FastAPI 后端接口与 ActionParser 调用链路开发实践
在前几周的工作中,我主要围绕 StoryVerse 项目的 ActionParser 模块完成了数据集构建、半自动标注、基线评测、微调方案设计以及两阶段 warmup 训练等内容。随着数据与模型训练流程逐步稳定,项目开发重点也开始从“模型本身能否完成动作解析任务”,进一步转向“模型能力如何接入系统并服务于真实业务流程”。因此,本阶段我开始负责 FastAPI 后端相关代码的开发与调试,重点是将 ActionParser 的能力封装成后端可调用的服务接口,使其能够与后续的多智能体剧情推进、角色响应和前端交互流程衔接起来。
这一阶段的工作和前期模型训练不同。模型训练更关注数据质量、训练策略和评估指标,而后端开发则更强调接口规范、数据结构、异常处理、模块解耦和工程可维护性。对于 StoryVerse 这样一个基于 LLM 的多智能体小说角色扮演平台来说,后端并不只是简单地转发请求,而是整个系统中承接用户输入、调用模型能力、组织结构化动作结果、再传递给后续世界状态与角色智能体模块的核心中间层。因此,FastAPI 后端代码的开发实际上是把前期 ActionParser 研究成果真正转化为系统能力的重要一步。
本阶段最先要解决的问题,是明确后端中 ActionParser 模块的职责边界。前期我们已经确定 ActionParser 的核心任务是将用户输入的自然语言行为解析为统一 JSON 结构,例如动作类型、目标对象、动作内容、执行者、是否需要拆分子动作等字段。但在后端服务中,这个模块不能只停留在“输入一句话,返回模型原始输出”的层面,而是需要具备完整的工程处理流程。也就是说,后端不仅要调用模型,还要负责构造提示词、发送请求、接收模型响应、解析 JSON、校验字段合法性、处理异常情况,并最终返回一个稳定、可被其他模块直接使用的数据结构。

围绕这一目标,我首先对后端代码结构进行了梳理,将与 ActionParser 相关的功能拆分为更清晰的模块。整体思路是避免把所有逻辑都写在接口函数中,而是尽量按照“路由层、服务层、数据模型层、工具层”的方式组织代码。路由层主要负责接收 HTTP 请求和返回响应,服务层负责具体的 ActionParser 调用逻辑,数据模型层定义请求体与响应体结构,工具层则承担 JSON 提取、字段校验、默认值补全等辅助功能。这样的划分可以让代码更容易维护,也方便后续替换模型调用方式,例如从本地模型切换为远程 API,或者从普通推理接口切换为微调后模型服务。
在 FastAPI 接口设计上,我围绕 ActionParser 的核心功能设计了对应的请求与响应结构。请求部分主要接收用户输入文本,同时可以预留角色名、当前场景、上下文信息等字段,为后续系统增强留出空间。响应部分则严格对齐 ActionParser 的输出 schema,使后端返回结果能够被后续模块直接消费。相比直接返回字符串,这种结构化响应的优势非常明显:前端可以直接展示动作解析结果,剧情引擎可以根据 action_type 决定下一步逻辑,角色智能体也可以根据 target 和 content 生成更符合情境的回应。
在这一过程中,我重点处理了 ActionParser 输出结构的合法性校验问题。由于模型输出具有一定不确定性,即使在 prompt 中要求“只输出 JSON”,实际返回结果仍然可能出现字段缺失、类型错误、额外解释文本、布尔值格式异常、动作类别不在预设集合内等问题。如果后端直接把这些结果向下游传递,就会导致系统后续模块出现难以定位的错误。因此,我在后端逻辑中加入了严格的结构校验机制,例如检查 action_type 是否属于 speak、move、observe、interact、use、wait 这几类之一,检查 need_split 是否为布尔值,检查 sub_actions 是否为数组,并对 actor、target、content 等字段做统一字符串处理。
def _validate_action_schema(action: dict, depth: int = 0) -> tuple[bool, str | None]:
"""递归校验动作结构。depth=0 表示主动作,depth=1 表示子动作。"""
if not isinstance(action, dict):
return False, "action必须是JSON对象"
required_fields = {
"action_type",
"target",
"content",
"actor",
"need_split",
"sub_actions",
}
missing_fields = required_fields - set(action.keys())
if missing_fields:
return False, f"action缺少必要字段: {sorted(missing_fields)}"
action_type = action.get("action_type")
if action_type not in ACTION_TYPES:
return False, f"action_type必须是以下类型之一: {sorted(ACTION_TYPES)}"
if not isinstance(action.get("target"), str):
return False, "target字段必须是字符串"
if not isinstance(action.get("content"), str):
return False, "content字段必须是字符串"
if not isinstance(action.get("actor"), str):
return False, "actor字段必须是字符串"
if not isinstance(action.get("need_split"), bool):
return False, "need_split字段必须是布尔值"
if not isinstance(action.get("sub_actions"), list):
return False, "sub_actions字段必须是列表"
if depth >= 1 and action.get("need_split"):
return False, "sub_actions中的子动作不允许继续嵌套拆分"
if action.get("need_split"):
if len(action.get("sub_actions")) == 0:
return False, "need_split为true时,sub_actions不能为空"
for index, sub_action in enumerate(action["sub_actions"]):
sub_action = repair_action_schema_if_needed(sub_action)
ok, error = _validate_action_schema(sub_action, depth=depth + 1)
if not ok:
return False, f"sub_actions[{index}]不合法: {error}"
else:
if len(action.get("sub_actions")) != 0:
return False, "need_split为false时,sub_actions必须为空数组"
return True, None其中一个比较关键的问题是 need_split 和 sub_actions 的一致性。按照当前 ActionParser 的设计,如果 need_split 为 false,那么 sub_actions 应当为空数组;如果 need_split 为 true,那么 sub_actions 必须包含至少一个合法子动作。这个规则看似简单,但在实际调试中非常重要,因为模型有时会输出 need_split 为 true 但 sub_actions 为空的结果,这在语义上是不完整的,也会破坏后续多动作执行逻辑。因此,后端不能只检查 JSON 是否能被解析,还必须进一步检查字段之间的逻辑关系。通过这类校验,后端可以及时发现模型输出中的不合法结构,并返回清晰的错误信息,方便后续继续优化 prompt 或模型微调数据。
除了结构校验,我还对模型输出的解析过程进行了专门处理。由于大语言模型在实际返回时可能会在 JSON 前后附带说明文字,或者使用 Markdown 代码块包裹结果,因此后端需要具备一定的容错能力,能够从原始字符串中提取出真正的 JSON 内容。为此,我在工具逻辑中加入了 JSON 提取和解析步骤,尽量让系统在面对轻微格式噪声时仍然能够恢复出可用结果。但与此同时,我也没有过度放宽校验标准,因为如果后端容忍过多错误格式,反而会掩盖模型本身的问题。最终的处理策略是:允许轻微包装格式存在,但核心字段和逻辑关系必须严格合法。
在服务层设计中,我还考虑了 prompt 构造与模型调用的解耦问题。ActionParser 的效果很大程度上受 prompt 影响,如果把 prompt 写死在接口函数里,后续调整会非常不方便。因此,我将 prompt 构造逻辑单独抽离出来,使其可以根据用户输入、角色信息、场景上下文等内容动态生成模型请求。当前阶段可以先使用固定模板完成基本动作解析,后续则可以继续扩展为更复杂的上下文增强版本,例如在 prompt 中加入当前章节背景、用户扮演角色、附近可交互对象、可用道具等信息,从而让 ActionParser 的解析结果更加贴合游戏世界状态。
在调试过程中,我也针对 FastAPI 接口进行了多轮基础测试。测试重点不是只看接口能不能返回结果,而是要验证完整链路是否稳定,包括请求体是否能被正确解析、服务层是否能够正常调用解析逻辑、模型输出是否能被后端转换为标准响应、异常情况是否能给出明确提示等。例如,当输入“我走到门边,敲门说有人吗”这类复合行为时,后端需要判断模型是否能够正确识别为 interact 或拆分为 move 与 speak 等子动作;当模型输出 need_split 为 true 但 sub_actions 为空时,后端能够检测出结构不合法并返回对应错误。这些测试帮助我进一步明确了后端校验的必要性,也暴露出 prompt 和模型输出之间仍然需要继续优化的地方。
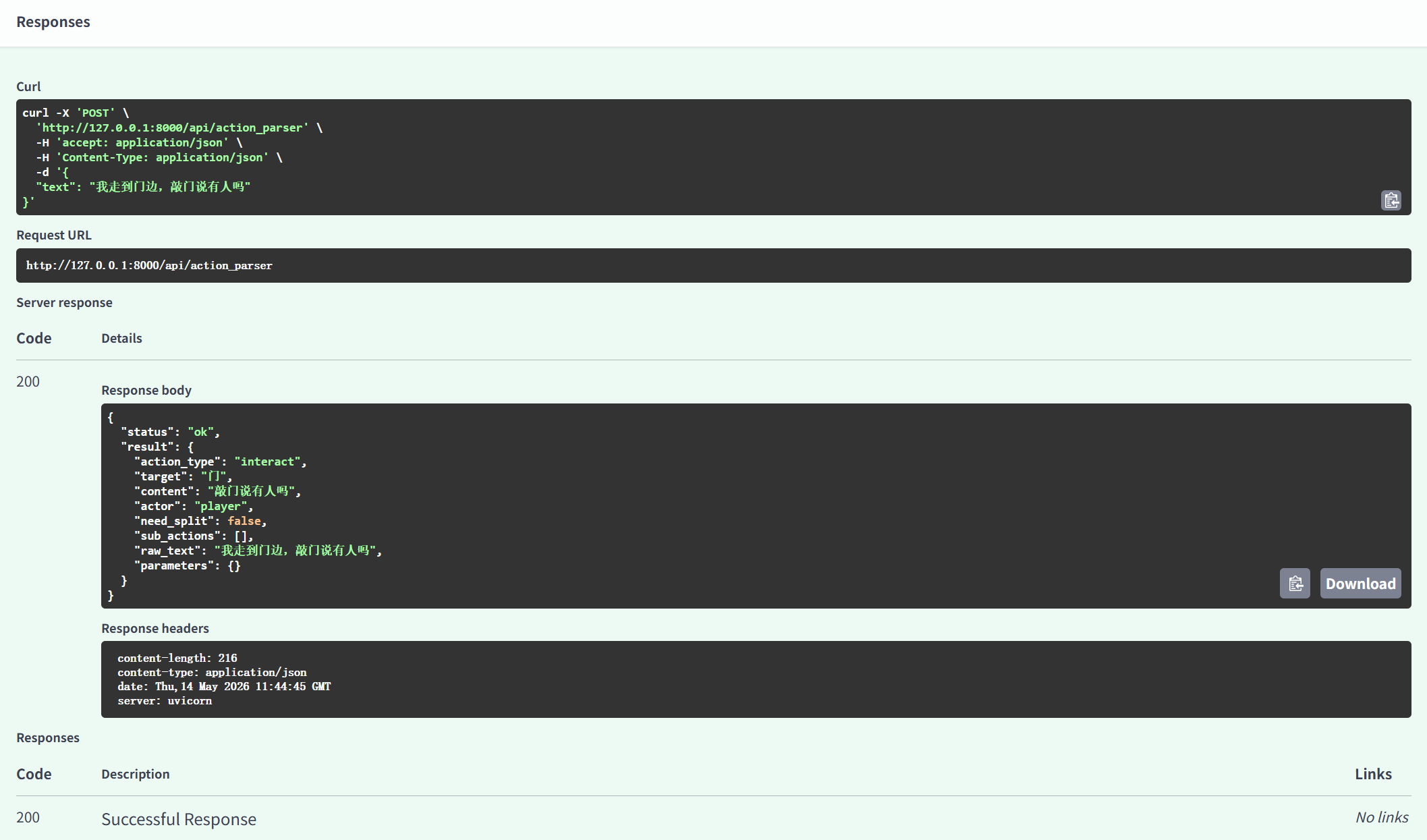
本阶段还有一个重要工作,是对 ActionParser 相关后端文件进行职责拆分和代码补全。为了让代码结构更清晰,我将请求响应模型、解析服务、校验函数、异常处理等内容分别放在对应文件中,而不是堆叠在单个文件里。这样做可以明显提升后续维护效率。例如,当我们需要修改输出 schema 时,只需要调整数据模型和校验逻辑;当我们需要更换模型调用方式时,主要修改服务层即可;当我们需要新增接口时,也可以复用已有的解析和校验工具,而不是重复编写逻辑。
从系统整体角度看,这一阶段的 FastAPI 后端开发还承担了一个“对齐团队模块”的作用。StoryVerse 并不是一个单独模型项目,而是一个包含小说世界状态、角色智能体、用户交互、剧情推进和前端展示的综合系统。因此,ActionParser 的返回结果必须能够被其他同学负责的模块理解和使用。后端接口的统一输出格式,实际上就是不同模块之间的通信协议。通过在后端层面固定 schema、校验规则和错误响应格式,可以减少团队协作中的歧义,避免出现“模型能输出,但其他模块不知道怎么用”的问题。
在这一阶段中,我也进一步认识到,后端开发与模型开发之间存在很强的相互反馈关系。比如,当后端校验发现模型经常输出非法结构时,这说明 prompt 或训练数据需要进一步强化格式约束;当某些动作类型经常被模型混淆时,也可以反过来指导数据集补充或评估集设计;当接口需要支持更多上下文字段时,则意味着 ActionParser 后续可能不应只依赖单句输入,而应逐步引入场景信息。因此,FastAPI 后端并不是模型训练完成后的简单包装,而是帮助模型能力进入真实系统并持续迭代的重要工程环节。
总体来看,本阶段的工作主要完成了 StoryVerse 后端 ActionParser 调用链路的基础建设,包括 FastAPI 接口设计、请求响应结构定义、ActionParser 服务逻辑封装、模型输出 JSON 解析、字段合法性校验、need_split 与 sub_actions 逻辑约束、异常返回机制设计以及基础接口测试。通过这些工作,前期围绕 ActionParser 进行的数据标注、微调设计和模型评估,开始逐步转化为后端可调用的系统能力。
这一阶段的意义在于,项目不再只是停留在“训练一个能解析动作的模型”,而是进一步迈向“让模型能力真正接入 StoryVerse 平台”的工程实现阶段。后续我将继续围绕 ActionParser 接口进行优化,包括完善 prompt_service 模块、增强上下文输入能力、优化错误处理逻辑,并与其他后端模块进行联调,使 ActionParser 能够真正参与到用户输入解析、角色行为理解和剧情推进流程中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)