从0到1:企业级AI项目迭代日记 Vol.25|不是个人助理,是业务系统——一个企业AI的完整自述
今天有同行来交流,对方也在做企业 AI,走的是类似的路子——接模型、做功能、找客户落地。不是谈合作,就是纯粹聊技术路线,各自做了什么、踩了哪些坑、对这件事的判断是不是一致。
这次对话有一种特殊价值:你得把自己做的东西讲得让对方听懂,这个过程里,你会发现什么东西真的想清楚了,什么东西自己还有些模糊。
看完这篇文章,你就知道我们这套系统现在实际是什么、怎么做的,以及 25 天走下来留下的几个判断。
一、我们在解决什么问题
企业部署 AI,通常卡在三件事:
信息散。 文档在每个人电脑里,系统各管各的,知识靠人传递,同一个问题要问三个人。
流程靠人跑。 从 A 系统取数、录到 B 系统、再通知 C——这条路每天有人在走,但没有人把它自动化,因为这些系统之间没有桥。
经验不沉淀。 熟悉流程的人离开,后来的人从头学。工作方法在脑子里,不在系统里。
对应这三件事,我们做的是:统一知识管理、Agent 代替人在系统间操作、工作流固化可重复执行。
二、系统实际怎么做的
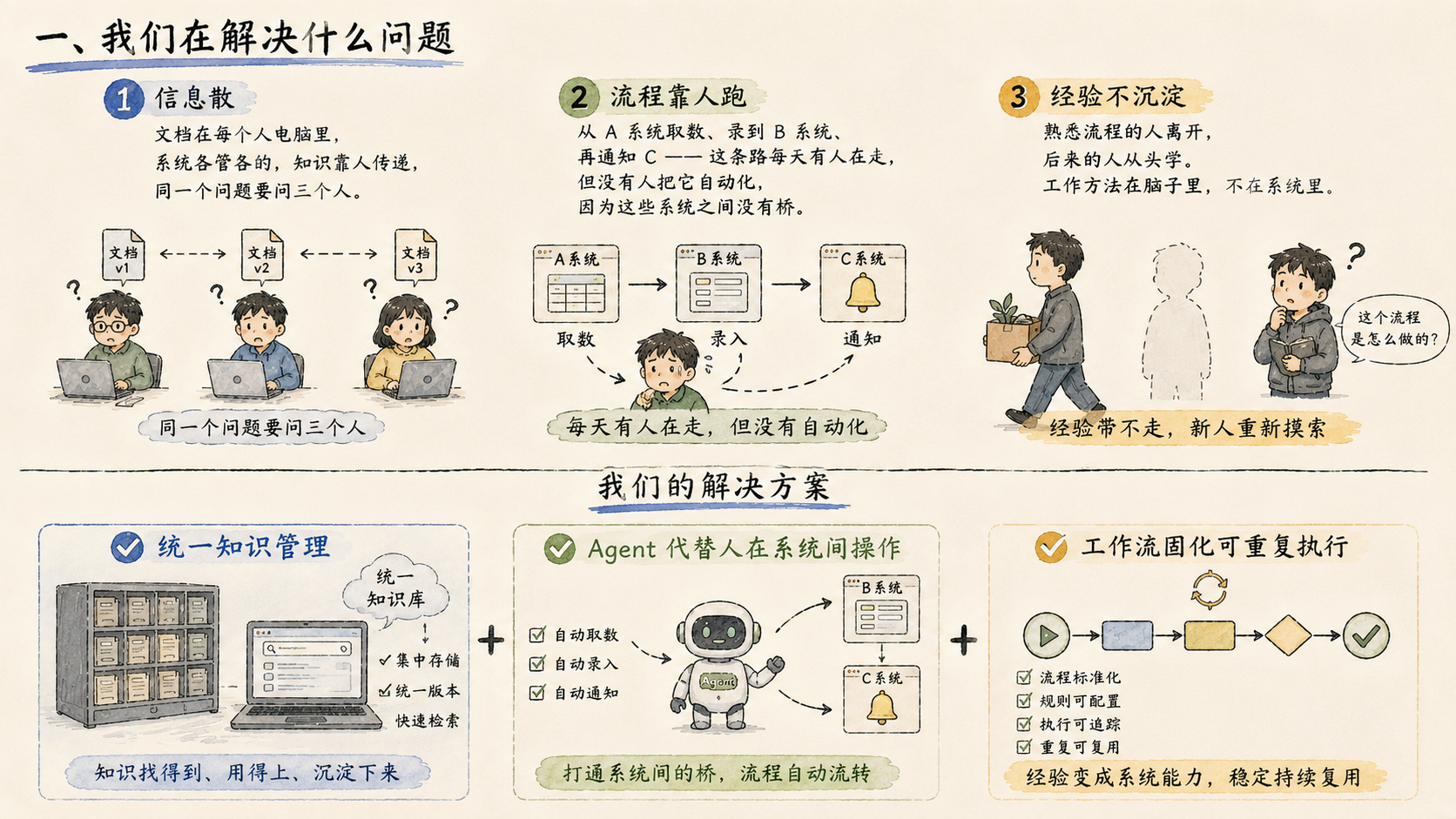
1.消息入口与调度
飞书和 Web 端两个入口,背后接同一套消息处理体系。跨渠道消息通过 NATS 消息队列进入统一 Orchestrator,再分发给对应 Agent 处理。记忆跨端共享,飞书的对话上下文同步到 Web 端可见。飞书端支持流式输出,消息卡片实时展示完成状态、耗时、调用模型、缓存命中等信息,不是等所有内容生成完再一次性返回。
2.执行核心:ReAct 循环
这是我们改动最大的一个架构决定。
原来:用户输入 → 意图识别节点 → 路由到处理链。每加一层判断就加一个可能失败的点。链路最深时有五六层,每层 80% 的成功率,五层级联后端到端只剩 33%。
现在:去掉意图路由节点,识别不了就直接进 ReAct 循环,模型自己推理用什么工具、怎么响应。工具描述写清楚,模型自行选择调用,不需要在前面再挂一个强制路由节点。所有模型节点,要么进 ReAct 循环,要么进 Plan-Execute,没有只调模型不带工具的孤立节点。
3.多 Agent 协同
系统不是单一助手,是一个 Agent 集群。不同 Agent 承担不同职责——通用对话、知识检索、工具执行、巡检诊断——由编排层根据角色、权限和上下文动态路由和协同调度。
复杂任务支持多种协作模式:多个 Agent 交叉验证同一结果,或者分工并行处理不同子任务,或者各自执行后汇总到同一个结果空间。今天演示时,用户描述了一个需求,系统派出子 Agent 动态生成了对应的配置并直接挂载——整个过程不需要工程师介入。
4.工作流:LangGraph 真实循环图
早期把 LangGraph 当成流程编排工具用,把固定流程塞进图结构。后来发现这是把它当 if-else 用,根本没用上循环图的能力。重构之后,真正用上了 Checkpoint 持久化、人工审批挂起等待、断点续跑这套机制。
最难的地方是嵌套子图的断点恢复——人工审批节点在子图里时,父图原本感知不到子图的暂停状态,任务会卡住无法恢复。这个问题前两天刚解决,现在从主图到任意嵌套层级的子图,都可以在等待人工介入后正确恢复。
工作流在系统里是一个 “带描述的大工具” 。用户触发时,模型根据描述判断是否调用,和选普通工具是同一套机制,不需要额外的路由节点。工作流里可以包含人工节点、系统操作节点、跨角色流转——这些都可以被稳定承载。
5.工具层:业务系统原子化
把各业务系统的接口能力拆成原子化工具,挂载到 Agent 工具集。工具定义写清楚,模型自行选择调用,不需要硬编码“查什么信息调哪个接口”。
对于企业存量系统,支持让 AI 自动探索系统接口结构,整理成可调用的工具集,经人工审核后正式挂载——这样企业原来依赖人在系统间来回操作的步骤,可以逐步转移给 Agent 完成。
平台维护公共工具库和技能市场,管理员管理系统级工具;用户可以在权限范围内从中选配、组合成个性化 Agent,也可以在运行时自定义系统提示词、工具集、技能集、工作流、模型和接口地址。
6.知识库:双轨检索
文档入库后走两条处理路径:原文切片进向量库做语义检索;同时生成内容摘要,构建知识图谱做结构化检索。两路并行召回,由模型判断引用哪部分。原始文件完整保留,以便模型升级后重新向量化处理。
RAG 不是每次必走,由意图推断决定是否触发。意图识别的 Temperature 设为 0,防止结果飘移。
知识入库支持三条路径:管理后台直接上传、聊天中上传文件并发指令入库、飞书传文件后指令入库。上传的文件也可以只进入当前对话的即时上下文而不入库,两种用途都支持。目前支持 Word、PDF、TXT、音频文件的读取与处理。
7.会话记忆:三层管理
会话内通过 Token 阈值压缩保留关键信息;会话间的短期记忆体量小,直接注入上下文,不走向量召回;长期记忆才进向量库做语义检索。不是所有记忆都走 RAG——召回成本和精度在不同时间维度下差异很大,分层处理是为了在效果和成本之间找到平衡。
三、企业级意味着什么
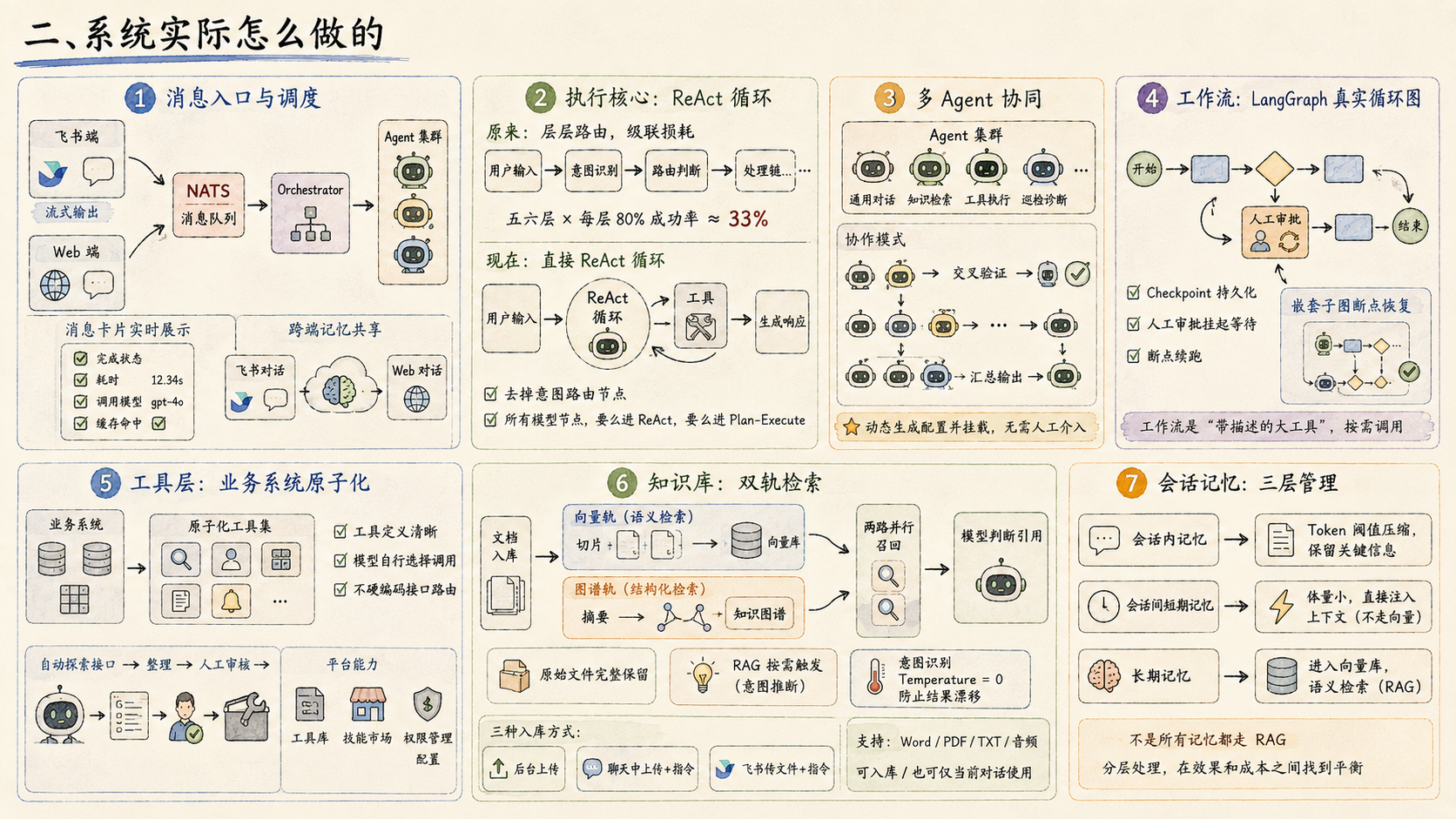
1.权限与访问控制
用户角色与 Agent 绑定,Agent 只能访问被授权的工具集和知识源。权限边界在代码层面约束,不是靠提示词限制的。管理员在后台统一管理 Agent 配置、角色绑定、知识源授权和系统运行参数。
2.执行追踪与审计
Web 端右侧面板实时展示每个节点的执行状态、调用的工具、响应耗时,让系统在做什么对用户始终可见。飞书端消息卡片上带状态标,任务完成后显示完整的耗时、模型、缓存和上下文信息。每一步操作都有迹可查,审计日志覆盖主要链路。
3.部署
支持云端部署,也支持本地私有化部署,接本地开源模型,满足数据不出域的需求。工程层面覆盖 Kubernetes 部署、Helm 打包、数据库迁移、环境隔离、限流和运行时治理,有完整的从研发到测试再到生产的交付路径。
四、几个没变过的判断
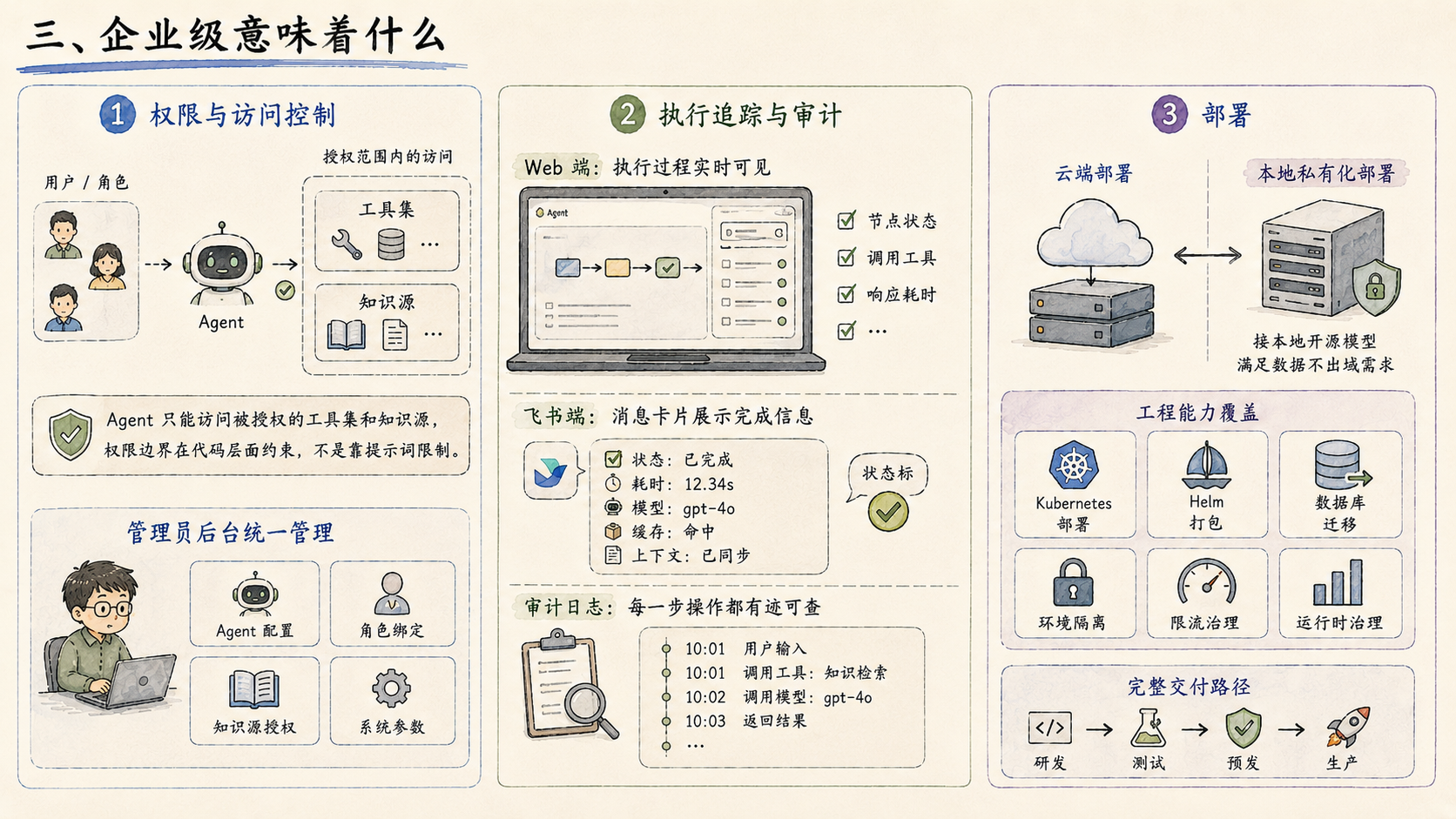
-
边界靠架构卡,不靠提示词。 模型会漂移,关键限制必须在代码层面通过架构和权限机制实现,不能只写进系统提示词就算数。
-
不依赖模型主动性。 关键动作由系统强制触发,不能寄希望于模型在正确时机自己做正确的事。
-
续跑优于降级。 原来设计的是“超时就返回固定回复”,现在设计的是“任何时刻都能续跑”。用户能接受等待,不能接受中断。 Checkpoint 是这个原则的工程实现。
-
端到端成功率才是真成功率。 每个模块单独测都正常,不代表链路跑得通。评估指标必须是完整链路,而不是单节点通过率。
还没解决的也没有回避: 用户本地存量文件没有办法批量同步进知识库;SSE 连接刷新后会断流;用户手动配置过工具后,系统后续新增的默认工具对他不可见。这些是接下来要解决的问题。
这,是第二十五天。
《从0到1:企业级AI项目迭代日记》记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)