Java 程序员第 11 阶段:主流向量库对比落地:Milvus、ES、FAISS 选型实战
一、为什么向量库是 RAG 的性能瓶颈?
当我们构建 RAG 系统时,常见的架构是:
用户问题 → Embedding模型 → 向量化 → 向量库检索 → Top-K 相关文档 → LLM生成答案
在这个链路中,**向量库检索**是决定 RAG 质量的关键环节:
|
指标 |
差的表现 |
好的表现 |
|
召回率 |
检索结果与问题不相关 |
精准召回高度相关内容 |
|
延迟 |
500ms+,用户体验差 |
<50ms,即时响应 |
|
规模 |
百万向量后性能退化 |
亿级向量依然稳定 |
|
成本 |
需要高配服务器 |
中等配置即可 |
**踩坑教训**:我们曾用 MySQL 的 JSON 字段存储向量,百万向量搜索耗时 3 秒;切换到专用向量库后,同样的查询只需 25ms。
 二、三大向量库核心对比
二、三大向量库核心对比
2.1 Milvus:企业级分布式向量数据库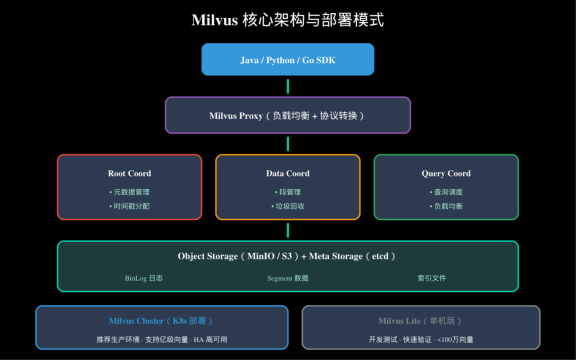
# Docker Compose 快速部署
version: '3.8'
services:
milvus:
image: milvusdb/milvus:v2.3.3
container_name: milvus
ports:
- "19530:19530" # gRPC
- "9091:9091" # HTTP
volumes:
- ./volumes/milvus:/var/lib/milvus
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
networks:
- milvus
**核心优势**:
- ✅ **10亿级向量**:水平扩展,支持分布式部署
- ✅ **多种索引**:HNSW、IVF_PQ、DiskANN 等按需选择
- ✅ **GPU 加速**:HNSW 建库速度提升 10 倍
- ✅ **丰富的 SDK**:Java、Python、Go、Node.js 全覆盖
2.2 Elasticsearch dense_vector:全文+向量混合搜索
// ES 8.x 创建向量字段
PUT /rag_documents
{
"mappings": {
"properties": {
"content": { "type": "text" },
"title": { "type": "text" },
"embedding": {
"type": "dense_vector",
"dims": 1536,
"index": true,
"similarity": "cosine"
}
}
}
}
// 混合检索查询
POST /rag_documents/_search
{
"query": {
"script_score": {
"query": { "match": { "content": "Spring Boot配置" } },
"script": {
"source": "cosineSimilarity(params.queryVector, 'embedding') + 1.0",
"params": { "queryVector": [0.123, -0.456, ...] }
}
}
},
"knn": {
"field": "embedding",
"queryVector": [0.123, -0.456, ...],
"k": 10,
"num_candidates": 100
}
}
**核心优势**:
- ✅ **天然混合搜索**:向量+全文一站式解决
- ✅ **成熟生态**:Kibana 可视化、ELK 监控
- ✅ **运维简单**:已有 ES 集群可直接使用
- ⚠️ **向量规模有限**:建议 <1亿向量
2.3 FAISS:Facebook 开源的向量索引库
import faiss
import numpy as np
# 创建索引 (IVF_PQ)
dimension = 1536
nlist = 100 # 聚类数量
m = 32 # 子空间数量
nbytes = 4 # 每个向量4字节
index = faiss.IndexIVFPQ(
faiss.IndexFlatIP(dimension), # 粗粒度索引
dimension,
nlist,
m,
nbytes
)
# 训练索引
vectors = np.random.randn(100000, dimension).astype('float32')
faiss.normalize_L2(vectors)
index.train(vectors)
index.add(vectors)
# 搜索
query = np.random.randn(1, dimension).astype('float32')
faiss.normalize_L2(query)
distances, indices = index.search(query, k=10)
**核心特点**:
- ✅ **性能极致**:CPU/GPU 多核优化
- ✅ **内存效率**:PQ 压缩可达 10-50 倍
- ✅ **离线批处理首选**:不擅长在线服务
- ⚠️ **纯库非服务**:需要自行封装 HTTP 接口
 三、索引算法选型指南
三、索引算法选型指南
|
算法 |
适用场景 |
内存占用 |
查询速度 |
精度 |
|
**FLAT** |
<100万向量,需要100%精度 |
高 |
慢 |
100% |
|
**HNSW** |
生产环境首选,平衡速度与精度 |
中 |
极快 |
95-99% |
|
**IVF_PQ** |
超大规模,内存受限 |
低 |
快 |
90-95% |
|
**DiskANN** |
十亿级向量,SSD 环境 |
极低 |
中 |
90%+ |
**推荐策略**:
# 小规模 (<100万): FLAT 或 HNSW
# 中等规模 (100万-1亿): HNSW
# 大规模 (>1亿): IVF_PQ + DiskANN
四、Java + Milvus 实战落地
4.1 Spring Boot 集成
<!-- pom.xml -->
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.3.3</version>
</dependency>

4.2 完整 CRUD 代码
@Service
@Slf4j
public class MilvusVectorService {
private final MilvusServiceClient milvusClient;
private final String COLLECTION_NAME = "rag_documents";
private final int DIMENSION = 1536;
public MilvusVectorService() {
this.milvusClient = new MilvusServiceClient(
new Endpoint("localhost", 19530)
);
}
/**
* 创建 Collection
*/
public void createCollection() {
// 删除已存在的 Collection
milvusClient.dropCollection(
DropCollectionParam.newBuilder()
.withCollectionName(COLLECTION_NAME)
.build()
);
// 创建 Collection
milvusClient.createCollection(
CreateCollectionParam.newBuilder()
.withCollectionName(COLLECTION_NAME)
.withDimension(DIMENSION)
.withMetricType(MetricType.Cosine)
.build()
);
// 创建 HNSW 索引
milvusClient.createIndex(
CreateIndexParam.newBuilder()
.withCollectionName(COLLECTION_NAME)
.withFieldName("vector")
.withIndexType(IndexType.HNSW)
.withMetricType(MetricType.Cosine)
.withExtraParam("{\"M\": 16, \"efConstruction\": 200}")
.build()
);
log.info("Collection {} created with HNSW index", COLLECTION_NAME);
}
/**
* 插入向量数据
*/
public void insertVectors(List<String> ids, List<Float> vectors, List<String> texts) {
List<InsertParam.Field> fields = Arrays.asList(
new InsertParam.Field("id", ids),
new InsertParam.Field("vector", vectors),
new InsertParam.Field("text", texts)
);
InsertParam param = InsertParam.newBuilder()
.withCollectionName(COLLECTION_NAME)
.withFields(fields)
.build();
MutationResult result = milvusClient.insert(param);
log.info("Inserted {} vectors", result.getSuccIndexCount());
}
/**
* 向量相似度搜索
*/
public List<SearchResult> searchVectors(List<Float> queryVector, int topK) {
// 归一化向量 (余弦相似度需要)
normalizeVector(queryVector);
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName(COLLECTION_NAME)
.withVectorFieldName("vector")
.withVectors(Collections.singletonList(queryVector))
.withTopK(topK)
.withMetricType(MetricType.Cosine)
.withParams("{\"ef\": 128}")
.build();
SearchResult results = milvusClient.search(searchParam);
List<SearchResult> searchResults = new ArrayList<>();
for (int i = 0; i < results.getRowRecords().size(); i++) {
List<Field> fields = results.getRowRecords().get(i).getFields();
String text = fields.stream()
.filter(f -> "text".equals(f.getName()))
.map(f -> (String) f.getFieldData())
.findFirst()
.orElse("");
Float distance = results.getDistanceRecords().get(i).get(0);
searchResults.add(new SearchResult(text, distance));
}
return searchResults;
}
/**
* 删除 Collection
*/
public void dropCollection() {
milvusClient.dropCollection(
DropCollectionParam.newBuilder()
.withCollectionName(COLLECTION_NAME)
.build()
);
}
/**
* 关闭连接
*/
@PreDestroy
public void close() {
milvusClient.close();
}
private void normalizeVector(List<Float> vector) {
float norm = 0;
for (float v : vector) {
norm += v * v;
}
norm = (float) Math.sqrt(norm);
for (int i = 0; i < vector.size(); i++) {
vector.set(i, vector.get(i) / norm);
}
}
}
4.3 RAG 检索服务
@Service
public class RAGRetrievalService {
@Autowired
private MilvusVectorService milvusService;
@Autowired
private EmbeddingService embeddingService;
@Value("${rag.top_k:5}")
private int topK;
/**
* RAG 检索
*/
public List<检索结果> retrieve(String query) {
// 1. 将查询向量化
List<Float> queryEmbedding = embeddingService.embed(query);
// 2. 向量库检索
List<SearchResult> results = milvusService.searchVectors(queryEmbedding, topK);
// 3. 过滤低相似度结果 (阈值 0.7)
return results.stream()
.filter(r -> r.getScore() > 0.7)
.map(r -> new 检索结果(r.getText(), r.getScore()))
.collect(Collectors.toList());
}
}
五、生产环境调优踩坑
坑点1:向量维度不匹配
// 错误:Dimension must match
// text-embedding-3-small 输出 1536 维
// 但 Collection 创建时设为 768 维
// 解决:确保一致性
private final int DIMENSION = 1536; // OpenAI text-embedding-3-small
坑点2:索引未加载导致查询慢
// 索引创建后需要加载到内存
milvusClient.loadCollection(
LoadCollectionParam.newBuilder()
.withCollectionName(COLLECTION_NAME)
.build()
);
// 或者使用 release 释放内存
milvusClient.releaseCollection(
ReleaseCollectionParam.newBuilder()
.withCollectionName(COLLECTION_NAME)
.build()
);
坑点3:HNSW 的 ef 参数设置
# ef 参数影响查询精度和速度
# ef 越大精度越高,但查询越慢
# 推荐: 64-512 之间调整
# 建库时 efConstruction = 200 (固定)
# 查询时 ef = 128 (可动态调整)
坑点4:Milvus 连接池耗尽
// 错误:连接数超过最大限制
// Milvus 默认 maxConnectionPoolSize = 100
// 解决:增加连接池大小
MilvusServiceClient client = new MilvusServiceClient(
new Config("localhost", 19530,
new ChannelConstraints()
.setMaxConnectionPoolSize(500)
.setMaxConnectionIdleTime(10000))
);
六、选型决策总结
|
场景 |
推荐方案 |
原因 |
|
**亿级向量 + 生产环境** |
Milvus Cluster |
水平扩展、HA高可用 |
|
**全文+向量混合检索** |
ES dense_vector |
一套系统解决两种需求 |
|
**离线批处理 + 极致性能** |
FAISS + GPU |
内存效率最优 |
|
**快速验证 + 小规模** |
Milvus Lite |
零运维、快速上手 |
|
**已有 ES 基础设施** |
ES dense_vector |
复用现有集群 |
**最终推荐**:
- **RAG 知识库首选**:Milvus(独立向量库)
- **中小型混合搜索**:Elasticsearch 8.x(向量+全文)
- **离线场景**:FAISS + 自建服务
---
**作者**:洛水石
**技术栈**:Java / Spring Boot / Milvus / RAG / 向量检索
**关注**:云原生架构 · 搜索技术 · 分布式系统

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)