OpenSpatial: A Principled Data Engine for Empowering Spatial Intelligence论文精读
·
这篇论文《OpenSpatial: A Principled Data Engine for Empowering Spatial Intelligence》的核心贡献是提出并开源了一个面向空间智能的数据引擎,系统性地解决了当前多模态大语言模型在空间理解能力上的数据瓶颈问题。
一、论文解决了什么问题?
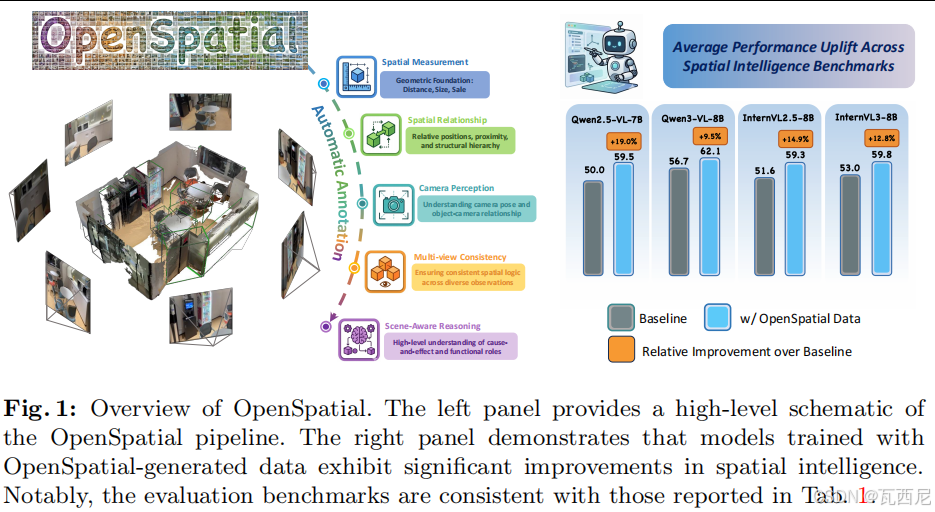
核心问题:当前多模态大模型缺乏高质量、可扩展、多样化的空间理解训练数据,导致空间智能能力不足。
具体表现包括:
- 数据质量差:现有方法大多基于2D标签或弱监督信号,难以精确表达物体的3D几何结构。
- 数据多样性不足:现有数据集往往只覆盖少数场景或任务,导致模型“空间短视”,在真实世界中泛化能力差。
- 数据生成过程不透明:大多数方法只发布最终数据集,不开放数据生成工具,导致研究不可复现,难以进行系统性的消融实验。
二、论文怎么解决这些问题?
论文提出了一个开源、可控、模块化的空间数据引擎——OpenSpatial,其核心设计包括:
1. 3D框为中心的数据表示
- 使用有向3D边界框作为统一的空间表示。
- 每个物体用一个OBB表示:中心坐标、边长、旋转角度(Roll/Pitch/Yaw),定义在世界坐标系中。
- 这种表示方式:
- 视角不变:在不同视图中保持一致。
- 支持多种空间推理:测量、关系、多视图一致性等。
- 比点云更紧凑,比2D标签更精确。
2. 两条并行的数据标注路径
| 模式 | 方法 | 特点 |
|---|---|---|
| 人工标注 | 遵循EmbodiedScan协议 | 精度高,但成本高,难以扩展 |
| 自动3D提升 | 使用Gemini + SAM + 三维重建 | 可扩展到互联网视频、开放场景 |
自动提升流程:
- 对每帧图像进行物体识别 + 实例分割
- 跨帧关联同一物体
- 重建3D凸包 → 拟合OBB
3. 场景图驱动的QA合成
- 对每个场景构造场景图(物体 + 属性 + 关系)
- 生成两类QA:
- 单视图QA:带视觉锚点(标记图像)的空间关系、比较、推理问题
- 多视图QA:跨视图一致性、相机变换、重识别等问题
- 显式控制任务类型,避免“空间短视”
4. 任务分类体系(5大类,19个子任务)
| 任务 | 含义 |
|---|---|
| Spatial Measurement (SM) | 尺寸、距离等度量 |
| Spatial Relationship (SR) | 左右、前后、上下等关系 |
| Camera Perception (CP) | 相机位姿、物体-相机关系 |
| Multi-view Consistency (MC) | 跨视图一致性 |
| Scene-Aware Reasoning (SAR) | 场景布局、可通行性、规划 |
三、标签是如何制作的?
整个标签制作流程是论文最核心的技术贡献之一,具体步骤如下:
Step 1:获取场景级3D OBB
- 输入:多视图图像或视频关键帧 + 相机位姿
- 两种方式:
- 人工标注:在3D空间中手动标注OBB
- 自动提升:
- 每帧用Gemini做物体识别
- 每帧用SAM做实例分割
- 跨帧匹配同一物体
- 重建3D凸包 → 拟合OBB
Step 2:3D框 → 帧级属性映射
- 将每个OBB投影到每个图像帧
- 应用两个过滤条件:
- 投影后的2D框是否在相机视锥内
- 是否被遮挡(通过深度图+点云占有率判断)
- 对通过过滤的框:
- 使用SAM精修掩码
- 生成2D框、部分点云、物体标签
Step 3:构建场景图
- 每帧一个场景图:物体节点 + 属性 + 关系边
- 多视图时合并场景图
Step 4:QA生成
- 程序化枚举物体、属性、关系
- 生成问题模板 + 答案
- 对单视图问题,生成标记图像(高亮目标物体)作为视觉锚点
四、实验验证效果
- 训练数据:OpenSpatial-3M(300万样本),结合部分SenseNova-800K和通用数据(1:1比例)
- 模型:在Qwen2.5-VL、InternVL等模型上SFT
- 结果:
- 在BLINK、AllAngles、MMSI等空间推理基准上平均提升14.1%,最高19%
- 比Cambrian-S、SenseNova-SI、VST等开源数据集效果更优
- 保持通用能力不下降(MMBench、MMMU等)
五、总结:论文的核心价值
| 维度 | 贡献 |
|---|---|
| 理念 | 从“发布数据集”转向“开源数据引擎” |
| 表示 | 首次系统化采用3D OBB作为空间推理的统一基元 |
| 数据 | 开源OpenSpatial-3M,300万样本,5大类任务 |
| 工程 | 高效并行 + 自动3D提升 + 场景图驱动 |
| 效果 | 显著提升多种模型的空间推理能力,SOTA |
数据集开源地址
https://huggingface.co/datasets/jdopensource/JoyAI-Image-OpenSpatial/tree/main/data

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)