【AAAI2026】GuideGen:用文本引导生成全躯干 CT 图像与解剖掩码的前沿方法解析
【AAAI2026】GuideGen:用文本引导生成全躯干 CT 图像与解剖掩码的前沿方法解析

在医学影像人工智能领域,高质量标注数据一直是训练深度学习模型的瓶颈。传统方法中,生成 CT 图像通常只关注局部器官或固定区域,而对全躯干的多器官和病灶生成存在困难。GuideGen 提出了一种创新框架,通过结构化文本 prompt,结合分类扩散(categorical diffusion)和 HDR 自编码器,实现全躯干 CT 图像与对应解剖掩码的渐进式生成,为多器官分割和肿瘤检测提供高质量合成数据。
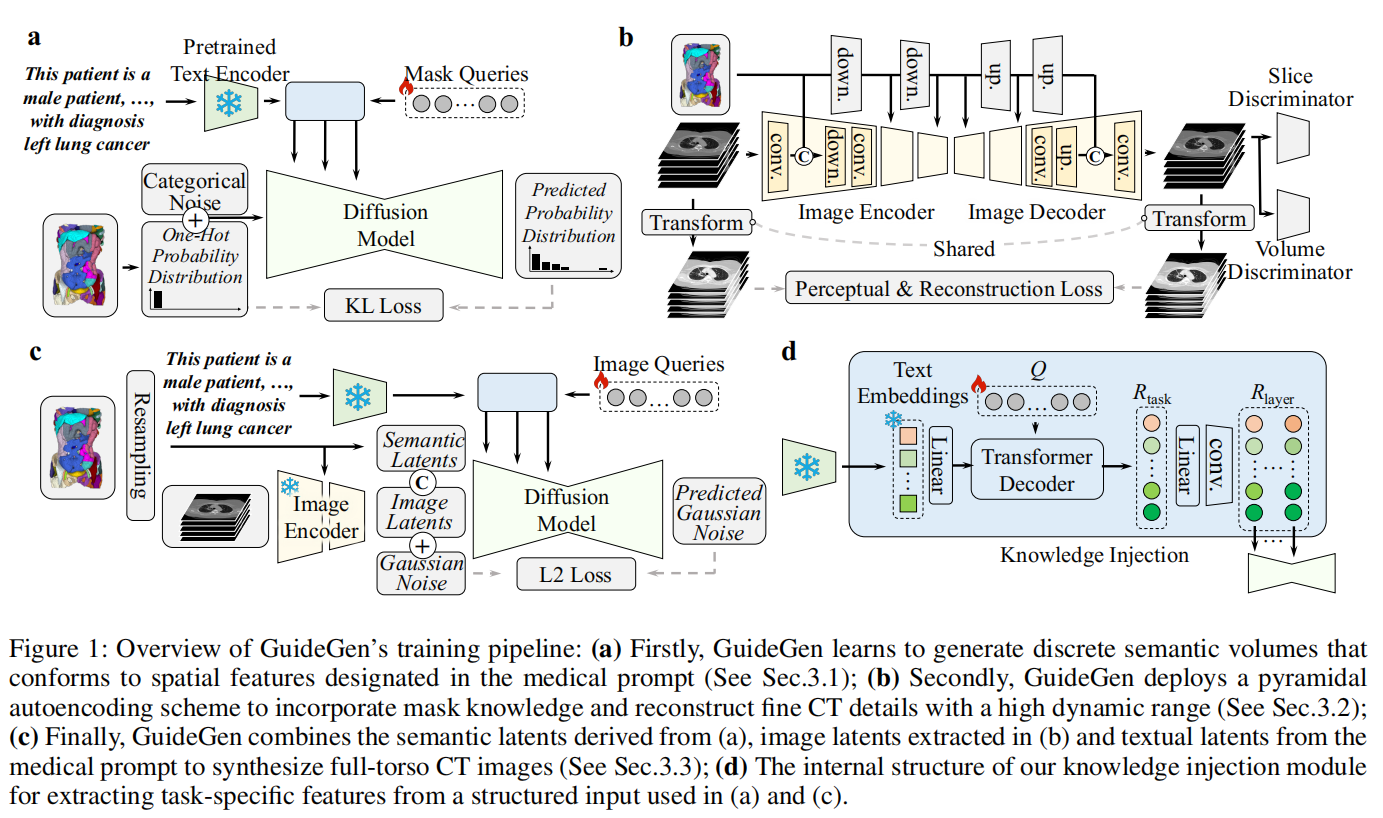
论文图1是GuideGen整体框架,展示文本条件输入→mask latent→HDR autoencoder→latent-guided diffusion→CT输出的生成流程。为了方便读者理解,重绘了一幅图。
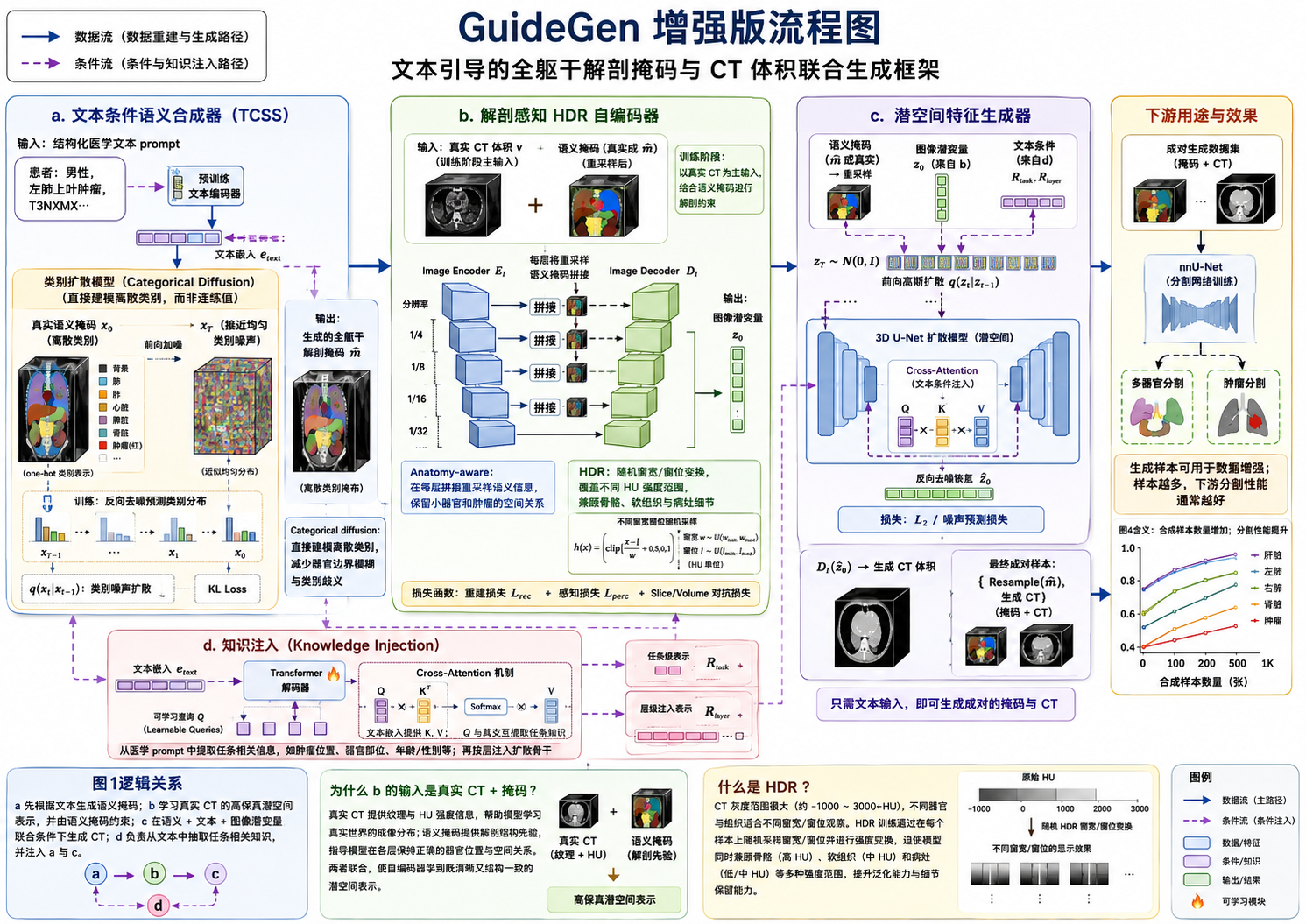
GuideGen的优势是什么?
在传统方法中,生成医学影像通常只关注局部器官或固定区域,难以覆盖全躯干。而在临床应用中,研究者不仅需要图像,更需要 与图像严格对齐的掩码 来训练分割模型或进行多器官分析。GuideGen 的创新在于:
- 分阶段生成:先生成 mask latent,再生成 CT latent,最后解码为全躯干 CT 图像;
- 文本条件控制:用户可以通过结构化 prompt 指定器官、肿瘤数量及位置;
- 高保真结构和细节:HDR autoencoder 保留高低强度差异,保持骨骼、软组织和肿瘤细节。
在生成过程中,mask latent 在潜空间中先行生成,然后作为结构指导参与 CT 图像生成,从而实现 渐进式联合生成。
GuideGen 核心技术原理
1. Categorical Diffusion(分类扩散)
Mask latent 的生成采用 categorical diffusion,这是 GuideGen 的核心创新之一。与普通 diffusion 处理连续值不同,mask 是 离散类别 voxel,每个 voxel 可能属于 N 个类别(器官、肿瘤、背景)。
前向扩散过程逐步扰动 one-hot 类别分布:
q(xt∣xt−1)=(1−βt)e(xt−1)+βt1N q(x_t \mid x_{t-1}) = (1-\beta_t) e(x_{t-1}) + \beta_t \frac{1}{N} q(xt∣xt−1)=(1−βt)e(xt−1)+βtN1
其中 e(xt−1)e(x_{t-1})e(xt−1) 是 one-hot 编码,βt\beta_tβt 是噪声权重。反向去噪由 UNet 模型预测每个 voxel 的类别概率 x^t−1\hat{x}_{t-1}x^t−1,优化 KL 散度:
LKL=Ex0,t[DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))] L_{KL} = \mathbb{E}_{x_0,t} \Big[D_{KL}\big(q(x_{t-1}\mid x_t,x_0) \parallel p_\theta(x_{t-1}\mid x_t)\big)\Big] LKL=Ex0,t[DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))]
Categorical diffusion 的优势在于直接生成 离散 mask,保证边界清晰、语义一致,并为后续 CT 潜空间生成提供结构引导。相比连续 diffusion,mask 不会出现灰色或半透明类别,小器官和肿瘤边界保留更好。
2. HDR Autoencoder(解剖感知高动态范围自编码器)
输入是真实 CT 体积 vvv 与 mask latent m^\hat{m}m^。HDR autoencoder 对 CT 灰度进行 learnable scale & bias 映射,解决高动态范围(-1000 HU 至 +3000 HU)下低强度病灶被忽略的问题。编码器在每一层融合 mask latent,生成潜空间表示 z0z_0z0。
训练损失包括:
Lrec=∥D(E(v,m^))−v∥22,Lperc=∥ϕ(D(E(v,m^)))−ϕ(v)∥22 L_{rec} = \|D(E(v,\hat{m})) - v\|_2^2, \quad L_{perc} = \|\phi(D(E(v,\hat{m}))) - \phi(v)\|_2^2 Lrec=∥D(E(v,m^))−v∥22,Lperc=∥ϕ(D(E(v,m^)))−ϕ(v)∥22
其中 E/DE/DE/D 分别为编码器/解码器,ϕ\phiϕ 为感知特征提取器。
这里 mask latent 作为结构引导,使潜空间同时保留图像纹理和语义信息,为后续潜空间 diffusion 提供稳定结构。
3. Latent-guided Diffusion & Knowledge Injection
潜空间 diffusion 模块联合 mask latent、CT latent 和文本 latent,在 latent 空间逐步去噪生成最终 CT latent,再由 autoencoder 解码成 CT 图像。文本条件通过 cross-attention 注入 UNet 每一层:
zt−1=UNet(zt,etext,m^) z_{t-1} = UNet(z_t, e_{text}, \hat{m}) zt−1=UNet(zt,etext,m^)
Knowledge Injection 模块利用 transformer decoder 提取文本中任务相关信息,保证 mask-prompt 对齐,提高结构控制能力。
4. 开源代码对应模块
train_mask_synthesizer.py:categorical diffusion UNet 训练,loss 为 KL divergence;autoencoder.py:HDR autoencoder 编码器和解码器,同时融合 mask latent;latent_diffusion.py:潜空间 3D UNet diffusion,实现 cross-attention 注入文本条件;knowledge_injection.py:提取任务相关文本知识并注入 UNet,保证 mask 与 prompt 对齐。
实验与结果
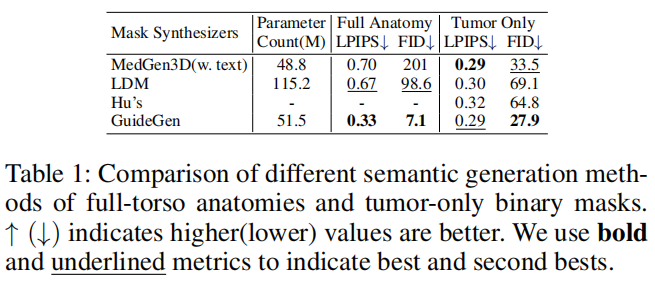
GuideGen 在全躯干 mask 与 CT 图像生成上优于 Pinaya、GenerateCT、MedSyn、MAISI 等基线。
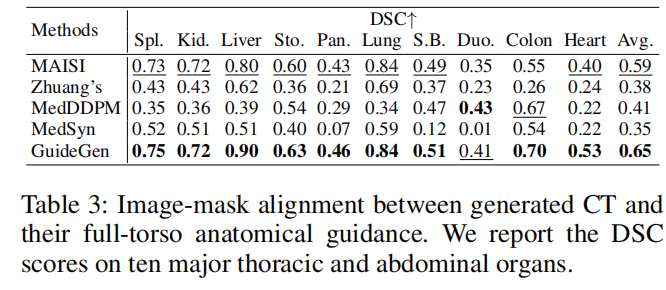
GuideGen 在图像-语义 mask 对齐上 DSC 平均 0.65,明显高于 MedSyn 和 Zhuang’s 方法。
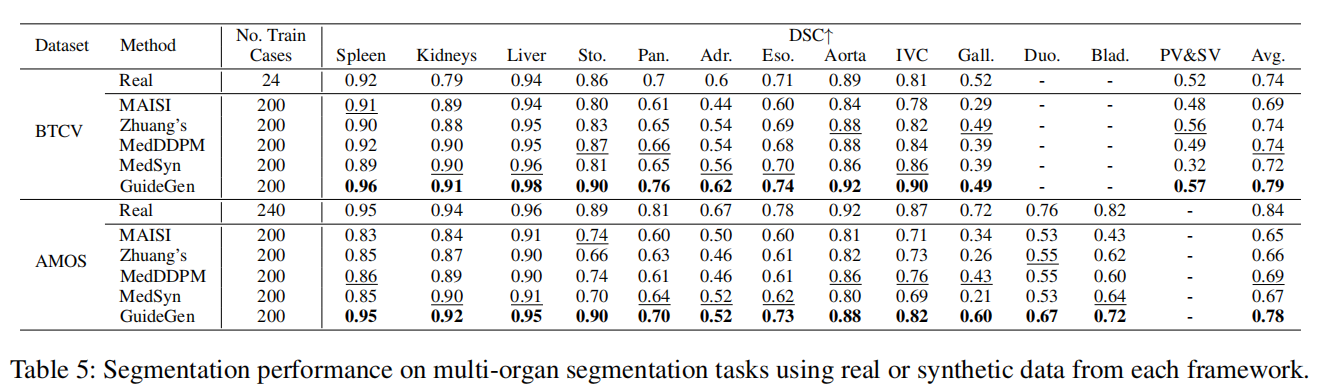
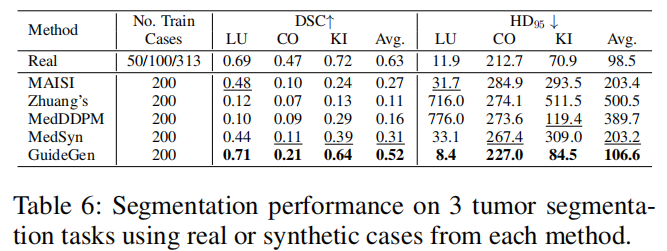
对下游任务多器官分割和肿瘤分割(BTCV、AMOS、MSD、KiTS21),GuideGen 生成样本训练的 nnU-Net 模型 Dice 分数明显优于其他生成方法,甚至部分指标可接近真实数据训练。
Ablation 实验显示,缺少 knowledge injection 或 HDR autoencoder 会明显降低 mask-prompt 对齐和下游分割性能。
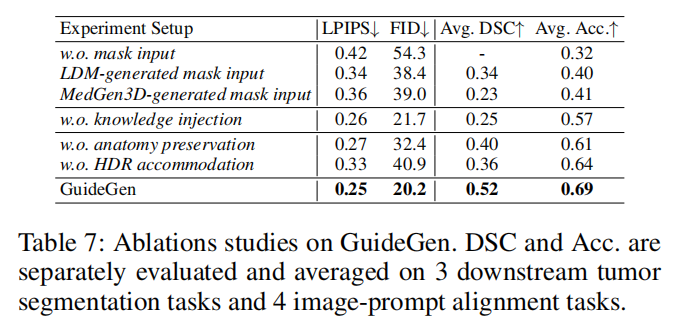
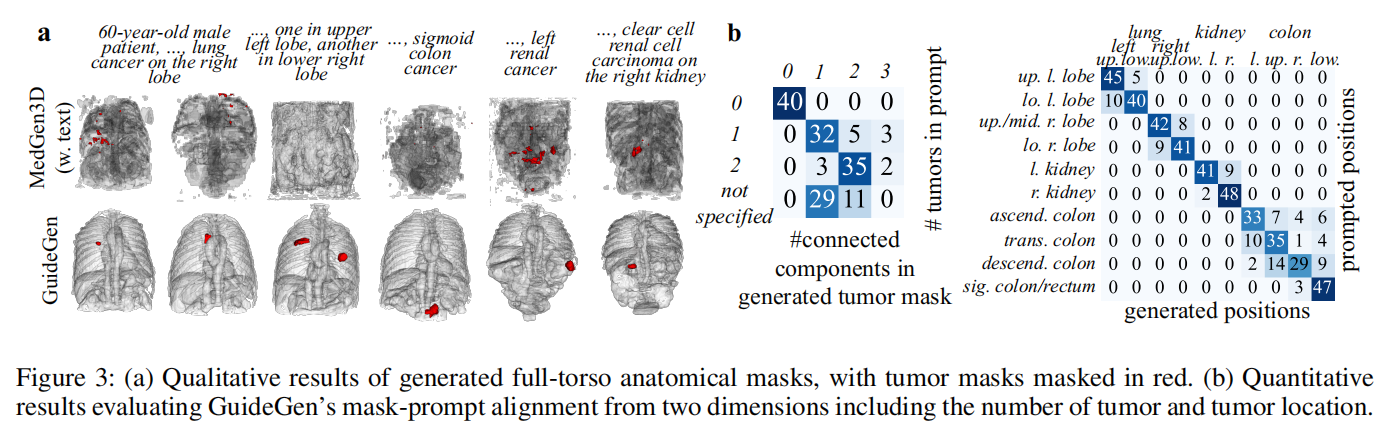
图 2显示基于同一文本 prompt 的生成效果,GuideGen mask 标红,CT 图像清晰且器官结构合理。
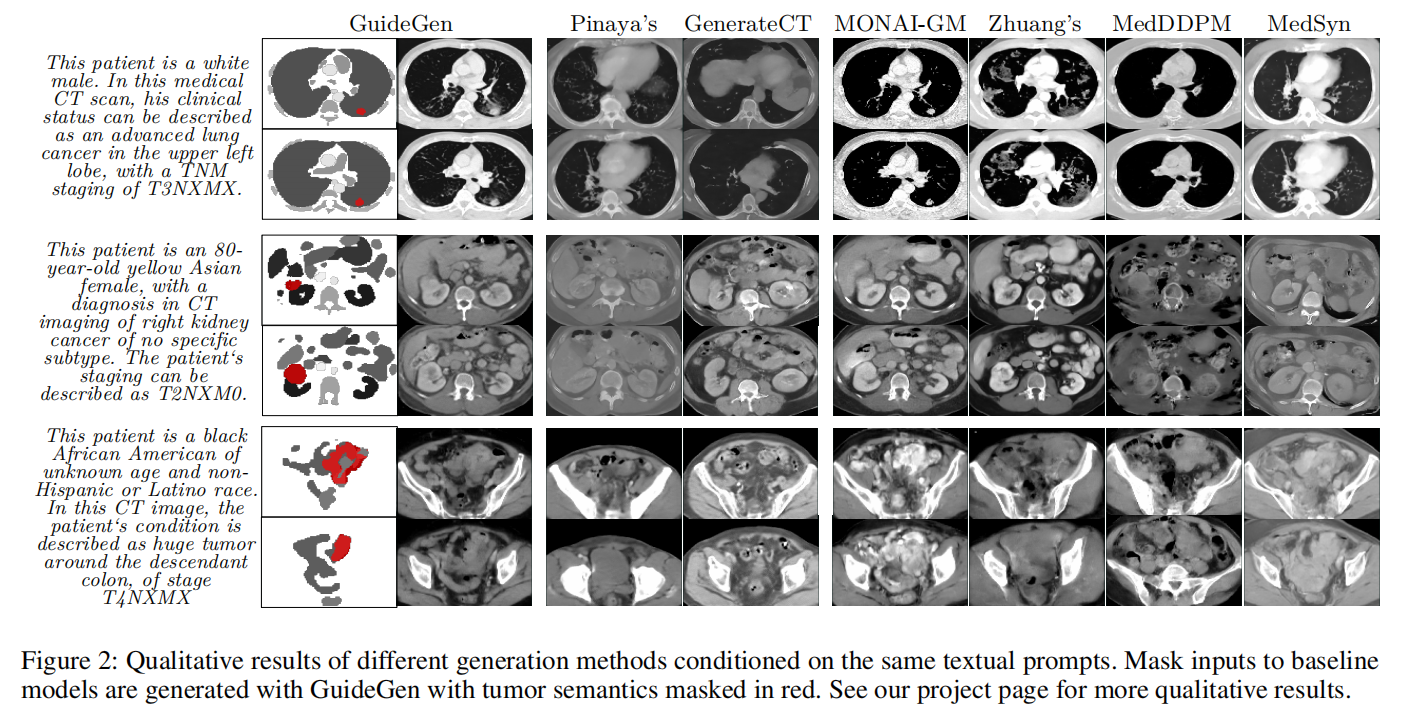
图 3展示 tumor 数量与位置的 mask-prompt 对齐情况。
批判性分析
GuideGen 的优势在于全躯干生成、mask-prompt 对齐和渐进式生成,尤其是 categorical diffusion 保证了离散 mask 的精度。然而局限也很明显:
- 对 structured prompt 依赖强,自由文本灵活性有限;
- 全躯干生成分辨率仅 128³,微小血管或肿瘤可能丢失;
- GPU 内存消耗高,训练 batch=1,VRAM > 20GB;
- 临床可用性和病理多样性尚未充分验证。
尽管如此,GuideGen 在 mask 对齐精度、下游多器官分割性能上领先现有方法,尤其适合稀缺数据增强和训练预训练模型。
总结
GuideGen 通过 categorical diffusion → HDR autoencoder → latent-guided diffusion → Knowledge Injection 的组合,实现了全躯干 CT 与掩码的渐进式生成。数学原理、潜空间建模、mask-prompt 对齐和可学习下采样等技术保证了生成数据的结构与语义一致性,为医学影像 AI 数据增强提供了可行的解决方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)