一文搞明白模型里面的文件都是干嘛的
·
文件总览
Qwen3 模型文件夹里的文件,按作用分成几类,用大白话讲清楚👇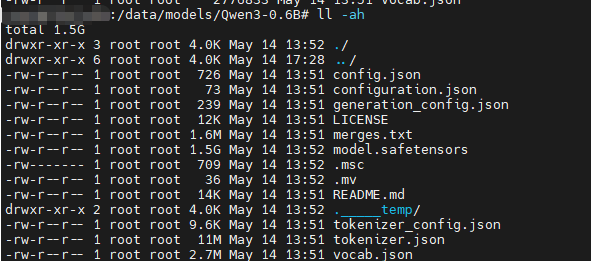
1. 模型架构与配置文件(“说明书”)
这些文件定义了模型长什么样、怎么运行,是加载模型时必须读取的配置。
config.json
模型的“架构说明书”,里面写了层数、注意力头数、隐藏层维度、上下文长度、词表大小等核心参数。没有它,代码根本不知道怎么把模型搭起来。generation_config.json
模型生成文本时的“行为规则”,比如默认的温度、top-p、最大生成长度、重复惩罚等参数。它控制着模型回答时的风格和策略。
2. 分词器文件(“翻译官”)
这些文件负责把你输入的文字,转换成模型能看懂的数字(token id),再把模型输出的数字变回文字。
tokenizer.json/vocab.json/merges.txt
分词器的核心配置和词表。vocab.json里存着模型认识的所有词(token)和对应的编号,merges.txt定义了分词的合并规则,合起来实现了 BPE 分词算法。tokenizer_config.json
分词器的额外配置,比如特殊标记(<|endoftext|>、用户/助手标记)、padding 策略等。
3. 模型权重文件(“大脑本体”)
这些文件是模型真正的“知识”所在,里面存着训练好的所有参数(权重)。
model.safetensors/pytorch_model.bin(或分片文件如model-00001-of-00002.safetensors)
这是模型的主体,所有层的权重(注意力权重、FFN权重、词嵌入权重等)都存在这里。safetensors是现在更推荐的格式,加载更快、更安全,避免了旧格式的安全风险。model.index.json(如果是分片权重)
记录了权重分片文件和模型各层的对应关系,加载时会根据这个文件找到对应的参数。
4. 辅助与元数据文件
README.md/LICENSE
模型说明文档和许可证,记录模型的用途、限制和版权信息。.gitattributes
用于 Git LFS(大文件存储)的配置,在 Hugging Face 上托管大文件时会用到。- 其他
.txt/.py文件
有些模型会附带示例代码、测试脚本或额外的说明文件,方便用户快速上手。
💡 简单总结一下它们的工作流程:
- 用
config.json搭好模型的“骨架” - 用
model.safetensors给骨架填上“肌肉和知识” - 用
tokenizer文件把你的文字转换成模型能懂的信号 - 用
generation_config控制模型怎么生成回答
文件具体作用
config.json 解读
root@f10r1n06:/data/models/Qwen3-0.6B# cat config.json
{
"architectures": [
"Qwen3ForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 1024,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 40960,
"max_window_layers": 28,
"model_type": "qwen3",
"num_attention_heads": 16,
"num_hidden_layers": 28,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000,
"sliding_window": null,
"tie_word_embeddings": true,
"torch_dtype": "bfloat16",
"transformers_version": "4.51.0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 151936
}
字段逐行解读表
| 字段 | 数值 | 大白话含义 | 部署/推理影响 |
|---|---|---|---|
| architectures | Qwen3ForCausalLM | 模型架构:因果语言大模型 | 框架靠这个识别加载模型结构 |
| attention_bias | false | 注意力层不添加偏置 | Qwen 固定设计,无需修改 |
| attention_dropout | 0.0 | 注意力层不做随机丢弃 | 推理输出更稳定,无随机扰动 |
| bos_token_id | 151643 | 对话起始符 `< | im_start |
| eos_token_id | 151645 | 对话结束符 `< | im_end |
| head_dim | 128 | 单个注意力头维度 | Qwen3 特殊GQA排布,不用改 |
| hidden_act | silu | 中间层激活函数 | 大模型标准非线性激活 |
| hidden_size | 1024 | 模型主干隐藏层维度 | 决定模型基础能力,越大越吃显存 |
| initializer_range | 0.02 | 权重初始化标准差 | 仅训练用,推理无效 |
| intermediate_size | 3072 | FFN前馈网络中间维度 | 影响模型理解、推理能力 |
| max_position_embeddings | 40960 | 模型原生最大上下文长度 | vLLM --max-model-len 不能超过这个值 |
| max_window_layers | 28 | 滑动窗口最大层数 | 配合滑动窗口使用 |
| model_type | qwen3 | 模型类型标识 | 框架匹配Qwen3专属逻辑 |
| num_attention_heads | 16 | Query注意力头数量 | 16头Q |
| num_hidden_layers | 28 | Transformer总层数 | 一共28层网络 |
| num_key_value_heads | 8 | Key/Value注意力头数量 | 8头KV,GQA分组注意力,省显存提速 |
| rms_norm_eps | 1e-06 | 归一化极小值 | 防止除0,固定参数不用改 |
| rope_scaling | null | 位置编码缩放 | 未做长度外扩,原生配置 |
| rope_theta | 1000000 | ROPE位置编码基数 | Qwen3特色,擅长长文本 |
| sliding_window | null | 滑动窗口大小 | 不启用局部注意力窗口 |
| tie_word_embeddings | true | 输入输出词权重共享 | 小模型省参数量、省显存 |
| torch_dtype | bfloat16 | 模型默认精度 | vLLM直接用bf16即可,显卡标配 |
| transformers_version | 4.51.0 | 训练依赖版本 | 仅版本记录,不影响推理 |
| use_cache | true | 开启KV缓存 | 必须开,vLLM靠这个加速生成 |
| vocab_size | 151936 | 模型词表总数量 | 模型能识别的token总数 |
核心部署小结
- 最大上下文限制:40960,vLLM 设参数别超
- 结构:28层、16Q/8KV GQA、隐藏维度1024
- 自带权重绑定,省显存;默认bf16直接跑
- 内置正确bos/eos,vLLM自动识别停词
generation_config.json解读
root@f10r1n06:/data/models/Qwen3-0.6B# cat generation_config.json
{
"bos_token_id": 151643,
"do_sample": true,
"eos_token_id": [
151645,
151643
],
"pad_token_id": 151643,
"temperature": 0.6,
"top_k": 20,
"top_p": 0.95,
"transformers_version": "4.51.0"
}
generation_config.json 是大模型文本生成的“行为说明书”,决定模型回答的随机性、风格、长度、停止条件。
生成配置参数表格
| 字段名 | 值 | 作用解读(大白话) |
|---|---|---|
| bos_token_id | 151643 | 句子开头标记的ID,模型用它识别一段文本的开始 |
| do_sample | true | 开启随机采样,回答更自然、多样;false=固定贪心输出 |
| eos_token_id | [151645, 151643] | 句子结束标记ID列表,模型遇到就停止生成 |
| pad_token_id | 151643 | 填充标记ID,用于把不同长度的文本补齐到相同长度 |
| temperature | 0.6 | 生成温度,控制随机性:0=死板,1=多样,0.6偏自然 |
| top_k | 20 | 只从概率最高的前20个词里选,防止生成奇怪词汇 |
| top_p | 0.95 | 核采样,从**累计概率95%**的词汇里选,平衡多样性与稳定性 |
| transformers_version | 4.51.0 | 模型导出时使用的 HuggingFace 库版本 |
极简总结
- 151643 = 开始 + 填充 + 结束标记(多功能标记)
- 151645 = 额外结束标记
- temperature=0.6 = 回答自然、不呆板、不胡说
- top_k=20 + top_p=0.95 = 高质量、稳定生成


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)