day23_PyTorch自动微分与神经网络(上)
day23_PyTorch自动微分与神经网络(上)
写在前面
神经网络的内容比较多,因此拆分到两天来讲。
一、PyTorch自动微分
1. 什么是自动微分
自动微分(Automatic Differentiation, AD) 是 PyTorch 的核心功能之一,通过 torch.autograd 模块实现。它的作用就是帮我们自动计算梯度,不用再手动去推导数公式了。
在训练神经网络时,最常用的算法就是反向传播。简单说就是:模型做出预测 → 计算损失 → 根据损失反向调整每个参数的"责任大小"(即梯度)→ 更新参数。这个"计算梯度"的步骤,PyTorch 的 autograd 全自动搞定。
核心的使用方式就两个:
backward()— 反向传播,计算梯度.grad— 查看某个张量的梯度值
⚠️ 重要限制:PyTorch 不支持向量张量对向量张量的求导,只支持标量张量对向量张量的求导。也就是说
loss必须是一个标量(一个值)才能调用backward()。
2. 梯度基本计算
先看一个最简单的例子,对单个权重求梯度:
import torch
# 开启自动微分:requires_grad=True
w = torch.tensor([10, 20], requires_grad=True, dtype=torch.float)
# 定义损失函数
loss = 2 * w ** 2
# 反向传播求梯度(loss必须是标量,所以用sum()汇总)
loss.sum().backward()
print(f"当前权重: {w.data}")
print(f"梯度: {w.grad}")
print(f"更新后权重(lr=0.01): {w.data - 0.01 * w.grad}")
# 手动更新权重:w = w - lr * grad
w.data = w.data - 0.01 * w.grad
输出结果:
当前权重: tensor([10., 20.])
梯度: tensor([40., 80.])
更新后权重(lr=0.01): tensor([9.6000, 19.2000])
🔑 注意:
.grad会累加梯度值,也就是说多次调用backward()梯度会叠加。所以一般在每次反向传播前需要梯度清零(optimizer.zero_grad())。
3. 多参数梯度更新(w 和 b)
实际训练中,我们往往同时更新权重矩阵 w 和偏置 b:
import torch
# 准备训练数据
x = torch.ones(2, 5) # 输入:2个样本,每个5个特征
y = torch.zeros(2, 3) # 标签:2个样本,每个3个输出
# 权重和偏置,开启自动微分
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
# 1. 定义损失函数
loss_fn = torch.nn.MSELoss()
# 2. 计算预测值:z = wx + b(矩阵乘法)
z = x.matmul(w) + b
# 3. 计算损失
loss = loss_fn(z, y)
# 4. 反向传播,推导梯度
loss.sum().backward()
# 查看梯度
print(f"w.grad:\n{w.grad}")
print(f"b.grad:\n{b.grad}")
这段代码就是神经网络训练的雏形:给定输入 → 线性变换 → 计算损失 → 反向传播 → 得到梯度。下一步就是用梯度去更新参数了。
📝 总结:需要对梯度计算的张量,设置
requires_grad=True;计算梯度调用backward();查看梯度用.grad;注意梯度会累加,训练前记得清零。
二、人工神经网络基础
1. 什么是神经网络
人工神经网络(Artificial Neural Network, ANN) 简称神经网络,是一种模仿生物神经网络结构和功能的计算模型。
人脑有大量的神经元,每个神经元通过树突接收信号,在细胞核中汇总处理,当电位达到阈值后通过轴突输出信号。人工神经网络就是把这个过程数学化了:
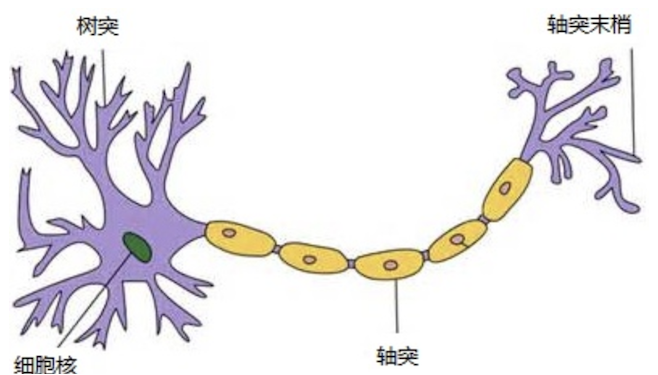
一个神经元的计算过程:
- 输入信号 xxx 乘以各自的权重 www
- 加权求和得到内部状态值 z=w⋅x+bz = w \cdot x + bz=w⋅x+b
- 通过激活函数 fff 得到激活值 a=f(z)a = f(z)a=f(z)
🔑 一句话:神经元 = 加权求和 + 激活函数
2. 神经网络的结构
一个完整的神经网络由三层组成:
| 层级 | 作用 |
|---|---|
| 输入层(Input Layer) | 接收原始数据(图像、文本、声音等),每个特征对应一个神经元 |
| 隐藏层(Hidden Layers) | 输入层和输出层之间的所有层,神经网络的"深度"就由隐藏层数量决定 |
| 输出层(Output Layer) | 输出最终预测结果,根据任务类型(回归/分类)设计神经元数量 |
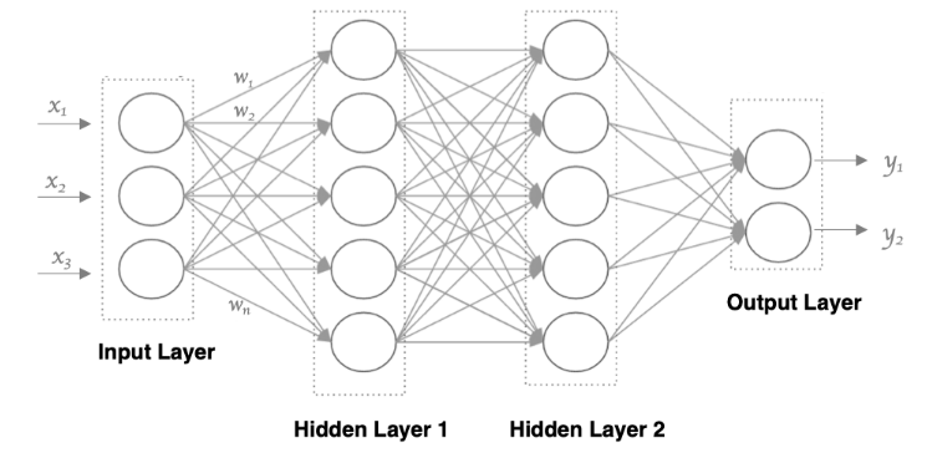
特点:
- 同一层的神经元之间没有连接
- 第 N 层的每个神经元和第 N-1 层的所有神经元相连(全连接)
- 每个连接都有权重 www 和偏置 bbb
- 数据以二维形式在层间传递(batch_size, features)
3. 内部状态值与激活值
每个神经元在前向传播时会产出两个值:
- 内部状态值:z=W⋅x+bz = W \cdot x + bz=W⋅x+b(加权求和的结果)
- 激活值:a=f(z)a = f(z)a=f(z)(经过激活函数变换后的结果)
在反向传播时,还会产出对应的梯度值用于参数更新。
三、激活函数
1. 激活函数的作用
激活函数的核心作用就是引入非线性因素。如果不加激活函数,无论堆多少层网络,本质上还是一个线性模型。加了激活函数,神经网络才能拟合各种复杂的曲线。
2. 常见激活函数
| 激活函数 | 公式 | 特点 | 适用场景 |
|---|---|---|---|
| Sigmoid | f(x)=11+e−xf(x) = \frac{1}{1+e^{-x}}f(x)=1+e−x1 | 输出(0,1),适合概率输出,但容易梯度消失 | 二分类输出层 |
| Tanh | f(x)=ex−e−xex+e−xf(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}f(x)=ex+e−xex−e−x | 输出(-1,1),均值为0,比Sigmoid好一点 | 隐藏层(备选) |
| ReLU | f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x) | 计算简单,不会在正区间饱和,但会出现Dead ReLU | 隐藏层首选 |
| SoftMax | f(xi)=exi∑jexjf(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}}f(xi)=∑jexjexi | 输出和为1的概率分布 | 多分类输出层 |
Sigmoid
Sigmoid 的函数图像呈 S 形,将输入映射到 (0, 1) 区间:
import torch
import matplotlib.pyplot as plt
# 绘制 Sigmoid 函数图像
x = torch.linspace(-20, 20, 1000)
y = torch.sigmoid(x)
plt.plot(x, y)
plt.grid()
plt.title('Sigmoid 函数图像')
plt.show()
# 绘制 Sigmoid 导数图像
x = torch.linspace(-20, 20, 1000, requires_grad=True)
torch.sigmoid(x).sum().backward()
plt.plot(x.detach(), x.grad)
plt.grid()
plt.title('Sigmoid 导数图像')
plt.show()
Tanh
Tanh 是 Sigmoid 的升级版,输出范围 (-1, 1),均值为 0:
x = torch.linspace(-20, 20, 1000)
y = torch.tanh(x)
plt.plot(x, y)
plt.grid()
plt.title('Tanh 函数图像')
plt.show()
ReLU(推荐首选)
ReLU 是目前最常用的激活函数,在正区间不会饱和:
x = torch.linspace(-20, 20, 1000)
y = torch.relu(x)
plt.plot(x, y)
plt.grid()
plt.title('ReLU 函数图像')
plt.show()
💡 ReLU 的缺点:当输入为负数时,梯度为 0,会导致神经元"死亡"(Dead ReLU)。可以使用 Leaky ReLU 等变体缓解。
SoftMax(多分类专用)
SoftMax 将网络输出的 logits 转换成概率分布,所有输出值之和为 1:
scores = torch.tensor([0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.05, 3.75])
probabilities = torch.softmax(scores, dim=0)
print(probabilities)
# tensor([0.0212, 0.0177, 0.0202, 0.0202, 0.0638, 0.0287, 0.0185, 0.0522, 0.0183, 0.7392])
可以看到,值最大的位置(3.75)对应的概率也最高(0.7392)。
3. 激活函数选择指南
| 位置 | 推荐选择 |
|---|---|
| 隐藏层 | 优先选 ReLU,效果不好再试 Leaky ReLU 等,少用 Sigmoid |
| 二分类输出层 | Sigmoid |
| 多分类输出层 | SoftMax |
| 回归输出层 | 恒等(Identity)(不加激活函数) |
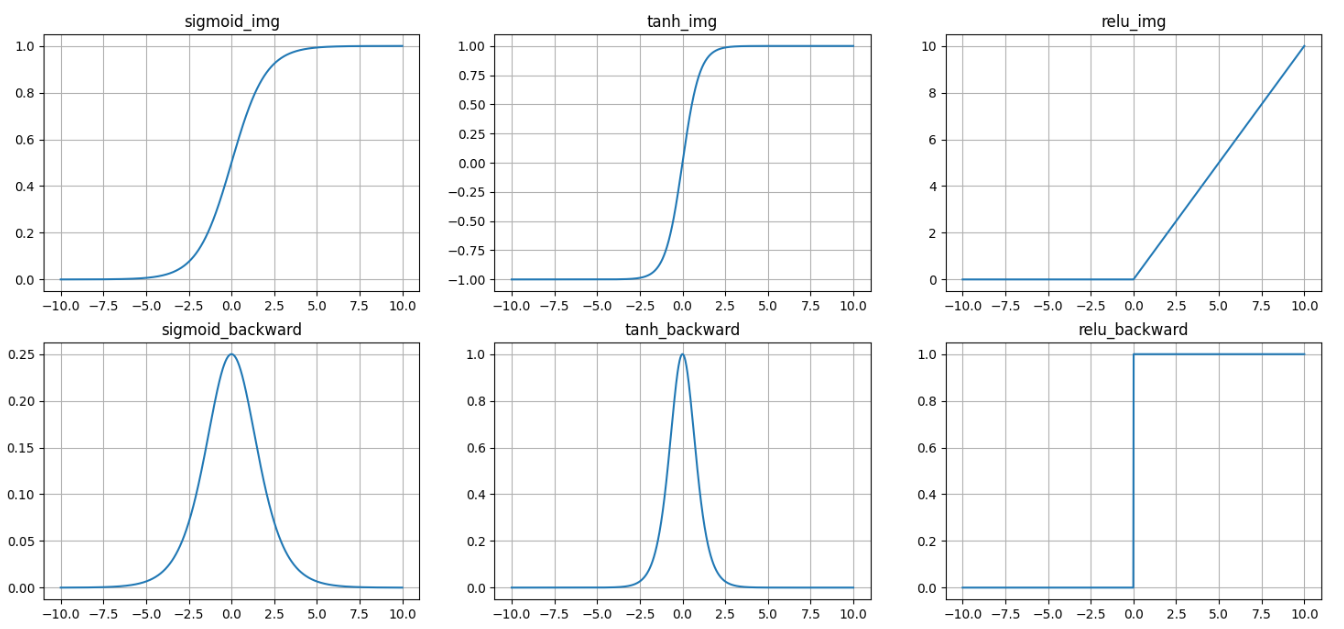
4.激活函数可视化
"""可视化三种常见激活函数(sigmoid、tanh、ReLU)及其梯度曲线。"""
import torch
from matplotlib import pyplot as plt
# ========== 激活函数曲线 ==========
# linspace: 在 [-10, 10] 上均匀取 1000 个点
# requires_grad=True 让 PyTorch 追踪计算图,后续可以求梯度
x1 = torch.linspace(start=-10, end=10, steps=1000, requires_grad=True)
y1 = torch.sigmoid(x1)
x2 = torch.linspace(start=-10, end=10, steps=1000, requires_grad=True)
y2 = torch.tanh(x2)
x3 = torch.linspace(start=-10, end=10, steps=1000, requires_grad=True)
y3 = torch.relu(x3)
# subplots(行数, 列数) → 创建 2 行 3 列的画布,figsize=(宽, 高) 英寸
# _ 是 Figure 对象(画布),axs 是 2×3 的 Axes 数组(每个子图就是一个 Axes)
_, axs = plt.subplots(2, 3, figsize=(18, 8))
# axs[行, 列] 定位子图;plot(x, y) 在该子图上画线
# detach() 断开计算图(否则带 grad 的 tensor 不能转 numpy)
# .numpy() 将 tensor 转为 matplotlib 能识别的 numpy 数组
axs[0, 0].plot(x1.detach().numpy(), y1.detach().numpy())
axs[0, 0].set_title("sigmoid_img") # 子图标题
axs[0, 0].grid(True) # 显示网格
axs[0, 1].plot(x2.detach().numpy(), y2.detach().numpy())
axs[0, 1].set_title("tanh_img")
axs[0, 1].grid(True)
axs[0, 2].plot(x3.detach().numpy(), y3.detach().numpy())
axs[0, 2].set_title("relu_img")
axs[0, 2].grid(True)
# ========== 梯度曲线 ==========
# 利用 PyTorch autograd 自动求导:
# 1. 对函数值求和 → sum() 得到一个标量
# 2. backward() 自动计算该标量对所有 requires_grad 输入(即 x)的梯度
# 3. 梯度结果保存在 x.grad 中(形状与 x 相同)
# 原理:d(Σsigmoid(x_i))/dx_i = sigmoid'(x_i),恰好得到每个点的导数值
torch.sigmoid(x1).sum().backward()
y1 = x1.grad
torch.tanh(x2).sum().backward()
y2 = x2.grad
torch.relu(x3).sum().backward()
y3 = x3.grad
axs[1, 0].plot(x1.detach().numpy(), y1.detach().numpy())
axs[1, 0].set_title("sigmoid_backward")
axs[1, 0].grid(True)
axs[1, 1].plot(x2.detach().numpy(), y2.detach().numpy())
axs[1, 1].set_title("tanh_backward")
axs[1, 1].grid(True)
axs[1, 2].plot(x3.detach().numpy(), y3.detach().numpy())
axs[1, 2].set_title("relu_backward")
axs[1, 2].grid(True)
# 显示整个画布(不调用的话图形不会弹出)
plt.show()
代码运行结果
四、参数初始化
1. 常见初始化方法
PyTorch 在 torch.nn.init 中提供了丰富的初始化方法:
| 初始化方法 | 函数 | 说明 |
|---|---|---|
| 均匀分布 | nn.init.uniform_(tensor) |
从 (0,1) 均匀分布采样 |
| 正态分布 | nn.init.normal_(tensor, mean=0, std=1) |
从标准正态分布采样 |
| 全0初始化 | nn.init.zeros_(tensor) |
所有权重置为 0 |
| 全1初始化 | nn.init.ones_(tensor) |
所有权重置为 1 |
| 固定值初始化 | nn.init.constant_(tensor, val) |
所有权重设为固定值 |
| Kaiming(HE)初始化 | nn.init.kaiming_normal_() / nn.init.kaiming_uniform_() |
适合ReLU系列 |
| Xavier(Glorot)初始化 | nn.init.xavier_normal_() / nn.init.xavier_uniform_() |
适合Sigmoid/Tanh |
import torch.nn as nn
linear = nn.Linear(5, 3)
# 均匀分布初始化
nn.init.uniform_(linear.weight)
# Kaiming正态分布初始化(ReLU推荐)
nn.init.kaiming_normal_(linear.weight)
# Xavier均匀分布初始化(Sigmoid/Tanh推荐)
nn.init.xavier_uniform_(linear.weight)
2. 初始化方法选择
| 激活函数 | 推荐初始化 |
|---|---|
| Sigmoid / Tanh | Xavier 初始化(Glorot) |
| ReLU / Leaky ReLU | Kaiming 初始化(HE) |
| 浅层网络 | 随机初始化即可 |
| 深层网络 | 需要方差平衡,选 Xavier 或 Kaiming |
📝 实际使用:PyTorch 每个网络层都有默认的初始化方法,通常优先用 Kaiming 或 Xavier。初学者可以先用默认设置。
五、总结
| 知识点 | 一句话总结 |
|---|---|
| 自动微分(autograd) | PyTorch自动计算梯度,backward()反向传播,.grad获取结果 |
| 人工神经网络 | 由输入层、隐藏层、输出层组成,每个神经元=加权和+激活函数 |
| 激活函数 | 引入非线性,隐藏层用ReLU,二分类输出用Sigmoid,多分类用SoftMax |
| 参数初始化 | Sigmoid/Tanh用Xavier,ReLU用Kaiming(PyTorch默认够用) |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)