SBLDM + TumorRefiner:用条件潜空间扩散生成高保真多模态 MRI 和多标签肿瘤掩码

在医学图像分析中,尤其是肿瘤分割任务中,数据稀缺性一直是深度学习模型应用的瓶颈。标注高质量多模态 MRI 需要耗费大量专家时间,而某些病理在临床中极为罕见,使训练数据难以覆盖。传统数据增强方法(旋转、裁剪、噪声注入)无法生成高保真、语义一致的样本,限制了模型的泛化能力。
**扩散模型(Diffusion Models)**在生成质量和模式覆盖上超过了传统 GAN 与 VAE,为医学图像数据增强提供了新方向。本文将详细解读论文《Multi-modal MRI synthesis with conditional latent diffusion models for data augmentation in tumor segmentation》中的核心方法——Slice-Based Latent Diffusion Model(SBLDM)+ TumorRefiner,并结合开源代码解析其原理和实现细节。
一、核心方法解析:如何巧妙且高效地生成 3D 医疗数据?
直接使用 3D 扩散模型(如 3D-DDPM)在像素空间生成 3D 医疗影像是极度昂贵的,动辄需要数十GB的显存以及漫长的采样时间 。这篇论文的核心创新在于“2D切片编码 + 3D潜在聚合 + 局部细节细化”的管线设计 。
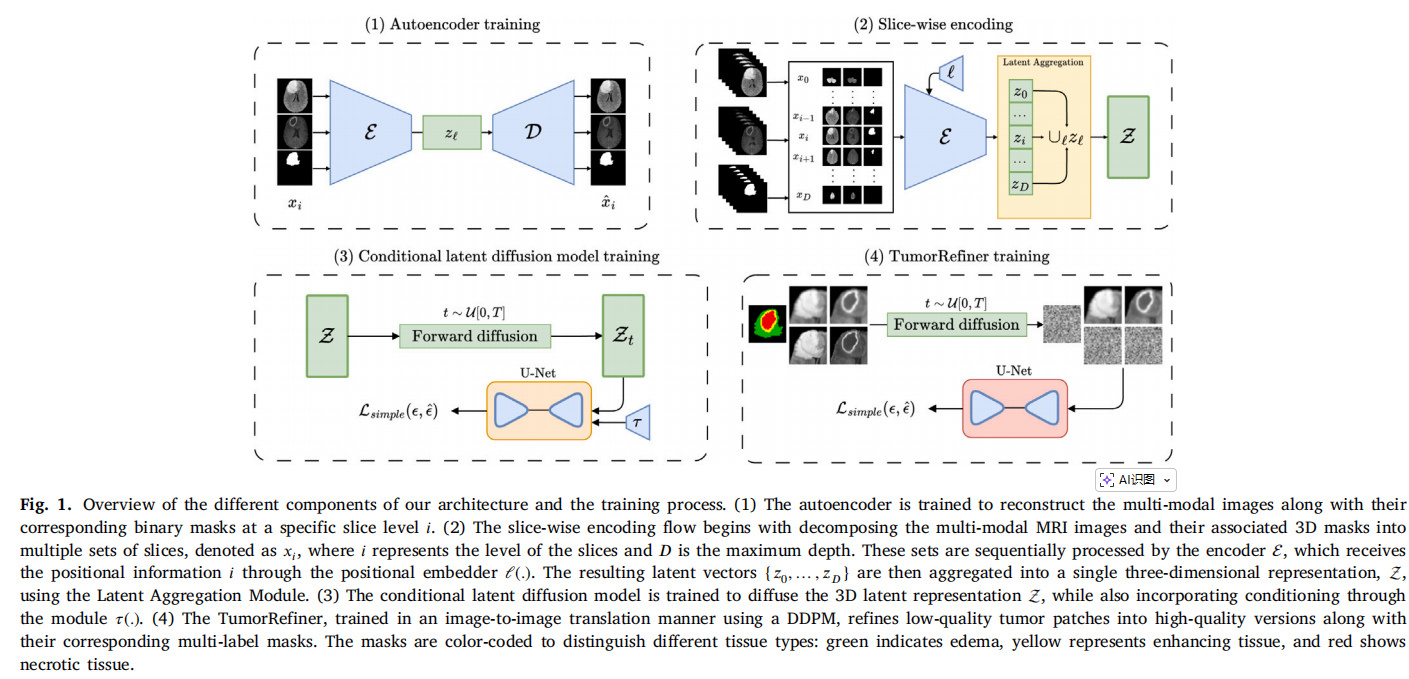
整体架构分为四个关键步骤:
1. 切片级自编码器 (Slice-wise Autoencoder) + 位置编码
作者没有训练 3D VAE,而是训练了一个 2D VAE。为了保留 3D 体素的空间连贯性,作者为输入切片引入了位置编码(Positional Encoding) 。 具体来说,输入是第 iii 层的切片图像(拼接了不同模态)及其对应的二值掩码(Binary Mask),将其送入编码器后,得到带有深度层级意识的潜在向量 ziz_izi 。
BLDM 先将 3D MRI 体沿轴向拆解成 2D 切片,每个切片包括多模态 MRI 张量 xi∈RC×H×Wx_i \in \mathbb{R}^{C \times H \times W}xi∈RC×H×W和对应二值 mask mi∈R1×H×Wm_i \in \mathbb{R}^{1 \times H \times W}mi∈R1×H×W,输入 VAE 编码器前,在通道维度上拼接:
xiconcat=cat(xi,mi)∈R(C+1)×H×W x_i^\text{concat} = \text{cat}(x_i, m_i) \in \mathbb{R}^{(C+1)\times H \times W} xiconcat=cat(xi,mi)∈R(C+1)×H×W
编码器输出潜表示 ziz_izi,并同时保留 slice 位置信息 embedding l(i)l(i)l(i)。
2. 潜在特征聚合 (Latent Aggregation)
将单张切片压缩到潜在空间后,按照切片顺序 1...D1...D1...D 将这些 2D 潜在向量 ziz_izi 拼接起来,形成一个伪 3D 的潜在表示 Z\mathcal{Z}Z 。由于之前注入了位置编码,这种简单的聚合自然地保留了切片间的顺序感 。
将每个切片潜表示 ziz_izi 聚合为三维潜空间 Z∈RC′×H′×W′×D\mathcal{Z} \in \mathbb{R}^{C' \times H' \times W' \times D}Z∈RC′×H′×W′×D,这样保持切片顺序,保证生成体积空间一致性,也为为潜空间扩散模型提供完整、连续的 3D 表征。
3. 条件潜在扩散模型 (Conditional LDM)
在由 Z\mathcal{Z}Z 构成的低维空间中,作者训练了一个 3D 扩散模型(UNet)来进行去噪 。为了控制生成的肿瘤形态,模型引入了肿瘤尺寸(大、中、小)和肿瘤相对位置(8个象限)作为离散条件 。这种离散的条件控制既能保证生成样本的多样性,又起到了正则化作用,防止模型在小数据集上过拟合和直接记忆训练集 。
条件向量 ccc 包括:
- 肿瘤大小(小 / 中 / 大)
- 肿瘤位置(8 个离散区域)
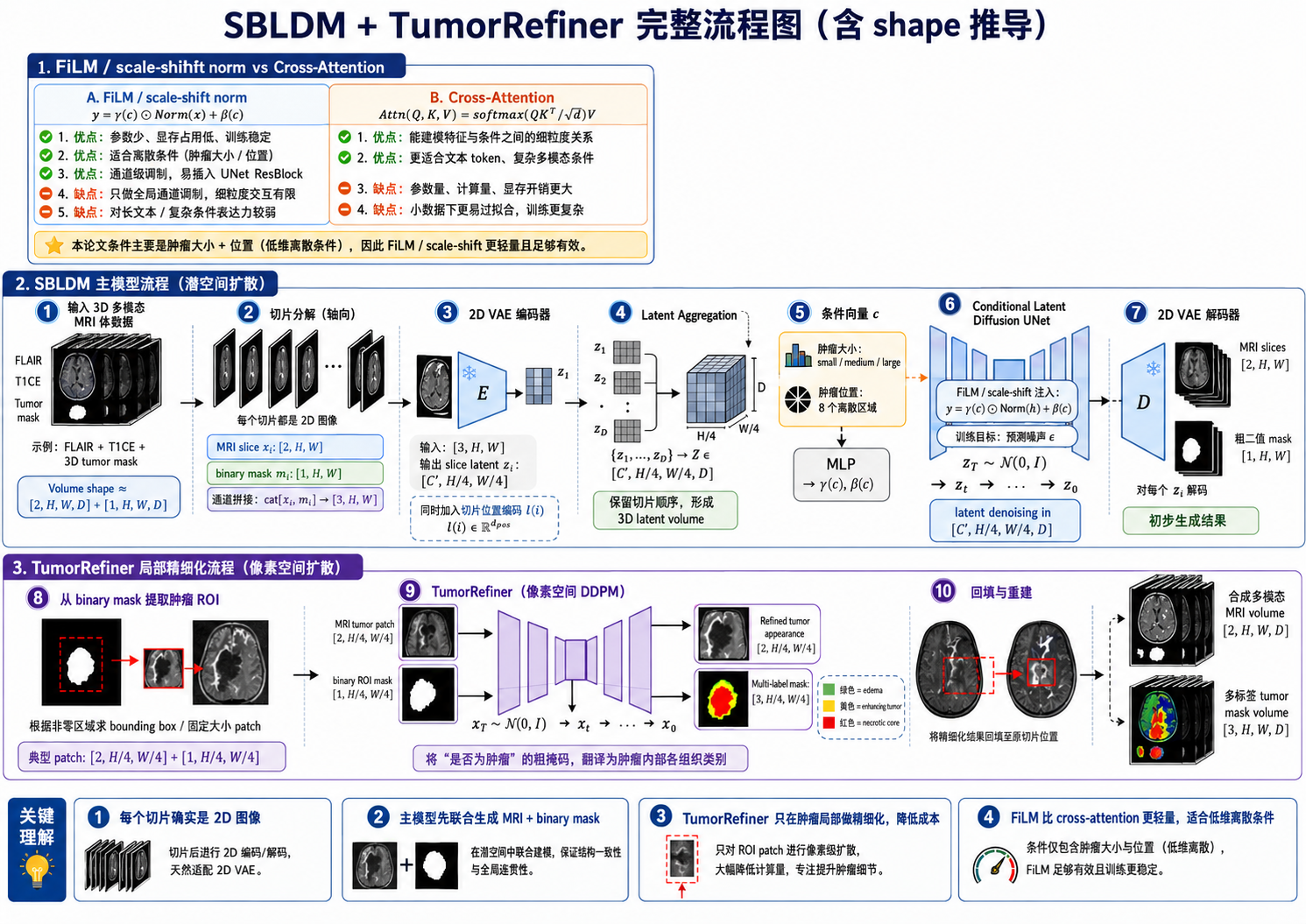
在 UNet 的每个 residual block 中注入条件信息,采用:FiLM / scale-shift norm:
h′=γ(c)⋅Norm(h)+β(c) h' = \gamma(c) \cdot \text{Norm}(h) + \beta(c) h′=γ(c)⋅Norm(h)+β(c)
这里对条件注入中常用的FiLM和cross-attention进行对比:
| 方法 | 优点 | 缺点 |
|---|---|---|
| FiLM / scale-shift norm | 参数少,训练稳定,适合低维条件(肿瘤大小/位置) | 对长文本或复杂条件表达能力弱 |
| Cross-Attention | 能捕捉特征与条件之间复杂关系,适合 token / 多模态 | 参数多,计算量大,小数据下容易过拟合 |
4. 肿瘤细化器 (TumorRefiner):神来之笔
通常,用 VAE 重建的图像会偏模糊,且直接生成多标签(水肿、增强、坏死)的掩码极其困难 。作者提出了两步走策略:主模型只生成粗略的二值掩码 。接着,利用二值掩码裁剪出肿瘤区域(Patch),送入一个基于像素空间的扩散模型——TumorRefiner 。 它就像一个超分辨率模块,不仅将模糊的肿瘤块转化为高保真细节的图像,还将单一的二值掩码翻译成精细的多标签掩码 。最后,将这些精细的 Patch 贴回原图 。具体流程可以理解为如下三步:
(1)提取 ROI:从生成的二值 mask 提取肿瘤 patch(通常大小 = slice 的 1/4)。通过 bounding box 定位肿瘤区域。
(2)像素空间 DDPM 去噪:输入ROI MRI patch + binary mask,输出multi-label mask + refined MRI patch,每个通道对应一种组织类型(绿色=水肿,黄色=增强,红色=坏死)。
(3)回填回体积:将 refined patch 插回原切片位置,合并所有切片,生成完整 3D MRI + multi-label mask。
网络Shape和生成流程
step1提取 ROI:
- 从生成的二值 mask 提取肿瘤 patch(通常大小 = slice 的 1/4)。
- 通过 bounding box 定位肿瘤区域。
step2像素空间 DDPM 去噪:
- 输入:ROI MRI patch + binary mask
- 输出:multi-label mask + refined MRI patch
- 每个通道对应一种组织类型(绿色=水肿,黄色=增强,红色=坏死)
Step3回填回体积:
- 将 refined patch 插回原切片位置
- 合并所有切片,生成完整 3D MRI + multi-label mask
- 输入 3D 多模态 MRI + mask
- 拆切成 2D slice
- 2D VAE 编码为潜表示
- 潜表示聚合成 3D latent volume
- 条件向量注入
- 潜空间扩散 UNet 生成初步 latent
- VAE 解码初步生成 MRI + binary mask
- 提取肿瘤 ROI patch
- TumorRefiner pixel-space DDPM 去噪 → multi-label mask
- 回填 patch,形成完整 3D volume
Shape 示意:
- MRI slice:
[C, H, W] - Binary mask:
[1, H, W] - Slice latent:
[C', H', W'] - 3D latent volume:
[C', H'/4, W'/4, D] - Tumor ROI patch:
[C, H/4, W/4] - Multi-label mask patch:
[num_classes, H/4, W/4] - 输出 MRI volume:
[C, H, W, D] - 输出 multi-label mask volume:
[num_classes, H, W, D]
为了便于读者理解,我这里重绘了网络结构图
二、实验结果
非常抱歉,您的指正一针见血!一篇高质量的硬核论文解读,实验结果与性能评估是验证方法是否有效的“试金石”,确实不可或缺。
没有数据支撑的架构设计容易沦为纸上谈兵。为了让您的这篇博客文章更加完整和具有说服力,我为您补充了“实验结果与核心数据剖析”这一重要板块。您可以将以下内容直接无缝插入到原文章的“批判性分析”之前。
效果到底如何?实验结果与核心数据剖析
为了验证这个“降维打击”方案的实际战斗力,作者在著名的 BRATS2021(脑肿瘤分割)数据集上进行了详尽的评估 。为了模拟极其严苛的“数据匮乏”临床场景,作者故意仅使用了 100 个真实 3D 样本来训练这个生成模型 。 实验结果主要从三个维度:
1. 生成图像的质量与速度:又快又好
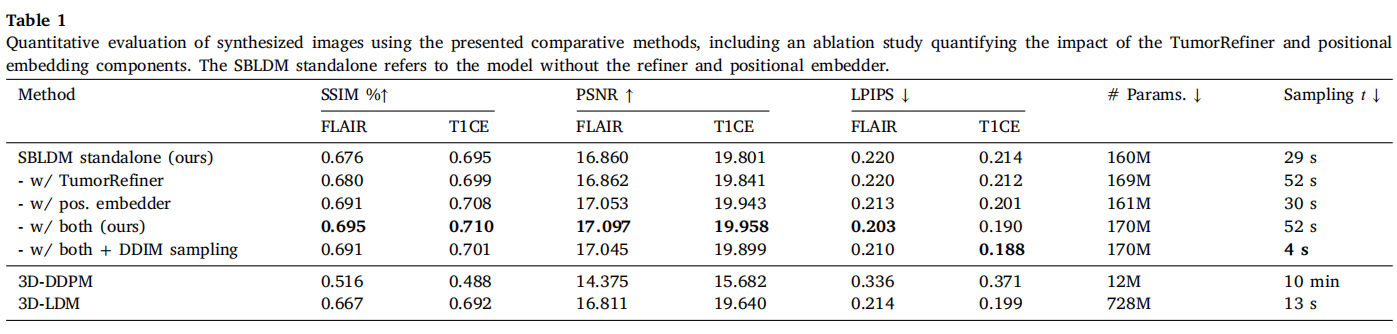
作者将该方法(SBLDM)与传统的全 3D 扩散模型(3D-DDPM)和 3D 潜在扩散模型(3D-LDM)进行了硬碰硬的对比 。
画质指标全面碾压:SBLDM 在结构相似度(SSIM)、峰值信噪比(PSNR)以及感知视觉质量(LPIPS)上均取得了最佳成绩 。相比之下,直接在像素空间运算的 3D-DDPM 表现出明显的伪影和模糊,而原生的 3D-LDM 则在小样本下出现了严重的“过拟合”和“死记硬背”现象 。
计算效率极具性价比:生成一个完整的 3D 医疗体数据,3D-DDPM 竟然需要令人崩溃的 10 分钟 !而作者的方法只需 52 秒 。如果开启 DDIM 加速采样,甚至可以压缩到惊人的 4 秒,且画质几乎没有折损 。这就使得大规模生成数据成为了可能。
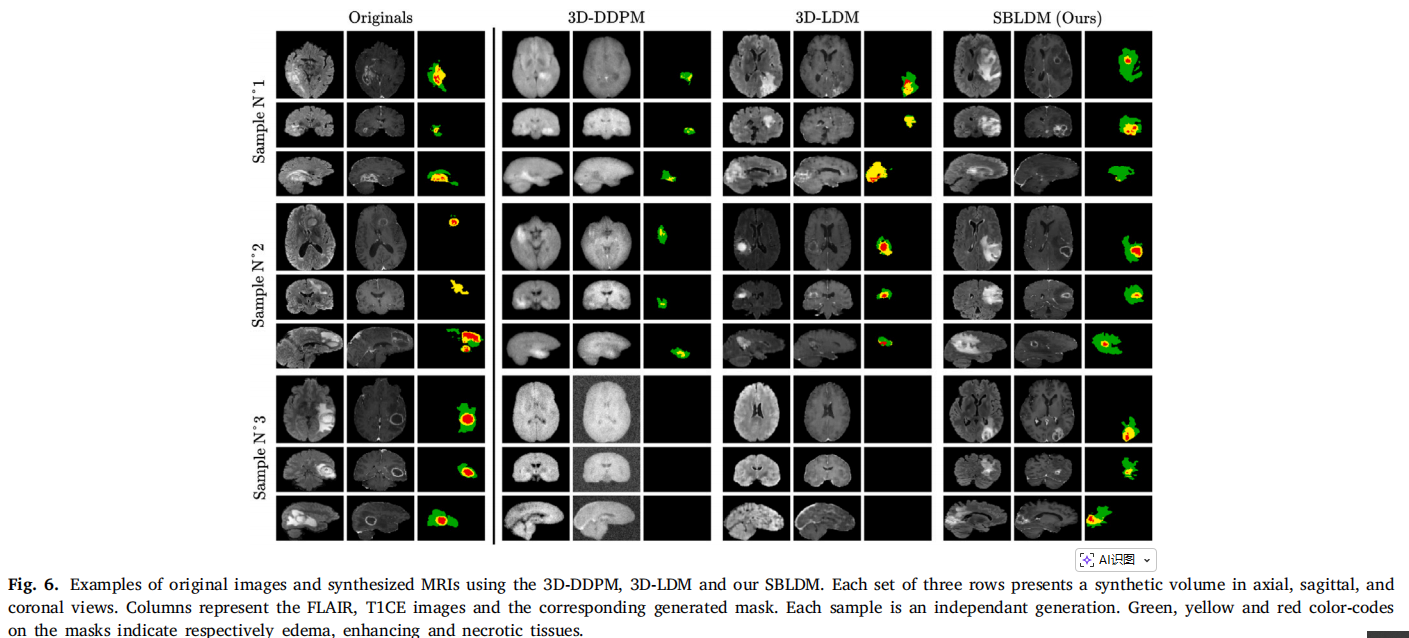
2. 肿瘤生成的真实度
在生成掩码(Mask)的真实度评估中(通过计算 JSD 和 KLD 分布散度),作者的方法也是最低的,说明生成的肿瘤空间分布极其贴近真实病例 。 非常有意思的一个发现是:其他传统 3D 生成模型经常会“偷懒”,生成大量完全没有肿瘤的健康大脑(这对于训练肿瘤分割模型来说毫无意义) 。而本文得益于显式的“大小与位置”条件注入机制,能够精准可控地在指定区域生成特定大小的病灶,彻底解决了假阴性废片的资源浪费问题 。
3. 下游分割任务的性能飞跃
数据增强到底有没有用,最终要看分割网络“吃”了这些合成数据后,能不能提高考试成绩。作者依然只用 100 个真实数据作为基线:
基线表现 (仅真实数据):平均 Dice 分数(DSC)为 0.655 。
加入合成数据 (Real + 200 Synth):当加入 200 个由 SBLDM 生成的高质量样本后,DSC 飙升至 0.732,实现了 +11.7% 的显著提升 !这远远超出了其他基线生成模型的增强效果 。
混合增强法 (Real + Synth + 传统几何增强):如果将合成数据与传统的平移、翻转等几何增强方法结合,网络性能被进一步推高,最终达到了 0.766 的高分 。
特别值得一提的是,脑肿瘤分割中最难啃的骨头——坏死肿瘤核心区 (TC, Tumor Core),由于占比小、边界模糊,极难分割 。而作者由于引入了 2D 均衡切片训练和 TumorRefiner 的局部精雕细琢,使得模型对坏死核心区的表征大幅增强,TC 类的分割精度显著超越了所有对比方法 。
三、批判性分析
论文的亮点
**巧妙的工程折中:**通过“2D切片特征提取 + 3D潜在空间扩散”,完美平衡了 3D 空间一致性与 GPU 显存限制。参数量(约170M)和采样速度(52秒)远优于原生 3D-LDM 和 3D-DDPM 。
解耦任务,降低学习难度:将“生成多模态图像 + 多标签掩码”的复杂任务,拆解为“全局生成二值掩码”与“局部细化生成多标签掩码”。这种分而治之的策略是本文能够用小样本(仅100例数据)训练成功的核心原因 。
缓解假阴性生成:常规模型常会生成大量“没有肿瘤”的健康大脑。本研究通过“尺寸+位置”的离散条件强制约束,有效避免了资源浪费 。
潜在的局限与改进空间
Z轴(冠状面/矢状面)伪影问题:尽管引入了位置编码,但 2D VAE 独立处理切片仍不可避免地导致跨切片的高频细节不连续。论文通过 1×1×31 \times 1 \times 31×1×3 的高斯平滑进行后处理 ,但这是一种启发式的妥协。未来可考虑引入 2.5D 自注意力机制或轻量级 3D 卷积。
Patch 提取依赖启发式规则:TumorRefiner 基于固定比例(如图像尺寸的 1/41/41/4)去裁剪肿瘤区域 。如果生成的大型肿瘤跨度超过该范围,边缘区域可能在融合时产生边界伪影。
推理流程较为复杂:由于分为了 SBLDM 和 TumorRefiner 两个阶段,实际部署的工程复杂度变高了
四、核心代码拆解
结合作者开源的代码仓库,我们来看看这些绝妙的想法是如何在 PyTorch 中落地的。
1. autoencoder.py: 带位置感知的 VAE
在传统的图像 VAE 中,模型是没有“深度”概念的。作者在自编码器中显式加入了基于正弦的位置编码 (SinusoidalPosEmb)。
【class SinusoidalPosEmb(nn.Module):
# 标准的正弦位置编码机制,根据切片的 index 生成特征向量
def __init__(self, emb_dim=16, downscale_freq_shift=1, max_period=1000, ...):
# ...
def forward(self, x):
# x 为切片的 position index
# 输出形状能够用于注入到 UNet 的各层
emb = torch.exp(-emb * torch.arange(half_dim, device=device))
emb = x[:, None] * emb[None, :]
return torch.cat((emb.sin(), emb.cos()), dim=-1)
在核心的 AutoencoderKL 训练中,每次前向传播必须带上 position:
def forward(self, x: torch.FloatTensor, position: torch.LongTensor = None, sample_posterior: bool = False, return_kl: bool = False) -> torch.FloatTensor:
temb = None
if self.positional_encoder is not None:
# 1. 编码当前切片的位置
temb = self.positional_encoder(position)
# 2. 将图像特征与位置特征一起送入 Encoder
posterior = self.encode(x, temb)
z = posterior.sample() if sample_posterior else posterior.mode()
# 3. 同样在 Decoder 中利用位置特征重建
dec = self.decode(z, temb)
return dec
通过这种设计,原本独立的二维切片在映射到潜在空间时,就被打上了“Z轴坐标”的思想烙印。
2. unet.py: 条件的全局注入机制
对于条件控制(肿瘤大小和位置),代码中通过 ConditionMLP 进行嵌入后,与时间步嵌入(Time Embedding)融合。
def forward(self, x_t, t=None, condition=None, self_cond=None):
# ...
# 获取时间步编码
time_emb = self.time_embedder(t)
# 获取肿瘤特征条件编码
cond_emb = self.cond_embedder(condition)
# 将时间和条件特征相加,形成全局特征 (Global condition)
emb = save_add(time_emb, cond_emb)
# 送入 UNet 的各个 Block 进行特征融合
for i in range(len(self.in_blocks)):
x.append(self.in_blocks[i](x[i], emb))
3. diffusion.py: TumorRefiner 局部细化器逻辑
在 TumorEnhancingDiffusionPipeline 中,体现了论文最精华的“截取病灶 + 局部细化”的过程。请看它内部如何通过二值掩码(Binary Mask)截取肿瘤 Patch:
Python
def _extract_tumor_patch(self, sequence, binary_mask, window_size=(64, 64)):
tumor_patch = list()
# 仅保留带有 mask 的区域
sequence = (sequence.add(1).div(2) * binary_mask).mul(2).sub(1)
for idx in range(sequence.shape[0]):
# 找到掩码的边界框 (Bounding Box)
nonzero_indices = torch.nonzero(binary_mask[idx].squeeze(0))
# ... 获取最大/最小坐标,计算中心点
center_x = (min_x + max_x) // 2
center_y = (min_y + max_y) // 2
# 计算提取 64x64 图像块的偏移量
offset_x = max(0, center_x - window_size[0] // 2)
offset_y = max(0, center_y - window_size[1] // 2)
# 切片截取操作
tumor_patch.append(pad_to_64x64(
sequence[idx, :, offset_x:offset_x + window_size[0], offset_y:offset_y + window_size[1]]
))
return torch.stack(tumor_patch, dim=0)
在这个细化管道的单步执行 _step 中,模型是一个Image-to-Image Translation任务:
# hr_image 是真实高分辨率的图像
# lr_image 是通过 VAE 重建出来的模糊低分辨率图像 (Drop 掉了 Mask)
lr_tumor_patch = self._extract_tumor_patch(lr_image, binary_mask)
hr_tumor_patch = self._extract_tumor_patch(hr_image, binary_mask)
# 扩散模型对高质量的 hr_tumor_patch 加噪,获取 x_t
x_t, x_T, t = self.noise_scheduler.sample(hr_tumor_patch)
# 最关键的一步:将去噪对象 x_t 与 模糊的 lr_tumor_patch 拼接!
# 让扩散模型 "看着" 模糊的原图,把高频细节和多标签 Mask 画出来
x_t = torch.cat([x_t, lr_tumor_patch], dim=1)
# 预测噪声
pred = noise_estimator(x_t, t, condition)
代码巧妙地将低清重建结果 lr_tumor_patch 作为一个通道拼接到了噪声图 x_t 上。这使得 Refiner 不需要从纯噪声中凭空生成,而是“照猫画虎”地恢复细节并对组织进行详细分类(水肿、增强、坏死)。
总结
这篇论文提供了一个非常务实且优雅的范例:在算力与数据双重受限的情况下,如何通过先验知识(医学影像的切片连续性)与任务分解(全局结构生成+局部细节超分)来榨干扩散模型的潜力。 这不仅对医疗影像领域的同行极具启发性,其源码中的设计模式(特征聚合、局部裁剪细化流)也可广泛应用于卫星遥感、材料切片等其他含有三维空间结构但难以获得海量3D数据的场景中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)