SpatialMosaic论文精读
·
这篇论文 《SpatialMosaic: A Multiview VLM Dataset for Partial Visibility》 主要解决了当前多模态大语言模型在多视角、部分可见、遮挡严重、低重叠度的真实场景中3D空间推理能力不足的问题。
一、论文解决了什么问题?
核心问题:
现有的多模态大语言模型在3D空间推理任务中,通常依赖:
- 预先构建好的3D表示(如点云、网格)
- 或使用现成的3D重建流水线
但这些方法在真实世界中面临三大挑战,导致模型表现不佳:
- 部分可见性:一个物体只在部分视角中出现,而不是所有视角都可见。
- 遮挡:在单一视角中,物体被其他物体或图像边界部分遮挡。
- 低重叠度:不同视角之间的共同可见区域非常少,难以通过传统匹配方法建立对应关系。
这些问题在当前的多视角数据集中未被充分探索,而人类可以通过整合不完整的视觉信息进行3D推理,但现有模型在这方面表现很差。
二、论文怎么解决这个问题?
论文从数据和模型两个角度入手,提出了完整的解决方案: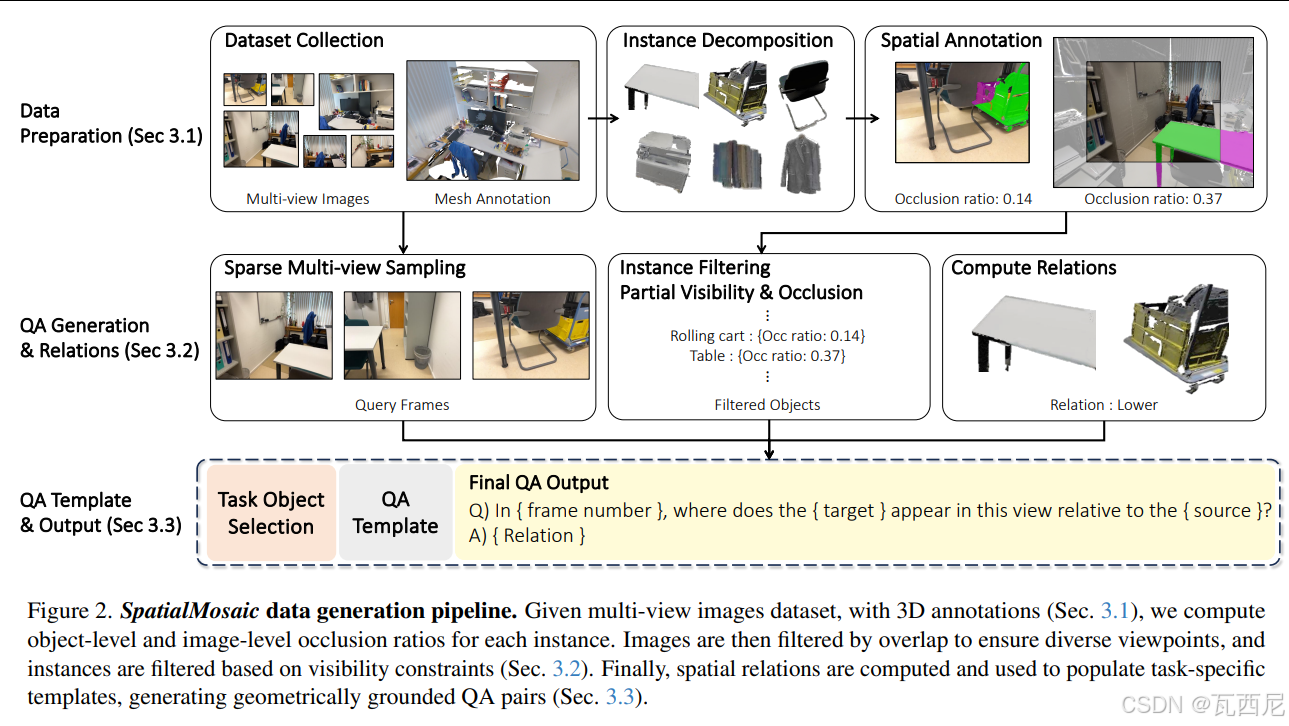
1. 数据层面:构建高质量、挑战性的多视角数据集
提出方法:
- 设计了一个自动化的数据生成与标注流水线,基于现有的高质量3D场景数据集 ScanNet++。
- 该流水线能够:
- 计算每个物体的遮挡比例(物体级遮挡 + 视野边界截断)
- 根据低重叠度采样多视角组合
- 自动生成6类空间推理任务的QA对
产出数据集:
- SpatialMosaic:包含 200万 个QA对的指令微调数据集
- SpatialMosaic-Bench:包含 100万 个QA对的评测基准,涵盖6类任务:
- 物体计数
- 最优视角选择
- 物体定位
- 遮挡感知的存在判断
- 遮挡感知的属性判断
- 遮挡感知的空间关系判断
2. 模型层面:融合3D几何信息的视觉-语言模型
提出模型:SpatialMosaicVLM
架构特点:
- 使用 VGGT 作为几何编码器,提取多视角图像的3D结构特征
- 使用 CLIP ViT 作为视觉编码器,提取每张图像的2D外观特征
- 通过交叉注意力机制融合几何特征与视觉特征
- 融合后的特征与问题一起输入到大语言模型中进行答案生成
优势:
- 不依赖显式3D重建
- 能有效处理遮挡、部分可见、低重叠度的多视角输入
- 在训练中学习了如何从碎片化视觉线索中整合出3D空间结构
三、实验验证了什么?
主要实验结果:
1. 在 SpatialMosaic-Bench 上:
- 现有的开源多模态模型(如LLaVA、InternVL等)在部分可见、遮挡、低重叠条件下表现大幅下降
- 经过 SpatialMosaic 微调的 VLM-3R 和 SpatialMosaicVLM 显著优于所有基线模型
- SpatialMosaicVLM 比 LLaVA-NeXT-Video-7B 高出 34%
2. 在 VSTI-Bench(时间空间推理)上:
- 模型在零样本设置下,直接迁移到未见过的任务类型(如相机位移、物体相对距离等)
- 即使没有训练过这些任务,SpatialMosaicVLM 仍然超过所有开源模型,甚至优于 LLaVA-NeXT-Video-72B
四、论文的核心贡献总结
| 贡献 | 说明 |
|---|---|
| 问题定义 | 明确了多视角空间推理中的三大挑战:部分可见、遮挡、低重叠 |
| 数据流水线 | 提出可扩展的自动标注与QA生成方法,适用于现有3D场景数据集 |
| 数据集 | 构建了 SpatialMosaic 和 SpatialMosaic-Bench,规模大、挑战性强 |
| 模型架构 | 提出 SpatialMosaicVLM,融合几何与视觉特征,提升多视角空间推理能力 |
| 实验验证 | 在多个基准上验证了模型在遮挡、低重叠、零样本迁移下的优越性 |
五、论文的局限与未来方向(可补充思考)
- 当前数据来源于室内场景 ScanNet++,是否能推广到室外、动态场景仍需验证
- 模型依赖 VGGT 作为几何编码器,推理效率可能受限于3D重建模型的速度
- 未来可以探索更轻量的几何编码器,或端到端的学习方式
Json样例
{
"dataset": "SpatialMosaic",
"version": "1.0",
"description": "Multiview VLM dataset for partial visibility, occlusion, and low-overlap conditions",
"source_scene": "ScanNet++",
"scene_id": "scene_0042",
"qa_sample": [
{
"task_type": "object_count",
"question": "How many chair(s) are visible across these frames?",
"frames": [0, 1, 2, 3],
"answer": "3",
"options": ["1", "2", "3", "4"],
"correct_option_index": 2,
"metadata": {
"target_category": "chair",
"visible_instance_ids": ["chair_01", "chair_03", "chair_05"],
"total_instances_in_scene": 5,
"visibility_scenario": "partially_visible",
"gt_scenario": "partial_coverage"
}
},
{
"task_type": "best_view_selection",
"question": "How many chair(s) are visible across these frames? And tell me which frame provides the most informative view of the chair(s).",
"frames": [0, 1, 2, 3],
"answer": "3, Frame 2",
"options": [
"2, Frame 0",
"3, Frame 1",
"3, Frame 2",
"4, Frame 3"
],
"correct_option_index": 2,
"metadata": {
"target_category": "chair",
"count_ground_truth": 3,
"best_frame_id": 2,
"best_frame_reason": "highest_visible_count_and_pixel_area",
"per_frame_visible_counts": [1, 2, 3, 1],
"per_frame_visible_pixels": [12450, 28760, 45320, 9870]
}
},
{
"task_type": "object_localization",
"question": "Is there a(n) monitor in Frame 1? If so, what is the bounding box center coordinates?",
"frames": [0, 1, 2, 3],
"query_frame_id": 1,
"answer": "Yes; (512, 384)",
"options": [
"Yes; (512, 384)",
"Yes; (256, 512)",
"Yes; (768, 256)",
"No"
],
"correct_option_index": 0,
"metadata": {
"target_instance": "monitor_01",
"is_visible_in_query_frame": true,
"bbox_center": [512, 384],
"bbox_2d": [384, 256, 640, 512],
"occlusion_ratio_in_frame": 0.12,
"fov_occlusion_ratio": 0.0
}
},
{
"task_type": "occlusion_aware_existence",
"subtask": "left_right",
"question": "In Frame 3, is the mouse to the right of the laptop in this viewpoint?",
"frames": [0, 1, 2, 3],
"query_frame_id": 3,
"answer": "Yes",
"options": ["Yes", "No"],
"correct_option_index": 0,
"metadata": {
"source_instance": "laptop_01",
"target_instance": "mouse_01",
"source_visible_in_frame": true,
"target_visible_in_frame": false,
"target_occlusion_ratio": 0.67,
"ground_truth_relation": "right",
"evaluated_axis": "x",
"relation_camera_frame": {
"source_bbox_3d": [[-0.5, 0.2, 1.2], [0.5, 0.1, 1.0]],
"target_bbox_3d": [[0.6, 0.15, 1.15], [0.9, 0.05, 1.05]]
}
}
},
{
"task_type": "occlusion_aware_existence",
"subtask": "farther_closer",
"question": "In Frame 2, is the plant farther from the camera than the container in this viewpoint?",
"frames": [0, 1, 2, 3],
"query_frame_id": 2,
"answer": "No",
"options": ["Yes", "No"],
"correct_option_index": 1,
"metadata": {
"source_instance": "container_01",
"target_instance": "plant_01",
"source_visible_in_frame": true,
"target_visible_in_frame": false,
"target_occlusion_ratio": 0.52,
"ground_truth_relation": "closer",
"evaluated_axis": "z",
"depth_source": 2.3,
"depth_target": 1.8
}
},
{
"task_type": "occlusion_aware_attribute",
"subtask": "higher_lower",
"question": "In Frame 4, which object appears higher than the table in this viewpoint?",
"frames": [0, 1, 2, 3, 4],
"query_frame_id": 4,
"answer": "Lamp",
"options": ["Lamp", "Chair", "Book", "Cup"],
"correct_option_index": 0,
"metadata": {
"source_instance": "table_01",
"target_instance": "lamp_01",
"source_visible_in_frame": true,
"target_visible_in_frame": false,
"target_occlusion_ratio": 0.73,
"ground_truth_relation": "higher",
"evaluated_axis": "y",
"distractor_objects": [
{"instance": "chair_02", "relation_to_source": "lower"},
{"instance": "book_03", "relation_to_source": "lower"},
{"instance": "cup_01", "relation_to_source": "lower"}
]
}
},
{
"task_type": "occlusion_aware_spatial_relation",
"subtask": "full_3d",
"question": "In Frame 1, where does the pillow appear in this view relative to the sofa?",
"frames": [0, 1, 2],
"query_frame_id": 1,
"answer": "To the left of the sofa",
"options": [
"To the left of the sofa",
"To the right of the sofa",
"Higher than the sofa",
"Farther from the camera than the sofa"
],
"correct_option_index": 0,
"metadata": {
"source_instance": "sofa_01",
"target_instance": "pillow_01",
"source_visible_in_frame": true,
"target_visible_in_frame": false,
"target_occlusion_ratio": 0.81,
"ground_truth_relations": {
"x_axis": "left",
"y_axis": "higher",
"z_axis": "closer"
},
"evaluated_axis": "x",
"distractor_relations": [
"right",
"lower",
"farther"
]
}
}
],
"difficulty_metadata": {
"overlap_ratio_between_frames": [0.12, 0.08, 0.15, 0.10],
"max_overlap": 0.15,
"avg_occlusion_ratio_targets": 0.68,
"visibility_scenario": "partially_visible",
"difficulty_level": "high"
}
}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)