如何更好使用好OpenCode
-
OpenCode是什么
-
OpenCode 是一个开源的 AI 编程助手,运行在终端里。它能
-
理解代码:读代码、分析代码、解释代码
-
生成代码:写新功能、改旧代码、重构架构
-
执行操作:运行命令、操作文件、连接外部工具
-
自动化:批量处理、多步骤任务、持续集成
-
-
-
OpenCode 的架构
-
┌─────────────────────────────────────────┐│ 用户界面层 (CLI/TUI) ││ - 命令行交互 / 终端界面 / Web 界面 │├─────────────────────────────────────────┤│ AI 引擎层 (LLM) ││ - Claude / GPT / Gemini / Ollama │├─────────────────────────────────────────┤│ 核心能力层 ││ - Agent 系统 / Skills 系统 / MCP 系统 │├─────────────────────────────────────────┤│ 工具集成层 ││ - 文件系统 / Git / 浏览器 / API / DB │└─────────────────────────────────────────┘
-
用户界面层:你输入命令的地方,可以是命令行、终端界面或者 Web
-
AI 引擎层:真正"思考"的地方,支持多种大语言模型
-
核心能力层:OpenCode 的核心竞争力,包括 Agent、Skills、MCP 三大系统。
-
工具集成层:连接外部世界的能力,让 AI 能操作真实的环境
-
-
如何用好OpenCode
-
Agent 模式:让 AI 自主完成复杂任务
-
Skills 系统:让 AI 拥有你的团队经验
-
MCP 集成:让 AI 能使用各种专业工具
-
企业级功能:让 AI 能安全地服务整个团队
-
-
Agent 模式
-
传统模式 vs Agent 模式
-
传统模式(对话模式):
你:这段代码有 bug,帮我看看 AI:问题在第 15 行,应该改成 xxx 你:(复制粘贴)改好了吗? AI:还有第 23 行 你:(复制粘贴)现在呢? AI:第 37 行也有问题 你:(内心崩溃)... -
Agent 模式:
你:把项目里所有 bug 都修好 AI:好的,我来处理 ↓ AI:(自动读取文件 → 分析问题 → 修改代码 → 验证修复 → 提交结果) ↓ AI:已修复 23 处问题,这是修改摘要... -
区别:
-
传统模式是"你指挥,AI 建议"。你得一步步告诉 AI 做什么,它才能帮你
-
Agent 模式是"你定目标,AI 执行"。你只需要说"把项目里所有 bug 都修好",AI 会自己规划步骤、执行操作、验证结果。
-
-
-
Agent 模式的核心能力
-
自主决策能力
-
分析任务复杂度
-
规划执行步骤
-
选择最佳方案
-
处理异常情况
-
-
多步骤执行能力
-
连续执行多个操作
-
根据中间结果调整策略
-
自动验证每一步的结果
-
失败时自动重试或报告
-
-
工具使用能力
-
读取文件系统
-
执行 shell 命令
-
运行测试
-
操作 Git
-
-
上下文感知能力
-
理解项目结构
-
记住之前的操作
-
保持任务连贯性
-
处理依赖关系
-
-
-
Agent 模式的底层原理
-
ReAct 框架(Reasoning + Acting),Agent 模式的核心是一个叫做 ReAct 的框架。ReAct = Reasoning(推理)+ Acting(行动)
-
工作流程是这样的
-
思考(Thought):AI 分析问题,决定下一步做什么
-
行动(Action):AI 执行具体的操作(读文件、改代码、运行命令)
-
观察(Observation):AI 观察执行结果
-
循环:根据观察结果,再次思考、行动、观察,这个过程会不断循环,直到任务完成
-
-
工具调用机制
-
OpenCode 给 AI 提供了一系列"工具",每个工具都有
-
名字(name)
-
描述(description)
-
参数(parameters)
-
返回值(return value)
-
-
比如"读文件"工具:
{ "name": "read_file", "description": "读取指定文件的内容", "parameters": { "path": { "type": "string", "description": "文件路径" } } } -
上下文管理
-
任务目标
-
执行历史
-
当前状态
-
中间结果
-
错误信息,OpenCode 通过精心设计的提示词(Prompt)和上下文压缩技术,确保 AI 能在有限的上下文窗口内高效工作。
-
-
-
-
如何开启 Agent 模式
-
最简单的方式是在启动 OpenCode,在命令行切换到对应的目录,然后执行opencode
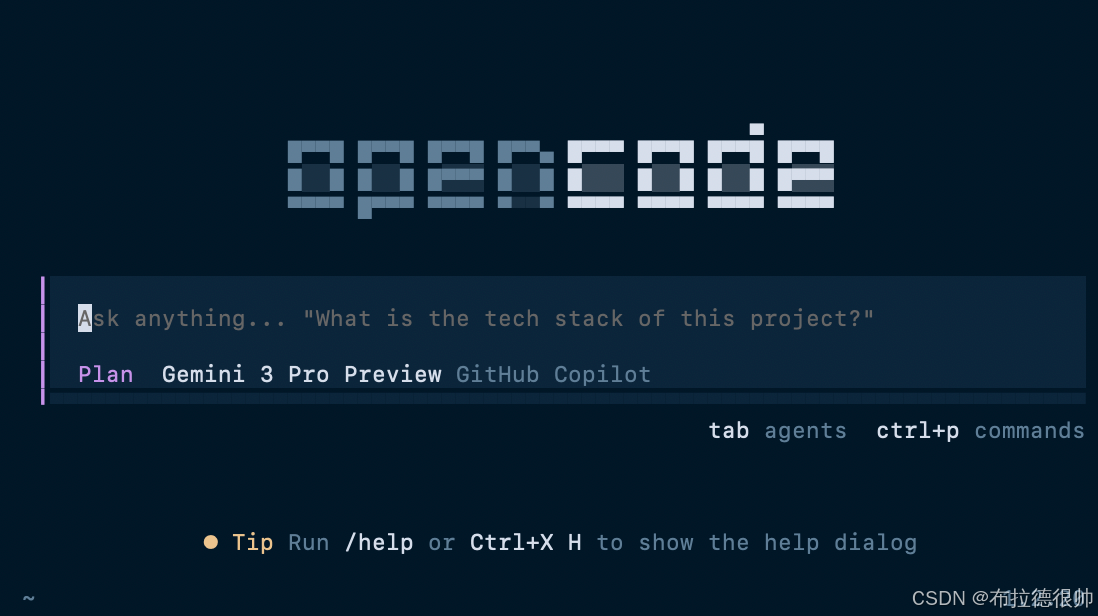
当前是 plan 模式,只能对话,按 tab 切换 build 模式

-
-
Agent 模式的最佳实践
-
任务拆解原则
-
大任务拆小任务:
-
❌ 不好:
> 帮我把这个老项目全部重构了 -
✅最佳实践
> 第一步:将网络请求重构为项目特有的 NetWork.get().xxx().onResponse{} 链式调用格式 > 第二步:按照 VMContract 规范重构代码,确保 ViewModel 实现接口并通过 LiveData 暴露数据 -
-
每个任务要有明确的目标和验收标准
要求:给 src/utils 目录下所有 Kotlin 工具函数补充完整的 KDoc 注释。 验收标准:每个 public / internal 函数必须包含 KDoc: 使用 /** */ 格式 必须包含:@param 所有参数必须覆盖,必须说明参数语义(尤其是 Boolean / flag / 可空参数) -
-
review 机制
-
养成看
git diff的习惯
-
-
测试驱动
-
让 AI 改完代码后必须跑测试:
-
-
修改代码并确保所有测试通过 > 如果测试失败,回滚修改并报告问题 -
-
Skills系统
-
什么是Skills:Skills 是一套可复用的指令模板,Skills 就是把"你的经验"变成"AI 的能力"
-
Skills 和 Agent 模式有什么区别
Agent 模式
Skills 系统
定位
执行能力
知识封装
作用
让 AI 能动手
让 AI 懂规则
使用方式
临时指令
预定义模板
复用性
每次都要说
一次定义多次使用
适用场景
具体任务
标准化流程
Agent 模式就像你让一个程序员"去重构代码"。他会自己思考怎么做。Skills 系统就像你给程序员 一本《代码重构手册》,告诉他:"以后重构都按这个手册来"。两者可以结合使用:用 Skills 定义 流程,用 Agent 模式执行流程
-
Skills 能做什么
-
代码质量类
-
开发流程类
-
团队协作类
-
领域专业类
-
-
Skills如何加载
-
当你启动 OpenCode 时,它会从当前目录开始,向上查找所有包含
.opencode/skills/或.claude/skills/的目录。当前工作目录/.opencode/skills/ 当前工作目录/.claude/skills/ 父目录/.opencode/skills/ 父目录/.claude/skills/ ... 直到 git 仓库根目录 ~ ~/.config/opencode/skills/ (全局) ~/.claude/skills/ (全局兼容)子项目可以覆盖或扩展父项目的 Skills,Skill 的 description 字段包含关键词,AI 会根据用户 输入匹配最合适的 Skill,例如:用户说"帮我审查代码" → 匹配 code-review Skill,用户 说"生 成 API 文档" → 匹配 api-doc Skill
-
显式调用
-
用户可以直接指定使用某个 Skill:/skill use code-review
-
-
-
创建Skill
name: beast-android-review description: 针对 Beast Android 项目的架构、网络层、MVVM 规范及性能安全审查 tags: - android - kotlin - beast-arch - mvvm - performance --- # Beast Android 项目代码审查 ## 审查范围 ### 1. 架构规范 (MVVM & VMContract) - **VMContract 实现** - ViewModel 必须实现 `*VMContract` 接口 - 必须继承自 `PageVM<Intent>` 或相关基类 - 数据暴露必须使用 `CommLiveData` 或 `LiveData`,严禁直接暴露 `MutableLiveData` - **生命周期管理** - 检查是否滥用 `GlobalScope` (应使用 `viewModelScope` 或 `lifecycleScope`) - 检查 `onCleared()` 资源释放 ### 2. 网络层规范 (Custom Network Framework) - **链式调用完整性** - 必须遵循 `Request -> setParams -> onResponse -> onError -> doRequest` 模式 - 严禁漏掉 `.doRequest()` (这是最常见错误) - **异常处理** - 必须包含 `.onError { }` 处理逻辑 - 关键业务请求必须处理 `data.isSuccess()` 和 `data.code` 校验 - **线程安全** - 网络回调默认在主线程,检查是否在回调中执行耗时操作 (应切 `Dispatchers.IO`) ### 3. Kotlin & 代码风格 - **空安全 (Null Safety)** - 严禁使用 `!!` 非空断言 (除非有极强理由) - 使用 `?.let` 或 `runCatching` 处理潜在空指针 - **变量定义** - 优先使用 `val` - 可变状态使用 `AtomicBoolean` / `AtomicInteger` (在并发场景下) - 集合操作优先使用 `mutableListOf` / `arrayListOf` 配合读写分离 ### 4. 业务逻辑与埋点 - **关键埋点检查** - 检查 `DzTrackEvents`、`PlayerTrack` 调用是否完整 - 检查 `LogUtil` 是否符合规范 (Tag 统一) - **广告与VIP逻辑** - 检查广告位 ID 是否硬编码 (应从配置读取) - 检查会员权益逻辑是否被绕过 ### 5. 性能与资源 - **内存泄漏** - 检查 ViewModel 中是否持有 View/Context 引用 - 检查 `EventBus` / `Listener` 是否反注册 - **UI 渲染** - 检查是否在 `onBindViewHolder` 中进行耗时计算 ## 输出格式 ```markdown ## Beast Android 代码审查报告 ### 概览 - 审查模块:{{module_name}} - 问题总数:{{issue_count}} 个 - ⛔ 阻断 (Blocker):{{blocker_count}} 个 - ⚠️ 警告 (Warning):{{warning_count}} 个 - 💡 建议 (Suggestion):{{suggestion_count}} 个 ### 详细问题 #### 1. [⛔ 阻断] business/detail/vm/PlayDetailVM.kt:468 **问题**:网络请求链式调用不完整,缺少 `doRequest()` **代码**: DetailNetwork.get().adWelfareRequest() .setParams(...) .onResponse { ... } // ❌ 缺少 .doRequest(),请求不会发送 **修复**: DetailNetwork.get().adWelfareRequest() .setParams(...) .onResponse { ... } .doRequest() // ✅ 已添加 #### 2. [⚠️ 警告] business/detail/vm/PlayDetailVM.kt:85 **问题**:ViewModel 内部变量未使用 Atomic 类型,存在并发风险 **代码**: private var adLoaded = false **修复**: private val adLoaded = AtomicBoolean(false) ### 改进建议 1. 建议将 `_allDataList` 的过滤逻辑移至 `Dispatchers.Default` 线程执行,避免阻塞 UI。 2. ... ## 使用示例 > /skill use beast-android-review path=business/detail/src/main/java/com/dz/business/detail/vm/PlayDetailVM.kt ```保存在项目跟目录,
,然后就可以应用这个skill Review代码了,使用/skill use beast-android-review path=business/detail/src/main/java/com/dz/business/detail/vm/PlayDetailVM.kt这种方式,输出结果:
-
团队 Skills 仓库
-
创建一个专门的仓库管理团队 Skills
beast-opencode-skills/ ├── README.md ├── skills/ │ ├── code-review/ │ │ └── SKILL.md │ ├── commit-message/ │ │ └── SKILL.md │ └── pr-template/ │ └── SKILL.md ├── templates/ │ └── component/ ├── scripts/ │ └── install.sh └── package.json安装脚本(
scripts/install.sh)#!/bin/bash # 安装团队 Skills 到全局 SKILLS_DIR="$HOME/.config/opencode/skills" REPO_URL="https://gitlab31.dhwaj.cn/clt-dzfree/beast-android/opencode-skills.git" # 克隆或更新 if [ -d "$SKILLS_DIR/.git" ]; then cd "$SKILLS_DIR" && git pull else git clone "$REPO_URL" "$SKILLS_DIR" fi echo "✓ 团队 Skills 已安装到 $SKILLS_DIR" echo "可用的 Skills:" ls "$SKILLS_DIR/skills/" -
-
项目级 Skills
-
与项目代码一起管理,将项目特定的 Skills 放在项目仓库中:
-
dz-project/ ├── .opencode/ │ └── skills/ │ ├── domain-specific/ # 领域特定 │ ├── framework-specific/ # 框架特定 │ └── team-conventions/ # 团队约定 ├── src/ ├── package.json └── README.md如果多个项目共享同一套 Skills,可以使用 Git 子模块
# 添加 Skills 子模块 git submodule add https://gitlab31.dhwaj.cn/clt-dzfree/beast-android/opencode-skills.git .opencode/skills # 克隆项目时递归克隆子模块 git clone --recursive https://gitlab31.dhwaj.cn/clt-dzfree/beast-android.git -
-
MCP
-
什么是mcp
-
让 AI 能操作外部工具和系统,MCP(Model Context Protocol)是一个开放的协议标准,它定义了 AI 模型如何与外部工具、数据源、服务进行交互
-
MCP核心特点
-
标准化:统一的接口定义,不同工具遵循相同规范
-
安全性:细粒度权限控制,可审计可追溯
-
扩展性:支持任意类型的工具和服务
-
灵活性:本地和远程服务都能连接
-
-
MCP可以解决什么问题
-
浏览器自动化
-
数据库操作
-
API 集成
-
文件系统
-
版本控制
-
-
-
MCP 架构
┌─────────────────────────────────────────┐ │ OpenCode │ │ ┌──────────────────┐ │ │ │ MCP Client │ │ │ └────────┬─────────┘ │ └──────────────────┼──────────────────────┘ │ ┌────────┴────────┐ │ MCP Protocol │ │ (stdio / sse) │ └────────┬────────┘ │ ┌───────────┼───────────┐ │ │ │ ┌──────┴──────┐ ┌─┴────────┐ ┌┴──────────┐ │ MCP Server │ │ MCP │ │ MCP │ │ (Playwright)│ │ Server │ │ Server │ │ │ │ (GitHub) │ │ (Filesystem) └─────────────┘ └──────────┘ └───────────┘ -
MCP与Skills 的区别
-
核心区别
维度
MCP
Skills
定位
外部工具连接
内部知识封装
作用
扩展 AI 能力
规范 AI 行为
实现
独立进程/服务
Markdown 文件
范围
跨项目通用
项目/团队特定
权限
需要显式授权
默认允许
-
协作关系
┌─────────────────────────────────┐ │ 用户请求 │ └──────────────┬──────────────────┘ │ ┌──────┴──────┐ │ Skills │ ← 决定"做什么" └──────┬──────┘ │ ┌──────┴──────┐ │ MCP │ ← 决定"用什么做" └──────┬──────┘ │ ┌──────┴──────┐ │ 外部工具 │ └─────────────┘举例:
1,用户说"测试登录功能" 2,Skills 系统匹配到"e2e-testing" Skill 3,Skill 指导 AI 使用 Playwright MCP 4,Playwright MCP 操作浏览器执行测试 -
查看opencode可以用的MCP
-
opencode mcp list
可以看到目前我这个电脑上没有配置MCP服务
-
添加MCP服务
-

到这里可以看到我成功的添加了drawio这个强大的绘图服务,添加完成以后再输入命令opencode mcp ls
可以看到有一个mcp服务安装
-
通过draw.io绘制流程图
-
-
安装OMO
-
如果说OpenCode 就从一个 AI 助手,那么安装Oh My OpenCode后,OpenCode 就从一个 AI 助手变成了一个完整的 AI 开发团队。Oh My OpenCode是一个为 OpenCode(设计的强大插件/扩展层。它将单个 AI 代理升级为一个多智能体协作团队,提供开箱即用的高
-
核心亮点包括
-
Sisyphus 主智能体:负责持续执行复杂任务,直至完成
-
持并行运行专业子智能体(如 Oracle 预言者、Librarian 文档专家、Frontend Engineer 前端工程师、Explore 探索者等)。
-
内置 LSP/AST 工具(代码重构)、MCP(模型调用插件,如搜索、文档检索)、钩子系统(25+ 种事件触发)
-
多模型调度:自动分配任务给最适合的模型(例如 Gemini 处理前端、Claude 处理规划)
-
关键词触发完整自动化(如
ultrawork或ulw),支持后台任务、Todo 强制执行、上下文注入等 -
基本触发
-
在 OpenCode 的提示词中加入关键词 ultrawork(或简写 ulw),例如:这会激活完整模式:Sisyphus 主智能体接管,自动分配子任务给专业代理,并行执行(后台映射代码库、深度探索、自动重构等),直至任务 100% 完成
-
-
选择哪种智能体执行
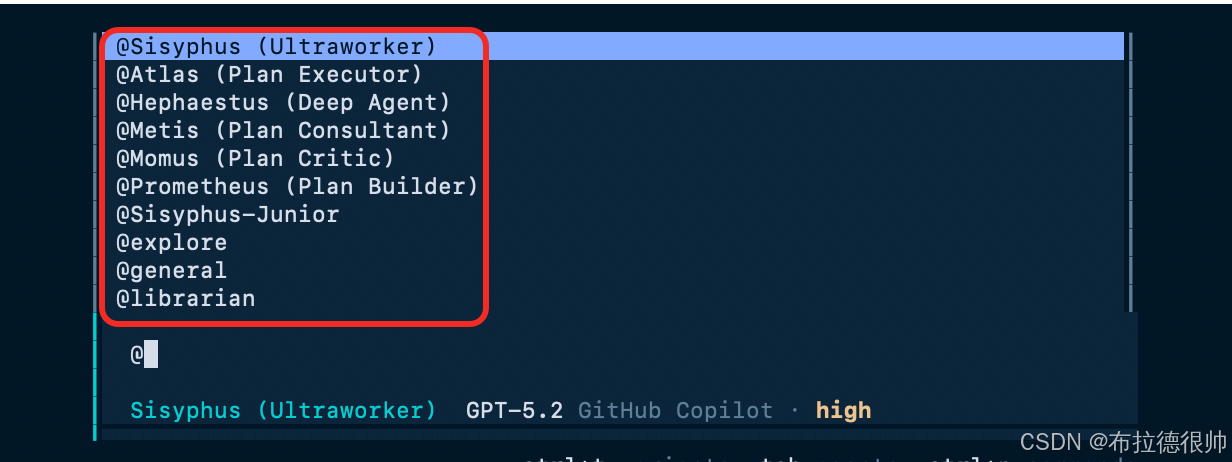
对于大型复杂任务可以通过/ralph-loop 连续循环运行好几个小时执行,直到最后任务完成
-
-
-
-
-
-
最佳实践
-
从写好提示词开始
-
提示词(Prompt)是你与 AI 沟通的桥梁。好的提示词能让 AI 准确理解你的意图,给出高质量的结果
-
具体明确
-
❌ 差的提示词
帮我重构代码 -
✅ 好的提示词:
优化 java/com/business/detail/vm/DetailVM.kt中的requestInfoList函数: - 当前实现使用方法太长 - 抽取核心功能到具体方法,方法命名需要见名知意 - 保持现有接口不变 - 添加适当的类型定义 - 采用合适的设计模式,做到高内聚,低耦合,结构清晰 -
-
提供上下文
-
❌ 差的提示词:这个报错怎么解决?
-
✅ 好的提示词:
在运行测试时遇到错误: 错误信息: (MyFirebaseMessagingService.kt:39) com.google.firebase.messaging.FirebaseMessagingService.dispatchMessage (FirebaseMessagingService.java:254) com.google.firebase.messaging.FirebaseMessagingService.passMessageIntentToSdk (FirebaseMessagingService.java:204) com.google.firebase.messaging.FirebaseMessagingService.handleMessageIntent (FirebaseMessagingService.java:190) com.google.firebase.messaging.FirebaseMessagingService.handleIntent (FirebaseMessagingService.java:179) com.google.firebase.messaging.EnhancedIntentService.lambda$processIntent$0 (EnhancedIntentService.java:82) java.util.concurrent.ThreadPoolExecutor.runWorker (ThreadPoolExecutor.java:1154) 问题:om.dz.business.fcm.FcmManager.sendCustomCommonNotification这行报错,线上crash收集到的。 请给出修复方案,要求: 1. 考虑兼容性 2. 处理错误状态 -
结构化输出
-
明确要求 AI 的输出格式:
请分析这段代码的性能问题,按以下格式输出: ## 问题列表 1. [问题描述] - [严重程度:高/中/低] - 位置:[文件:行号] - 影响:[性能/内存/可读性] - 建议:[具体优化方案] ## 优化优先级 按影响程度和实现难度排序 ## 代码示例 提供优化后的代码片段 -
-
迭代优化
-
不要期望一次提示就得到完美结果。采用迭代方式
第一轮:基本功能实现 第二轮:添加错误处理 第三轮:优化性能 第四轮:完善文档 -
-
提示词模板库
-
代码审查请求
请审查以下代码,关注: 1. 代码规范和风格 2. 潜在 bug 和安全问题 3. 性能优化机会 4. 可维护性和可读性 文件:{{file_path}} 代码:{{code}} 请以清单形式列出所有问题,按严重程度排序。对于每个问题,提供: - 问题描述 - 具体位置 - 修复建议 - 代码示例 -
功能开发请求
请实现以下功能: ## 需求描述 {{feature_description}} ## 技术要求 - 技术栈:{{tech_stack}} - 接口定义:{{api_spec}} - 数据模型:{{data_model}} ## 验收标准 {{acceptance_criteria}} ## 约束条件 - 不要修改现有接口 - 保持向后兼容 - 添加单元测试 请按以下步骤执行: 1. 分析需求,提出实现方案 2. 等我确认后再开始编码 3. 实现功能 4. 编写测试 5. 生成文档 -
Bug 修复请求
请修复以下 Bug: ## Bug 描述 {{bug_description}} ## 复现步骤 1. {{step_1}} 2. {{step_2}} 3. {{step_3}} ## 期望行为 {{expected_behavior}} ## 实际行为 {{actual_behavior}} ## 环境信息 - 浏览器:{{browser}} - 版本:{{version}} - 相关代码:{{file_path}} ## 错误日志 {{error_log}} 请: 1. 分析根本原因 2. 提供修复方案(先不执行) 3. 等我确认后执行修复 4. 验证修复结果 -
上下文管理技巧
# 引用单个文件 @java/com/dz/business/detail/vm/PlayDetailVM.kt帮我审查这个组件 # 引用多个文件 @java/com/dz/business/base/dialog/evaluate/ReviewDialogHelper.kt @java/com/dz/business/base/dialog/evaluate/ReviewController.kt 分析类型定义 # 引用特定函数 @chapterListLoadingRequest函数帮我优化性能 # 引用代码行范围 @java/com/dz/business/detail/vm/PlayDetailVM.kt:650-737 这段逻辑太臃肿,结构不清晰问题 -
保持上下文连贯:
# 第一次请求 > 分析 ava/com/dz/business/detail/vm/PlayDetailVM.kt的接口设计 # AI 分析完成... # 第二次请求(基于之前的分析) > 基于刚才的分析,帮我重构这些接口 > 要求保持 RESTful 规范 # AI 理解上下文,基于之前的分析进行重构 -
清理上下文:
-
-
> /context clear 上下文已清理。之前的对话历史将不再影响后续回答。 > /context summary 当前上下文摘要: - 正在处理:用户管理系统重构 - 相关文件:src/api/users.ts, src/services/userService.ts - 上次操作:接口分析 -
-
日常开发工作流
┌─────────────────────────────────────────────────────────┐ │ 开发流程(AI 辅助) │ ├─────────────────────────────────────────────────────────┤ │ 1. 需求理解 │ │ ↓ 使用对话模式讨论需求 │ │ - 与 AI 讨论业务逻辑 │ │ - 确定技术方案 │ │ - 识别潜在风险 │ │ │ │ 2. 技术设计 │ │ ↓ 生成设计文档 │ │ - 让 AI 帮助设计架构 │ │ - 生成接口定义 │ │ - 定义数据模型 │ │ │ │ 3. 编码实现 │ │ ↓ 切换 Agent 模式 │ │ - 生成代码框架 │ │ - 实现业务逻辑 │ │ - 编写单元测试 │ │ │ │ 4. 代码审查 │ │ ↓ 使用 Skills │ │ - 自动代码审查 │ │ - 人工复核 │ │ - 修复问题 │ │ │ │ 5. 测试验证 │ │ ↓ 运行测试套件 │ │ - 单元测试 │ │ - 集成测试 │ │ - AI 辅助调试 │ │ │ │ 6. 文档更新 │ │ ↓ 自动生成文档 │ │ - API 文档 │ │ - 更新 README │ │ - 添加变更日志 │ └─────────────────────────────────────────────────────────┘-
具体示例
-
# ========== 步骤 1: 需求理解 ========== > 我要实现一个广告】接入MAX、AdMob的开屏功能,需求如下: > 一、需求描述 广告类型:开屏 接入渠道 MAX聚合的applovin、admob、meta、Liftoff、InMobi、panggle。 AdMob聚合的admob、panggle、InMobi、Liftoff。 测试广告位 MAX(applovin) MAX(admob) MAX(meta) MAX(Liftoff) MAX(InMobi) MAX(panggle) MAX(applovin、admob、meta、Liftoff、InMobi、panggle) AdMob(admob) AdMob(panggle) AdMob(InMobi) AdMob(Liftoff) AdMob(admob、panggle、InMobi、Liftoff) > > 请帮我分析这个需求,包括: > - 涉及哪些模块 > - 可能的技术方案 > - 需要注意的安全问题 AI:分析完成,建议... # ========== 步骤 2: 技术设计 ========== > 基于刚才的分析,帮我设计技术方案: > 1. 生成 API 接口文档(OpenAPI 格式) > 2. 设计数据库表结构 > 3. 设计前端表单组件 AI:生成设计文档... # ========== 步骤 3: 编码实现 ========== > /agent on > 请按照设计文档实现用户注册功能: > 1. 先实现后端 API(Node.js + Express) > 2. 再实现前端表单(React + TypeScript) > 3. 最后实现邮箱验证逻辑 > > 每完成一个模块告诉我,我确认后再继续 AI:[实现后端 API] 用户:确认,继续 AI:[实现前端表单] 用户:确认,继续 AI:[实现邮箱验证] 用户:确认,完成 # ========== 步骤 4: 代码审查 ========== > /skill use code-review > 审查刚才实现的用户注册功能 AI:[自动审查报告] # ========== 步骤 5: 测试验证 ========== > 运行所有测试,确保通过 AI:✓ 所有测试通过 # ========== 步骤 6: 文档更新 ========== > 更新相关文档: > 1. 更新 API 文档 > 2. 更新 README 的使用说明 > 3. 添加变更日志 AI:文档已更新 -
-
AI思考和展望
-
AI 是效率放大器,而非替代者
-
在研发体系中,AI 应作为工程师与产品经理的“增强工具”,重点关注
-
数据安全与隐私合规(尤其涉及用户行为与内容分发)
-
输出可控性(避免幻觉带来的决策风险)
-
持续学习与Prompt工程优化,构建团队级AI使用范式
-
-
-
需求阶段:引入 AI 进行预 Review 与价值评估
-
在 PRD 或需求评审前,通过 AI 提前完成
-
需求完整性检查(是否存在边界遗漏、异常路径缺失)
-
技术实现风险识别(如并发、缓存一致性、埋点缺失等)
-
产品价值分析(用户收益 vs 成本 vs 转化路径)
-
-
-
提测阶段:基于 AI 的冒烟预测试机制
-
在正式 QA 前,引入 AI 做轻量自动化验证:
-
核心路径冒烟(登录、播放、广告链路等)
-
UI/交互异常检测(文案、布局、状态机异常)
-
-
-
AI + 崩溃治理
-
Crash 自动归因(类似 Glide / NPE / 多线程问题
-
给出修复建议甚至代码Patch
-
-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)