8×8矩阵搞定LLM长期记忆:Mind Lab提出δ-mem,仅0.12%参数撬动31%性能提升|开源
让大模型记住”你是谁”,需要多大的记忆体? 来自Mind Lab、南洋理工、复旦、上交、港中文、港科大(广州)联合团队的最新研究给出了一个令人惊讶的答案: 8×8的矩阵就够了。 刚刚发布的δ-mem论文证明:一个仅占主干模型0.12%参数的轻量记忆机制,可以让冻结的LLM在长期记忆任务上获得显著提升——MemoryAgentBench提升1.31倍,LoCoMo提升1.20倍,TTL子任务直接从26.14翻倍到50.50。 更关键的是,δ-mem既不需要全参数微调,也不需要替换主干架构,更不需要扩展显式上下文。它把记忆问题从”塞更多token”的死胡同里拽了出来。
长上下文≠长期记忆 先说一个被很多人忽略的事实。 当大模型被部署到长期个人助手、长程Agent系统这类场景里,它的生命周期不再是”回答单条prompt”那么简单——它需要在跨越多次交互的任务里持续积累、更新、复用历史信息。 最直觉的做法是把上下文窗口拉长,把历史对话全塞进去。但这条路有两个根本问题: 第一,标准注意力的计算成本是上下文长度的平方级。 第二,更长的上下文≠更好的使用。 模型在超长上下文下经常出现”context degradation”或”context rot”——信息塞进去了,但用不好。即便是百万token级别的上下文窗口(GPT、Gemini都有),也没从根本上解决记忆问题。 简单说:把记忆问题简化成长上下文处理问题,是一条死路。 行业需要的是更聪明的记忆机制——能在固定上下文窗口里更紧凑地表示历史信息,能跨交互动态维护,还能在推理时被主干模型有效调用。
现有方案的三大流派,各有死穴 Mind Lab在论文里把现有记忆机制按两个维度做了系统梳理:
- 记忆状态(Memory State):历史信息怎么存
- 记忆引导(Memory Steering):存的东西怎么影响主干推理 按这个框架,现有方法分成三派: 第一派:文本记忆(TMM) 代表:MemGPT、MemoryBank、RAG系列 把记忆存成文本,通过输入上下文注入。灵活、不改架构,但受制于上下文窗口、检索噪声和压缩损失。 第二派:外通道记忆(OMM) 代表:Memorizing Transformers、LongMem、MLP Memory 把记忆放在外部模块里,通过检索或编码和主干交互。能模块化,但有检索开销、融合复杂、和主干表示对不齐。 第三派:参数化记忆(PMM) 代表:LoRA、Prefix-Tuning、ROME、MEMIT 把记忆编码进前缀或adapter的参数里。高效、兼容冻结主干,但静态的本质让它没法适应动态演化的信息。 三派都有死穴,指向一个共同的需求:一个能维护紧凑、动态演化的记忆状态,同时通过和主干内部注意力计算紧密对齐的路径来引导主干的机制。 这就是δ-mem要解决的问题。
δ-mem的核心设计:在线关联记忆 + 低秩注意力修正 δ-mem的设计思路可以用一句话概括: 给冻结的全注意力主干配一个紧凑、动态更新的”在线关联记忆状态”(OSAM),用它的读出生成对主干注意力计算的低秩修正。 具体来说,δ-mem不存储所有历史token的文本,而是把过去的信息压缩进一个固定大小的状态矩阵,通过delta-rule学习随新token的到来持续更新。 每个位置上的计算顺序是固定的三步:
- Read:从旧状态读出关联记忆信号
- Steer:用信号引导当前的注意力计算
- Write:把当前信息写回状态
关键组件1:记忆投影 给定当前隐状态,δ-mem先把它投影到一个低维的关联记忆空间,生成三个向量:
- qtmq^m_tqtm:查询旧状态
- ktmk^m_tktm:描述当前信息应该怎么写入
- vtmv^m_tvtm:写入的具体内容 同时,写门 βt\beta_tβt 和保留门 λt\lambda_tλt 控制着每个维度独立的更新——某些维度保留旧记忆,某些维度更积极地写入新信息。 关键组件2:从在线状态读取 写入当前信息之前,δ-mem先读旧状态: rt=St−1qtm,\mathbf r_t = \mathbf S_{t-1}\mathbf q_t^m,
这个读出操作的成本和历史长度完全无关——因为状态大小是固定的。 关键组件3:通过低秩修正引导注意力 读出的信号通过两个轻量线性映射,转成query侧和output侧的修正:
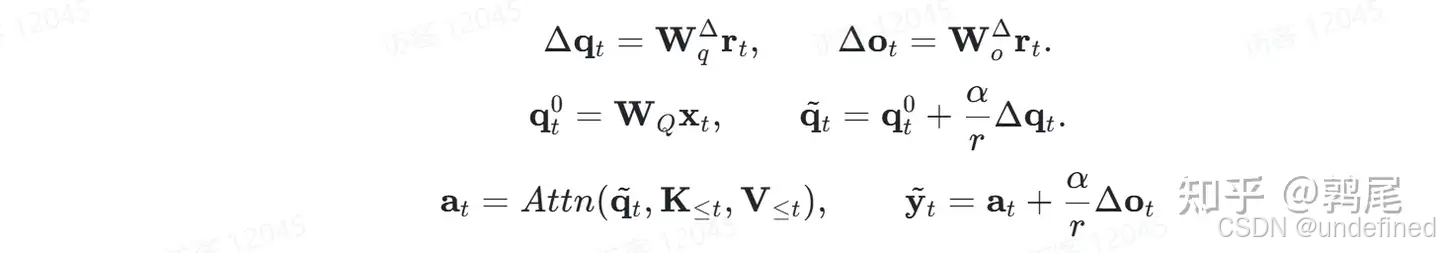
关键组件4:带门控的delta-rule状态更新 注意力计算完成后,δ-mem把当前信息写回状态:
St=Diag(λt)St−1−Diag(βt)St−1ktm(ktm)⊤+Diag(βt)vtm(ktm)⊤.\mathbf S_t = \mathrm{Diag}(\boldsymbol\lambda_t)\mathbf S_{t-1} - \mathrm{Diag}(\boldsymbol\beta_t) \mathbf S_{t-1} \mathbf k_t^m(\mathbf k_t^m)^\top + \mathrm{Diag}(\boldsymbol\beta_t) \mathbf v_t^m(\mathbf k_t^m)^\top .
展开看,三项各司其职:
- 第一项:保留之前的状态
- 第二项:沿当前key方向移除旧的预测分量
- 第三项:沿同一方向写入新值 这是带控制遗忘的纠错更新,而不是无差别地累加外积。
三种写入粒度:Token、Segment、多状态 δ-mem还设计了三种写入策略,对应不同的应用场景: TSW(Token-State Write):在每个token位置更新状态。粒度最细,但容易被格式符号、重复表达和短期噪声影响。 SSW(Sequence-State Write):把粒度从token提升到消息段,先平均段内所有token的隐状态再写入。减少冗余写入,平滑状态演化。 MSW(Multi-State Write):把记忆分解为多个并行子状态。不同子状态积累不同类型的信息——事实、偏好、任务进度、局部事件互不干扰。
实验结果:8×8矩阵打败所有基线 实验在三个主干模型(Qwen3-4B-Instruct、Qwen3-8B、SmolLM3-3B)上展开,对比了文本记忆、参数记忆、外通道记忆的多个代表方法。 核心结论数据: 在Qwen3-4B-Instruct上: 暂时无法在飞书文档外展示此内容 几个关键观察: 第一,δ-mem在所有方法中表现最强。 TSW变体达到51.66%的平均分,比基线提升+4.87,比最强基线Context2LoRA提升+6.76。 第二,在记忆密集任务上提升最明显。 MemoryAgentBench从29.54%提到38.85%,LoCoMo MSW达到49.12%——TTL子任务从26.14几乎翻倍到50.50。 第三,HotpotQA的EM/F1从42.35⁄56.00提升到49.41⁄63.66。 更有意思的是不同主干上的表现:
- Qwen3-8B:从47.20%提升到50.86%(SSW最优)
- SmolLM3-3B:从26.08%大幅跃升到36.96%(MSW最优,+10.88分) 这说明:能力更强的主干受益于SSW的段级平滑,而较小的主干受益于MSW的多状态分离。
最反直觉的实验:移除显式上下文后,δ-mem仍能恢复信息 为了验证在线关联记忆能不能保留有用的历史信息,研究团队做了一个极端实验:完全移除原始历史上下文,只注入压缩后的记忆状态。 [图片] 结果令人意外: 在HotpotQA上:
- Overall EM:从0.08%提升到6.48%
- Overall F1:从8.27%提升到15.20%
- Bridge子集EM:从0.08%提升到3.97%(多跳证据恢复) 在LoCoMo上:
- 整体平均:从3.49%提升到8.05%
- 多跳、时间、开放域、单跳问题都有明显提升 这说明:8×8的在线状态确实存储了和上下文相关的历史信号,即便显式上下文被移除,模型仍能恢复关键信息。 这是一个非常强的证据——记忆不需要被显式存储在token空间里。
参数开销:仅0.12%,比MLP Memory少600倍 δ-mem最让人意外的不是性能,而是参数效率。 具体对比:
- δ-mem (SSW/TSW):4.87M可训练参数,占主干0.12%
- δ-mem (MSW):19.47M,占0.48%
- Context2LoRA:5.90M,0.15%
- MemGen:46.20M,1.13%
- MLP Memory:3078.00M,76.40%
推理效率:和Vanilla几乎持平 参数少不等于推理慢。研究团队也测了实际推理效率: 显存占用:δ-mem和Vanilla、Context2LoRA几乎一致,即便prompt长度增加到32K也没有显著开销。 解码吞吐:δ-mem因为每步要读取和更新在线状态,比Vanilla稍慢。 实际表现:在长上下文场景下用极小的计算开销换取记忆能力,这个权衡相当划算。 [图片] [图片] One More Thing 这是Mind Lab最近半年第N篇硬核工作了。 回顾这个团队的节奏:
- 2025年底:全球首个万亿参数LoRA-RL训练,GPU消耗直降90%,技术获NVIDIA Megatron-Bridge和Seed verl官方合并
- 2026年初:提出Context Learning范式,把临时上下文增益永久写进模型参数
- 2026年4月:完成GLM5/GLM5.1的全栈LoRA训练支持
- 2026年4月:发布216次实验的LoRA rank scaling研究,重新定义低秩研究议程
- 2026年5月:发布δ-mem,用8×8矩阵解决LLM长期记忆问题 每一项工作都在围绕同一个核心命题:让大模型从真实使用中持续成长。 仔细看会发现一条清晰的技术路线:
- 大模型RL训练降本 → 让研究循环更便宜
- Context Learning → 让临时增益变成永久能力
- LoRA-RL范式研究 → 把低秩端做成可靠工具
- δ-mem → 把长期记忆做成轻量在线状态 所有的工作都在指向一件事:把大模型变成一个能持续学习、持续成长的活系统,而不是训练完就冻结的静态产物。 Mind Lab是一家专注于”经验智能”(Experiential Intelligence)的研究实验室,10人核心团队成员来自OpenAI、DeepMind、Seed,学术背景横跨清华、MIT、Cornell,发表200+篇论文,被引30,000+次。 他们的Slogan是: Real intelligence learns from real experience. 真正的智能源于真实的体验。 从δ-mem这次的工作看,他们离这个目标又近了一步——8×8的矩阵装下的不只是数字,更是LLM长期记忆的全新范式。
参考链接: [1] arXiv论文: https://arxiv.org/abs/2605.12357 [2] Github (Mind Lab): https://github.com/MindLab-Research/delta-Mem [3] Github (Declare-lab): https://github.com/declare-lab/delta-Mem

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)