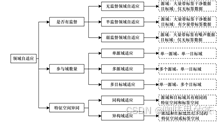
双源判别器助力城市场景语义分割
|
篇名 |
问题,背景 |
方法 |
其他 |
|
基于双源判别器的域自适应城市场景语义分割 (2023) |
1.跨域数据集外观分布不同导致域差异,导致对抗训练不稳定,分割精度不够理想。 2.网络对小目标分割精度不理想 |
(1)对源域 S 使用风格转换方法 FastPhotoStyle 得到新源域 S',从图像层面降低域差异。(2)利用生成器分别提取源域 S、新源域 S'和目标域 T 的分割特征图,将新源域的特征图作为中间桥梁,分别与源域特征图,目标域特征图进行通道维度上的特征融合(3)将得到的 2 个融合后的特征图输入双源判别器中,双源判别器和生成器迭代进行对抗训练
将自训练的伪标签(根据阈值选取置信度最高的)作为目标域的监督信息融入对抗训练值
将伪标签中最大概率类别出现的频率之和作为类平衡损失因子引入损失函数中 |
效果
(PS:对应方法) |
|
图引导的特征融合和分组对比学习的域自适应语义分割 (2024) |
1.原有方法没有考虑两个域像素之间的关联性以及类不平衡问题,使语义分割网络的跨域性能较差 2. 解决数据集中存在的类不平衡问题,同时提取到更多域不变特征 |
双跨域图卷积网络 (1)构造了跨域的位置相似性矩阵和通道相似性矩阵,通过双跨域图卷积来更新图像特征图上的 结点信息,建立域内和域间像素的长距离上下文依赖关系,使无监督域自适应分割网络能提取到更多 的域不变信息。 (2)为了解决类不平衡问题,提出了分组对比学习方法,构造了分组对比损失函数,以进一步提取域不变特征。 |
局限 域之间的位置信息挖掘的不够充分,导致模型在一些类别较复 杂的场景仍会出现错误分类的情况 |
|
一种结合域自适应的图像语义分割算法(2021) |
|
|
|
|
基于深度学习和域自适应的图像语义分割(2020) |
主要问题: 当前的图像分割方法都难以满足工业界的需要,尤其是为了采集训练用数据集带来 的巨大人力物力财力消耗 细分问题:
|
主要问题解决方案:
细分问题对应方案:
|
一、图像分割的国内外研究历史和现状 传统分割方法: 1.阈值法2.区域生长方法3.分水岭算法4.基于边缘检测的图像分割算法 基于深度学习的分割方法: 语义分割、实例分割、全景分割 特征提取领域: VGGNet(深度卷积神经网络)-> ResNet(残差网络)-> 全卷积网络-> 无监督的图像分割
|
|
基于鉴别模型和对抗损失的无监督域自适应方法(2020) |
收集注释良好的图像数据集来训练深度学习算法成本过高 且耗时,而仅在渲染图像训练的模型通常无法推广到真实图像 原方案:无监督域自适应算法:试图在 2个域之间映射一些表示或提取域不变的特征,将 2 个域映射到共同的特征空间 |
本文方法:基于生成对抗 网络( GAN) 架构的无监督域自适应方法: 使用鉴别模型,无需权重共享、对抗损失 和辅助分类任务,以无监督的方式学习从一个域到另一个域的变换。 首先使用源域中的标签学习鉴别表示, 然后使用通过域-对抗性损失学习的非对称映射将 目标数据映射到同一空间的单独编码。 辅助分类任务:结合辅助的任务学习共同的特征表示 |
本文方法优势:与特定任务的体系结构分离,跨标签空间 的泛化以及训练稳定 辅助分类任务优势:最大限度地丰富训练样本,增强学习到特征的 泛化性能,而且有效增大类间距离和减小类内距离, 有利于提高分类精度。 |
|
Bidirectional Learning for Domain Adaptation of Semantic Segmentation (双向学习在语义分割域适应中的应用) |
1.手动为大型数据集标注像素级别的标签既昂贵又耗时。现有的域适应技术要么局限于小数据集,要么与监督学习相比性能不佳 2.原有的通过减少域偏移获得的性能受限于图像到图像翻译的质量。一旦翻译失败,后续步骤就无计可施 |
提出了一种新的双向学习框架,用于图像语义分割的域适应。该系统包含两个独立的模块:图像到图像的转换模型和分割适应模型,学习过程涉及两个方向(即“翻译到分割”和“分割到翻译”)。整个系统形成了闭环学习。两个模型将交替促进彼此,从而使域差距逐渐减小。 在正向(即“翻译到分割”)上,提出了一种自监督学习(SSL)方法来训练分割适应模型。在反向,提出了一种新的感知损失,它强制每个图像像素与其翻译版本之间的语义一致性,从而在翻译模型和分割适应模型之间建立桥梁 图像翻译和分割适应模型共同训练,在训练过程中,分割模型可以为图像翻译提供反馈,帮助改善翻译结果的质量和准确性。同时,经过改进的翻译结果又可以作为更好的输入数据,进一步提升分割模型的性能 |
这种方法不仅可以利用虚拟数据来扩充训练集,还可以通过减少域差异来提高分割模型的性能 具体解释: 双向学习:该方法通过源域和目标域之间的双向信息流动来减小域间差异。模型不仅从源域学习,还从目标域中学习,增强了对目标域数据的适应能力。 自监督学习:自监督学习是一种利用数据自身的信息来训练模型的方法。这种方法不需要额外的标签,而是从数据中提取有用的特征进行训练。通过引入自监督学习,模型能够进一步增强其泛化能力,提高在未见过的数据上的性能。 |
|
Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training (基于类平衡自训练的无监督领域自适应语义分割)2018 |
源数据与目标数据之间存在很大差异,可能导致性能显著下降,并且不能通过进一步增加表示能力来轻易解决。 语义分割需要对每个像素进行密集的预测,这要求模型不仅要学习全局的域转换,还要保留精细的局部结构信息,通过最小化域对抗损失来减少源域和目标域特征分布之间的全局和类别差异的方法效果不理想 |
|
1.该模型能够更好地处理迁移难度较大的类别,因为不同类别的迁移难度可能因数据分布、视觉外观或语义复杂性而异。CBST的引入有效地缓解了这个问题,提高了整体分割性能。 2.利用空间先验信息提高了模型的适应性,增强了其在不同数据集之间的泛化能力。 3.该方法与对抗性域适应方法兼容,可与现有的对抗性域适应技术相结合,以进一步提高模型的性能 |
|
Unsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision(2020) |
原方法主要关注于减少源域和目标域之间的全局差异,忽略了目标域内部可能存在的分布变化。在实际应用中,目标域数据可能由于各种因素(如光照、噪声等)而呈现出不同的视觉外观和语义复杂性。这种域内差异可能导致模型在目标域内的某些子集上性能不佳。 |
提出了一种两步自监督域适应方法,旨在同时最小化域间差距和域内差距。1.域间适应。2.使用基于熵的排序函数将目标域划分为简单和困难两部分。3.从简单子域到困难子域采用自监督适应技术。 具体:1.使用源域数据训练一个初始的分割模型。2.利用该模型对目标域数据进行预测,并根据预测结果的不确定性或其他度量指标将目标域划分为不同的子集。3.针对每个子集应用自监督学习方法,通过最小化子集内部的分布差异来优化模型。 1.通过优化模型在简单图像上的性能,获得一个较好的初始模型。2.利用迭代自训练的方法,逐步将困难图像纳入训练过程(根据模型在简单图像上的预测结果来生成伪标签,将这些伪标签用于监督模型在困难图像上的训练,不断迭代该过程)。 |
优点:能够同时减少域间差距和域内差距,可以帮助模型更好地适应目标域内的各种变化条件,从而提高模型在目标域上的性能,进而提高整体性能。 不足:在现实中,源域和目标域之间的差距太大,使得难以在目标域中筛选出足够数量的简单部分进行域内监督 |
|
Source-Free Domain Adaptation for Semantic Segmentation (语义分割的无源域适应) 2021 |
现有的无监督域适应方法需要完全访问源数据集,以便在模型适应过程中减少源域和目标域之间的差距。但源数据集通常是私有的,无法与训练好的源模型一起发布。 |
SFDA框架:在知识迁移和模型适应两个阶段之间交替工作,通过知识迁移,从固定的源模型中保留源域知识 知识迁移:利用一个生成器来估计源域(工作域)并合成与真实源数据分布相似的假样本,这些样本可用于将域知识从训练好的源模型转移到目标模型。引入了一种双注意力蒸馏(DAD)机制,帮助生成器合成具有有意义语义上下文的样本,这有利于高效的像素级别域知识转移 模型适应:提出了一种基于熵的域内块级自监督模块(IPSM),以在模型适应阶段利用正确分割的块作为自监督(通过结合像素级和块级损失来充分利用目标域的信息,并进一步提高分割性能) |
解决了传统UDA方法需要源数据集的问题,这在保护数据隐私和实际应用中具有重要意义,此外,SFDA框架中的知识迁移和自监督学习机制,能够充分利用源模型和目标域数据的信息,进一步提高了域适应的效果。 |
|
Unsupervised Domain Adaptation for Semantic Image Segmentation: a Comprehensive Survey (2021.12) 综述 |
1.SiS(语义图像分割) 全卷积网络:完全卷积层;用全局环境补充 图形模型:在 SiS 中集成更大的上下文,用条件随机场补充卷积网络 递归神经网络:对像素间的长距离依赖关系进行建模 基于金字塔网络的模型:多分辨率重建架构 基于注意力的模型:对每个像素位置的多尺度特征进行权衡 基于编码器-解码器的模型:通过最小化GT和预测的分割图之间的重建损失来训练 膨胀卷积模型:改善多尺度处理的分割 Transformer模型:自注意力网络+前馈神经网络 2.DASiS(域自适应图像语义分割) 域对齐:特征级别的适应方法;图像级别的适应方法;输出级别...; 互补技术:伪标签和自我训练;目标预测的熵最小化;课程学习;共同培训;自组装;模型蒸馏;对抗性攻击; 自监督学习 3.Beyond classical DASiS 多源DASIS 多目标DASIS 领域泛化 半监督域适应 Active DASiS 无源域适应 跨域类标签不匹配 |
||
|
基于图像风格对抗和二重类别优化的夜间图像语义分割 (2024) |
夜间图像语义分割中存在语义信息传递丢失和不重视小频率类别问题 |
基于图像风格对抗和二重类别优化网络架构模型: 首先,将对抗学习风格语义信息和内容语义信息进行同时传递, 以避免语义信息的丢失,提高分割精度。 其次,利用二重类别指导策略:第 1 重对源域图像进行采样,对小类别目标进行调整;第 2 重引入重新加权策略,对小类别目标在最后结果输出时进行类别识别调整,以提高特殊类别目标的权重 |
应用:ITA模型能够较为准确地分割夜间道路图像,可供夜间自动驾驶任务借鉴 原有方法及其不足:
|
|
Empirical Generalization Study: Unsupervised Domain Adaptation vs. Domain Generalization Methods for Semantic Segmentation in the Wild (2023) |
现实很多场景不在模型的训练数据中表示,导致性能不佳,从目前的文献中尚不清楚哪种方法具有更好的泛化能力 |
提出了一个评估框架,在这个框架中,可以公平地比较最先进的UDA和DG方法的泛化能力。从这次评估中,我们发现利用未标记数据的 UDA 方法在泛化方面优于 DG 方法,并且可以在看不见的数据上提供与需要标记所有数据的全监督训练方法相似的性能。其中,使用未标记数据的能力在实现这一目标方面起着关键作用 |
结论 强烈建议使用 UDA 策略训练语义分割模型,这些模型需要在野外可靠且稳健地使用标记和许多未标记的数据,特别是考虑到未标记数据比标记数据更容易、更便宜地收集 |
|
Domain Adaptation for Semantic Segmentation with Maximum Squares Loss |
半监督学习中当将熵最小化应用于 UDA(无监督域适应) 进行语义分割时,熵的梯度偏向于易于转移的样本。 未标记目标域中存在类别不平衡 |
|
|
|
A review of domain adaptation without target labels 综述2019 |
分类器如何从源域学习并推广到目标域 |
|
未来方向及工作
|
|
针对车辆与行人检测的感兴趣区域自适应分割算法 |
在基于图像的车辆与行人检测中,车载摄像机采集的行车图像混杂大量无关信息,不仅耗费了计算资源还可能干扰检测 目标特征的提取,而现有的固定比例/区域的感兴趣区域图像分割适应性低 |
提出一种基于消失点和车辆高度的 ROI 自适应分割算法。首先,该算法利用道路消失点准 确找到道路位置,避免分割区域浪费,保证检测的实时性; 其次,综合车辆实际高度及检测算法有效检测距离对图像上车辆高度进行补充,减少目标不完整分割,增加检测的准确性; 最后,循环利用前一帧行车图像的车道消失点及其推导的实时俯仰角更新下一帧 ROI,以做到依据路面坡度情况及车身俯仰姿态的 ROI 实时自适应分割。 |
该算法速度快,鲁棒性好, 在不同情况下都能做到 ROI 的快速精确分割,有利 于后续检测的实时性和准确性 |
|
Unsupervised Domain Adaptation for Semantic Segmentation with Pseudo Label Self-Refinement 2024 |
利用为新数据生成的伪标签,指导学生模型的训练过程的方法在训练过程中存在嘈杂的伪标签传播问题,会导致性能下降 |
提出训练辅助伪标签细化网络,通过定位和细化它们来帮助自我训练不太容易受到错误伪标签预测的影响。它优化嘈杂的伪标签,提高其质量,并通过预测具有挑战性的像素(可能具有错误预测的标签)的二进制掩码来定位伪标签中的潜在错误。并且在框架中引入了两个额外的组件,对比学习和基于傅立叶的风格适应,以进一步提高训练模型的质量。 |
第一个是新的伪标签细化模块,该模块可以学习预测精细的伪标签以及包含噪声标签信息的错误掩码。 还开发了一种使用基于FFT的扰动的新颖训练策略,使我们能实现细化模块的预期行为。 该框架在三个 UDA 细分基准中明显优于 SOTA 方法,涵盖正常到恶劣天气和合成到实际适应。 |
|
Source-Free Domain Adaptation for RGB-D Semantic Segmentation with Vision Transformers2024 |
大多数领域适应方法无法有效地处理多模态数据(将RGB视觉效果与深度信息相结合) 目的:实现无源域适应,在不访问源数据的情况下进行适应 |
使用 RGB-D 视觉转换器进行无源语义分割 提出了MISFIT:MultImodal Source-Free Information fusion Transformer,这是一个深度感知框架,它将深度数据注入基于视觉转换器的分割模块中。此外,还提出了一种基于深度的熵最小化策略,以适应不同距离的权重区域。 在输入级别,在预训练期间利用了风格迁移;在功能层面,通过在变压器的注意力模块中交换信息来解决多模态设置;在输出层面,将基于深度的自学策略用于领域适应 通过利用由深度数据提供的互补信息驱动的多种适应策略,提出的多模态框架可以提高分割模型的鲁棒性和泛化能力 |
解决了具有挑战性的无源域适应设置,即在不重用源数据的情况下执行适应 未来的研究将致力于改进基于变换器的分割模型中对深度数据的利用,以及开发专门针对真实深度数据与估计深度数据之间不一致性的域适应策略 |
|
领域自适应研究综述2021 |
目标领域标注数据稀缺,训练数据和测试数据通常具有不同的输入特征空间和数据分布 |
1.算法分类
2.基于距离度量的方法 KL 散度、最大均值差异、Wasserstein 距离、最大密度差异 3.基于对抗学习的方法 基于对抗性判别的方法、基于对抗性生成的方法 4.其他代表性方法 基于重构的方法、基于样本选择的方法 |
图像分类、目标检测、自然语言处理、推荐系统
流式数据与在线持续迁移学习、语义分歧与开放集迁移学习、数据隐私与数据访问受限的迁移学习、负迁移 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)