AI产品经理必看!告别大模型适配难题,掌握LoRA微调降本增效3天落地!
文章针对AI产品经理在通用大模型适配业务场景中遇到的痛点,提出了大模型微调作为垂类AI产品定制化的核心手段。文章详细阐述了微调的必要性、定义、常见方式(全量、半参数、轻量化)、运行模式(云端在线、本地离线),并详细介绍了微调全生命周期流程(数据准备、训练配置、模型训练、效果评估、模型部署)。文章重点推荐LoRA作为轻量化微调的最优方案,并介绍了LLaMA开源模型、魔搭社区和阿里百炼平台。最后,通过电商售后AI案例,展示了如何利用LLaMA+LoRA在魔搭+百炼平台上实现低成本、高效的微调落地,提升客服效率。文章强调AI产品经理应掌握微调业务逻辑,选择合适的平台和框架,实现大模型定制化落地。
在AI产品应用落地过程中,绝大多数产品经理都会面临一个共性痛点:通用大模型适配业务场景能力差、专属话术不标准、行业知识缺失、幻觉问题频发。此时单纯依靠提示词工程、RAG检索增强无法从根本上解决模型底层适配问题,大模型微调就成为垂类AI产品定制化的核心手段。

本文专为AI产品经理打造,核心聚焦微调全生命周期流程,适合零基础入门、用于业务选型、产品方案撰写、落地项目实操。
二、读懂大模型微调
2.1 为什么要做微调?
通用大模型存在三大固有缺陷,这正是微调技术存在的核心价值所在:
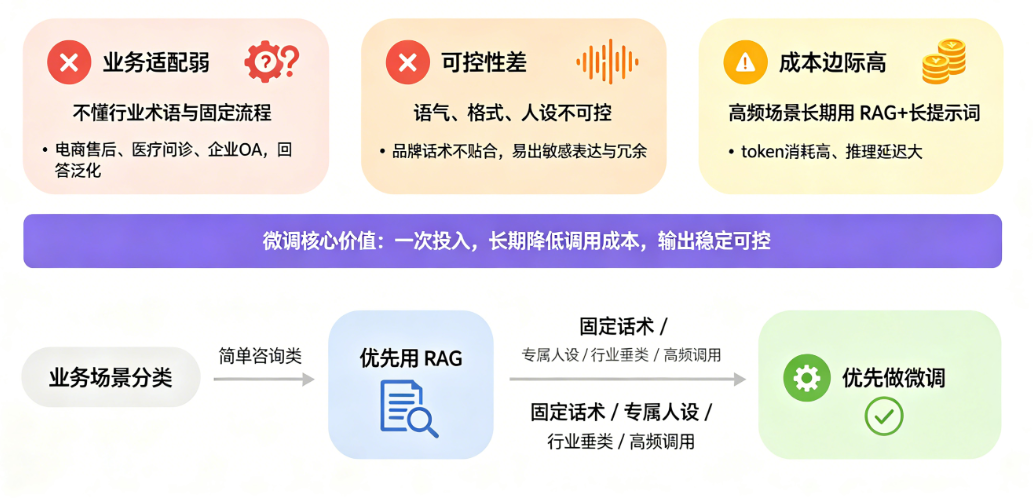
业务适配弱:通用模型不懂行业专业术语、固定业务流程,例如电商售后、医疗问诊、企业内部办公问答,回答泛化严重。
可控性差:模型输出语气、格式、人设不可控,无法贴合企业品牌话术,容易出现敏感表达、无效冗余回答。
成本边际高:高频复杂场景下,长期依赖RAG+长提示词,token消耗高、推理延迟大,微调一次可长期降低调用成本。
产品经理核心判断原则:简单咨询类业务优先用RAG;固定话术、专属人设、行业垂类、高频调用场景,优先做微调。
2.2 什么是微调
大模型微调,简单来说就是在预训练通用大模型的基础上,用专属业务数据集,二次训练优化模型权重,让模型适配特定业务逻辑。区别于从零训练大模型,微调低成本、短周期、轻量化,是中小企业AI产品最优选择。
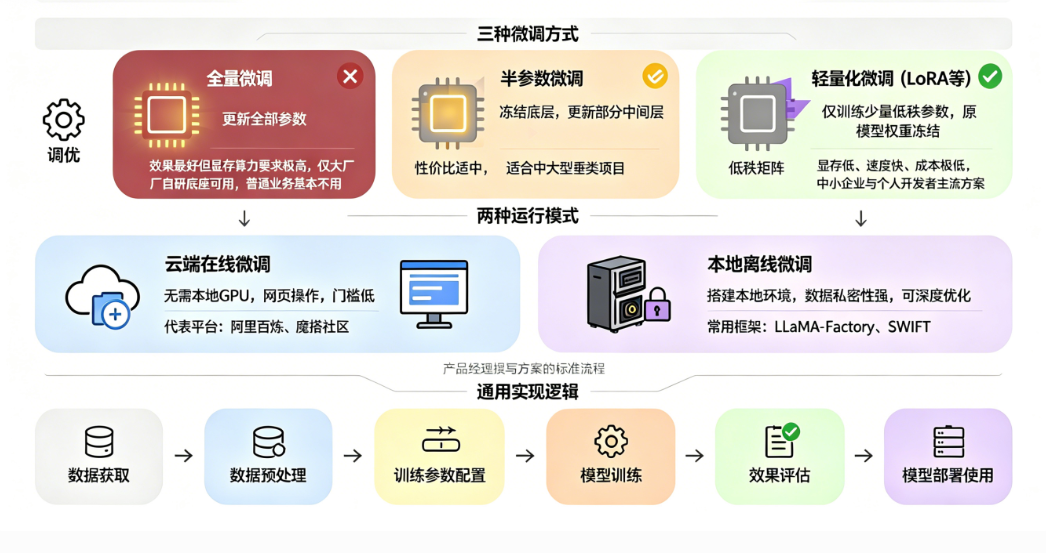
2.2.1 微调的三种常见方式
全量微调:更新模型全部参数,效果最好、显存算力要求极高、成本昂贵,仅适用于大厂自研底座模型,普通产品业务基本不用。
半参数微调:冻结大部分底层参数,更新部分中间层参数,性价比适中,适合中大型垂类项目。
轻量化微调:仅训练少量低秩矩阵参数,冻结原模型权重,显存占用低、训练速度快、成本极低,是目前中小企业、个人开发者主流方案。
2.2.2 微调两种运行模式
云端在线微调:依托公有云平台,无需本地GPU,网页可视化操作,上手门槛低,代表平台:阿里百炼、魔搭社区。
本地离线微调:搭建本地环境,依托显卡算力,数据私密性强,可自定义深度优化,常用框架:LLaMA-Factory、SWIFT。
2.3 微调通用实现逻辑
无论线上还是本地、无论哪种模型,微调的生命周期流程大致分为六个阶段,也是产品经理撰写方案的标准流程:数据获取→数据预处理→训练参数配置→模型训练→效果评估→模型部署使用。
三、主流微调框架与平台
3.1 Lora:轻量化微调最优方案
很多产品经理纠结为什么不用全量微调,优先选LoRA?

算力门槛低:仅训练1%-10%模型参数,无需高端A100显卡,普通消费级显卡、云端免费算力即可运行。
不破坏原模型:冻结底座模型权重,仅新增适配矩阵,不会丢失通用能力,避免灾难性遗忘。
灵活可插拔:训练后的LoRA适配器可随时加载、卸载,同一底座模型可适配多个业务场景。
适配人群:90%商业化AI产品、初创团队、个人开发者,也是阿里百炼、魔搭社区默认主推的微调方式。
3.2 LLaMA:开源通用底座模型
LLaMA是Meta推出的开源大模型,产品视角三大核心亮点:

开源免费可商用:无高额授权费用,魔搭社区可直接下载汉化优化版本。
体量灵活:涵盖1B、3B、7B、70B参数版本,轻量化模型适配端侧部署,大参数模型适配复杂业务。
适配LoRA:原生兼容轻量化微调,社区教程成熟、bug少,是垂类微调首选底座。
3.3 魔搭社区(ModelScope)
阿里旗下开源AI平台,定位模型+数据集+算力一站式开源社区,免费算力资源、海量开源数据集、LLaMA全系汉化模型、可视化微调界面,无需代码,适合做模型验证、低成本测试。
3.4 阿里百炼
阿里商业化AI开发平台,定位企业级商用微调,区别于魔搭:支持专有模型微调、数据加密隔离、官方售后、适配阿里云服务器部署,适合正式上线商业化产品,稳定性、安全性优于魔搭。

产品选型总结:测试验证用魔搭、商用上线用百炼、轻量化微调用LoRA、开源底座用LLaMA。
四、实战全流程:LLaMA+LoRA微调全生命周期(魔搭+百炼)
某电商企业需要定制售后咨询AI,痛点是通用模型话术口语化、售后流程不规范、不会处理退换货流程。解决方案:基于LLaMA3,采用LoRA微调,依托魔搭做训练测试、百炼做商用部署。
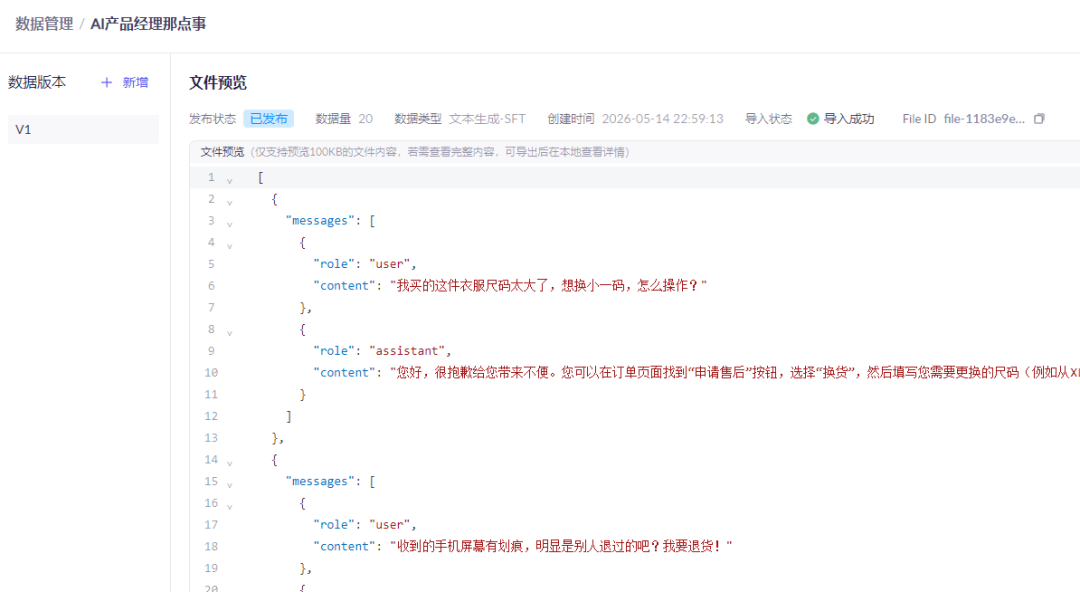
4.1 第一步:数据准备
4.1.1 数据获取渠道
开源数据集:魔搭社区、Hugging Face,获取通用对话、行业公开数据集,适合测试。
业务自有数据:企业历史聊天记录、客服工单、标准话术文档,核心商用数据,隐私性高。
人工构造数据:针对小众场景,人工编写问答对,补充开源数据短板。
4.1.2 数据准备工作
AI产品经理无需手动清洗数据,但要制定数据规范:


格式统一:统一为JSON问答对格式(instruction-input-output)【注意:这里由于我们使用的是百炼平台,无法识别Alpaca这种指令式三元组的形式,因此,我们提供chatML格式数据来进行模型微调】,适配百炼、魔搭通用模板。
去重降噪:删除重复问答、无效话术、敏感词汇,避免模型学习垃圾数据。
比例合理:训练集90%、验证集10%,少量优质数据优于大量杂乱数据,LoRA微调一般500-5000条数据即可达标。
4.2 第二步:训练前置配置
4.2.1 平台选择
测试阶段:魔搭社区,免费GPU,无需配置环境;商用阶段:阿里百炼,私有部署、数据加密。
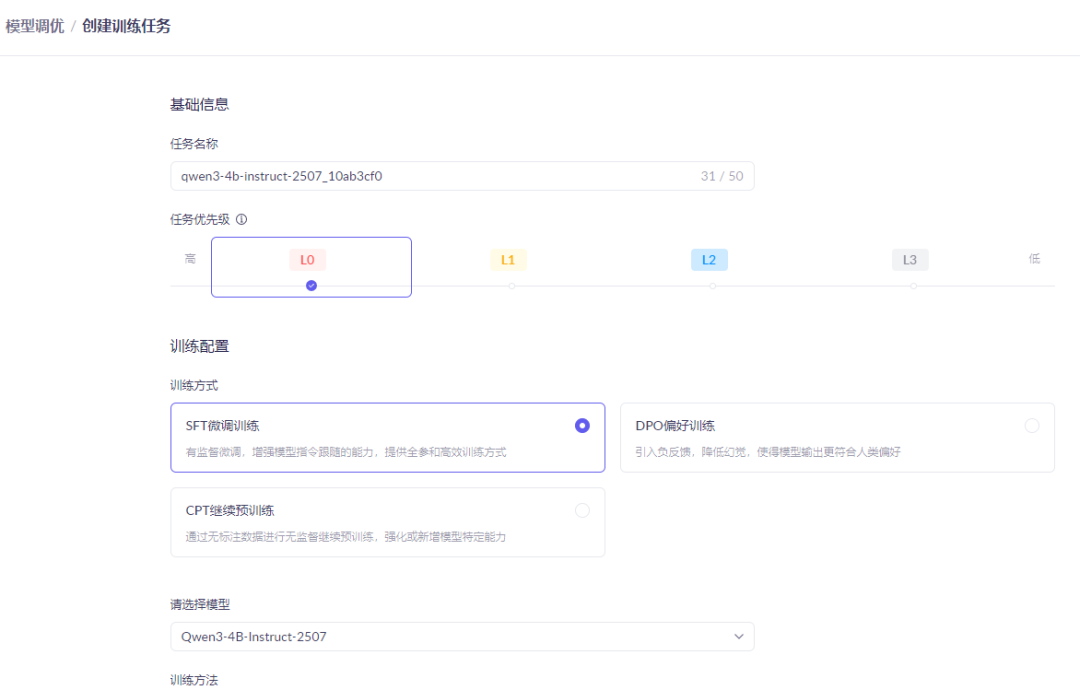
4.2.2 核心参数配置
整理通用最优参数,适配LLaMA+LoRA,直接套用即可:
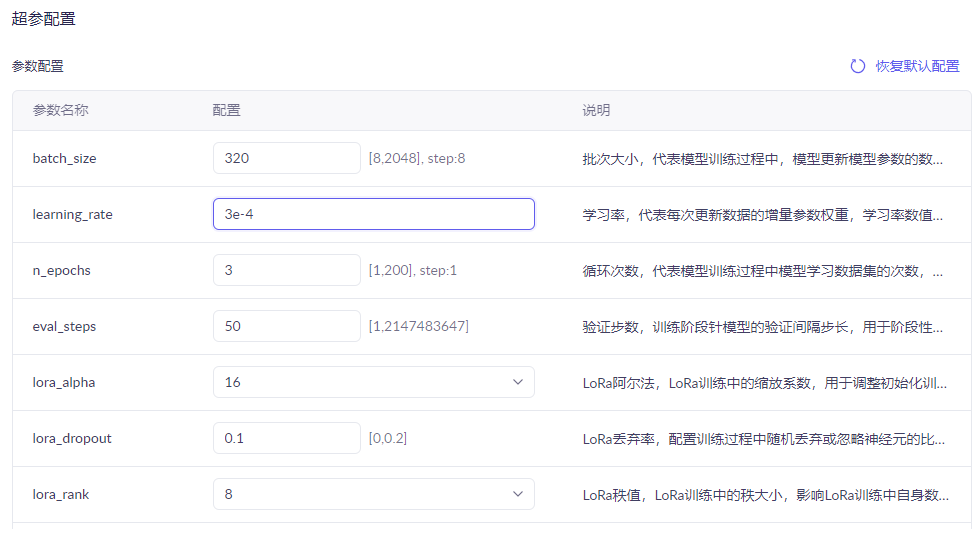
学习率:3e-4 ~ 5e-5,数值过高过拟合、过低收敛慢。
训练轮数epoch:2-5轮,轮数过多会死记硬背数据集。
LoRA秩值r:8-16,数值越大适配能力越强,显存消耗越高。
截断长度:512-2048,根据问答文本长度调整。
4.3 第三步:模型训练过程
百炼控制台创建微调任务,私有化上传业务数据;
配置LoRA微调参数,绑定阿里云算力;
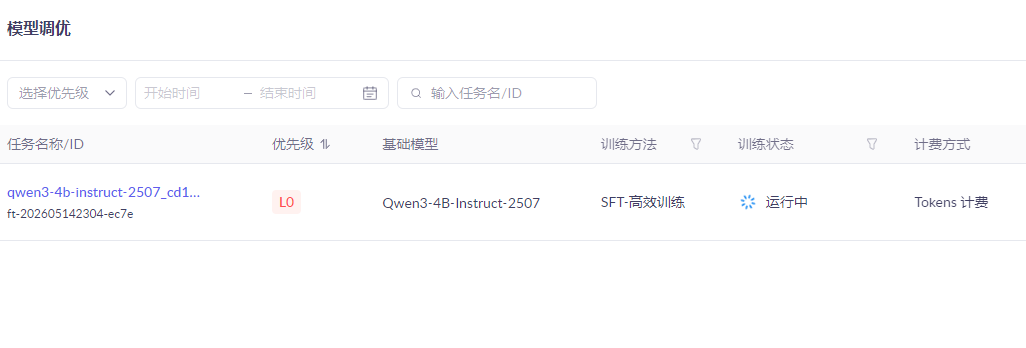
后台自动训练,生成专属模型快照。
产品监控要点:重点关注loss损失值,训练中训练集loss、验证集loss同步平稳下降,无断崖式波动,说明训练正常。
4.4 第四步:训练结果评估
训练完成后,产品经理从三个维度验收模型,拒绝纯技术指标:
业务合规性:是否严格遵循售后话术,无违规、冗余回答;
准确率:测试集问答匹配度,垂类业务准确率需达到90%以上;
泛化性:非数据集内相似问题,能否正常输出合规答案,避免过拟合。
本次电商案例微调结果:模型熟练掌握退换货流程、售后赔付标准,语气统一为官方客服话术,无通用闲聊回答,完美适配业务需求。
4.5 第五步:微调后模型使用与部署
4.5.1 模型导出
魔搭导出LoRA适配器文件,体积小、便于存储;百炼直接生成商用模型接口,无需手动导出。
4.5.2 三种部署方式(产品落地分类)
API调用(主流):百炼一键生成API接口,接入小程序、后台系统,适配线上商业化产品。
本地部署:下载LLaMA+LoRA合并模型,本地私有化部署,适配涉密企业。
端侧部署:量化压缩轻量化模型,部署手机、嵌入式设备,适配硬件AI产品。
4.5.3 迭代优化
上线后收集用户不良问答,定期补充数据集,二次微调迭代,持续优化模型准确率。
五、又到说再见的时候了
对于AI产品经理而言,微调不是技术炫技,而是低成本落地垂类AI产品的最优解决方案,优先采用LoRA轻量化微调,依托阿里魔搭+百炼平台,可快速完成从测试到商用的全流程落地。全量微调成本高、周期长,不适合中小企业;RAG仅优化外部知识库,无法改变模型底层输出逻辑;而LoRA微调算力门槛低、不破坏底座、适配性强,搭配开源LLaMA模型,结合魔搭免费测试、百炼商用部署的组合模式,兼顾成本、效率、安全性。本次电商售后AI案例,通过标准化数据处理、LoRA参数配置,依托魔搭完成模型训练,百炼完成商用上线,仅用3天完成全流程,成本不足千元,解决通用模型话术混乱、业务不懂的痛点,上线后客服咨询处理效率提升40%。AI产品经理无需深耕代码,但必须吃透微调业务逻辑:分清微调种类、选对平台框架、把控数据标准、看懂训练指标、规划部署方案。记住核心选型公式:测试用魔搭、商用上百炼、轻量化选LoRA、开源底座选LLaMA,用最低成本实现大模型定制化落地,这就是微调的核心价值。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献146条内容
已为社区贡献146条内容

所有评论(0)