当AI学会“抱臂发抖“: 魔珐星云具身Agent评测与交互未来之思
魔珐星云具身Agent评测
从“文本生成”到“具身表达”的端到端闭环,正是魔珐星云与普通数字人工具的核心区别。传统方案中,大模型生成文本后,往往需要经过TTS语音合成、口型驱动、动作预设、视频渲染等多环节拼接,不仅延迟高、易卡顿,更无法支持自然的打断、情绪衔接等交互行为。而魔珐星云通过一套完整的端到端链路,实现了从文本/指令输入,到语音、表情、肢体动作的实时生成,再到端侧3D渲染输出的全流程打通,无需额外的中间件或复杂的后期处理。
纯文本Agent撞上体验天花板之后,具身Agent正用表情、手势和打断机制,重新定义什么是"像人一样的交互"。
楔子:一个让人"出戏"的瞬间
前几天,我在测试一款号称搭载了"情感引擎"的语音助手。我问它:"今天有点累,感觉快抑郁了。"
它用字正腔圆的合成语音,瞬间回复:"抑郁是一种常见的心境障碍,建议您及时寻求专业心理帮助,以下是为您搜索到的三甲医院精神科……"
那一刻,一种巨大的荒谬感击中了我。它的话术无懈可击,信息精确,却比沉默更让我感到孤独。它不懂我的疲惫,不懂我语气中的消沉,它只是在机械地执行一次信息提取与知识匹配。
这就是纯文本Agent撞上的那面无形的墙。而我们今天要评测的主角——魔珐星云具身Agent,正是试图用"身体"去撞碎这面墙的一次激进尝试。
一、初见"小悦":当文字有了表情和骨骼
评测的第一站,是名为"小悦出行"的数字人Demo。她不是一张会动嘴的图片,而是一个拥有完整神态、手势和反应模型的智能体。
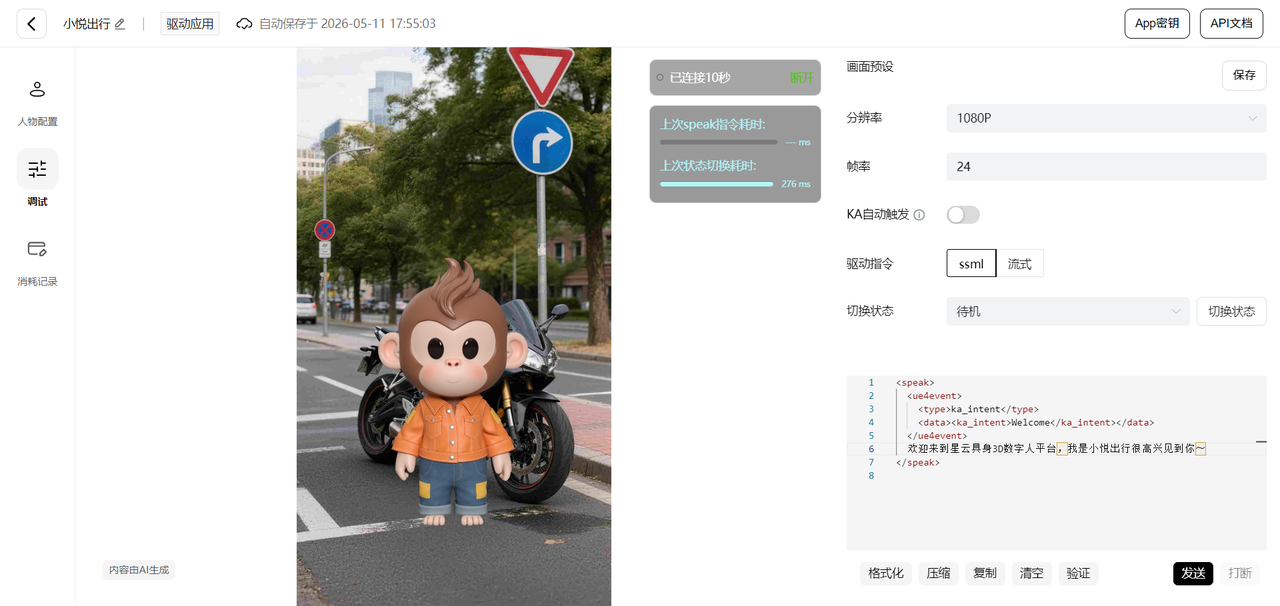
在调试界面,我看到了这场"拟人"背后的骨架:结构化指令。开发者发给小悦的,不是一个简单的TTS文本,而是一个包含 语音内容、事件指令、意图类型 的三元组。
正是这个机制,将"表达"从"文字朗读"中解放出来。当系统设定意图为"欢迎"时,她不仅会说"您好",还会同时展露微笑、摊开手掌做出引导手势。而当意图切换为"提醒",她的眼神会变得更聚焦,手势也变得明确而具有指向性。
这不是在文本上叠加动画,而是表达方式与语义内容的深度绑定。信息不再是冰冷的,它开始带有"表情"。
我的第一感受是:自然。这种自然感并非源于画质的纤毫毕现,而是源于一种"可视化的思维"过程。你似乎能"看懂"她的话正在脑中组织,这种感知是纯文字永远无法给予的。
核心对比
| 维度 | 纯文本Agent | 具身Agent(魔珐星云) |
| 输入/输出 | 文字 → 文字 | 文字 → 语音+表情+眼神+手势+身体动作 |
| 信息通道 | 单一(文字) | 多模态(视觉+听觉+语义) |
| 交互方式 | 单向播放,不可打断 | 双向实时,支持打断 |
| 用户感知 | 工具感 | 人感 |
二、深度评测:打磨得像真实对话的三大交互机制
如果说表情和手势是具身Agent的"皮囊",那下面的三个交互机制,就是它的骨骼与神经。

-
状态流转:让它知道自己"在干什么"
小悦拥有清晰的状态机:待机时安静站立,交互时身体前倾,聆听时眼神专注。通过调试界面的切换指令,你可以随时命令她在状态间跳转。这个看似简单的设计,构成了"拟人感"的基石。在真实对话中,你不会在别人沉默时一直盯着对方,也不会在自己说话时分心。状态的明确,让机器的行为变得可预测,从而可信。
我的感想:这让我想起为何很多Chatbot让人感觉"毛骨悚然"——因为它们没有状态,永远处于一个随时准备回答的、目光灼灼的亢奋状态,这恰恰是最不像人的地方。
关键机制
-
打断机制:真正对话的灵魂所在
这是整个评测过程中,最让我感到惊喜的部分。
在纯文本Agent的交互中,"打断"是绝对禁区。你必须像参加颁奖典礼一样,听完它冗长的发言,才能进行下一轮输入。这是"单向输出",不是"对话"。
但在测试小悦时,我刻意在她说到一半时突然插话:"不对,换一条路。"
她瞬间中止了当前回复,语音收拢,表情切换为聆听模式,并在极短的延迟后,给出新响应:"好的,正在重新规划。" 同时,她的手指向旁边的导航预览图。
这个瞬间,我体验到了一种久违的、被尊重的交互感。真实对话的核心,正是这种可打断、可协商、可即时修正的动态过程。它让人掌握了沟通的主导权,而不是去适应机器的交流节拍。
我的期望:我期待将来的打断不仅是基于人声,更能结合计算机视觉。当数字人"看到"我身体微动、嘴唇张开准备说话时,就能预判并暂停,将这场"人机对话"的交响乐指挥得更加行云流水。
-
端侧渲染:被压缩到极致的延迟魔法
这一切丝滑体验的基础,是魔珐星云反复强调的端侧渲染。通过AI 端渲与端侧解算AI端溢和解算,推理直接在本地芯片上完成。
效果立竿见影:没有云端"上传-计算-回传"的2-3秒真空期,Agent的响应是毫秒级的。一个眼神的流转、一个微表情的浮现,都与语音节奏严丝合缝。这消解的不仅是技术延迟,更是用户心理上的"等待感"和"工具感"。更重要的是,它意味着任何带百元级屏幕的设备,都有了升级为具身Agent的可能。
<speak>
<ue4event>
<type>ka_intent</type>
<data><ka_intent>Welcome</ka_intent></data>
</ue4event>
欢迎来到星云具身3D数字人平台,我是小悦。小悦出行,伴你智慧启程——丰富的出行服务与智能互动等你体验,精彩不容错过~
</speak>
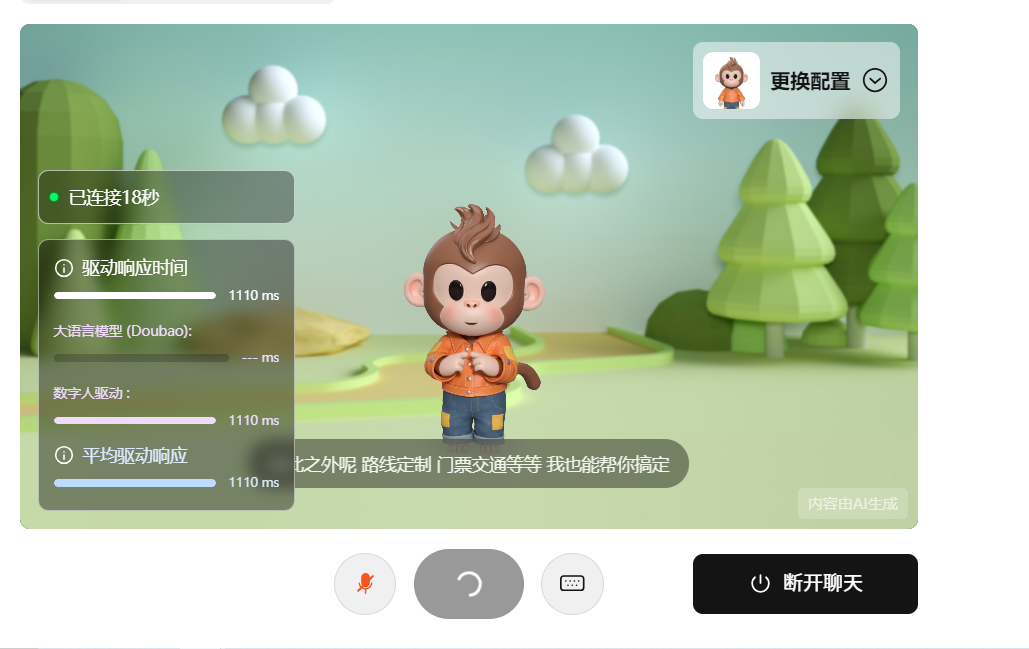
三、拆解具身驱动的四大支柱:从感知到表达的全链路
评测至此,我的工程师思维驱使我必须"开盖"看看里面的构造。魔珐星云的技术架构,可被总结为四个相互咬合的能力齿轮:
-
自研文生 3D 多模态大模型多模态生成:这是大脑。它不只在NLP层面理解"说了什么",更解析"什么情绪",并实时生成联动指令。我曾想象一个场景:对它说"我有点冷",它的回复不仅可以是"已调高空调温度",更可以同步做出一个抱臂发抖的共情微表情。这传递的信息远超文字——传递的是"我懂你"。
-
低成本端侧运行:这是心脏。它将强大的AI算力需求"浓缩"到百元级ARM芯片上,让智能不再是一种昂贵的云端特权,而是可以植入每一个边缘设备中的普惠能力。
-
虚实兼容:这是身体的延伸。同一套技术栈,既能驱动屏幕里的3D数字人,也能驱动物理世界的人形机器人。这为未来留下了巨大的想象空间。
-
跨端适配:这是血管网络。毫秒级低延时,全端覆盖,并100%兼容国产信创。这彻底扫清了具身Agent从demo走向规模化部署的商业化障碍。
我的感想:这一技术架构的核心哲学,是让智能去适应环境,而不是让环境去改造自身以适应智能。这种非侵入式的接入,是所有技术能够真正落地的前提。
技术架构
| 能力层 | 核心功能 | 实际效果 |
| 多模态生成 | 文本驱动语义与情绪解析,实时生成语音、表情及动作 | "我有点冷" → 抱臂发抖的共情表情 |
| 低成本端侧运行 | AI端溢和解算,百元级芯片可跑 | 无需GPU,任何带屏设备可升级 |
| 虚实兼容 | 同一技术栈驱动3D数字人与实体机器人 | 虚拟与物理世界统一交互 |
| 跨端适配 | 毫秒级低延时,多端部署,兼容国产信创 | Web、App、小程序、一体机全覆盖 |
四、畅想未来:当万物拥有了"身体与表情"
评测的终点,不应该是技术参数的罗列,而是对未来交互形态的展望。纯文本Agent让我们更快地获取信息,而具身Agent则试图重构我们与技术的关系:
-
在智能座舱里:数字助手不再只是一个声音,她会侧耳倾听你的指令,在你打断时立刻停止,点头回应你,并用眼神和手势为你指路。驾驶的孤独感会被这种有"在场感"的交互消解。
-
在家居屏幕上:中控管家不再是一个冰冷的控制面板。你说"有点冷",它不仅调节温度,还会做出那个"抱臂发抖"的表情。那一刻,家似乎也变得更温暖了。
-
在线下门店:导购屏不再循环播放广告。数字人导购的视线会追随你的脚步,用眼神和手势主动介绍商品,像一个真正的销售顾问为你提供专属服务。
-
在人形机器人身上:这是最具想象力的未来。当驱动数字人的技术栈,同样能驱动一个实体机器人,它就不再是执行指令的机械臂,而是一个能配合表情和肢体语言进行自然协作的伙伴。
结语:交互的本质,是让机器去适应人
过去十年的科技发展,一直在做一件事:训练人去适应机器。我们学会了关键词搜索,学会了结构化指令,学会了忍受一个没有表情、无法打断的聊天框。
而魔珐星云具身Agent所代表的路线,是一场根本性的转向:让机器去适应人。它用表情回应我们的情绪,用动作配合我们的语境,用眼神传递它的"态度"。它通过多模态生成、端侧渲染、虚实兼容与跨端适配这四大支点,第一次让这种具有"人感"的交互,获得了可大规模落地的力量。
我们站在一个交互入口代际更替的起点。竞争的下半场,核心命题将从"让AI更聪明"转向"让AI更像人"。因为最终,人类最自然、最高效、最能获得慰藉的交互方式,永远是找到一个能"看懂"我们的表情,并愿意"抱臂发抖"的同类。
告别单向的文字聊天框吧。
一个拥有身体的AI交互新世界,正在屏幕和物理世界的另一端,向我们点头微笑。
专属链接:https://xingyun3d.com?utm_campaign=daily&utm_source=jixinghuiKoc84

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)