深度学习-卷积神经网络
参考:《动手学深度学习》,https://zh-v2.d2l.ai/index.html
引用自《动手学深度学习》:卷积神经网络(Convolutional Neural Network,CNN)是一类专门处理具有网格结构数据(如图像、音频)的深度学习模型。与全连接网络不同,CNN 通过局部连接和参数共享两大核心机制,能够高效地提取数据的空间或时间局部特征。
一些题外话,上一节我们用 MLP 搞定了手写数字识别,准确率还不错。但仔细想想,MLP 处理图像时有个"硬伤"——它得把二维图像硬生生拉成一维向量。这就好比把一张照片切成小方块再排成一条线,像素点之间的空间关系全乱了。那有没有一种网络,能直接"看懂"图像的空间结构呢?这篇笔记,我们就从零开始,一步步揭开**卷积神经网络(CNN)**的面纱。
本文脉络
- 回顾 MLP:隐藏层与激活函数的配合
- MLP 处理图像的困境:空间关系丢失与参数爆炸
- 卷积操作:从零实现滑动窗口卷积,体验常见卷积核
- 池化层:最大池化与平均池化的原理与实战
- LeNet-5 实战:完整实现 MNIST 手写数字识别
- 总结与延伸:核心回顾与后续学习方向
预计阅读时间:20 分钟 | 难度:入门-中等 | 前置知识:MLP 基础、PyTorch 基础
# ==================== 中文字体配置 ====================
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# macOS 可用中文字体(按优先级):
# STHeiti - 系统黑体 | Songti SC - 宋体 | PingFang HK - 苹方
# 方法1:使用 rcParams 设置字体
plt.rcParams['font.sans-serif'] = ['STHeiti', 'Songti SC', 'PingFang HK', 'Kaiti SC', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 方法2:查找系统中可用的中文字体(备用方案)
def get_chinese_font():
"""获取可用的中文字体名称"""
chinese_fonts = ['STHeiti', 'Songti SC', 'PingFang HK', 'Kaiti SC', 'Heiti TC']
available_fonts = [f.name for f in fm.fontManager.ttflist]
for font in chinese_fonts:
if font in available_fonts:
return font
return None
CHINESE_FONT = get_chinese_font()
if CHINESE_FONT:
print(f"找到中文字体: {CHINESE_FONT}")
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = [CHINESE_FONT]
else:
print("未找到中文字体,尝试使用默认字体")
print("✅ 中文字体配置完成!")
找到中文字体: STHeiti
✅ 中文字体配置完成!
一、回顾 MLP:隐藏层与激活函数的"黄金搭档"
在正式进入 CNN 之前,咱们先花点时间回顾一下上一节的核心内容。MLP 之所以能处理那些复杂的分类和回归任务,靠的是两个关键组件的默契配合。
1.1 隐藏层:数据的"流水线"
每一层隐藏层本质上做的是一件事——仿射变换:
h(l)=W(l)h(l−1)+b(l)\mathbf{h}^{(l)} = \mathbf{W}^{(l)}\mathbf{h}^{(l-1)} + \mathbf{b}^{(l)}h(l)=W(l)h(l−1)+b(l)
拆开来看:
- W(l)\mathbf{W}^{(l)}W(l):权重矩阵,控制输入到输出的线性映射
- b(l)\mathbf{b}^{(l)}b(l):偏置向量,给每个输出通道加一个偏移
- h(l−1)\mathbf{h}^{(l-1)}h(l−1):上一层的输出,也就是这一层的输入
这里有个很重要的事情:如果没有激活函数介入,不管堆多少层隐藏层,整个网络等价于一个线性函数。这就跟单层感知机没啥区别了,根本拟合不了复杂的非线性关系。
1.2 激活函数:给网络注入"灵魂"
激活函数的作用就是打破上面的线性束缚,为网络引入非线性。最常用的 ReLU 长这样:
σ(x)=max(0,x)\sigma(x) = \max(0, x)σ(x)=max(0,x)
很简单对吧?小于 0 的直接归零,大于 0 的原封不动。但就是这么一个简单的操作,让神经网络有了拟合任意复杂函数的能力。
把激活函数加进去后,第 lll 层的完整前向传播公式就变成了:
h(l)=σ(W(l)h(l−1)+b(l))\mathbf{h}^{(l)} = \sigma\left(\mathbf{W}^{(l)}\mathbf{h}^{(l-1)} + \mathbf{b}^{(l)}\right)h(l)=σ(W(l)h(l−1)+b(l))
多个这样的层串起来,就是我们常说的"万能近似器"。
换个角度想:MLP 的核心逻辑就是"线性变换 + 非线性激活"不断重复。后面的 CNN 也不例外,只不过把线性变换从全连接换成了卷积,思路是一脉相承的。
二、MLP 处理图像的困境:从"像素列表"到"理解画面"
上一节我们用 MLP 搞定了手写数字识别,准确率也还不错。但如果你仔细想想,MLP 处理图像的方式其实挺"笨"的——它根本不把输入当"图片"看,而是当成一堆数字组成的长列表。
为了理解为什么 MLP 处理图像效率低,咱们不妨换个角度思考:
🧠 人类是怎么看图像的?
当你看一张照片时,你的眼睛不会从左到右、逐行扫描每一个像素。相反,你会:
- 先看局部:目光会落在某个区域,识别边缘、纹理、角落
- 再找模式:几个边缘组合起来 → 一个圆弧 → 可能是数字 “0” 的一部分
- 不管位置:同一个数字,出现在画面中央还是角落,你都能认出来
这种能力叫视觉层次化感知:从局部到全局、从简单到复杂。而 MLP 的"全连接"方式,与这种自然的视觉处理机制完全背道而驰。
2.1 问题一:把图像当"列表"处理,空间关系全丢了
MLP 的全连接层(nn.Linear)做的是标准的矩阵乘法:y=Wx+b\mathbf{y} = \mathbf{W}\mathbf{x} + \mathbf{b}y=Wx+b。这意味着输入 x\mathbf{x}x 必须是一维向量。
所以一张 28×2828 \times 2828×28 的图像,必须用 x.view(x.size(0), -1) 硬生生拉成 784784784 维的向量。这就像:
把一幅精美的拼图打碎,然后把所有碎片串成一条项链——你还看得出原来的画面吗?CNN 就是为了解决这个问题而生的,它直接在二维(甚至三维)的空间上进行计算,天然保留了像素间的邻接关系。
具体来说,展平操作破坏了两种至关重要的视觉信息:
空间邻接性:图像中相邻的像素通常属于同一个物体的边缘或纹理。比如手写数字 “8” 的上半圆,相邻像素共同构成了一个弧形。展平后,这些像素在向量中可能相隔几百个位置,网络无法直观地"看到"这个弧形。
位置无关性:同一个数字出现在图像的左上角还是右下角,它还是那个数字。但 MLP 会为每个像素位置学习独立的权重——它实际上在"死记硬背"每个位置该是什么样子,而不是学会识别"这是个圆弧"。
2.2 问题二:参数爆炸——效率极低的"死记硬背"
全连接层的参数量公式:
Params=输入维度×输出维度+偏置\text{Params} = \text{输入维度} \times \text{输出维度} + \text{偏置}Params=输入维度×输出维度+偏置
对于 MNIST 这种 28×2828 \times 2828×28 的小图,一个中等规模的 MLP 就需要 50 万+ 参数(详见后面第 28 个单元格的详细对比)。而 MNIST 训练集只有 60,000 张图——参数量几乎是样本数的 9 倍!
这意味着什么?打个比方:你让一个学生背 53 万条规则来识别 6 万个例子,他当然能背下来,但遇到没见过的新例子就傻眼了。这就是过拟合——记住训练数据,而不是学会泛化。
2.3 换个思路:CNN 是怎么解决这些问题的?
CNN 的设计哲学其实非常接近人类的视觉机制:
| 人类视觉 | CNN 对应机制 | 解决的问题 |
|---|---|---|
| 关注局部区域 | 局部连接(卷积核只看一小块) | 避免全连接的参数爆炸 |
| 同一边缘在图中任何位置都一样 | 参数共享(一个卷积核滑遍全图) | 位置无关性 |
| 从简单到复杂的层次识别 | 多层卷积(边缘→纹理→形状) | 层次化特征提取 |
多嘴一句:MLP 和 CNN 的根本区别在于如何看待输入数据。MLP 把所有输入当成"一坨数字",每个输入和输出之间都有一条独立的连线。CNN 则认为数据有空间结构,用滑动窗口的方式去"扫描"图像,既保留了空间信息,又大幅减少了参数量。这正是 CNN 能碾压 MLP 的核心原因。
下面用代码看看展平操作到底"毁"了什么,然后咱们一步步实现卷积操作来体验 CNN 的解决思路。
# 可视化演示:展平操作如何破坏图像的空间关系
import torch
import matplotlib.pyplot as plt
import numpy as np
# === 第一步:创建一个 5×5 的模拟图像 ===
# 用坐标值填充,方便追踪每个像素在展平后的位置变化
image_2d = torch.arange(25).reshape(5, 5).float()
print("=== 原始 2D 图像 ===")
print(image_2d)
print("注意:相邻数字(如 11,12,13)在 2D 中是水平相邻的")
# === 第二步:展平为 1D 向量 ===
image_1d = image_2d.view(-1)
print(f"\n=== 展平后的 1D 向量 ===")
print(image_1d)
# === 第三步:分析空间邻接关系的破坏 ===
print("\n" + "=" * 50)
print("🔍 空间邻接关系分析")
print("=" * 50)
# 以像素 12(中心像素)为例
print("\n在 2D 图像中,像素 12 (第2行第2列) 的四个方向邻居:")
print(f" 上邻居: {image_2d[1, 2]:.0f} (行-1)")
print(f" 下邻居: {image_2d[3, 2]:.0f} (行+1)")
print(f" 左邻居: {image_2d[2, 1]:.0f} (列-1)")
print(f" 右邻居: {image_2d[2, 3]:.0f} (列+1)")
print(f"\n在 1D 向量中,像素 12 位于索引 12,它的'邻居'是:")
print(f" 左侧: 索引 11 → 值 {image_1d[11]:.0f} ✅ 真正的左邻居")
print(f" 右侧: 索引 13 → 值 {image_1d[13]:.0f} ✅ 真正的右邻居")
print(f" 但'上下邻居'在哪里?索引 7(上) 和 17(下) 与索引12相隔甚远!")
print("\n" + "=" * 50)
print("⚠️ 关键问题:换行跳跃带来的虚假相邻")
print("=" * 50)
# 展示换行问题:4 和 5 在 1D 中相邻,但在 2D 中不在同一行
print("看像素 4 (0,4) 和像素 5 (1,0):")
print(f" 在 2D 中:4 在第0行最右端,5 在第1行最左端")
print(f" 它们在图像上**相距很远**,不是邻居!")
print(f" 在 1D 中:索引 4 和索引 5 **紧挨在一起**")
print(f" → MLP 会误以为它们有关联,这就是'虚假邻接'!")
# === 第四步:可视化对比 ===
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 左侧:2D 热力图
im1 = ax1.imshow(image_2d.numpy(), cmap='viridis', aspect='equal')
ax1.set_title('2D 图像:保留空间结构\n每个像素有上下左右邻居',
fontsize=13, fontweight='bold')
ax1.set_xlabel('列', fontsize=11)
ax1.set_ylabel('行', fontsize=11)
for i in range(5):
for j in range(5):
ax1.text(j, i, f'{int(image_2d[i, j])}',
ha='center', va='center',
color='white', fontsize=11, fontweight='bold')
plt.colorbar(im1, ax=ax1, fraction=0.046, label='像素值')
# 右侧:1D 条形图
ax2.bar(range(25), image_1d.numpy(), color='steelblue', edgecolor='black', alpha=0.8)
ax2.set_title('1D 展平:空间关系丢失\n相邻索引≠空间相邻',
fontsize=13, fontweight='bold')
ax2.set_xlabel('展平后索引位置', fontsize=11)
ax2.set_ylabel('像素值', fontsize=11)
ax2.set_xticks(range(0, 25, 5))
ax2.grid(axis='y', alpha=0.3)
# 标记换行跳跃的虚假相邻
ax2.axvspan(4.5, 5.5, color='red', alpha=0.2, label='虚假相邻')
ax2.legend(loc='upper left')
plt.tight_layout()
plt.show()
print("\n" + "=" * 50)
print("💡 小结:展平操作的本质问题")
print("=" * 50)
print("• MLP 把图像当成'一维列表'处理")
print("• 空间上的相邻像素在展平后可能相距甚远")
print("• 空间上不相关的像素在展平后可能紧挨着")
print("• CNN 通过卷积核直接扫描 2D 图像,避免了这个问题")
=== 原始 2D 图像 ===
tensor([[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[10., 11., 12., 13., 14.],
[15., 16., 17., 18., 19.],
[20., 21., 22., 23., 24.]])
注意:相邻数字(如 11,12,13)在 2D 中是水平相邻的
=== 展平后的 1D 向量 ===
tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24.])
==================================================
🔍 空间邻接关系分析
==================================================
在 2D 图像中,像素 12 (第2行第2列) 的四个方向邻居:
上邻居: 7 (行-1)
下邻居: 17 (行+1)
左邻居: 11 (列-1)
右邻居: 13 (列+1)
在 1D 向量中,像素 12 位于索引 12,它的'邻居'是:
左侧: 索引 11 → 值 11 ✅ 真正的左邻居
右侧: 索引 13 → 值 13 ✅ 真正的右邻居
但'上下邻居'在哪里?索引 7(上) 和 17(下) 与索引12相隔甚远!
==================================================
⚠️ 关键问题:换行跳跃带来的虚假相邻
==================================================
看像素 4 (0,4) 和像素 5 (1,0):
在 2D 中:4 在第0行最右端,5 在第1行最左端
它们在图像上**相距很远**,不是邻居!
在 1D 中:索引 4 和索引 5 **紧挨在一起**
→ MLP 会误以为它们有关联,这就是'虚假邻接'!
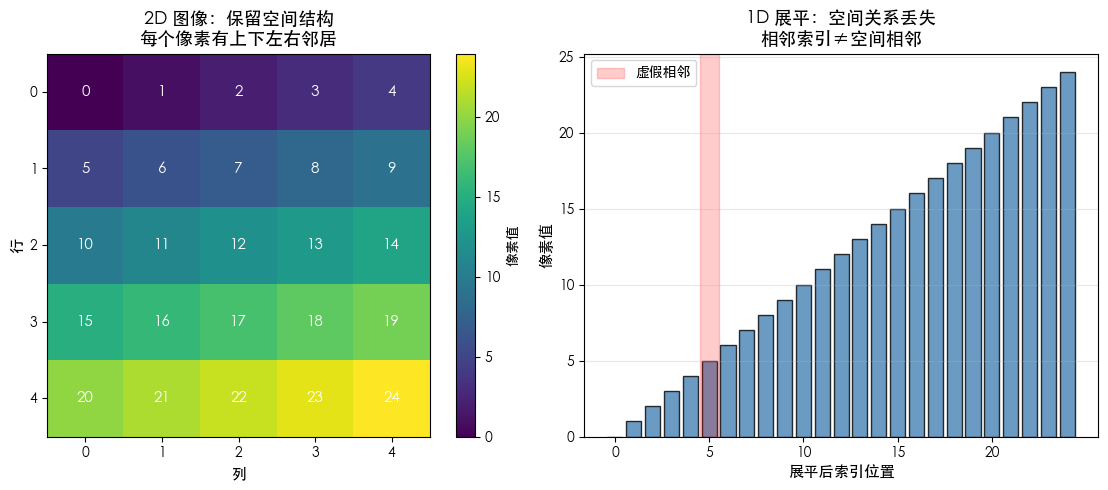
==================================================
💡 小结:展平操作的本质问题
==================================================
• MLP 把图像当成'一维列表'处理
• 空间上的相邻像素在展平后可能相距甚远
• 空间上不相关的像素在展平后可能紧挨着
• CNN 通过卷积核直接扫描 2D 图像,避免了这个问题
三、卷积操作详解:图像的"空间特征探测器"
既然展平会破坏图像的空间结构,那有没有一种方法可以直接在二维图像上操作呢?答案是:卷积(Convolution)。
3.1 什么是卷积?
想象你有一个 3×33 \times 33×3 大小的"小窗口",把它放在图像的左上角,然后做一件事:把窗口里的 9 个数字和图像对应位置的 9 个像素相乘,再把结果加起来。然后把窗口向右移一格,重复同样的操作。一直移动到覆盖整张图像,你就得到了一张新的"特征图"。
这个"小窗口"就是卷积核(Kernel),也叫滤波器(Filter)。它的数值就是网络要学习的参数。
换个角度理解:卷积核就像一个"模板匹配器"。如果图像中某块区域跟卷积核的模式很"像",卷积结果就会很大;如果完全不像,结果就接近 0。通过训练,网络会自动学到各种有用的模板——比如检测边缘、角点、纹理等。
3.2 卷积计算:手把手拆解每一步
这部分是理解 CNN 的核心,咱们慢慢来,确保每一步都搞清楚。
3.2.1 第一步:准备输入和卷积核
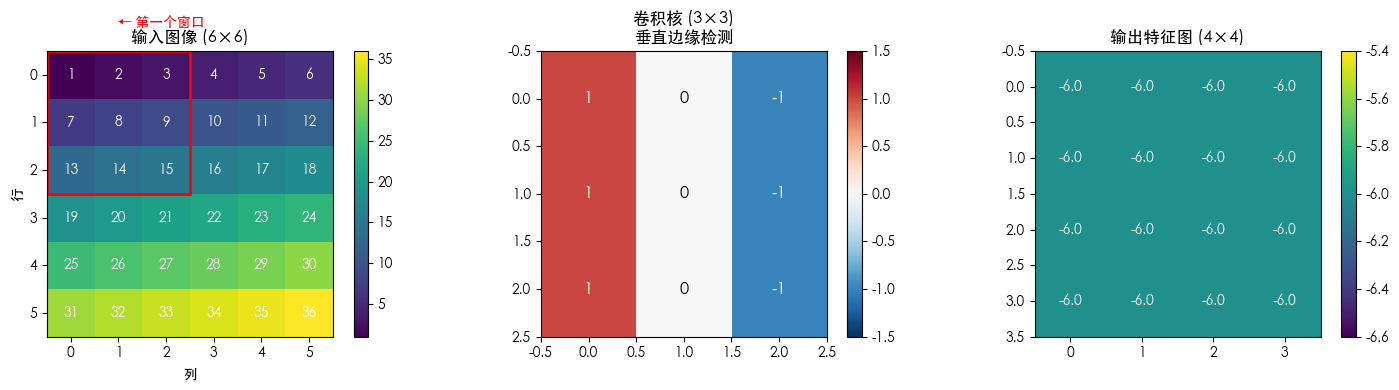
假设我们有一个 6×66 \times 66×6 的输入图像 III,和一个 3×33 \times 33×3 的卷积核 KKK:
I=[123456789101112131415161718192021222324252627282930313233343536],K=[10−110−110−1]I = \begin{bmatrix} 1 & 2 & 3 & 4 & 5 & 6 \\ 7 & 8 & 9 & 10 & 11 & 12 \\ 13 & 14 & 15 & 16 & 17 & 18 \\ 19 & 20 & 21 & 22 & 23 & 24 \\ 25 & 26 & 27 & 28 & 29 & 30 \\ 31 & 32 & 33 & 34 & 35 & 36 \end{bmatrix}, \quad K = \begin{bmatrix} 1 & 0 & -1 \\ 1 & 0 & -1 \\ 1 & 0 & -1 \end{bmatrix}I= 171319253128142026323915212733410162228345111723293561218243036 ,K= 111000−1−1−1
这个卷积核是一个垂直边缘检测器:左边是正的,右边是负的,中间为 0。它的直觉是——如果图像中某处左边亮、右边暗,卷积结果就会是正的;反之则是负的。
3.2.2 第二步:在第一个位置做"逐元素相乘再求和"
把卷积核放在图像的左上角,覆盖区域是:
Iregion=[123789131415]I_{\text{region}} = \begin{bmatrix} \boxed{1} & \boxed{2} & \boxed{3} \\ \boxed{7} & \boxed{8} & \boxed{9} \\ \boxed{13} & \boxed{14} & \boxed{15} \end{bmatrix}Iregion= 171328143915
卷积运算的公式:对应位置相乘,然后把 9 个乘积加起来
S(0,0)=1×1+0×2+(−1)×3+1×7+0×8+(−1)×9+1×13+0×14+(−1)×15=1+0−3+7+0−9+13+0−15=−6\begin{aligned} S(0,0) &= 1 \times \boxed{1} + 0 \times \boxed{2} + (-1) \times \boxed{3} \\ &+ 1 \times \boxed{7} + 0 \times \boxed{8} + (-1) \times \boxed{9} \\ &+ 1 \times \boxed{13} + 0 \times \boxed{14} + (-1) \times \boxed{15} \\ &= 1 + 0 - 3 + 7 + 0 - 9 + 13 + 0 - 15 \\ &= -6 \end{aligned}S(0,0)=1×1+0×2+(−1)×3+1×7+0×8+(−1)×9+1×13+0×14+(−1)×15=1+0−3+7+0−9+13+0−15=−6
所以输出特征图的左上角第一个值是 −6-6−6。
3.2.3 第三步:向右滑动一步,重复计算
现在把卷积核向右移动一格(步幅 stride=1),覆盖区域变成:
Iregion=[2348910141516]I_{\text{region}} = \begin{bmatrix} \boxed{2} & \boxed{3} & \boxed{4} \\ \boxed{8} & \boxed{9} & \boxed{10} \\ \boxed{14} & \boxed{15} & \boxed{16} \end{bmatrix}Iregion= 2814391541016
S(0,1)=1×2+0×3+(−1)×4+1×8+0×9+(−1)×10+1×14+0×15+(−1)×16=−6\begin{aligned} S(0,1) &= 1 \times \boxed{2} + 0 \times \boxed{3} + (-1) \times \boxed{4} \\ &+ 1 \times \boxed{8} + 0 \times \boxed{9} + (-1) \times \boxed{10} \\ &+ 1 \times \boxed{14} + 0 \times \boxed{15} + (-1) \times \boxed{16} \\ &= -6 \end{aligned}S(0,1)=1×2+0×3+(−1)×4+1×8+0×9+(−1)×10+1×14+0×15+(−1)×16=−6
注意这里有个有趣的观察:因为我们用了垂直边缘检测核(左正右负),当卷积核滑到一个"左边亮、右边暗"的区域时,输出会是正值。
3.2.4 第四步:继续滑动,直到覆盖整张图像
重复上述过程,每次向右或向下移动一格,直到卷积核的右下角触到图像的右下角。最终得到的输出特征图尺寸为 4×44 \times 44×4(计算公式见 3.3 节)。
3.2.5 完整过程可视化
输入 6×6 卷积核 3×3 输出 4×4
┌─────────────────┐ ┌───────────┐ ┌─────────────────┐
│[1 2 3] 4 5 6│ │ 1 0 -1 │ │ -6 -6 -6 -6 │ ← 第一行
│[7 8 9] 10 11 12│ │ 1 0 -1 │ │ -6 -6 -6 -6 │ ← 第二行
│[13 14 15] 17 18 │ │ 1 0 -1 │ │ -6 -6 -6 -6 │ ← 第三行
│ 19 20 21 ... │ └───────────┘ │ -6 -6 -6 -6 │ ← 第四行
│ 25 26 27 ... │ └─────────────────┘
│ 31 32 33 ... │
└─────────────────┘
↑ 第一步:框住的区域与卷积核做逐元素相乘再求和
多嘴一句:你可能会注意到这个例子的输出全是 −6-6−6。这是因为输入图像的数值是均匀递增的(1,2,3,…,36),每一行的梯度完全一样。真实的图像不会这么"完美",不同位置的卷积结果会有正有负、有大有小,正是这些差异构成了丰富的特征图。
3.3 关键概念拆解:Stride(步幅)和 Padding(填充)
3.3.1 Stride(步幅):窗口每次走多远
定义:卷积核每次滑动的格子数。
| 步幅 | 效果 | 输出尺寸 | 说明 |
|---|---|---|---|
| s=1s=1s=1 | 每次移动 1 格 | 较大 | 信息保留最完整 |
| s=2s=2s=2 | 每次移动 2 格 | 减半 | 常用于降维 |
| s=3s=3s=3 | 每次移动 3 格 | 更小 | 信息损失较大 |
为什么需要 stride > 1? 当图像很大时,stride=1 会产生很大的特征图,计算量爆炸。stride=2 可以自然地缩小特征图,替代一部分池化的功能。
3.3.2 Padding(填充):给图像"加边框"
定义:在输入图像的四周补零(zero-padding),让卷积核能滑到图像的边缘。
为什么需要 padding? 如果不加 padding,卷积每做一次图像就会缩小一圈。堆叠多层之后,图像可能变成负尺寸!常见的 padding 策略:
| 填充方式 | 符号 | 效果 | 适用场景 |
|---|---|---|---|
| 无填充 | p=0p=0p=0 | 输出缩小 | 简单网络 |
| 同尺寸填充 | p=⌊k/2⌋p = \lfloor k/2 \rfloorp=⌊k/2⌋ | 输出与输入相同 | 深层网络 |
| 自定义填充 | 指定数值 | 灵活控制 | 特殊需求 |
举例:输入 6×66 \times 66×6,卷积核 3×33 \times 33×3
- 无 padding(p=0p=0p=0):输出 = 6−31+1=4\frac{6 - 3}{1} + 1 = 416−3+1=4,即 4×44 \times 44×4
- 加 padding(p=1p=1p=1):先补一圈 0,变成 8×88 \times 88×8,输出 = 8−31+1=6\frac{8 - 3}{1} + 1 = 618−3+1=6,即 6×66 \times 66×6(保持原尺寸!)
3.4 卷积输出尺寸:万能公式
对于输入尺寸 Hin×WinH_{\text{in}} \times W_{\text{in}}Hin×Win,卷积核尺寸 k×kk \times kk×k,步幅 sss,填充 ppp:
Hout=⌊Hin+2p−ks⌋+1H_{\text{out}} = \left\lfloor \frac{H_{\text{in}} + 2p - k}{s} \right\rfloor + 1Hout=⌊sHin+2p−k⌋+1
Wout=⌊Win+2p−ks⌋+1W_{\text{out}} = \left\lfloor \frac{W_{\text{in}} + 2p - k}{s} \right\rfloor + 1Wout=⌊sWin+2p−k⌋+1
实战验证:MNIST 输入 28×2828 \times 2828×28,LeNet-5 第一层卷积核 5×55 \times 55×5,无填充,步幅 1:
Hout=28+0−51+1=24H_{\text{out}} = \frac{28 + 0 - 5}{1} + 1 = 24Hout=128+0−5+1=24
所以第一层卷积输出是 24×2424 \times 2424×24。
3.5 卷积的三大核心优势
局部连接:每个输出只跟输入的一小块区域有关,保留了空间邻接关系。不像全连接层那样"每个像素跟每个输出都连"。
参数共享:同一个卷积核在整个图像上滑动,只需学一套参数。一个 3×33 \times 33×3 的卷积核只有 9 个参数(加偏置是 10 个),但它能"看"遍整张图!
平移等变性(Translation Equivariance):图像里的物体平移了,输出特征图也会跟着平移。具体来说,就是输入平移,输出特征图也跟着平移相同的位置。这意味着网络学会了"识别特征"而不是"记住位置"。
换个角度想:如果说 MLP 的全连接层是"每个像素都跟每个输出节点连线",那卷积层就是"一个小窗口在图像上滑动,每次只看局部"。前者参数爆炸,后者高效又保留了空间信息。
3.6 感受野(Receptive Field):卷积核的"视野范围"
感受野是理解 CNN 的另一个重要概念。一个输出像素的感受野,是指输入图像中能够影响这个输出值的所有像素的区域。
- 第一层卷积:感受野 = 卷积核大小(如 3×33 \times 33×3)
- 第二层卷积:感受野 = 3+(3−1)=53 + (3-1) = 53+(3−1)=5,即 5×55 \times 55×5
- 第三层卷积:感受野 = 5+(3−1)=75 + (3-1) = 75+(3−1)=7,即 7×77 \times 77×7
随着网络层数加深,后面层的输出像素能看到越来越大的输入区域。这就是 CNN 能够从局部到全局理解图像的数学基础:浅层看到边缘,中层看到纹理,深层看到形状和物体。
下面咱们从零实现一个卷积函数,亲手看看卷积是怎么工作的。
# 从零实现二维卷积运算,理解底层原理
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
# ===== 第一步:定义卷积函数 =====
def manual_conv2d(image, kernel):
"""手动实现二维卷积(互相关运算)
Args:
image: 2D 输入图像 (H, W)
kernel: 2D 卷积核 (kH, kW)
Returns:
output: 2D 输出特征图 (H-kH+1, W-kW+1)
"""
h_in, w_in = image.shape
k_h, k_w = kernel.shape
# 输出尺寸计算公式:H_out = H_in - kH + 1, W_out = W_in - kW + 1
h_out = h_in - k_h + 1
w_out = w_in - k_w + 1
output = torch.zeros(h_out, w_out)
# 滑动窗口遍历
for i in range(h_out):
for j in range(w_out):
# 提取当前窗口覆盖的区域
window = image[i:i+k_h, j:j+k_w]
# 对应元素相乘后求和
output[i, j] = torch.sum(window * kernel)
return output
# ===== 第二步:创建测试图像 =====
test_image = torch.tensor([
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0],
[7.0, 8.0, 9.0, 10.0, 11.0, 12.0],
[13.0, 14.0, 15.0, 16.0, 17.0, 18.0],
[19.0, 20.0, 21.0, 22.0, 23.0, 24.0],
[25.0, 26.0, 27.0, 28.0, 29.0, 30.0],
[31.0, 32.0, 33.0, 34.0, 35.0, 36.0]
])
print("=" * 60)
print("📝 第一步:输入图像和卷积核")
print("=" * 60)
print("\n输入图像 (6×6):")
print(test_image)
# ===== 第三步:定义垂直边缘检测核 =====
edge_kernel = torch.tensor([
[ 1.0, 0.0, -1.0],
[ 1.0, 0.0, -1.0],
[ 1.0, 0.0, -1.0]
])
print("\n卷积核 (3×3):垂直边缘检测器")
print(edge_kernel)
print("解读:左边是+1,右边是-1 → 检测从左到右由亮变暗的边缘")
# ===== 第四步:手动演示第一个位置的卷积计算 =====
print("\n" + "=" * 60)
print("🔍 第二步:手动计算第一个位置的卷积结果")
print("=" * 60)
# 提取左上角 3×3 区域
window_00 = test_image[0:3, 0:3]
print(f"\n窗口覆盖区域(图像左上角 3×3):")
print(window_00)
print(f"\n逐元素相乘:")
product = window_00 * edge_kernel
print(product)
result_00 = torch.sum(product).item()
print(f"\n求和结果: {result_00:.1f}")
print("计算过程: 1×1 + 2×0 + 3×(-1) + 7×1 + 8×0 + 9×(-1) + 13×1 + 14×0 + 15×(-1)")
print(" = 1 + 0 - 3 + 7 + 0 - 9 + 13 + 0 - 15 = -6")
# ===== 第五步:执行完整卷积 =====
print("\n" + "=" * 60)
print("📊 第三步:完整卷积输出")
print("=" * 60)
result = manual_conv2d(test_image, edge_kernel)
print(f"\n卷积输出 (4×4):")
print(result)
print(f"\n观察:")
print(f" • 输出尺寸: {result.shape}(从 6×6 缩小为 4×4)")
print(f" • 所有值均为 -6:因为输入图像均匀递增,每一行的梯度一致")
print(f" • 真实图像不会有如此均匀的梯度,输出会有正有负")
# ===== 第六步:可视化卷积过程 =====
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# 左侧:输入图像
im1 = axes[0].imshow(test_image.numpy(), cmap='viridis', aspect='equal')
axes[0].set_title('输入图像 (6×6)', fontsize=12, fontweight='bold')
axes[0].set_xlabel('列')
axes[0].set_ylabel('行')
for i in range(6):
for j in range(6):
axes[0].text(j, i, f'{int(test_image[i, j])}',
ha='center', va='center',
color='white', fontsize=10, fontweight='bold')
# 标记第一个窗口
rect = plt.Rectangle((-0.5, -0.5), 3, 3, fill=False, edgecolor='red', linewidth=2)
axes[0].add_patch(rect)
axes[0].text(1, -1, '← 第一个窗口', color='red', fontsize=10, fontweight='bold')
plt.colorbar(im1, ax=axes[0], fraction=0.046)
# 中间:卷积核
im2 = axes[1].imshow(edge_kernel.numpy(), cmap='RdBu_r', aspect='equal', vmin=-1.5, vmax=1.5)
axes[1].set_title('卷积核 (3×3)\n垂直边缘检测', fontsize=12, fontweight='bold')
for i in range(3):
for j in range(3):
color = 'white' if abs(edge_kernel[i, j]) > 0.5 else 'black'
axes[1].text(j, i, f'{edge_kernel[i, j]:.0f}',
ha='center', va='center',
color=color, fontsize=12, fontweight='bold')
plt.colorbar(im2, ax=axes[1], fraction=0.046)
# 右侧:输出特征图
im3 = axes[2].imshow(result.numpy(), cmap='viridis', aspect='equal')
axes[2].set_title('输出特征图 (4×4)', fontsize=12, fontweight='bold')
for i in range(4):
for j in range(4):
axes[2].text(j, i, f'{result[i, j]:.1f}',
ha='center', va='center',
color='white', fontsize=10, fontweight='bold')
plt.colorbar(im3, ax=axes[2], fraction=0.046)
plt.tight_layout()
plt.show()
print("\n" + "=" * 60)
print("💡 小结:卷积的核心步骤")
print("=" * 60)
print("1. 把卷积核放在图像的某个位置")
print("2. 对应位置相乘:image[i:i+k, j:j+k] × kernel")
print("3. 所有乘积求和:torch.sum(product)")
print("4. 结果存入输出特征图的对应位置")
print("5. 滑动卷积核,重复步骤 2-4,直到覆盖整张图")
============================================================
📝 第一步:输入图像和卷积核
============================================================
输入图像 (6×6):
tensor([[ 1., 2., 3., 4., 5., 6.],
[ 7., 8., 9., 10., 11., 12.],
[13., 14., 15., 16., 17., 18.],
[19., 20., 21., 22., 23., 24.],
[25., 26., 27., 28., 29., 30.],
[31., 32., 33., 34., 35., 36.]])
卷积核 (3×3):垂直边缘检测器
tensor([[ 1., 0., -1.],
[ 1., 0., -1.],
[ 1., 0., -1.]])
解读:左边是+1,右边是-1 → 检测从左到右由亮变暗的边缘
============================================================
🔍 第二步:手动计算第一个位置的卷积结果
============================================================
窗口覆盖区域(图像左上角 3×3):
tensor([[ 1., 2., 3.],
[ 7., 8., 9.],
[13., 14., 15.]])
逐元素相乘:
tensor([[ 1., 0., -3.],
[ 7., 0., -9.],
[ 13., 0., -15.]])
求和结果: -6.0
计算过程: 1×1 + 2×0 + 3×(-1) + 7×1 + 8×0 + 9×(-1) + 13×1 + 14×0 + 15×(-1)
= 1 + 0 - 3 + 7 + 0 - 9 + 13 + 0 - 15 = -6
============================================================
📊 第三步:完整卷积输出
============================================================
卷积输出 (4×4):
tensor([[-6., -6., -6., -6.],
[-6., -6., -6., -6.],
[-6., -6., -6., -6.],
[-6., -6., -6., -6.]])
观察:
• 输出尺寸: torch.Size([4, 4])(从 6×6 缩小为 4×4)
• 所有值均为 -6:因为输入图像均匀递增,每一行的梯度一致
• 真实图像不会有如此均匀的梯度,输出会有正有负
============================================================
💡 小结:卷积的核心步骤
============================================================
1. 把卷积核放在图像的某个位置
2. 对应位置相乘:image[i:i+k, j:j+k] × kernel
3. 所有乘积求和:torch.sum(product)
4. 结果存入输出特征图的对应位置
5. 滑动卷积核,重复步骤 2-4,直到覆盖整张图
3.7 常见卷积核实战:不同的核,不同的"视角"
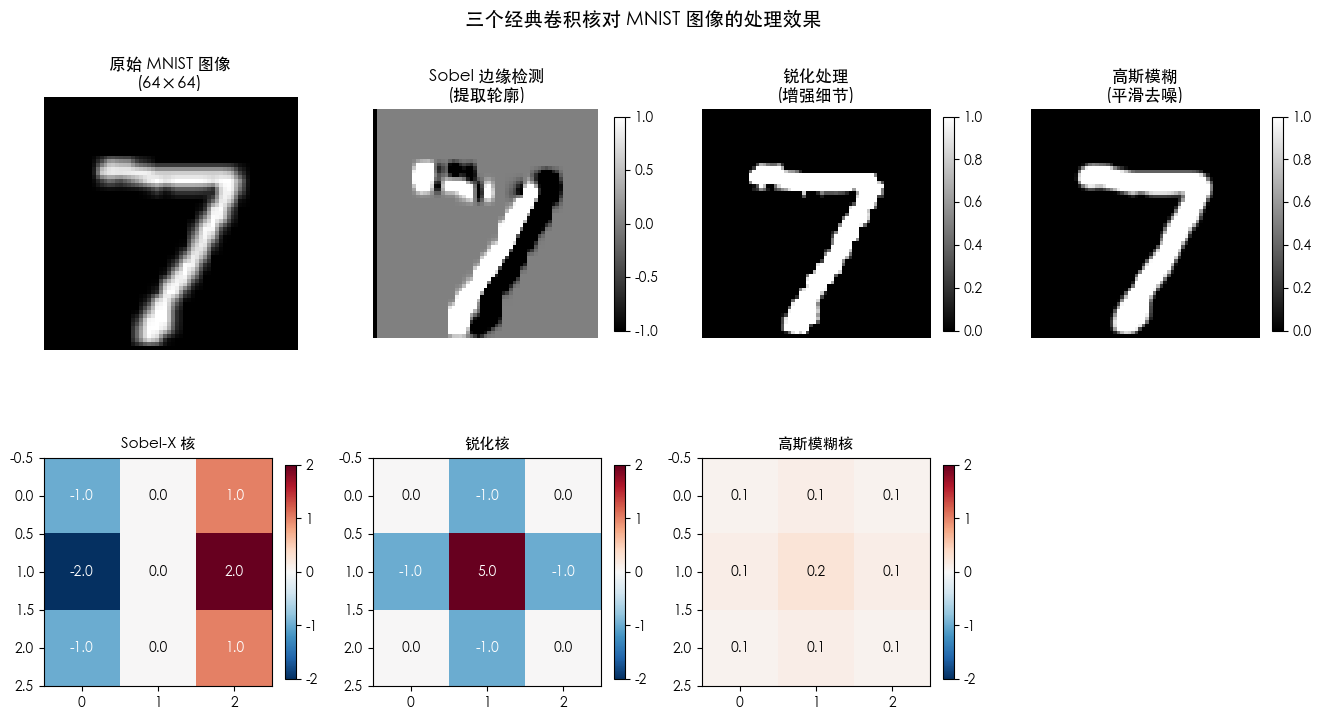
卷积核就像一个个"特征探测器",不同的核能提取不同的图像特征。这就像你用不同的滤镜看同一张照片——每个滤镜突出的是不同的信息。
边缘检测:Sobel 核
用于找出图像中的边缘和轮廓。它通过计算像素值的梯度来工作——梯度大的地方就是边缘。
KSobel-X=[−101−202−101],KSobel-Y=[−1−2−1000121]K_{\text{Sobel-X}} = \begin{bmatrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{bmatrix}, \quad K_{\text{Sobel-Y}} = \begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ 1 & 2 & 1 \end{bmatrix}KSobel-X= −1−2−1000121 ,KSobel-Y= −101−202−101
原理拆解:Sobel-X 核的左边是负数、右边是正数,中间是 0。这意味着它会检测从左到右的亮度变化——如果右边比左边亮,输出是正的;如果左边比右边亮,输出是负的。这就是水平方向(X 轴)的边缘检测。
Sobel-Y 同理,只是检测从上到下的亮度变化(垂直方向)。
锐化核
增强图像的细节和边缘,让模糊的地方变得更清晰。原理是突出中心像素与周围像素的差异:
KSharpen=[0−10−15−10−10]K_{\text{Sharpen}} = \begin{bmatrix} 0 & -1 & 0 \\ -1 & 5 & -1 \\ 0 & -1 & 0 \end{bmatrix}KSharpen= 0−10−15−10−10
原理拆解:中心权重是 5,四周是 -1。这相当于:5×中心 - (上+下+左+右)。如果中心像素比四周都亮(比如一个白色点周围是黑色),结果会非常大,让中心更"突出"。
高斯模糊核
对图像进行平滑处理,常用于去噪。给中心像素更高权重,周围像素权重随距离递减:
KBlur=116[121242121]K_{\text{Blur}} = \frac{1}{16} \begin{bmatrix} 1 & 2 & 1 \\ 2 & 4 & 2 \\ 1 & 2 & 1 \end{bmatrix}KBlur=161 121242121
原理拆解:中心权重最大(4/16 = 0.25),四周次之(2/16 = 0.125),角落最小(1/16 = 0.0625)。所有权重之和 = 1,保证亮度不变。
重要认知:在传统图像处理中,这些核是人工设计的,靠的是经验和数学推导。但在深度学习中,卷积核的数值是网络自己学出来的!CNN 通过反向传播自动调整卷积核的权重,学会最适合当前任务的"特征探测器"。这也是为什么 CNN 比传统方法效果更好的核心原因之一。
下面用 PyTorch 的 conv2d 来实际感受这些卷积核的威力!
# 使用 PyTorch 实现常见卷积核的效果展示
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from scipy.ndimage import zoom
# 1. 获取一张真实的测试图片
print("=== 加载真实测试图片 ===")
# 找到一张更像典型数字 7 的图片(带横杠的 7)
target_indices = [0, 15, 25, 35, 45, 55, 65, 75, 85, 95] # 先检查这些索引
found_idx = None
for idx in range(500):
if test_dataset[idx][1] == 7:
# 可视化看看哪个更像 7
img_check = test_dataset[idx][0].squeeze().numpy()
# 计算图像"重心":真正的 7 重心偏右上
h, w = img_check.shape
y_coords, x_coords = np.mgrid[:h, :w]
total = img_check.sum()
if total > 0:
center_x = (x_coords * img_check).sum() / total
center_y = (y_coords * img_check).sum() / total
# 7 的重心通常在右侧偏上 (x > w/2, y < h/2)
if center_x > w * 0.55 and center_y < h * 0.45:
found_idx = idx
print(f"📷 找到索引 {idx} 的手写数字 7 (标签验证: {test_dataset[idx][1]})")
print(f" 图像重心: ({center_x:.1f}, {center_y:.1f}) - 符合 7 的特征")
test_img_np = img_check
break
if found_idx is None:
# 如果没找到理想的,就用第一个 7
for idx in range(100):
if test_dataset[idx][1] == 7:
found_idx = idx
test_img_np = test_dataset[idx][0].squeeze().numpy()
print(f"📷 使用索引 {idx} 的数字 7")
break
# 为了更好展示卷积效果,将 28×28 上采样到 64×64
test_img_np = zoom(test_img_np, 64/28, order=1)
print(f"🔍 已上采样到 64×64")
# 转换为 PyTorch 张量 (batch, channel, H, W)
test_img = torch.from_numpy(test_img_np).unsqueeze(0).unsqueeze(0)
print(f"输入图像形状: {test_img.shape}")
print(f"像素值范围: [{test_img.min():.3f}, {test_img.max():.3f}]")
# === 三个经典卷积核对 MNIST 真实图像的处理效果 ===
# 定义三个卷积核
# 1. Sobel 边缘检测核(X 方向)
sobel_kernel = torch.tensor([[-1., 0., 1.],
[-2., 0., 2.],
[-1., 0., 1.]]).view(1, 1, 3, 3)
# 2. 锐化核
sharpen_kernel = torch.tensor([[ 0., -1., 0.],
[-1., 5., -1.],
[ 0., -1., 0.]]).view(1, 1, 3, 3)
# 3. 高斯模糊核
blur_kernel = torch.tensor([[1., 2., 1.],
[2., 4., 2.],
[1., 2., 1.]]).view(1, 1, 3, 3) / 16.0
# 对同一张图像分别做卷积
sobel_out = F.conv2d(test_img, sobel_kernel, padding=1).squeeze().numpy()
sharpen_out = F.conv2d(test_img, sharpen_kernel, padding=1).squeeze().numpy()
blur_out = F.conv2d(test_img, blur_kernel, padding=1).squeeze().numpy()
# 可视化:原始图像 + 三个卷积核处理结果 + 三个卷积核权重
fig = plt.figure(figsize=(16, 8))
gs = fig.add_gridspec(2, 4, hspace=0.3, wspace=0.3)
# 原始图像
ax0 = fig.add_subplot(gs[0, 0])
ax0.imshow(test_img_np, cmap='gray')
ax0.set_title('原始 MNIST 图像\n(64×64)', fontsize=12, fontweight='bold')
ax0.axis('off')
# Sobel 效果
ax1 = fig.add_subplot(gs[0, 1])
im1 = ax1.imshow(sobel_out, cmap='gray', vmin=-1, vmax=1)
ax1.set_title('Sobel 边缘检测\n(提取轮廓)', fontsize=12, fontweight='bold')
ax1.axis('off')
plt.colorbar(im1, ax=ax1, fraction=0.046, shrink=0.8)
# 锐化效果
ax2 = fig.add_subplot(gs[0, 2])
im2 = ax2.imshow(sharpen_out, cmap='gray', vmin=0, vmax=1)
ax2.set_title('锐化处理\n(增强细节)', fontsize=12, fontweight='bold')
ax2.axis('off')
plt.colorbar(im2, ax=ax2, fraction=0.046, shrink=0.8)
# 模糊效果
ax3 = fig.add_subplot(gs[0, 3])
im3 = ax3.imshow(blur_out, cmap='gray', vmin=0, vmax=1)
ax3.set_title('高斯模糊\n(平滑去噪)', fontsize=12, fontweight='bold')
ax3.axis('off')
plt.colorbar(im3, ax=ax3, fraction=0.046, shrink=0.8)
# 下方:三个卷积核的权重可视化
kernels = {
'Sobel-X 核': sobel_kernel.squeeze().numpy(),
'锐化核': sharpen_kernel.squeeze().numpy(),
'高斯模糊核': blur_kernel.squeeze().numpy()
}
for idx, (name, kernel) in enumerate(kernels.items()):
ax = fig.add_subplot(gs[1, idx])
im = ax.imshow(kernel, cmap='RdBu_r', vmin=-2, vmax=2, aspect='equal')
ax.set_title(name, fontsize=11, fontweight='bold')
for i in range(3):
for j in range(3):
val = kernel[i, j]
color = 'white' if abs(val) > 0.5 else 'black'
ax.text(j, i, f'{val:.1f}', ha='center', va='center',
fontsize=10, fontweight='bold', color=color)
plt.colorbar(im, ax=ax, fraction=0.046, shrink=0.8)
# 空白占位
ax4 = fig.add_subplot(gs[1, 3])
ax4.axis('off')
plt.suptitle('三个经典卷积核对 MNIST 图像的处理效果', fontsize=14, fontweight='bold', y=0.98)
plt.show()
print("✅ 可视化完成!")
print("\n观察要点:")
print(" • Sobel 核提取了数字的轮廓(边缘位置出现亮线)")
print(" • 锐化核让笔画边界更加清晰突出")
print(" • 模糊核让图像变得柔和,细节减少")
print("\n这就是卷积神经网络中'卷积核学习'的直观体现:网络会自动学到各种有用的特征探测器!")
=== 加载真实测试图片 ===
📷 使用索引 0 的数字 7
🔍 已上采样到 64×64
输入图像形状: torch.Size([1, 1, 64, 64])
像素值范围: [-0.424, 2.809]
✅ 可视化完成!
观察要点:
• Sobel 核提取了数字的轮廓(边缘位置出现亮线)
• 锐化核让笔画边界更加清晰突出
• 模糊核让图像变得柔和,细节减少
这就是卷积神经网络中'卷积核学习'的直观体现:网络会自动学到各种有用的特征探测器!
3.8 卷积的适用性分析
卷积虽然好用,但也不是万能的。来看看它最适合和不适合的场景。
卷积擅长的场景:
图像分类、目标检测、图像分割——这些任务的核心是提取边缘、纹理、形状等局部特征,这正是卷积的强项。任何具有空间或时间局部关联的数据,都可以考虑用卷积。
卷积不太适合的场景:
纯序列数据(如文本、时间序列)——虽然有 1D 卷积,但注意力机制通常更优。图结构数据——节点之间的关系不规则,需要图神经网络(GNN)。全局依赖关系强的任务——卷积的局部性限制了其感受野,需要堆叠多层或使用空洞卷积。
一句话总结:卷积的核心思想是利用数据的局部相关性,通过共享参数的方式提取空间特征。这使它在处理图像、音频、视频等具有规则网格结构的数据时表现出色。
接下来,我们学习 CNN 中的另一个关键组件——池化层,它帮助我们在保留重要特征的同时降低计算复杂度。
四、池化层:特征图的"瘦身大师"
卷积层提取了丰富的空间特征,但特征图的尺寸往往很大。直接把它们送入全连接层会导致参数量爆炸。这时就需要**池化层(Pooling Layer)**来帮忙了。
4.1 池化是什么?
池化的核心思想很简单:用一个小窗口在特征图上滑动,每次取窗口内的一个统计值作为代表。就像把一张高清照片压缩成缩略图——虽然丢失了一些细节,但主要轮廓依然清晰。
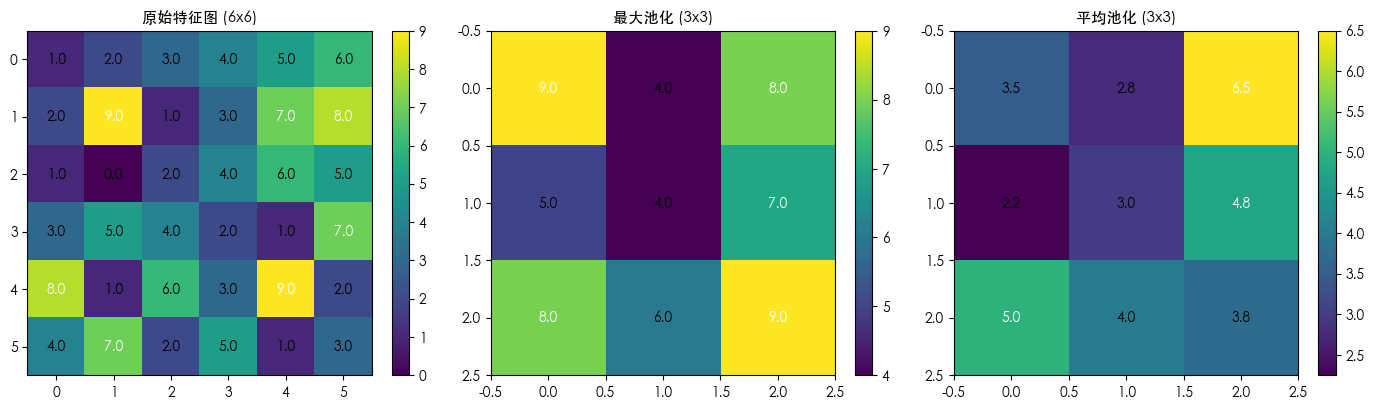
4.2 最大池化(Max Pooling)
取窗口内的最大值。这相当于问:“这个区域最显著的特征是什么?”
Pmax(i,j)=max(m,n)∈ΩF(i+m,j+n)P_{\text{max}}(i,j) = \max_{(m,n) \in \Omega} F(i+m, j+n)Pmax(i,j)=(m,n)∈ΩmaxF(i+m,j+n)
其中 Ω\OmegaΩ 是池化窗口覆盖的区域。
最大池化的优势:
- 保留最强烈的激活信号(最可能是特征所在位置)
- 对微小平移具有鲁棒性(物体移动一点,最大值通常不变)
- 计算简单高效
4.3 平均池化(Average Pooling)
取窗口内所有值的平均。这相当于问:“这个区域的整体响应强度是多少?”
Pavg(i,j)=1∣Ω∣∑(m,n)∈ΩF(i+m,j+n)P_{\text{avg}}(i,j) = \frac{1}{|\Omega|}\sum_{(m,n) \in \Omega} F(i+m, j+n)Pavg(i,j)=∣Ω∣1(m,n)∈Ω∑F(i+m,j+n)
平均池化的特点:
- 保留背景信息和全局响应
- 对噪声更平滑,不容易受极端值影响
- 适合编码全局上下文
4.4 池化输出尺寸怎么算?
对于输入尺寸 H×WH \times WH×W,池化窗口 k×kk \times kk×k,步幅 sss,输出尺寸为:
Hout=⌊H−ks⌋+1,Wout=⌊W−ks⌋+1H_{\text{out}} = \left\lfloor \frac{H - k}{s} \right\rfloor + 1, \quad W_{\text{out}} = \left\lfloor \frac{W - k}{s} \right\rfloor + 1Hout=⌊sH−k⌋+1,Wout=⌊sW−k⌋+1
通常使用 2×22 \times 22×2 窗口、步幅为 222 的配置,这样刚好将特征图尺寸减半。
多嘴一句:为什么要用池化?一来降维减少计算量,二来让网络对小的平移更鲁棒——特征稍微挪个位置,最大值通常还在。这在图像任务里特别有用。
下面通过代码直观对比两种池化的效果!
# 池化层原理与实现:最大值 vs 平均值
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
# 创建一个 6x6 的特征图(模拟卷积层输出)
feature_map = torch.tensor([[1.0, 2.0, 3.0, 4.0, 5.0, 6.0],
[2.0, 9.0, 1.0, 3.0, 7.0, 8.0],
[1.0, 0.0, 2.0, 4.0, 6.0, 5.0],
[3.0, 5.0, 4.0, 2.0, 1.0, 7.0],
[8.0, 1.0, 6.0, 3.0, 9.0, 2.0],
[4.0, 7.0, 2.0, 5.0, 1.0, 3.0]])
# 添加 batch 和 channel 维度:(1, 1, 6, 6)
feature_map = feature_map.unsqueeze(0).unsqueeze(0)
print("=== 原始特征图 (6x6) ===")
print(feature_map[0, 0])
# 1. 最大池化:2x2 窗口,步幅 2
max_pool = F.max_pool2d(feature_map, kernel_size=2, stride=2)
print("\n=== 最大池化输出 (3x3) ===")
print(max_pool[0, 0])
print("说明:每个 2x2 区域取最大值,保留了最显著的特征(如 9, 8, 7 等)")
# 2. 平均池化:2x2 窗口,步幅 2
avg_pool = F.avg_pool2d(feature_map, kernel_size=2, stride=2)
print("\n=== 平均池化输出 (3x3) ===")
print(avg_pool[0, 0])
print("说明:每个 2x2 区域取平均值,响应更平滑,没有极端值")
# 3. 手动演示最大池化的工作原理(第一个窗口)
print("\n=== 手动验证:左上角第一个 2x2 窗口 ===")
window = feature_map[0, 0, 0:2, 0:2]
print(f"窗口内容:\n{window}")
print(f"最大值: {window.max().item():.1f} (对应 max_pool[0,0,0,0])")
print(f"平均值: {window.mean().item():.2f} (对应 avg_pool[0,0,0,0])")
# 可视化对比
fig, axes = plt.subplots(1, 3, figsize=(14, 4))
def plot_heatmap(ax, data, title):
im = ax.imshow(data.numpy(), cmap='viridis', aspect='equal')
ax.set_title(title, fontsize=11, fontweight='bold')
# 添加数值标注
for i in range(data.shape[0]):
for j in range(data.shape[1]):
val = data[i, j].item()
color = 'white' if val > data.max().item() * 0.7 else 'black'
ax.text(j, i, f'{val:.1f}', ha='center', va='center',
fontsize=10, fontweight='bold', color=color)
plt.colorbar(im, ax=ax, fraction=0.046)
plot_heatmap(axes[0], feature_map[0, 0], '原始特征图 (6x6)')
plot_heatmap(axes[1], max_pool[0, 0], '最大池化 (3x3)')
plot_heatmap(axes[2], avg_pool[0, 0], '平均池化 (3x3)')
plt.tight_layout()
plt.show()
print("\n💡 池化的关键作用:")
print(" 1. 降维:从 6x6=36 个值压缩到 3x3=9 个值,减少 75% 的数据量")
print(" 2. 扩大感受野:后续层能看到更大的输入区域")
print(" 3. 增强平移不变性:小范围内的位置变化不影响池化结果")
print(" 4. 防止过拟合:减少参数量,降低模型复杂度")
=== 原始特征图 (6x6) ===
tensor([[1., 2., 3., 4., 5., 6.],
[2., 9., 1., 3., 7., 8.],
[1., 0., 2., 4., 6., 5.],
[3., 5., 4., 2., 1., 7.],
[8., 1., 6., 3., 9., 2.],
[4., 7., 2., 5., 1., 3.]])
=== 最大池化输出 (3x3) ===
tensor([[9., 4., 8.],
[5., 4., 7.],
[8., 6., 9.]])
说明:每个 2x2 区域取最大值,保留了最显著的特征(如 9, 8, 7 等)
=== 平均池化输出 (3x3) ===
tensor([[3.5000, 2.7500, 6.5000],
[2.2500, 3.0000, 4.7500],
[5.0000, 4.0000, 3.7500]])
说明:每个 2x2 区域取平均值,响应更平滑,没有极端值
=== 手动验证:左上角第一个 2x2 窗口 ===
窗口内容:
tensor([[1., 2.],
[2., 9.]])
最大值: 9.0 (对应 max_pool[0,0,0,0])
平均值: 3.50 (对应 avg_pool[0,0,0,0])
💡 池化的关键作用:
1. 降维:从 6x6=36 个值压缩到 3x3=9 个值,减少 75% 的数据量
2. 扩大感受野:后续层能看到更大的输入区域
3. 增强平移不变性:小范围内的位置变化不影响池化结果
4. 防止过拟合:减少参数量,降低模型复杂度
五、LeNet-5 实战:MNIST 手写数字识别
前面我们学习了卷积和池化的基本原理。现在,把它们组合起来,搭建一个完整的 CNN 网络——经典的 LeNet-5,用于 MNIST 手写数字识别。
LeNet-5 由 Yann LeCun 于 1998 年提出,是卷积神经网络的"开山之作"。虽然结构简单,但它确立了 CNN 的经典范式:卷积 → 激活 → 池化 → 全连接。
5.1 LeNet-5 网络结构总览
LeNet-5 的整体架构可以分为两大部分:特征提取(卷积层+池化层)和分类(全连接层)。
整体架构视图
我们可以把 LeNet-5 想象成一个"漏斗"结构:
输入 (28×28×1)
│
├── 特征提取阶段(逐层提取抽象特征)
│ ├── Conv1+ReLU: 28×28×1 → 24×24×6 (边缘检测)
│ ├── Pool1: 24×24×6 → 12×12×6 (空间压缩)
│ ├── Conv2+ReLU: 12×12×6 → 8×8×16 (组合特征)
│ └── Pool2: 8×8×16 → 4×4×16 (再次压缩)
│
├── Flatten: 4×4×16 → 256 维向量
│
└── 分类阶段(逐层映射到类别概率)
├── FC1+ReLU: 256 → 120 (高层特征融合)
├── FC2+ReLU: 120 → 84 (进一步抽象)
└── FC3: 84 → 10 (输出 10 个类别的概率)
特征提取阶段(卷积层+池化层)
| 层 | 操作 | 输入尺寸 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| Input | 输入 | 1×28×281 \times 28 \times 281×28×28 | 1×28×281 \times 28 \times 281×28×28 | 单通道灰度图 |
| Conv1 | 卷积 5×55 \times 55×5 | 1×28×281 \times 28 \times 281×28×28 | 6×24×246 \times 24 \times 246×24×24 | 6 个卷积核,无 padding |
| ReLU1 | 激活 | 6×24×246 \times 24 \times 246×24×24 | 6×24×246 \times 24 \times 246×24×24 | 引入非线性(维度不变) |
| Pool1 | 最大池化 2×22 \times 22×2 | 6×24×246 \times 24 \times 246×24×24 | 6×12×126 \times 12 \times 126×12×12 | 步幅 2,尺寸减半 |
| Conv2 | 卷积 5×55 \times 55×5 | 6×12×126 \times 12 \times 126×12×12 | 16×8×816 \times 8 \times 816×8×8 | 16 个卷积核 |
| ReLU2 | 激活 | 16×8×816 \times 8 \times 816×8×8 | 16×8×816 \times 8 \times 816×8×8 | 引入非线性 |
| Pool2 | 最大池化 2×22 \times 22×2 | 16×8×816 \times 8 \times 816×8×8 | 16×4×416 \times 4 \times 416×4×4 | 步幅 2,尺寸再减半 |
分类阶段(全连接层)
| 层 | 操作 | 输入尺寸 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| Flatten | 展平 | 4×4×164 \times 4 \times 164×4×16 | 256256256 | 将三维特征图转为一维 |
| FC1 | 全连接 | 256256256 | 120120120 | 第一个全连接层 |
| Act3 | ReLU | 120120120 | 120120120 | 引入非线性 |
| FC2 | 全连接 | 120120120 | 848484 | 第二个全连接层 |
| FC3 | 全连接 | 848484 | 101010 | 输出层(10 个类别) |
5.2 维度计算的关键公式
对于卷积层(无 padding,步幅为 1):
Hout=Hin−k+1H_{\text{out}} = H_{\text{in}} - k + 1Hout=Hin−k+1
对于池化层(步幅等于窗口大小):
Hout=HinkH_{\text{out}} = \frac{H_{\text{in}}}{k}Hout=kHin
其中 kkk 是卷积核或池化窗口的尺寸。
5.3 数据流转的直观理解
如果把 LeNet-5 看作一个信息处理流水线:
- Conv1:像 6 个不同的"显微镜",每个观察图像的不同方面(有的检测水平边缘,有的检测垂直边缘…)
- Pool1:把每张照片压缩成缩略图,保留最重要的信息
- Conv2:基于缩略图,用 16 个更复杂的"探测器"组合浅层特征
- Pool2:再次压缩,得到高度抽象的特征表示
- Flatten:把三维特征图拉成一维,准备分类
- FC1→FC2→FC3:像层层审批,最终决定这个数字是 0-9 中的哪一个
5.4 参数量分析
LeNet-5 的参数量主要集中在全连接层:
| 模块 | 参数量 | 占比 |
|---|---|---|
| Conv1 | 5×5×1×6+6=1565\times5\times1\times6 + 6 = 1565×5×1×6+6=156 | 0.35% |
| Conv2 | 5×5×6×16+16=2,4165\times5\times6\times16 + 16 = 2,4165×5×6×16+16=2,416 | 5.44% |
| FC1 | 256×120+120=30,840256\times120 + 120 = 30,840256×120+120=30,840 | 69.42% |
| FC2 | 120×84+84=10,164120\times84 + 84 = 10,164120×84+84=10,164 | 22.88% |
| FC3 | 84×10+10=85084\times10 + 10 = 85084×10+10=850 | 1.91% |
| 总计 | 44,426 | 100% |
关键洞察:虽然全连接层只有 3 个,但它们占据了 94% 以上的参数量!这也是为什么现代 CNN(如 ResNet、EfficientNet)倾向于用全局平均池化替代全连接层来大幅减少参数。
多嘴一句:做 CNN 的时候,养成随手检查维度的习惯非常重要。每一步输入输出尺寸都对得上,网络基本就没问题了。下面咱们一步步实现这个网络,并亲眼见证数据在每一层中的"变身"过程!
class LeNet5(nn.Module):
"""简化版 LeNet-5 用于 MNIST 识别 (28x28 输入)
支持 CUDA/MPS/CPU 设备
"""
def __init__(self):
super(LeNet5, self).__init__()
# === 特征提取模块 ===
# 第一层卷积:1 个输入通道(灰度图)→ 6 个输出通道,5x5 卷积核
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
# 第二层卷积:6 → 16 个通道,5x5 卷积核
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# === 分类模块 ===
# 全连接层:池化后的特征图展平为 16*4*4 = 256 维
# 计算路径: 28→Conv1(24)→Pool1(12)→Conv2(8)→Pool2(4)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # 10 个类别(数字 0-9)
def forward(self, x, verbose=False):
"""前向传播,verbose=True 时打印每层维度"""
if verbose:
print(f"输入: {x.shape}")
# Conv1: 输入 (1, 28, 28) → 卷积 5x5,无padding → 输出 (6, 24, 24)
# 维度计算: H_out = 28 - 5 + 1 = 24
x = self.conv1(x)
if verbose:
print(f"Conv1 后: {x.shape} [28→24 = 28-5+1]")
# ReLU 激活(维度不变)
x = F.relu(x)
if verbose:
print(f"ReLU1 后: {x.shape}")
# MaxPool1: 2x2 池化,步幅 2 → 输出 (6, 12, 12)
# 维度计算: H_out = 24 / 2 = 12
x = F.max_pool2d(x, kernel_size=2, stride=2)
if verbose:
print(f"Pool1 后: {x.shape} [24→12 = 24/2]")
# Conv2: 输入 (6, 12, 12) → 卷积 5x5 → 输出 (16, 8, 8)
# 维度计算: H_out = 12 - 5 + 1 = 8
x = self.conv2(x)
if verbose:
print(f"Conv2 后: {x.shape} [12→8 = 12-5+1]")
# ReLU 激活(维度不变)
x = F.relu(x)
if verbose:
print(f"ReLU2 后: {x.shape}")
# MaxPool2: 2x2 池化,步幅 2 → 输出 (16, 4, 4)
# 维度计算: H_out = 8 / 2 = 4
x = F.max_pool2d(x, kernel_size=2, stride=2)
if verbose:
print(f"Pool2 后: {x.shape} [8→4 = 8/2]")
# 展平: (16, 4, 4) → 256 维向量
x = x.view(x.size(0), -1)
if verbose:
print(f"Flatten 后: {x.shape} [16×4×4=256]")
# 全连接层
x = F.relu(self.fc1(x))
if verbose:
print(f"FC1+ReLU 后: {x.shape} [256→120]")
x = F.relu(self.fc2(x))
if verbose:
print(f"FC2+ReLU 后: {x.shape} [120→84]")
x = self.fc3(x) # 输出层不需要激活函数(交叉熵损失内部会处理)
if verbose:
print(f"FC3 (输出): {x.shape} [84→10]")
return x
# === 实例化模型并测试前向传播 ===
print("=== LeNet-5 维度流转演示 ===\n")
# 创建模型实例
model = LeNet5()
# 测试输入:batch=4, channel=1, 28x28
test_input = torch.randn(4, 1, 28, 28)
# 执行前向传播,verbose=True 打印每层维度变化
output = model(test_input, verbose=True)
print(f"\n=== 网络结构总结 ===")
print(model)
print(f"\n=== 参数量统计 ===")
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数量: {total_params:,}")
print(f"可训练参数: {trainable_params:,}")
print(f"不可训练参数: {total_params - trainable_params:,}")
=== LeNet-5 维度流转演示 ===
输入: torch.Size([4, 1, 28, 28])
Conv1 后: torch.Size([4, 6, 24, 24]) [28→24 = 28-5+1]
ReLU1 后: torch.Size([4, 6, 24, 24])
Pool1 后: torch.Size([4, 6, 12, 12]) [24→12 = 24/2]
Conv2 后: torch.Size([4, 16, 8, 8]) [12→8 = 12-5+1]
ReLU2 后: torch.Size([4, 16, 8, 8])
Pool2 后: torch.Size([4, 16, 4, 4]) [8→4 = 8/2]
Flatten 后: torch.Size([4, 256]) [16×4×4=256]
FC1+ReLU 后: torch.Size([4, 120]) [256→120]
FC2+ReLU 后: torch.Size([4, 84]) [120→84]
FC3 (输出): torch.Size([4, 10]) [84→10]
=== 网络结构总结 ===
LeNet5(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=256, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
=== 参数量统计 ===
总参数量: 44,426
可训练参数: 44,426
不可训练参数: 0
5.5 数据准备:加载 MNIST 数据集
有了网络结构,接下来需要准备训练数据。PyTorch 提供了便捷的 DataLoader 来自动处理数据加载和批处理。
MNIST 数据集包含:
- 训练集:60,000 张 28×2828 \times 2828×28 灰度手写数字图像
- 测试集:10,000 张图像
- 类别:0-9 共 10 个数字
数据预处理通常包括:
- 转换为张量:将 PIL 图像或 NumPy 数组转为 PyTorch 张量
- 归一化:将像素值从 [0,255][0, 255][0,255] 缩放到 [0,1][0, 1][0,1] 或标准化为均值为 0、方差为 1 的分布
下面加载数据集并可视化一些样本。
# 第二步:加载 MNIST 数据集并可视化
import torch
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
# 定义数据预处理:转换为张量 + 归一化
# 归一化参数 (0.1307, 0.3081) 是 MNIST 数据集的均值和标准差
transform = transforms.Compose([
transforms.ToTensor(), # 将 PIL 图像转为 Tensor,像素值从 [0,255] 缩放到 [0,1]
transforms.Normalize((0.1307,), (0.3081,)) # 标准化:x = (x - mean) / std
])
# 下载并加载训练集和测试集
# 注意:数据集会下载到本地 data/MNIST/ 目录
print("正在下载/加载 MNIST 数据集...")
train_dataset = torchvision.datasets.MNIST(
root='./data', # 数据存储目录
train=True, # True 表示训练集
download=True, # 如果本地没有则自动下载
transform=transform # 应用预处理
)
test_dataset = torchvision.datasets.MNIST(
root='./data',
train=False, # False 表示测试集
download=True,
transform=transform
)
# 创建 DataLoader:负责批处理和数据打乱
batch_size = 256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
print(f"\n✅ 数据集加载完成!")
print(f"训练集样本数: {len(train_dataset):,}")
print(f"测试集样本数: {len(test_dataset):,}")
print(f"训练批次数: {len(train_loader)} (每批 {batch_size} 张)")
# 可视化一些训练样本
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
for i, ax in enumerate(axes.flat):
# 随机获取一个样本
img, label = train_dataset[i]
# 反归一化以便可视化
img_denorm = img * 0.3081 + 0.1307 # x = x * std + mean
img_denorm = img_denorm.clamp(0, 1) # 截断到 [0, 1]
ax.imshow(img_denorm.squeeze(), cmap='gray')
ax.set_title(f'Label: {label}', fontsize=12, fontweight='bold')
ax.axis('off')
plt.suptitle('MNIST 手写数字样本展示', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
# 检查一个 batch 的形状
images, labels = next(iter(train_loader))
print(f"\n=== 一个 Batch 的数据形状 ===")
print(f"图像: {images.shape} [batch_size, channels, height, width]")
print(f"标签: {labels.shape} [batch_size]")
print(f"像素值范围: [{images.min():.3f}, {images.max():.3f}]")
正在下载/加载 MNIST 数据集...
✅ 数据集加载完成!
训练集样本数: 60,000
测试集样本数: 10,000
训练批次数: 235 (每批 256 张)

=== 一个 Batch 的数据形状 ===
图像: torch.Size([256, 1, 28, 28]) [batch_size, channels, height, width]
标签: torch.Size([256]) [batch_size]
像素值范围: [-0.424, 2.821]
5.6 定义损失函数与优化器
网络有了,数据有了,接下来需要告诉模型两个关键问题:
如何衡量预测的好坏? → 损失函数(Loss Function)
如何改进预测? → 优化器(Optimizer)
交叉熵损失(Cross-Entropy Loss)
对于多分类任务,交叉熵损失是最常用的选择。对于单个样本,公式为:
L=−∑c=1Cyclog(y^c)\mathcal{L} = -\sum_{c=1}^{C} y_c \log(\hat{y}_c)L=−c=1∑Cyclog(y^c)
其中 CCC 是类别数(MNIST 中为 10),ycy_cyc 是真实标签的 one-hot 编码,y^c\hat{y}_cy^c 是模型预测的概率。
直观理解:如果模型把正确的类别预测为高概率,损失就小;反之损失就大。
SGD 优化器(随机梯度下降)
SGD 通过沿梯度的反方向更新参数来最小化损失:
θt+1=θt−η⋅∇θL\theta_{t+1} = \theta_t - \eta \cdot \nabla_\theta \mathcal{L}θt+1=θt−η⋅∇θL
其中 η\etaη 是学习率(Learning Rate),控制每次更新的步长。学习率太大会导致震荡,太小则收敛缓慢。
GPU 加速:CUDA 与 MPS
深度学习涉及大量矩阵运算,GPU 的并行架构可以显著加速训练。PyTorch 支持多种加速后端:
| 设备 | 说明 | 适用场景 |
|---|---|---|
| CUDA | NVIDIA 显卡专属加速 | 台式机/游戏本,最成熟 |
| MPS | Apple Silicon (M1/M2/M3/M4) 原生加速 | MacBook,统一内存架构 |
| CPU | 通用处理器 | 无 GPU 时的备选 |
多嘴一句:MPS 是 Apple 自家的 GPU 加速方案,无需安装 NVIDIA CUDA 工具包。对于 MacBook 用户来说,PyTorch 会自动检测并使用 MPS,非常方便!
# 第三步:初始化模型、损失函数和优化器
import torch.optim as optim
# === 自动检测设备:优先使用 GPU 加速 ===
# 1. CUDA: NVIDIA GPU (需要安装 CUDA 驱动和 cudatoolkit)
# 2. MPS: Apple Silicon M1/M2/M3/M4 (macOS 原生 GPU 加速)
# 3. CPU: 默认回退选项
if torch.cuda.is_available():
device = torch.device('cuda')
device_name = torch.cuda.get_device_name(0)
print(f"🎮 检测到 NVIDIA GPU: {device_name}")
print(f" CUDA 版本: {torch.version.cuda}")
print(f" GPU 内存: {torch.cuda.get_device_properties(0).total_mem / 1024**3:.1f} GB")
elif hasattr(torch.backends, 'mps') and torch.backends.mps.is_available():
device = torch.device('mps')
print(f"🍎 检测到 Apple Silicon GPU (MPS 加速)")
print(f" PyTorch MPS 后端已启用,使用统一内存架构")
else:
device = torch.device('cpu')
print(f"💻 未检测到 GPU,使用 CPU 运行")
print(f"👉 使用设备: {device}")
# 创建模型实例并移到设备上
model = LeNet5().to(device)
# 定义损失函数:交叉熵损失(内部包含 Softmax,所以网络输出不需要加激活)
criterion = nn.CrossEntropyLoss()
# 定义优化器:SGD + 动量
# 动量 (momentum=0.9) 可以在梯度方向一致时加速收敛,遇到震荡时起到缓冲作用
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 打印模型参数总量
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"\n模型总参数量: {total_params:,}")
print(f"可训练参数: {trainable_params:,}")
print(f"\n损失函数: {criterion}")
print(f"优化器: {optimizer}")
🍎 检测到 Apple Silicon GPU (MPS 加速)
PyTorch MPS 后端已启用,使用统一内存架构
👉 使用设备: mps
模型总参数量: 44,426
可训练参数: 44,426
损失函数: CrossEntropyLoss()
优化器: SGD (
Parameter Group 0
dampening: 0
differentiable: False
foreach: None
fused: None
lr: 0.01
maximize: False
momentum: 0.9
nesterov: False
weight_decay: 0
)
5.7 训练循环:把前面串起来
训练是整个深度学习流程的核心环节。每个训练周期(Epoch)包含以下步骤:
- 从 DataLoader 取出一个 batch 的数据
- 前向传播:将输入送入网络,得到预测结果
- 计算损失:对比预测结果与真实标签
- 反向传播:计算损失对每个参数的梯度
- 更新参数:优化器根据梯度调整模型权重
- 清零梯度:为下一个 batch 做准备
这个过程不断重复,直到遍历完整个训练集。通常我们会进行多个 Epoch,让模型逐步学习。
多嘴一句:这里的训练流程和上一节线性回归里的逻辑是一模一样的,只是网络从"wx + b"变成了"卷积+池化+全连接"。底层思想完全一致:前向算预测、反向算梯度、优化器更新参数。
下面咱们用代码跑通完整的训练循环。
# 第四步:完整的训练循环
import time
def train_one_epoch(model, train_loader, criterion, optimizer, device):
"""训练一个 epoch
Returns:
avg_loss: 平均损失
accuracy: 训练准确率
"""
model.train() # 切换到训练模式(启用 Dropout 等)
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (images, labels) in enumerate(train_loader):
# 将数据移到设备上
images, labels = images.to(device), labels.to(device)
# === 核心训练步骤 ===
# 1. 清零梯度(非常重要!否则梯度会累加)
optimizer.zero_grad()
# 2. 前向传播:获取模型预测
outputs = model(images)
# 3. 计算损失
loss = criterion(outputs, labels)
# 4. 反向传播:计算梯度
loss.backward()
# 5. 更新参数
optimizer.step()
# 统计信息
running_loss += loss.item()
_, predicted = outputs.max(1) # 取概率最大的类别
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
avg_loss = running_loss / len(train_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy
def evaluate(model, test_loader, criterion, device):
"""在测试集上评估模型
Returns:
avg_loss: 平均损失
accuracy: 测试准确率
"""
model.eval() # 切换到评估模式(关闭 Dropout 等)
running_loss = 0.0
correct = 0
total = 0
# 评估时不需要计算梯度,节省内存和计算
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
avg_loss = running_loss / len(test_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy
# 开始训练!
num_epochs = 10 # 训练 10 个 epoch
train_losses = []
train_accs = []
test_losses = []
test_accs = []
# === 显示设备加速信息 ===
device_info = ""
if device.type == 'cuda':
device_info = f"NVIDIA GPU 加速 ({torch.cuda.get_device_name(0)})"
print(f"🚀 GPU 加速已启用,训练速度将显著提升!")
elif device.type == 'mps':
device_info = "Apple Silicon GPU 加速 (MPS 后端)"
print(f"🚀 MPS 加速已启用,使用 Apple Silicon 统一内存架构")
else:
device_info = "CPU(无 GPU 加速,训练较慢)"
print(f"🚀 开始训练 LeNet-5 模型")
print(f"📱 计算设备: {device_info}")
print(f"🔢 使用设备: {device}")
print(f"⏱️ Epochs: {num_epochs}")
print(f"📏 学习率: {optimizer.param_groups[0]['lr']}")
print("-" * 60)
start_time = time.time()
for epoch in range(num_epochs):
# 训练一个 epoch
t_loss, t_acc = train_one_epoch(model, train_loader, criterion, optimizer, device)
# 在测试集上评估
te_loss, te_acc = evaluate(model, test_loader, criterion, device)
# 记录历史
train_losses.append(t_loss)
train_accs.append(t_acc)
test_losses.append(te_loss)
test_accs.append(te_acc)
# 打印进度
elapsed = time.time() - start_time
print(f"Epoch [{epoch+1:2d}/{num_epochs}] | "
f"Train Loss: {t_loss:.4f} Acc: {t_acc:.2f}% | "
f"Test Loss: {te_loss:.4f} Acc: {te_acc:.2f}% | "
f"Time: {elapsed:.1f}s")
print("-" * 60)
print(f"✅ 训练完成!总用时: {time.time() - start_time:.1f}秒")
print(f"最终测试准确率: {test_accs[-1]:.2f}%")
🚀 MPS 加速已启用,使用 Apple Silicon 统一内存架构
🚀 开始训练 LeNet-5 模型
📱 计算设备: Apple Silicon GPU 加速 (MPS 后端)
🔢 使用设备: mps
⏱️ Epochs: 10
📏 学习率: 0.01
------------------------------------------------------------
Epoch [ 1/10] | Train Loss: 0.8419 Acc: 73.74% | Test Loss: 0.1468 Acc: 95.51% | Time: 3.0s
Epoch [ 2/10] | Train Loss: 0.1254 Acc: 96.13% | Test Loss: 0.0884 Acc: 97.13% | Time: 5.8s
Epoch [ 3/10] | Train Loss: 0.0842 Acc: 97.38% | Test Loss: 0.0660 Acc: 97.85% | Time: 8.7s
Epoch [ 4/10] | Train Loss: 0.0653 Acc: 97.92% | Test Loss: 0.0532 Acc: 98.17% | Time: 11.6s
Epoch [ 5/10] | Train Loss: 0.0550 Acc: 98.25% | Test Loss: 0.0510 Acc: 98.40% | Time: 15.1s
Epoch [ 6/10] | Train Loss: 0.0475 Acc: 98.54% | Test Loss: 0.0452 Acc: 98.38% | Time: 18.3s
Epoch [ 7/10] | Train Loss: 0.0420 Acc: 98.69% | Test Loss: 0.0424 Acc: 98.54% | Time: 21.7s
Epoch [ 8/10] | Train Loss: 0.0378 Acc: 98.78% | Test Loss: 0.0374 Acc: 98.78% | Time: 25.3s
Epoch [ 9/10] | Train Loss: 0.0338 Acc: 98.93% | Test Loss: 0.0405 Acc: 98.63% | Time: 28.7s
Epoch [10/10] | Train Loss: 0.0329 Acc: 98.91% | Test Loss: 0.0429 Acc: 98.65% | Time: 32.5s
------------------------------------------------------------
✅ 训练完成!总用时: 32.5秒
最终测试准确率: 98.65%
5.8 训练结果可视化
训练完成后,咱们需要通过图表来分析模型的学习情况。两个最关键的指标是:
损失曲线(Loss Curve):训练损失下降表示模型在拟合训练数据,测试损失下降表示模型具有良好的泛化能力。如果训练损失持续下降但测试损失开始上升,说明出现了过拟合。
准确率曲线(Accuracy Curve):训练准确率上升表示模型学习到了训练集的模式,测试准确率接近训练准确率说明模型泛化良好。两者差距过大可能意味着过拟合或欠拟合。
下面画出训练过程中的损失和准确率变化曲线。
# 第五步:可视化训练结果
import matplotlib.pyplot as plt
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
# 损失曲线
epochs_range = range(1, num_epochs + 1)
ax1.plot(epochs_range, train_losses, 'b-o', label='训练损失', linewidth=2, markersize=6)
ax1.plot(epochs_range, test_losses, 'r-s', label='测试损失', linewidth=2, markersize=6)
ax1.set_xlabel('Epoch', fontsize=12)
ax1.set_ylabel('Loss', fontsize=12)
ax1.set_title('训练与测试损失变化', fontsize=13, fontweight='bold')
ax1.legend(fontsize=11)
ax1.grid(True, alpha=0.3)
# 准确率曲线
ax2.plot(epochs_range, train_accs, 'b-o', label='训练准确率', linewidth=2, markersize=6)
ax2.plot(epochs_range, test_accs, 'r-s', label='测试准确率', linewidth=2, markersize=6)
ax2.set_xlabel('Epoch', fontsize=12)
ax2.set_ylabel('Accuracy (%)', fontsize=12)
ax2.set_title('训练与测试准确率变化', fontsize=13, fontweight='bold')
ax2.legend(fontsize=11)
ax2.grid(True, alpha=0.3)
ax2.set_ylim([min(test_accs) - 2, 100]) # 留出一些空间
plt.tight_layout()
plt.show()
# 打印最终结果
print("=" * 60)
print("📊 训练结果总结")
print("=" * 60)
print(f"最终训练准确率: {train_accs[-1]:.2f}%")
print(f"最终测试准确率: {test_accs[-1]:.2f}%")
print(f"训练/测试差距: {train_accs[-1] - test_accs[-1]:.2f}%")
print(f"\n💡 分析:")
if train_accs[-1] - test_accs[-1] < 2:
print(" 训练和测试准确率接近,模型泛化良好!")
elif train_accs[-1] - test_accs[-1] > 5:
print(" 训练准确率远高于测试准确率,可能存在过拟合。")
else:
print(" 差距在合理范围内,模型表现不错。")
if test_accs[-1] > 98:
print(" 测试准确率超过 98%,模型非常优秀!🎉")
elif test_accs[-1] > 95:
print(" 测试准确率超过 95%,模型表现良好。")
else:
print(" 测试准确率低于 95%,可以尝试调参或增加训练轮数。")
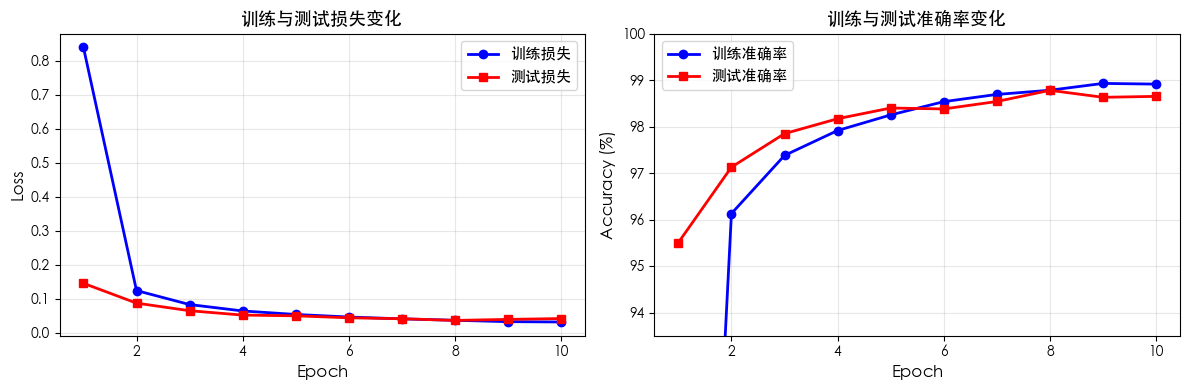
============================================================
📊 训练结果总结
============================================================
最终训练准确率: 98.91%
最终测试准确率: 98.65%
训练/测试差距: 0.26%
💡 分析:
训练和测试准确率接近,模型泛化良好!
测试准确率超过 98%,模型非常优秀!🎉
5.9 看看模型实际预测效果
训练好的模型到底学到了什么?咱们随机抽取一些测试样本,看看模型的预测结果和置信度。
# 第六步:可视化模型预测结果
import torch.nn.functional as F
def visualize_predictions(model, test_dataset, num_samples=10, device='cpu'):
"""随机抽取样本并可视化模型预测结果"""
model.eval()
# 随机选择样本
indices = torch.randperm(len(test_dataset))[:num_samples]
fig, axes = plt.subplots(2, 5, figsize=(15, 7))
for idx, ax in enumerate(axes.flat):
# 获取样本
img, true_label = test_dataset[indices[idx]]
# 推理
with torch.no_grad():
img_batch = img.unsqueeze(0).to(device) # 添加 batch 维度
output = model(img_batch)
probs = F.softmax(output, dim=1) # 转换为概率
pred_label = output.argmax(1).item()
confidence = probs.max().item()
# 反归一化用于可视化
img_denorm = img * 0.3081 + 0.1307
img_denorm = img_denorm.clamp(0, 1)
# 绘制图像
ax.imshow(img_denorm.squeeze(), cmap='gray')
# 设置标题(避免使用 STHeiti 不支持的 ✓ ✗ 符号)
if pred_label == true_label:
title_color = 'green'
title = f'预测: {pred_label} ({confidence*100:.1f}%) [正确]'
else:
title_color = 'red'
title = f'预测: {pred_label} ({confidence*100:.1f}%) [错误]\n真实: {true_label}'
ax.set_title(title, fontsize=11, fontweight='bold', color=title_color)
ax.axis('off')
plt.suptitle('LeNet-5 模型预测结果展示', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
# 执行可视化
# 确保模型在正确的设备上(防止模型参数在 CPU 而输入在 GPU/MPS)
model = model.to(device)
visualize_predictions(model, test_dataset, num_samples=10, device=device)
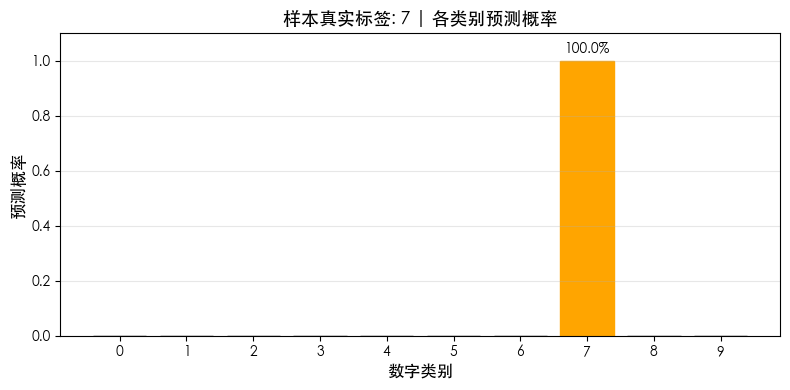
# 额外展示每个类别的预测概率分布(以第一个样本为例)
print("\n=== 第一个样本的概率分布 ===")
model.eval()
with torch.no_grad():
img, true_label = test_dataset[0]
img_batch = img.unsqueeze(0).to(device)
output = model(img_batch)
probs = F.softmax(output, dim=1).squeeze().cpu().numpy()
fig, ax = plt.subplots(figsize=(8, 4))
bars = ax.bar(range(10), probs, color='steelblue', edgecolor='black')
ax.set_xlabel('数字类别', fontsize=12)
ax.set_ylabel('预测概率', fontsize=12)
ax.set_title(f'样本真实标签: {true_label} | 各类别预测概率', fontsize=13, fontweight='bold')
ax.set_xticks(range(10))
ax.set_ylim(0, 1.1)
ax.grid(axis='y', alpha=0.3)
# 标注最高概率
max_idx = probs.argmax()
bars[max_idx].set_color('orange')
ax.annotate(f'{probs[max_idx]*100:.1f}%',
xy=(max_idx, probs[max_idx]),
xytext=(0, 5),
textcoords='offset points',
ha='center', fontsize=10, fontweight='bold')
plt.tight_layout()
plt.show()

=== 第一个样本的概率分布 ===
六、总结与延伸
恭喜你,从零开始走完了 CNN 的完整学习流程!咱们来回顾一下这篇笔记的核心收获。
6.1 核心知识点回顾
MLP 的局限性:全连接网络在处理图像时,强制将二维结构展平为一维向量,破坏了像素间的空间邻接关系,且参数量随图像尺寸急剧增长。
卷积操作的优势:
- 局部连接:每个神经元只关注输入的一小块区域,保留空间结构
- 参数共享:同一卷积核在整个图像上滑动,大幅减少参数量
- 平移等变性:能自动识别不同位置出现的相同模式
池化层的作用:通过降采样压缩特征图尺寸,降低计算复杂度的同时增强模型的平移不变性。最大池化保留最强特征,平均池化保留全局响应。
LeNet-5 的设计范式:卷积 → 激活 → 池化 → 全连接的经典组合,成为了后续几乎所有 CNN 架构的基础模板。
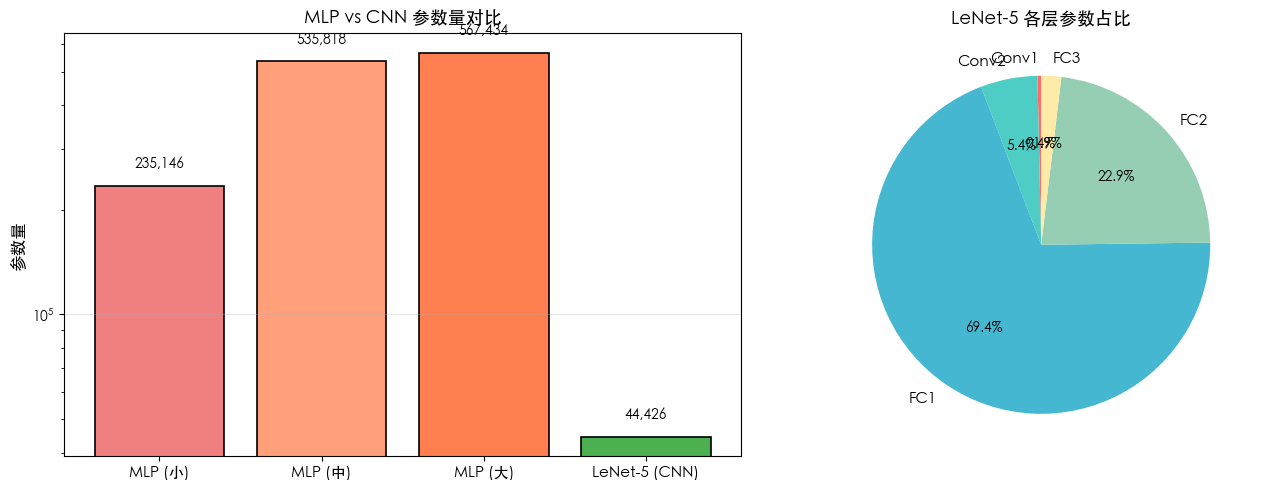
6.1.1 实战验证:MLP vs CNN 参数量对比
前面提到"卷积的参数效率远高于全连接",下面用代码直观验证:实现相同任务(MNIST 识别),MLP 和 CNN 的参数量差距有多大。
# 参数数量对比:MLP vs CNN —— 谁更高效?
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
print("=" * 60)
print("📊 MLP vs CNN 参数量对比分析")
print("=" * 60)
# ===== MLP 模型 =====
class MLP_MNIST(nn.Module):
"""用于 MNIST 的 MLP 网络"""
def __init__(self, hidden_dims=[784, 256, 128]):
super().__init__()
layers = []
dims = [784] + hidden_dims + [10]
for i in range(len(dims)-1):
layers.append(nn.Linear(dims[i], dims[i+1]))
if i < len(dims) - 2: # 最后一层不加激活
layers.append(nn.ReLU())
self.net = nn.Sequential(*layers)
def forward(self, x):
x = x.view(x.size(0), -1) # 展平
return self.net(x)
# ===== 用于参数对比的简化版 LeNet-5 CNN =====
class LeNet5_Simple(nn.Module):
"""LeNet-5 for MNIST (28x28 input → Pool2 output 4x4)"""
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 28→Conv1(24)→Pool1(12)→Conv2(8)→Pool2(4) → 展平 16*4*4=256
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
# ===== 创建不同配置的 MLP =====
mlp_small = MLP_MNIST(hidden_dims=[256, 128]) # 小 MLP
mlp_medium = MLP_MNIST(hidden_dims=[512, 256]) # 中等 MLP
mlp_large = MLP_MNIST(hidden_dims=[512, 256, 128]) # 大 MLP
# ===== 用于对比的简化 CNN =====
cnn = LeNet5_Simple()
# ===== 统计参数量 =====
def count_params(model):
total = sum(p.numel() for p in model.parameters())
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
return total, trainable
models = {
'MLP (小)': mlp_small,
'MLP (中)': mlp_medium,
'MLP (大)': mlp_large,
'LeNet-5 (CNN)': cnn
}
print(f"\n{'模型':<20} {'总参数量':>12} {'可训练参数':>12}")
print("-" * 50)
results = {}
for name, model in models.items():
total, trainable = count_params(model)
results[name] = total
print(f"{name:<18} {total:>12,} {trainable:>12,}")
print("-" * 50)
cnn_params = results['LeNet-5 (CNN)']
print(f"\n💡 关键发现:")
print(f" • LeNet-5 仅需 {cnn_params:,} 个参数")
print(f" • 中等 MLP 需要 {results['MLP (中)']:,} 个参数,是 CNN 的 {results['MLP (中)']//cnn_params} 倍")
print(f" • 大 MLP 需要 {results['MLP (大)']:,} 个参数,是 CNN 的 {results['MLP (大)']//cnn_params} 倍")
# ===== 可视化对比 =====
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
# 柱状图
names = list(results.keys())
values = list(results.values())
colors = ['lightcoral', 'lightsalmon', 'coral', '#4CAF50']
bars = ax1.bar(range(len(names)), values, color=colors, edgecolor='black', linewidth=1.2)
ax1.set_xticks(range(len(names)))
ax1.set_xticklabels(names, fontsize=11)
ax1.set_ylabel('参数量', fontsize=12)
ax1.set_title('MLP vs CNN 参数量对比', fontsize=13, fontweight='bold')
ax1.set_yscale('log') # 对数刻度更清晰
ax1.grid(axis='y', alpha=0.3)
# 在柱子上标注数值
for bar, val in zip(bars, values):
ax1.text(bar.get_x() + bar.get_width()/2, bar.get_height()*1.1,
f'{val:,}', ha='center', va='bottom', fontsize=10, fontweight='bold')
# 饼图:CNN 中各层参数占比
cnn_param_details = {
'Conv1': sum(p.numel() for p in cnn.conv1.parameters()),
'Conv2': sum(p.numel() for p in cnn.conv2.parameters()),
'FC1': sum(p.numel() for p in cnn.fc1.parameters()),
'FC2': sum(p.numel() for p in cnn.fc2.parameters()),
'FC3': sum(p.numel() for p in cnn.fc3.parameters())
}
labels = list(cnn_param_details.keys())
sizes = list(cnn_param_details.values())
pie_colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4', '#FFEAA7']
wedges, texts, autotexts = ax2.pie(sizes, labels=labels, autopct='%1.1f%%',
colors=pie_colors, startangle=90,
textprops={'fontsize': 11})
for autotext in autotexts:
autotext.set_fontweight('bold')
autotext.set_fontsize(10)
ax2.set_title('LeNet-5 各层参数占比', fontsize=13, fontweight='bold')
plt.tight_layout()
plt.show()
print(f"\n🎯 为什么 CNN 参数少却效果好?")
print(f" 1. 参数共享:一个卷积核在整张图上滑动,只学一套权重")
print(f" 2. 局部连接:每个输出只连一小块区域,不是全连接")
print(f" 3. 空间先验:天然利用图像的局部结构信息,学习效率更高")
============================================================
📊 MLP vs CNN 参数量对比分析
============================================================
模型 总参数量 可训练参数
--------------------------------------------------
MLP (小) 235,146 235,146
MLP (中) 535,818 535,818
MLP (大) 567,434 567,434
LeNet-5 (CNN) 44,426 44,426
--------------------------------------------------
💡 关键发现:
• LeNet-5 仅需 44,426 个参数
• 中等 MLP 需要 535,818 个参数,是 CNN 的 12 倍
• 大 MLP 需要 567,434 个参数,是 CNN 的 12 倍
🎯 为什么 CNN 参数少却效果好?
1. 参数共享:一个卷积核在整张图上滑动,只学一套权重
2. 局部连接:每个输出只连一小块区域,不是全连接
3. 空间先验:天然利用图像的局部结构信息,学习效率更高
6.2 延伸思考
LeNet-5 虽然是"老祖宗"级别的网络,但它的设计思想至今仍在进化:
| 网络 | 年份 | 关键创新 |
|---|---|---|
| AlexNet | 2012 | 引入 ReLU、Dropout、GPU 训练 |
| VGGNet | 2014 | 使用小卷积核(3×3)堆叠加深网络 |
| ResNet | 2015 | 残差连接解决梯度消失,可达上百层 |
| EfficientNet | 2019 | 统一缩放深度、宽度、分辨率 |
它们的核心思路都是一致的:用卷积提取局部特征,用池化逐步抽象,用全连接完成分类。只是在不同方向上做了更精细的设计。
6.3 下一步可以尝试的
- 修改 LeNet 的超参数(学习率、batch size、卷积核数量),观察对性能的影响
- 探索更深的网络结构(如 ResNet、VGG)
- 学习数据增强技术(随机旋转、裁剪、翻转)进一步提升泛化能力
- 了解批量归一化(BatchNorm)和 Dropout 等正则化手段
深度学习的世界才刚刚向你展开,继续探索吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)