大模型淘金热里的“卖水人”:为什么说 Hyperouter 可能是你下一个 API 入口?

2026 年 5 月,大模型的价格战终于打到了一个荒诞又理所当然的节点。
一边是头部厂商把缓存命中价向上微调,另一边,高性价比模型在聚合平台上的价格几乎探底。开发者的痛点不再是“哪个模型最强”,而是“我今天该用哪个 API 地址”——模型接入的碎片化,正在催生一层全新的基础设施:API 网关。
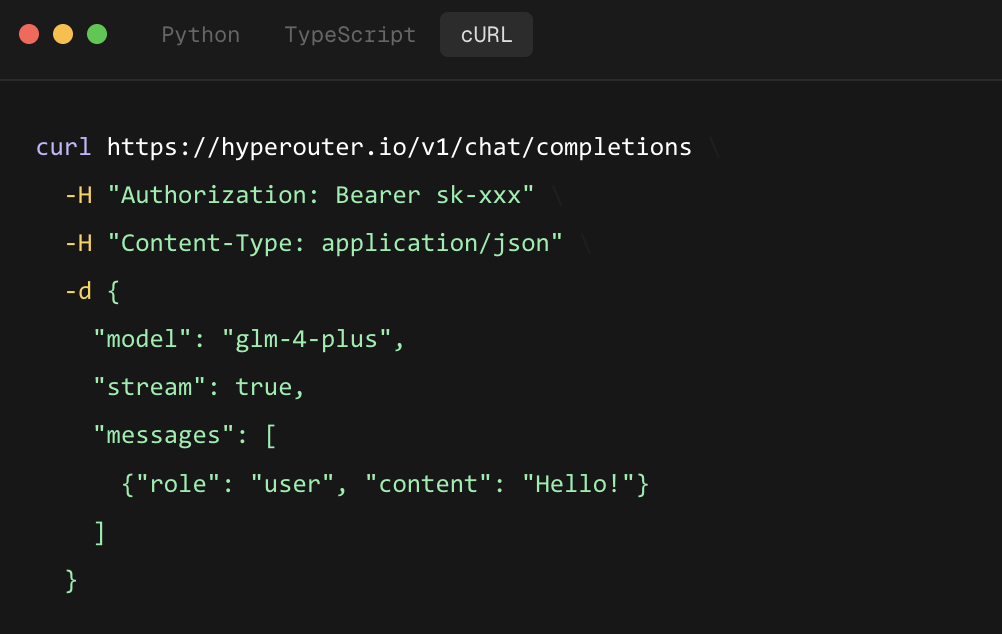
全球 AI 网关市场正以惊人的速度增长,有机构预测到 2032 年规模将达 2.44 亿美元,年复合增长率超过 45%。在这个赛道里,一个名为 Hyperouter 的新平台,正试图用一句简单的话打动开发者:只需替换 Base URL,你就能在 OpenAI、Anthropic、Gemini 三种协议之间自由切换。更妙的是,这一切都不需要改代码。
这大概率是开发者正在寻找的那把“万能钥匙”。

一、一句话看懂 Hyperouter:它会说三种“模型语言”
打开 Hyperouter 官网,最打动人的不是模型列表,而是这一行:
统一的大模型接口网关。兼容 OpenAI、Anthropic、Gemini 多种 API 格式,支持协议互转,只需替换 Base URL 即可接入。
如果你是开发者,这意味着什么?
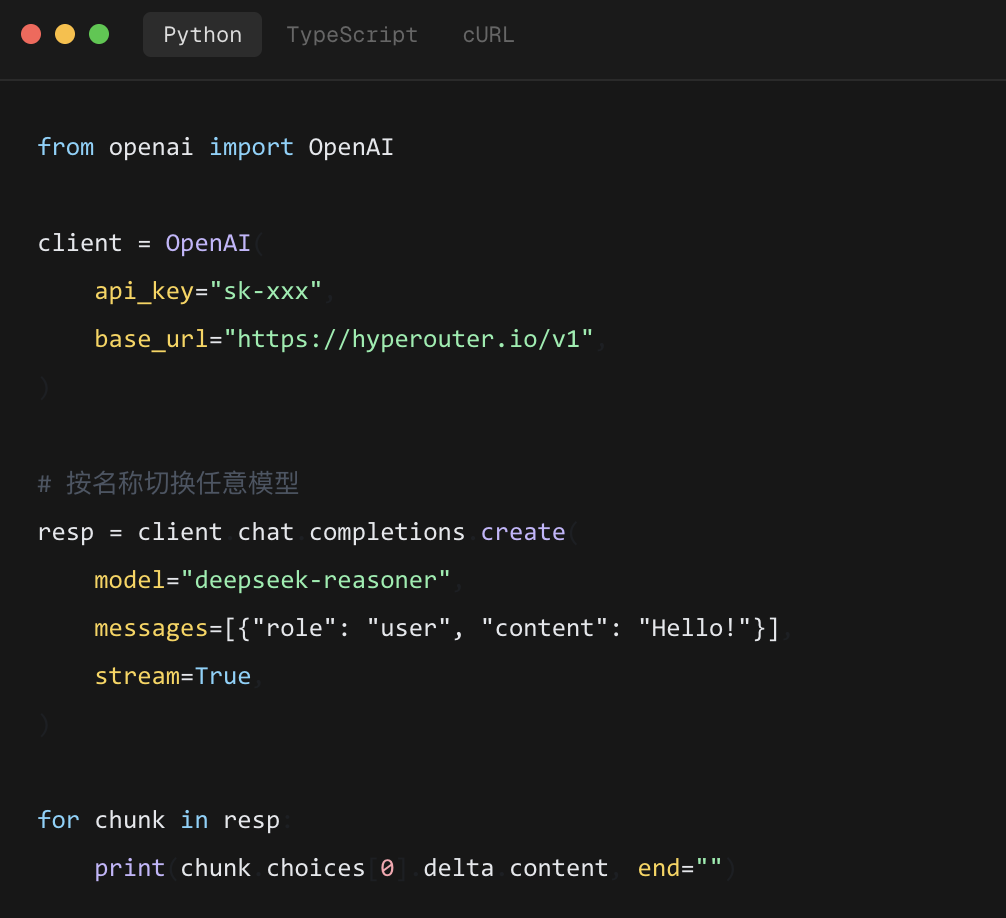
你写了一段标准的 openai Python SDK 代码,调的是 model="claude-sonnet-4-20250514",但底层实际请求的是 Anthropic 的原生接口。返回的结果却被无缝地包装成 OpenAI 格式,你的流式处理、异常捕获都不需要改。甚至,你也可以用 Anthropic 的原生 SDK 去请求 Gemini——Hyperouter 在中间自动做了翻译。
这是一种极高灵活度的解耦。用行话说,Hyperouter 是一个“协议胶水”工厂。它不造模型,只负责把不同供应商的接口统一成开发者顺手的样子。对已经陷入“多模型适配地狱”的团队来说,这可能是今年最值得试用的一个小工具。
二、协议互转:一个被低估的开发者体验革命
多数网关都在做“统一入口、多模型路由”。Hyperouter 的差异化在哪?就是“协议互转”。
还原一个真实场景:你的聊天应用是用 OpenAI SDK 写的,一直跑得很稳。后来为了处理超长文档,你买了 Claude,但它的 Messages API 和 OpenAI 的 Chat Completions 不完全一样;再后来,你内部工具链又接上了 Gemini。三套代码、三套鉴权、三种错误处理,维护起来如同噩梦。
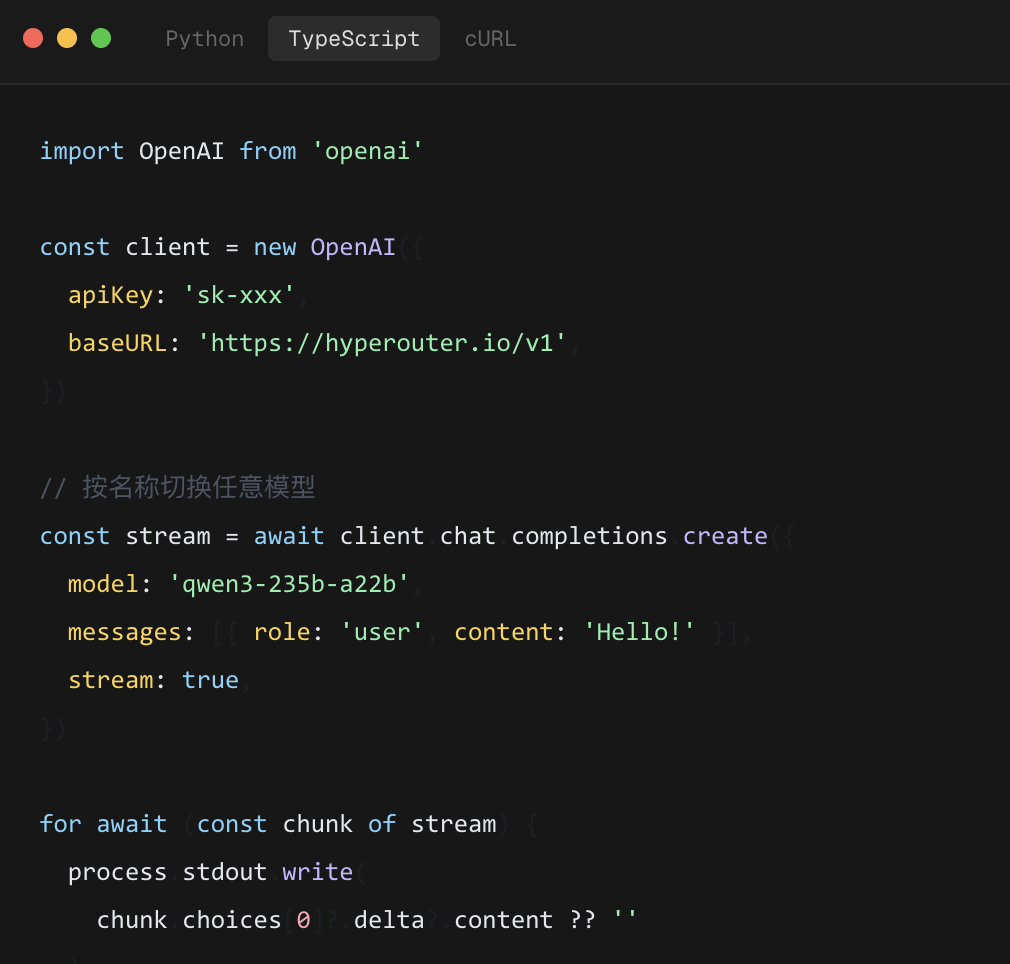
Hyperouter 的思路是:既然客户端只想说一种语言,那就让网关来当翻译官。你保持一套代码,在请求中指定模型名即可,网关自动完成参数映射、认证转换、响应格式适配。更厉害的是,它允许你“用 Anthropic 格式请求 OpenAI 模型”——这在多语言客户端环境下价值极大。
可以这样理解:OpenAI 的格式正在成为行业事实标准,但 Anthropic 和 Gemini 的原生接口也有各自的性能优化。Hyperouter 不强制你迁移格式,而是让每种格式都能访问所有模型。这种开放度,在目前的网关市场里非常少见。
三、不只是转发:一个正在变“厚”的开发者工具箱
如果你以为 Hyperouter 只是一个“请求转发器”,那就小看它了。它的产品矩阵正在快速变厚:
-
智能负载均衡 & 故障转移:自动选择最快可用的上游,供应商故障时无缝切换,开发者连感知都不需要。
-
Prompt 语义缓存:自动缓存重复请求,降低延迟和成本。有数据表明,这类缓存在客服等场景可节省 30% 以上的 Token 开销。
-
用量看板与成本分析:按模型、按团队统计 Token 消耗、延迟分布和费用明细,还能导出或通过 API 查询。
-
团队密钥管理:为每个项目创建不同权限的 API Key,设置速率限制、消费上限和有效期,预算管理一步到位。
-
消费预警:邮件、Webhook、飞书、钉钉多渠道告警,防止账单暴雷。
-
完整审计日志:请求级记录,可搜索、可导出,满足企业合规需求。
换言之,Hyperouter 已经不是一个轻量级代理,而是一个完整的 AI 流量治理平台。它把原本分散在多个 SaaS 里的能力整合进了一个 Base URL 后面。对于从单人开发到中型团队的用户来说,这种“开箱即用”的体验会省下大量搭建和维护成本。
四、供应商中立的底气:不绑定任何一家模型
网关最忌讳的事是什么?变成某家模型的高级代理。一旦网关和某家供应商深度绑定,它就丢掉了作为“调度层”的独立性。
从产品设计上看,Hyperouter 显然非常清楚这一点。它的所有治理功能——密钥管理、看板、缓存、告警——都与模型无关。你的监控体系和预算策略,不会因为底层模型从 A 换成 B 而产生任何变化。模型目录也会持续扩展,保持供应商中立。
这种“接入层”与“模型层”的解耦,带来的直接好处是:开发者可以随时拥抱市场上最合适、性价比最高的模型,而不用被迫跟着某一家走。在模型价格战白热化、新模型层出不穷的当下,保持切换的自由本身就是一种降本增效。
五、开发者到底能得到什么?算一笔体验账
如果你正在考虑试用 Hyperouter,下面几点可能是你立刻能感受到的:
-
零迁移成本。把
base_url改成https://hyperouter.io/v1,原有代码一行不动,API Key 换成平台颁发的密钥即可。 -
多模型极速切换。想对比不同模型的效果?只需要改请求里的
model参数,网关帮你找到对应的供应商。 -
一条密钥通吃。不用再去各个模型官网申请、管理一串 Key,一个 Hyperouter 密钥就能调用所有已接入模型。
-
成本肉眼可见地优化。自动缓存加上智能路由,能实实在在地降低重复请求的 Token 消耗,账单会变好看。
-
团队协作友好。可以给前端、后端、测试环境分配不同的 Key,各自有独立的限额和权限,再也不怕某个同事把额度跑光。
六、巨头的压力与网关的生存之道
当然,网关赛道并非一片蓝海。OpenRouter 正在融资上亿美元,Cloudflare 把 AI Gateway 嵌入了其庞大的网络矩阵,IBM 和 Palo Alto Networks 也在今年相继入场。相比这些巨头,Hyperouter 还很年轻。
但如果我们回顾技术发展史,任何一个平台型工具的崛起,都不是靠资源碾压,而是靠解决了一个足够尖锐的开发者痛点。Postman 如此,Vercel 如此,Supabase 也如此。
Hyperouter 抓的痛点就是多协议互转——一个被多数大厂视为“边缘功能”但实际开发中极度刚需的能力。如果你所在团队已经受够了在多套 SDK 之间疲于奔命,那么花 5 分钟试试 Hyperouter,很可能就能省下未来无数个“为什么这个接口又对不上了”的深夜调试。
结语:一个值得放进书签栏的 Base URL
大模型时代,开发者不缺模型,缺的是让模型“听话”的中间层。Hyperouter 不是要教会你选哪个模型,而是让你在任何时候、用任何你喜欢的代码风格,都能顺畅地调用它们。
如果你厌倦了在各种 API 文档之间反复横跳,不妨现在就去 Hyperouter 拿个 Key,把 base_url 换掉,跑一遍你最熟悉的那段 demo。你会感到一种久违的舒畅:原来统一接口这件事,真的有人做到了。
这可能不是今年最性感的 AI 叙事,但它极大概率,会是你工具箱里最实用的那个“瑞士军刀”。
关于Hyperouter.io
Hyperouter.io 是一个统一的 API 网关服务,为各种大语言模型(LLM)提供单一的接入点。开发者只需在代码中修改基础 URL,就能在不同的模型供应商之间切换,或转换 API 格式。
⚙️ 主要功能
-
多供应商与协议支持:作为一个翻译层,兼容 OpenAI、Anthropic 和 Gemini 的 API 格式,并能自动在不同格式之间转换请求与响应。
-
单一 API 密钥:只需一个 Hyperouter API 密钥,即可访问所有受支持的模型,无需在每个供应商处分别注册。
-
智能负载均衡与故障转移:平台会监控上游供应商,自动将请求路由至最快可用的选项,并在某个供应商宕机时立即进行故障转移。
-
团队与用量管理:内置团队协作和成本监控工具,如限定范围的 API 密钥、速率限制、消费上限以及用量仪表盘。
-
提示缓存:通过自动语义缓存系统,降低重复请求的延迟与费用。
-
费用警报与审计日志:可设置消费阈值,通过邮件或 Webhook(包括飞书/钉钉)接收提醒。所有请求级别的详细信息都可以在可搜索的审计日志中查看。
🚀 快速入门
可以很方便地集成到现有项目中。如官网代码示例所示,只需将 base_url 更新为 https://hyperouter.io/v1,并将 api_key 替换为你的 Hyperouter 密钥。该服务宣称,首 Token 延迟(TTFB)的中位数低于 80 毫秒。
本文基于公开信息撰写,仅代表行业观察,开发者请根据自身需求评估选型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)