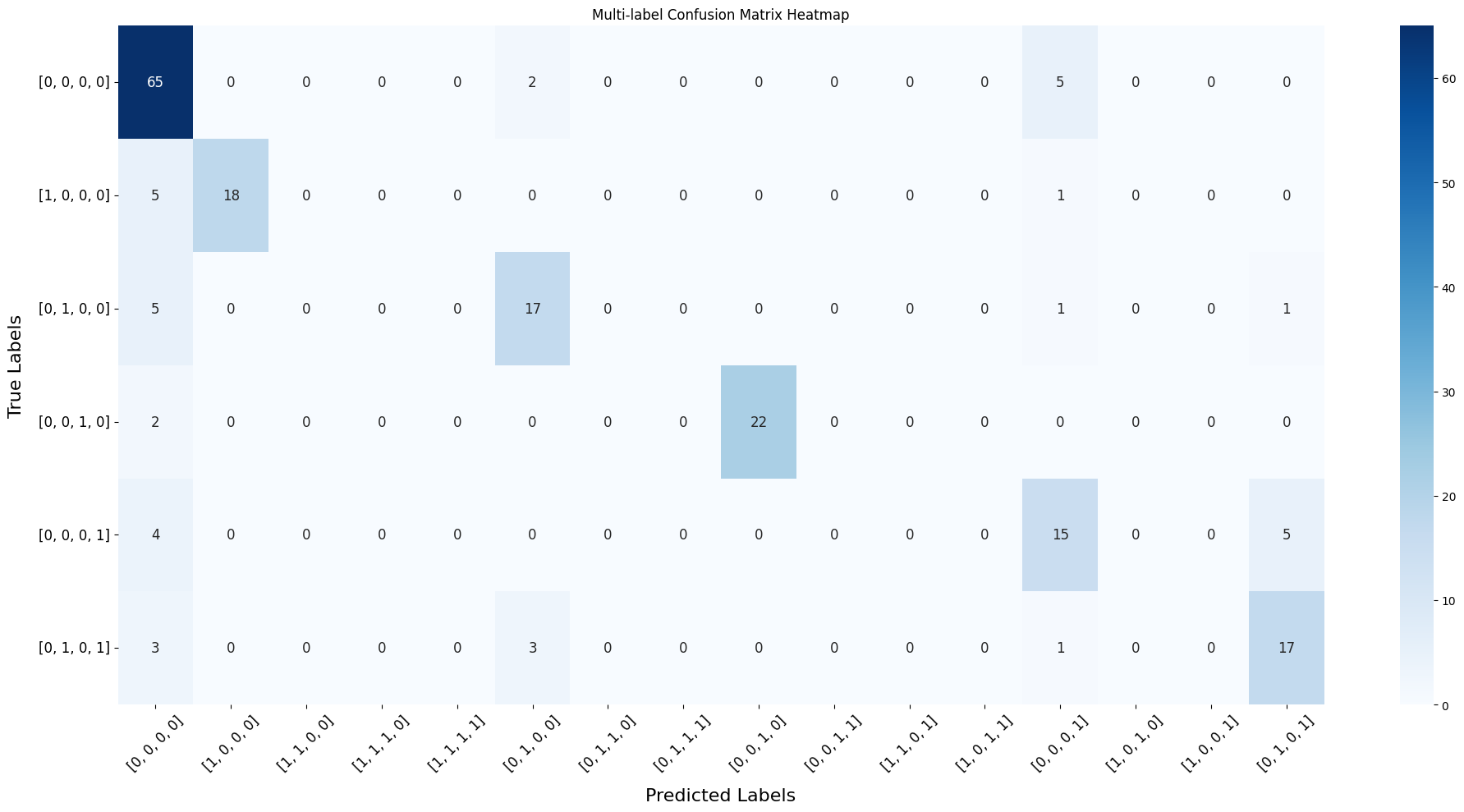
这张图最适合拿来做课堂分析,因为它能帮助学生看出:
- 哪些真实攻击模式经常被识别对
- 哪些模式容易被识别错
- 错误通常会错到哪一种模式上
plt.figure(figsize=(20, 10))
sns.heatmap(
df_confusion_matrix,
annot=True,
cmap='Blues',
fmt='d',
annot_kws={'size': 12}
)
plt.xlabel('Predicted Labels', fontsize=16, labelpad=12)
plt.ylabel('True Labels', fontsize=16, labelpad=12)
plt.xticks(fontsize=12, rotation=45)
plt.yticks(fontsize=12, rotation=0)
plt.title("Multi-label Confusion Matrix Heatmap")
plt.tight_layout()
plt.show()
二十六、可选任务:二分类攻击检测
题目最后还给了一个 optional task:
把原来的 4 维标签:
y = [ y C E B 1 , y T 1 , y C E B 2 , y T 2 ] y = [y_{CEB1},\; y_{T1},\; y_{CEB2},\; y_{T2}] y=[yCEB1,yT1,yCEB2,yT2]
压缩成一个二分类标签:
0:无攻击1:至少有一个传感器被攻击
为什么这个任务通常更容易?
因为它不需要你精确指出“攻击的是哪一个传感器”,
只需要判断:
有没有攻击
所以二分类通常比多标签精确识别更容易。
y_train_bin = (y_train.sum(axis=1) > 0).astype(int)
y_test_bin = (y_test.sum(axis=1) > 0).astype(int)
print("前 10 个二分类标签(train):")
print(y_train_bin[:10])
二十七、这道题以后怎么快速拆解?
以后学生遇到类似“时序 + 攻击识别 + 多标签输出”的题,可以按这个流程拆:
- 先看输入是几维数组
- 先看每个时间步有几个输入特征
- 先明确输出是不是多标签
- 为每个攻击场景手动建立标签
- 把所有场景拼成统一数据集
- 只标准化输入,不标准化 0/1 标签
- 用 LSTM 处理序列
- 输出层神经元个数 = 标签维度
- 用 sigmoid + BinaryCrossentropy
- 不只看训练 accuracy,还要看:
- Exact-Match Accuracy
- F1-score
- 具体攻击组合的识别率
二十八、学生最容易犯的错
- 把这题当成普通单标签分类
- 不知道为什么输出层是 4 个神经元
- 不知道为什么用 sigmoid 而不是 softmax
- 错误地把输出标签做标准化
- 不理解训练 accuracy 和 Exact-Match Accuracy 的区别
- 直接用普通 confusion matrix,不知道多标签要单独处理
- 没有保证 train/test 里都包含各类攻击组合
二十九、课堂追问
- 为什么这题是多标签分类,不是普通分类?
- 为什么输出层必须是
Dense(4, activation='sigmoid')? - 为什么不能对输出标签做
StandardScaler()? - 为什么 BinaryAccuracy 和 Exact-Match Accuracy 不一样?
- 为什么多标签任务下,F1-score 比单纯 accuracy 更值得看?
- 为什么 train/test 划分时要考虑攻击组合的分布?
- 如果一个样本真实标签是
[0,1,0,1],预测成[0,1,0,0],在 Exact-Match Accuracy 下算对还是错?为什么?
总结
本文通过一个完整的化工过程网络攻击检测案例,系统地讲解了如何用 LSTM 解决多标签时序分类问题。关键要点如下:
- 理解多标签分类与单标签分类的本质区别。
- 掌握三维时序数据的 shape 含义与 reshape 操作。
- 学会构造多标签输出,并正确处理标准化问题。
- 使用 LSTM 处理序列,搭配 sigmoid 输出和 BinaryCrossentropy 损失。
- 评价模型不能只看逐元素 accuracy,还要使用 Exact-Match Accuracy、F1-score 和自定义混淆矩阵。
希望本文能帮助学生彻底理解这类题目的解决思路,并能够迁移到其他类似的时序多标签分类任务中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)