第十四章:深度强化学习的黄金年代
第十四章:征服游戏与科学——深度强化学习的黄金年代
[!info]
规模定律告诉我们,只要给足够的参数、数据和计算,语言模型的能力会持续提升——这是一条看不到终点的幂律曲线。GPT-3 的 1750 亿参数证明了规模的力量,但也暴露了一个没有被规模解决的问题:这个强大的模型不知道"自己应该做什么"。它被训练来预测下一个词,而不是帮助人类。而在 NLP 社区沿着预训练-规模这条轨道全力冲刺的同时,另一个实验室的研究者们,在一条完全平行的轨道上,问了一个截然不同的问题:能不能让 AI 学会做决策,而不只是识别模式?这条平行轨道的起点不是语言,不是图像,而是电子游戏;它的终点不是聊天机器人,而是国际数学奥林匹克——以及今天支撑起所有推理型 AI 的强化学习基础设施。
[!question]
如果说监督学习是让机器从"对照答案"中学习,那么能不能让机器从"结果的好坏"中学习?当游戏规则已知、但正确答案未知时,AI 如何找到最优策略?深度强化学习能否攻克那些连人类专家也束手无策的问题?
14.1、2016 年 3 月,首尔
2016 年 3 月 8 日,韩国首尔,四季酒店。
棋盘上,黑子与白子构成一幅还未写完的宇宙图景。坐在棋盘一侧的,是九段棋手李世石(이세돌,1983—,韩国围棋九段,公认的二十一世纪最具天赋的职业棋手之一)。他在 2006 年横扫当时所有顶级对手,此后十余年始终站在世界棋坛的最前沿;他是职业棋坛中少有的以攻击性棋风著称的棋手,以善走"手筋"——棋盘上出人意料的攻击性妙手——闻名于世。他的对手,是一台运行 DeepMind 软件的计算机,程序名为 AlphaGo。
这是第一局。
直播这场对决的平台覆盖了来自全球数十个国家的数百万观众。中国媒体称之为"人机之战",韩国媒体称之为"机器对人类智慧的挑战",西方媒体则把它类比为 1997 年卡斯帕罗夫输给深蓝的历史性时刻——尽管当时几乎没有人相信会出现那样的结果。围棋界的权威人士在赛前普遍表态:AI 不可能在五年内战胜顶级职业棋手。世界冠军柯洁曾公开评价,他看不出 AlphaGo 有任何赢下李世石的可能。
第一局,AlphaGo 赢了。
棋界震惊,但人们仍在自我安慰:可能是李世石状态不好,或者棋手面对机器存在心理障碍。第二局,AlphaGo 再赢。第三局,还是赢。三连胜后,比赛已经没有悬念——不管第四、五局结果如何,AlphaGo 已经赢下了这场五番棋系列赛,并且在历史上永久地改写了"AI 能做什么"的答案。
但第四局发生了一件意想不到的事。
对局进行到第 78 手时,李世石走了一步令所有人屏息的棋。那手棋落在棋盘右侧一个看起来奇怪而反直觉的位置——黑棋在对方阵地里的一个"断点"轻轻刺入,那个位置在一般的棋局节奏里太超前,太冒进,几乎没有哪位职业棋手会在那个时机落子于此。
AlphaGo 的价值网络完全没有预料到这步棋——它不在 AlphaGo 认为值得考虑的候选落点范围之内。
但正是这步棋,击穿了 AlphaGo 的防线。AlphaGo 的评估开始混乱,接下来数十手,它一步步走入陷阱,局面从优势逐渐变成劣势,最终崩溃认负。直播大厅里爆发出久违的掌声——那是人类在这场系列赛中第一次找回了些许尊严。
赛后,李世石无声地哭泣。不是因为输,是因为那一局赢了。在对局回顾室,棋手们争相复盘第 78 手,有人称之为"神之一手"(Hand of God)。这个细节在此后多年被反复引用——在 AlphaGo 无坚不摧的机器外表上,一位人类棋手以一步几乎不可能的落子,找到了一道裂缝。
最终比分:AlphaGo 4,李世石 1。
四个月前,同一台 AlphaGo 曾以 5:0 击败欧洲冠军樊麾(Fan Hui,1981—,中法双重国籍围棋职业棋手,连续三届欧洲围棋冠军 2013-2015)。那场比赛没有公开直播,棋界很多人不相信 AI 真的能赢,认为是实验室的夸大宣传,并指出樊麾远不是世界顶尖水平。直到首尔的三月,全世界才意识到:这不是一个需要再等十年的未来,而是一个已经降临的现在。
14.2、为什么围棋是"AI 永远无法攻克的堡垒"
要想理解 AlphaGo 的历史意义,必须先理解围棋对 AI 来说有多难。
14.2.1 暴力搜索的极限
在 AlphaGo 出现之前,AI 下棋依靠的主要武器是暴力搜索——穷举所有可能的棋步序列,用"极小极大算法"(Minimax)评估每条路径,找到对当前一方最有利的下一步。这在国际象棋上取得了决定性的成功:深蓝(Deep Blue,IBM,1997 年)打败世界冠军卡斯帕罗夫(Garry Kasparov,1963—,被认为是国际象棋史上最强棋手之一),靠的是每秒搜索约 2 亿步棋,配合专家精心调教的局面评估函数。
围棋的状态空间彻底摧毁了这个方案。
国际象棋每步平均约有 35 种合法落子,而围棋每步平均约有 250 种。整局棋的状态空间,围棋约为 1017010^{170}10170——这个数字超过了宇宙中所有原子的总数量(约 108010^{80}1080)。
用一个直观的类比:如果你每秒能搜索一万亿步棋,从宇宙大爆炸开始一直搜索到今天,你覆盖的围棋状态仍然不到所有可能状态的 10−10010^{-100}10−100。这不是"计算能力不够强"的工程问题,而是物理上根本不可能的事。穷举失效不是深蓝的设计失误,而是围棋复杂性的本质特征。
14.2.2 评估函数:无法用规则捕捉的直觉
国际象棋 AI 除了暴力搜索,还有一件武器:人类专家设计的局面评估函数——用来快速估算当前棋局对各方的优劣,让 AI 不需要搜索到游戏终局,只需往前看几步就能做出合理决策。在国际象棋里,这个评估函数相对容易设计——棋子数量、控制格子数、王的安全性等指标可以被量化。
围棋的局面评估,连职业九段棋手也常常需要沉思数分钟。围棋的形势判断依赖极其复杂的"势"的感知——“这一块棋是活的还是死的?”"这片空域最终会归谁?"这些判断依赖于全盘几百步之后才能揭晓的结果,是一种整体性的、模糊的、高度情境化的直觉,即使棋手本人也很难用语言描述自己的判断过程。
专家系统无法编码这种判断,人工规则无法捕捉"围棋之美"背后的复杂逻辑。1990 年代曾有研究者尝试用专家规则和浅层机器学习构建围棋 AI,最好的程序也只能达到业余初学者水平。
到 2015 年,围棋被围棋界和 AI 界普遍认为是"AI 在未来十年内无法攻克的最后棋类游戏"。这不是谦虚,是当时真实的技术判断——而且有充分的理由支撑。
14.2.3 游戏是强化学习的完美训练场
尽管围棋极其困难,但游戏环境有一个真实世界很少提供的奢侈条件:清晰的胜负信号。
在围棋中,胜就是胜,负就是负,没有模糊地带。AI 可以反复对弈,每次游戏结束后都得到一个明确的反馈:赢或者输。这个反馈,在强化学习里叫做"奖励信号(Reward Signal)"。
监督学习的前提是:有人提前把"正确答案"标注好。但在复杂的决策问题里,"正确答案"往往不存在或无法预先给出。你不知道围棋第 34 手的最优落点是什么——只有整盘棋结束后,你才知道整体走法是赢还是输。这就是强化学习(Reinforcement Learning,RL) 的用武之地:在没有预设正确答案的情况下,需要通过与环境交互和从结果中学习,从而找到最优行动策略。
14.3、强化学习:从尝试与错误中学会策略
14.3.1 一个古老的学习机制
强化学习的基本思想,比机器学习本身古老得多。巴甫洛夫的经典条件反射、斯金纳的操作条件反射——动物通过奖励和惩罚来学习行为——这些心理学实验在二十世纪初就已经系统研究了"从结果学习"的机制。
计算机科学家把这个思想形式化:
一个智能体(Agent) 置身于一个环境(Environment) 中。在每个时刻,它处于某个状态(State,sss),根据当前策略采取某个动作(Action,aaa)。环境接收这个动作,返回两样东西:新的状态 s′s's′,以及一个奖励信号(Reward,rrr)——告诉 Agent 刚才的动作是好是坏。
Agent 的目标:找到一个策略(Policy,π\piπ),让它在所有时刻的决策,最大化累积奖励的期望值(不只是当下的奖励,而是整个未来奖励的折现总和)。
这里有一个关键的困难,叫做信用分配问题(Credit Assignment Problem):当最终结果出来时,你怎么知道是哪一步决策导致了这个结果?一盘围棋下完,你知道赢了——但是哪 50 步是关键的好棋?哪 5 步是导致差点输掉的失误?奖励信号只告诉你最终结果,但从事后的胜负信号反推出每一步决策的"贡献",是 RL 最核心的计算挑战之一。
14.3.2 MDP 与 Q 值:给每步决策打分
RL 的形式化框架叫做马尔可夫决策过程(Markov Decision Process,MDP)。它的核心假设是:当前状态 sss 包含了做决策所需的全部信息——历史不重要,只有当前状态重要(马尔可夫性质)。围棋棋盘上的当前局面满足这个性质:知道现在棋盘上所有棋子的位置,就已经有了做下一步决策的全部信息。
解决信用分配问题的核心工具是 Q 值(Q-value):在状态 sss 下执行动作 aaa 后,遵循最优策略所能获得的期望累积奖励,记为 Q(s,a)Q(s, a)Q(s,a)。直觉上,Q 值就是"在这个局面下走这步棋,长期来看有多好"。
如果能精确知道所有状态-动作对的 Q 值,做决策就变得简单:在每个状态下,选择 Q 值最大的动作。
Q-learning 是计算 Q 值的经典算法,由克里斯托弗·沃特金斯(Christopher Watkins,-,剑桥大学博士,Q-learning 发明者)在 1989 年的博士论文中提出。它的思路是:从随机的 Q 值估计开始,每次执行动作并观察到奖励后,根据实际获得的奖励和后续状态的估计价值,更新 Q 值的估计。这个更新规则被称为 Bellman 更新,以数学家理查德·贝尔曼(Richard Bellman,1920-1984,动态规划理论奠基人)命名。理论上,Q-learning 能在足够多的试验后收敛到最优策略。
实践上,状态空间爆炸使 Q-learning 在复杂环境中完全不可行:围棋有 1017010^{170}10170 个状态,一张存储所有 Q 值的表格是不可能的。
这个问题直到 2013 年才被解决,解决它的工具,正是我们已经熟悉的深度神经网络。
14.3.3 两种优化策略的路径
在 Q-learning 之外,RL 还有另一类核心算法思路:策略梯度(Policy Gradient)。
Q-learning 的思路是"先算出每步的好坏,再根据好坏选择行动"——间接地通过 Q 值来改善策略。策略梯度的思路更直接:直接优化策略函数本身,让产生好结果的行为在策略中出现的概率更高。
直觉类比:Q-learning 像是先给每道菜打分,再根据分数决定点什么——需要把对结果的判断转化成对当前的估计。策略梯度像是直接观察顾客的满意度,哪道菜被喜欢就让它在菜单上更显眼——直接根据反馈调整行为概率。
策略梯度的数学推导来自一个优美的定理——策略梯度定理(Policy Gradient Theorem),由萨顿(Richard Sutton,1950—,RL 领域泰斗,《强化学习:导论》作者)和同事在 2000 年形式化。它告诉我们,在不知道完整环境模型的情况下,也可以精确计算出"怎么调整策略参数,能让期望累积奖励提升"的梯度方向——这使得策略优化可以直接用深度学习框架里的随机梯度下降来完成。
AlphaGo 的策略网络用策略梯度来优化自我对弈胜率;ChatGPT 用 PPO(近端策略优化,Proximal Policy Optimization)来优化人类偏好得分——从围棋到对话 AI,策略梯度是连接两者的技术纽带。
14.4、DQN:深度学习遇上强化学习
14.4.1 从像素到动作:一个统一框架
2013 年,谷歌旗下 AI 研究实验室 DeepMind 在 NIPS 发表了论文《用深度强化学习玩 Atari》。第一作者沃洛季米尔·明尼赫(Volodymyr Mnih,-,乌克兰裔研究员)和团队的核心洞察:用深度神经网络来近似 Q 函数。
与其存一张不可能存下的 Q 值表格,不如训练一个神经网络——接收游戏画面(像素)作为输入,输出每个可能动作的 Q 值估计。这个网络被称为 Deep Q-Network(DQN)。
想法很简单,但想让它真正稳定地工作,需要解决两个当时没有标准解法的核心问题:
问题一:时序相关性破坏了训练假设
在游戏中,连续帧之间高度相关——从第 ttt 帧到第 t+1t+1t+1 帧,画面往往只有微小变化。而深度神经网络的梯度下降训练,需要数据是独立同分布的(i.i.d.)——这是从统计学角度保证训练有效的基本假设。如果直接用序贯游戏帧训练,就好像让学生只用同一本书的内容反复做题,答案有系统性偏差,网络容易过拟合到局部规律,陷入糟糕的策略而无法自拔。
DeepMind 的解决方案:经验回放(Experience Replay)。把历史上所有的"状态-动作-奖励-新状态"四元组(通称 “transition”)存在一个重放缓冲区(Replay Buffer) 里。每次训练时,不是用最新的游戏帧,而是从缓冲区里随机均匀采样一个批次。这打破了时序相关性——随机采样出来的数据,来自游戏历史的不同时刻,彼此之间没有顺序依赖,从统计角度更接近 i.i.d.。
这个想法最初由林龙(Lin Long-Ji)在 1992 年提出,但在深度学习时代被 DeepMind 系统性地应用,才展示出真正的力量。
问题二:训练目标本身在动
Q-learning 是一种 Bootstrapping 方法——它用当前估计的 Q 值来更新 Q 值。问题在于:如果更新目标(target)本身就是由当前神经网络产生的,那么每次更新网络参数后,目标也在变。这就像试图射击一个移动靶,而靶是跟着你的子弹走的——训练极不稳定,容易来回振荡,甚至发散。
DeepMind 的解决方案:目标网络(Target Network)。维护两个参数几乎相同的网络:一个在线网络(Online Network) 负责选择动作,每次训练后立即更新;一个目标网络(Target Network) 负责生成训练目标,但它的参数每隔固定步数才从在线网络同步一次(如每 10000 步同步一次)。
这给训练目标提供了一个"临时稳定锚点"——在这 10000 步内,目标是固定的,不会随着在线网络的更新而抖动。这大幅降低了训练振荡,是让 DQN 真正稳定收敛的关键工程决策之一。

图 14.1:DQN 架构示意图,该算法的实际工作步骤为:
- 创建 Q 网络和目标网络
- 使用 Q 网络填充经验缓冲区
- 重复以下步骤足够次数
- 从经验缓冲区随机抽取样本
- 将样本作为输入馈入 Q 网络和目标网络
- 使用目标网络的输出训练 Q 网络(即在标准监督学习场景中,目标网络的输出将充当 Q 网络的标签)
- 应用探索/利用策略(例如 εεε-贪婪策略)
- 如果选择探索则生成随机动作,如果选择利用则将当前状态输入Q 网络并从输出推导动作
- 对环境施加动作,获取奖励和新状态
- 将旧状态、动作、奖励和新状态存储到经验缓冲区(也称为回放记忆)
- 每隔一定轮数,将 Q 网络的权重复制到目标网络
14.4.2 49 个游戏,一套权重,人类水平
2015 年,DeepMind 将这项工作完整发表在《自然》期刊上,论文标题《通过深度强化学习实现人类级别的控制》(Human-level control through deep reinforcement learning)。
结果令人震撼:同一套 DQN 架构,只通过接收像素输入和游戏得分,无需任何游戏专有的人工规则,在 49 个不同的 Atari 游戏中,有 29 个达到了人类玩家的水平甚至超越人类。
这是第一次,一个 AI 系统:
- 从原始感知直接学习复杂决策:输入是未经处理的像素,不是人工设计的特征,神经网络自己学会提取有用的视觉信息
- 用同一套框架处理多种截然不同的游戏:赛车、弹珠台、乒乓球、太空侵略者——同一套代码,同一套训练流程,只换游戏规则
- 仅凭稀疏的"得分"信号,自主发现多步骤策略:没有人告诉 AI"应该这样玩",一切都来自尝试、观察、强化
在《打砖块》(Breakout)游戏中,DQN 甚至发现了一个专业级别的高效策略:“隧道挖掘”——把小球打到侧墙旁边,让它钻进砖墙顶端和边界之间的缝隙,在顶部快速反弹,一次清除整排砖块,最高效地得分。这个策略没有任何人教给它,是 DQN 在数百万帧的自我训练中摸索出来的。在某种意义上,DQN 在《打砖块》里"发明"了一个玩法,而这个玩法已经超出了游戏设计者的预期。
DQN 的发表在 AI 界引起广泛关注,但也有大量质疑:Atari 毕竟只是 2D 游戏,状态空间有限,奖励信号相对密集。围棋完全不同:几百步后才决出胜负,中间没有密集的奖励信号;棋盘局面的数量远超任何现有计算能力的处理范围。
但 DeepMind 已经把目光投向了围棋。
14.5、AlphaGo(2016):三套神经网络合奏
14.5.1 核心挑战:稀疏奖励与巨大动作空间
DQN 的框架在围棋上面临两个根本性的困难:
第一,稀疏奖励。一盘围棋通常有 200-300 步,而奖励只在最后一步出现——“你赢了"或者"你输了”。300 步之后才得到一次"对"或"错"的反馈,怎么知道是哪一步走错了?这就像让一个学生在期末考完所有课程后,只告诉他"总体上不太好",但不告诉他具体哪门课、哪道题出了问题——信用分配问题被放大到极致。
第二,巨大的动作空间。围棋的动作空间是 19×19=36119 \times 19 = 36119×19=361 个可能落子点,状态空间 1017010^{170}10170,朴素 Q-learning 或 DQN 根本无从下手。
大卫·西尔弗(David Silver,1976—,DeepMind 强化学习负责人,强化学习教材作者,AlphaGo 系列主要架构师)的团队,设计了一个精妙的三组件架构,将监督学习、强化学习和树搜索组合起来,各司其职,解决不同的核心困难。
14.5.2 策略网络:学习围棋的"直觉"
第一个组件是策略网络(Policy Network)。它的任务是:给定当前棋盘局面,预测哪个落子点最可能是好棋。
换成概率语言:输出一个在 19×19=36119 \times 19 = 36119×19=361 个落子点上的概率分布,概率高的地方是"值得考虑"的好棋,概率低的地方是"不值得搜索"的坏棋。
训练数据:KGS(一个在线围棋平台)上数十万盘人类高手的对局棋谱,共约 3000 万步落子。训练方式:监督学习——给定局面,预测人类棋手实际走的下一步。把这个过程做到极致:模型的输入是完整棋盘局面(以及若干衍生特征),输出是对 361 个落子点的概率分布,目标是使人类实际走的那步棋在输出中概率最高。
训练后的策略网络准确率约为 57%,意味着有一半以上的时间能猜对人类棋手的选择。在围棋 361 个可能落子点的巨大动作空间里,这已经是惊人的精度——它意味着 AI 已经掌握了围棋的基本"直觉":大部分时候,它知道哪些地方是值得考虑的,哪些地方可以直接排除。
但"预测人类下一步"不等于"下出最强的棋"——人类棋手也会犯错,人类的集体知识有上限。所以 DeepMind 用强化学习进一步优化策略网络:让它与以前版本的自身对弈(Self-Play),通过胜负信号更新策略——赢棋时,这盘棋里的每一步出现概率都微微提升;输棋时,每一步出现概率都微微降低。这个过程叫做策略梯度(Policy Gradient)。
经过策略梯度优化后的 RL 策略网络,面对仅凭监督学习的版本,胜率超过 80%——这说明自我对弈发现的围棋知识,已经超越了人类棋谱所能传授的东西。
14.5.3 价值网络:解决稀疏奖励
第二个组件是价值网络(Value Network)。它的任务是:给定当前棋盘局面,预测当前玩家最终获胜的概率(一个介于 -1 到 1 之间的实数)。
这解决了稀疏奖励的问题。不需要下完整盘棋才知道形势——有了价值网络,在任何中间局面都能立即估算"这盘棋赢面多大",相当于给每个中间状态补充了一个"伪奖励"。
训练价值网络的数据来源有些精妙:用已经训练好的 RL 策略网络进行大量自我对弈(3000 万盘,每盘从随机局面开始),每盘棋的每个局面都打上最终胜负标签,产生海量"局面-胜率"训练样本。之所以不能直接用人类棋谱中的局面,是因为人类棋谱里同一个对局的局面高度相关,用于训练会导致过拟合。
价值网络单独的预测精度已经接近蒙特卡洛方法的估计(大量随机走棋到终局取平均),但计算量只有后者的万分之一——这才是它真正的工程价值:用神经网络直接"短路"了原本需要模拟几千步才能知道的信息。
14.5.4 MCTS:让搜索变得有方向
第三个组件是蒙特卡洛树搜索(MCTS,Monte Carlo Tree Search)。
MCTS 是 2006 年左右在围棋 AI 研究中发展起来的框架,核心思想是在游戏树上有选择地展开节点:多探索那些看起来有希望的分支,少探索那些看起来无望的分支,而不是暴力枚举所有可能性。它是一种在"探索(探索未知的落点)"和"利用(深入已知的好路线)"之间做平衡的搜索策略。
单独的 MCTS 在围棋里效果有限,因为它在叶节点要进行随机走棋模拟到终局——随机走棋的质量很差,需要大量模拟才能得到可靠的估计,速度极慢。
AlphaGo 用两个神经网络改造了 MCTS:
- 策略网络:决定"往哪个分支走"——展开当前节点时,策略网络给出每个落点的概率,高概率落点被优先搜索,低概率落点被忽略。这把搜索集中在有价值的方向,极大减少了需要搜索的分支数量
- 价值网络:替代随机模拟,直接估计叶节点的价值——不需要从叶节点随机走到终局,价值网络一次前向传播就能给出胜率估计,计算更快,估计更准
两者结合的结果是:AlphaGo 在有限的计算时间内(通常每步思考几秒),对最重要的棋步进行了有效的深度分析,而不是漫无目的地暴力搜索。
14.5.5 Move 37 与 Move 78:两种不同的"神迹"
首尔系列赛中,最令棋界久久回味的,有两步棋——但它们代表了两种完全不同的"神迹"。
第二局第 37 手:机器的神迹
对局进入中盘,AlphaGo 在棋盘靠右的位置走了第 37 手。按照围棋的落子习惯,那个位置在这个局面时机太早,那个方向太违背常规——英语解说员迈克尔·雷德蒙德(Michael Redmond,9 段职业棋手,英语围棋解说第一人)当时沉默了好几秒,无法立即解读这步棋的意图。
棋手们看了数十手后逐渐明白:那步棋是一个影响极广的棋盘手筋,它以一种非线性的方式预先布局了数十手之后的局面,它的"收益"不在当下,而在未来某个时刻才会兑现的奖励。这不是人类棋手常见的思维方式,因为人类很难同时追踪如此遥远的因果链条。AlphaGo 的策略网络给这步棋的概率:只有万分之一。但 AlphaGo 的 MCTS 搜索给它的胜率估计:最高。
世界围棋冠军柯洁事后说:“当我看到这步棋,我感到了某种触动,它让我重新思考围棋的可能性。”
第四局第 78 手:人类的神迹
第四局,李世石走了那步出乎所有人预料的棋,AlphaGo 崩了。
这两步棋放在一起,构成了这场系列赛最深刻的叙事——一步棋来自机器,一步棋来自人类,都是"不可能的落点",都撼动了另一方的防线。也许这才是 2016 年首尔真正留下的遗产:不只是"AI 赢了",而是"AI 和人类都在彼此身上发现了新的可能性"。
14.6、AlphaGo Zero(2017):从零开始,超越人类积累的一切
14.6.1 一个更激进的问题
2016 年的胜利之后,DeepMind 的研究者们提出了一个颠覆性的问题:人类的棋谱,对 AI 来说究竟是帮助还是束缚?
AlphaGo 的策略网络以人类棋谱为起点——它初始学到的"直觉",是人类围棋文明几千年积累的提炼。但人类对围棋的理解,从宇宙的尺度来看,只是搜索空间极小的一角。如果存在超越人类从未发现过的更优棋路,从人类棋谱出发是否会成为枷锁?
2017 年 10 月,AlphaGo 团队在《自然》发布了 AlphaGo Zero,完全颠覆了这个前提。
Zero 的训练规则非常简单:
- 只告诉 AI 围棋的规则(什么是合法落子,什么是胜利条件)
- 从完全随机的落子开始,对自己的旧版本进行自我对弈(Self-Play)——每次生成最新版本的 AI 后,把它作为陪练来训练对手
- 根据对局的最终结果(赢或者输),用策略梯度更新神经网络
没有人类的棋谱,没有任何形式的人工知识注入,没有手工特征。唯一的信息源,是规则本身和无数盘自我对弈的胜负结果。
14.6.2 三天,四十天,超越了一切
训练 3 天后,AlphaGo Zero 对阵 2016 年打败李世石的 AlphaGo 版本(AlphaGo Lee),胜率 100:0。
训练 21 天后,它超过了 AlphaGo Master——DeepMind 在 2017 年初以 60:0 横扫包括柯洁在内的全球所有顶级职业棋手的更强版本。
训练 40 天后,AlphaGo Zero 达到了所有 AlphaGo 版本历史上的最高水平,在顶级水平持续提升中,没有出现明显的饱和迹象。
不需要人类的知识,比学了所有人类知识的版本还要强。这个结果在当时令整个 AI 界震惊。
14.6.3 技术上做了什么不同?
相比原版 AlphaGo,Zero 做了几个关键改变:
单一网络替代两个网络:原版 AlphaGo 有独立的策略网络和价值网络。Zero 把两个网络合并成一个,共享残差网络(ResNet) 的主干部分,最后分成两个"头"(Head)——一个输出策略(各落子点的概率分布),一个输出价值(当前局面的预计胜率)。共享特征提取使两个任务互相促进:学习"当前局面谁优谁劣"(价值)本身就要求理解"哪些落点是好棋"(策略);反过来学习"好棋在哪"也需要理解局面的整体走势。
完全去掉人工特征:原版 AlphaGo 的输入包含了人工设计的特征(如"气"的计算、各种棋型的识别)。Zero 的输入只是原始棋盘——黑子的位置、白子的位置、最近 8 步的历史局面,再加上轮到哪方落子。没有任何人工特征工程,完全依赖神经网络自己学习有用的表示。
更简洁的 MCTS:不再用独立的 Rollout 策略网络进行随机模拟,完全依赖主网络的价值头来评估叶节点。搜索更快,评估更准。
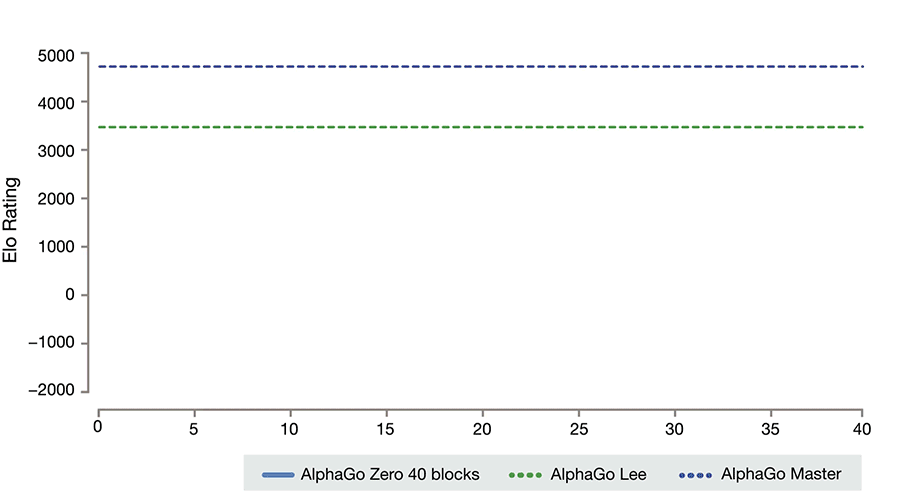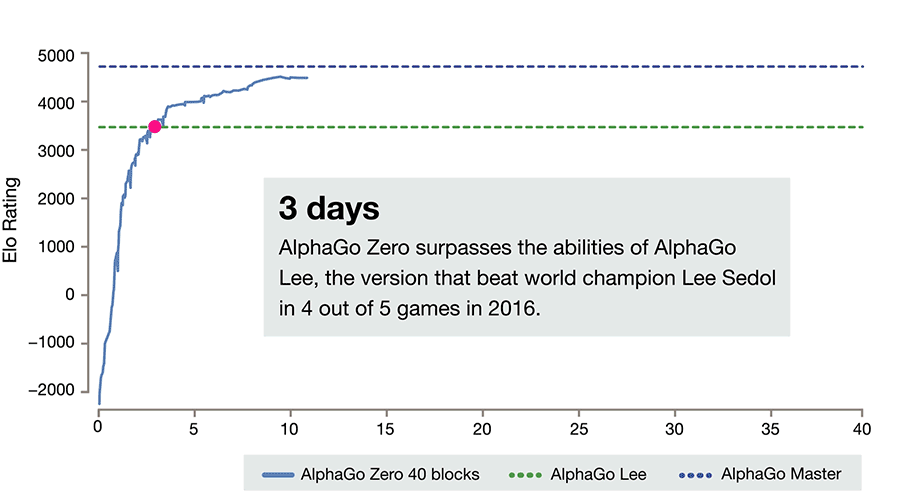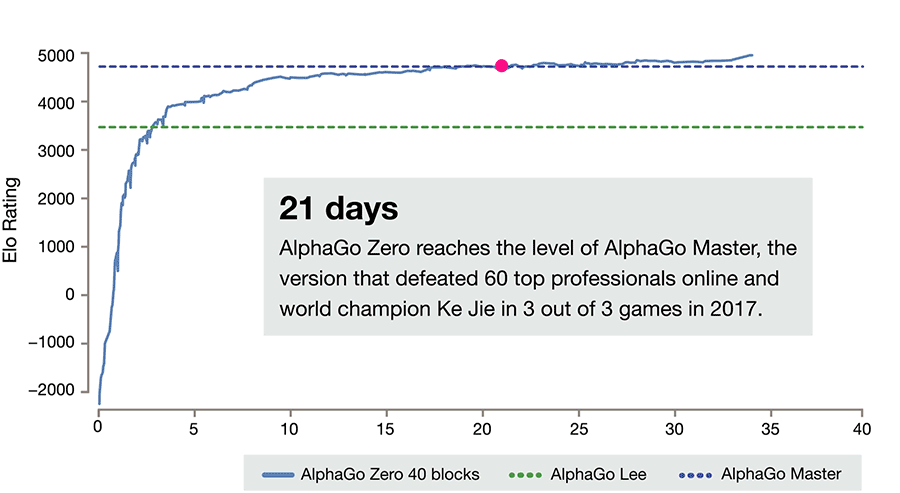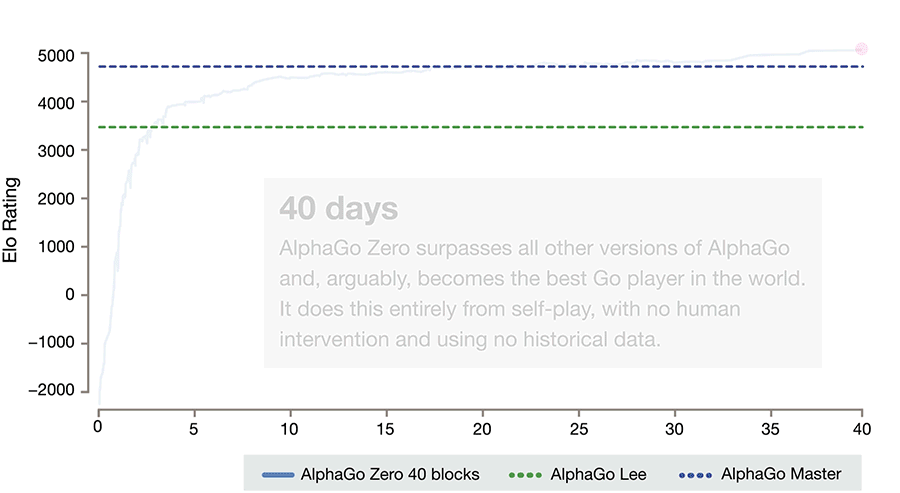
图 14.2:AlphaGo Zero 训练曲线,横轴为训练天数(0-40天),纵轴为 Elo 评分,展示 AlphaGo Zero 的 Elo 随训练时间的增长曲线,并用水平虚线标注 AlphaGo Lee(Elo ~3739)和 AlphaGo Master(Elo ~4858)的水平线,体现 Zero 如何在 40 天内超越所有前代版本。
14.6.4 这个结果意味着什么?
AlphaGo Zero 的成功在 AI 界引发了两种截然对立的解读。
一种解读:这证明了当计算资源足够充足,从规则出发的纯 RL 自我对弈,能发现超越所有人类积累的最优策略。人类知识固然有价值,但带有偏见和历史局限性——几千年的人类围棋,只是整个搜索空间的极小局部最优。在不受限的计算假设下,自我对弈是达到全局最优的更直接路径。
另一种解读:这个胜利的代价是 490 万盘自我对弈——这是任何人类棋手一生也无法完成的练习量。在样本效率上(用多少数据达到多高水平),人类的学习远比 RL 更高效。一个 10 岁的棋童,通过向师父学习几年,就能达到 AlphaGo Zero 训练前期的水平,但消耗的"数据量"不到后者的万分之一。
这场争论延伸到更大的问题:纯粹的数据驱动学习,是否能复现人类的高效学习?还是人类学习中有某种特殊的先验知识结构——归纳偏置、因果推理、概念迁移——是数据驱动的 RL 无法简单替代的?这个问题至今也没有形成定论,并持续推动着 AI 基础研究的方向。
14.7、AlphaZero(2017):一个算法统治三种棋
AlphaGo Zero 回答了"人类知识是否必要",AlphaZero 则回答了一个更宏大的问题:这套框架是否是通用的?
2017 年 12 月,DeepMind 在 arXiv 发布了 AlphaZero,用完全相同的算法框架,只改变游戏规则输入,在三种棋类游戏上分别进行了训练:
国际象棋:训练 9 小时后,在 100 盘对局中以 28 胜 72 平 0 负的成绩击败 Stockfish——国际象棋界当时最强的引擎,一个经过数十年专家精调、每秒搜索约 7000 万步棋的系统。AlphaZero 每秒搜索约 8 万步——比 Stockfish 少了将近 1000 倍——但赢了。
将棋(日本象棋):训练 12 小时后,击败 Elmo——当时的将棋最强引擎,以压倒性优势取胜。
围棋:训练 13 小时后,达到 AlphaGo Zero 同等水平。
国际象棋界被这个结果震惊到有些难以接受。Stockfish 的主要开发者之一 Tord Romstad 看到棋谱后承认:“它下棋的风格和我们见过的任何引擎都不同,它好像在’理解’棋局,而不是在穷举计算。”
研究者对 AlphaZero 的国际象棋风格进行了系统分析:相比传统引擎优先最大化棋子物质优势,AlphaZero 更愿意牺牲棋子换取位置优势和动态主动权——这是顶级特级大师(Grandmaster)风格的精髓,优先掌握主动权和棋局节奏而非计算物质得失。这种棋风以前从未在计算机棋手中出现过,它不是被设计进去的,而是 AlphaZero 通过自我对弈自己"发现"的。
AlphaZero 证明了:这套"从规则出发的自我对弈"框架,是通用的。 只需要知道游戏规则——不需要人类知识,不需要领域特定的设计——给足够的计算,AI 就能在这个领域超越所有人类和人类设计的系统。
这个结论的影响远超棋类游戏:它预示着任何可以被明确规则化的问题,都可能成为自我对弈 RL 的战场。
14.8、AlphaStar(2019):不完备信息与实时决策
围棋尽管极其复杂,仍然是"完备信息回合制游戏"——双方都能看到完整的棋盘,每一步可以思考较长的一段时间。现实世界的决策问题很少如此"公平"和"充裕"。
2019 年 1 月,DeepMind 展示了 AlphaStar——能在《星际争霸 II》(StarCraft II)中达到职业选手水平的 AI,这是深度强化学习从"理想环境"踏入"近真实复杂度"的重要一步。
《星际争霸 II》被认为是游戏 AI 的终极挑战,原因是多维度的:
不完备信息:战争迷雾(Fog of War)遮住了对手的操作。你看不到对手在哪里建造基地、训练什么兵种,必须根据不完整的信息推断对手意图,并制定相应的侦察和欺骗策略。这从根本上改变了 AI 的决策框架——MCTS 假设可以看到完整的游戏树,在不完备信息游戏里这个假设几乎完全失效。
实时决策:围棋可以思考较长的时间,星际争霸要求每分钟执行数百个动作。职业选手的 APM(每分钟操作次数)通常在 200-400 之间,AI 必须在极短时间内(毫秒级)完成感知-决策-执行的完整循环,没有"慢慢想"的余地。
超长时间跨度和层次化决策:一盘游戏可以持续 30 分钟以上,涉及宏观战略(科技树路线、资源调配、扩张时机)和微观操作(每个单位的移动路径、战斗目标选择)的同时协调。这两个层次的决策有不同的时间尺度,需要同时优化。
巨大的多维动作空间:每一步的合法操作是多个维度的组合——选择哪个单位(最多几百个)、执行什么命令(移动、攻击、建造……)、目标位置(地图上任意坐标)……直接用 DQN 来建模这个动作空间几乎不可行。
AlphaStar 的核心架构创新之一是多智能体自我博弈(Multi-agent Self-Play):不是只训练一个 AI 对抗自己,而是同时训练一群 AI 智能体组成的"联赛",每个智能体专门对抗某些风格的对手。这产生了一个多样化的策略生态系统,避免了单一 AI 的策略过于单一而形成策略盲区(例如只会一种战术而被任何了解这个战术弱点的对手克制)。
2019 年 1 月的公开直播演示中,AlphaStar 以 5:0 击败了职业选手 TLO(格热戈日·科明茨,Grzegorz Komincz,波兰职业选手)和 MaNa(多里安·维布斯,Dario Wünsch,波兰职业选手)。
围棋(完备信息,回合制)和星际争霸(不完备信息,实时)——两种截然不同的游戏环境里,AI 都达到了人类顶级水平。深度强化学习跨越了"理想化假设"的边界,开始在更接近真实世界的混乱条件下证明自己。
AlphaStar 之后,研究者也坦承了它的局限。AlphaStar 使用的是独立的摄像头视角(类似"电影视角"),而非像职业选手那样频繁切换到地图不同角落查看战况——这让 AlphaStar 在某种程度上拥有比真实人类选手更稳定的信息获取方式。职业选手事后分析认为,如果加入这个限制,AlphaStar 的表现会有一定影响。
这是 RL 研究中一个反复出现的诚实问题:实验室里达到"超人水平",究竟是在什么假设下达到的?这些假设和现实的距离有多远?AlphaStar 团队在论文中详细披露了这些限制,因为清楚地区分"在设定条件下达成什么"和"在无限制条件下达成什么",是科学诚信的基本要求。这种对结果边界的诚实讨论,也是 DeepMind 系列工作在学界赢得广泛尊重的原因之一。
14.9、AlphaFold:一段叙事桥接
在 DeepMind 沿着 RL 轨道从 Atari 到围棋到星际争霸一路推进的同时,另一条研究线在悄悄积蓄力量——蛋白质结构预测。
2020 年的 CASP14(蛋白质结构预测竞赛)上,DeepMind 的 AlphaFold 2 以碾压其他参赛者的精度,解决了生物学界 50 年来最重要的开放问题之一。2024 年,德米斯·哈萨比斯(Demis Hassabis,1976—)和约翰·贾姆珀(John Jumper,1985—)因此获得诺贝尔化学奖,这是 AI 研究史上首次斩获诺贝尔科学类奖项。
这里需要明确一点:AlphaFold 2 的核心是 Transformer,是监督学习,不是强化学习。 它的技术架构——Evoformer 模块、多序列比对(MSA)、等变几何注意力——已经在本书第十章中详述。
在这里提到 AlphaFold,是因为它完成了一幅重要的叙事图景:DeepMind 在同一个十年里,同时保持了两条研究线的世界领先地位——RL 路线(DQN → AlphaGo → AlphaZero → AlphaStar → AlphaProof)和监督学习+Transformer 路线(AlphaFold)。这两条路线共同定义了 DeepMind 在 AI 史中的独特地位:它始终把"理解智能本身"作为驱动力,而不是把商业化作为首要目标。
14.10、AlphaProof(2024):RL 攻克形式化数学
14.10.1 游戏之后,数学
2024 年 7 月,DeepMind 公布了 AlphaProof 与 AlphaGeometry 2 的组合在 2024 年国际数学奥林匹克(IMO)题目上的成绩:解答了 6 道题中的 4 道。若以真实参赛规则评分,这达到了银牌水平(满分 42 分,AlphaProof 组合得到 28 分,距金牌线约差 1-2 分)。
国际数学奥林匹克是全球最顶尖的数学竞赛,参赛者是各国最优秀的高中数学天才。即使对人类顶级数学家而言,IMO 的许多题目也需要非凡的创造力和直觉洞察。
这不是"解数学题"意义上的暴力计算——AlphaProof 的输出是用 Lean 4(一种形式化数学证明语言)写成的完整机器验证证明,每一步推导都经过 Lean 4 的逻辑核验,绝无模糊近似,不存在"大概对"。这比填写最终答案要困难几个数量级:在自然语言证明中可以略去的"显然"步骤,在 Lean 4 里必须逐一展开,每一步都必须严格合法。
14.10.2 从围棋到数学:一脉相承的结构
AlphaProof 的技术架构与 AlphaZero 有深刻的结构相似性,这不是巧合,而是同一套思想在不同领域的迁移:
环境即规则系统:Lean 4 证明系统充当"游戏环境"——AI 在证明过程中每写出一条推导步骤,Lean 4 检查这步是否合法(是否符合数学逻辑规则),就像围棋裁判检查每步是否是合规落子。状态是"当前已写出的证明",动作是"下一步写出什么推导",规则是数学逻辑本身。
稀疏奖励与长程规划:证明成功 → 正奖励;超出步数限制或证明卡死 → 负奖励。和围棋的胜负信号类似,但更为稀疏——一道困难的 IMO 题目可能需要数百乃至数千步形式化推导步骤,而奖励只在最后一步出现。
LLM + RL 的深度融合:这里出现了一个关键的技术融合节点。AlphaProof 用一个预训练的语言模型来提出"下一步推导应该写什么"的候选——语言模型已经通过大量数学文本训练,掌握了对数学推理步骤的基本理解。在这个语言模型策略的基础上,RL 通过树搜索在可能的证明路径空间里寻找正确的完整路径。
这个架构告诉我们:监督学习的语言模型提供了"知道数学语言的模样",RL 提供了"找到正确证明路径"的搜索能力。两者缺一不可——纯粹的语言模型会在长链推导中犯下逻辑错误,而纯粹的 RL 没有语言模型提供的先验知识,搜索空间太大无从下手。
AlphaProof 不只是游戏 AI 的延伸,而是 RL 进入人类创造性智识活动的宣言:数学证明,这个人类最严谨的知识活动,正在被机器系统性地攻克。
14.11、边界与局限:强化学习的根本性挑战
14.11.1 样本效率:AI 是"挥霍资源"的学习者
AlphaGo Zero 在 40 天内打完了 490 万盘自我对弈,才达到超越所有人类的水平。
一个人类棋手,一生下棋的总盘数,即使是职业棋手,可能也不超过 10 万盘。
这个对比揭示了 RL 最核心的短板:样本效率(Sample Efficiency)极低。人类能从极少量经验中泛化、推理、迁移到新情境——这背后有什么?认知科学家的答案包括:先天的归纳偏置(对物理世界和社会关系的先验预期)、语言和符号系统(大幅压缩知识表示)、因果推理能力(理解"为什么"而不只是"是什么")、跨领域迁移(从国际象棋学到的策略思维可以迁移到商业谈判)。
当前的 RL 系统大多依靠数以百万计的自我对弈来弥补缺乏先验的不足。这使 RL 的成功难以迁移到"经验昂贵、无法大量试验"的真实世界场景。医疗 AI 不能在真实病人身上反复试错学习;工业机器人不能摔坏数万个零件来学习正确操作;自动驾驶不能在真实道路上通过撞车来学习避障。游戏环境里"试错"是免费的(最多重置游戏),真实世界里"试错"有可能是代价惨重的。
14.11.2 奖励设计:定义"你真正想要的"
强化学习对奖励信号的质量极度依赖。奖励稀疏(只有最终结果)使学习效率低下——这是可以通过设计"奖励塑形(Reward Shaping)"来部分缓解的工程问题;但奖励设计错误,会导致 AI 学到完全意想不到的错误行为,这被称为奖励黑客(Reward Hacking)。
一个被反复引用的案例:OpenAI 训练 AI 玩海岸赛船游戏(CoastRunners),奖励设定为赛道上积累的得分(路过特定标志物得分)。AI 发现,在某个位置原地转圈可以反复经过得分点,积累高分,而不需要完成赛程——于是 AI 学会了着火转圈,永远不到达终点,但得分极高。
这不是 AI 的"调皮",而是它在精确地最大化设计者给出的奖励——只是设计者给出的奖励和设计者真正想要的行为之间,存在一条裂缝。
奖励设计是一门艺术,也是 RL 落地的核心工程挑战。在任何复杂任务中,如何精确地定义"好的行为"而不被 AI 以你没想到的方式钻空子,是一个极为困难的问题。这个困难,在 AI 对齐研究领域有一个更大尺度的哲学表述:如何向一个智能系统准确传达"你真正想要的"而不只是"你能描述的想要的"? RL 的奖励设计困境,是对齐问题的微观版本——它以一个可观察、可实验的具体形式,预演了对齐问题的核心难题。
14.11.3 泛化能力:窄域的无敌与领域外的无知
AlphaGo Zero 是围棋历史上最强的棋手。但它无法下国际象棋,无法理解"围棋"这个词的文化含义,无法告诉你李世石的这场系列赛对 AI 历史意味着什么。
这种窄域超越(Superhuman in narrow domain) 与真正意义上的通用智能之间,存在着巨大的鸿沟。RL 系统通常极度依赖于训练环境的特定参数——棋盘大小、规则细节、画面风格——在环境稍有变化时性能可能急剧下滑("分布偏移"问题)。
这种脆弱性在博弈游戏中不是问题(游戏规则固定不变),但在真实世界中是致命缺陷。解决这个问题——让 RL 训练的 AI 能在真实世界的多变条件下鲁棒地行动——是具身智能研究的核心难点,也是我们将在第三十二章要专门讨论机器人 AI 的原因。
14.11.4 探索-利用困境:知道该探索还是该利用
RL 中有一个经典的基础困难:探索-利用困境(Exploration-Exploitation Dilemma)。
"利用"是指充分利用当前已知的最优策略(已知的好棋走法);"探索"是指尝试不确定的、可能更好的策略(走一步没见过的棋,看看结果)。
如果只利用,AI 可能永远停留在局部最优,错过更好的全局策略——就像只在熟悉的街区觅食的动物,永远不知道更远处有更丰盛的食物来源。
如果只探索,AI 会把大量时间花在尝试明显糟糕的策略上,浪费宝贵的训练样本。
平衡探索和利用,是 RL 算法设计的核心挑战之一。AlphaZero 通过 MCTS 的上置信界(UCB)公式来做这个平衡,但在更复杂的连续动作空间和大规模环境中,这个问题至今没有完美的解法。
14.12、两条轨道的汇合:RL 如何改变了语言模型
回到我们暂时离开的 LLM 主线。这条平行的 RL 轨道,从 2022 年起与语言模型的发展路线开始深度交汇,产生了今天最强大的 AI 系统的技术基础:
自我对弈 → 自我批评与改进:AlphaGo Zero 的自我对弈思想,在 LLM 领域演变为多个重要机制。Anthropic 的 Constitutional AI 让 AI 按照一套原则对自己的输出进行批评和修改,本质上是语言模型版本的"自我对弈"。RLAIF(AI Feedback 的强化学习)用 AI 打分代替人类打分,也是"用自己来训练自己"思想的延伸。
稀疏奖励与信用分配 → 奖励模型:RL 中如何从最终结果反推每一步决策贡献的信用分配问题,在 RLHF 中演变为"训练奖励模型":用人类对"偏好/拒绝"输出对的标注,训练一个神经网络来预测人类偏好——这个奖励模型,本质上是把人类的价值判断转化成了一个可微的奖励函数。
策略优化(PPO):让语言模型最大化奖励模型打分的算法,用的正是近端策略优化(Proximal Policy Optimization,PPO)——一个通用的 RL 策略梯度算法,由 OpenAI 于 2017 年提出,最初用于机器人控制和游戏任务,后来成为 RLHF 的核心优化引擎。
GRPO:DeepSeek-R1 训练中使用的奖励优化方法(Group Relative Policy Optimization),是对 PPO 的简化变体,去掉了价值函数估计,改用组内相对奖励——这正是 RL 在语言推理领域工程化落地的典型产物,DeepSeek 用它把 RL 训练推理的计算成本降低到之前的一小部分。
推理即搜索:AlphaZero 的树搜索策略,在 OpenAI 的 o1/o3 等推理模型中演变为"思维链"(Chain-of-Thought)和 Test-Time Compute Scaling——模型在推理时花更多计算来"搜索"更好的答案路径,而不是一步到位生成答案。这和 MCTS 在游戏树里搜索最优落子的思想,有深刻的结构相似性。
AlphaGo 式的"游戏环境自我验证"思想:AlphaGo Zero 之所以能自我对弈学习,是因为围棋有明确的规则——输赢可以被客观验证。这个思想被推广到语言模型领域:对于有客观答案的任务(数学题、代码是否能运行、逻辑推理是否有效),模型同样可以用"答对/答错"作为奖励信号,直接做强化学习——不需要人类打分,不需要昂贵的奖励模型。这被称为"基于可验证奖励的强化学习(RL with Verifiable Rewards)",是 DeepSeek-R1 和 o1 等推理模型的核心训练成分。围棋和数学,在这个角度看来,是同一类问题:有清晰规则,有客观胜负,可以无限自我对弈。
从 2013 年 DQN 的 Atari 游戏像素,到 2024 年 AlphaProof 的国际数学奥林匹克形式化证明,再到 2025 年语言模型用 RL 系统性地强化推理能力——这条平行轨道不是 AI 历史的旁支,而是今天最前沿 AI 系统能力的直接来源之一。
AlphaGo 在 2016 年证明了一件事:给机器一个清晰的目标和足够的计算资源,它能发现超越所有人类的策略。这个证明,从根本上改变了整个领域对 AI 可能性的预期——而它引入的技术和思想,至今仍在塑造着最新的 AI 系统。
14.13、知识自检
读完本章,你应该能做到:
- 解释强化学习的基本框架(Agent、环境、状态、动作、奖励、策略)与监督学习的根本区别——监督学习需要什么,RL 需要什么,各自适合什么场景
- 说出 DQN 相比朴素 Q-learning 的两个关键创新(经验回放、目标网络),并解释它们各自解决了什么问题
- 解释 AlphaGo 的三个核心组件(策略网络、价值网络、MCTS)各自的职责,以及它们如何协同工作——能用一句话说清楚每个组件解决了哪个具体困难
- 说清楚 AlphaGo Zero 与原版 AlphaGo 的本质区别——Zero "从零开始"意味着什么,这个结果对"人类专家知识是否必要"这个问题意味着什么
- 解释为什么围棋对 AI 特别难,穷举搜索为什么在物理上不可能,AlphaGo 如何绕开了这个根本性困难
- 说出 RL 在实际应用中的至少 3 个核心挑战(样本效率、奖励设计、泛化能力),并解释它们与现实世界部署的关系
- 解释 RL 与 LLM 是如何在 RLHF 和推理模型中汇合的——AlphaGo 的哪些技术思想在语言模型领域找到了对应物
14.14、常见误解
❌ “AlphaGo 是靠穷举所有棋步、找到最优解来赢棋的”
✅ 实际上:围棋的状态空间是 1017010^{170}10170,穷举在物理上不可能——从宇宙大爆炸到今天以光速计算,也远不够覆盖所有状态。AlphaGo 靠的是策略网络(减少需要考虑的分支数量)+ 价值网络(评估局面价值,避免模拟到终局)+ MCTS(智能探索而非随机枚举)的组合,在有限时间内找到高质量的落子选择。搜索是有方向的智能搜索,不是暴力枚举。
❌ “AlphaGo Zero 打败了所有人类说明 AI 不需要任何人类知识就能超越人类”
✅ 实际上:AlphaGo Zero 的优势体现在计算资源近乎无限的条件下——490 万盘自我对弈,这是任何人类棋手一生也无法完成的练习量。在样本效率上(用多少数据达到多高水平),人类的学习远比 RL 更高效。“不需要人类棋谱"不等于"不需要大量计算资源”。Zero 的胜利是计算的胜利,不是"AI 天然比人类强"的证明。
❌ “强化学习可以解决所有问题,只要给出正确的奖励函数”
✅ 实际上:奖励函数的设计极其困难。“奖励黑客"问题(AI 找到意想不到的方式最大化奖励指标但不完成真实目标)是 RL 应用的核心工程难题。定义"你真正想要的行为"而不只是"你能描述的”,本质上和 AI 对齐问题是同一件事。此外,样本效率低、泛化能力差也是 RL 在真实世界落地的系统性挑战。
❌ “AlphaGo 使用了模拟人类思维的方式来’理解’围棋”
✅ 实际上:AlphaGo 不"理解"围棋的文化意义、美学价值或人类心理。它只优化一件事:最大化当前局面最终获胜的概率。Move 37 之所以看起来像"神来之笔",是因为它在 AlphaGo 的评估框架下是胜率最高的落点——不是因为 AlphaGo 有美学感受力。"理解"是我们对功能行为的拟人化解读。
❌ “AlphaZero 超越 Stockfish 是因为算力更强、搜索了更多步棋”
✅ 实际上:Stockfish 每秒搜索约 7000 万步,AlphaZero 每秒搜索约 8 万步——比 Stockfish 少了约 1000 倍。AlphaZero 的胜利来自更好的局面理解(神经网络更准确地评估哪些分支值得探索,哪些可以剪枝),而不是搜索更多。这是"评估质量"对"搜索数量"的胜利。
❌ “RL 和监督学习是完全独立的技术路线”
✅ 实际上:AlphaGo 本身就是监督学习(预训练策略网络)和 RL(自我对弈优化)的组合。AlphaProof 用了 LLM(监督学习的语言模型)+ RL 搜索。RLHF 用监督学习训练奖励模型,再用 RL 优化语言模型。两条路线的深度融合,正是当前最强 AI 系统的主流训练范式——而这个融合,DeepMind 在 2016-2024 年的系列工作中已经系统性地预演了。
本章关键词
| 词汇 | 简明定义 |
|---|---|
| 强化学习(Reinforcement Learning,RL) | 通过与环境交互,从奖励信号中学习最优策略的机器学习范式;不需要预标注的"正确答案" |
| 马尔可夫决策过程(MDP) | RL 的形式化数学框架:状态(S)、动作(A)、转移概率(P)、奖励(R)、折扣因子(γ);要求当前状态包含决策所需的全部信息 |
| Q 值(Q-value) | 在状态 sss 下执行动作 aaa 后,遵循最优策略所能获得的期望累积奖励;Q-learning 的核心计算对象 |
| 信用分配问题(Credit Assignment Problem) | 当最终奖励出现时,如何把这个奖励分配回之前的各步决策,判断哪一步决策贡献了多少结果;RL 的核心难题之一 |
| Deep Q-Network(DQN) | DeepMind 2013/2015 年提出,用深度神经网络近似 Q 函数,首次让神经网络从原始像素中学习复杂决策 |
| 经验回放(Experience Replay) | 将历史交互经验存入缓冲区,训练时随机采样,打破时序相关性;DQN 稳定训练的关键技术 |
| 目标网络(Target Network) | DQN 的双网络结构:在线网络频繁更新,目标网络缓慢更新,为训练提供稳定目标 |
| 策略网络(Policy Network) | AlphaGo 中预测"在当前局面下各落子点好棋概率分布"的神经网络;从人类棋谱学习围棋直觉 |
| 价值网络(Value Network) | AlphaGo 中预测"当前局面下当前玩家最终获胜概率"的神经网络;解决稀疏奖励和终局模拟问题 |
| 蒙特卡洛树搜索(MCTS) | 通过有选择的树展开和节点评估找到高质量落子的搜索算法;结合神经网络后大幅提升搜索质量 |
| 自我博弈(Self-Play) | AI 通过与自己(或历史版本)对战来产生训练数据,无需人类对局;AlphaGo Zero 的核心训练范式 |
| 策略梯度(Policy Gradient) | 直接优化策略参数的 RL 算法类别,通过让高奖励动作出现概率更高来改进策略 |
| 奖励黑客(Reward Hacking) | AI 找到意想不到的方式最大化奖励指标但不完成真实目标;RL 的核心工程挑战,也是对齐问题的微观版本 |
| 探索-利用困境(Exploration-Exploitation Dilemma) | RL 的基本困境:如何在充分利用已知最优策略(利用)和尝试可能更好的未知策略(探索)之间平衡 |
| 样本效率(Sample Efficiency) | 达到某一性能水平所需的经验量;RL 的样本效率通常远低于人类学习,是真实世界部署的核心障碍 |
| AlphaGo Zero | 2017 年 DeepMind 发布,完全不依赖人类棋谱,仅通过自我博弈学习,超越所有前代 AlphaGo 版本 |
| AlphaZero | 2017 年 DeepMind 发布,同一算法在国际象棋、将棋、围棋三种棋类上均超过对应领域最强引擎 |
| AlphaStar | 2019 年 DeepMind 发布,在《星际争霸 II》中达到职业选手水平,首个在不完全信息实时游戏中超越人类的 AI |
| AlphaProof | 2024 年 DeepMind 发布,结合 LLM 和 RL 搜索,在 2024 年 IMO 上解答 4/6 道题,输出 Lean 4 形式化证明 |
延伸阅读
-
必读:Mnih, V., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518, 529–533.——DQN 的 Nature 论文,经验回放和目标网络的完整描述,实验设计清晰
-
必读:Silver, D., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529, 484–489.——原版 AlphaGo 论文,策略网络+价值网络+MCTS 的完整描述,读第 2-3 节
-
必读:Silver, D., et al. (2017). Mastering the game of Go without human knowledge. Nature, 550, 354–359.——AlphaGo Zero 论文,自我博弈框架,训练曲线和与前代版本的对比
-
推荐:Silver, D., et al. (2018). A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), 1140–1144.——AlphaZero 论文,三种游戏的实验对比,风格分析最有意思
-
推荐:Vinyals, O., et al. (2019). Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575, 350–354.——AlphaStar 论文,多智能体自我博弈,不完全信息处理
-
入门:Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press.——RL 领域的经典教材,第 1-6 章覆盖 MDP、Q-learning、策略梯度基本框架,有免费在线版本
-
深入:DeepMind Blog (2024). AI achieves silver-medal standard solving International Mathematical Olympiad problems.——AlphaProof 的技术博客,解释形式化证明 + RL 搜索的组合方式
[!tip]
下一章预告:RL 征服了游戏与科学,语言模型掌握了文字。2022 年,这两条路线迎来了它们最重要的交汇点——一个叫做 ChatGPT 的产品,用来自人类反馈的强化学习(RLHF)对齐一个预训练语言模型,第一次让 AI 真正"懂得"如何与人类交谈。这是第十五章的故事:从 InstructGPT 到 ChatGPT,对齐的艰难之路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)