深入解析Redis高性能底层逻辑:内存存储、单线程模型与I/O多路复用
在现代高并发分布式架构体系中,Redis是当之无愧的高性能中间件标杆。在普通物理服务器配置下,单节点Redis即可轻松实现十万级QPS、微秒级读写延迟,远超传统磁盘数据库、多数缓存组件的性能上限,广泛应用于电商大促、直播弹幕、短视频流量、用户会话存储、分布式限流、热点数据缓存等核心高吞吐、低延迟场景。
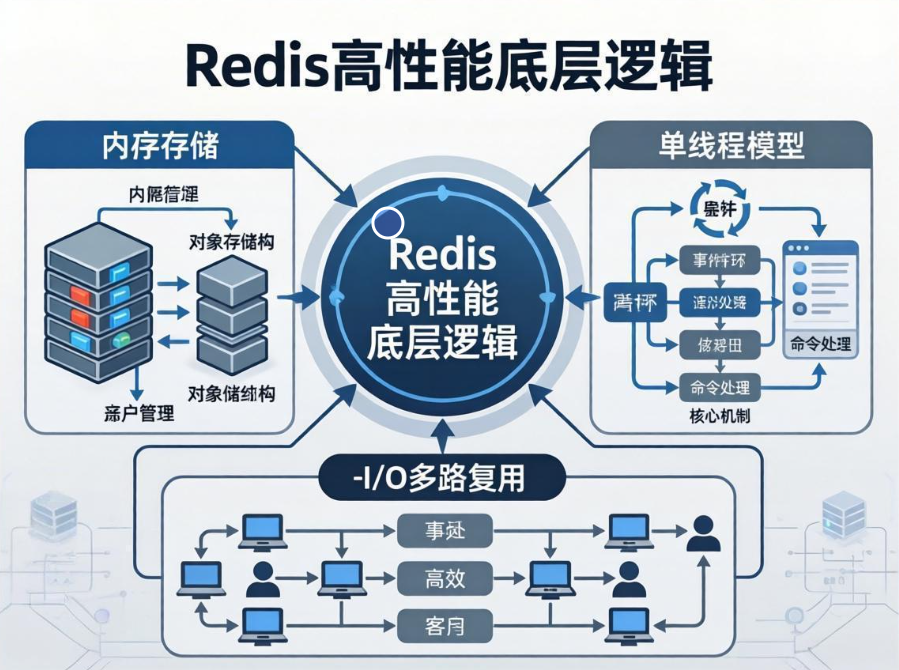
多数开发者仅知晓Redis“速度快”,却对其高性能的底层核心逻辑一知半解,甚至产生“Redis只是因为用了内存所以快”的片面认知。事实上,纯内存存储只是Redis高性能的基础条件,而非全部核心。Redis能够碾压多数同类组件,实现极致性能表现,是内存存储架构、极简单线程执行模型、epoll I/O多路复用机制、精细化数据结构编码、事件驱动调度体系五大核心能力深度协同的结果。
本文将从零底层视角,全方位、深层次拆解Redis三大核心高性能支柱:内存存储机制、单线程模型设计、I/O多路复用原理。摒弃碎片化知识点,从底层原理、设计取舍、技术优势、底层坑点、版本演进、场景适配六个维度深度剖析,完整还原Redis高性能的本质逻辑,帮助开发者彻底读懂Redis快的根源,为生产环境调优、架构设计、故障排查筑牢底层认知根基。
一、核心基石:纯内存存储架构,从介质层面碾压磁盘IO瓶颈
计算机系统的性能瓶颈,90%以上场景都集中在IO操作,而非CPU计算。传统MySQL、PostgreSQL等关系型数据库以磁盘为核心存储介质,磁盘寻道、读写、同步刷新的物理特性,注定其无法支撑微秒级响应、十万级并发。而Redis的核心底层设计,就是将全部核心数据常驻内存,彻底规避磁盘IO的物理性能瓶颈,这是其高性能的首要前提。
1.1 内存与磁盘的极致性能差距
从硬件物理特性层面,内存与磁盘的读写性能存在量级差距,这是Redis性能优势的底层硬件基础。常规硬件环境下的性能数据对比,足以直观体现差距:
- 内存随机读写延迟:0.1~0.3微秒,几乎无寻址耗时,数据直接通过总线与CPU交互;
- 机械硬盘随机读写延迟:5~10毫秒,存在磁盘磁头寻道、盘片旋转耗时,延迟是内存的数万倍;
- 固态硬盘SSD随机读写延迟:0.1~0.5毫秒,虽大幅优于机械硬盘,但仍是内存延迟的千倍级别。
传统磁盘数据库的每一次查询、写入操作,都大概率伴随磁盘IO交互,单次请求耗时被物理硬件锁死,很难突破万级QPS上限。而Redis所有核心读写操作均在内存中完成,无需等待磁盘寻址、数据加载,天然具备微秒级响应能力,这是其高吞吐、低延迟的硬件底层保障。
1.2 Redis内存存储的精细化底层优化
并非所有内存数据库都能实现Redis的极致性能,Redis在纯内存存储的基础上,做了大量精细化底层优化,最大化内存读写效率、最小化资源损耗,规避内存存储的固有短板。
首先是自研专属数据结构,规避通用结构性能冗余。Redis没有直接复用C语言原生数据结构,而是针对性自研SDS、压缩列表、跳表等轻量化结构,适配缓存场景的读写特性。以字符串存储为例,Redis放弃C语言原生字符串,采用SDS(简单动态字符串),摒弃固定长度字符数组的缺陷,实现动态扩容、预分配内存、惰性释放空间,彻底杜绝内存碎片化、重复内存申请释放的性能损耗,同时兼容二进制安全存储,适配所有业务数据类型。
其次是内存编码自适应优化,极致压缩内存占用。Redis针对不同数据量、数据类型,自动适配最优底层编码格式。例如Hash结构,数据量小、字段少时自动使用压缩列表编码,内存占用极低;数据量扩容后自动升级为哈希表编码,保障读写效率。List、Set、ZSet结构均具备自适应编码能力,在低内存占用和高读写性能之间实现动态平衡,避免内存浪费导致的性能间接损耗。
1.3 内存存储的配套机制:平衡性能与数据安全
纯内存存储存在致命短板:断电、进程重启会导致数据全部丢失。为解决这一问题,Redis设计了轻量化、低损耗的持久化机制,在不影响核心读写性能的前提下,保障数据可靠性,实现性能与安全的平衡。
Redis的RDB快照、AOF日志持久化操作,均采用后台异步线程执行,完全不占用主线程资源。核心读写请求全程在内存中同步完成,磁盘落地操作异步化,彻底规避持久化IO阻塞核心业务的问题。同时Redis 4.0+推出混合持久化机制,结合RDB快速写入和AOF增量记录的双重优势,进一步降低持久化的CPU、磁盘IO开销,让内存读写的极致性能不被数据安全机制拖累。
1.4 内存存储的核心设计取舍与边界
Redis选择纯内存存储,也做出了明确的设计取舍,这是理解其适用场景的关键。其一,放弃超大容量存储能力,优先保障性能,内存硬件成本远高于磁盘,注定Redis不适合存储海量冷数据,仅适配高频热点数据;其二,必须配套内存淘汰、过期清理机制,通过allkeys-lfu、volatile-lru等精准淘汰策略,自动清理冷数据,保障内存资源高效复用,避免内存溢出故障;其三,依赖持久化机制兜底数据,无法做到绝对数据零丢失,适配缓存、非核心业务数据场景。
综上,纯内存存储是Redis高性能的基础底座,彻底解决了IO层面的最大性能瓶颈,为后续单线程模型、I/O多路复用的性能发挥提供了先决条件。
二、核心精髓:单线程执行模型,极致规避并发性能损耗
很多开发者存在认知误区:多线程一定比单线程性能高。但Redis用实践证明,在内存读写、高并发连接场景下,精心设计的单线程模型,性能远优于传统多线程模型。这也是Redis能够以极低CPU资源,支撑十万级QPS的核心关键。
首先纠正一个核心概念:Redis的“单线程”并非指整个进程只有一个线程,而是核心命令执行、网络IO读写、请求解析调度全程由单一主线程串行执行。而持久化、内存碎片整理、异步删除、集群心跳等耗时、阻塞型辅助操作,均由独立子线程异步执行,既保留单线程的极致简洁高效,又规避了单线程的功能短板。
2.1 传统多线程模型的致命性能缺陷
常规服务、数据库普遍采用多线程模型处理并发请求,为每个连接或每个请求分配独立线程,看似能并行处理请求,实则存在大量隐性性能损耗,这也是多线程模型无法适配极致低延迟场景的核心原因。
第一,线程上下文切换开销巨大。CPU切换不同线程时,需要保存当前线程上下文、加载新线程上下文,频繁切换会消耗大量CPU算力,导致有效业务处理算力被稀释。在高并发场景下,成千上万的线程频繁切换,会引发CPU飙升、系统负载过高,严重拖累响应速度。
第二,锁竞争与并发冲突严重。多线程并行读写共享内存数据,会出现数据竞争问题,必须依赖互斥锁、读写锁保障数据一致性。锁的加锁、解锁、等待阻塞过程,会产生大量性能损耗,同时大幅增加代码复杂度,极易出现死锁、锁超时、并发数据异常等问题。
第三,线程资源冗余浪费。每个线程都会占用独立的栈内存、文件句柄、系统资源,海量并发场景下,大量空闲线程会造成系统资源冗余,降低资源利用率,反而限制系统吞吐上限。
2.2 Redis单线程模型的核心优势
Redis主线程串行执行所有核心命令,从根源上彻底解决了多线程的所有性能痛点,实现极简、高效的请求处理逻辑。
其一,零锁竞争、零并发冲突。单线程串行执行,同一时间仅处理一条命令,所有读写操作串行化,无需加锁、解锁,彻底杜绝死锁、锁等待、并发数据不一致问题,不仅简化了底层代码逻辑,更消除了锁机制带来的全部性能损耗,这是Redis数据操作高效、稳定的核心原因。
其二,零线程上下文切换开销。核心业务全程由单一线程独占CPU,无需频繁切换线程,CPU算力可以100%用于处理请求解析、数据读写等核心业务,无任何无效算力损耗,算力利用率拉满。
其三,执行逻辑极简,延迟极致稳定。单线程执行链路清晰、无冗余逻辑,不存在多线程调度的不确定性,请求响应延迟极其稳定,极少出现突发延迟抖动,完美适配高并发、高稳定要求的业务场景。
2.3 单线程模型的核心设计逻辑:适配场景、扬长避短
Redis敢于采用单线程模型,核心是精准拿捏了自身的业务属性:Redis是典型的I/O密集型组件,而非CPU密集型组件。所有核心操作均为内存读写,单次命令执行耗时极短,微秒级即可完成,单线程串行处理的速度,完全可以覆盖海量并发请求,不会出现CPU瓶颈。
反之,如果是复杂计算、大数据处理的CPU密集型场景,单线程模型会快速触发CPU瓶颈,性能远不如多线程。但Redis的核心场景是简单、高频的内存读写,单线程的处理效率,完全能够支撑十万级QPS,同时规避了多线程的所有弊端,实现性价比最高的性能方案。
2.4 单线程模型的短板与Redis的解决方案
单线程模型存在唯一致命短板:一旦主线程执行耗时命令,所有请求都会排队阻塞。这也是生产环境中Redis卡顿、雪崩的核心诱因。针对这一短板,Redis设计了完善的规避机制,这也是前文调优技巧的底层原理。
首先,严格区分核心任务与耗时任务,耗时操作全部异步化。数据持久化、内存碎片整理、大Key删除、日志写入等耗时操作,全部交由后台子线程处理,绝不阻塞主线程;其次,禁止主线程执行O(n)级耗时命令,通过规范禁用KEYS、全量FLUSH、HGETALL全量遍历等阻塞命令;最后,通过分批迭代、异步执行、任务拆分等方式,规避单次任务耗时过长的问题,保障主线程始终高速流转。
2.5 Redis线程模型的版本演进(规避单线程瓶颈)
为进一步突破单线程性能上限,Redis在后续版本持续迭代线程模型,在保留单线程核心优势的前提下,弥补性能短板。Redis 6.0推出多线程IO模型,实现读写IO多线程并行处理,命令执行仍保持单线程串行。
该演进方案极其精妙:网络IO读写属于阻塞型、高耗时操作,多线程并行处理可大幅提升网络吞吐;而核心命令执行依旧单线程,保留零锁、无切换的优势,兼顾了高并发IO处理能力和执行稳定性。Redis 7.0进一步优化多线程机制,细化线程分工,进一步释放高并发场景下的性能潜力。
三、终极赋能:I/O多路复用,单线程支撑百万并发的灵魂机制
有了内存存储的低延迟基础、单线程的高效执行模型,还需要解决一个核心问题:单线程如何支撑数万、数十万的并发客户端连接? 普通阻塞I/O模型下,一个线程只能处理一个连接,单线程无法实现高并发,而I/O多路复用机制就是解决这一问题的终极答案,是Redis单线程高并发的核心灵魂。
3.1 传统I/O模型的并发瓶颈
为理解I/O多路复用的优势,我们先对比传统I/O模型的缺陷,清晰看懂技术迭代的核心逻辑。
阻塞I/O模型:单线程只能监听一个Socket连接,未收到客户端请求时,线程全程阻塞等待,完全无法处理其他连接,并发能力为1,无法适配多客户端场景。
非阻塞I/O模型:单线程可以轮询多个Socket连接,无请求时不阻塞,持续遍历所有连接状态。但该模式存在致命缺陷:需要无限循环轮询所有连接,大量CPU资源消耗在无效轮询上,CPU利用率极低,并发连接量越大,无效损耗越严重。
多线程I/O模型:为每个连接分配独立线程,解决并发问题,但回归多线程的固有缺陷,线程切换、锁竞争、资源冗余问题频发,无法实现极致性能。
3.2 I/O多路复用的核心原理
I/O多路复用是一种单线程监听多个文件描述符(FD),仅在连接就绪时处理请求的高效IO机制。其核心逻辑可以概括为:一个线程、一次监听、海量连接、按需处理。
Redis主线程通过epoll(Linux平台)、kqueue(Mac平台)、select(兼容平台)等多路复用函数,将所有客户端Socket连接注册到内核监听队列中。内核会全程监控所有连接的状态,当某个连接出现可读、可写、异常事件时,内核会主动通知Redis主线程,主线程仅处理就绪的连接,无需无效轮询。
简单来说:没有事件就绪,线程休眠,零CPU消耗;有事件就绪,精准处理,无无效损耗。完美解决了阻塞I/O并发低、非阻塞I/O CPU浪费的双重问题,让单线程可以高效支撑数万乃至数十万并发连接。
3.3 Redis事件驱动调度体系(多路复用落地核心)
Redis基于I/O多路复用,封装了一套完整的事件驱动模型,构成主线程的核心执行循环,也是Redis运行的核心调度中枢。整套体系分为两大核心事件:文件事件、时间事件。
文件事件即网络IO事件,包含客户端连接、请求读取、响应写入等网络操作,由epoll监听触发,是Redis的核心事件类型,采用异步非阻塞方式处理,高效响应客户端请求;时间事件即定时任务事件,包含过期Key清理、集群心跳检测、客户端超时关闭、内存监控等定时操作,保障服务稳定运行。
Redis主线程通过无限事件循环,持续监听、处理两类事件,优先级明确、调度高效。所有网络请求均通过多路复用精准触发,无无效遍历、无阻塞等待,最大化释放单线程的并发处理能力。
3.4 epoll为何是Redis的最优选择?
I/O多路复用包含select、poll、epoll三种主流实现,Redis默认优先采用epoll,核心是epoll完美适配Redis的高并发场景,相较于前两者具备碾压性优势。
select/poll存在两大致命缺陷:其一,每次监听都需要将全部文件描述符从用户态拷贝到内核态,并发连接越多,拷贝开销越大;其二,返回就绪事件后,需要遍历所有连接才能找到就绪事件,时间复杂度为O(n),海量连接下性能急剧下降。
而epoll采用事件回调机制,只需一次注册文件描述符,无需反复拷贝;内核会主动记录就绪事件,主线程直接获取就绪列表,无需全局遍历,时间复杂度为O(1)。在十万级并发连接场景下,epoll的性能远超select/poll,这也是Redis能够支撑超高并发的底层IO保障。
3.5 I/O多路复用的性能协同逻辑
I/O多路复用、单线程模型、内存存储三者并非独立生效,而是深度协同、互相赋能,形成Redis的性能闭环。内存存储保障单次请求处理微秒级完成,不会阻塞事件循环;单线程模型保障事件调度无锁、无切换损耗,执行极致高效;I/O多路复用保障单线程能够支撑海量并发连接,突破单线程并发上限。三者结合,让Redis实现了低延迟、高吞吐、高稳定、低资源占用的极致性能表现。
四、深度整合:三大核心机制的协同闭环与性能本质
单独拆解任意一项机制,都无法完全解释Redis的高性能,三者的深度协同、设计互补,才是Redis碾压同类组件的核心本质。我们可以通过完整的一次Redis请求链路,直观看懂三者的协同逻辑:
1. 客户端发起读写请求,Socket连接注册至epoll内核监听队列;
2. epoll监听连接状态,请求就绪后主动触发事件,唤醒Redis主线程;
3. 主线程通过事件驱动机制,精准读取客户端请求数据,无无效轮询、无阻塞等待;
4. 主线程单线程串行解析命令,内存中直接完成数据读写,无锁竞争、无磁盘IO损耗;
5. 处理完成后,主线程通过多路复用机制将结果返回客户端,继续循环处理下一个就绪事件;
6. 持久化、内存整理等耗时操作异步化,不干扰核心请求处理链路。
整条请求链路全程无阻塞、无冗余、无无效损耗,每一个环节都经过极致优化,这就是Redis十万级QPS、微秒级延迟的完整底层逻辑。
五、底层认知误区与生产落地启示
基于以上三大核心底层逻辑,我们可以纠正生产环境中普遍存在的认知误区,同时提炼出可落地的架构设计、调优运维启示。
5.1 常见认知误区纠正
误区一:Redis快只是因为用了内存。纠正:内存只是基础,若无单线程零损耗执行、epoll多路复用高并发调度,纯内存存储无法支撑海量并发,性能会被IO调度、线程开销锁死。
误区二:单线程Redis无法发挥多核CPU性能。纠正:Redis核心瓶颈不在CPU,而在网络IO和内存吞吐,单核CPU性能完全足够支撑单机上限。如需更高并发,可通过集群横向扩容,比多线程单核优化更高效、更稳定。
误区三:多线程版本Redis性能远超单线程。纠正:Redis6.0+多线程仅优化网络IO,核心命令执行仍为单线程,既保留了单线程的稳定性,又提升了IO吞吐,并非彻底摒弃单线程模型,稳定性依旧是核心优势。
5.2 底层逻辑对应的生产调优启示
1. 坚决规避主线程阻塞操作。基于单线程模型特性,任何耗时命令、同步阻塞操作都会直接拖垮整体性能,生产环境必须禁用慢命令、拆分大Key、精简Lua脚本。
2. 优先优化网络IO参数。基于多路复用机制,合理调整tcp-backlog、TIME_WAIT回收、文件句柄数等内核参数,最大化发挥epoll高并发能力。
3. 做好内存精细化治理。基于内存存储特性,优化内存淘汰策略、碎片整理、过期时间打散,保障内存高效复用,规避OOM和缓存雪崩问题。
4. 架构扩容优先横向集群扩容。受单线程单核特性限制,单机性能存在上限,超高并发场景通过Cluster集群分片扩容,突破单机瓶颈,比垂直优化更有效。
六、全文总结:Redis高性能的终极本质
通过对内存存储、单线程模型、I/O多路复用三大核心底层逻辑的深度拆解,我们可以总结出Redis高性能的终极本质:精准适配业务场景,极致取舍、扬长避短,通过三层技术架构实现性能最大化、损耗最小化。
内存存储作为硬件底座,彻底规避磁盘IO的物理瓶颈,实现微秒级数据读写;单线程事件驱动作为执行核心,杜绝多线程锁竞争、上下文切换的无效损耗,保障执行高效稳定;epoll I/O多路复用作为并发引擎,让单线程突破并发连接上限,支撑十万级高吞吐。三者层层递进、深度协同,构成了Redis无可替代的高性能优势。
Redis的成功,并非依赖复杂的技术堆叠,而是极简设计思想的极致落地:砍掉所有冗余机制、规避所有性能损耗、聚焦核心场景优化。读懂这三大底层逻辑,不仅能彻底理解Redis“快”的根源,更能指导我们在生产环境中合理使用、精准调优、架构升级,规避99%的Redis性能故障,真正最大化释放Redis的性能潜力,让其成为高并发分布式系统的稳定性能基石。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)