告别“失忆”的组织:构建企业级 AI 记忆基质的工程思考
原文链接: AI 小老六
在今天的企业 AI 浪潮中,我们很容易陷入一个技术错觉:只要把 Slack、Jira、CRM 和内部文档库的 API 全都打通,再套上一个统一搜索框,公司就拥有了“大脑”。
这种方案确实能做出很酷的 Demo,但它解决的仅仅是“检索(Retrieval) ”问题,而非“记忆(Memory) ”问题。检索系统能告诉你“哪份文档提到了这件事”,而真正的组织记忆系统需要回答的是:“这件事在当下的业务语境里,到底意味着什么?”
如果缺乏这层底层的记忆基质(Memory Substrate) ,我们投入生产的 AI Agent 就像是在没有上下文的冰面上狂奔——动作飞快,但极易失控。构建企业大脑,本质上不是做一个更聪明的企业搜索,而是解决组织的“失忆症”,让机器真正理解并参与到组织的决策脉络中。
为什么数据堆砌换不来组织记忆?
企业里从来不缺数据,缺的是对数据的“语义解析”。
真实的业务决策往往散落在会议、邮件、甚至走廊上的口头交流中。几个月后,当后来者试图理解某个决策时,他们往往只能看到 PRD 或工单这些“决策的遗骸”。至于当时谁提出了反对意见、哪个前置假设最脆弱、哪些风险被战略性忽略了,这些鲜活的上下文早就随风飘散。
这就凸显了检索与记忆的本质差异。举个例子,客户在电话里提了一句:“如果做不到这一点,我们可以等到下个季度再推进。”
搜索系统只会把这句话作为纯文本召回。但在一个真正的企业记忆系统里,这句话会根据角色的不同,折射出完全不同的语义: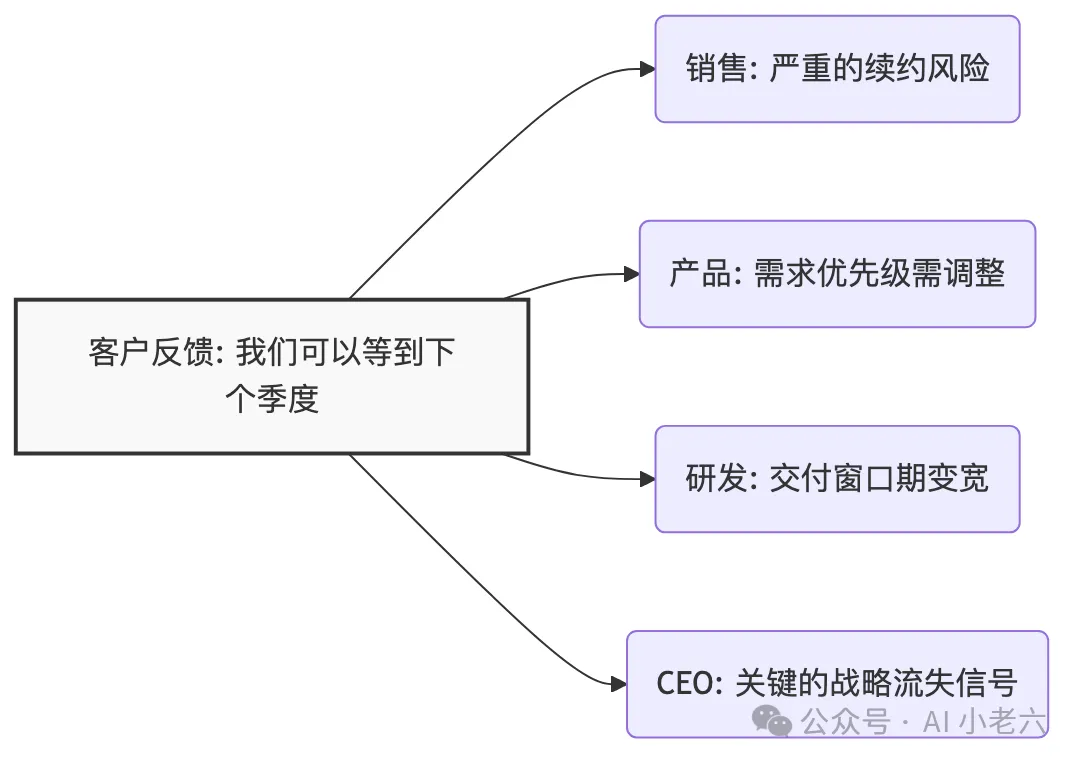
*图:同一条客户反馈在不同角色中的语义折射*
同一条信息,落在不同的时间节点和业务角色上,其分量截然不同。这正是为什么我们要把 Agent 重新放回组织系统里去思考:Agent 的任务、约束和安全边界,都必须建立在扎实的组织记忆之上。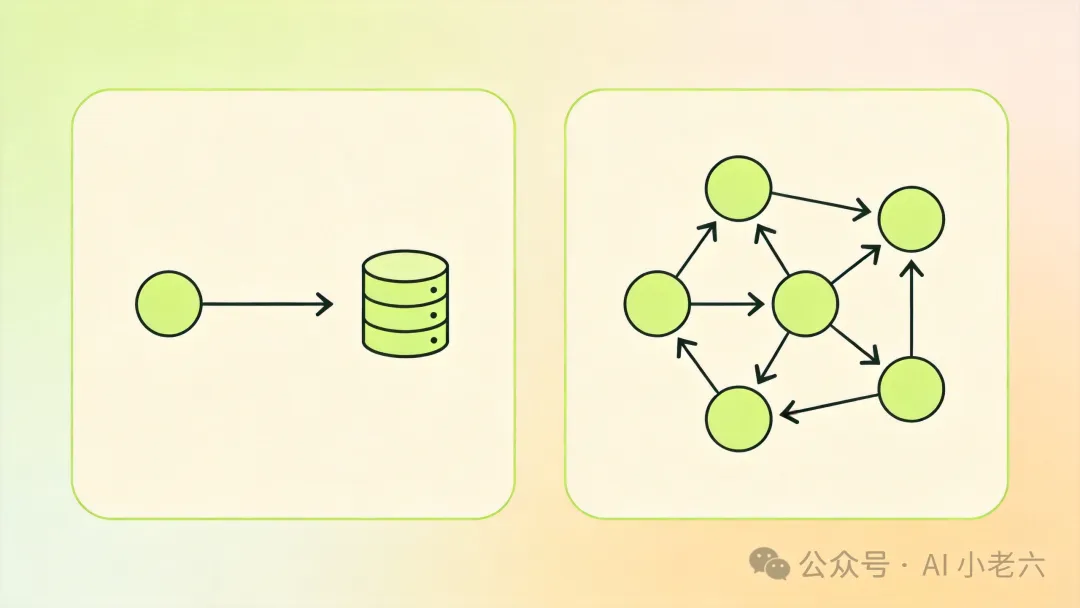
*图:数据检索与组织记忆的本质差异*
记忆基质的三层架构
要让 Agent 具备真正的业务 sense,企业大脑的记忆基质可以拆解为三个递进的层次。这不仅是对数据结构的重塑,更是对人类认知模式的工程化映射。
事实记忆(Factual Memory):追溯信息本源
第一层是事实记忆。不要把它等同于共享网盘或 Wiki,它的核心工程挑战在于建立高可信度的“溯源体系(Provenance) ”。
一条合格的事实记忆不能是一句孤立的断言,它必须包含明确的元数据:这条结论出自哪场会议?谁是当前的 Owner?信息的保鲜期(Freshness)过了吗?它的置信度有多高?权限边界在哪里?
例如,一条销售承诺不应只是一段文本,而是应该以结构化的形式存在,并关联到特定的客户、项目风险和原始会议录音。
这就要求我们跳出单纯的 RAG(检索增强生成)框架。Embedding 擅长寻找文本相似度,但无法处理“负责人变更”或“事实被新决议覆盖”这种动态逻辑。更务实的解法是构建 Semantic File System + Context Graph:让每一个业务 Artifact 都拥有明确的类型和元数据,同时用图网络(Graph)将它们的关系固化下来,使之可遍历、可更新。
交互记忆(Interaction Memory):还原决策现场
如果事实记忆记录的是“发生了什么”,交互记忆解决的就是“为什么这么决定”。
绝大多数高价值的业务对齐,都发生在系统之外的对话里。交互记忆的目标不是简单地保存会议转录(Transcript),而是要留存意义的生成过程。
这里引入了一个关键的工程概念:本体(Ontology) 。系统需要通过 Ontology 将非结构化的对话识别为特定的业务实体,比如“承诺(Commitment)”、“风险(Risk)”、“假设(Assumption)”或“反对意见(Objection)”。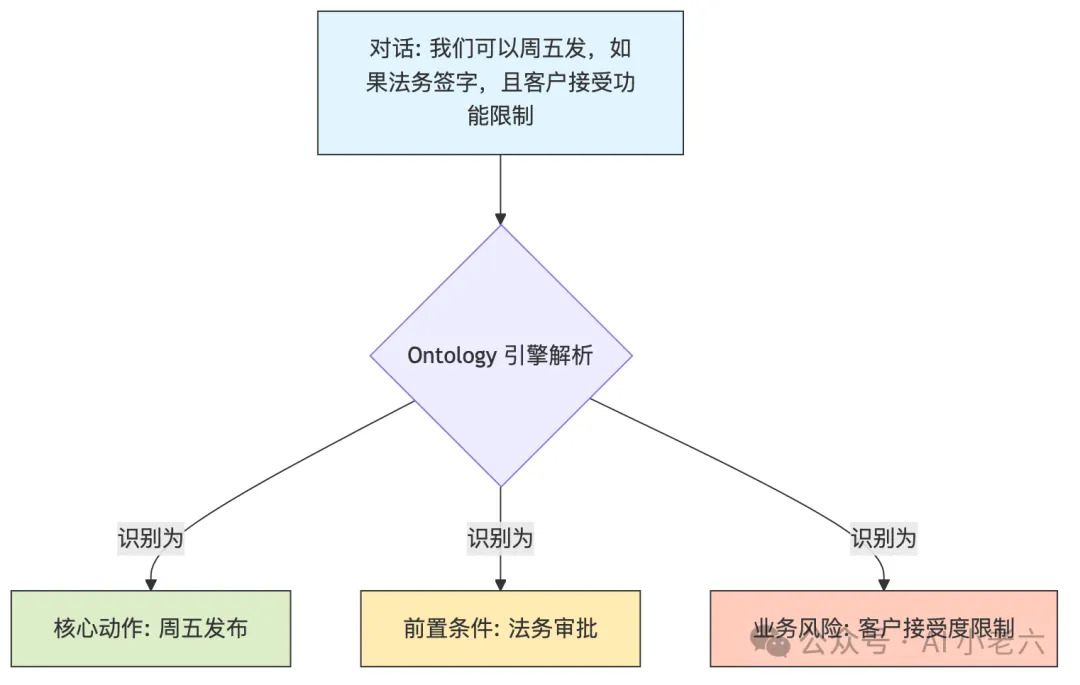
*图:本体引擎对非结构化对话的解析过程*
这层记忆离“人”最近,因此工程边界也最为严苛。不是所有的私下讨论都该沉淀为公司记忆,系统必须在“提供上下文”与“避免监控感”之间找到平衡。有些会议只能提取抽象信号,有些异议(Dissenting view)应当被完整保留而非被摘要抹平。能让组织安全地“重读过去”,才是交互记忆的真正价值。
行动记忆(Action Memory):上下文驱动的协同
前两层构建了档案库,第三层“行动记忆”才真正赋予了系统 Agent 时代的意义。它关注的不是“执行固定工作流(Workflow Automation)”,而是“协同(Coordination) ”。
当面对流程不完整、责任人不清晰的模糊地带时(例如:同一客户的抱怨在三次电话中被提及,但未被汇总为产品需求),Action Memory 能够主动将散落的上下文拼凑起来,带回工作现场。
它为 Agent 提供了清晰的执行边界:知道哪些动作可以直接执行,哪些需要人工审批,哪些判断已经过期需要重新对齐。这层记忆把 Agent 从一个莽撞的 API 调用器,变成了一个懂得组织分寸的数字成员。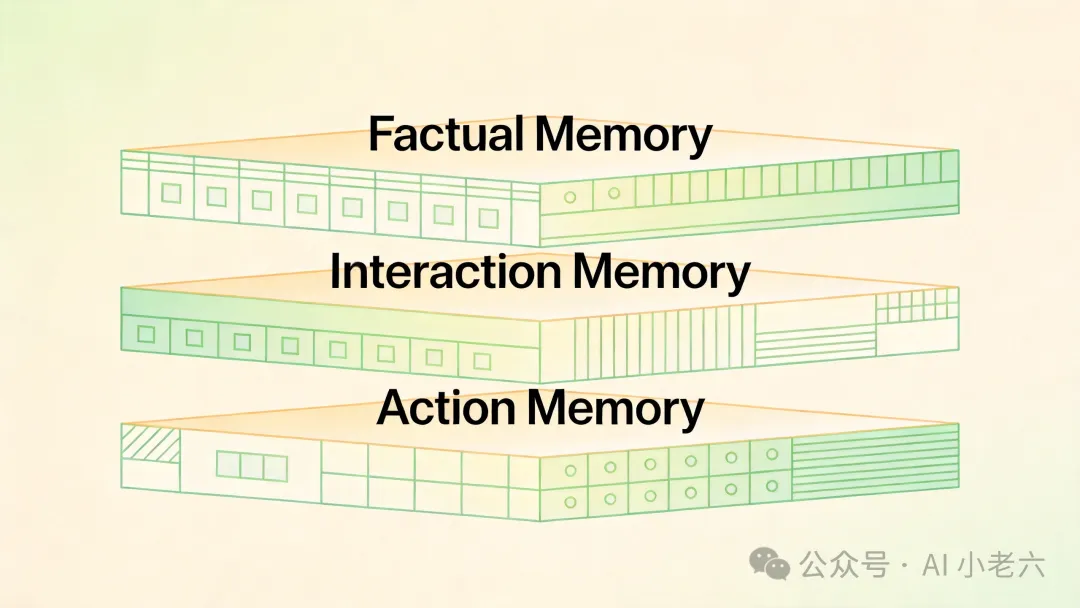
*图:事实、交互与行动三层记忆基质架构*
务实演进:最小可行架构(MVP)设计
如果要在工程上落地这样一个企业级大脑,不能从做一个聊天框起步,而应从底层的记忆基质搭起。以下是一个务实的最小可行架构及其关键设计原则:
*图:企业级大脑记忆基质的最小可行架构*
- • 先建 Event Log,保留回放能力:所有的输入(消息、转写、变更记录)先作为 Append-only 的事件流落盘。Schema 和 Ontology 随时会迭代,只要保留了最原始的事件日志,系统就永远具备纠错和重新解析的能力。
- • Extractor 输出 Claim,而非 Truth:不要让大模型直接把抽取的结论当成绝对事实写入库中。更稳健的做法是输出带有置信度、状态为“待验证(Unverified)”的“声明(Claim)”。让这些声明在图网络中被后续的事件交叉验证、降权或正式确认为事实。
- • 双擎检索:Embedding + Graph Traversal:单纯依靠 Embedding 容易丢失权限、负责人等核心属性;而单纯依靠图检索又会漏掉未结构化的新鲜信息。标准的查询必须是两者的结合:用 Embedding 召回候选切片,用 Graph 补全关系链。
- • Policy Layer 必须是一等公民:在处理交互记忆时,权限绝不仅仅是“文件读写”那么简单,它甚至细化到“用户是否有权知道某条记忆的存在”。权限控制如果不是底层基建而是上线前打的补丁,系统最终会沦为无人敢用的工具。
- • 克制的 Action Router:早期不要追求全盘自动化。让系统先从低风险动作切入:生成业务简报、标记冲突假设、建议人工复核。等组织对这套记忆基质建立信任后,再逐步向半自动和全自动迈进。
结语
在评估一家 AI-native 公司时,我们不应只看它部署了多少个 Agent,而应审视:这个组织是否能记住自己为何以这种方式工作。
没有事实记忆,企业就失去了信息的本源;没有交互记忆,企业就遗忘了决策的推敲过程;没有行动记忆,企业就不知如何在模糊态下协同。在这样一个失忆的底座上叠加再多的 Agent,也只是在错误的方向上加速。
AI 时代的软件工程,正在从单纯的“流程自动化”向更深邃的“组织记忆工程”演进。未来的核心护城河,属于那些从第一天起,就把组织的“Why”妥善沉淀下来的企业。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)