无需手写规则,大模型从对话记录中自动学会谈判与博弈

在人机对话的广阔世界里,除了我们熟悉的闲聊机器人和任务型助手,还存在一类特殊的对话智能体——非合作型对话代理 (non-collaborative dialogue agents)。它们被设计用于处理那些双方利益存在冲突的场景,例如商业谈判、慈善募捐、债务催收等。在这些对话中,智能体需要运用精妙的策略,在多轮博弈中引导对话走向,以达成对自身有利的目标。
ArXiv URL:http://arxiv.org/abs/2604.11427v2
传统上,构建这类智能体是一项高度依赖人类专家的劳动密集型工作。领域专家需要首先深入分析大量的对话实例,手动梳理、编码一套有效的“策略动作集”(比如在谈判中何时施压、何时妥协、何时转移话题),然后再基于这套固定的规则去训练策略规划模型。这个过程不仅成本高昂、耗时漫长,而且难以规模化,每进入一个新领域,几乎都要从头再来。
随着大型语言模型(LLM)展现出强大的归纳推理能力,一个极具吸引力的可能性浮出水面:我们能否让 LLM 直接从原始的专家对话录音或文本中,自动“悟出”其中隐藏的策略和规划逻辑?
来自北京航空航天大学、南开大学、新加坡国立大学等机构的研究者们给出了肯定的答案。他们提出了一种名为 METRO (Multi-dimEntional sTRategy induction from dialOgue transcripts) 的新方法。METRO 能够直接从原始对话文本中,自主归纳出策略动作和规划逻辑,并将其构建成一个名为“策略森林 (Strategy Forest)”的结构化知识体系。实验证明,METRO 的性能超越了现有方法 9%-10%,展现了卓越的策略多样性、远见性和跨任务迁移能力,为构建低成本、可扩展的非合作对话智能体开辟了一条新路。
核心机制:用“策略森林”为博弈智慧建模
METRO 的核心思想是将专家在对话中展现的隐性知识(tacit knowledge)——即“在什么情况下该说什么话”——进行形式化、结构化的表达。整个过程分为两个阶段:离线的归纳 (Induction) 阶段和在线的应用 (Application) 阶段。
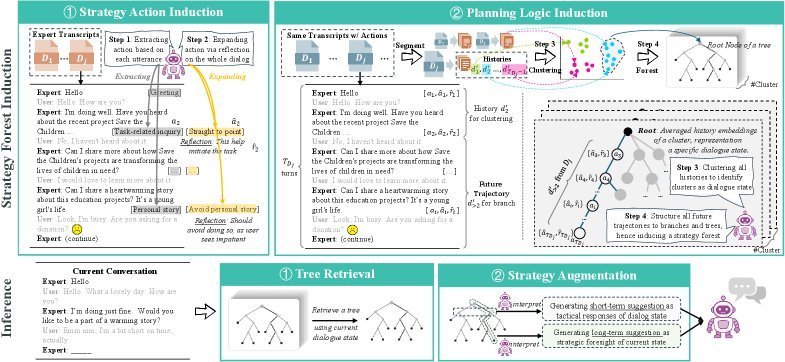
上图直观展示了 METRO 的工作流程。它首先在离线阶段,将大量原始对话转录稿(Transcripts)加工成一个结构化的“策略森林”,然后在在线推理时,利用这个森林来指导智能体的每一步决策。
1. 策略森林的归纳构建
策略森林的构建是 METRO 的基石,它包含两个关键步骤:策略行动归纳和规划逻辑归纳。
策略行动归纳 (Strategy Action Induction)
如果只是简单地从对话文本中提取专家说过的原话作为策略,那么智能体的能力将被原始语料的质量和多样性牢牢束缚。METRO 的高明之处在于,它不仅“提取”,更懂得“扩充”。
首先,对于一段专家对话 D=(u1,u1usr,…,uTD,uTDusr)D=(u_1, u_1^{\text{usr}}, \dots, u_{T_D}, u_{T_D}^{\text{usr}})D=(u1,u1usr,…,uTD,uTDusr),METRO 会通过 LLM 从专家的每句发言 uiu_iui 中提取出一个基础的策略动作 ai=Extraction(ui)a_i = \text{Extraction}(u_i)ai=Extraction(ui)。
更关键的是第二步:扩充 (Expansion)。METRO 会将对话历史 di′d'_idi′ 和提取出的基础动作 aia_iai 一同交给 LLM,并提示 LLM 在此基础上生成一个经过提炼或全新的策略动作 a^i\hat{a}_ia^i,同时附上采纳该新策略的理由 r^i\hat{r}_ir^i。这个过程可以表示为 (a^i,r^i)=Expansion(di′,ai)(\hat{a}_i, \hat{r}_i) = \text{Expansion}(d'_i, a_i)(a^i,r^i)=Expansion(di′,ai)。
通过这种方式,METRO 借助 LLM 自身的“内部知识”,超越了原始语料的限制,创造出更丰富、更精炼的策略动作库 A′\mathcal{A}'A′。这使得智能体在后续决策时,拥有了远比原始对话中观察到的更广泛的行动选项。
规划逻辑归纳 (Planning Logic Induction)
拥有了丰富的策略“弹药库”还不够,何时使用哪个“弹药”才是策略的核心。这便是规划逻辑。一段完整的对话,本质上就是一条从开场到结束的“行动轨迹”(action trajectory)。METRO 的目标就是将这些线性的轨迹,重构成一个树状的、以“状态”为中心的知识结构。
具体来说,METRO 会将每一条对话轨迹分解成若干个“子轨迹”。每个子轨迹都从一个特定的对话状态(例如“用户首次拒绝出价”)开始,并携带最终的任务结果(成功或失败)。然后,METRO 会将所有源于相同或相似对话状态的子轨迹聚合在一起,形成一棵“策略树 (Strategy Tree)”。
森林中的每一棵树 fi∈Ff_i \in \mathcal{F}fi∈F 都代表了一个关键的对话状态 SiS_iSi(树的根节点)。这棵树的内部结构则编码了从这个状态出发的两种规划逻辑:
-
短期战术响应 (Short-term Tactical Responses):根节点的直接子节点 childroi\text{childro}_ichildroi 代表了从状态 SiS_iSi 出发,最直接有效的“下一步”应该怎么走。这体现了策略的广度 (breadth)。
-
长期战略远见 (Long-term Strategic Foresight):从根节点到任意一个叶子节点的完整路径(即一个分支 trajij\text{traj}_{ij}trajij),代表了一条完整的、被历史证明是有效的长期行动序列。这体现了策略的深度 (depth)。
通过将成千上万段对话中的规划逻辑汇集成由无数策略树组成的“策略森林”,METRO 就为智能体构建了一个庞大而精细的外部“大脑”。
2. 在实战中应用策略森林
当智能体需要进行决策时,它无需进行复杂的模型训练或蒙特卡洛树搜索(MCTS)那样的重度计算。METRO 采用的是一种轻量级的检索增强方法。
在对话的第 ttt 轮,给定当前的对话历史 dtd_tdt,METRO 会执行以下操作:
-
树检索:计算当前对话状态与策略森林 F\mathcal{F}F 中所有策略树的根节点(即历史上的关键对话状态)之间的语义相似度,并检索出最相关的一棵树 fff。
-
策略建议生成:从检索到的树 fff 中,同时提取两种建议:
-
广度建议:基于与当前上下文最相似的 Top-K 个子节点,生成短期战术建议。
-
深度建议:基于树中完整的 Top-K 条分支,生成长期战略建议。
-
-
最终响应:将这两种建议拼接在一起,作为最终的提示(prompt)输入给 LLM,引导其生成既有战术针对性、又有战略远见的回复。
这种设计巧妙地利用了策略森林的多维度结构,在不牺牲策略深度和广度的前提下,保持了推理的高效率。
实验拆解:METRO 为何如此有效?
研究者在两个经典的非合作对话基准数据集(一个关于价格谈判 CraigslistBargain (CB),一个关于慈善劝说 PersuasionForGood (P4G))上进行了详尽的实验。结果显示,无论是在自动评估指标(如成功率 SR、平均对话轮次 AT)还是在人工评估中,METRO 均显著优于其他基线方法。
那么,METRO 的优势究竟从何而来?论文通过一系列精巧的分析和消融实验,揭示了其成功背后的原因。
策略动作的多样性是基础
METRO 的一个核心优势在于它能生成高度多样化的策略。研究者通过聚类分析发现,相比于数据集中预定义的人类策略和由其他方法(如 PRINCIPLES)生成的策略,METRO 归纳出的策略在“簇覆盖率 (Cluster Coverage, CC)”和“簇内覆盖率 (Within-Cluster Coverage, WCC)”上都表现更优。
这意味着 METRO 产生的策略不仅覆盖了更广泛的语义空间(种类多),而且在每个具体的策略类别内部,其表达也更加丰富多变(花样新)。这种策略上的多样性,使得智能体能够跳出刻板的应对模式,展现出更灵活、更像人类的博弈行为。
广度与深度的协同价值
策略森林的“广度”(短期战术)和“深度”(长期规划)是否都不可或缺?消融实验给出了有趣的答案。
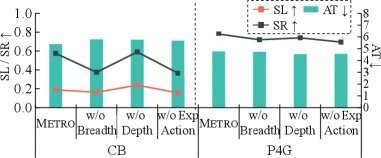
如上图所示,在 P4G 任务中,去掉广度(w/o Breadth)或深度(w/o Depth)模块都会导致性能下降,证明了两者协同作用的重要性。
然而,一个反常的现象出现在 CB 任务上:去掉深度规划逻辑(w/o Depth)后,模型的性能反而有所提升。研究者深入分析后发现,这是因为 CraigslistBargain 这个数据集本身的对话质量和策略多样性有限,导致从中归纳出的长期规划(分支)存在结构性冗余和偏差。在这种情况下,一个有偏的“长期军师”反而不如没有。
这个发现极具启发性:归纳策略的有效性,高度依赖于源头对话语料的质量。这也从侧面印证了,当拥有高质量专家数据时,METRO 的潜力将得到更充分的释放。
强大的跨任务迁移能力
一个好的策略归纳模型,不应只在特定领域生效。METRO 展现了强大的跨任务迁移能力。实验将从谈判任务(CB)中学到的策略,直接应用到劝说任务(P4G)上。结果显示,METRO 的表现远超其他基线方法。
更有趣的是,当把两个任务的策略集合并,扩大总体的策略空间时,许多依赖简单规划器的基线方法性能开始下降,因为它们难以从一个庞大的候选集中做出精准选择。而 METRO 凭借其精准的“树检索”机制,能够有效地在不断扩大的策略森林中导航,始终保持稳健的性能。这证明了 METRO 架构在应对策略空间演化和扩展时的优越可扩展性。
讨论与启示
METRO 的提出,为非合作对话领域乃至更广泛的隐性知识抽取领域,带来了重要的启示。
它成功地将 LLM 从一个单纯的“执行者”转变为一个“归纳者”和“规划者”,实现了从原始行为数据(对话文本)到结构化、可复用策略知识(策略森林)的自动化构建。这极大地降低了构建复杂对话智能体的门槛。
当然,研究也存在一些局限。目前实验所用的数据集,对话参与者多为普通用户,而非专业的谈判或劝说专家。如果未来能获得由认证专家产生的高保真对话数据,METRO 的性能上限有望被进一步推高。此外,论文虽然初步验证了使用 LLM 生成的对话数据作为训练源的可行性,但其与真实人类专家数据的深层差异,仍有待未来工作的深入探索。
总而言之,METRO 不仅是一个效果出色的新模型,更代表了一种富有前景的研究范式:利用大语言模型的归纳能力,从非结构化的专家行为中挖掘、建模并复用那些难以言传的隐性知识。这一思路,未来或可应用于棋类游戏、外科手术、法律辩论等更多需要专业策略和深厚经验的领域。无需手写规则,大模型从对话记录中自动学会谈判与博弈

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)