RAG 企业落地实战:从零搭建私有知识库问答系统(完整版)
📖 一、什么是 RAG?为什么企业需要它?
1.1 用大白话解释 RAG
想象一下,你有一个超级聪明的助手(大模型),但它不知道你公司的内部资料。
你问它:“我们公司去年的销售数据怎么样?”
它只能瞎编,因为它没看过你的销售报表。
RAG(检索增强生成) 就是给这个助手配一个"图书馆管理员":
简单说:先检索,再回答。让大模型"开卷考试",而不是"闭卷瞎编"。
1.2 企业为什么需要 RAG?
🛠️ 二、前置知识准备
2.1 你需要知道什么?
不需要:
- ❌ 深度学习理论
- ❌ 复杂的数学公式
- ❌ 大模型训练经验
需要:
- ✅ 基本的 Python 编程能力
- ✅ 会用命令行
- ✅ 了解 API 调用概念
2.2 环境准备
# 1. 安装 Python 3.8+(检查版本) python3 --version # 2. 创建虚拟环境(推荐) python3 -m venv rag-env source rag-env/bin/activate # Mac/Linux # 或 rag-env\Scripts\activate # Windows # 3. 安装核心依赖 pip install langchain chromadb openai sentence-transformers
2.3 你需要准备什么资源?
| 场景 | 痛点 | RAG 解决方案 |
| 客服问答 | 客服培训成本高,回答不一致 | 知识库统一,回答标准化 |
| 内部文档查询 | 文档分散,找资料费时 | 一句话检索所有文档 |
| 技术支持 | 工程师重复解答相同问题 | 自助问答,释放人力 |
| 培训新人 | 新人上手慢,老员工累 | 7×24 小时智能导师 |
资源用途获取方式OpenAI API Key调用大模型https://platform.openai.com企业文档知识库素材PDF/Word/Markdown 格式一台服务器部署服务本地电脑或云服务器
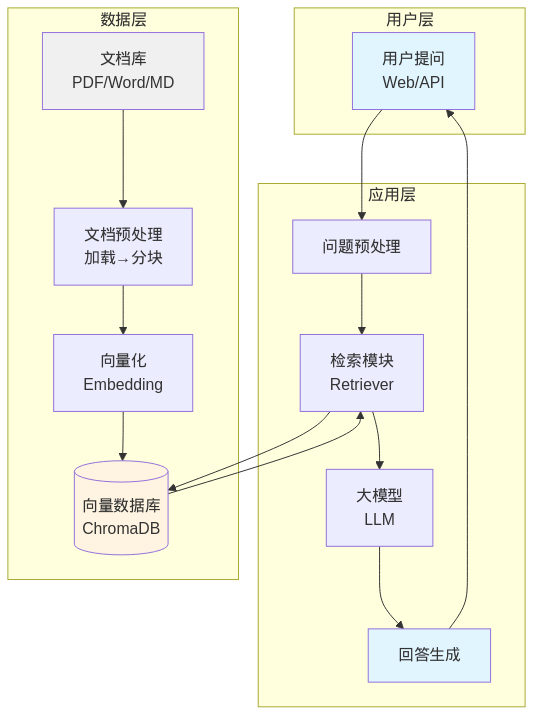
🏗️ 三、系统架构详解
3.1 完整架构图

3.2 核心组件说明
💻 四、手把手实战:从零搭建
4.1 项目结构
rag-system/ ├── docs/ # 原始文档 │ ├── employee-handbook.pdf │ ├── product-manual.md │ └── faq.txt ├── main.py # 主程序 ├── config.py # 配置文件 └── requirements.txt # 依赖列表
4.2 完整工作流程
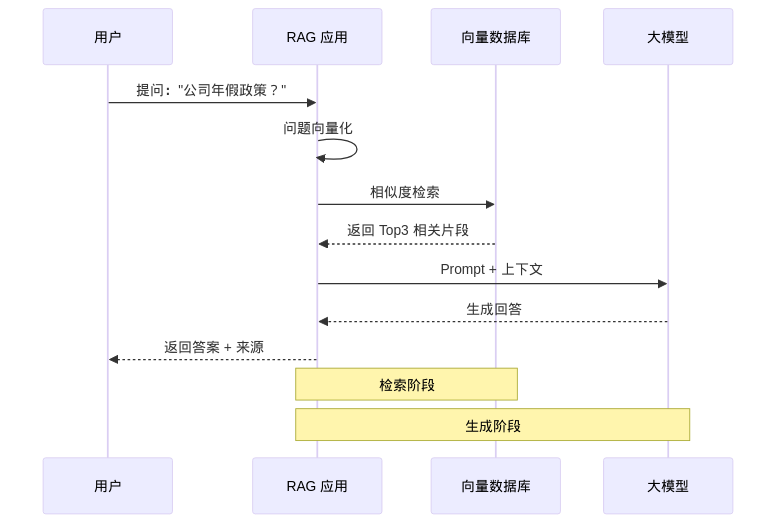
4.3 第一步:加载文档
# main.py from langchain.document_loaders import ( PyPDFLoader, TextLoader, UnstructuredMarkdownLoader ) from langchain.text_splitter import RecursiveCharacterTextSplitter def load_documents(doc_folder: str): """加载文档文件夹中的所有文档""" documents = [] # 加载 PDF pdf_loader = PyPDFLoader(f"{doc_folder}/employee-handbook.pdf") documents.extend(pdf_loader.load()) # 加载 TXT txt_loader = TextLoader(f"{doc_folder}/faq.txt") documents.extend(txt_loader.load()) # 加载 Markdown md_loader = UnstructuredMarkdownLoader(f"{doc_folder}/product-manual.md") documents.extend(md_loader.load()) return documents # 使用示例 docs = load_documents("./docs") print(f"加载了 {len(docs)} 个文档")
4.4 第二步:文本分块
为什么需要分块?
- 大模型有上下文长度限制(如 4K、8K tokens)
- 检索时只需要相关片段,不需要整篇文档
- 分块太小丢失上下文,太大检索不精准
def split_documents(documents, chunk_size=500, chunk_overlap=50): """将文档切分成合适大小的块""" text_splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, # 每块 500 字符 chunk_overlap=chunk_overlap, # 块之间重叠 50 字符(保持上下文连贯) length_function=len, separators=["\n\n", "\n", "。", "!", "?", " ", ""] ) chunks = text_splitter.split_documents(documents) print(f"切分成 {len(chunks)} 个文本块") return chunks # 使用示例 chunks = split_documents(docs) print(f"第一个文本块内容:{chunks[0].page_content[:200]}...")
4.5 第三步:向量化并存储
from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import Chroma import os def create_vector_store(chunks, persist_directory="./chroma_db"): """创建向量数据库""" # 使用中文 Embedding 模型 embeddings = HuggingFaceEmbeddings( model_name="shibing624/text2vec-base-chinese", model_kwargs={'device': 'cpu'} ) # 创建/加载向量数据库 vectorstore = Chroma.from_documents( documents=chunks, embedding=embeddings, persist_directory=persist_directory ) print(f"向量数据库已保存到 {persist_directory}") return vectorstore # 使用示例 vectorstore = create_vector_store(chunks)
4.6 第四步:构建问答链
from langchain.chat_models import ChatOpenAI from langchain.chains import RetrievalQA def create_qa_chain(vectorstore, openai_api_key: str): """创建问答链""" # 初始化大模型 llm = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0.3, # 降低随机性,让回答更稳定 openai_api_key=openai_api_key ) # 创建检索问答链 qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", # 把所有检索结果拼接到 prompt 里 retriever=vectorstore.as_retriever( search_kwargs={"k": 3} # 每次检索返回 3 个最相关片段 ), return_source_documents=True # 返回来源文档(方便追溯) ) return qa_chain # 使用示例 qa_chain = create_qa_chain(vectorstore, os.getenv("OPENAI_API_KEY"))
4.7 第五步:开始问答!
def ask_question(qa_chain, question: str): """提问并获取回答""" result = qa_chain({"query": question}) print("=" * 50) print(f"问题:{question}") print(f"回答:{result['result']}") print("=" * 50) # 显示来源文档(可选) print("\n参考来源:") for i, doc in enumerate(result['source_documents'], 1): print(f"{i}. {doc.page_content[:100]}...") return result # 测试问答 ask_question(qa_chain, "公司的年假政策是什么?") ask_question(qa_chain, "产品 A 的核心功能有哪些?")
🎨 五、添加可视化界面(可选但推荐)
5.1 用 Streamlit 快速搭建 Web 界面
pip install streamlit
# app.py import streamlit as st from main import load_documents, split_documents, create_vector_store, create_qa_chain st.set_page_config(page_title="企业知识库问答", page_icon="🤖") st.title("🤖 企业知识库智能问答") st.markdown("---") # 侧边栏:上传文档 with st.sidebar: st.header("📚 知识库管理") uploaded_files = st.file_uploader( "上传文档", type=["pdf", "txt", "md"], accept_multiple_files=True ) if uploaded_files: st.success(f"已上传 {len(uploaded_files)} 个文档") # 主界面:问答区域 question = st.text_area("请输入你的问题:", height=100) if st.button("🔍 开始问答", type="primary"): if not question.strip(): st.warning("请输入问题") else: with st.spinner("正在思考中..."): # 调用 QA 链 result = qa_chain({"query": question}) st.subheader("💡 回答") st.write(result['result']) # 显示参考来源 with st.expander("📖 查看参考来源"): for i, doc in enumerate(result['source_documents'], 1): st.markdown(f"**来源{i}**: {doc.page_content}")
运行:
streamlit run app.py --server.port 8501
访问 http://localhost:8501 即可使用!
⚠️ 六、常见问题与避坑指南
6.1 检索结果不相关怎么办?
可能原因:
- Embedding 模型不适合中文
- 分块大小不合理
- 检索参数 k 值太小
解决方案:
# 换用中文优化的 Embedding 模型 embeddings = HuggingFaceEmbeddings( model_name="shibing624/text2vec-base-chinese" # ✅ 中文优化 ) # 调整分块大小 chunks = split_documents(docs, chunk_size=300, chunk_overlap=30) # 增加检索数量 retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
6.2 回答太笼统/太简短怎么办?
优化 Prompt:
from langchain.prompts import PromptTemplate template = """ 你是一个专业的企业知识库助手。请根据以下参考资料回答问题。 要求: 1. 回答要详细、具体,不要泛泛而谈 2. 如果资料中没有相关信息,请直接说"不知道",不要编造 3. 尽量引用资料中的具体数据、条款 参考资料: {context} 问题:{question} 回答: """ prompt = PromptTemplate( template=template, input_variables=["context", "question"] )
6.3 处理大量文档时的性能问题
优化方案:
-
使用批量处理
-
增量更新向量库
-
使用更高效的向量数据库(如 Milvus)
# 批量处理文档 from langchain.text_splitter import RecursiveCharacterTextSplitter def batch_process(documents, batch_size=100): for i in range(0, len(documents), batch_size): batch = documents[i:i+batch_size] # 处理这一批... yield batch
📊 七、效果评估与优化
7.1 如何评估 RAG 系统好不好用?
| 组件 | 作用 | 推荐方案 |
| **文档加载器** | 读取各种格式文档 | LangChain Document Loaders |
| **文本分块器** | 把长文档切成小块 | LangChain Text Splitters |
| **Embedding 模型** | 文本转向量 | sentence-transformers |
| **向量数据库** | 存储和检索向量 | ChromaDB(轻量)/ Milvus(企业级) |
| **大模型** | 生成最终回答 | GPT-4 / Claude / 通义千问 |
指标评估方法目标值**回答准确率**人工抽查 100 个问题>85%**响应时间**从提问到回答的耗时<3 秒**用户满意度**用户评分/反馈>4/5 分**检索召回率**相关资料是否被检索到>90%
7.2 持续优化方向
-
文档质量:定期更新知识库,删除过时内容
-
模型升级:跟踪更好的 Embedding 模型和大模型
-
用户反馈:收集 bad case,针对性优化
-
A/B 测试:对比不同参数配置的效果
🚀 八、进阶:企业级部署方案
8.1 高可用架构
┌─────────────┐ ┌─────────────┐ │ 负载均衡 │ │ 监控系统 │ │ (Nginx) │ │ (Prometheus)│ └──────┬──────┘ └─────────────┘ │ ▼ ┌─────────────┐ ┌─────────────┐ │ 应用服务器 │←──→ │ 向量数据库 │ │ (多实例) │ │ (集群) │ └─────────────┘ └─────────────┘
8.2 安全考虑
- 🔐 API Key 加密存储
- 🔐 用户权限控制
- 🔐 审计日志记录
- 🔐 数据脱敏处理
📝 总结
恭喜你完成了一个企业级 RAG 问答系统的搭建!
核心要点回顾:
-
RAG = 检索 + 生成,让大模型"开卷考试"
-
文档预处理是关键(加载 → 分块 → 向量化)
-
选择合适的 Embedding 模型和向量数据库
-
持续优化:根据用户反馈迭代
下一步:
- 部署到生产环境
- 接入企业微信/钉钉
- 收集用户反馈,持续优化
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)