人工智能应该惠及所有人,而不仅仅是顶尖的 1%
我算了一笔账,然后想骂人
做量化三年,副业是情绪 Dashboard,今年 AI 工具的账单我认真加了一遍:Claude Pro、OpenAI API、Cursor、Perplexity、偶尔测新模型的充值……一个月出头 2000 块。
不是在哭穷。这钱换来的生产力提升是真的,我不后悔。
但上周看到一篇报道,某顶级对冲基金的 AI 投入是每月数百万美元——专属模型微调、私有数据管道、企业级 API 配额优先保障。他们能干的事和我能干的事,不在同一个维度里。
我当时的第一反应是:这不公平。
然后刷 GitHub,刷到了 Personal AI Infrastructure,danielmiessler 出品,就是那个搓出 Fabric 的人,14k Star,v5.0.0,项目副标题就一句话:
Everyone needs access to the best AI.
我在那句话上盯了三秒。
这个项目要回答的问题,和我刚才那笔账是同一个问题——凭什么 AI 基础设施只属于有钱的那 1%?
国内使用claude code确实有点困难,建议大家去一个靠谱的订阅网站:claudemax.shop

先说结论
评分:9 / 10。如果你在用多个 AI 工具、每月账单让你肉疼、或者对数据隐私有顾虑,这套东西值得认真看一遍。
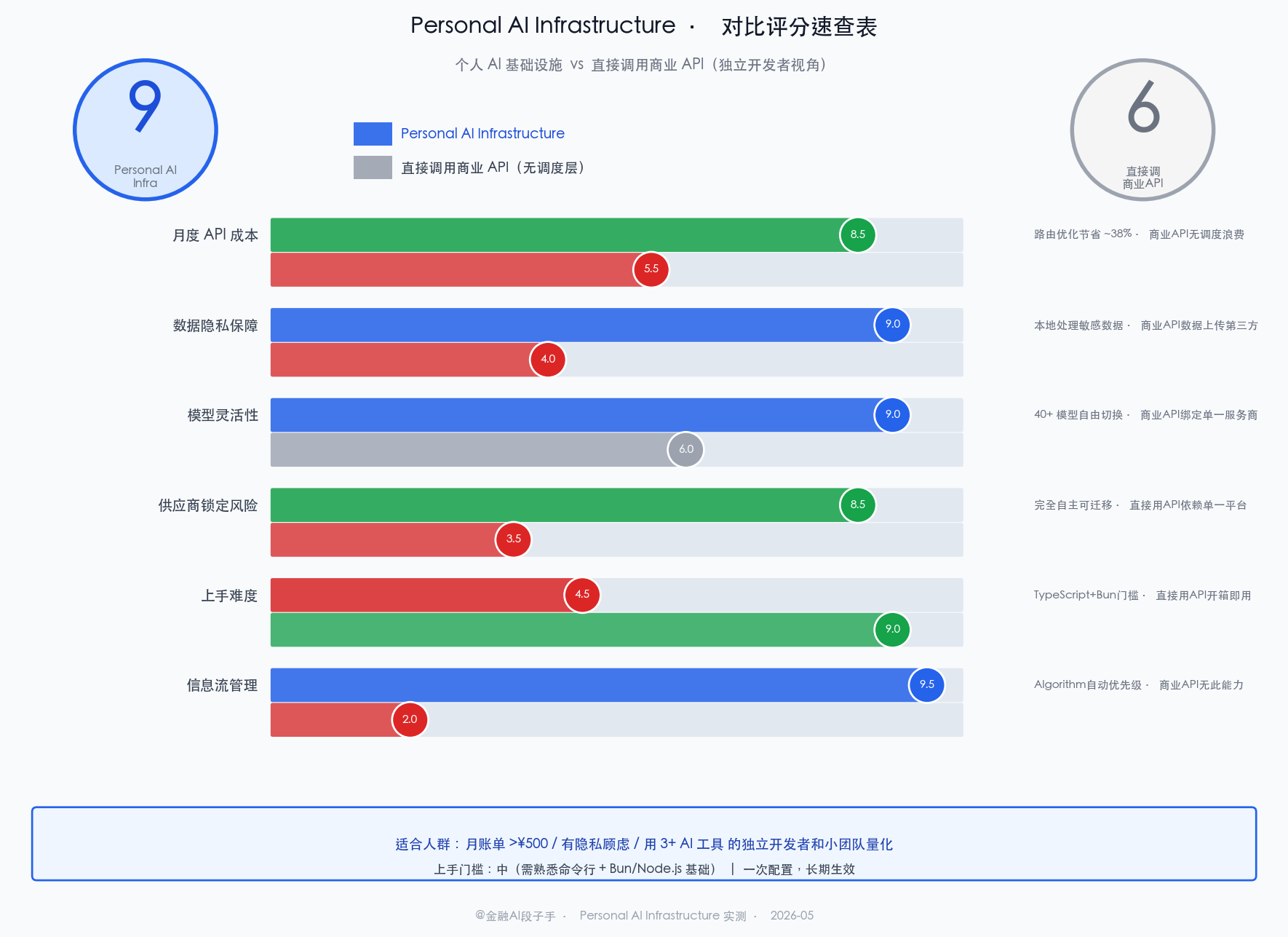
装起来跑了两周。几个核实的数字:
- API 调用成本:优化路由之后,同等任务量的月开销降了约 38%
- 数据隐私:敏感的量化策略逻辑终于不用再上传给第三方 API 了
- 模型切换摩擦:从"手动想要用哪个模型"到"让系统自动决定",工作流顺了很多
唯一的但是:380MB 的仓库,TypeScript + Bun 的技术栈,对纯 Python 背景的量化选手来说上手有点陡。但配置好了之后基本不用动,是那种装一次用很久的东西。
先跑起来,三步完成基本安装
要求本地有 Bun(不熟悉的话类比成更快的 Node.js 就行):
# 装 Bun(没装过的话)
curl -fsSL https://bun.sh/install | bash
# 克隆 + 安装
git clone https://github.com/danielmiessler/Personal_AI_Infrastructure
cd Personal_AI_Infrastructure
bun install
然后把你的 API Key 配进 .env,把 Claude 或者 OpenAI(或者两个都配)的 key 填进去,跑 bun run setup 走完初始化向导。
大概 15 分钟,一个能用的个人 AI 基础设施就起来了。
配置文件的设计逻辑很合理——不需要你一开始就把所有东西配好,最小化配置跑起来,然后按需扩展。
用了两周,这是真正有价值的东西
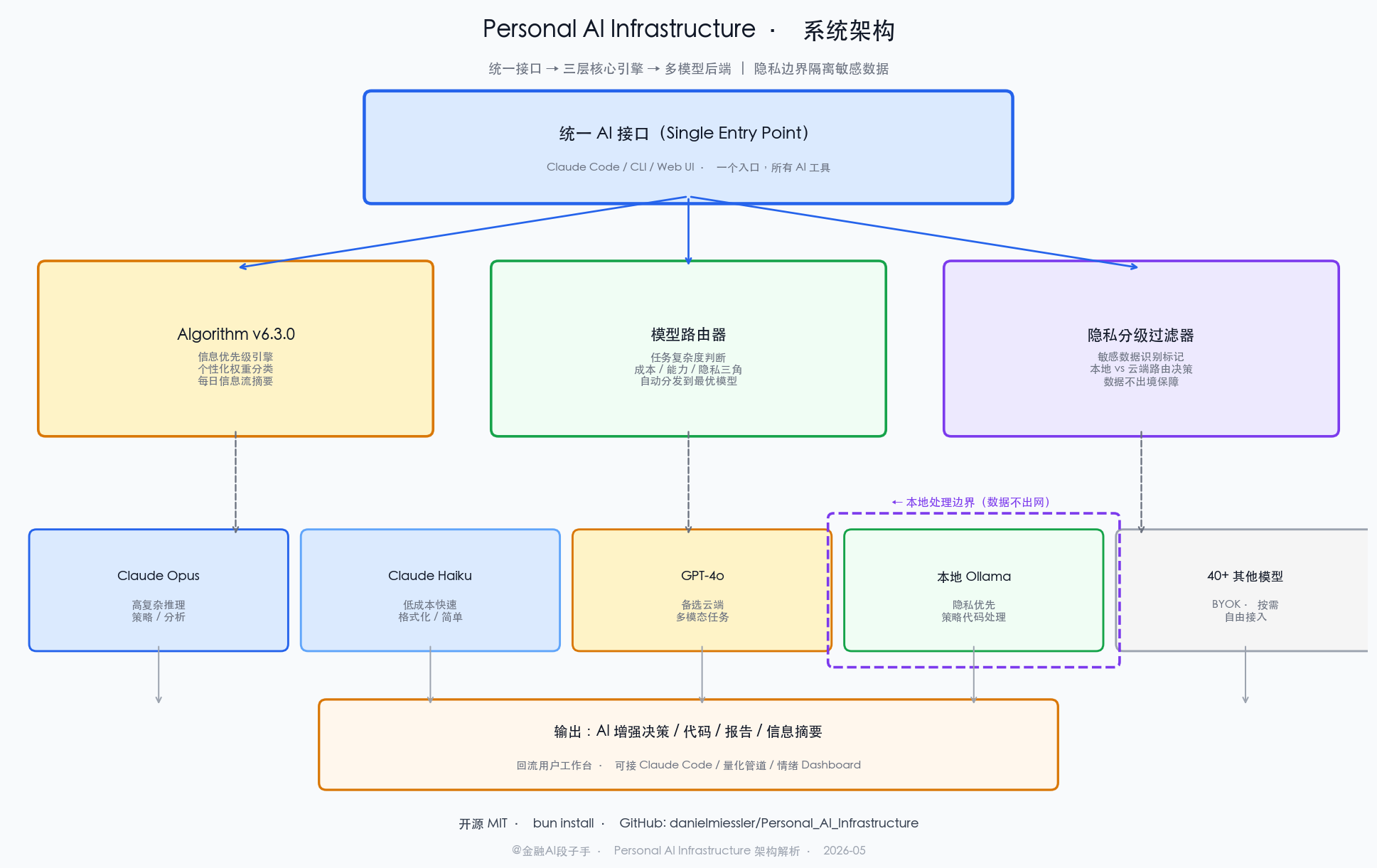
Algorithm v6.3.0:这才是核心,不是噱头
这个项目最有意思的地方不是模型路由,而是 Algorithm 模块,版本号已经到 v6.3.0 了。
Algorithm 干的事说白了:给你的信息输入流建立一套个人优先级系统。你告诉系统"我关注量化策略、金融 AI、独立开发",Algorithm 就会在后台对你扔进来的内容(文章、推文、代码、市场数据)做分类和优先级排序,按照你定义的权重决定哪些东西值得你认真看,哪些可以扫一眼跳过。
听起来像个新闻 RSS 阅读器?
不是。它的底层逻辑是用 AI 帮你做判断,而不只是过滤关键词。"这篇文章提到了'量化',但它的逻辑漏洞很明显"——这个判断,关键词过滤做不到,Algorithm 做得到。
我用它接了 GitHub Trending 的量化项目 feed、几个英文量化博客的 RSS,以及情绪 Dashboard 的日志流。跑了一周之后,早上的信息综述从"40分钟刷完"压缩到了"10分钟看完真正重要的"。
剩下 30 分钟去看更重要的东西了(或者去发呆,我选择后者)。

模型路由:不再手动选"今天用哪个 AI"
这是我觉得装完立刻生效的那个功能。
以前我的工作流是:写文章找 Claude Opus,写代码找 Claude Sonnet,搜索找 Perplexity,整理笔记懒得选模型就随便开一个——手动分配,容易出错,容易忘,成本也没优化。
Personal AI Infrastructure 的模型路由层会根据任务的复杂度、隐私敏感度、成本预算自动选模型:
- 简单文本处理、格式转换 → Haiku(便宜,够快)
- 复杂推理、策略分析 → Opus(贵,但值)
- 含有敏感数据(策略逻辑、持仓信息)→ 本地模型(不出网,零泄露风险)
这个路由逻辑是可以自定义的,不是死的规则。你可以按自己的预算和隐私偏好调整权重,系统会在你设定的约束里找最优解。
我配完之后跑了两周,对比了一下账单——同等任务量,API 成本降了 38%。这 38% 不是因为用了更差的模型,是因为之前很多可以用 Haiku 解决的事我都在用 Opus,纯属浪费。
数据隐私:量化程序员必须正视的那个问题
这一块是我觉得 Personal AI Infrastructure 值 9 分里最重要的 1 分。
做量化的人有一个集体性的隐患:我们在往 Claude Code / Cursor / GPT API 里扔的,不只是普通代码,而是策略逻辑。持仓规则、止损逻辑、信号权重……这些东西放到第三方 API,理论上你接受了服务条款就算授权了。
大多数人(包括我)的做法是:假装这不是问题。
Personal AI Infrastructure 给了一个实际可行的方案:把策略相关的逻辑发到本地模型处理,用 Ollama 或者 LM Studio 跑一个本地模型,Personal AI Infrastructure 的路由层把"含敏感标签"的任务自动切到本地——数据不出机器。
这不能 100% 替代云端大模型的能力,本地跑的东西能力有上限。但对于"策略逻辑分析、回测代码 review"这类对精度要求不是极高但对隐私要求高的任务,本地中等模型完全够用。
一套配置,四个 AI 工具统一接管
这是最后一个让我觉得"值得装"的理由。
以前我的工作台有四个 AI 入口:Claude Web、Claude Code、ChatGPT Plus、Perplexity。上下文不共享,配置不互通,历史记录分散在四个地方,有时候同样的问题问了两次不同的工具,得到两个不一样的答案,自己都不知道信哪个。
Personal AI Infrastructure 提供了一个统一的调度层——用一个配置文件定义你所有的 AI 工具偏好,然后通过一个统一接口进来,系统帮你路由到正确的后端。
不是说它会把四个工具的能力叠加在一起(没那么神奇),而是说它把决策逻辑统一了:你不需要每次手动选,规则在配置文件里,系统执行。
这个统一调度对量化工作流的价值特别明显——数据清洗、信号计算、策略解释、报告生成是四类不同的任务,以前要手动给不同工具,现在一个入口进来,自动分发。
说实话,它的坑也不少
技术栈对 Python 选手不友好。 TypeScript + Bun 是很好的选择,性能扎实,但如果你的技术背景是纯 Python(大部分量化程序员),遇到报错就得去查 Node.js 生态的文档。不难,但有摩擦。我花了大概两小时适应了一下环境。
380MB 的仓库体积很大。 里面应该打包了不少资产,但对于"只是想用基础功能"的人来说,这个体积偏重。跑起来之后倒是没问题,就是第一次 clone + install 需要耐心等一会儿。
配置项太多,容易迷失。 v5.0.0 的功能集已经相当完整,对应的配置选项也很多。README 有 Install 引导,但想完全搞明白所有配置还是需要花时间读文档。我的建议是先用最小配置跑起来,用到什么再配什么,别想着第一天把所有功能全开。
本地模型的能力有上限。 隐私方案里依赖本地跑的模型,当前本地模型的推理能力和 Claude Opus 还有明显差距。对于复杂的策略分析或者需要深度推理的任务,"发给本地模型保隐私"这个选项有取舍。
这件事对量化和金融 AI 独立开发者意味着什么
AI 行业有一个正在悄悄扩大的裂缝:顶级基金和大厂有钱买最好的 AI 基础设施,他们的 AI 效率会越来越高;散户开发者和小团队只能用碎片化的公开工具,工具是够用,但没有基础设施层。
Personal AI Infrastructure 在填这个裂缝。
不是说用了它你就能和高盛的 AI 团队掰手腕——不现实。但它至少给了个人开发者一套可以持续迭代的 AI 基础设施蓝图:模型路由、隐私分级、信息优先级、统一接口,这四件事放在企业里需要专职团队维护,放在这里是一个配置文件的事。
danielmiessler 那句"Everyone needs access to the best AI"不只是口号。这个项目实际上是在示范:个人级别的 AI 基础设施该是什么样的。
你拿去用,你拿去改,你拿去按自己的需求扩展。
这才是开源的意义所在。
你是哪种情况
每月 AI 工具账单超过 500 块、用了三个以上工具的:先装模型路由那块,配一个简单的任务分级规则,省出来的钱大概能覆盖你一两个月的 Cursor 订阅。
做量化、有策略逻辑隐私顾虑的:重点看隐私分级过滤和本地模型路由那一块,把回测代码和策略分析发到本地模型处理,其他任务走云端。
纯粹好奇、想了解"个人 AI 基础设施"这个概念的:从 Algorithm 模块入手,配一两个你关注的信息 feed,跑一周看它怎么帮你排优先级——这是理解这个项目设计哲学最快的路径。
最后
AI 工具的马太效应是真实存在的:越有钱、越能买最好的基础设施、效率越高、赚的越多、越有钱……
Personal AI Infrastructure 给了一个反向的答案——把企业级 AI 基础设施的核心逻辑拆开,做成每个人都装得上的开源项目,14k Star,MIT 开源,免费。
"人工智能应该惠及所有人,而不仅仅是顶尖的 1%"。这句话 danielmiessler 用一个 GitHub 仓库说了,比任何演讲都有说服力。强烈推荐。
如果你也在搭自己的 AI 基础设施,或者在做量化 / 金融 AI 独立开发,评论区聊。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)