智能调度新纪元:vLLMSemanticRouter如何优化大模型应用
大模型应用面临成本高、资源紧张等痛点,传统方式无法理解语义。于是我们调研到了vLLM Semantic Router,作为语义驱动的智能调度系统,通过理解用户输入语义,自动将请求分配给最合适的下游模型,实现成本优化与效率提升。
本文将带大家了解其原理与应用。
一、为什么要讲“语义路由器”
随着我们在项目中越来越多地接入大语言模型(LLM),大家会发现一个问题:
每个模型都有自己的“个性”。
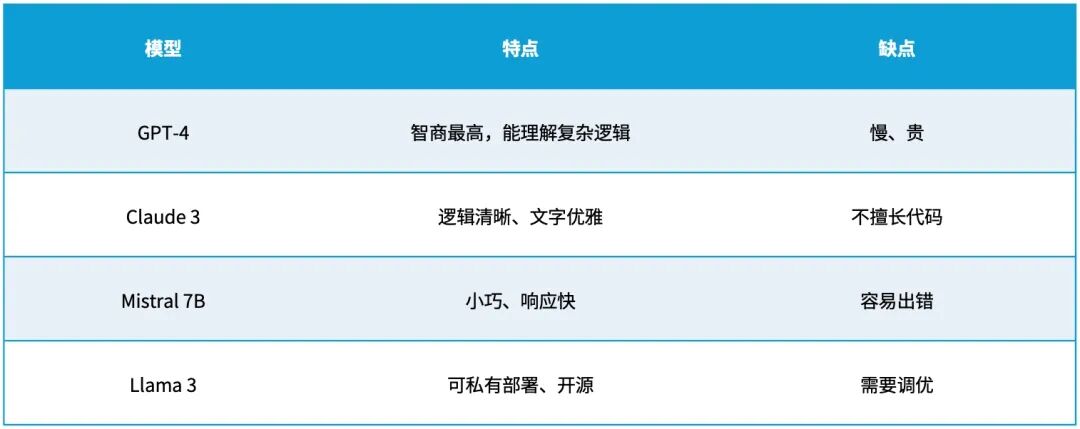
当系统面对成千上万条用户请求时,如果所有请求都打到 GPT-4,就会造成:
· 成本爆炸
· 延迟上升
· GPU 资源被挤爆
于是人们开始思考:
能不能像“操作系统调度CPU”一样,自动调度模型?
这就诞生了 —— vLLM Semantic Router。
二、它到底是什么?
它是一个“语义驱动的模型路由系统”,用一句话可以概括为:
让 AI 自己决定用哪个“AI大脑”来回答问题。
传统系统的路由方式通常基于规则,比如:
· URL 以 /api 开头 → 发给后端接口;
· URL 以 /static 开头 → 发给静态资源服务器。
但在大模型场景中,输入是自然语言,比如
“帮我生成一个SQL查询”
“解释一下Transformer的原理”
“把这段话翻译成英文”
这些输入没有固定格式。要知道“它属于哪种任务”,需要理解语义。
vLLM Semantic Router 就是基于“语义理解”来做路由的:
· 它会先用一个轻量的模型或 embedding(向量化模型)分析输入;
· 理解这段话在语义空间中属于哪一类;
· 然后把请求分配给最合适的下游模型(或Agent)。
这就是“Semantic Routing(语义路由)”的核心思想。
三、从传统架构到“智能调度”架构
1. 传统架构

缺点:
· 简单查询成本高
· 专业任务的次优性能
· 资源利用率低
· 型号选择没有灵活性
2. 智能调度架构(vLLM Semantic Router)
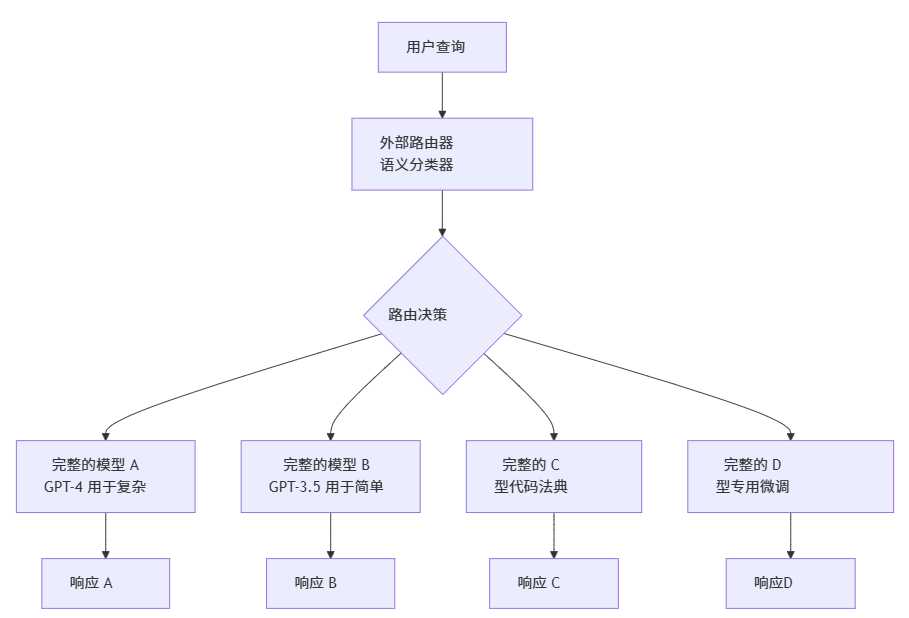
优势:
· 灵活性:可以混合不同的模型架构、大小和提供商
· 成本优化:仅在必要时使用昂贵的模型
· 专业化:利用针对特定领域的专用模型
· 可扩展性:添加新模型,无需重新训练现有模型
· 提供商多样性:结合来自不同提供商的模型(OpenAI、Anthropic、本地模型)
四、架构全景图
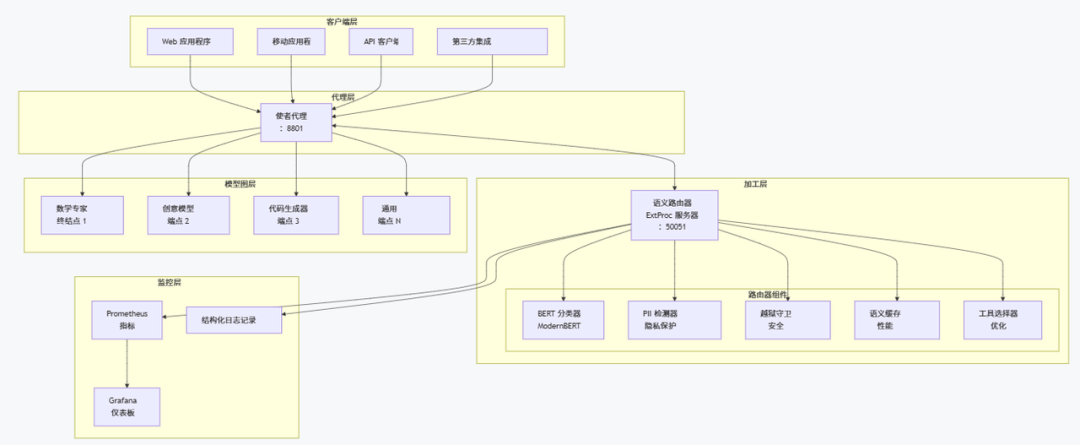
五、核心模块详解
1. 意图识别
目标: 判断用户请求的语义类型与复杂度。
实现方式:
-
使用 ModernBERT / MiniLM 等轻量级模型提取 embedding;
-
通过一个多分类器(IntentClassifier)判断任务类型,如:
-
问答类(Q&A)
-
翻译类
-
代码生成类
-
逻辑推理类
-
闲聊类
-
在实际部署中,vLLM Semantic Router 会将这个分类器常驻内存(常在CPU上运行),延迟仅为 1–2ms。
2. 语义缓存
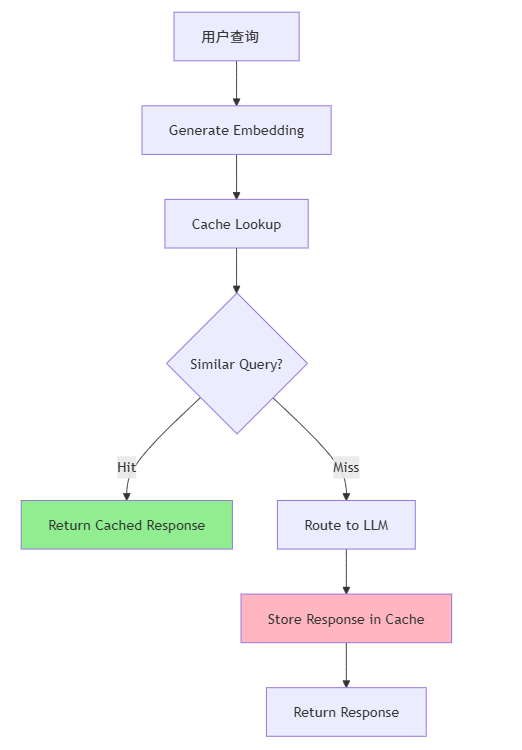
目标: 避免重复推理,提高响应速度。
实现方式:
-
对请求文本做 embedding;
-
查询向量数据库(如 Milvus)中是否有语义相似的请求;
-
若相似度超过阈值(如 0.9),直接返回缓存结果;
-
否则,将结果写入缓存。
简化逻辑:
vector = get_embedding(request_text)
similar = milvus.query(vector, top_k=1)
if similar.score > 0.9:
return similar.cached_response
else:
result = call_model()
milvus.insert(vector, result)📦 Milvus/Redis向量索引 可以支持上百万条缓存数据,查询延迟 <10ms。
3. 模型选择策略引擎
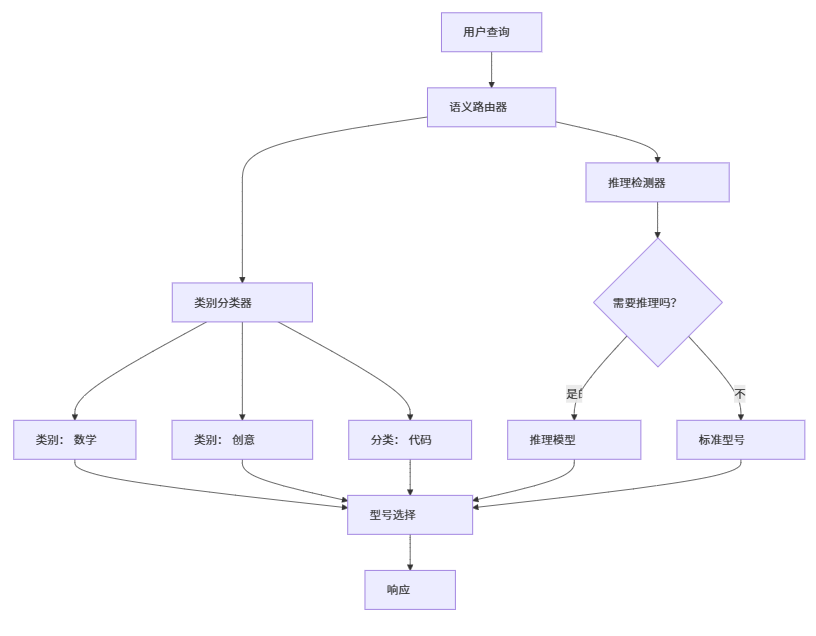
目标: 动态选择最优模型。
主要决策因子:

策略示例:
# 分类模型定义
classifier:
category_model:
model_id: "models/category_classifier_modernbert-base_model"
use_modernbert: true
threshold: 0.6
use_cpu: true
category_mapping_path: "models/category_classifier_modernbert-base_model/category_mapping.json"
# vLLM 模型端点配置
vllm_endpoints:
- name: "endpoint1"
address:"127.0.0.1"
port:8000
models: ["deepseek-v31", "qwen3-30b", "openai/gpt-oss-20b"] # Must match --served-model-name
weight:1
# 推理家族配置
reasoning_families:
deepseek:
type: "chat_template_kwargs"
parameter: "thinking"
qwen3:
type: "chat_template_kwargs"
parameter: "enable_thinking"
gpt-oss:
type: "reasoning_effort"
parameter: "reasoning_effort"
gpt:
type: "reasoning_effort"
parameter: "reasoning_effort"
# 默认推理强度
default_reasoning_effort: medium # low | medium | high
# 模型映射关系
model_config:
"deepseek-v31":
reasoning_family: "deepseek"
preferred_endpoints: ["endpoint1"]
"qwen3-30b":
reasoning_family: "qwen3"
preferred_endpoints: ["endpoint1"]
"openai/gpt-oss-20b":
reasoning_family: "gpt-oss"
preferred_endpoints: ["endpoint1"]
# 类别定义与模型优先级
categories:
- name: math
use_reasoning: true
reasoning_effort: high # overrides default_reasoning_effort
reasoning_description: "Mathematical problems require step-by-step reasoning"
model_scores:
- model: openai/gpt-oss-20b
score: 1.0
- model: deepseek-v31
score: 0.8
- model: qwen3-30b
score: 0.8
# 默认模型
default_model: qwen3-30b这些策略可以在 config/config.yaml 文件中配置, 在生产环境中甚至可以与 Prometheus 指标联动动态调整。
4. 安全检查
在企业部署中,安全是第一优先。
vLLM Semantic Router 自带以下机制:
-
PII 检测:识别是否包含手机号、身份证、邮件等敏感信息;
-
越狱保护:检测并阻止对抗性提示和提示注入(如“忽略之前的指令”);
主要特点:
-
实时保护:在请求到达 LLM 端点之前对其进行分析
-
特定于模型的策略:为不同的模型配置不同的 PII 策略
-
自动过滤:过滤掉不符合安全要求的模型
-
全面日志记录:所有安全决策的完整审计跟踪
-
可观测与监控(Observability)
5. 可观测与监控(Observability)
系统输出以下指标:
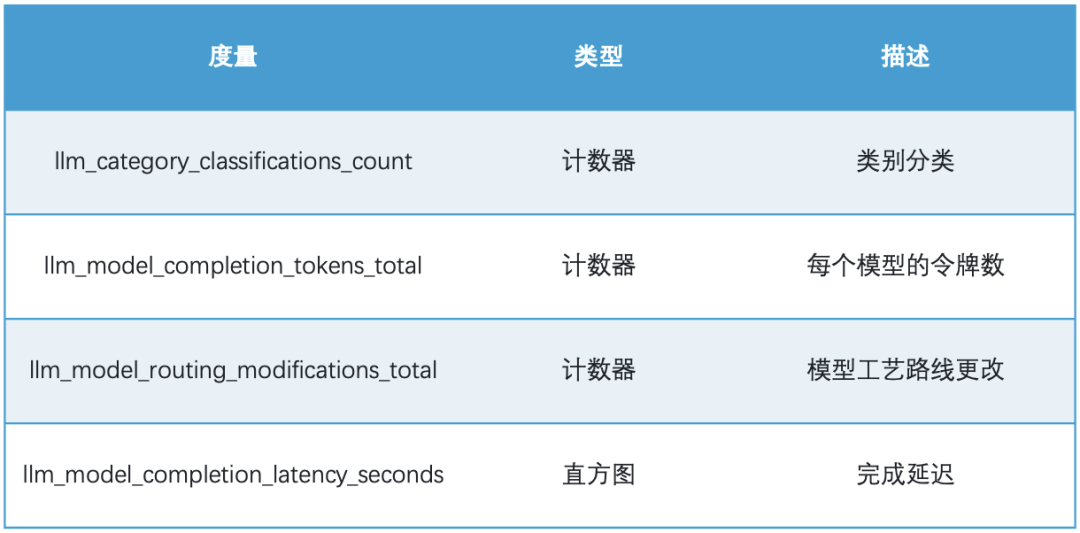
这些数据可以在 Grafana + Prometheus 中可视化展示。
主要特点:
-
Prometheus 集成:公开端口 9190 上的详细指标
-
运行状况终结点:服务和依赖项运行状况监视
-
预构建仪表板:满足常见监控需求的 Grafana 仪表板
-
结构化日志记录:JSON 格式的日志,便于分析
六、性能表现
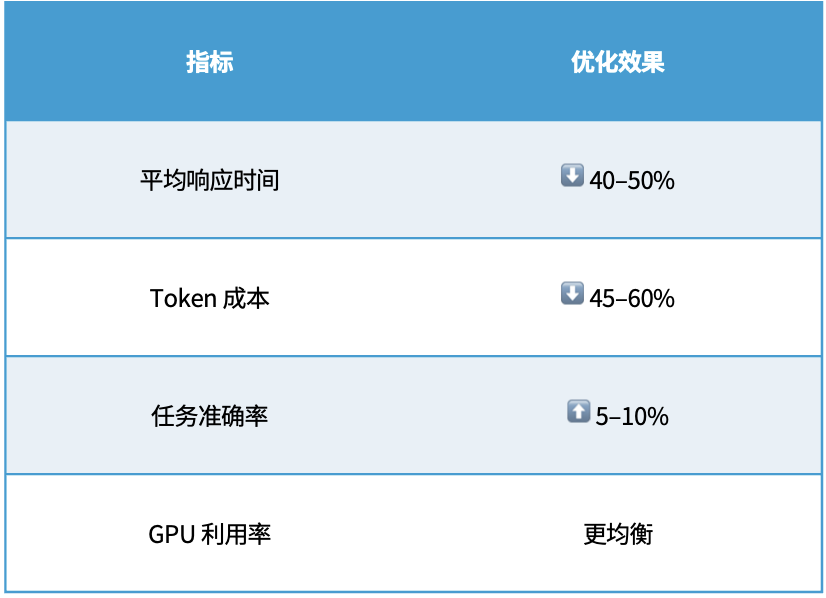
七、部署与应用场景
1. 部署方式
-
Docker Compose 部署:官方提供 Docker 镜像;
-
Kubernetes 部署:可在集群中作为独立服务运行;
-
本地编译部署:编译代码部署。
2. 典型应用
-
企业内部智能客服:根据问题复杂度自动切换模型;
-
多语言内容生成平台:根据语言选择不同LLM;
-
研发问答系统:代码类请求走专用模型;
-
知识问答(RAG)系统:在路由阶段判断是否需要查询数据库。
八、发展趋势与思考
vLLM Semantic Router 背后的理念其实代表了下一代AI系统架构方向:
“从单模型智能 → 到多模型协作。”
未来,AI 系统不再依赖一个“大脑”,而是由多个专长模型组成一个“专家团队”,语义路由器就是这个团队的“调度官”。
这与人类社会非常像:不同专家解决不同问题,而语义路由器负责分工与协调。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)