Project:电商图谱&智能客服系统
目录
https://github.com/lazysheepzzz/E-commerce-Knowledge-Graph.git
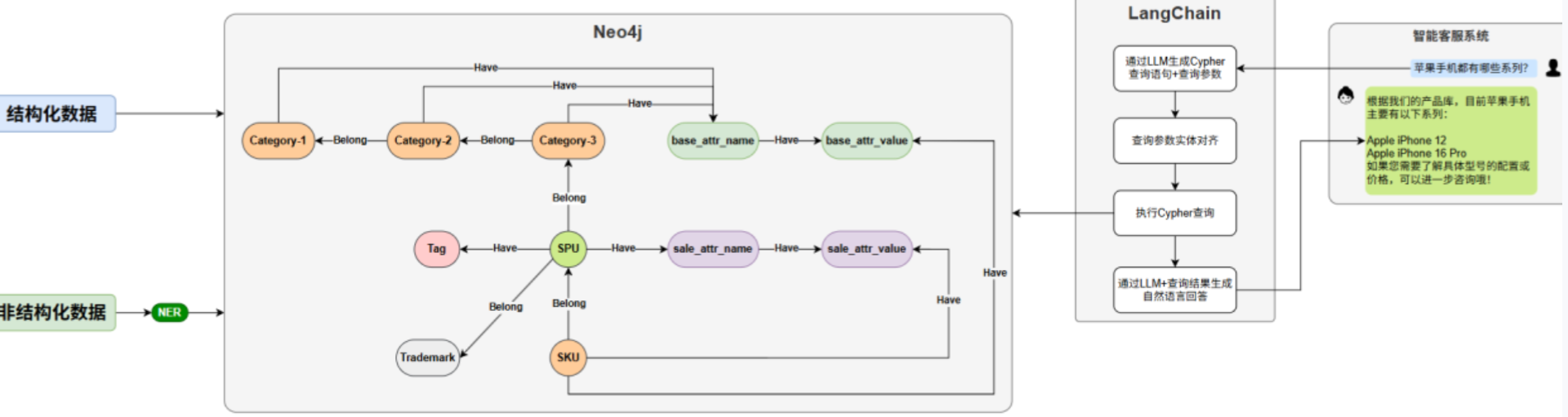
项目架构
本项目旨在构建电商领域知识图谱,并基于该知识图谱搭建智能电商客服系统。
技术栈&环境准备
技术栈
MySQL(关系型数据库)、Neo4j(图数据库)、Label Studio(标注工具)、Datasets(数据处
理)、Transformers(预训练模型)、PyTorch(深度学习框架)、TensorBoard(训练可视
化)、LangChain(大模型应用框架)、FastAPI(Web框架)。
环境准备

业务数据准备
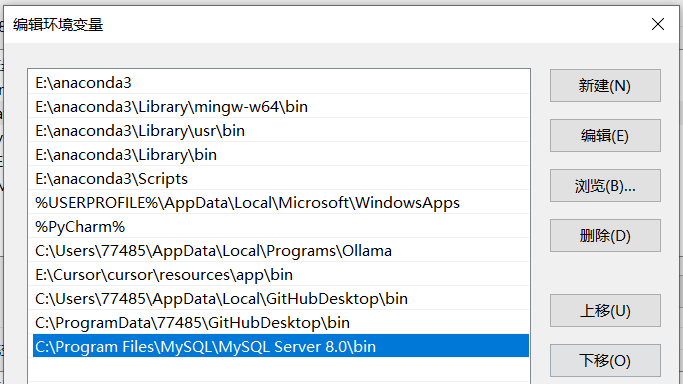
下载MySQL(这个是服务端也就是数据库本体),下载完之后要去系统高级设置那里配一下环境
变量。
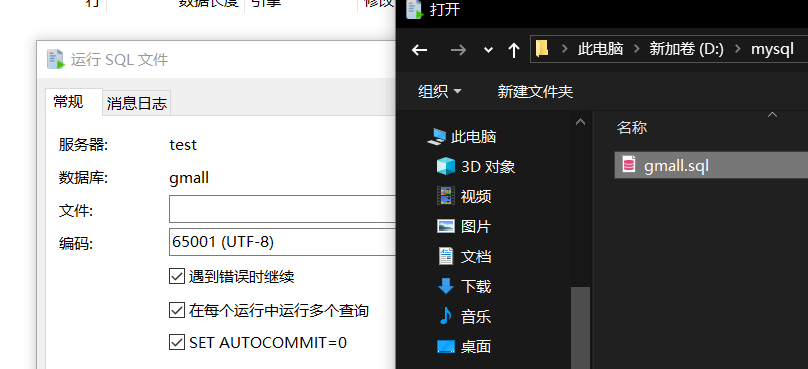
Navicat(这是一个可视化的客户端界面),新建查询输入代码添加gmall,运行sql文件添加
数据。

Neo4j
图数据库以节点和关系存储数据,比关系型数据库(表格+外键)更自然地表达现实世界的关联,
适合处理复杂的连接型数据。
Neo4j 是目前最流行的图数据库,Java开发,采用原生图存储和查询引擎,广泛应用于社交网络、
推荐系统、知识图谱、反欺诈分析、网络安全等领域。
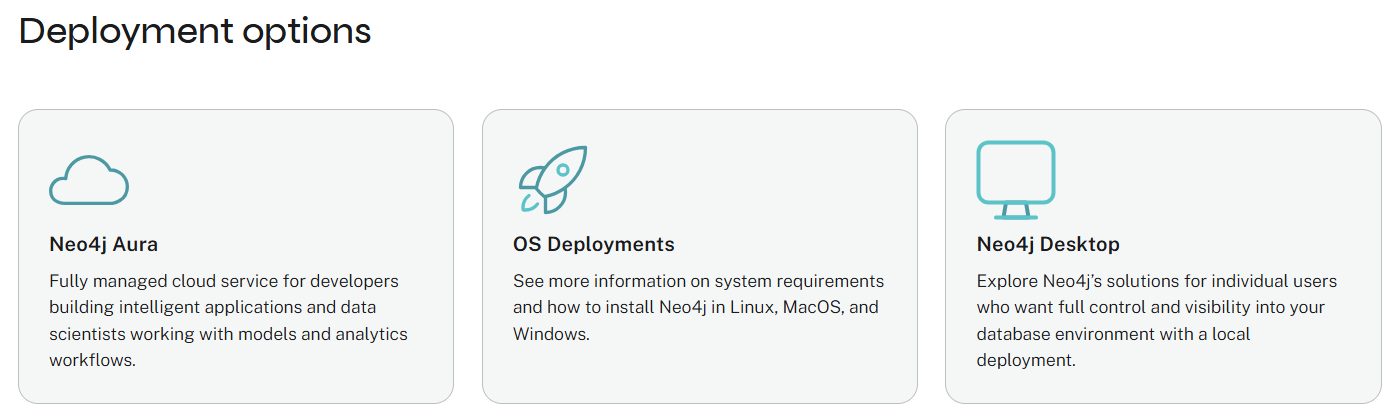
安装
三种安装方式,我们选OS
跑Neo4j之前,要下载JDK,因为Neo4j是用java开发的,需要请求java帮我们把数据库跑起来。
环境加进来。
![]()
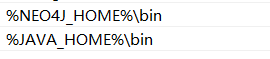
启动
第一种方式
neo4j console把neo4j起起来,然后ctrl+c可以退出。
![]()
这个可以访问网页版的客户端,是网页服务。
![]()
进去了网页之后,还有一个localhost,这个是数据端口,用于程序之间通信。
这种方式比较适合学习使用,需要的时候开一下,因为这个服务和cmd终端是绑定的,cmd关掉服
务就停了,不适合做大型的服务端调试,稳定性不高。
第二种方式
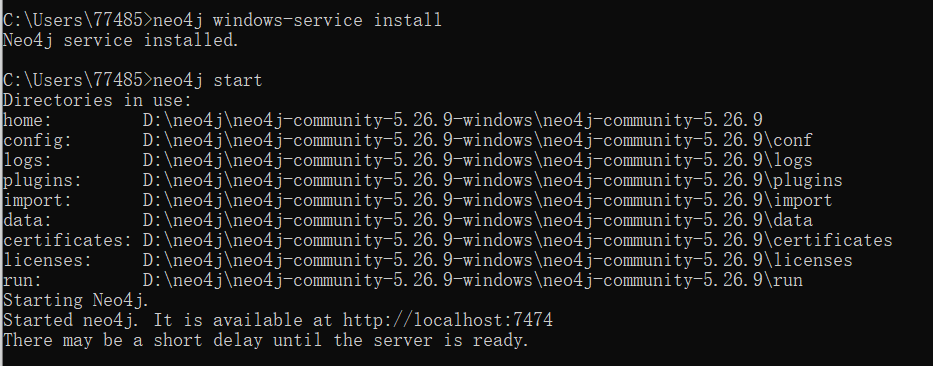
先neo4j windows-service install,安装服务(复制文件 + 注册到 Windows),下面的neo4j start就
是相当于把整个数据库(包括 7687 和 7474)一起启动。
stop是暂停服务,uninstall windows-service是卸载服务。
访问使用
可以用网页端直接访问,或者在cmd里输入。这个cypher-shell在D:\neo4j\neo4j-community-
5.26.9-windows\neo4j-community-5.26.9\bin里

一般用网页端。
Cypher基础
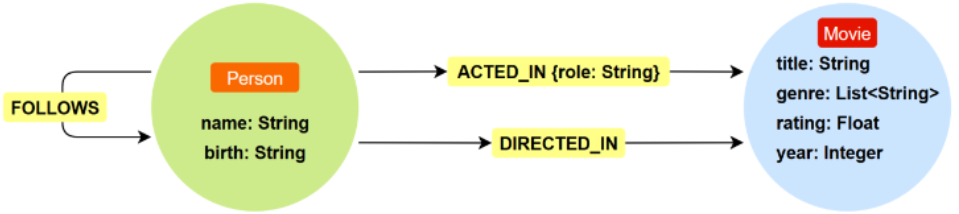
图数据模型
Cypher 基于 Neo4j 的图数据模型,包含三种基本元素:
-
节点
( )— 代表实体,可有标签和属性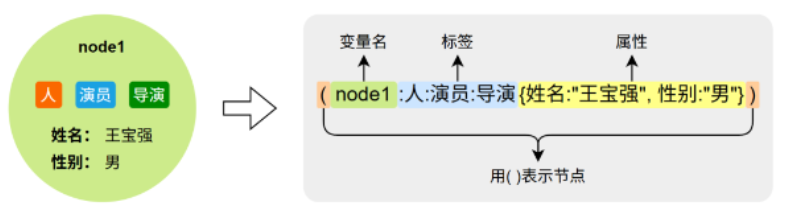
-
关系
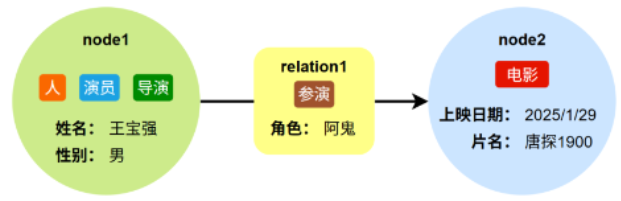
-[ ]->— 连接节点,必须有类型,可有属性和方向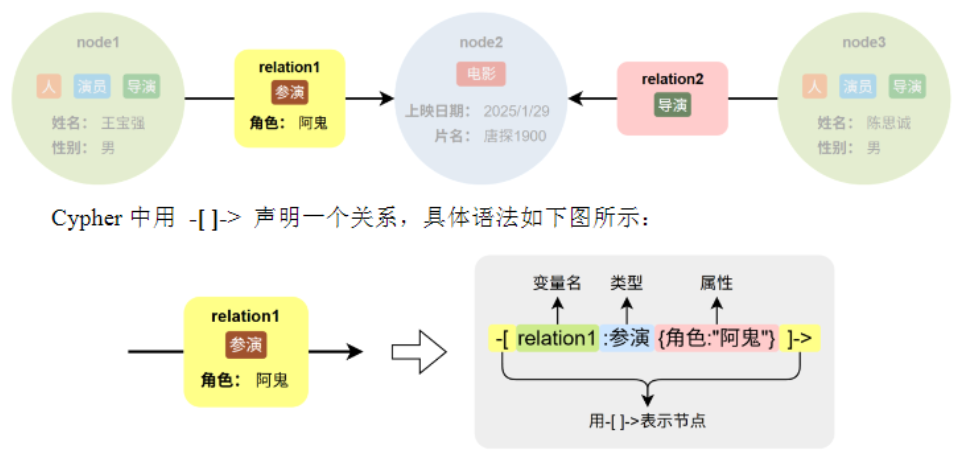
-
路径 — 节点和关系的组合,表示关联链条
写入和查询节点
写入节点

可以直接在网页上写代码。

查询节点
写入和查询关系
写入关系
在写入关系之前要先MATCH匹配,不然的话会新创建两个节点。

查询关系


写入和查询路径


修改数据
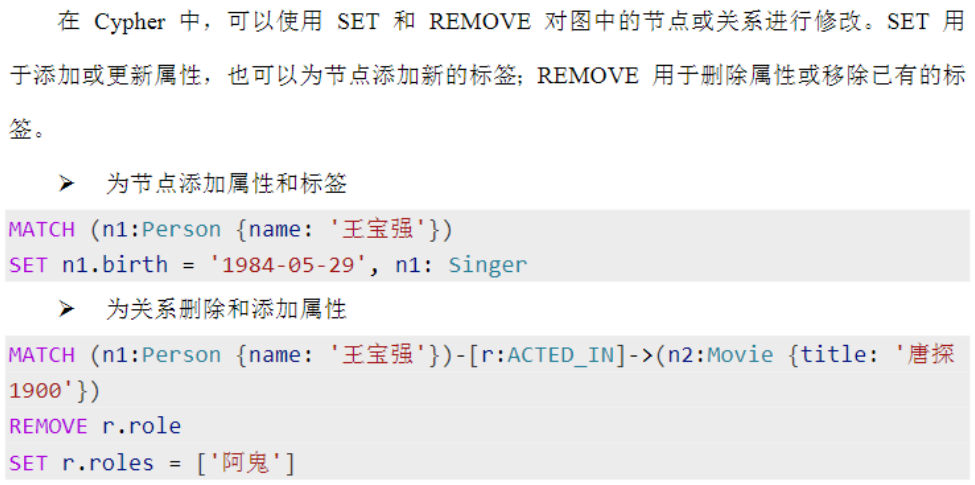
删除数据
先删关系再删节点,不然删不掉。

合并操作
MERGE相当于先MATCH匹配节点,再CREATE,这样就不会上面出现的额外创建节点问题。
ON的意思看注释。

Cypher数据类型
基本数据类型
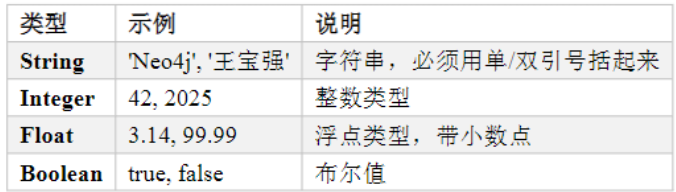
复合数据类型

![]()
Cypher函数
字符串函数

数学函数
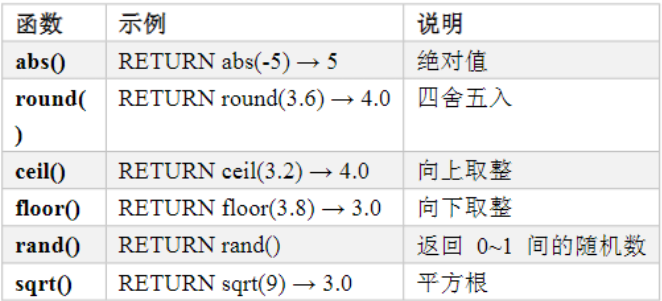
集合函数

日期时间函数
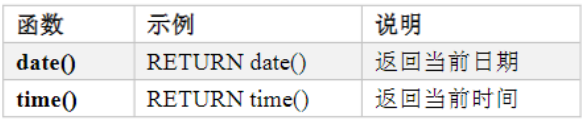
![]()
Cypher高级查询
数据准备
为理解 Cypher 高级查询,需预先构建“人物-电影”示例数据集,包含导演、演员、电影关系及社交
关注关系。
// =======================
//清空旧数据
// =======================
MATCH (n) DETACH DELETE n;
// =======================
//创建人物节点(9人)
// =======================
CREATE
(:Person {name:'张艺谋', birth:'1951-11-14'}),
(:Person {name:'陈凯歌', birth:'1952-08-12'}),
(:Person {name:'巩俐', birth:'1965-12-31'}),
(:Person {name:'葛优', birth:'1957-04-19'}),
(:Person {name:'章子怡', birth:'1979-02-09'}),
(:Person {name:'刘德华', birth:'1961-09-27'}),
(:Person {name:'吴京', birth:'1974-04-03'}),
(:Person {name:'贾玲', birth:'1982-04-29'}),
(:Person {name:'郭帆', birth:'1980-12-15'});
// =======================
//创建电影节点(10部)
// =======================
CREATE
(:Movie {title:'红高粱', year:1987, rating:8.4, genre:['文艺','历史
']}),
(:Movie {title:'活着', year:1994, rating:9.2, genre:['剧情','历史']}),
(:Movie {title:'霸王别姬', year:1993, rating:9.6, genre:['剧情','爱情
']}),
(:Movie {title:'英雄', year:2002, rating:7.5, genre:['动作','武侠']}),
(:Movie {title:'无间道', year:2002, rating:9.1, genre:['犯罪','悬疑
']}),
(:Movie {title:'一代宗师', year:2013, rating:8.0, genre:['动作','传记
']}),
(:Movie {title:'流浪地球', year:2019, rating:8.5, genre:['科幻','灾难
']}),
(:Movie {title:'战狼2', year:2017, rating:7.1, genre:['动作','军事
']}),
(:Movie {title:'你好,李焕英', year:2021, rating:7.7, genre:['喜剧','家
庭']}),
(:Movie {title:'满江红', year:2023, rating:7.2, genre:['悬疑','历史
']});
// =======================
//创建导演关系(9条)
// =======================
MATCH
(zhang:Person {name:'张艺谋'}),
(chen:Person {name:'陈凯歌'}),
(liu:Person {name:'刘德华'}),
(wu:Person {name:'吴京'}),
(jia:Person {name:'贾玲'}),
(guo:Person {name:'郭帆'}),
(m1:Movie {title:'红高粱'}),
(m2:Movie {title:'活着'}),
(m3:Movie {title:'霸王别姬'}),
(m4:Movie {title:'英雄'}),
(m5:Movie {title:'无间道'}),
(m6:Movie {title:'战狼2'}),
(m7:Movie {title:'你好,李焕英'}),
(m8:Movie {title:'流浪地球'}),
(m9:Movie {title:'满江红'})
CREATE
(zhang)-[:DIRECTED {award:true}]->(m1),
(zhang)-[:DIRECTED {award:true}]->(m2),
(zhang)-[:DIRECTED {award:false}]->(m4),
(zhang)-[:DIRECTED {award:false}]->(m9),
(chen)-[:DIRECTED {award:true}]->(m3),
(liu)-[:DIRECTED {award:false}]->(m5),
(wu)-[:DIRECTED {award:false}]->(m6),
(jia)-[:DIRECTED {award:true}]->(m7),
(guo)-[:DIRECTED {award:true}]->(m8);
// =======================
//创建参演关系(11条)
// =======================
MATCH
(gong:Person {name:'巩俐'}), (ge:Person {name:'葛优'}),
(zhangyi:Person {name:'章子怡'}), (liu:Person {name:'刘德华'}),
(wu:Person {name:'吴京'}), (zhang:Person {name:'张艺谋'}),
(jia:Person {name:'贾玲'}),
(m1:Movie {title:'红高粱'}), (m2:Movie {title:'活着'}),
(m3:Movie {title:'霸王别姬'}), (m4:Movie {title:'英雄'}),
(m5:Movie {title:'无间道'}), (m6:Movie {title:'流浪地球'}),
(m7:Movie {title:'满江红'}), (m8:Movie {title:'战狼2'}),
(m9:Movie {title:'你好,李焕英'})
CREATE
(gong)-[:ACTED_IN {role:'九儿', award:true}]->(m1),
(gong)-[:ACTED_IN {role:'家珍', award:false}]->(m2),
(ge)-[:ACTED_IN {role:'福贵', award:true}]->(m2),
(ge)-[:ACTED_IN {role:'袁四爷', award:false}]->(m3),
(zhangyi)-[:ACTED_IN {role:'如月', award:false}]->(m4),
(zhangyi)-[:ACTED_IN {role:'宫二', award:true}]->(m7),
(liu)-[:ACTED_IN {role:'刘建明', award:false}]->(m5),
(wu)-[:ACTED_IN {role:'刘培强', award:true}]->(m6),
(zhang)-[:ACTED_IN {role:'秦桧', award:false}]->(m7),
(wu)-[:ACTED_IN {role:'冷锋', award:true}]->(m8),
(jia)-[:ACTED_IN {role:'贾晓玲', award:true}]->(m9);
// =======================
//创建关注关系(11条)
// =======================
MATCH
(gong:Person {name:'巩俐'}), (zhang:Person {name:'张艺谋'}),
(zhangyi:Person {name:'章子怡'}), (chen:Person {name:'陈凯歌'}),
(ge:Person {name:'葛优'}), (liu:Person {name:'刘德华'}),
(wu:Person {name:'吴京'}), (jia:Person {name:'贾玲'}),
(guo:Person {name:'郭帆'})
CREATE
(gong)-[:FOLLOWS]->(zhang),
(zhangyi)-[:FOLLOWS]->(zhang),
(zhang)-[:FOLLOWS]->(chen),
(ge)-[:FOLLOWS]->(chen),
(liu)-[:FOLLOWS]->(zhang),
(gong)-[:FOLLOWS]->(zhangyi),
(wu)-[:FOLLOWS]->(zhang),
(jia)-[:FOLLOWS]->(zhang),
(guo)-[:FOLLOWS]->(zhang),
(liu)-[:FOLLOWS]->(wu),
(zhang)-[:FOLLOWS]->(guo);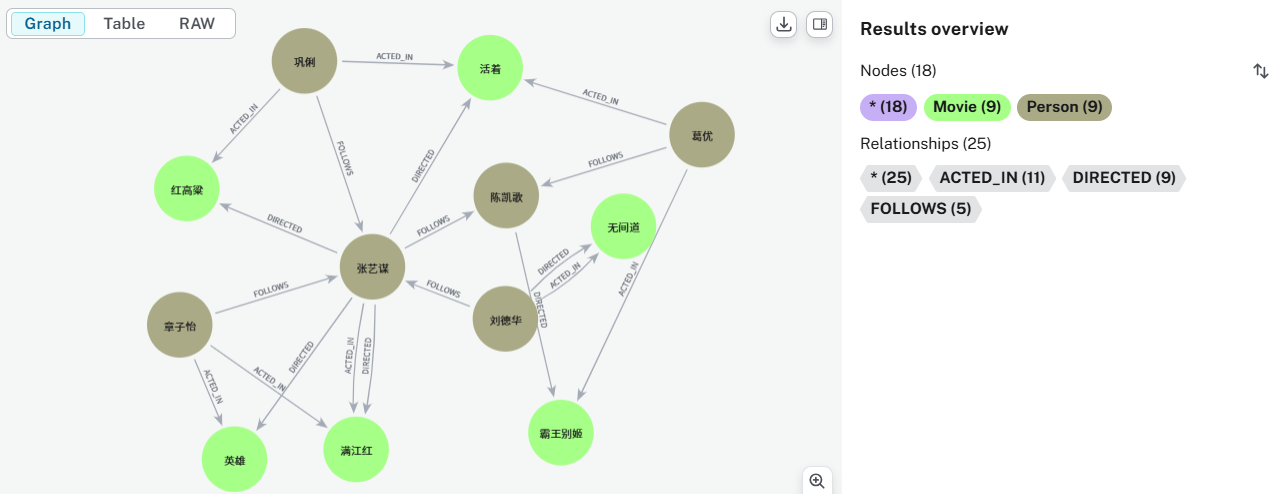
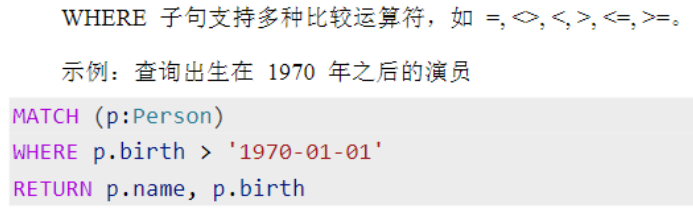
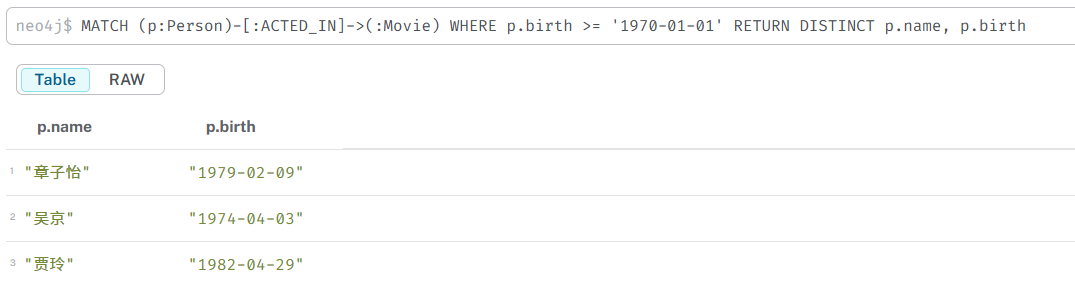
过滤
基本比较运算符
多条件组合
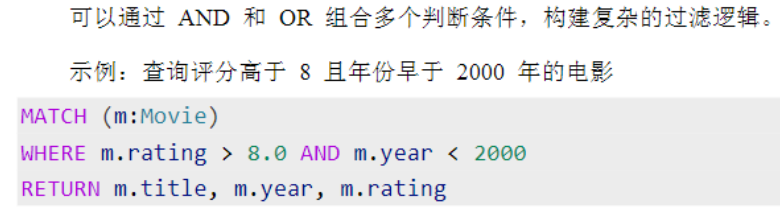
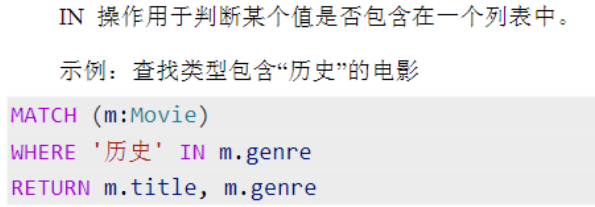
集合包含
字符串匹配
可使用CONTAINS、STARTS WITH、END_WITH操作进行字符串匹配,适用于文本类型的属性,
支持模糊或前缀匹配。
示例:查询名字中包含“张”的人物:
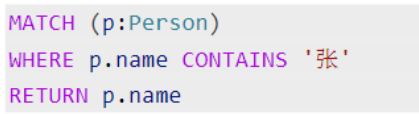
空值判断

排序

分页
在实际应用中,返回的数据量往往较大,不适合一次性展示或处理。为此,Cypher提供了SKIP和
LIMIT子句,用于对查询结果进行分页控制,非常适用于构建分页查询接口或分批处理数据。
使用LIMIT限制返回数量

使用SKIP跳过指定数量
SKIP n表示跳过前n条记录,通常与LIMIT搭配实现分页功能。

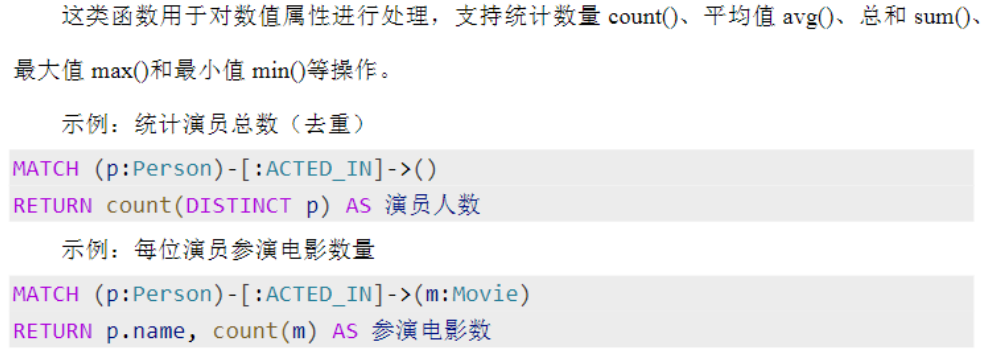
聚合
Cypher提供了多种聚合函数,用于对图数据进行计数、求平均、求最大最小值、聚合列表等统计
分析。当RETURN中同时包含聚合函数和非聚合字段时,Cypher会自动按照非聚合字段进行分
组,无需显式使用SQL中的GROUP BY关键字。
数值类聚合
列表类聚合
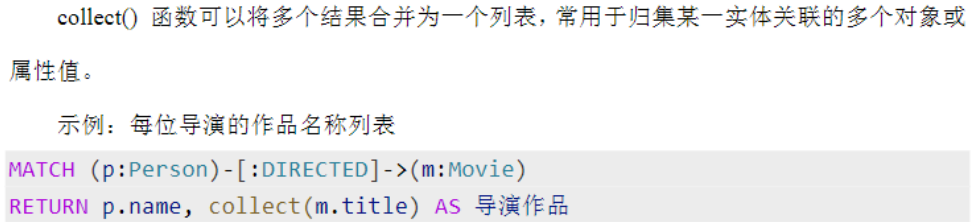
联合查询
UNION 合并查询结果并去重,UNION ALL 保留重复项。各查询的 RETURN 字段数量和类型必须一致。
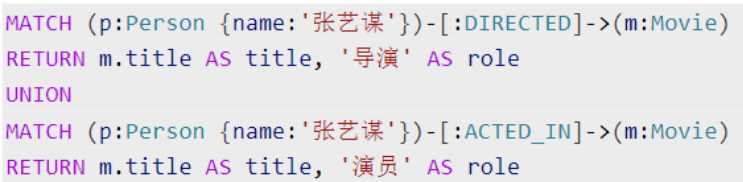
子查询

WITH 与 RETURN 语法相同,区别在于:WITH 将结果传递给下一阶段查询,RETURN 输出最终
结果。本示例中 WITH DISTINCT p 用于去重,避免重复执行子查询。子查询 CALL (p) { ... } 接收
变量 p,查出该导演评分最高的电影,将 title 和 rating 返回主查询并输出。
高级模式匹配
节点模式匹配
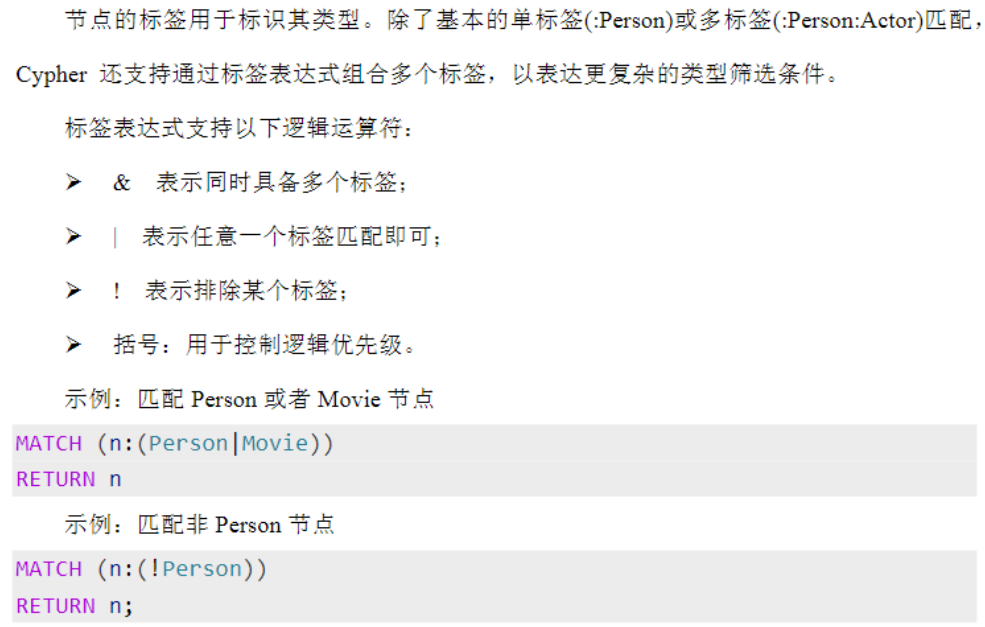
关系模式匹配

路径模式匹配
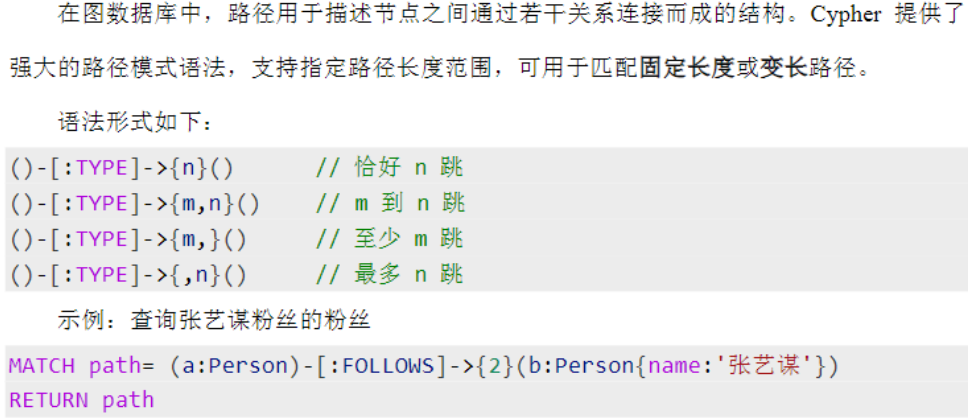
约束

属性唯一性约束



Python访问Neo4j
创建Driver
连接Neo4j的第一步是创建Driver对象,它是与数据库交互的核心入口。Driver是不可变的、线程安
全的,但创建成本较高,因此在应用中应仅创建一个实例并复用,避免重复创建带来的性能开销。
使用完毕后必须关闭Driver以释放资源,可以通过显式调用driver.close()方法,或使用with语句自
动管理其生命周期,推荐后者以避免资源泄漏。
from neo4j import GraphDatabase
URI = "neo4j://localhost:7687"
AUTH = ("neo4j", "12345678")
#通过创建Driver对象并提供URL和身份验证令牌来连接到数据库
#获取Driver实例后,使用.verify_connectivity()方法确保可以建立有效的连接
with GraphDatabase.driver(URI, auth=AUTH) as driver:
driver.verify_connectivity()
print("Connection established.")执行Cyphter语句
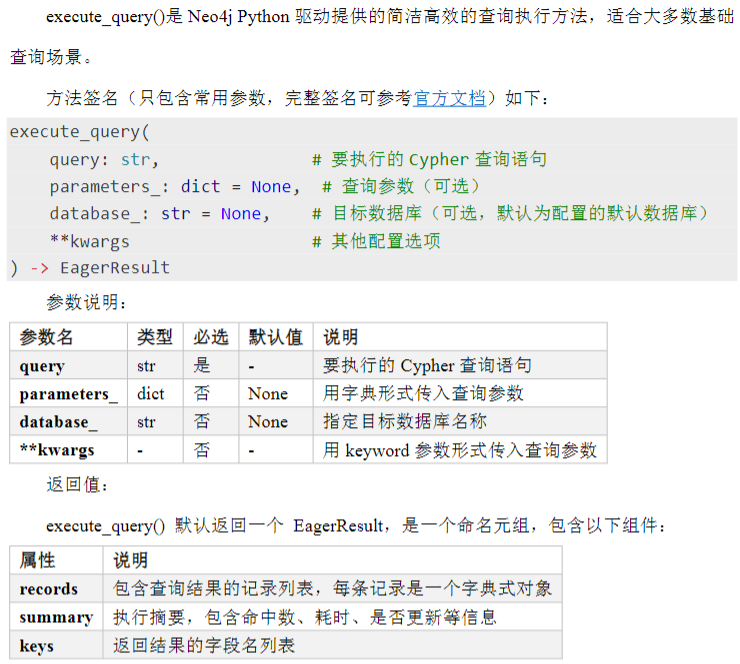
from neo4j import GraphDatabase
#连接配置
URI = "neo4j://localhost:7687"
AUTH = ("neo4j", "12345678")
#执行查询
with GraphDatabase.driver(URI, auth=AUTH) as driver:
#查询某个导演在某个年份之后拍过的电影
records, summary, keys = driver.execute_query(
"""
MATCH (p:Person{name:$name})-[r:DIRECTED]->(m:Movie)
WHERE m.year > $year
RETURN p.name AS director,m.year AS year, m.title AS movie
""",
parameters_={"name": "张艺谋", "year": 1990},
database_="neo4j"
)
#处理结果
print(f"查询返回了{len(records)}条记录")
for record in records:
print(f"{record['director']}在{record['year']}年拍摄了《{record['movie']}》")
查询返回了3条记录
张艺谋在2023年拍摄了《满江红》
张艺谋在2002年拍摄了《英雄》
张艺谋在1994年拍摄了《活着》实体抽取模型
Label-studio
数据标注用LabelStudio,先使用大模型自动标注,相当于生成一个训练数据集,然后再用数据
集,调一个自己的模型出来(这里用bert-base-chinese)。
这里可以重新开一个环境然后pip installlabel-studio,因为这就是一个准备数据的过程。
在环境里用label-studio start把服务起起来,等一会之后会弹出来登陆界面。
把原始数据文件上传上来。
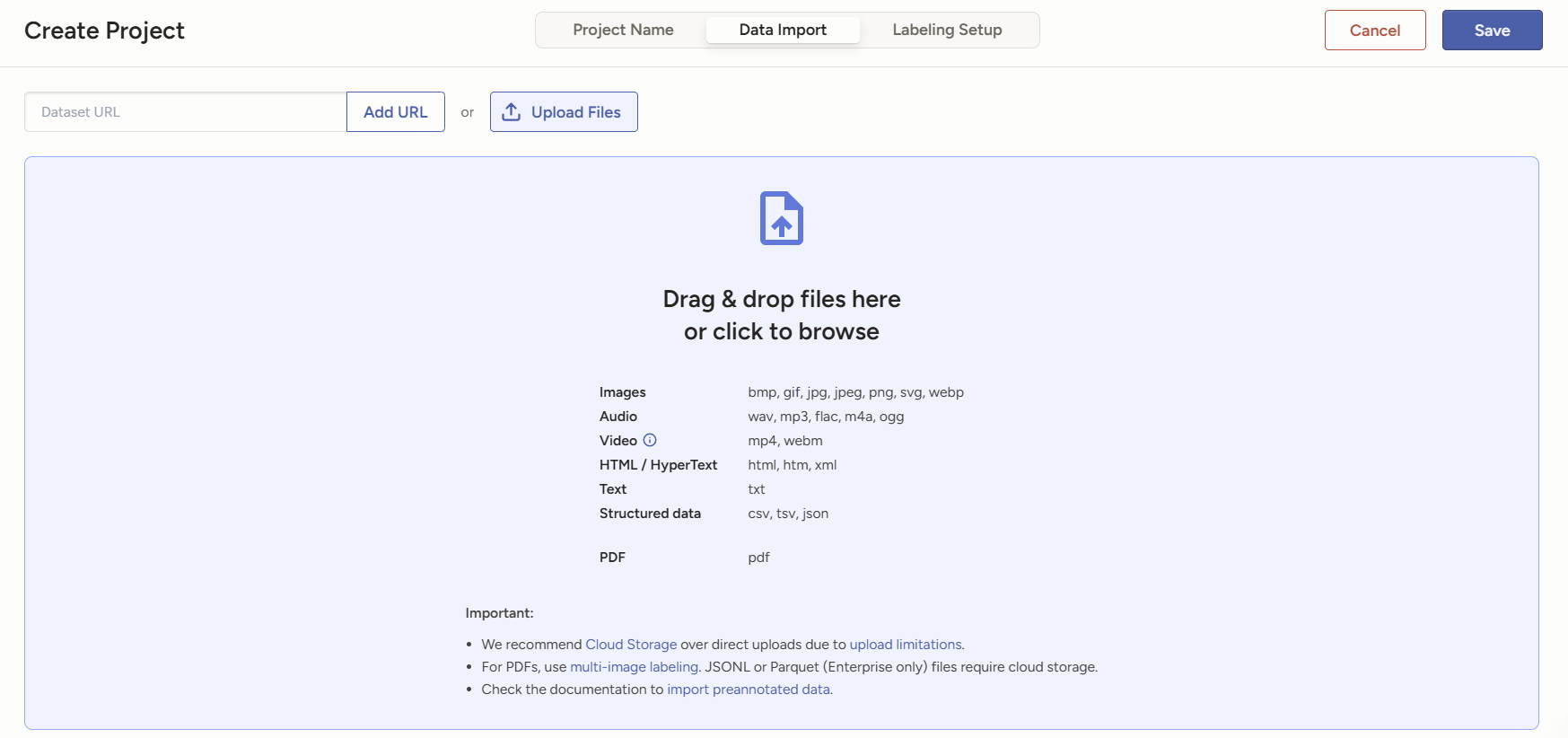
选NLP任务里的NER。
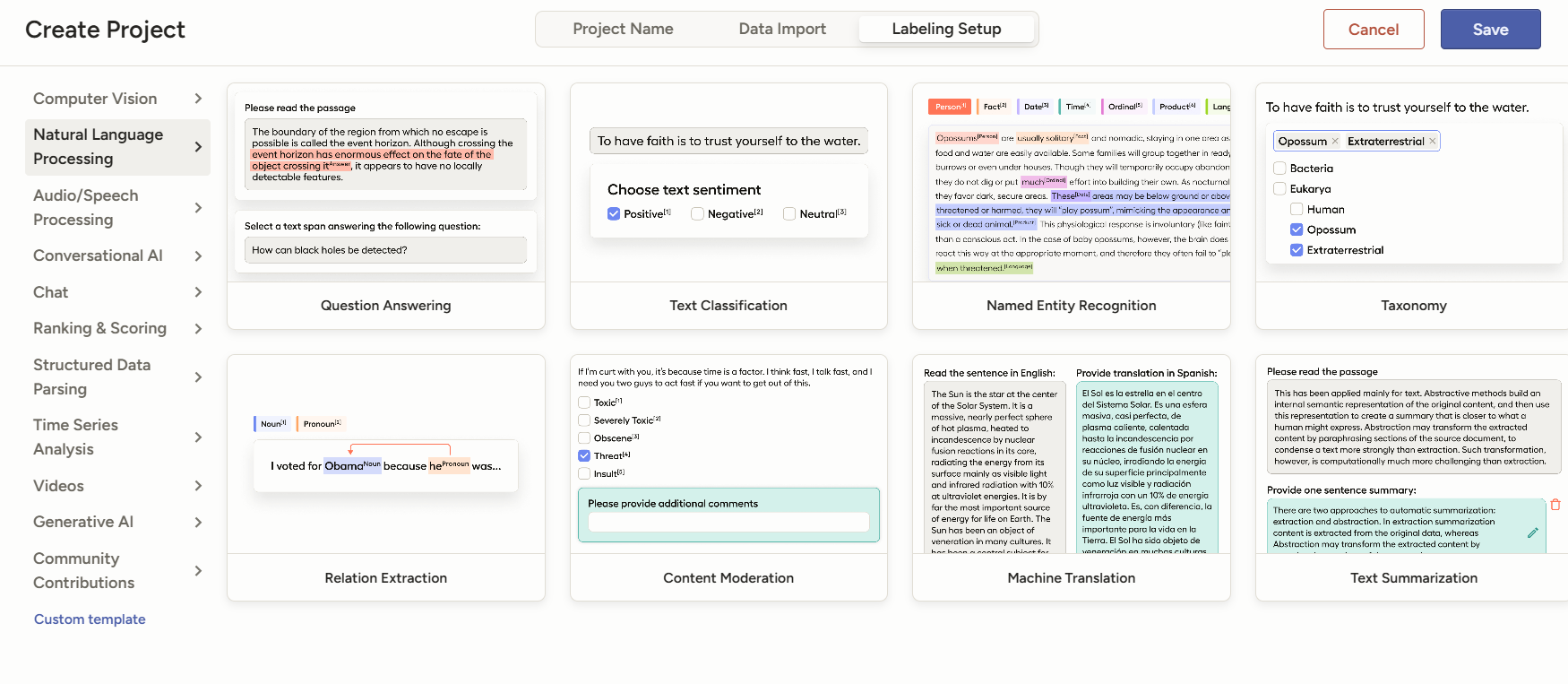
添加新的标签TAG,把不用的删掉。好了就点Save。

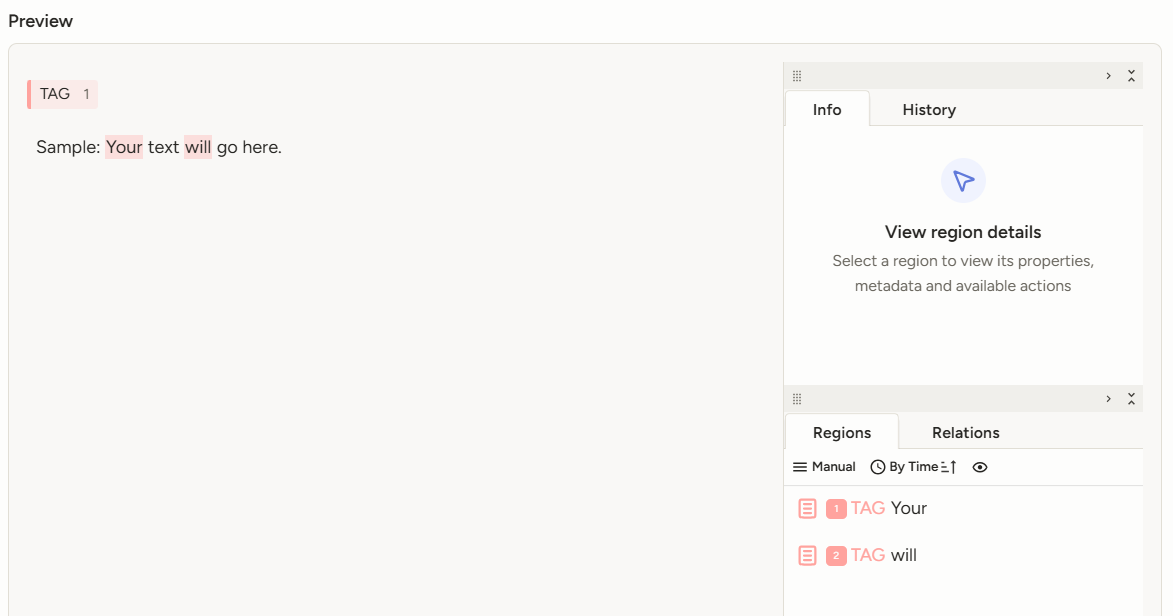
可以做人工标注。
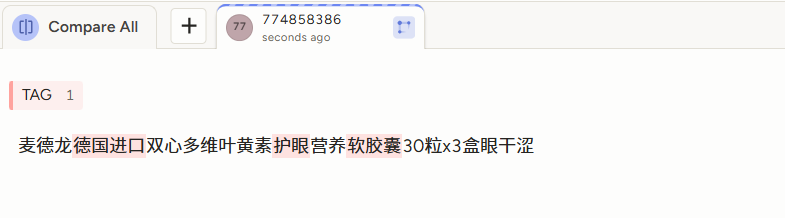
Export导出,选JSON-MIN,在pycharm中打开,可以看到标注好的数据。


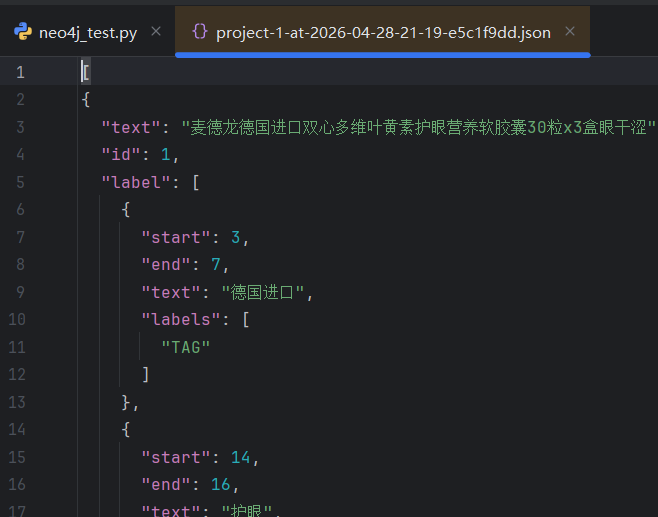
AI自动标注--ML Backend

推荐再创一个环境,不然冲突。-e就是可编辑模式。
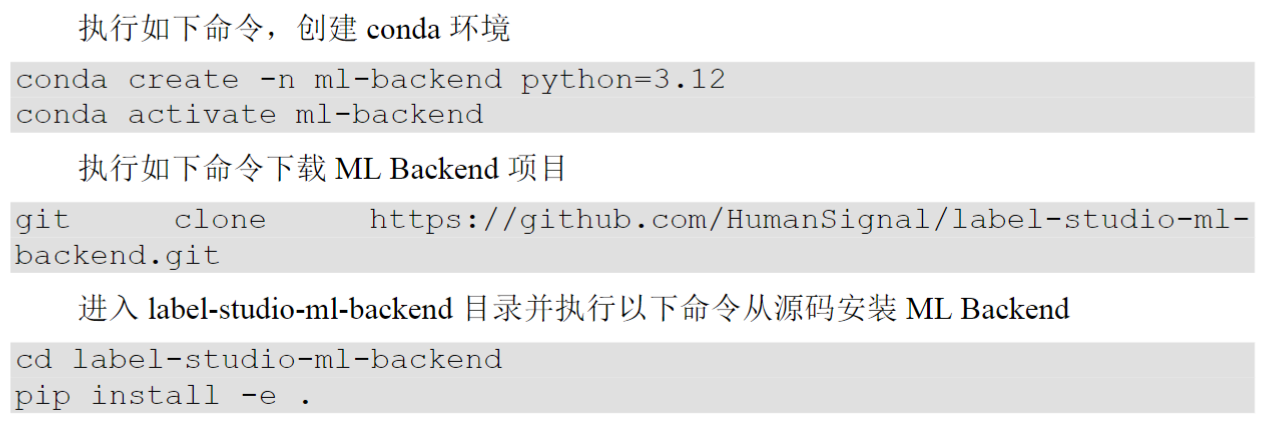

这个要在当前的目录下运行,我的是D:\label-studio-ml-backend

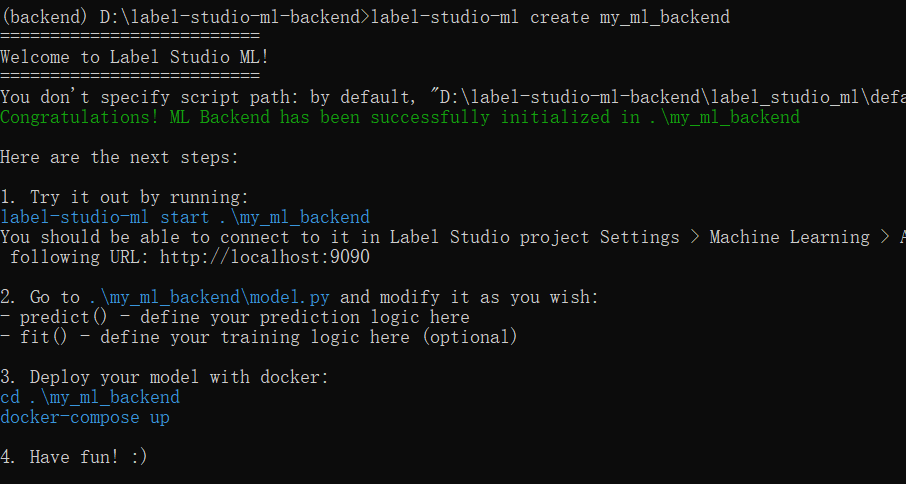
先起一个backend
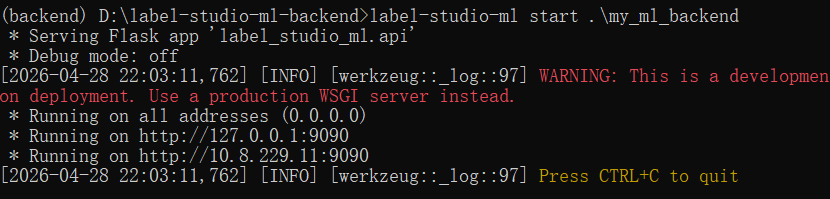
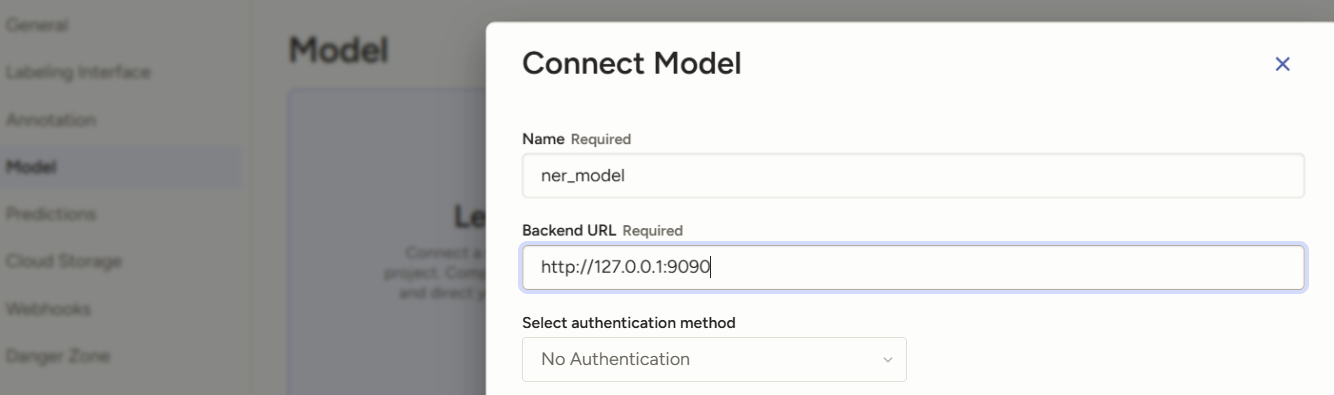
在label-studio的setting里点model可以建立连接。
修改代码,backend里的model.py
改文件里的model.py的代码。
首先修改setup。
def setup(self):
"""Configure any parameters of your model here
"""
self.set("model_version", "0.0.1")
# 大模型
llm = ChatDeepSeek(model = 'deepseek-chat',api_key='sk-999da7fed3354337a1217783e4016742')
# 提示词:使用模板
template = """
你是一个专业的电商领域NER模型。
任务:从用户输入的商品描述列表中分别抽取1-3个最能体现产品核心特征的标签。
要求:
1.抽取的标签必须是商品标题中的原始子字符串,不要生成新的词。
2.标签不能重叠。
3.每个标题最多输出3个标签。
4.输出格式必须是JSON数组,禁止输出任何额外说明。
5.输出顺序必须与输入标题列表顺序一一对应。
示例:
输入: ['苹果防水智能手表','加厚雪地靴']
输出: [["防水","智能"],["加厚"]]
现在请处理:{descriptions}
"""
prompt = PromptTemplate.from_template(template)
# JsonOutputParser
json_parser = JsonOutputParser()
# 创建一个简单的chain
self.chain = prompt | llm | json_parserpredict代码
def predict(self, tasks: List[Dict], context: Optional[Dict] = None, **kwargs) -> ModelResponse:
""" Write your inference logic here
:param tasks: [Label Studio tasks in JSON format](https://labelstud.io/guide/task_format.html)
:param context: [Label Studio context in JSON format](https://labelstud.io/guide/ml_create#Implement-prediction-logic)
:return model_response
ModelResponse(predictions=predictions) with
predictions: [Predictions array in JSON format](https://labelstud.io/guide/export.html#Label-Studio-JSON-format-of-annotated-tasks)
"""
print(f'''\
Run prediction on {tasks}
Received context: {context}
Project ID: {self.project_id}
Label config: {self.label_config}
Parsed JSON Label config: {self.parsed_label_config}
Extra params: {self.extra_params}''')
# 提取商品描述信息
descriptions = [task['data']['text'] for task in tasks]
# 得到模型输出
outputs = self.chain.invoke({'descriptions': descriptions})
# print(outputs)
# 包装成响应数据
predicitons = []
for description,output in zip(descriptions, outputs):
result = []
for tag in output:
# 查找起止位置
start = description.find(tag)
if start == -1:
continue
end = start + len(tag)
result.append({
'value':{
'start':start,
'end':end,
'text':tag,
'labels':['TAG']
},
'from_name':'label',
'to_name':'text',
'type':'labels'
})
predicitons.append({'result':result})
return ModelResponse(predictions=predicitons)实体抽取模型
preprocess
from dotenv import load_dotenv
load_dotenv()
from datasets import load_dataset
from transformers import AutoTokenizer
from configuration.config import *
def process():
dataset = load_dataset('json',data_files = RAW_DATA_FILE)['train']
# print(dataset)
dataset = dataset.remove_columns(['id', 'annotator', 'annotation_id', 'created_at', 'updated_at', 'lead_time'])
dataset_dict = dataset.train_test_split(test_size=0.2)
dataset_dict['test'],dataset_dict['valid'] = dataset_dict['test'].train_test_split(test_size=0.5).values()
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
def encode(example):
tokens = list(example['text'])
inputs = tokenizer(tokens,is_split_into_words = True,truncation = True)
entities = example['label']
labels = [LABELS.index('O')]*len(tokens)
for entity in entities:
start = entity['start']
end = entity['end']
labels[start:end] = [LABELS.index('B')] + [LABELS.index('I')] * (end - start - 1)
# 前后加上id = -100,对应CLS和SEP
labels = [-100] + labels + [-100]
inputs['labels'] = labels
return inputs
dataset_dict = dataset_dict.map(encode,remove_columns=['text','label']) # remove_columns 删除原始的文本列,只保留编码后的张量
print(dataset_dict['train'][0])
dataset_dict.save_to_disk(PROCESSED_DATA_DIR)
if __name__ == '__main__':
process()train
from datasets import load_dataset,load_from_disk
from transformers import AutoTokenizer, AutoModelForTokenClassification, TrainingArguments, Trainer, \
DataCollatorForTokenClassification, EvalPrediction,EarlyStoppingCallback
import time
from configuration.config import *
import evaluate
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
id2label = {id:label for id,label in enumerate(LABELS)}
label2id = {label:id for id,label in enumerate(LABELS)}
model = AutoModelForTokenClassification.from_pretrained(
MODEL_NAME,
num_labels=len(LABELS),
id2label=id2label,
label2id=label2id,
)
train_dataset = load_from_disk(PROCESSED_DATA_DIR/'train')
valid_dataset = load_from_disk(PROCESSED_DATA_DIR/'valid')
data_collator = DataCollatorForTokenClassification(
tokenizer=tokenizer,
padding=True,
return_tensors='pt',
)
args = TrainingArguments(
output_dir = str(CHECKPOINT_DIR / NER_DIR),
logging_dir = str(LOG_DIR / NER_DIR / time.strftime("%Y-%m-%d-%H-%M-%S")),
num_train_epochs = EPOCHS,
per_device_train_batch_size = BATCH_SIZE,
save_strategy = 'steps', # 保存策略
save_steps = SAVE_STEPS,
save_total_limit=3,
fp16 = True,
logging_strategy = 'steps',
logging_steps = SAVE_STEPS,
eval_strategy = 'steps',
eval_steps = SAVE_STEPS,
metric_for_best_model = 'eval_overall_f1',
greater_is_better = True,
load_best_model_at_end = True,
report_to="tensorboard"
)
seqeval = evaluate.load('seqeval')
def compute_metrics(prediction:EvalPrediction):
logits = prediction.predictions
preds = logits.argmax(axis = -1)
labels = prediction.label_ids
# 将标签id转换为真正的标注标签BIO
unpad_labels = []
unpad_preds = []
for pred,label in zip(preds,labels):
unpad_label = label[label != -100]
unpad_pred = pred[label != -100]
unpad_pred = [id2label[id] for id in unpad_pred]
unpad_label = [id2label[id] for id in unpad_label ]
unpad_labels.append(unpad_label)
unpad_preds.append(unpad_pred)
result = seqeval.compute(predictions=unpad_preds, references=unpad_labels)
return result
# early_stopping_callback = EarlyStoppingCallback(early_stopping_patience=2)
trainer = Trainer(
model=model,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
args=args,
data_collator=data_collator,
compute_metrics= compute_metrics,
# callbacks = [early_stopping_callback]
)
trainer.train()
trainer.save_model(CHECKPOINT_DIR/NER_DIR/'best_model')predict
import torch
from transformers import AutoTokenizer, AutoModelForTokenClassification
from configuration.config import *
class Predictor:
def __init__(self,model,tokenizer,device):
self.model = model.to(device)
self.model.eval()
self.tokenizer = tokenizer
self.device = device
def predict(self,inputs:str|list[str]):
is_str = isinstance(inputs,str)
if is_str:
inputs = [inputs]
tokens_list = [list(input) for input in inputs]
inputs_tensor = self.tokenizer(
tokens_list,
is_split_into_words=True,
padding = True,
truncation = True,
return_tensors = 'pt',
)
inputs_tensor = {k:v.to(self.device) for k,v in inputs_tensor.items()}
with torch.no_grad():
outputs = self.model(**inputs_tensor)
logits = outputs.logits
predictions = torch.argmax(logits,dim=-1).tolist()
final_predictions = []
for tokens,prediction in zip(tokens_list,predictions):
prediction = prediction[1:len(tokens)+1]
final_prediction = [ self.model.config.id2label[id] for id in prediction ]
final_predictions.append(final_prediction)
if is_str:
return final_predictions[0]
return final_predictions
def extract(self,inputs:str|list[str]):
is_str = isinstance(inputs, str)
if is_str:
inputs = [inputs]
predictions = self.predict(inputs)
entities_list = []
for input,labels in zip(inputs,predictions):
entities = self._extract_entities(list(input),labels)
entities_list.append(entities)
if is_str:
return entities_list[0]
return entities_list
def _extract_entities(self,tokens,labels):
entities = []
current_entity = ""
for token,label in zip(tokens,labels):
if label == 'B':
if current_entity:
entities.append(current_entity)
current_entity = token
elif label == 'I':
if current_entity:
current_entity += token
else:
if current_entity:
entities.append(current_entity)
current_entity = ""
if current_entity:
entities.append(current_entity)
return entities
def predict():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModelForTokenClassification.from_pretrained(str(CHECKPOINT_DIR/NER_DIR/'best_model'))
tokenizer = AutoTokenizer.from_pretrained(str(CHECKPOINT_DIR/NER_DIR/'best_model'))
predictor = Predictor(model,tokenizer,device)
text = "麦德龙德国进口双心多维叶黄素护眼营养软胶囊30粒x3盒眼干涩"
# result = predictor.predict(text)
#
# for token,label in zip(text,result):
# print(token,label)
entities = predictor.extract(text)
print(entities)
if __name__ == '__main__':
predict()eval
import evaluate
from datasets import load_from_disk
from transformers import Trainer, AutoTokenizer, AutoModelForTokenClassification, DataCollatorForTokenClassification, \
EvalPrediction
from configuration.config import *
tokenizer = AutoTokenizer.from_pretrained(CHECKPOINT_DIR/NER_DIR/'best_model')
model = AutoModelForTokenClassification.from_pretrained(CHECKPOINT_DIR/NER_DIR/'best_model')
test_dataset = load_from_disk(PROCESSED_DATA_DIR/'test')
valid_dataset = load_from_disk(PROCESSED_DATA_DIR/'valid')
data_collator = DataCollatorForTokenClassification(
tokenizer=tokenizer,
padding=True,
return_tensors='pt',
)
seqeval = evaluate.load('seqeval')
def compute_metrics(prediction:EvalPrediction):
logits = prediction.predictions
preds = logits.argmax(axis = -1)
labels = prediction.label_ids
# 将标签id转换为真正的标注标签BIO
unpad_labels = []
unpad_preds = []
for pred,label in zip(preds,labels):
unpad_label = label[label != -100]
unpad_pred = pred[label != -100]
unpad_pred = [model.config.id2label[id] for id in unpad_pred]
unpad_label = [model.config.id2label[id] for id in unpad_label ]
unpad_labels.append(unpad_label)
unpad_preds.append(unpad_pred)
result = seqeval.compute(predictions=unpad_preds, references=unpad_labels)
return result
# early_stopping_callback = EarlyStoppingCallback(early_stopping_patience=2)
trainer = Trainer(
model=model,
eval_dataset=test_dataset,
data_collator=data_collator,
compute_metrics= compute_metrics,
)
result = trainer.evaluate()
print(result)电商图谱构建

utils
from neo4j import GraphDatabase
from pymysql.cursors import DictCursor
from configuration.config import *
import pymysql
class MysqlReader:
def __init__(self):
self.connection = pymysql.connect(**MYSQL_CONFIG)
self.cursor = self.connection.cursor(DictCursor)
def read(self,sql):
self.cursor.execute(sql)
return self.cursor.fetchall()
def close(self):
self.cursor.close()
self.connection.close()
class Neo4jWriter:
def __init__(self):
self.driver = GraphDatabase.driver(**NEO4J_CONFIG)
def write_nodes(self,label:str,properties:list[dict]):
cypher = f"""
UNWIND $batch AS item
MERGE(:{label}{{ id : item.id, name : item.name}} )
"""
self.driver.execute_query(cypher,batch = properties)
def write_relations(self,type:str,start_label,end_label,relations:list[dict]):
cypher = f"""
UNWIND $batch AS item
MATCH (start:{start_label} {{id:item.start_id}}),(end:{end_label} {{id:item.end_id}})
MERGE(start)-[:{type}]->(end)
"""
self.driver.execute_query(cypher,batch = relations)
if __name__ == '__main__':
reader = MysqlReader()
writer = Neo4jWriter()
sql = """
select id,name from base_category1
"""
category1 = reader.read(sql)
print(category1)
# 下面这个代码也可以,但是每次遍历都要请求连接一次,效率不高
# for item in category1:
# cypher = """
# MERGE(n:Category1{ id : $id, name : $name} )
# """
# driver.execute_query(cypher,parameters_=item)
# cypher = """
# UNWIND $category1 AS item
# MERGE(n:Category1{ id : item.id, name : item.name} )
# """
# driver.execute_query(cypher, category1=category1)
writer.write_nodes('Category1',category1)
sql = """
select id,name from base_category2
"""
category2 = reader.read(sql)
print(category2)
# cypher = """
# UNWIND $category2 AS item
# MERGE(n:Category2{ id : item.id, name : item.name} )
# """
# driver.execute_query(cypher, category2=category2)
writer.write_nodes('Category2', category2)
# category2 -belong-> category1
sql = """
select id as start_id,
category1_id as end_id
from base_category2
"""
relations = reader.read(sql)
print(relations)
# cypher = """
# UNWIND $relations AS item
# MATCH (start:Category2 {id:item.start_id}),(end:Category1 {id:item.end_id})
# MERGE(start)-[:Belong]->(end)
# """
# driver.execute_query(cypher, relations=relations)
writer.write_relations('Belong',start_label = 'Category2',end_label = 'Category1',relations = relations)table_sync
from utils import MysqlReader,Neo4jWriter
class TableSynchronizer:
def __init__(self):
self.reader = MysqlReader()
self.writer = Neo4jWriter()
def sync_category1(self):
sql = """
select id,name
from base_category1
"""
properties = self.reader.read(sql)
self.writer.write_nodes('Category1', properties)
def sync_category2(self):
sql = """
select id,name
from base_category2
"""
properties = self.reader.read(sql)
self.writer.write_nodes('Category2', properties)
def sync_category3(self):
sql = """
select id,name
from base_category3
"""
properties = self.reader.read(sql)
self.writer.write_nodes('Category3', properties)
def sync_category3_to_category2(self):
sql = """
select id start_id,
category2_id end_id
from base_category3
"""
relations = self.reader.read(sql)
self.writer.write_relations('Belong',start_label='Category3', end_label='Category2',relations = relations)
def sync_category2_to_category1(self):
sql = """
select id start_id,
category1_id end_id
from base_category2
"""
relations = self.reader.read(sql)
self.writer.write_relations('Belong',start_label='Category2', end_label='Category1',relations = relations)
def sync_base_attr_name(self):
sql = """
select id,attr_name name
from base_attr_info
"""
properties = self.reader.read(sql)
self.writer.write_nodes('BaseAttrName', properties)
def sync_base_attr_value(self):
sql = """
select id,value_name name
from base_attr_value
"""
properties = self.reader.read(sql)
self.writer.write_nodes('BaseAttrValue', properties)
def sync_base_attr_name_to_value(self):
sql = """
select id end_id,
attr_id start_id
from base_attr_value
"""
relations = self.reader.read(sql)
self.writer.write_relations('Have',start_label='BaseAttrValue', end_label='BaseAttrValue',relations = relations)
def sync_category1_to_base_attr_name(self):
sql = """
select category_id start_id,
id end_id
from base_attr_info
where category_level = 1
"""
relations = self.reader.read(sql)
self.writer.write_relations('Have', start_label='Category1', end_label='BaseAttrName', relations=relations)
def sync_category2_to_base_attr_name(self):
sql = """
select category_id start_id,
id end_id
from base_attr_info
where category_level = 2
"""
relations = self.reader.read(sql)
self.writer.write_relations('Have', start_label='Category2', end_label='BaseAttrName', relations=relations)
def sync_category3_to_base_attr_name(self):
sql = """
select category_id start_id,
id end_id
from base_attr_info
where category_level = 3
"""
relations = self.reader.read(sql)
self.writer.write_relations('Have', start_label='Category3', end_label='BaseAttrName', relations=relations)
# 商品信息
def sync_spu(self):
sql = """
select id,
spu_name name
from spu_info
"""
properties = self.reader.read(sql)
self.writer.write_nodes('SPU', properties)
def sync_sku(self):
sql = """
select id,
sku_name name
from sku_info
"""
properties = self.reader.read(sql)
self.writer.write_nodes('SKU', properties)
def sync_sku_to_spu(self):
sql = """
select id start_id,
spu_id end_id
from sku_info
"""
relations = self.reader.read(sql)
self.writer.write_relations('Belong', start_label='SKU', end_label='SPU', relations=relations)
def sync_spu_to_category3(self):
sql = """
select id start_id,
category3_id end_id
from spu_info
"""
relations = self.reader.read(sql)
self.writer.write_relations('Belong', start_label='SPU', end_label='Category3', relations=relations)
def sync_trademark(self):
sql = """
select id,
tm_name name
from base_trademark
"""
properties = self.reader.read(sql)
self.writer.write_nodes('Trademark', properties)
def sync_spu_to_trademark(self):
sql = """
select id start_id,
tm_id end_id
from spu_info
"""
relations = self.reader.read(sql)
self.writer.write_relations('Belong', start_label='SPU', end_label='Trademark', relations=relations)
def sync_sale_attr_name(self):
sql = """
select id,
sale_attr_name name
from spu_sale_attr
"""
properties = self.reader.read(sql)
self.writer.write_nodes('SaleAttrName', properties)
def sync_sale_attr_value(self):
sql = """
select id,
sale_attr_value_name name
from spu_sale_attr_value
"""
properties = self.reader.read(sql)
self.writer.write_nodes('SaleAttrValue', properties)
def sync_sale_attr_name_to_value(self):
sql = """
select a.id start_id,
v.id end_id
from spu_sale_attr a
join spu_sale_attr_value v
on a.spu_id = v.spu_id
and a.base_sale_attr_id = v.base_sale_attr_id
"""
relations = self.reader.read(sql)
self.writer.write_relations('Have',start_label='SaleAttrName', end_label='SaleAttrValue',relations=relations)
def sync_spu_to_sale_attr_name(self):
sql = """
select spu_id start_id,
id end_id
from spu_sale_attr
"""
relations = self.reader.read(sql)
self.writer.write_relations('Have',start_label='SPU', end_label='SaleAttrName',relations=relations)
def sync_sku_to_sale_attr_value(self):
sql = """
select sku_id start_id,
sale_attr_value_id end_id
from sku_sale_attr_value
"""
relations = self.reader.read(sql)
self.writer.write_relations('Have', start_label='SKU', end_label='SaleAttrValue', relations=relations)
def sync_sku_to_base_attr_value(self):
sql = """
select sku_id start_id,
value_id end_id
from sku_attr_value
"""
relations = self.reader.read(sql)
self.writer.write_relations('Have', start_label='SKU', end_label='BaseAttrValue', relations=relations)
if __name__ == "__main__":
synchronizer = TableSynchronizer()
synchronizer.sync_category1()
synchronizer.sync_category2()
synchronizer.sync_category3()
synchronizer.sync_category2_to_category1()
synchronizer.sync_category3_to_category2()
synchronizer.sync_base_attr_name()
synchronizer.sync_base_attr_value()
synchronizer.sync_base_attr_name_to_value()
synchronizer.sync_category1_to_base_attr_name()
synchronizer.sync_category2_to_base_attr_name()
synchronizer.sync_category3_to_base_attr_name()
synchronizer.sync_spu()
synchronizer.sync_sku()
synchronizer.sync_sku_to_spu()
synchronizer.sync_spu_to_category3()
synchronizer.sync_trademark()
synchronizer.sync_spu_to_trademark()
synchronizer.sync_sale_attr_name()
synchronizer.sync_sale_attr_value()
synchronizer.sync_sale_attr_name_to_value()
synchronizer.sync_spu_to_sale_attr_name()
synchronizer.sync_sku_to_sale_attr_value()
synchronizer.sync_sku_to_base_attr_value()text_sync
import torch
from transformers import AutoTokenizer, AutoModelForTokenClassification
from configuration.config import *
from utils import MysqlReader,Neo4jWriter
from ner.predict import Predictor
class TextSynchronizer():
def __init__(self):
self.reader = MysqlReader()
self.writer = Neo4jWriter()
self.extractor = self._init_extractor()
# 内部函数,初始化一个predictor
def _init_extractor(self):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModelForTokenClassification.from_pretrained(str(CHECKPOINT_DIR / NER_DIR / 'best_model'))
tokenizer = AutoTokenizer.from_pretrained(str(CHECKPOINT_DIR / NER_DIR / 'best_model'))
return Predictor(model, tokenizer,device)
# 同步tag标签
def sync_tag(self):
sql = """
select id,description
from spu_info
"""
spu_desc = self.reader.read(sql)
ids = [item['id'] for item in spu_desc]
descs = [item['description'] for item in spu_desc]
tags_list = self.extractor.extract(descs)
# for id, tags in zip(ids, tags_list):
# print(id, tags)
tag_properties = []
relations = []
for id,tags in zip(ids,tags_list):
for index,tag in enumerate(tags):
tag_id = '-'.join([str(id),str(index)])
property = {'id':tag_id,'name':tag}
tag_properties.append(property)
relation = {'start_id':id,'end_id':tag_id}
relations.append(relation)
self.writer.write_nodes('Tag', tag_properties)
self.writer.write_relations('Have', start_label='SPU', end_label='Tag', relations=relations)
if __name__ == '__main__':
synchronizer = TextSynchronizer()
synchronizer.sync_tag()
基于图数据库问答系统案例
from langchain_deepseek import ChatDeepSeek
from langchain_neo4j import Neo4jGraph, GraphCypherQAChain
from configuration.config import *
graph = Neo4jGraph(
url = NEO4J_CONFIG['uri'],
username = NEO4J_CONFIG['auth'][0],
password = NEO4J_CONFIG['auth'][1],
)
# print(graph.schema)
# cypher = 'MATCH (n) RETURN n LIMIT 4'
# print(graph.query(cypher))
llm = ChatDeepSeek(
model = 'deepseek-chat',
api_key = API_KEY,
temperature=0
)
chain = GraphCypherQAChain.from_llm(
graph = graph,
llm = llm,
verbose = True,
allow_dangerous_requests = True
)
result = chain.invoke({'query':'华为有哪些产品?'})
print(result)
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (t:Trademark {name: '华为'})<-[:Belong]-(s:SPU)
RETURN s.name
Full Context:
[{'s.name': '华为HUAWEI二手笔记本MateBook13触屏2K全面屏'}, {'s.name': '华为Mate 40 pro'}, {'s.name': 'HAWEIAI Book 2025英特尔14 Pro满血独显笔记本'}, {'s.name': '华为智慧屏 4K全面屏智能电视机'}]
> Finished chain.
{'query': '华为有哪些产品?', 'result': '华为的产品包括:华为HUAWEI二手笔记本MateBook13触屏2K全面屏、华为Mate 40 pro、HAWEIAI Book 2025英特尔14 Pro满血独显笔记本,以及华为智慧屏 4K全面屏智能电视机。'}实体对齐
实体对齐思路
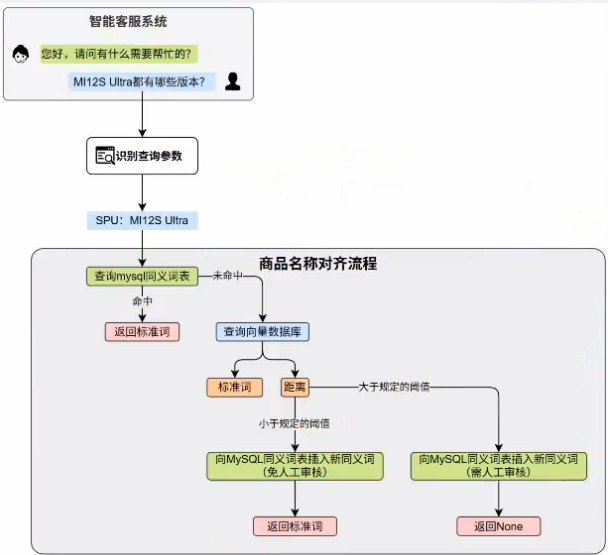
基于向量数据库和同义词表
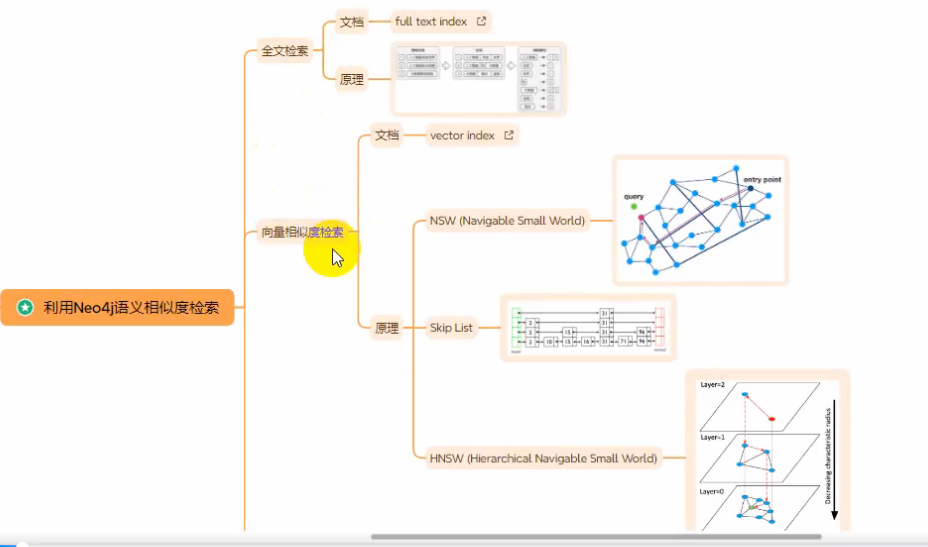
基于Neo4j语义相似度检索
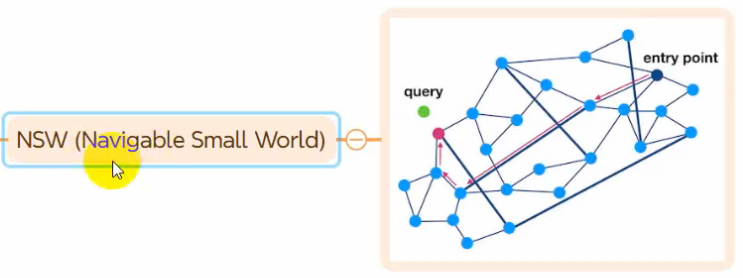
具体实现
utils
from langchain_neo4j import Neo4jGraph, Neo4jVector
from configuration.config import *
from langchain_huggingface import HuggingFaceEmbeddings
class IndexUtil:
def __init__(self):
self.graph = Neo4jGraph(
url=NEO4J_CONFIG['uri'],
username=NEO4J_CONFIG['auth'][0],
password=NEO4J_CONFIG['auth'][1],
)
self.embedding_model = HuggingFaceEmbeddings(
model_name = 'BAAI/bge-base-zh',
encode_kwargs = {'normalize_embeddings': True}
)
# 创建全文索引
def create_fulltext_index(self,index_name,label,property):
cypher = f"""
CREATE FULLTEXT INDEX {index_name} IF NOT EXISTS
FOR (n:{label}) ON EACH [n.{property}]
"""
self.graph.query(cypher)
# 向量索引
def create_vector_index(self,index_name,label,source_property,embedding_property):
# 生成嵌入向量,并添加到节点属性中
embedding_dim = self._add_embedding(label,source_property,embedding_property)
cypher = f"""
CREATE VECTOR INDEX {index_name} IF NOT EXISTS
FOR (n:{label})
ON n.{embedding_property}
OPTIONS {{ indexConfig: {{
`vector.dimensions`: {embedding_dim},
`vector.similarity_function`: 'cosine'
}}
}}
"""
self.graph.query(cypher)
# 内部函数,生成嵌入向量并添加到节点属性中,返回向量维度
def _add_embedding(self,label,source_property,embedding_property):
# 查询所有节点对应的源属性值作为模型的输入,还需查出节点id
cypher = f"""
MATCH (n:{label})
RETURN n.{source_property} AS text,id(n) AS id
"""
results = self.graph.query(cypher)
# 获取查询结果中的文本内容
docs = [result['text'] for result in results]
# 调用嵌入模型,得到嵌入向量
embeddings = self.embedding_model.embed_documents(docs)
# 将id和嵌入向量组合成字典形式
batch = []
for result,embedding in zip(results,embeddings):
item = {'id':result['id'],'embedding':embedding}
batch.append(item)
# 执行cypher按id查节点写入新的嵌入向量属性
cypher = f"""
UNWIND $batch AS item
MATCH (n:{label})
WHERE id(n) = item.id
SET n.{embedding_property} = item.embedding
"""
self.graph.query(cypher,params = {'batch':batch})
return len(embeddings[0])
if __name__ == '__main__':
index = IndexUtil()
index.create_fulltext_index('trademark_fulltext_index','Trademark','name')
index.create_vector_index('trademark_vector_index', 'Trademark', 'name','embedding')
#
#
#
# index_name = "trademark_vector_index" # default index name
# keyword_index_name = "trademark_fulltext_index" # default keyword index name
#
# store = Neo4jVector.from_existing_index(
# index.embedding_model,
# url=NEO4J_CONFIG['uri'],
# username=NEO4J_CONFIG['auth'][0],
# password=NEO4J_CONFIG['auth'][1],
# index_name=index_name,
# keyword_index_name=keyword_index_name,
# search_type="hybrid",
# )
#
# result = store.similarity_search('Apple',k = 1)[0].page_content
# print(result)
index.create_fulltext_index('spu_fulltext_index','SPU','name')
index.create_vector_index('spu_vector_index','SPU','name','embedding')
index.create_fulltext_index('sku_fulltext_index','SKU','name')
index.create_vector_index('sku_vector_index','SKU','name','embedding')
index.create_fulltext_index('category1_fulltext_index','Category1','name')
index.create_vector_index('category1_vector_index','Category1','name','embedding')
index.create_fulltext_index('category2_fulltext_index','Category2','name')
index.create_vector_index('category2_vector_index','Category2','name','embedding')
index.create_fulltext_index('category3_fulltext_index','Category3','name')
index.create_vector_index('category3_vector_index','Category3','name','embedding')service
from langchain_core.output_parsers import JsonOutputParser, StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_neo4j import Neo4jGraph, Neo4jVector
from configuration.config import *
class ChatService:
def __init__(self):
self.graph = Neo4jGraph(
url=NEO4J_CONFIG['uri'],
username=NEO4J_CONFIG['auth'][0],
password=NEO4J_CONFIG['auth'][1],
)
self.embedding_model = HuggingFaceEmbeddings(
model_name = 'BAAI/bge-base-zh',
encode_kwargs = {'normalize_embeddings': True}
)
self.llm = ChatDeepSeek(
model = 'deepseek-chat',
api_key = API_KEY,
)
# 定义所有实体对应的混合检索Neo4jVector对象
self.neo4j_vectors = {
'SPU': Neo4jVector.from_existing_index(
self.embedding_model,
url=NEO4J_CONFIG['uri'],
username=NEO4J_CONFIG['auth'][0],
password=NEO4J_CONFIG['auth'][1],
index_name='spu_vector_index',
keyword_index_name='spu_fulltext_index',
search_type="hybrid",
),
'SKU': Neo4jVector.from_existing_index(
self.embedding_model,
url=NEO4J_CONFIG['uri'],
username=NEO4J_CONFIG['auth'][0],
password=NEO4J_CONFIG['auth'][1],
index_name='sku_vector_index',
keyword_index_name='sku_fulltext_index',
search_type="hybrid",
),
'Category1': Neo4jVector.from_existing_index(
self.embedding_model,
url=NEO4J_CONFIG['uri'],
username=NEO4J_CONFIG['auth'][0],
password=NEO4J_CONFIG['auth'][1],
index_name='category1_vector_index',
keyword_index_name='category1_fulltext_index',
search_type="hybrid",
),
'Category2': Neo4jVector.from_existing_index(
self.embedding_model,
url=NEO4J_CONFIG['uri'],
username=NEO4J_CONFIG['auth'][0],
password=NEO4J_CONFIG['auth'][1],
index_name='category2_vector_index',
keyword_index_name='category2_fulltext_index',
search_type="hybrid",
),
'Category3': Neo4jVector.from_existing_index(
self.embedding_model,
url=NEO4J_CONFIG['uri'],
username=NEO4J_CONFIG['auth'][0],
password=NEO4J_CONFIG['auth'][1],
index_name='category3_vector_index',
keyword_index_name='category3_fulltext_index',
search_type="hybrid",
),
'Trademark': Neo4jVector.from_existing_index(
self.embedding_model,
url=NEO4J_CONFIG['uri'],
username=NEO4J_CONFIG['auth'][0],
password=NEO4J_CONFIG['auth'][1],
index_name='trademark_vector_index',
keyword_index_name='trademark_fulltext_index',
search_type="hybrid",
)
}
# 定义parser
self.json_parser = JsonOutputParser()
self.str_parser = StrOutputParser()
def chat(self,question):
# 根据用户问题生成cypher以及需要对齐的实体
result = self._generate_cypher(question)
cypher = result['cypher_query']
entities_to_align = result['entities_to_align']
print(cypher)
print("对齐之前的实体名称:",entities_to_align)
# 实体对齐
aligned_entities = self._entity_align(entities_to_align)
print("对齐之后的实体名称:",aligned_entities)
# 执行cypher语句,得到查询结果
query_result = self._execute_cypher(cypher, aligned_entities)
print("查询结果:",query_result)
# 根据用户问题和查询结果生成答案
answer = self._generate_answer(question,query_result)
print("最终输出:",answer)
return answer
# 根据问题调用LLM生成cypher
def _generate_cypher(self,question):
prompt = """
你是一个专业的Neo4j Cypher查询生成器。你的任务是根据用户问题生成一条Cypher查询语句,用于从知识图谱中获取回答用户问题所需的信息。
用户问题:{question}
知识图谱结构信息:{schema_info}
要求:
1.生成参数化Cypher查询语句,用param_0, param_1等代替具体值
2.识别需要对齐的实体
3.必须严格使用以下JSON格式输出结果
{{
"cypher_query": "生成的Cypher语句",
"entities_to_align": [
{{"param_name": "param_0",
"entity": "原始实体名称",
"label": "节点类型"
}}
]
}}
"""
prompt = PromptTemplate.from_template(prompt)
prompt = prompt.format(question=question,schema_info = self.graph.schema)
output = self.llm.invoke(prompt)
result = self.json_parser.invoke(output)
return result
# 实体对齐
def _entity_align(self,entities_to_align):
# 遍历所有的实体
for index,entity_to_align in enumerate(entities_to_align):
label = entity_to_align['label']
entity = entity_to_align['entity']
# 混合检索,得到对齐后的实体名称
aligned_entity = self.neo4j_vectors[label].similarity_search(entity,k=1)[0].page_content
entities_to_align[index]['entity']=aligned_entity
return entities_to_align
# 执行cypher
def _execute_cypher(self,cypher,aligned_entities):
params = {aligned_entity['param_name']:aligned_entity['entity'] for aligned_entity in aligned_entities}
return self.graph.query(cypher,params=params)
# 生成回答
def _generate_answer(self,question,query_result):
prompt = """
你是一个电商智能客服,根据用户问题,以及数据库查询结果生成一段简洁、准确的自然语言回答。
用户问题: {question}
数据库返回结果: {query_result}
"""
prompt = prompt.format(question=question,query_result=query_result)
output = self.llm.invoke(prompt)
result = self.str_parser.invoke(output)
return result
if __name__ == '__main__':
chat_service = ChatService()
chat_service.chat('Apple有哪些产品')
MATCH (t:Trademark {name: $param_0})<-[:Belong]-(s:SPU) RETURN s.name
对齐之前的实体名称: [{'param_name': 'param_0', 'entity': 'Apple', 'label': 'Trademark'}]
对齐之后的实体名称: [{'param_name': 'param_0', 'entity': '苹果', 'label': 'Trademark'}]
查询结果: [{'s.name': 'Apple iPhone 16 Pro'}, {'s.name': 'Apple iPhone 12'}]
最终输出: Apple目前有iPhone 16 Pro和iPhone 12两款产品在售。schemas
from pydantic import BaseModel
class Question(BaseModel):
message: str
class Answer(BaseModel):
message: strapp
import uvicorn
from fastapi import FastAPI
from starlette.responses import RedirectResponse
from starlette.staticfiles import StaticFiles
from schemas import Question,Answer
from service import ChatService
from configuration.config import *
app = FastAPI()
# 挂载
app.mount("/static", StaticFiles(directory=WEB_STATIC_DIR), name="static")
service = ChatService()
@app.get("/")
def read_root():
return RedirectResponse(url="/static/index.html")
@app.post("/api/chat")
def read_item(question: Question) -> Answer:
result = service.chat(question)
return Answer(message=result)
if __name__ == "__main__":
uvicorn.run('web.app:app', host="0.0.0.0", port=8000)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)