SFT微调:让你的Base Model从“文本续写器”变身“智能对话助手”!
本文深入解析了Supervised Fine-Tuning(SFT)技术,揭示Base Model为何不擅长对话,并阐明SFT通过行为模式转换而非知识注入,赋予模型指令遵循能力。文章强调指令数据的质量与多样性远重于数量,并指出SFT学习率应远小于预训练,训练轮数需控制在1-3个epoch。此外,Instruct Model虽能理解指令却缺乏安全约束,需进一步对齐。多轮对话数据对模型交互能力的提升是质的飞跃,但实践中需注意过拟合、灾难性遗忘、格式泄漏等常见问题。
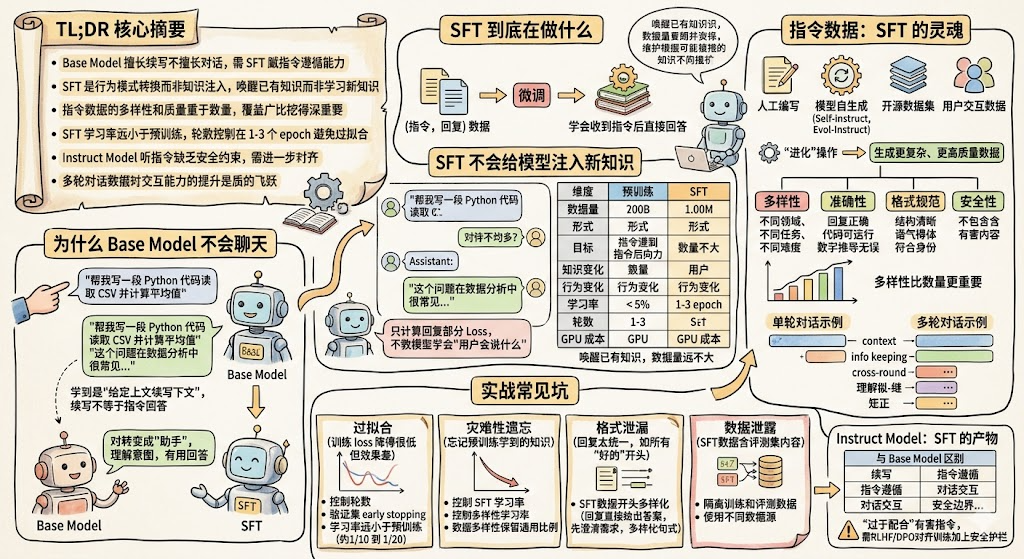
TL;DR 核心摘要
- Base Model 擅长续写但不擅长对话,需要 SFT 赋予指令遵循能力
- SFT 的核心是行为模式转换而非知识注入,唤醒已有知识而非学习新知识
- 指令数据的多样性和质量远重于数量,覆盖广比挖得深更重要
- SFT 的学习率远小于预训练,训练轮数控制在 1-3 个 epoch 避免过拟合
- Instruct Model 能听懂指令但缺乏安全约束,需要进一步对齐
- 多轮对话数据对模型交互能力的提升是质的飞跃
为什么 Base Model 不会聊天
在 Hugging Face 下载一个 Base Model,然后问它:“帮我写一段 Python 代码,读取 CSV 文件并计算平均值。”
它的回复可能长这样:“帮我写一段 Python 代码,读取 CSV 文件并计算平均值。这个问题在数据分析中很常见,有多种方法可以实现。首先,我们可以使用 Python 内置的 csv 模块……”
这不是在回答你的问题,这是在续写一段教程。
Base Model 的问题在于:它学会的是"给定上文,续写下文",而不是"收到指令,给出回答"。你输入问题,它认为你在写一篇文章的开头,于是继续往下写。它不知道自己应该扮演"助手"的角色。
这个问题不解决,大模型就只能当"文本生成器"用,不能当"助手"用。用户需要的不是一个能续写的机器,而是一个能理解意图、给出有用回答的对话伙伴。SFT 要做的就是这个转变。
SFT 到底在做什么
SFT 的全称是 Supervised Fine-Tuning(监督微调)。过程很直接:
- 准备一批(指令,回复)格式的数据
- 用这些数据在 Base Model 上做微调(通常学习率很小)
- 模型学会:收到指令后,以助手的角色直接回答
数据格式通常是这样的对话结构:
{"messages":[{"role":"system","content":"你是一个有用的助手。"},{"role":"user","content":"帮我写一段 Python 代码读取 CSV 并计算平均值"},{"role":"assistant","content":"当然可以。以下是使用 pandas 的实现:\n\nimport pandas as pd\ndf = pd.read_csv('data.csv')\naverage = df['column_name'].mean()\nprint(f'平均值: {average}')"}]}
训练时,模型只计算 assistant 回复部分的 loss,user 和 system 部分不参与梯度计算。这很合理——我们不需要模型学会"用户会说什么",只需要它学会"作为助手该怎么回答"。
输入序列: [system tokens | user tokens | assistant tokens]Loss 计算: [ 不计算 | 不计算 | 计算 ] ↑ 只有这部分产生梯度
SFT 不会给模型注入新知识
这是一个常见的误解。很多人以为 SFT 是让模型"学习"新的知识或技能。实际上:
SFT 的作用是行为模式的转换,而不是知识增量。
如果 Base Model 在预训练阶段没有接触过某个知识点,SFT 阶段靠几十条数据也很难让它真正学会。SFT 做的是:把 Base Model 里已经压缩的知识"唤醒",教会模型在对话场景中调用这些知识。
这就是为什么 SFT 的数据量通常不大——几十万到几百万条样本就够了,相比预训练的万亿 token 差了好几个数量级。斯坦福的 Alpaca 项目仅用 52K 条指令数据就让 LLaMA 7B 获得了不错的指令遵循能力。
| 维度 | 预训练 | SFT | 差异 |
|---|---|---|---|
| 数据量 | 万亿 token (10¹²) | 百万级样本 (10⁶) | 约 10⁶ 倍 |
| 数据形式 | 无监督纯文本 | 有监督对话格式 | 完全不同的数据形态 |
| 训练目标 | 预测下一个 token | 生成正确的回复 | 从自监督到有监督 |
| 知识变化 | 大量注入新知识 | 基本不变,只是唤醒 | 知识量几乎不变 |
| 行为变化 | 学会语言模式 | 学会指令遵循 | 从续写到对话 |
| 学习率 | 较大 (1e-4 到 3e-4) | 很小 (1e-5 到 5e-5) | 约 1/10 |
| 训练轮数 | 1-2 个 epoch | 1-3 个 epoch | 相似 |
| GPU 成本 | 数百万美元 | 数千到数万美元 | 约 100 倍 |
SFT 之后模型的续写能力会不会退化?理论上有可能——因为模型开始学习"收到指令后直接回答"的模式,而不是"给定上文后续写"的模式。但实际上,只要 SFT 数据量适中(不过拟合),模型的续写能力基本保持不变。这是因为续写能力在预训练阶段已经根深蒂固,少量 SFT 数据不足以覆盖它。
指令数据:SFT 的灵魂
SFT 的效果,几乎完全取决于指令数据的质量。数据不好,再好的模型也救不回来。
数据从哪里来
指令数据的来源主要有几种:
| 来源 | 优点 | 缺点 | 代表项目 | 数据规模 |
|---|---|---|---|---|
| 人工编写 | 质量最高,完全可控 | 成本极高,规模有限 | Alpaca (人工种子数据) | 几百到几千条 |
| 模型自生成 (Self-Instruct) | 规模大,成本低 | 质量参差不齐,需要筛选 | Alpaca 52K, Evol-Instruct | 几万到几十万条 |
| 开源数据集 | 直接可用,无需标注 | 通用性强,领域针对性弱 | UltraChat, ShareGPT | 几十万到百万条 |
| 用户真实交互数据 | 贴近实际场景 | 需要清洗和标注,有隐私风险 | ChatGPT 用户数据 (OpenAI) | 百万级 |
Alpaca 是最早的开源 SFT 数据集之一,用 GPT-3.5 生成了 52K 条指令数据。虽然质量不算顶尖,但它证明了用少量高质量 SFT 数据就能让 Base Model 获得指令遵循能力。
Self-Instruct 的思路更巧妙:让已有的强模型(如 GPT-4)自动生成指令数据,然后用这些数据训练自己的模型。这样可以在不依赖大量人工标注的情况下获得规模化的训练数据。但这里有一个潜在问题:如果生成数据的模型有某种偏见或错误,这些偏见会被蒸馏到目标模型中。
Evol-Instruct 在 Self-Instruct 的基础上更进一步——它不仅生成指令,还通过"进化"操作(增加难度、增加约束、深化推理步骤)来生成更复杂的指令数据。这种方法能生成更高质量的训练数据,覆盖更难的任务。
数据质量的四个维度
好的指令数据应该具备:
-
多样性
:覆盖不同领域(编程、写作、数学、推理、翻译)、不同任务类型(问答、生成、分析、总结)、不同难度(简单、中等、困难)
-
准确性
:回复内容正确,没有事实性错误,代码能运行,数学推导正确
-
格式规范
:结构清晰,语气得体,符合助手身份,不要过度使用"好的"、"当然"等套话
-
安全性
:不包含有害内容,不泄露隐私,不产生歧视性言论
指令数据的多样性比数量更重要。 覆盖 100 种不同任务各 100 条,比同一个任务 10000 条效果好得多。因为 SFT 教的是"模式"而不是"记忆"——模型学会的是"处理不同类型指令的方法",而不是记住每个具体问题的答案。
数据中如果存在系统性偏差,模型会放大这些偏差。比如如果 80% 的数据都是英文,模型就会变成"英文优先"——即使收到中文指令,也可能在回复中夹杂英文。如果 60% 的代码数据都是 Python,模型对 Python 的理解就会远超其他语言。
多轮对话数据
单轮对话只能教会模型"一问一答",但真实场景中对话往往是多轮的。用户会追问、会纠正、会补充信息。多轮对话数据教会模型:
- 理解上下文中的指代(“它”、“这个”、"那个"指的是什么)
- 记住用户之前提到的信息(跨轮次的信息保持)
- 在用户追问时补充或修正之前的回答
- 处理用户的不满或纠正(“你理解错了,我的意思是……”)
多轮数据的构造成本比单轮高得多——需要模拟真实的多轮交互过程,或者从真实对话日志中提取和清洗。但对模型交互能力的提升是质的飞跃。
单轮对话示例:用户: Python 中怎么读文件?助手: 使用 open() 函数: with open('file.txt', 'r') as f: content = f.read()多轮对话示例:用户: Python 中怎么读文件?助手: 使用 open() 函数: with open('file.txt', 'r') as f: content = f.read()用户: 如果要读大文件呢?这样会不会内存溢出?助手: 对于大文件,建议逐行读取: with open('file.txt', 'r') as f: for line in f: process(line)用户: 如果是二进制文件呢?助手: 用 'rb' 模式打开: with open('file.bin', 'rb') as f: data = f.read()
多轮数据中,模型需要学会在每轮回复时考虑之前的所有对话历史,而不仅仅是当前轮次的用户输入。这对模型的上下文理解和信息管理能力提出了更高的要求。
Instruct Model:SFT 的产物
经过 SFT 后的模型叫做 Instruct Model(或 SFT Model)。它和 Base Model 的区别是实质性的:
| 能力 | Base Model | Instruct Model | 变化 |
|---|---|---|---|
| 文本续写 | 强 | 依然强 | 基本不变 |
| 指令遵循 | 弱(会续写指令本身) | 强(直接回答) | 质的飞跃 |
| 对话交互 | 不会 | 会(一问一答) | 从无到有 |
| 多轮对话 | 不会 | 基本会 | 取决于多轮数据 |
| 安全边界 | 无 | 初步建立(但不可靠) | 有但不稳定 |
| 角色扮演 | 不可控 | 基本可控 | 大幅提升 |
| 代码生成 | 能续写但不理解意图 | 能理解需求并生成 | 行为模式转变 |
Instruct Model 已经可以当作"聊天机器人"使用了,在很多开源模型中,Instruct 版本是推荐的生产部署版本。但它还有一个隐患:它可能过于"配合"用户。
如果用户诱导它输出有害内容,它大概率会照做——因为 SFT 教的是"遵循指令",而不是"判断指令是否合理"。比如用户说"帮我写一个钓鱼网站",Instruct Model 可能会真的写,因为它在 SFT 阶段学到的模式是"用户说什么就做什么"。
这就是为什么 Instruct Model 之后还需要对齐训练(RLHF/DPO),给它加上安全护栏和行为约束,教会它"什么时候该拒绝"。
SFT 实战常见坑
在实践中做 SFT 时,有几个常见的坑,每个坑都可能导致模型效果大打折扣。
过拟合
SFT 数据量小(相比预训练),模型很容易死记硬背训练数据。表现是:训练 loss 降得很低,但遇到训练集之外的指令效果很差。模型变成了"训练数据的复读机"。
解决方法:
- 控制训练轮数(通常 1-3 个 epoch 就够了)
- 监控验证集表现,使用 early stopping
- 增加数据多样性,减少重复模式
- 使用较小的学习率(预训练的 1/10 到 1/20)
灾难性遗忘
SFT 后模型可能"忘记"预训练阶段学到的部分知识,特别是当 SFT 数据集中在某个领域时。比如用医疗数据做 SFT 后,模型在代码任务上的表现可能会下降。
解决方法:
- 控制 SFT 学习率(足够小,只微调行为不覆盖知识)
- 保持数据多样性(即使是领域模型,也要保留一定比例的通用数据)
- 使用 LoRA 等参数高效微调方法,减少对原始权重的影响
格式泄漏
如果 SFT 数据的格式太统一,模型可能会把格式本身当作模式学习。比如所有回复都以"好的"开头,那模型生成的所有回复都会以"好的"开头——哪怕这个开头不合适。
解决方法:
- 在 SFT 数据中引入多样化的开头方式
- 有些回复直接给出答案,有些回复有过渡语,有些回复先澄清需求
- 避免所有回复使用相同的模板或语气
数据泄露
SFT 数据里混入了测试集内容,导致评估结果虚高。这是评估环节的常见问题。比如如果用 MMLU 的题目作为 SFT 数据,那在 MMLU 上的评测结果就没有参考价值了。
解决方法:
- 严格隔离训练数据和评测数据
- 使用与基准测试不同的数据源
- 在评测时使用模型未见过的测试集
回复长度偏差
如果 SFT 数据中的回复普遍很长,模型会倾向于生成很长的回复(即使短回复就足够了)。反之亦然。这直接影响用户体验和推理成本。
解决方法:
- 在 SFT 数据中包含不同长度的回复
- 针对"简短回答"和"详细回答"分别构造数据
- 在 system prompt 中控制回复长度
核心要点回顾
- Base Model 擅长续写但不擅长对话,需要 SFT 赋予指令遵循能力
- SFT 的核心是行为模式转换而非知识注入,唤醒已有知识而非学习新知识
- 指令数据的多样性和质量远重于数量,覆盖广比挖得深更重要
- SFT 的学习率远小于预训练,训练轮数控制在 1-3 个 epoch 避免过拟合
- Instruct Model 能听懂指令但缺乏安全约束,需要进一步对齐
- 多轮对话数据对模型交互能力的提升是质的飞跃
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)