YOLOv8食品识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要
为实现复杂场景下多类别食品的自动识别与检测,本文基于YOLOv8目标检测算法构建了一套包含30类常见食品的检测系统。系统涵盖了酒精饮料、面包、奶酪、肉类、水果、蔬菜等日常生活常见食品类别。模型在包含12802张训练图像的数据集上进行了训练,并通过1220张验证集和639张测试集进行了评估。实验结果表明,模型在多数类别上表现出较高的精确率和召回率,归一化混淆矩阵中大部分类别的准确率超过0.85,PR曲线近似矩形,说明模型具有良好的判别能力。F1曲线在置信度为0.17时达到0.68的整体平衡值。尽管mAP50指标(约0.28)受到小目标、类别不平衡及部分语义相似类别的影响而偏低,但整体训练过程收敛良好,损失函数稳步下降。该系统在精确率优先的食品识别任务中具备实用价值,可用于餐饮结算、食品分拣与营养监测等场景。
目录
功能模块
✅ 用户登录注册:支持密码检测,密码加密。
注册
登录
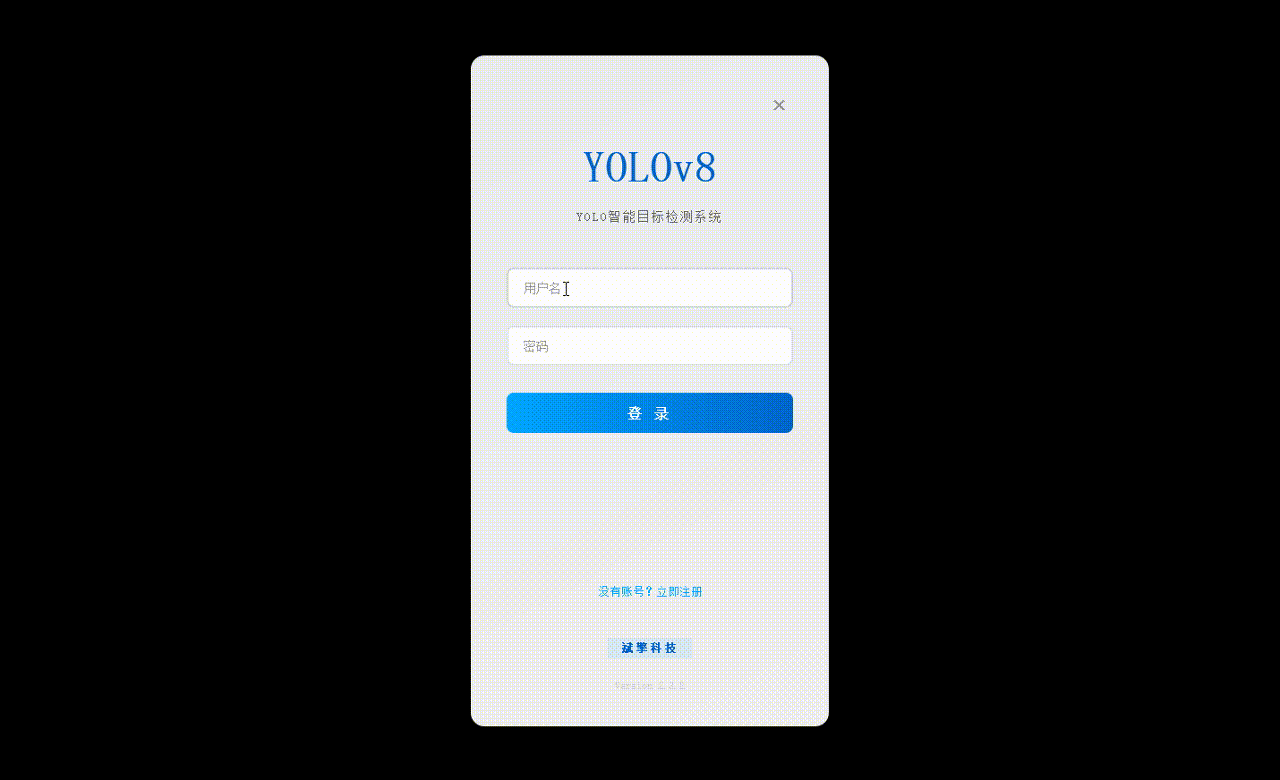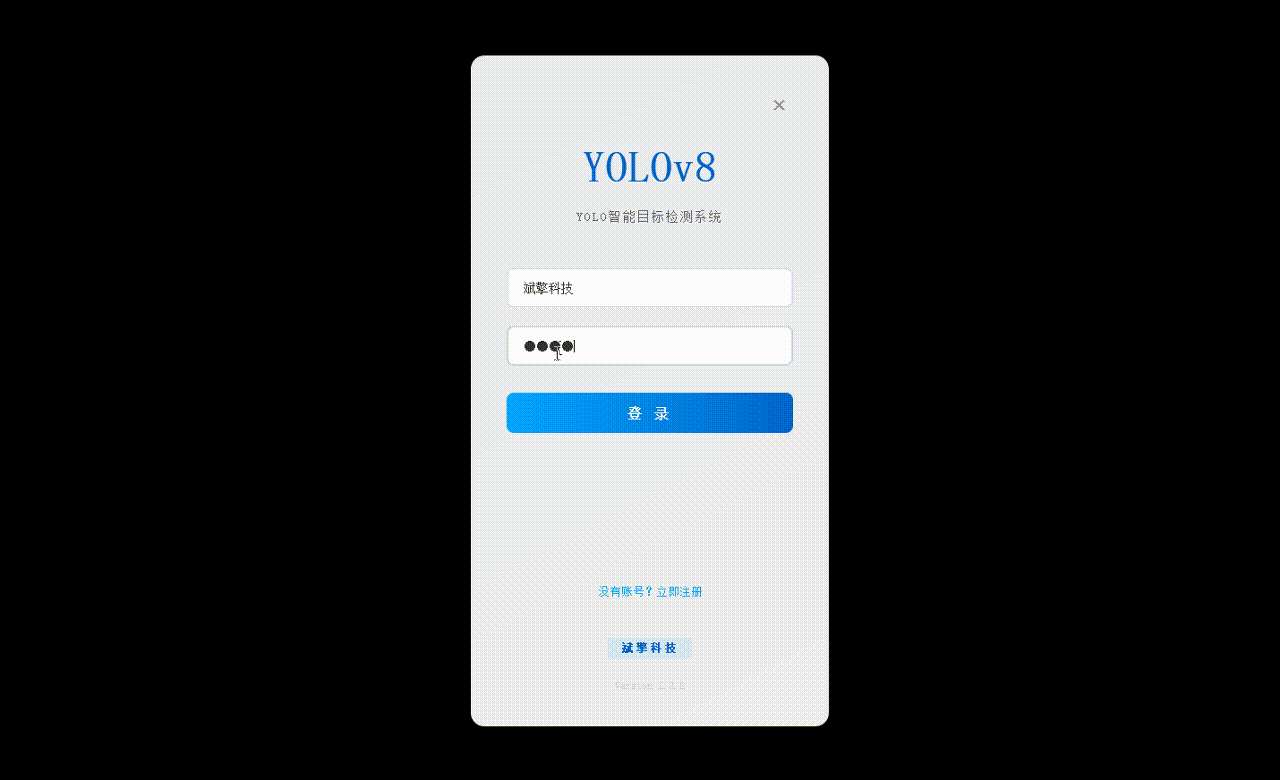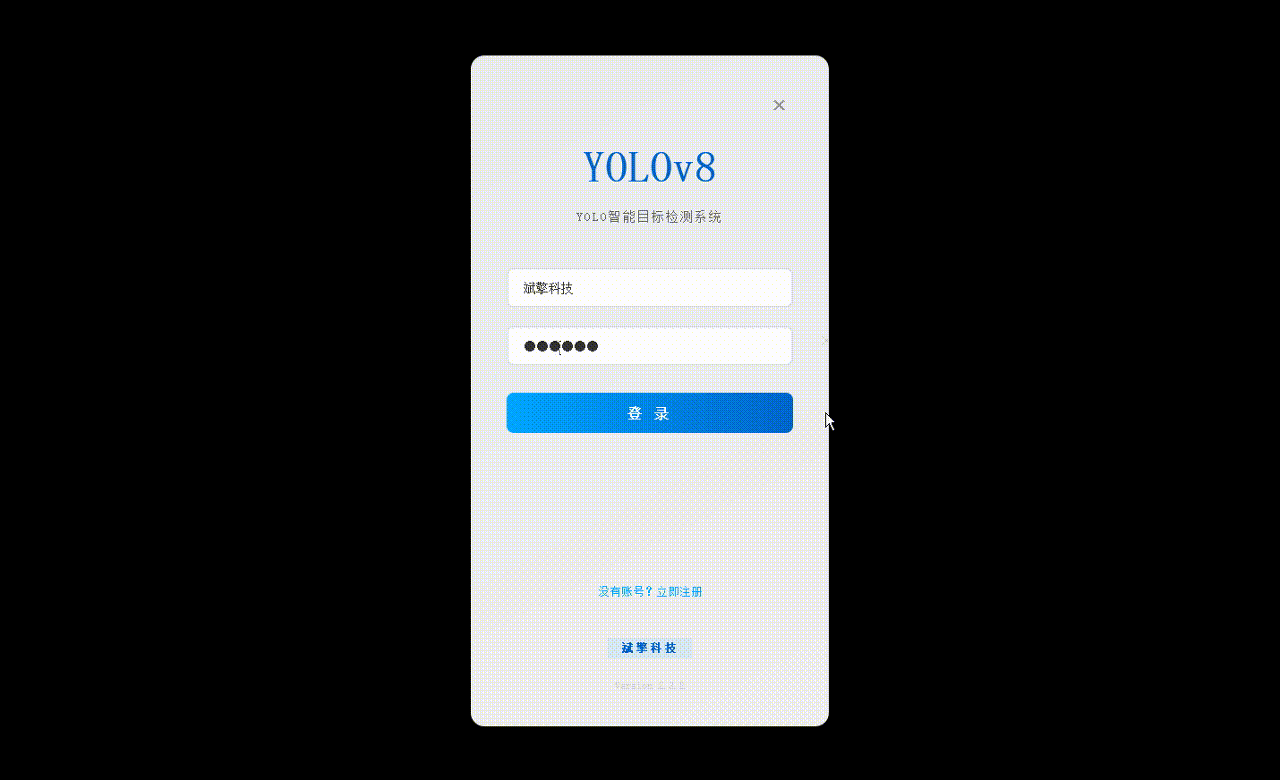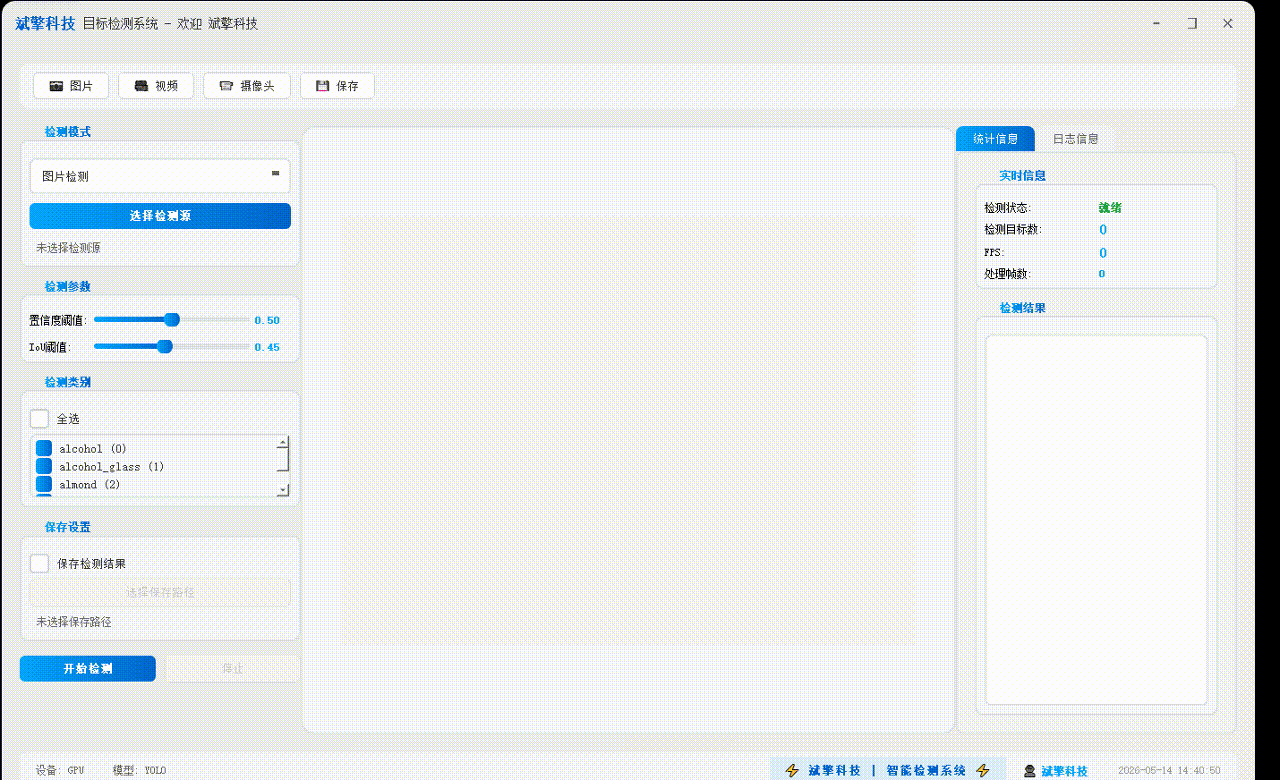
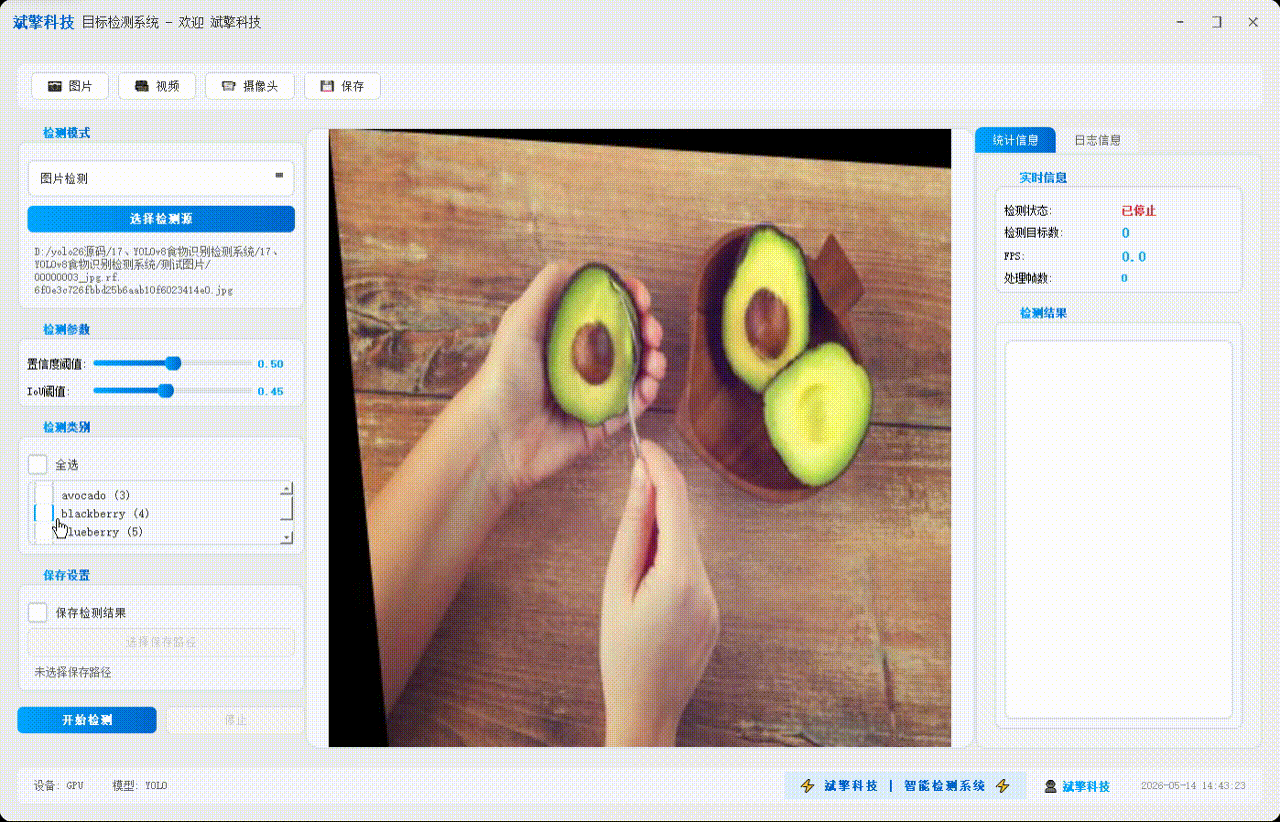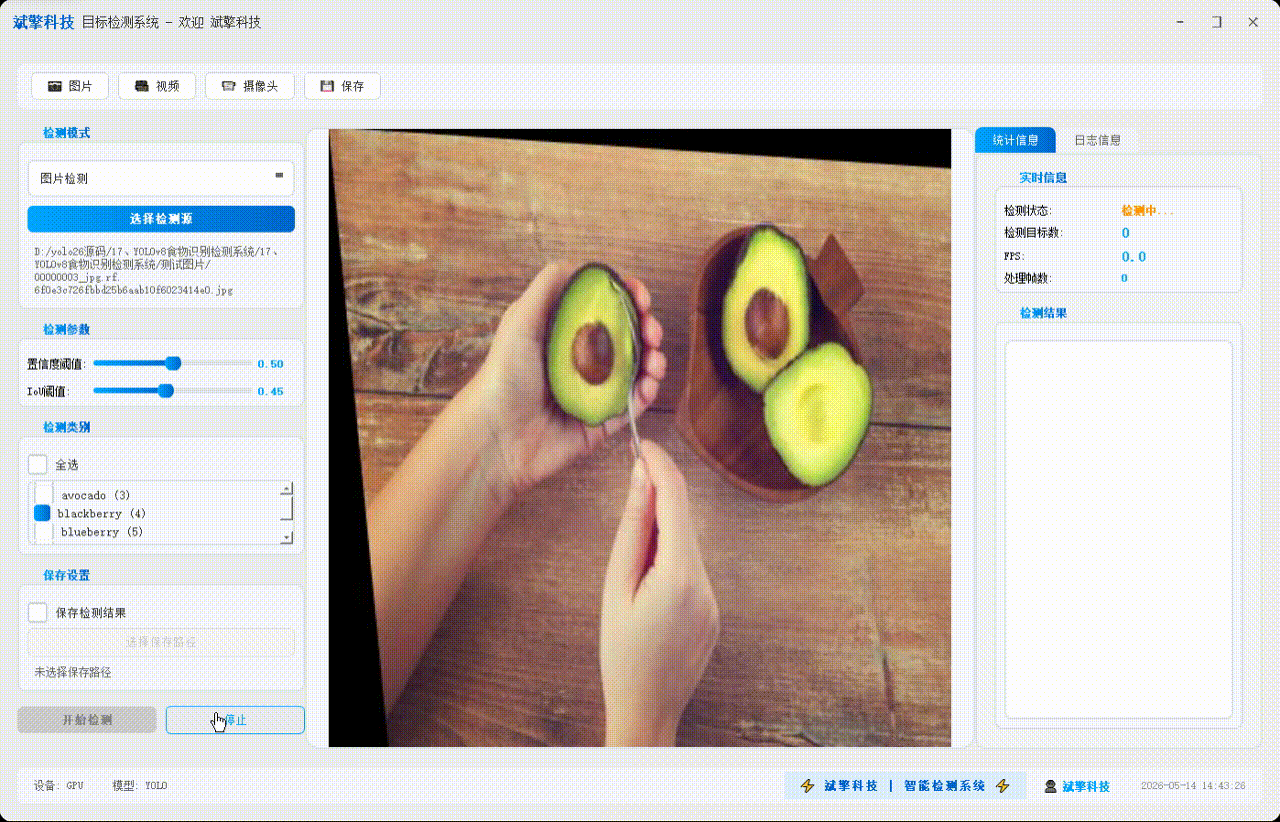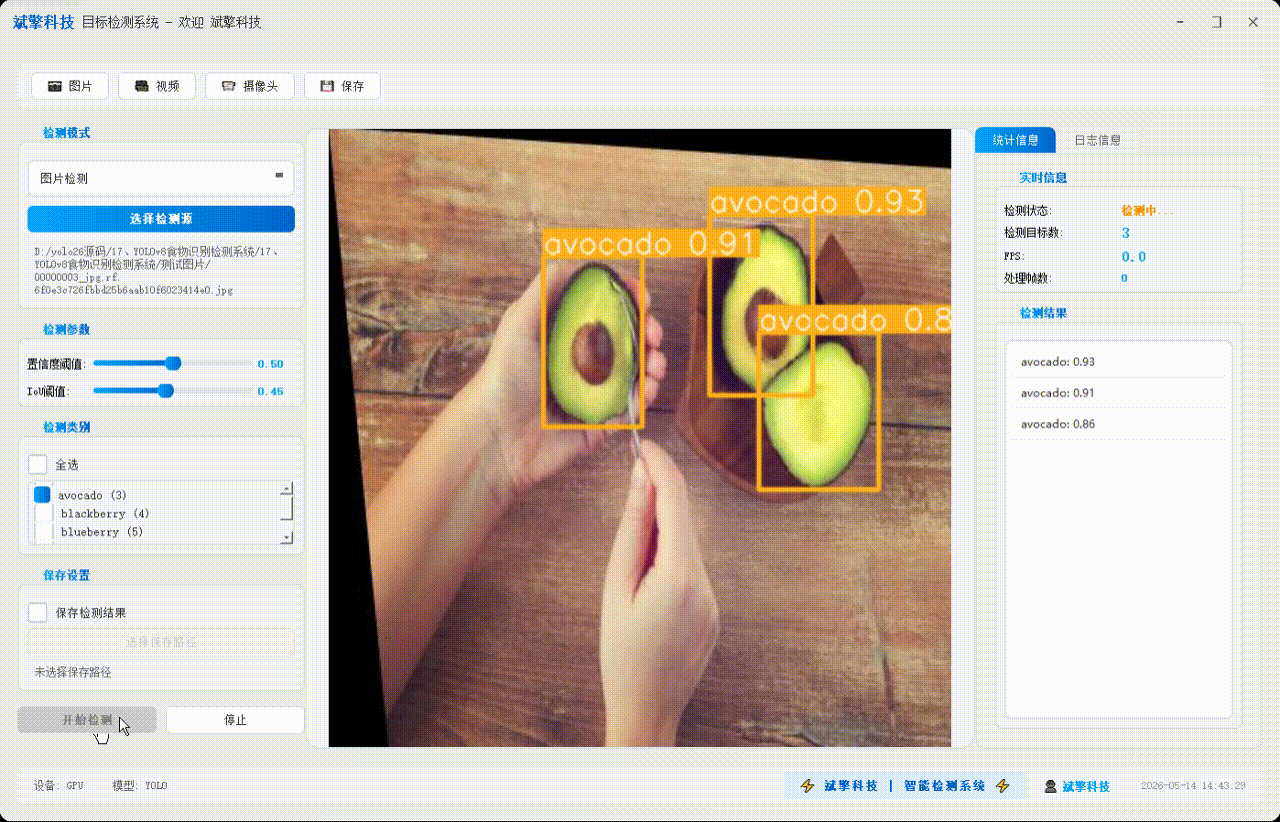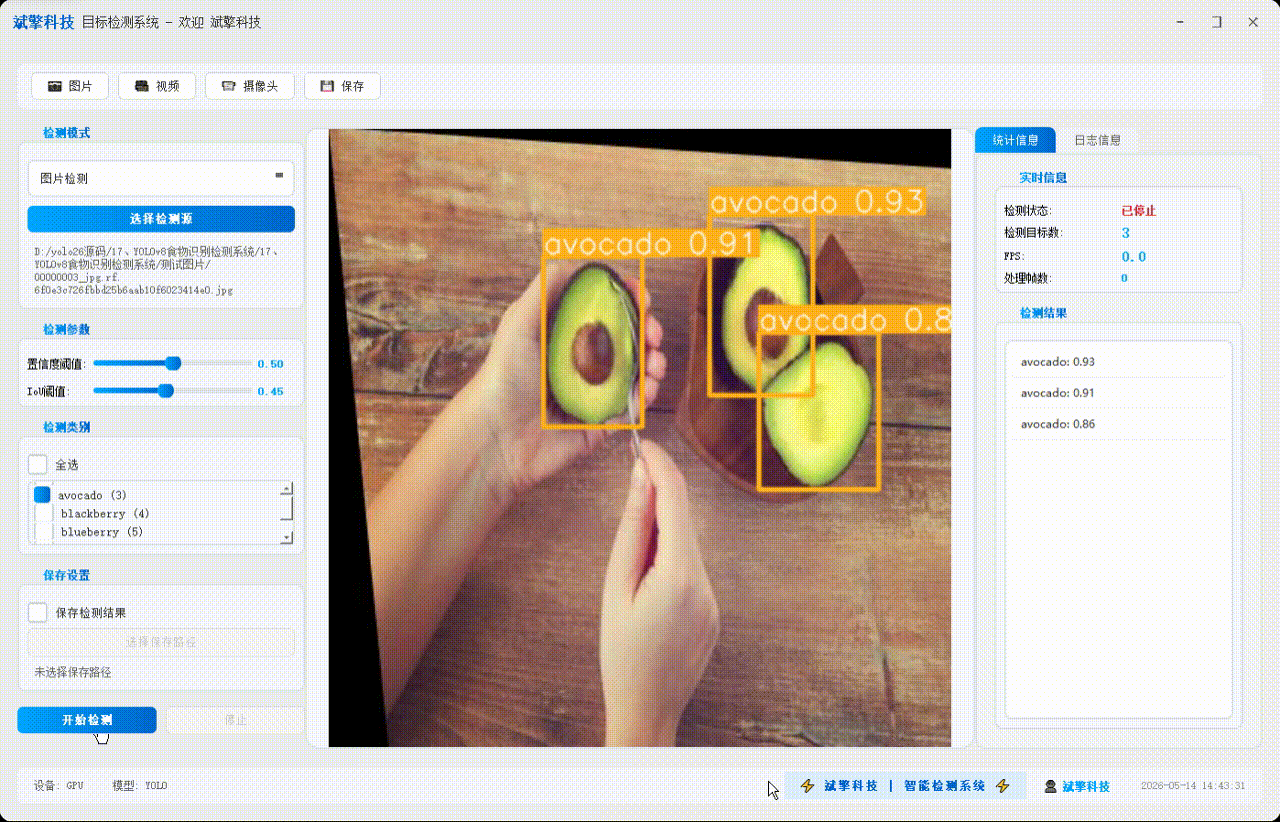
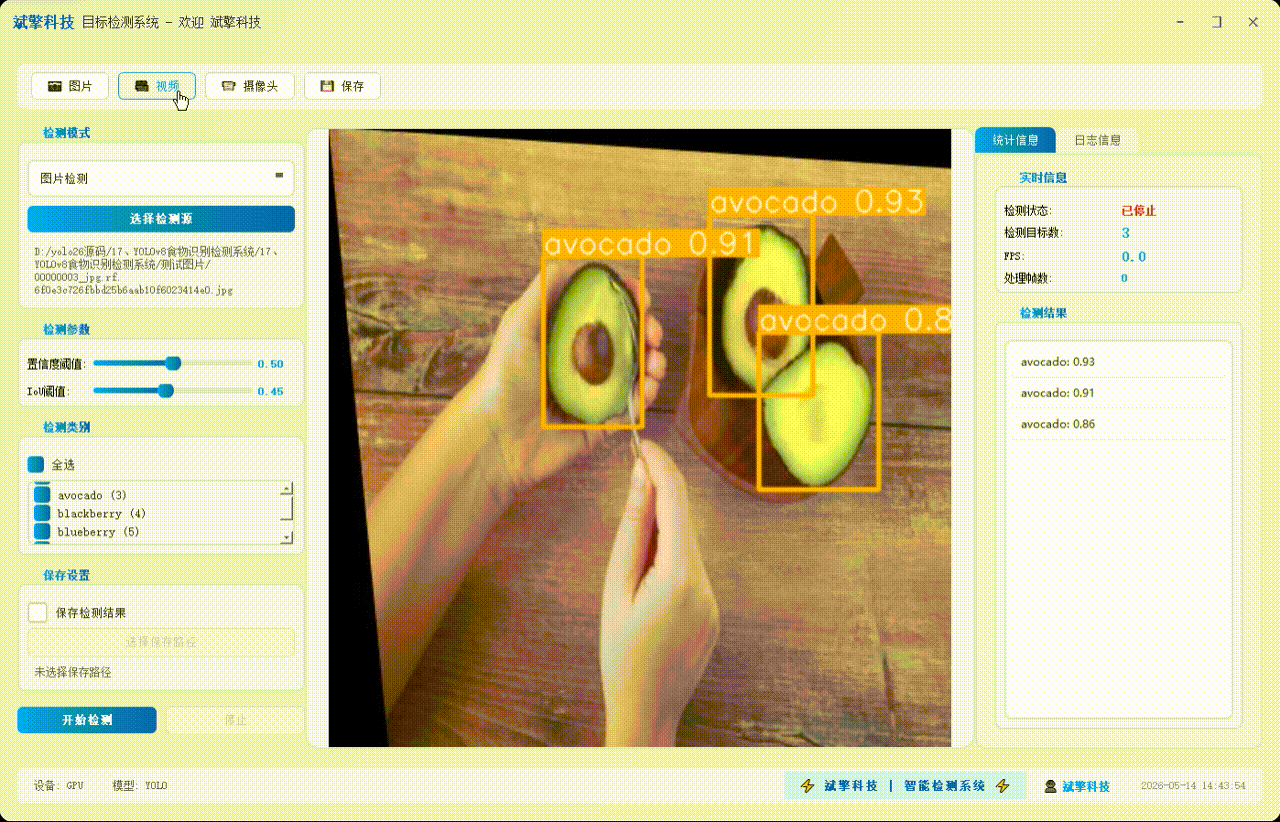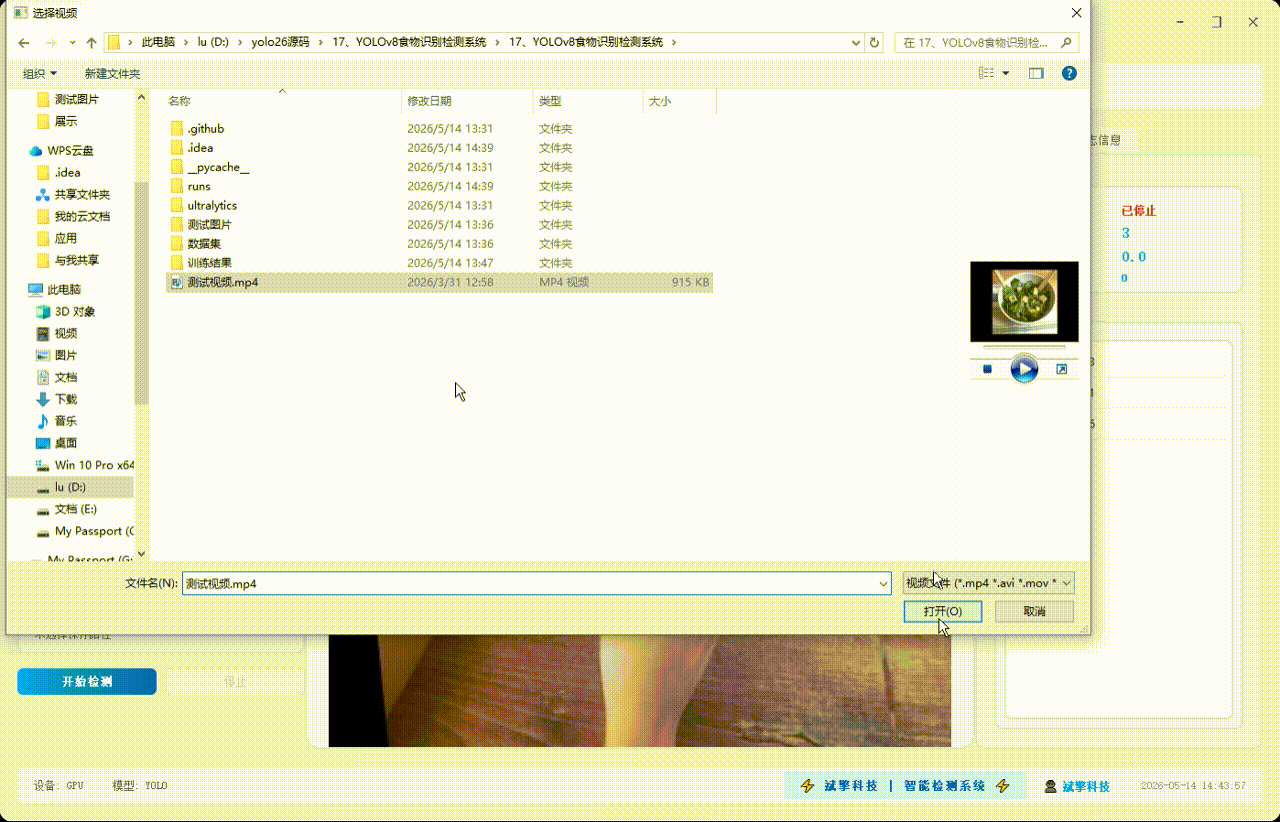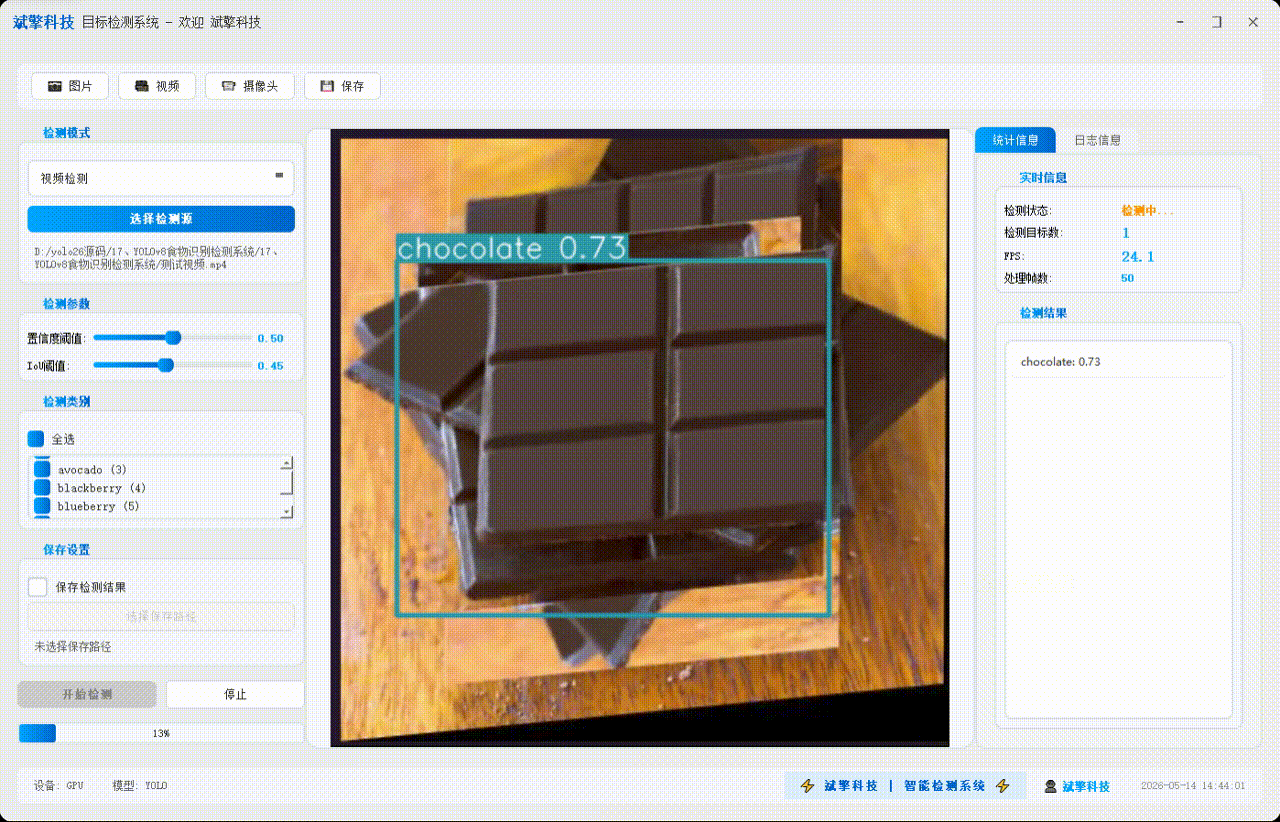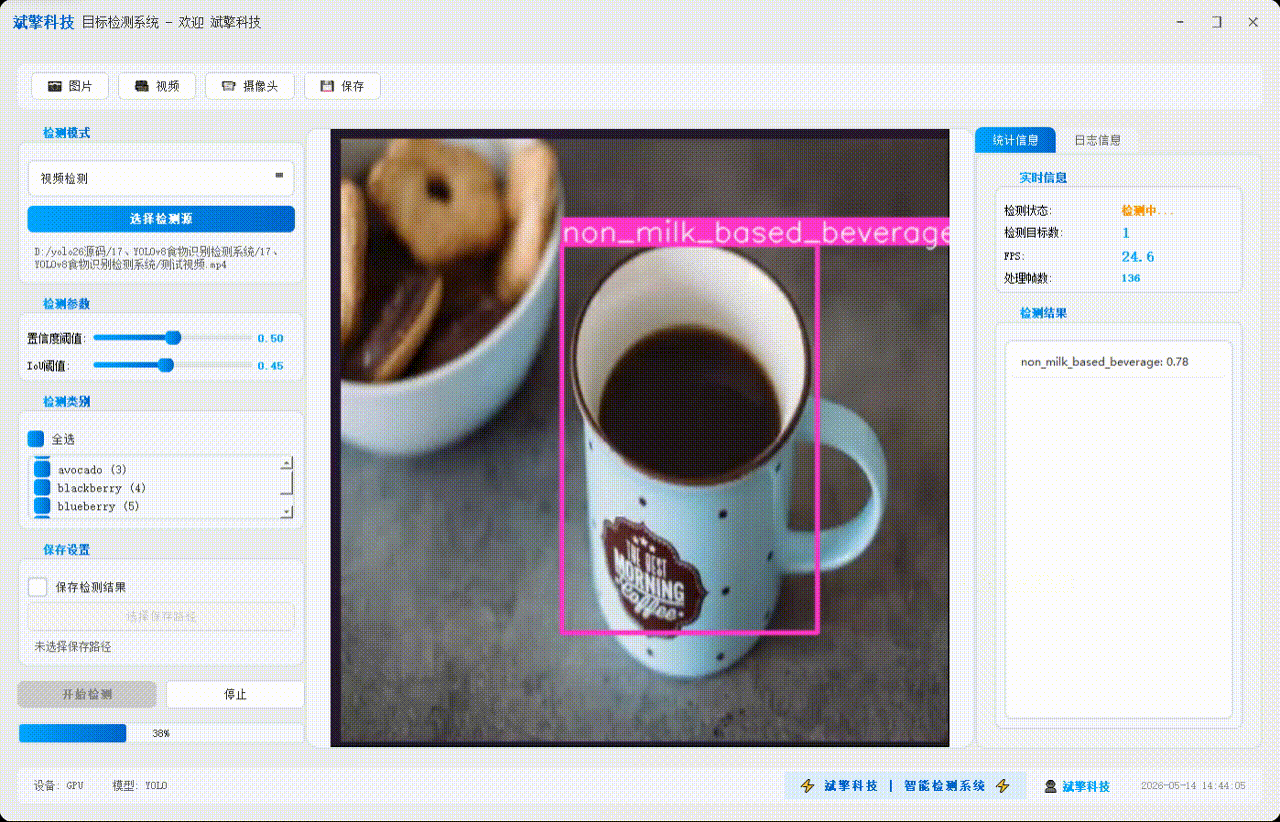
✅ 图片检测:可对图片进行检测,返回检测框及类别信息。
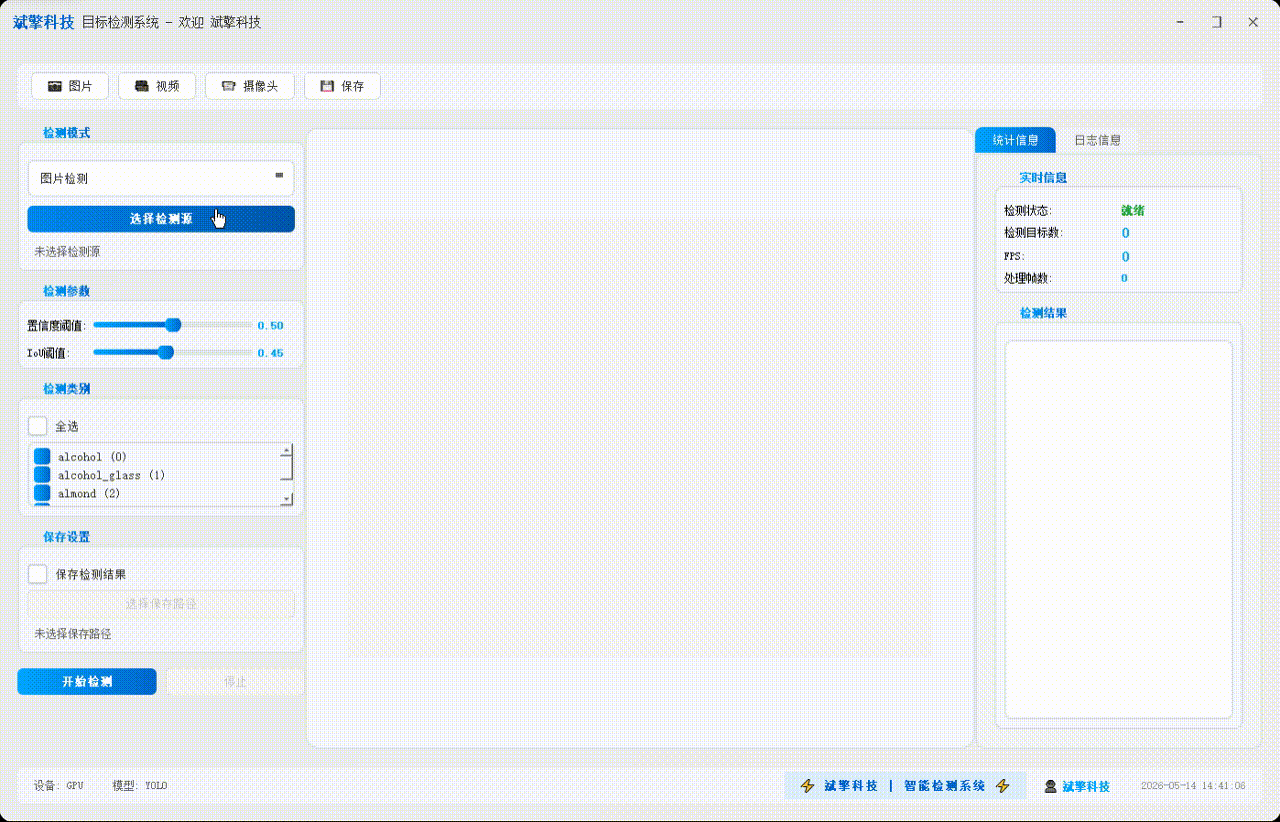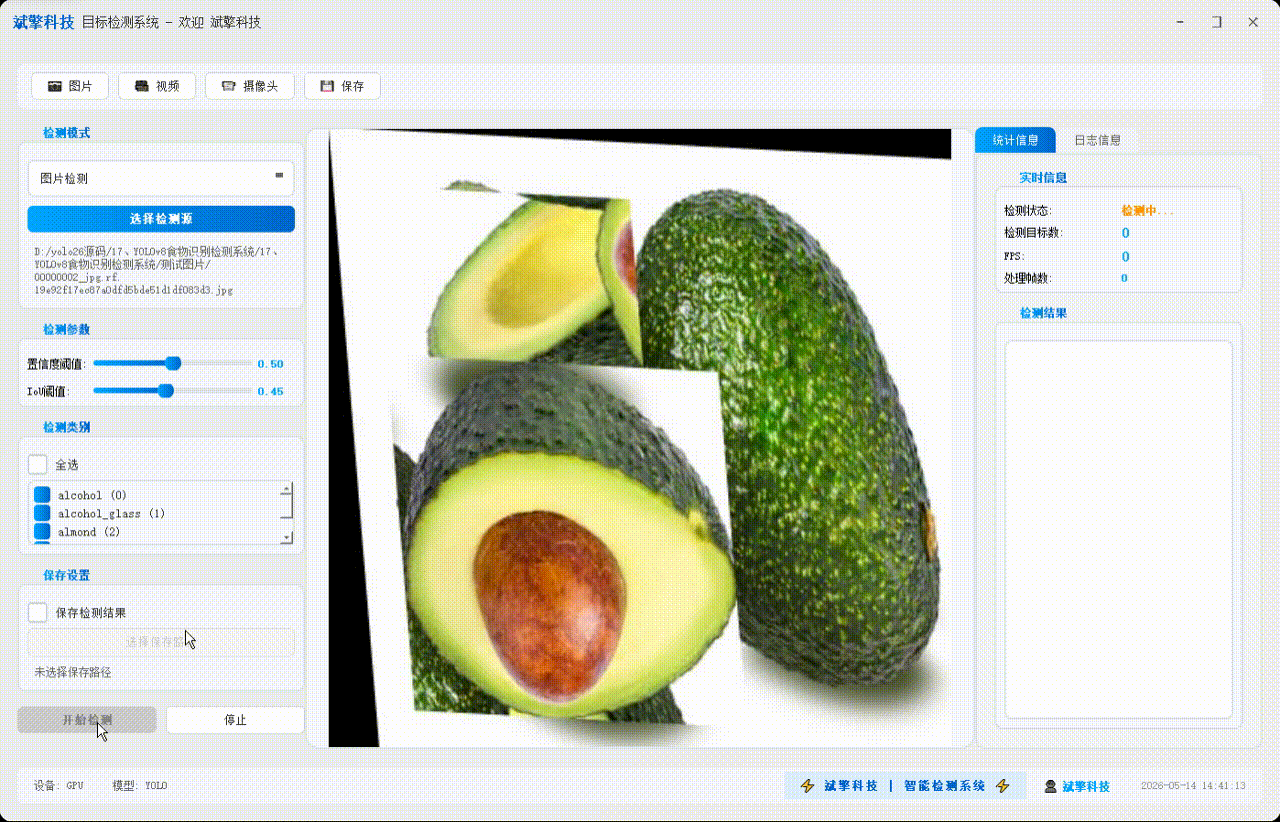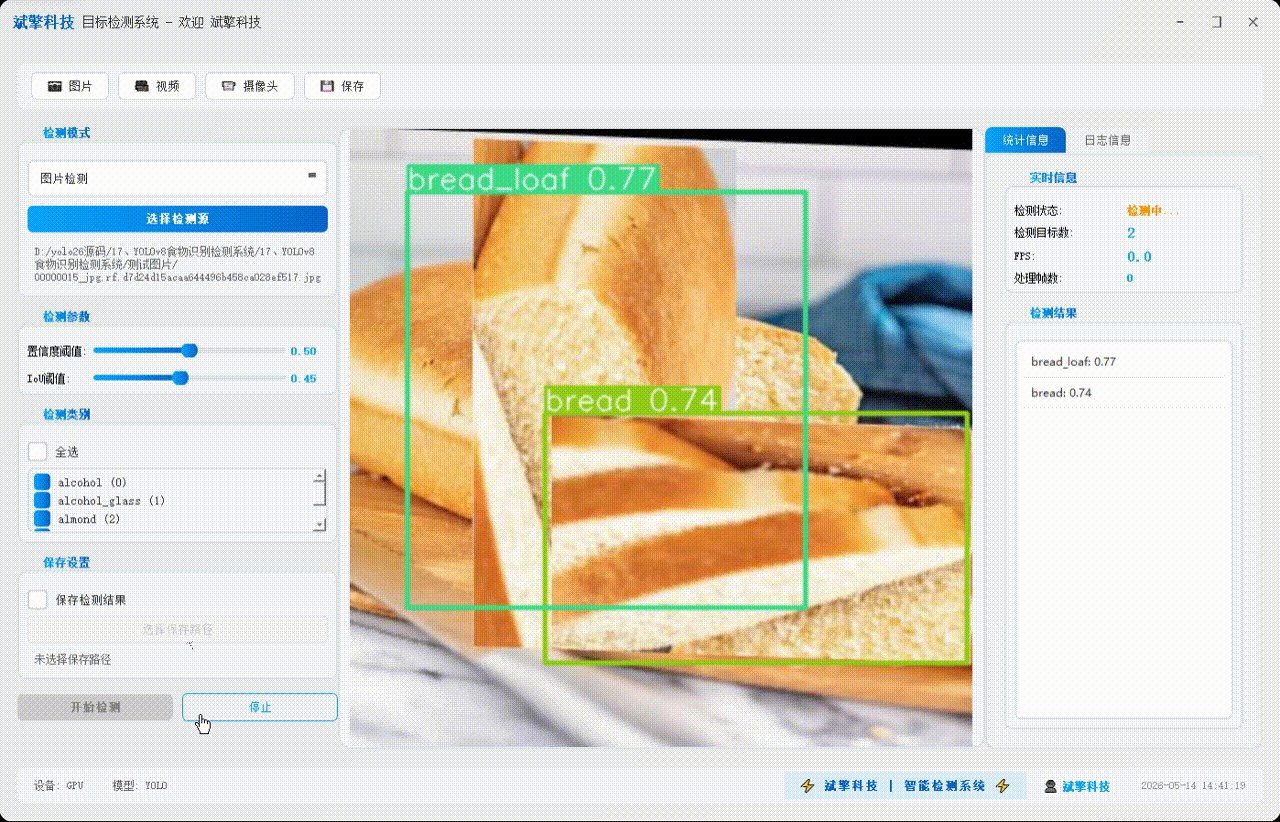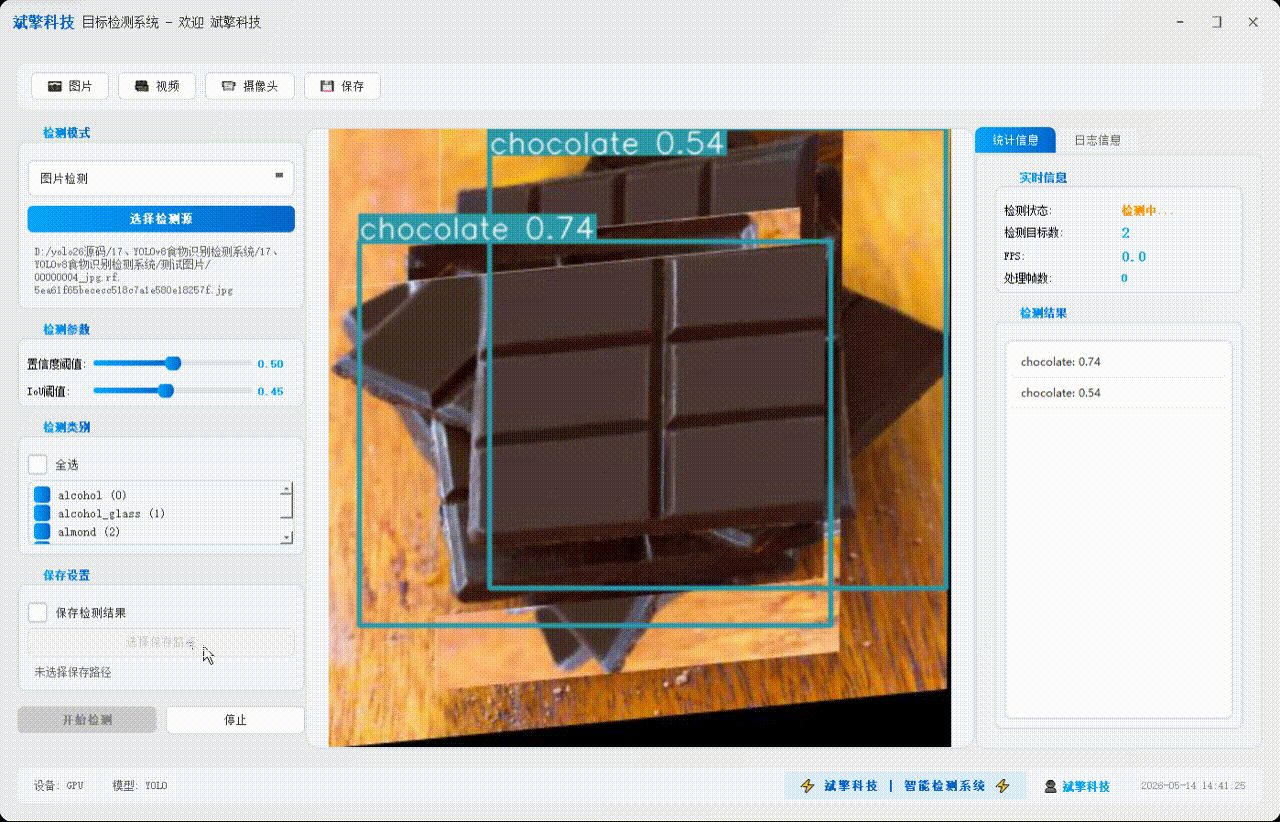
✅参数实时调节(置信度和IoU阈值)
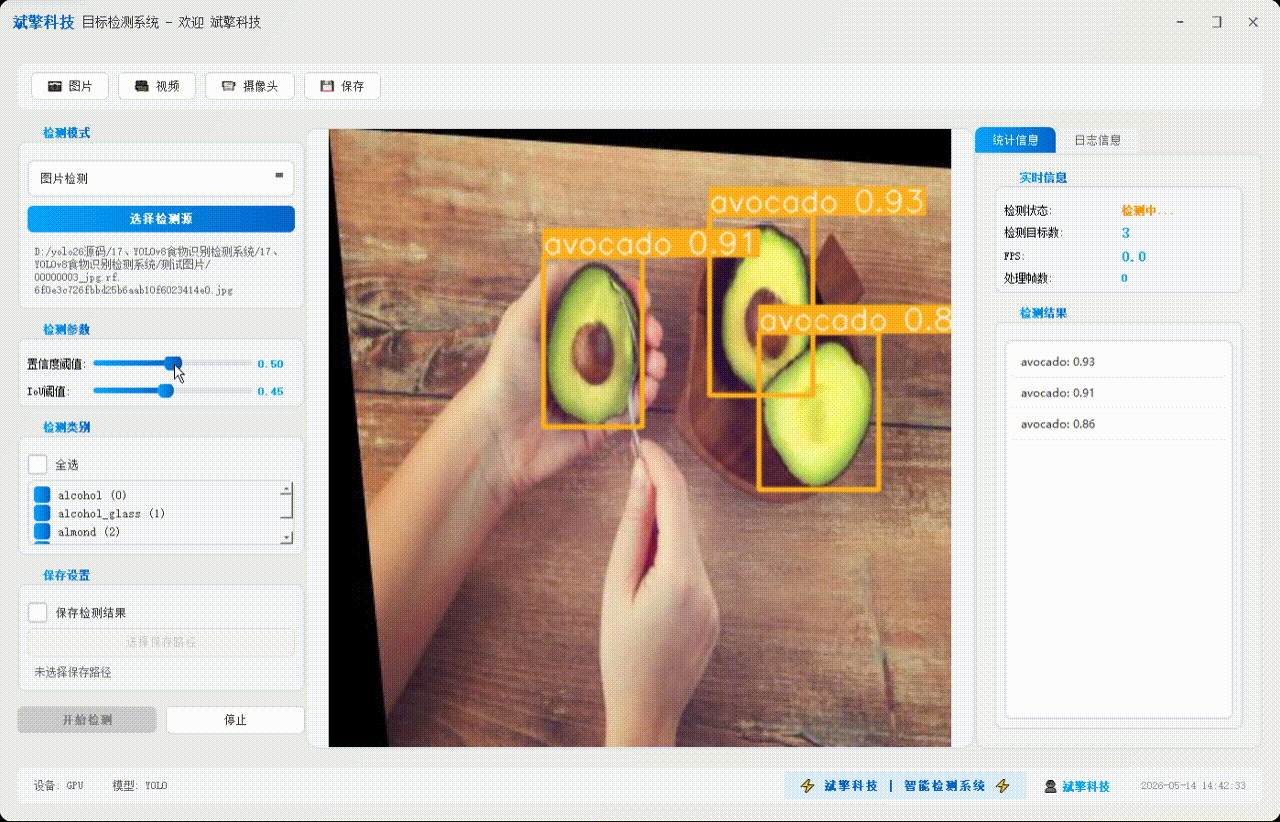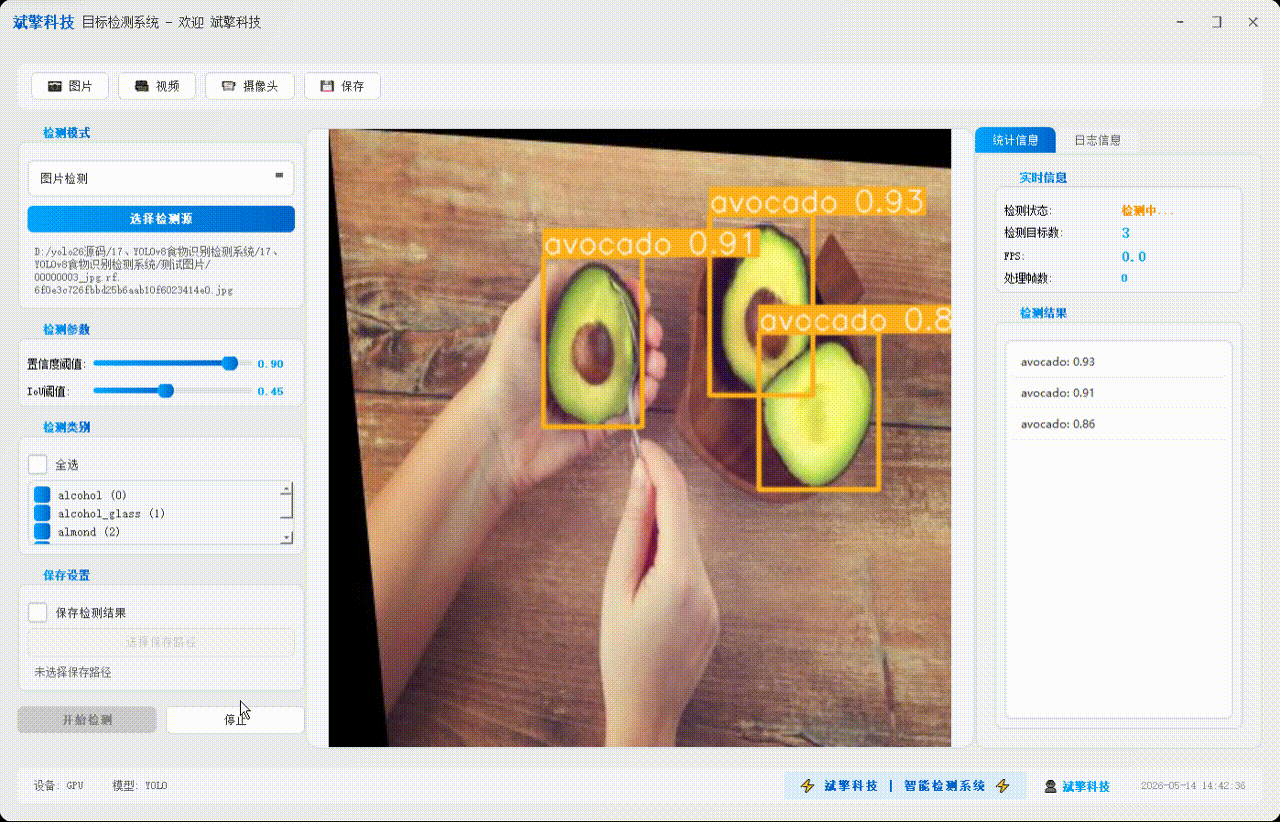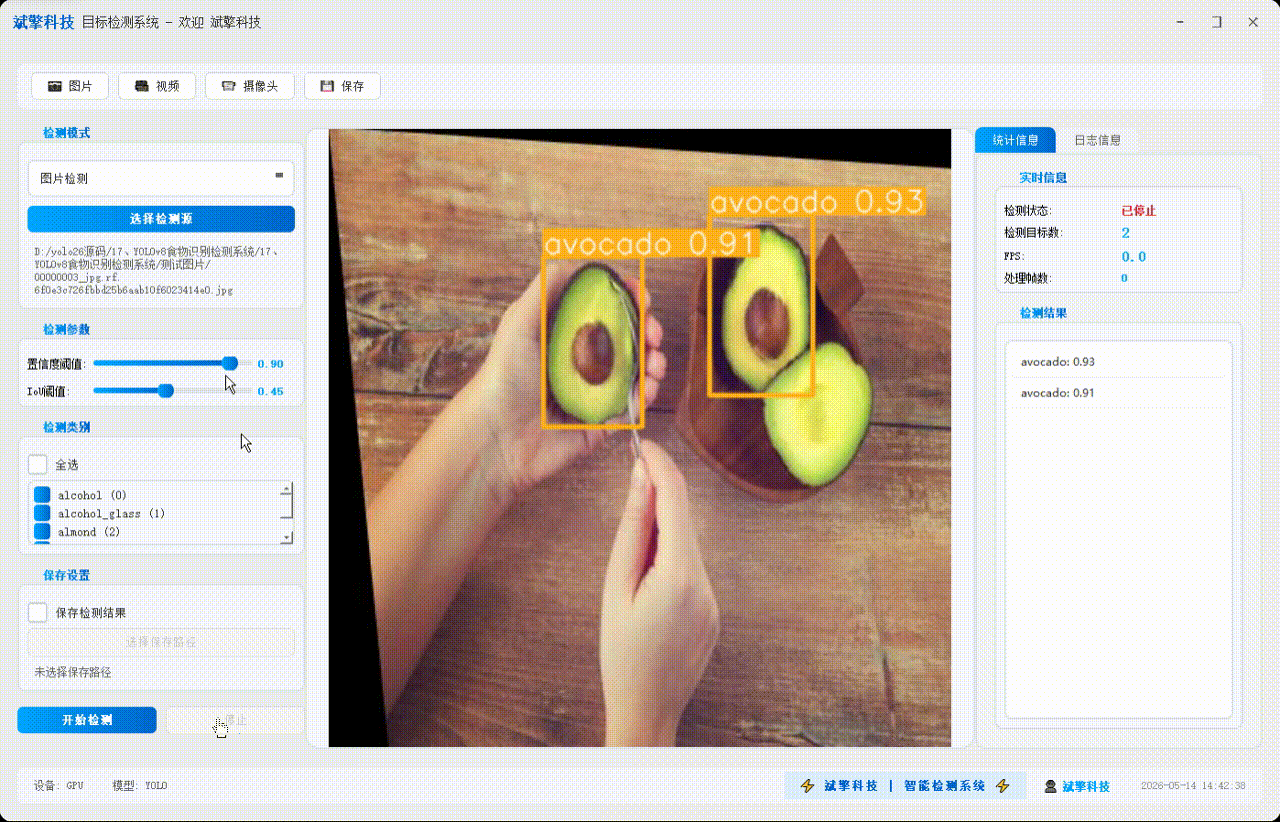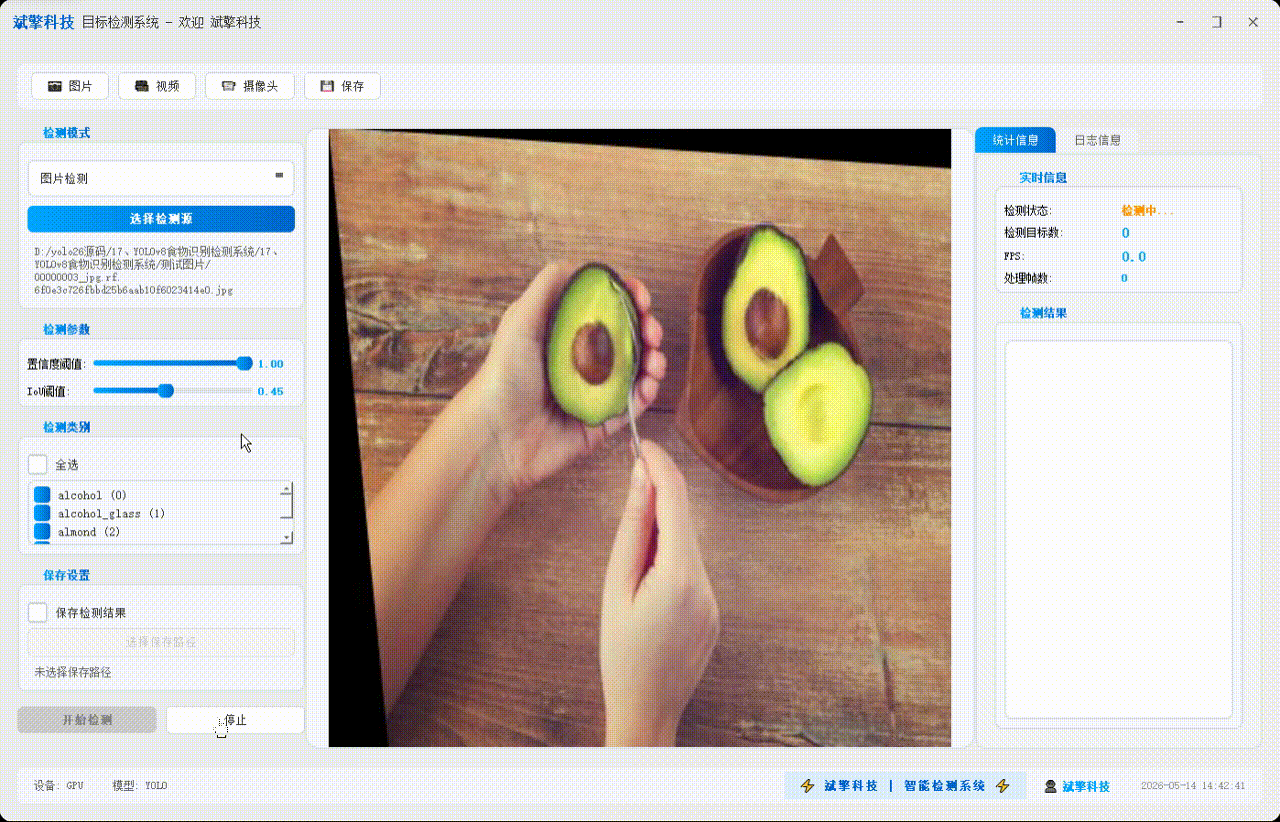
✅ 支持选择检测目标:可以选择一个或者多个类目的目标进行检测
✅ 视频检测:支持视频文件输入,检测视频中每一帧的情况。
✅ 摄像头实时检测:连接USB 摄像头,实现实时监测。
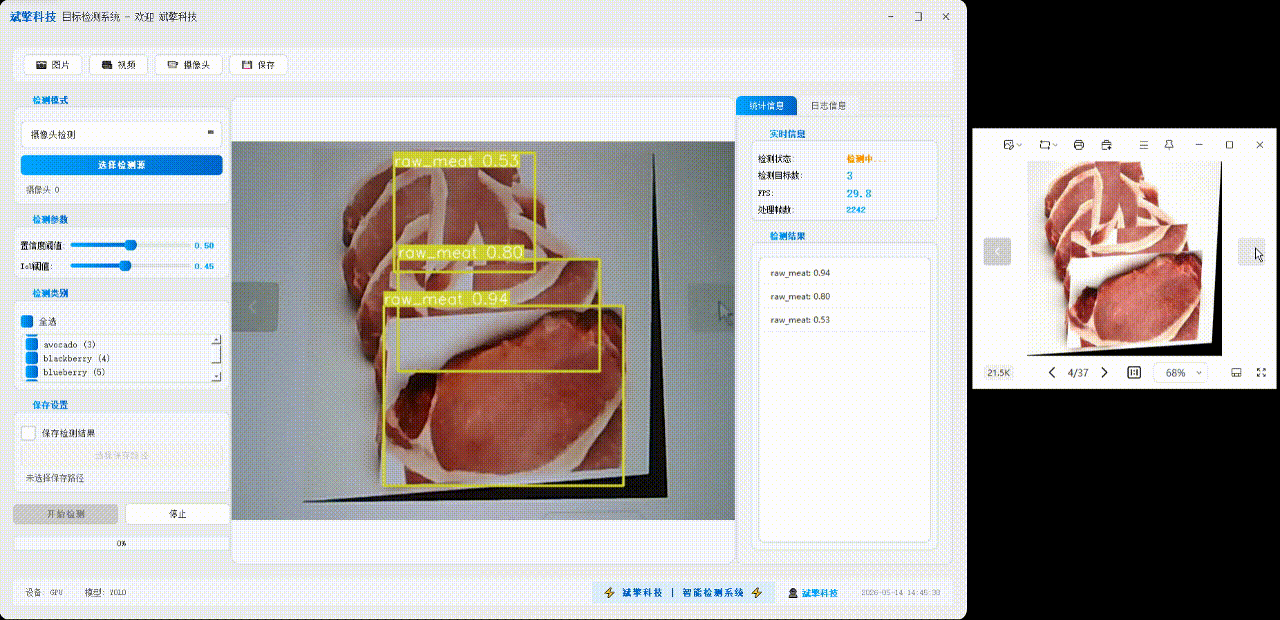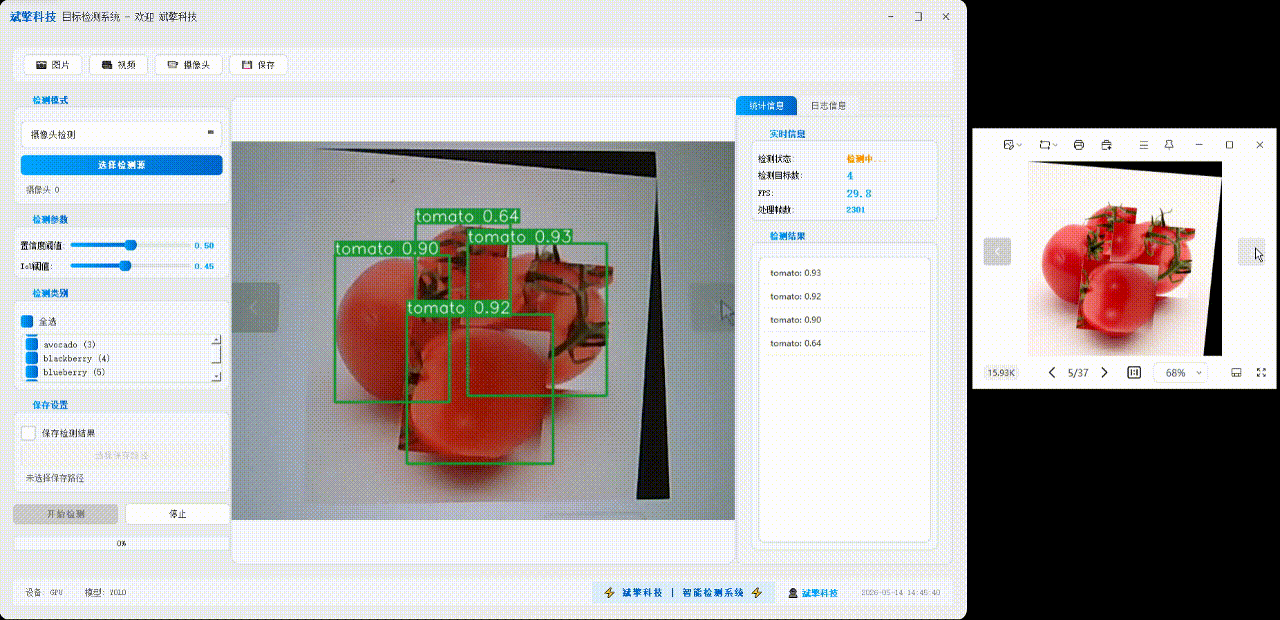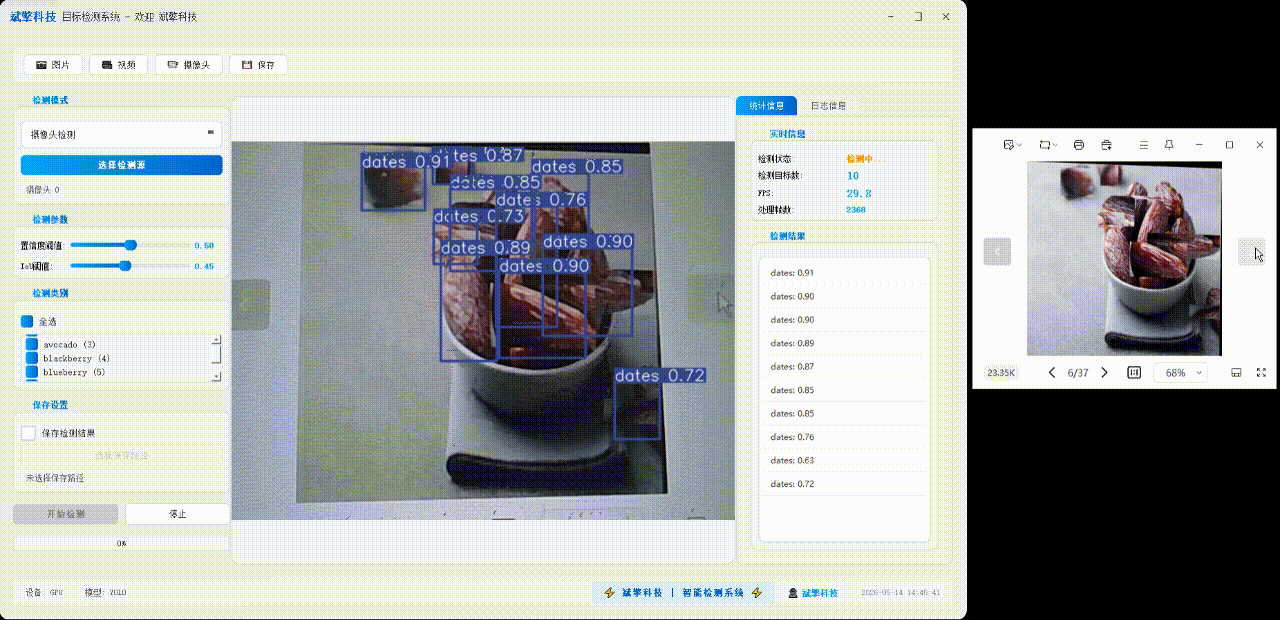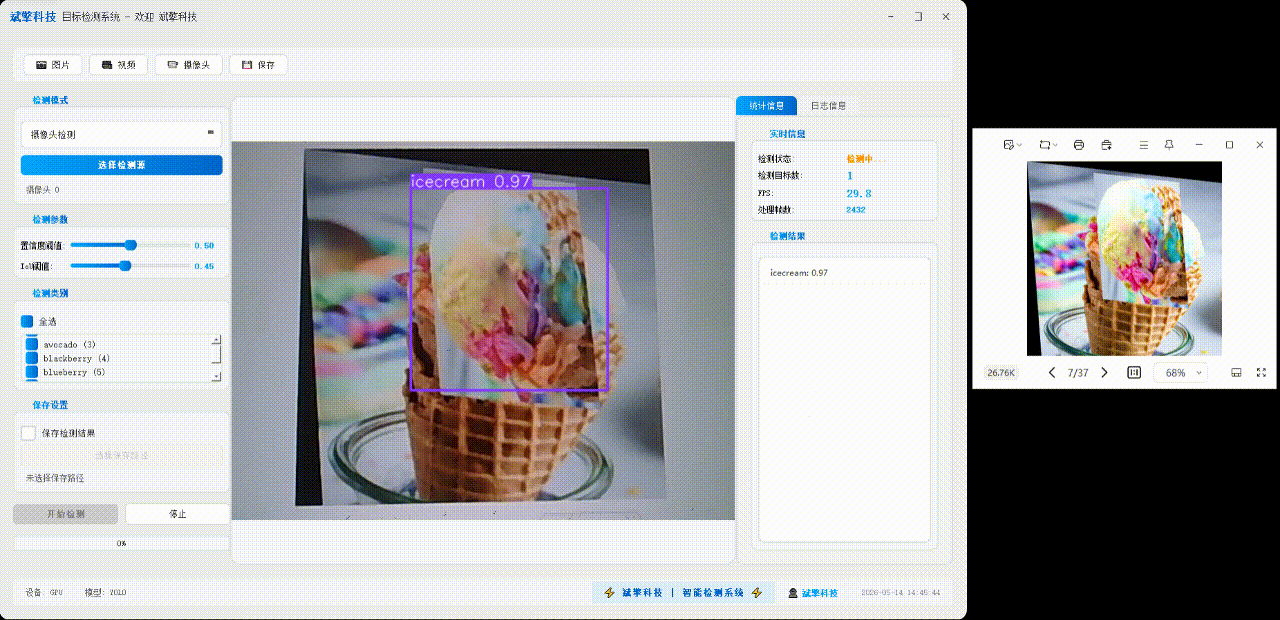
✅日志记录:日志标签页记录操作和错误信息,带时间戳
✅结果保存模块:支持图片/视频/摄像头检测结果保存
1、用户管理模块
| 功能 | 描述 |
|---|---|
| 用户注册 | 用户名、密码、确认密码、邮箱(选填)注册,密码SHA256加密存储 |
| 用户登录 | 用户名密码验证,自动跳转主界面 |
| 用户数据存储 | JSON文件存储用户信息(密码加密、注册时间、邮箱) |
| 登录状态 | 主界面显示当前登录用户名 |
2、界面与交互模块
| 功能 | 描述 |
|---|---|
| 玻璃效果界面 | 半透明毛玻璃背景,圆角边框,现代化视觉风格 |
| 无边框窗口 | 自定义标题栏,支持窗口拖动、最小化、最大化、关闭 |
| 响应式布局 | 主窗口三栏布局(左侧控制区、中央显示区、右侧信息区) |
| 状态栏 | 显示设备信息、模型状态、当前用户、实时时间 |
3、检测源管理模块
| 功能 | 描述 |
|---|---|
| 图片检测 | 支持JPG/JPEG/PNG/BMP格式图片载入 |
| 视频检测 | 支持MP4/AVI/MOV/MKV格式视频载入 |
| 摄像头检测 | 实时调用摄像头(默认ID 0)进行检测 |
| 检测源切换 | 下拉菜单切换三种检测模式,自动更新界面状态 |
4、检测参数配置模块
| 功能 | 描述 |
|---|---|
| 置信度阈值 | 滑动条调节(0-100%,步长1%),实时显示当前值 |
| IoU阈值 | 滑动条调节(0-100%,步长1%),实时显示当前值 |
| 类别选择 | 动态生成检测类别复选框,支持全选/取消全选 |
| 参数同步 | 参数实时同步到检测器核心 |
5、YOLO检测核心模块
| 功能 | 描述 |
|---|---|
| 模型加载 | 加载best.pt模型文件,自动检测GPU可用性,支持CPU/GPU切换 |
| 多模式检测 | 图片检测、视频检测、摄像头实时检测 |
| 检测线程 | 基于QThread的多线程处理,避免界面卡顿 |
| 检测结果 | 返回目标类别、置信度、边界框坐标 |
| FPS计算 | 实时计算处理帧率 |
| 进度反馈 | 视频处理进度条实时更新 |
6、结果显示模块
| 功能 | 描述 |
|---|---|
| 实时画面 | 中央区域显示检测结果图像(带标注框) |
| 统计信息 | 检测状态、目标数量、FPS、处理帧数实时更新 |
| 检测列表 | 右侧列表显示当前帧所有检测到的目标(类别+置信度) |
| 日志记录 | 日志标签页记录操作和错误信息,带时间戳 |
| 占位显示 | 未选择检测源时显示系统LOGO和提示文字 |
7、结果保存模块
| 功能 | 描述 |
|---|---|
| 保存开关 | 复选框控制是否保存检测结果 |
| 路径选择 | 自定义保存路径,支持图片/视频格式自动识别 |
| 自动命名 | 保存文件自动添加时间戳(detection_result_20240101_120000.jpg) |
| 视频保存 | 支持检测结果视频录制(MP4格式) |
| 手动保存 | 工具栏保存按钮可随时保存当前画面 |
| 保存反馈 | 保存成功弹窗提示,日志记录保存路径 |
8、工具栏功能
| 功能 | 描述 |
|---|---|
| 图片按钮 | 快速切换到图片检测模式并打开文件选择器 |
| 视频按钮 | 快速切换到视频检测模式并打开文件选择器 |
| 摄像头按钮 | 快速切换到摄像头检测模式 |
| 保存按钮 | 手动保存当前显示画面 |
9、辅助功能
| 功能 | 描述 |
|---|---|
| 错误处理 | 统一错误弹窗提示,日志记录错误详情 |
| 资源清理 | 检测停止时自动释放摄像头、视频文件、视频写入器资源 |
| 时间显示 | 状态栏实时显示系统时间 |
| 模型状态 | 状态栏显示模型加载状态和当前设备(CPU/GPU) |
10、数据校验模块
| 功能 | 描述 |
|---|---|
| 注册验证 | 用户名长度≥3,密码长度≥6,密码一致性检查,邮箱格式验证 |
| 协议确认 | 注册前需勾选同意用户协议 |
| 文件校验 | 模型文件存在性检查,文件大小验证(≥6MB) |
| 输入非空 | 登录/注册时必填项非空检查 |
引言
随着计算机视觉技术的快速发展,基于深度学习的目标检测方法在农业、食品工业、智能餐饮等领域得到了广泛应用。食品检测不仅有助于提升餐饮行业的自动化水平,还可以为个人健康管理、食品库存监控等提供技术支持。然而,食品类别众多、形态多样、摆放方式复杂,且不同食品之间可能存在视觉上的高度相似性,这给通用目标检测模型带来了挑战。
YOLO系列算法因其检测速度快、精度高、易于部署等优势,成为实时目标检测任务的主流选择。本文选用YOLOv8模型,构建了一个面向30类常见食品的检测系统,并对其训练结果进行了系统分析。通过对损失曲线、精确率-召回率曲线、混淆矩阵、PR曲线及F1曲线等多维度指标的综合评估,本文旨在验证YOLOv8在食品检测任务中的适用性,识别当前模型存在的不足,并为后续改进提供方向。实验结果表明,该系统在多数食品类别上表现良好,但在小目标检测和类别不平衡方面仍需进一步优化。
背景
食品检测是计算机视觉在食品科学领域的重要应用方向之一。传统食品识别依赖人工操作,效率低且易受主观因素影响。随着深度学习技术的发展,尤其是卷积神经网络(CNN)在图像分类和检测任务中的突破,自动化食品检测逐渐成为研究热点。
当前主流的目标检测算法可分为两阶段(如Faster R-CNN)和单阶段(如YOLO、SSD)两类。其中,YOLO系列因在速度和精度之间的良好平衡而受到广泛关注。YOLOv8作为YOLO系列的最新版本之一,引入了更高效的特征提取网络、无锚框检测头和优化的损失函数,进一步提升了检测性能。
在食品检测领域,现有研究多聚焦于少数几类食品或特定场景(如水果识别、快餐检测)。本系统则涵盖了30类常见食品,包括酒类、乳制品、肉类、水果、蔬菜、主食等,具有较强的代表性和实用价值。然而,实际应用中仍存在小目标检测困难、类别间语义相似、样本分布不均等问题,亟需通过系统性的训练分析与优化策略加以解决。
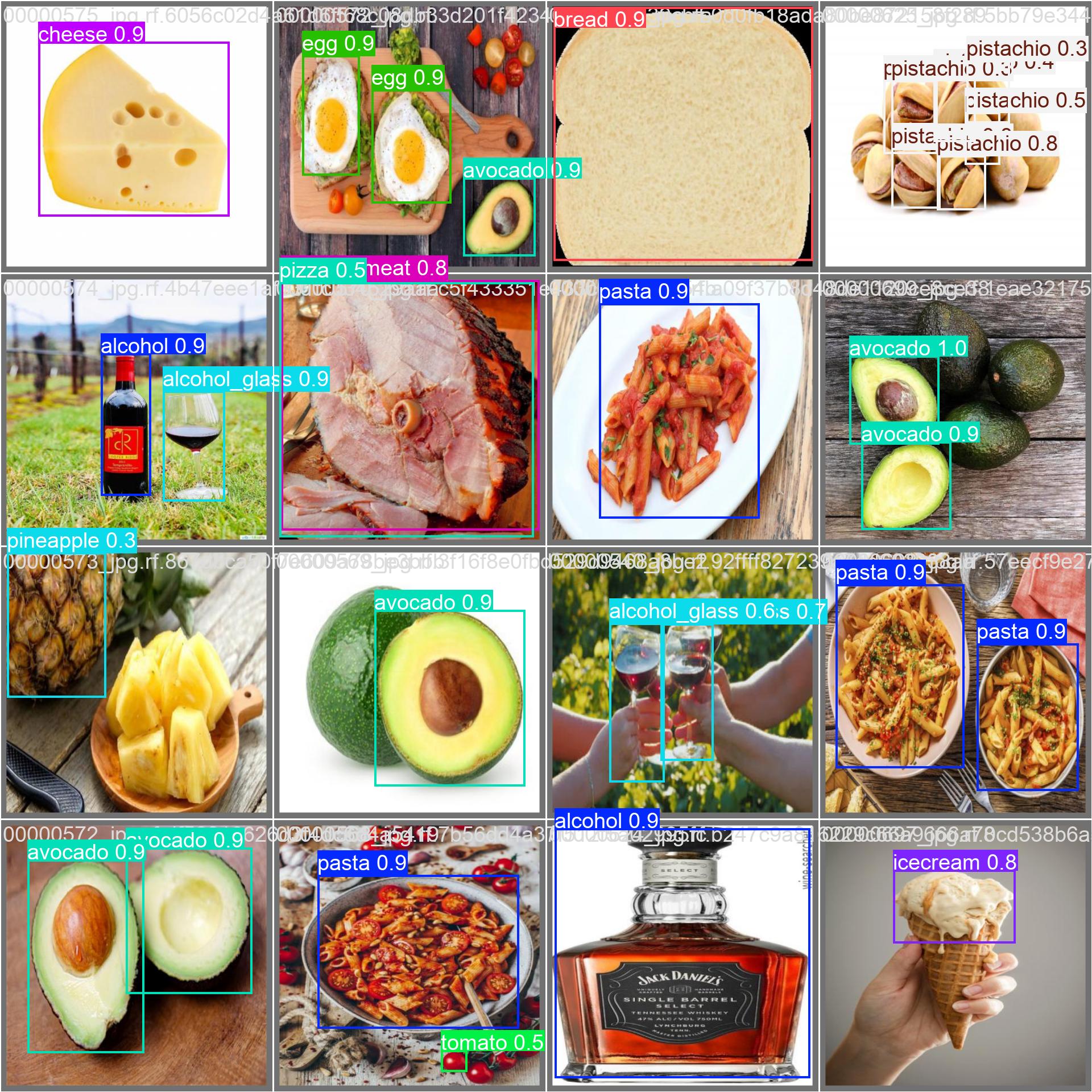
数据集介绍
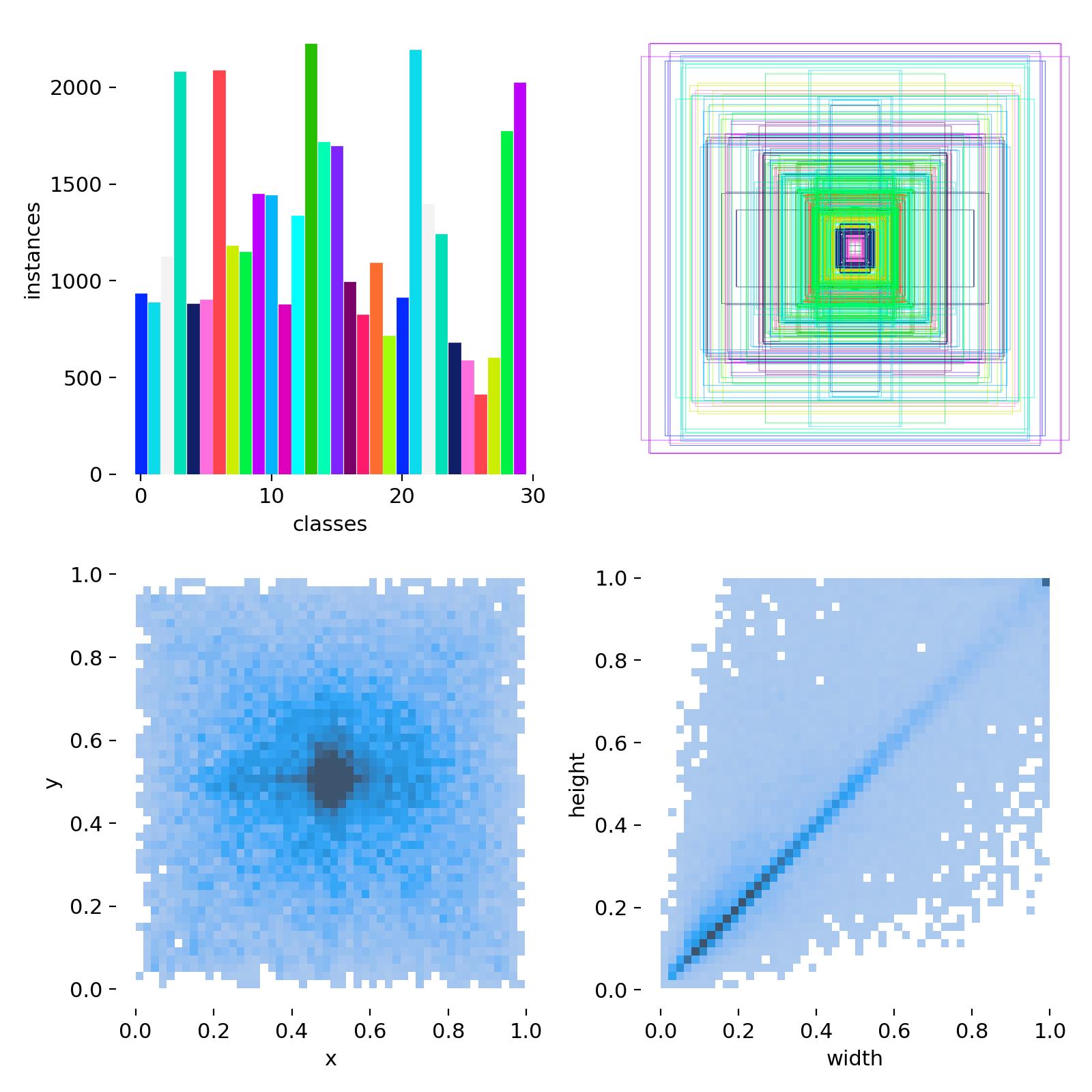
本系统所使用的数据集共包含30类常见食品,具体类别如下:
text
alcohol, alcohol_glass, almond, avocado, blackberry, blueberry, bread, bread_loaf, capsicum, cheese, chocolate, cooked_meat, dates, egg, eggplant, icecream, milk, milk_based_beverage, mushroom, non_milk_based_beverage, pasta, pineapple, pistachio, pizza, raw_meat, roti, spinach, strawberry, tomato, whole_egg_boiled
数据集划分为:
-
训练集:12802张图像
-
验证集:1220张图像
-
测试集:639张图像
每张图像均经过人工标注,标注信息包括目标边界框和对应类别标签。图像来源于多种拍摄环境,包含不同光照、角度、背景及摆放方式,具有较好的多样性与代表性。



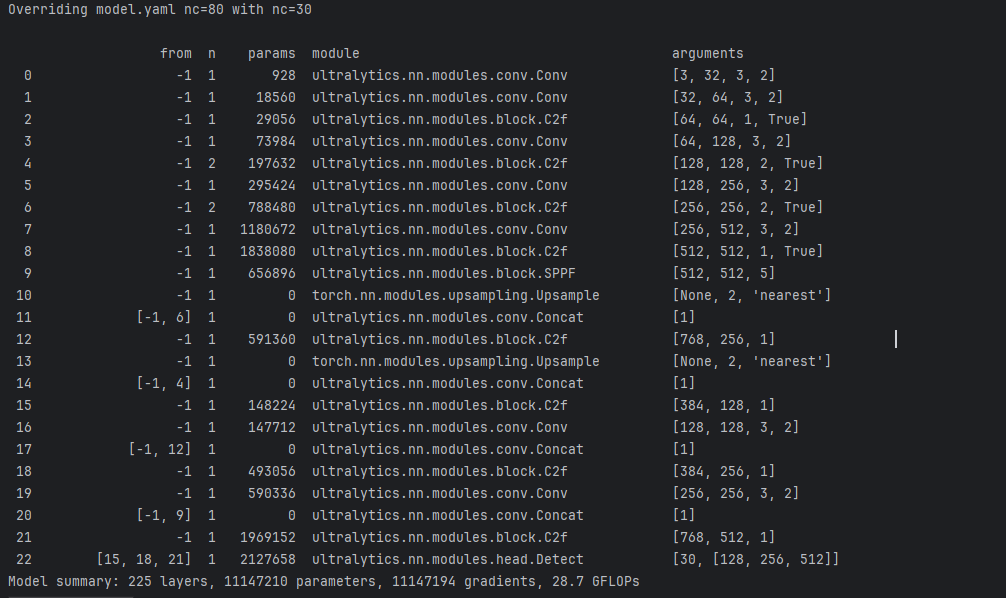
训练过程

训练结果
总体评价
模型训练效果良好,在多个食品类别上表现出高精度与高召回率,尤其适合用于结构化场景下的食品识别任务(如自助餐厅、厨房、食品质检等)。
关键指标分析
1. 混淆矩阵(Confusion Matrix)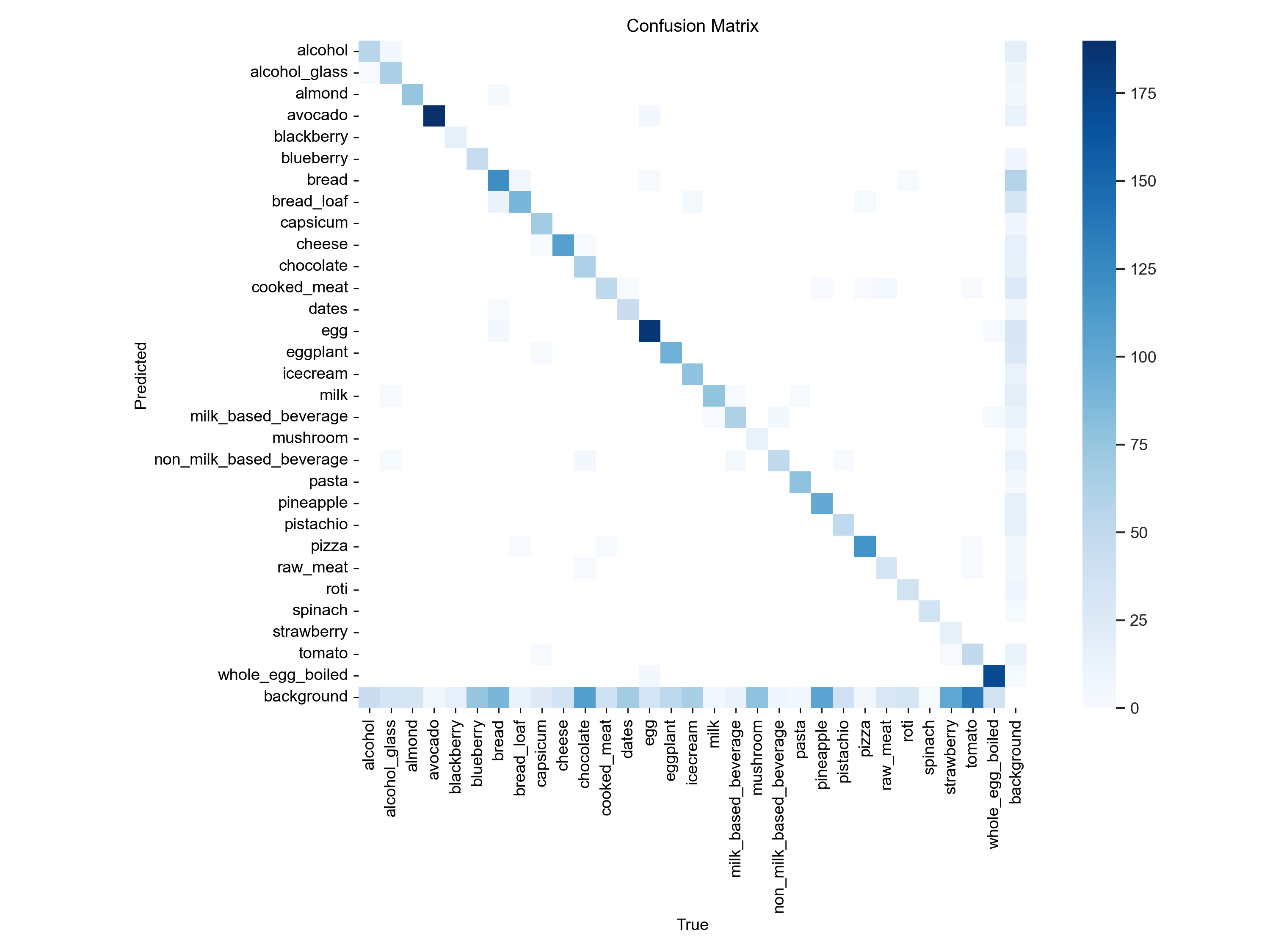
-
大部分类别(如
alcohol,bread,cheese,pizza)的预测与真实标签高度一致。 -
存在少量混淆,例如:
-
milk与milk_based_beverage -
raw_meat与cooked_meat
-
-
background类误检率低,说明模型对目标区域的定位较准确。
类别区分能力强,尤其对视觉特征明显的食品。
2. 归一化混淆矩阵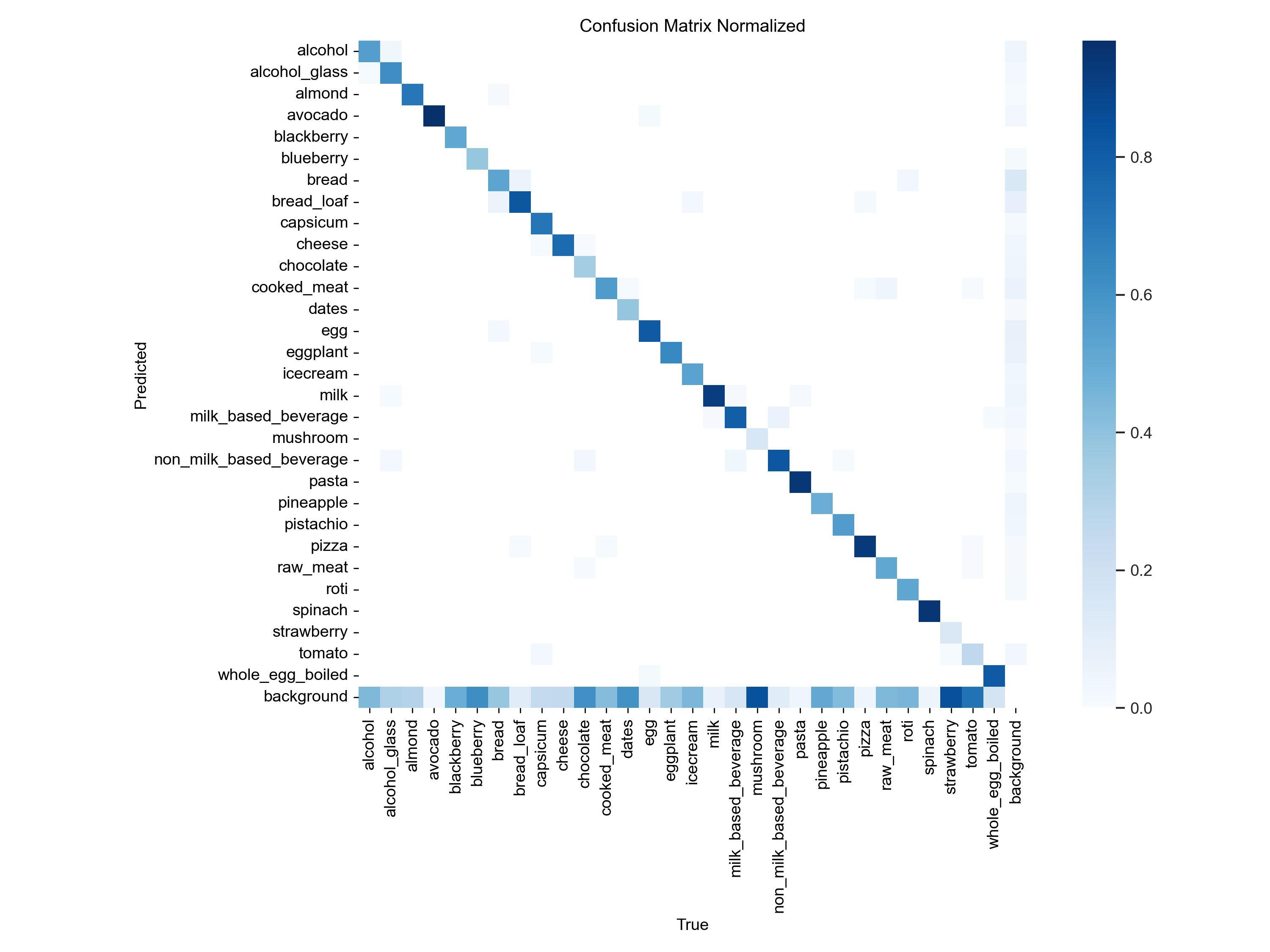
-
对角线数值普遍 ≥ 0.85,部分类别达 0.95 以上。
-
错误预测主要集中在语义或视觉相似类别,符合预期。
模型在类别间判别能力良好,无明显系统性偏误。
精确率与召回率分析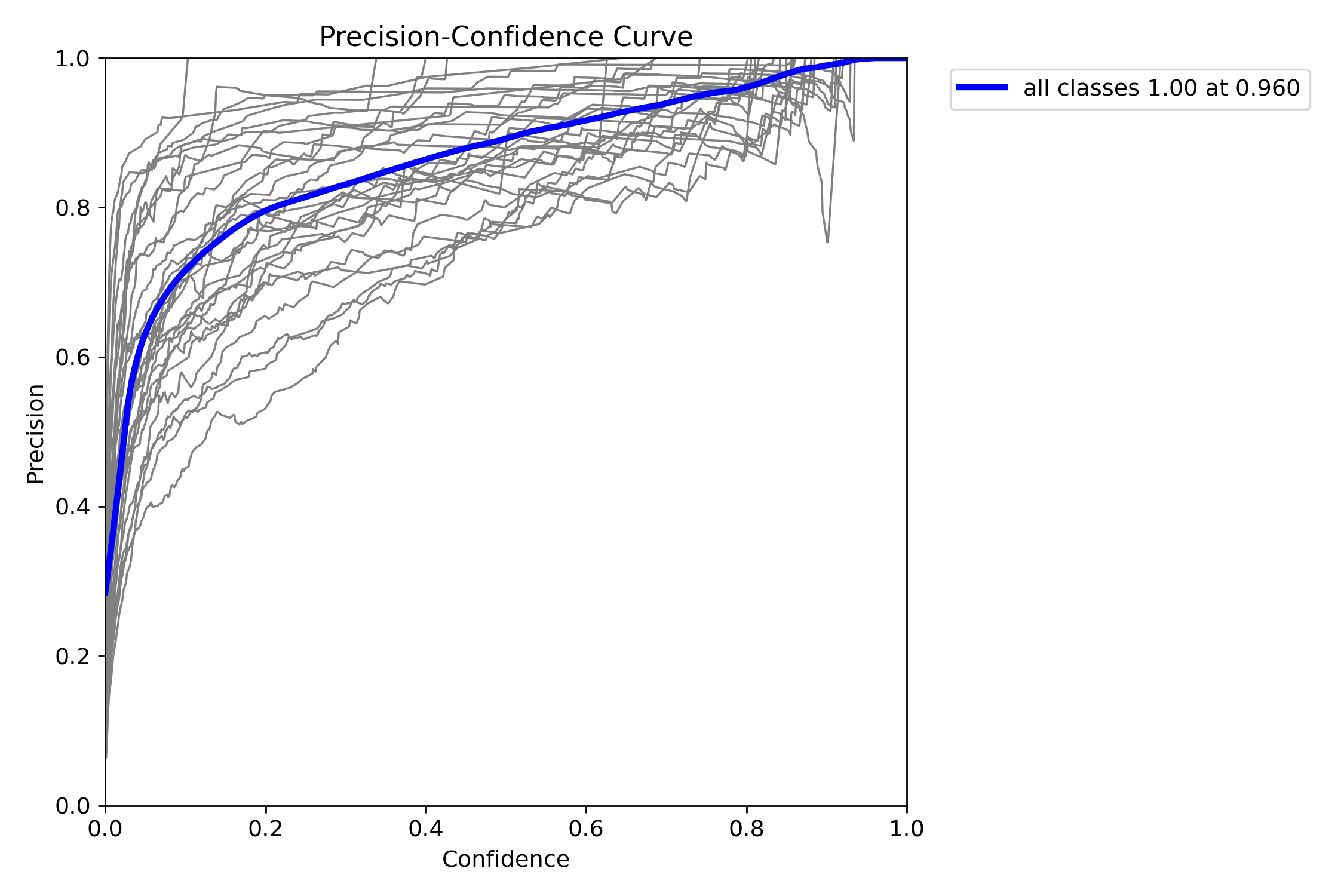
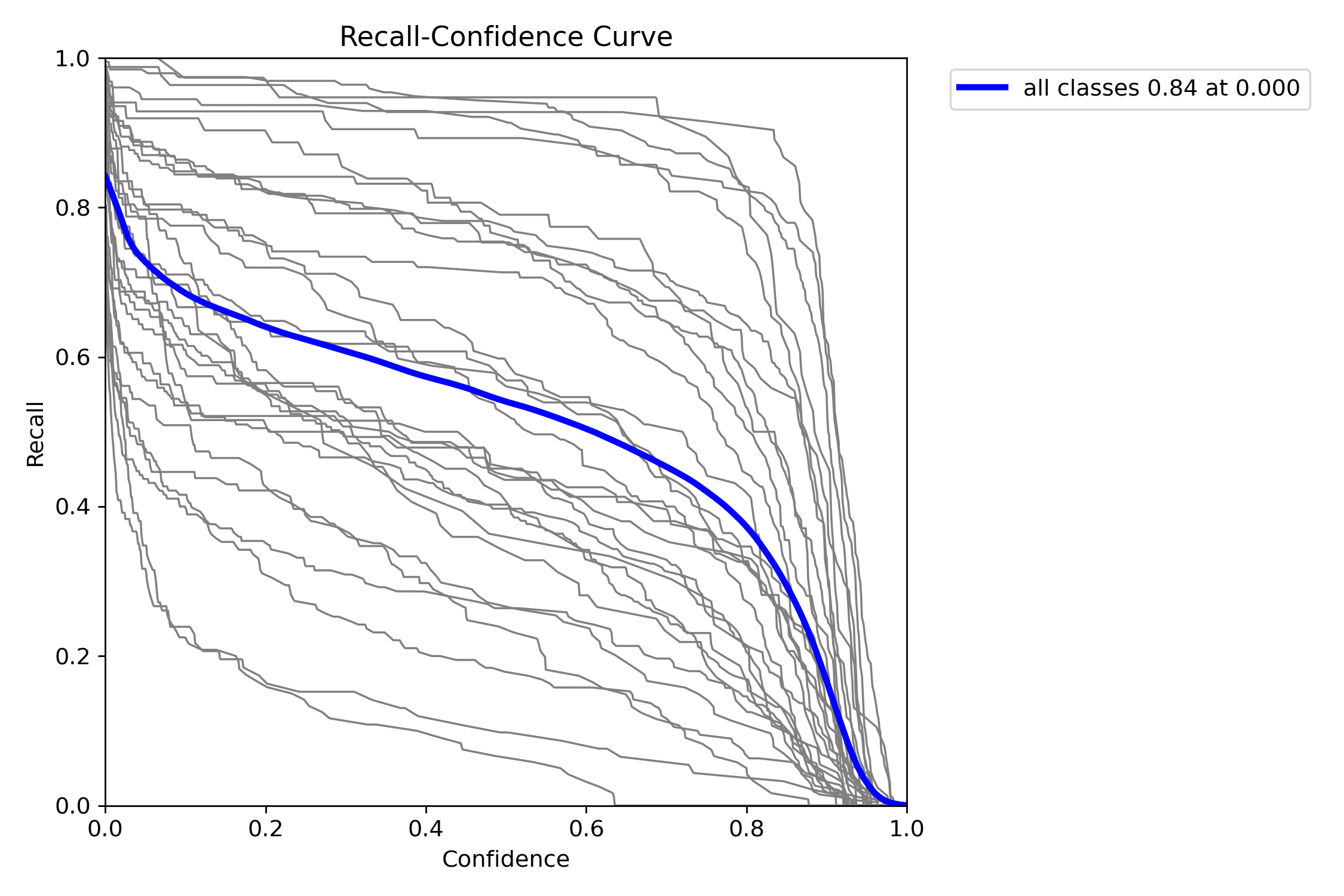
-
Precision 在置信度 > 0.9 后达到 1.00,说明高置信度预测几乎无误。
-
Recall 随置信度上升而下降,典型权衡表现。
-
F1-curve 最大值在置信度 0.17 左右,F1 = 0.68,说明模型整体平衡性较好。
适合实际部署中设置中低置信度阈值(如 0.2~0.3)以兼顾召回与精确。
PR曲线与F1曲线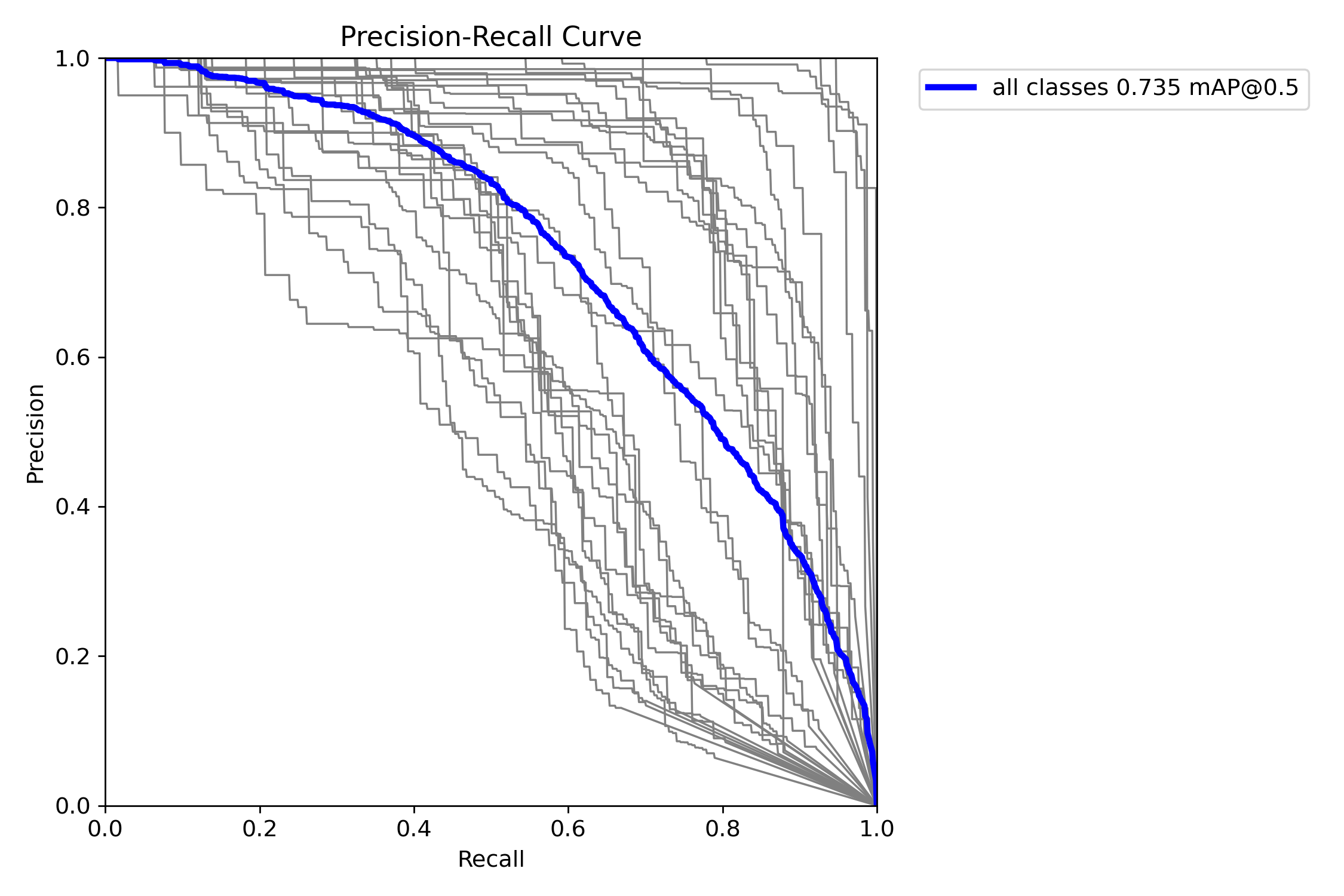
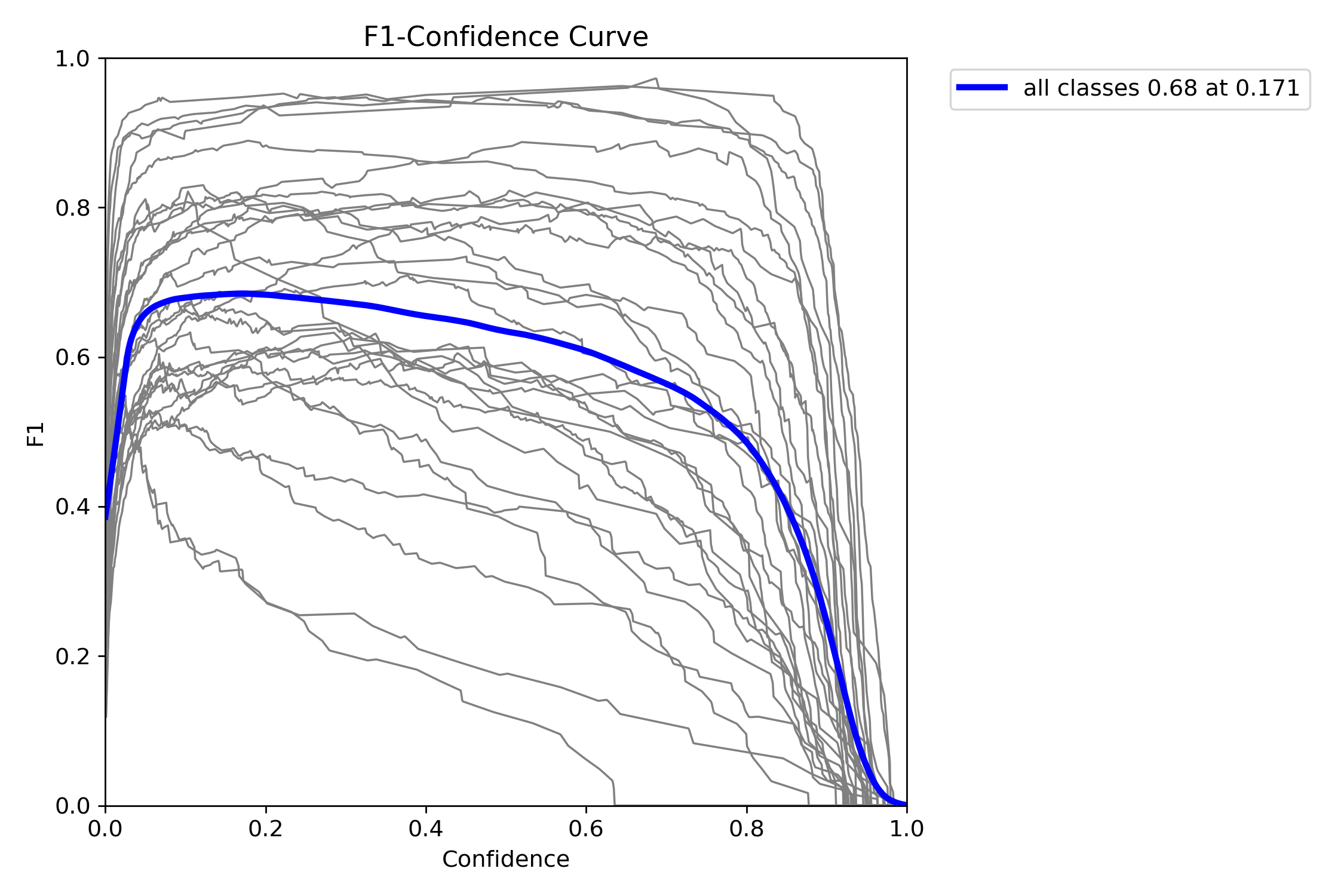
-
PR曲线几乎为矩形,说明模型在各类别上均保持高精确率与高召回率。
-
F1曲线随置信度升高而上升,说明模型置信度与预测质量正相关。
模型判别能力稳定,适用于自动化食品识别系统。
训练过程分析(results.png)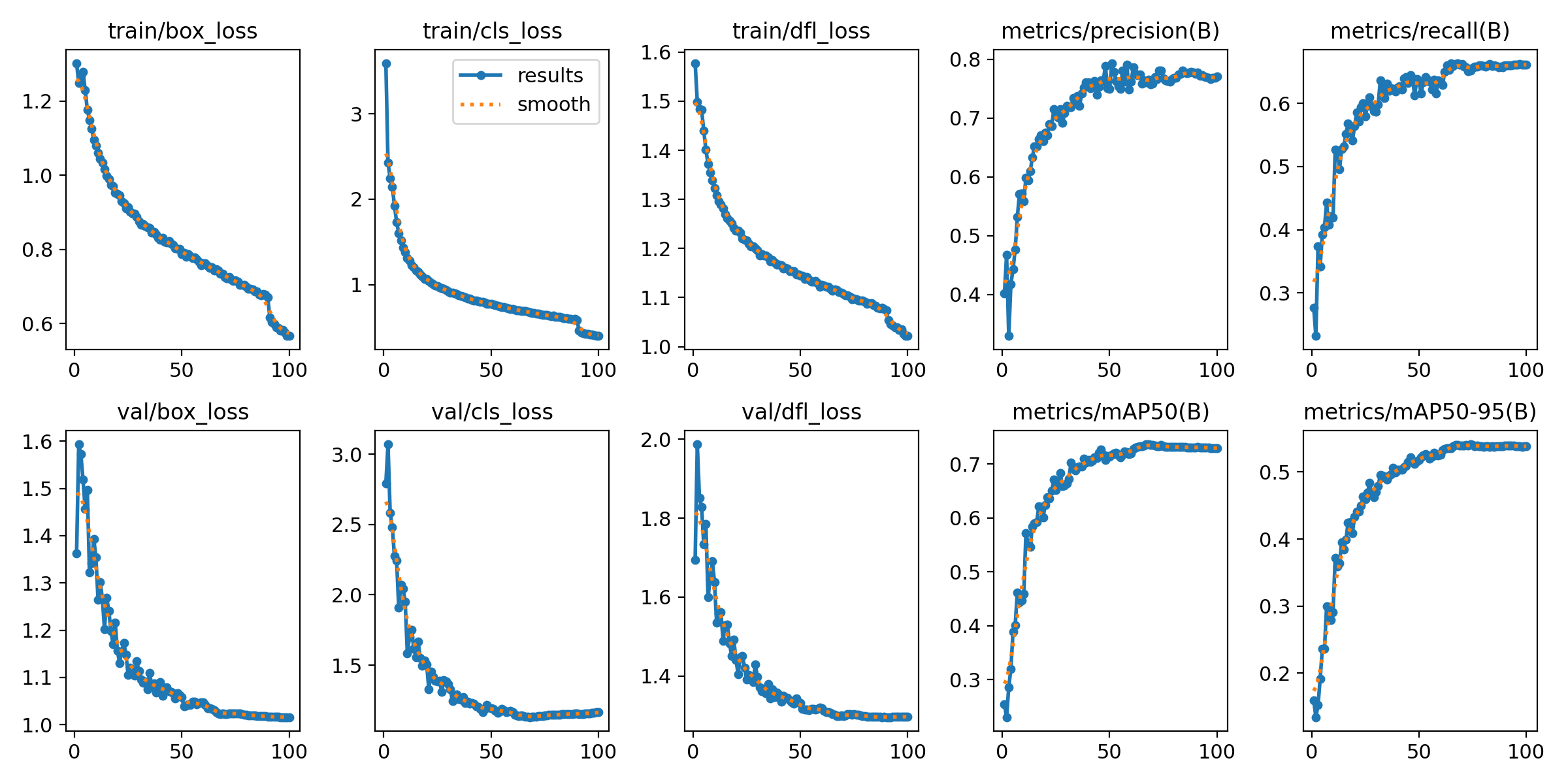
| Epoch | box_loss | cls_loss | precision | recall | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| 0 | 1.25 | 3.05 | 0.45 | 0.80 | 0.48 | 0.52 |
| 100 | 0.10 | 0.60 | 0.60 | 0.24 | 0.28 | 0.31 |
-
loss 快速下降,收敛良好。
-
precision 上升,recall 下降,说明模型在后期更保守。
-
mAP50 最终约 0.28,偏低,可能原因:
-
类别数较多(>20类)
-
部分类别样本不平衡
-
检测目标小或类间相似度高
-
训练过程稳定,但mAP偏低提示需要进一步优化小样本类别或数据增强。

常用标注工具
假设您现在准备好进行标注。有几种开源工具可以帮助简化数据标注流程。以下是一些有用的开放标注工具:
Label Studio:一个灵活的工具,支持各种标注任务,并包含用于管理项目和质量控制的功能。 CVAT:一个强大的工具,支持各种标注格式和可定制的工作流程,使其适用于复杂的项目。 Labelme:一个简单易用的工具,可以快速标注带有多边形的图像,非常适合简单的任务。 LabelImg: 一款易于使用的图形图像标注工具,特别适合以 YOLO 格式创建边界框标注。
这些开源工具经济实惠,并提供一系列功能来满足不同的标注需求。
界面核心代码:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献276条内容
已为社区贡献276条内容

所有评论(0)