Anywhere3D-Bench论文精读
·
这篇论文 《Anywhere3D-Bench: A Holistic Benchmark for Multi-Level Visual Grounding in 3D Scenes》 提出并解决了一个当前3D视觉-语言模型研究中的关键问题。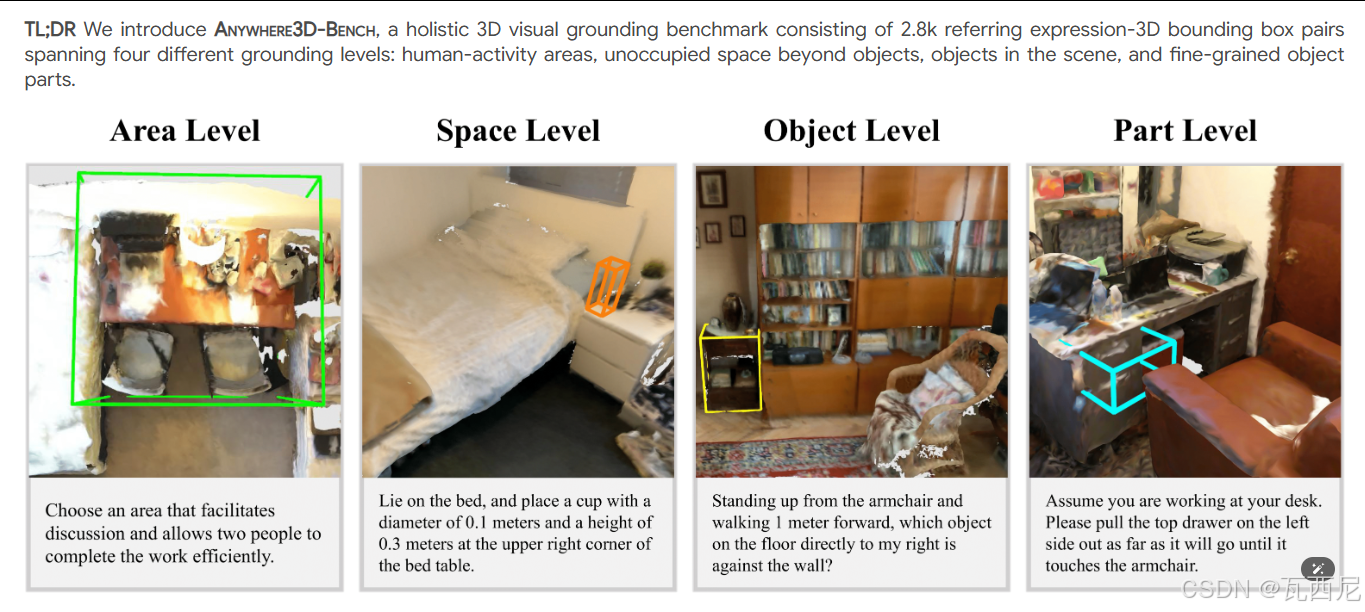
一、论文提出的问题
现有3D视觉定位(3D Visual Grounding)研究和基准测试存在严重局限:
-
局限于物体级别
几乎所有现有方法(如ScanRefer、Nr3D)都只能定位物体,无法理解“物体之外的区域”(如空间、区域、物体部件)。 -
缺乏多层次的视觉定位能力
人类可以自然地理解并定位:- 区域(Area):如“适合一起学习的区域”
- 空间(Space):如“在床头柜上空余的位置放一个杯子”
- 物体(Object):如“靠近沙发的椅子”
- 部件(Part):如“拉开柜子的最上面抽屉”
而现有模型和数据集几乎只覆盖物体级别。
-
现有模型在空间和部件级别上表现极差
即使是当前最强的多模态大模型(如Gemini-2.5-Pro、o3),在空间级任务上准确率仅约30%,部件级任务约40%,远低于物体级(62%)和区域级(85%)。
二、论文提出的解决方案
1. 构建新的基准数据集:Anywhere3D-Bench
-
包含 2,886 条自然语言描述 + 对应的3D边界框。
-
覆盖 4 个定位层级:
- Area(区域):如活动区、功能区
- Space(空间):物体之间的空余空间、距离、轨迹
- Object(物体):强调对物体大小、形状、间距的理解
- Part(部件):如抽屉、灯罩、水箱等,包括移动后的部件位置
-
数据来自ScanNet、MultiScan、3RScan、ARKitScenes等多个真实3D场景。
2. 设计严格的数据生成与标注流程
- 使用 GPT-4o + 场景图 自动生成多样化描述。
- 人工在3D场景中标注对应边界框,支持距离测量、边界框调整。
- 通过人工验证保证每个描述唯一对应一个3D边界框。
3. 系统性评估现有模型
论文评测了三大类模型:
- 纯文本LLM(如GPT-4.1、DeepSeek-V3)
- 多模态MLLM(如Gemini-2.5-Pro、o3、Qwen2.5-VL)
- 专门的3D视觉定位模型(如Chat-Scene、3D-VisTA)
并引入人类表现作为上界(整体准确率95%)。
4. 深入错误分析与模型对比
- 将错误分为:
- 视觉感知错误
- 逻辑推理错误
- 空间推理错误
- 对比 推理型模型(thinking model) 与 非推理型模型,发现推理型在空间定位上更优。
三、核心贡献总结
| 问题 | 解决方案 |
|---|---|
| 现有基准只覆盖物体级定位 | 提出首个跨4个层次的3D视觉定位基准 |
| 模型无法理解物体之外的区域 | 设计空间级(space-level)任务,包括距离、轨迹、常识空间 |
| 部件级定位能力差 | 引入部件移动、功能、关系等细粒度任务 |
| 缺乏系统性评估 | 全面评估LLM、MLLM、专用3D模型,并分析错误类型 |
开源数据集

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 25
25 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)